基于文本挖掘和K-means聚类的航空安全事故报告的可视化分析方法
2022-02-17马婷
马婷
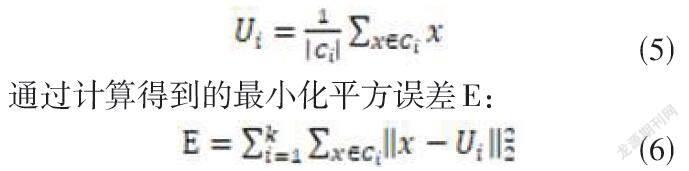






摘要: 航空事故对航空安全起到至关重要的作用,影响航空安全的因素是多重的。文章对航空安全事故报告采用文本挖掘和R语言,找出航空安全事故的致险因素,对航空安全提供参考,收集事故报告90例,首先采用了结巴分词对数据进行分词处理,其次是过滤分词结果中的停用词和无效词,然后进行关键字的提取,找出能够代表文本特征的词条,建立向量空间模型,最后采用K-means聚类算法,在K值为3时聚类效果达到最佳,将航空事故致险因素分为了人为-环境-设备三类,利用R语言的Word Cloud程序包将实验结果进行可视化处理,得出8项主要致险因素,17项一般致险因素。根据词云图中的致险因素,从人-环境-设备三个方面为以后的飞行安全提供了有价值的参考信息。
关键词: 航空安全事故报告;文本挖掘;分词;聚类;致险因素
中图分类号:G642 文献标识码:A
文章编号:1009-3044(2022)35-0056-04
人们的生活方式正悄无声息地发生变化,比起其他交通工具,乘坐飞机出行已经成了人们的日常。从2018的有关航空安全的数据来看,航空安全形势仍然严峻,还有许多安全问题是不容忽视的。因此,对于航空安全性进行提高是航空公司以及从业人员都迫不及待需要解决的问题[1]。
美国在20世纪70年代首创的航空安全系统(Aviation Safety Reporting System),是国外开始针对航空安全事故报告开展研究的起始点。该系统可以从航空安全报告中分析出造成事故的原因,从而使类似事件发生的概率大大降低。近年来,国内也有不少人致力于对安全事故报告进行相关方面的分析研究,如文献[2]基于文本挖掘技术和R语言,对334份建筑施工安全事故报告进行分词处理和特征项降维,识别出8项建筑工人不安全行为及其27项影响因素。文献[3]以某管制单位2004—2019年共269条管制原因不安全事件数据为挖掘语料,运用LDA主题模型挖掘管制运行风险主题及关键词,使用Word2Vec挖掘主题之间和关键词之间有怎样的关联性、用UCINET分析软件、可视化工具NETDRAW构建语义网络将关联关系进行可视化并进行网络分析。结果表明:挖掘到7个主题,主要以管制人为因素为主。文献[4]以航空安全事故报告作为数据基础,通过TF-IDF、LDA算法进行致险因素的分析,在此基础上提出如何来进行风险的预测。其中包括6项主要致因因素和20项一般致因因素。文献[5]构建出了基于朴素贝叶斯网络结构的“人-船-管理-环境”系统。通过对TFIDF算法的进一步改进,推导出人为因素是造成船舶碰撞事故风险因素的第一因子。文献[6]通过词云和网络结构图的可视化展示,展示出了地铁施工安全风险的致险因素,并根据这些因素对事故发生的重要程度对其进行了等级划分。文献[7]是以ASN、NTSB和世界事故数据为基础来构建民航系统的事故数据库,所采用的算法是多维关联规则的算法。文献[8]采用内容分析方法,分析在飞机飞行阶段的安全问题及造成安全问题的原因有什么样的关系,通过分析得到对于某一起航空安全事故发生的主要原因并不是单一的,而是由“环境”“管理”“人为”等多重因素相互叠加造成的。
上述方法大部分是通过分析事件及事件之间关系,但出于机器学习聚类的使用比较少,并且通过可视化展现分析结果的使用也比较少,本文借助了文本挖掘和R语言技术,K-means聚类的方法及可视化,从90例飞行事故报告,挖掘航空事故致险因素。
1 文本挖掘
文本挖掘是数据挖掘领域中的一个部分,主要的作用是挖掘对用户具有潜在价值的新知识。文本挖掘是针对文本类型的数据进行定性分析和定量计算,将包含在其中的各种类型的隐式知识挖掘出发,如隐含其中的信息模式、结构等[9]。文本挖掘的方法主要针对某些包含信息模式和结构的文本信息源展开分析和计算,其应用主要包含实现有监督的文本分类和无监督的文本聚类。
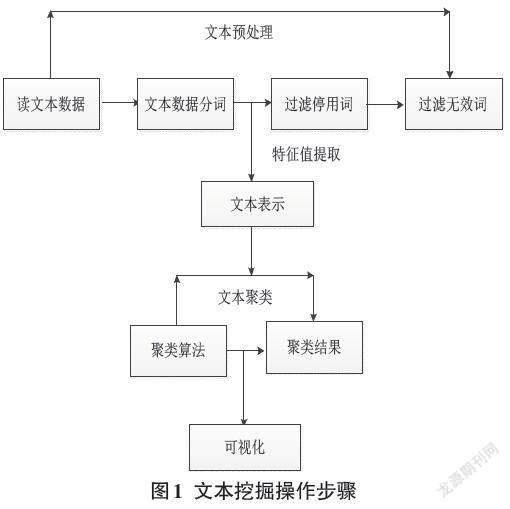
本文文本挖掘操作步骤如图1所示。
2 文本挖掘语料及挖掘工具选择
在做文本挖掘之前首先要选择合适的挖掘工具,典型的开源的文本挖掘工具有LINGPIPE、LIBSVM、WEKA、ROST CM等[10-11],ROST CM挖掘工具主要用于中文文本,WEKA算法在许多数据挖掘專业人员中相对流行,因为它的算法很全面, LIBSVM挖掘工具主要针对SVM模式识别与回归操作,并且为了对自然语言进行更好地处理,人们开发出了LINGPIPE挖掘工具包。R语言则可提供完全免费开放的环境,它由于涵盖的功能多种多样,而且包含在内的成熟稳定的函数齐全,成了一门可以用来专门做统计和数据分析工作的高效的语言,可以针对不同的用户需求提供相应的程序分析包,同各种IOS的兼容性好,而且它的功能也很齐全。因此,鉴于以上的分析比较,最终选择了涵盖数据处理、统计分析和数据可视化功能的R语言及相应程序包,对所搜集的航空安全事故报告进行了挖掘分析[12-14]。
为了保证实验所用的数据具有真实性,实用性,我们采用航空安全网(Aviation Safety Network)中的数据为实验中的基础数据,另外通过全网搜索与航空安全事故有关的信息,从民航资源网等相关的管理部门网站共收集事故报告90例。
搜集的90例航空安全事故报告来源如表1所示。
3 基于R语言文本挖掘的航空事故致险因素分析
特征表示通常我们会把文本数据用向量空间模型来表示,即提取的特征值与相对应的权重进行组合,所包含的概念如下:
(1) 某个语料库文档或单个文件集中的某一段,叫作文档,记为D,文件总数为[D];
(2) 区别其他类文档与这类文档的重要依据, 某一个给定的词或词语,我们把它称为特征值;
(3) 对于一类文档而言,特征值是有多么重要,我们用权重来表示。
TF表示某一个词或短语在一篇文档中出现多少次及频率[17]。在某个文档中,词频通常用来规范单词的数量并防止它偏向长文档,(与某个词语是否对整篇文章重要无关,在长文件中一个词的出现频率很高,而在某个短文件中出现的频率则很低),所以某一个给定的词或词语出现的频率次数称为词频,在一篇文档里面出现的某个词语ti对文档的重要程度我们把它表示为如公式(1)。
[tfi,j=ni,jknk,j] (1)
公式(1)中,分子部分n(i,j)表示在一篇文档中某个特定的词或词组出现的词频,而式子中的分母表示的是该文档中包含的所有的词或词组出现总词频。
对某个词语在文档中的重要程度进行衡量,我们通常用逆向文件频率来表示。以文件总数作为分子,以有哪些文档包含该特定词语的数目作为分母,再将分子除分母所得到的结果进行对数运算,得到的公式(2),称为某一个特定的词或词组的IDF:
(2)
其中|D|:语料库中的文件总数|{j:t_i∈d_(i,j) }|
tf-idf=tfi,j×idfi (3)
通过式(3)计算,就能得出每个特征项的权重Wik:
(4)
(4) 向量空间模型:特征值和权重进行组合构成向量空间模型。
3.1 航空事故报告预处理
使用了一款高效、对于繁体和自定义的词典可以进行分词得分词包——结巴分词来完成整个文档的分词操作。它以C++作为基础层,并且基于MIT协议实现对RCPP的高效调用。对90份文件采用结巴分词的方式进行分词处理,分词结果中存在着英文单词、停用词等对于本文分析赘余、无效的词汇,部分分词结果如图2所示。为了节省内存空间,在对自然语言数据进行处理的步骤中,通过停用词的过滤,可以提高检索的效率和存储效率,整理的停用词如图2(b)所示。基于已经整理的停用词词典、正则表达式分别过滤停用词、英文单词等无效词汇,过滤后的分布结果如图2(c)所示。观察过滤停用词与英文后的分词结果,发现存在着“网”“号”等单词长字,这些字在文本分析中无实际的效果,通过限制词长来过滤这些词,过滤效果如图2(d)所示。
3.2 特征值选择及空间向量构建
特征值是可以表示文本主要含义的信息,向量空间模型是在文本处理中的模型。TFIDF(term frequency–inverse document frequency)是一种统计方法[15-16],信息加权的技术领域应用较多,主要作用是用于根据某个字词的出现频率,在某个语料库或单个文件集中的某一个单词,对他们存在的重要程度进行评估。
如果在一篇文档中某个词以较高的词频存在时,它通常就可以被用来表示该类别中文档的特征,应该将这样的词语选出来,使其具有较高的权重,并将这些特征词作为区别其他类文档与这类文档的重要依据。
每一行作为一个文本,每一列为关键词,在文档-词频矩阵中,部分提取结果如图3所示。
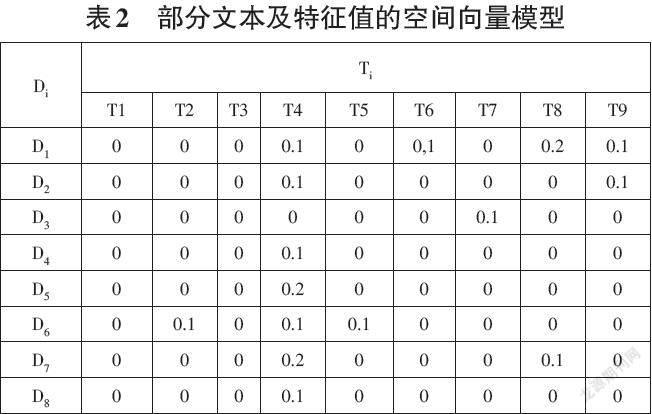
根据空间向量模型的构成方式,如表2为部分文本及特征值的空間向量模型。
3.3 K-Means聚类
K-Means算法其实是一种非常简单的算法,它根据给定样本集中的样本之间的距离,形成K个簇,让样本自动归入到相应的簇内。让簇内的各个点之间的距离尽可能小,而让各个簇之间尽最大的可能分散[18]。
假设生成的K个簇是([S1、S2...Sk]),[Ui]是簇[Si]的均值向量,或者称其为簇的质心,用数据方式表示为:
(5)
通过计算得到的最小化平方误差E:
(6)
K-Means算法实现步骤:
(1)数据集分成几个集合,先确定出K值;
(2)选出质心,质心的选择是任意的,它可以是随机从数据集中选出的k个数据点。
(3)数据集中的每个点与质点之间都有一个距离,我们通过计算距离,能够找到数据集中的点离哪个质点近,就把它们分为一类。
(4)通过上述步骤,使所有数据与其适当的集合成为一个聚类,用k个集合表示,对每一个集合的质心,重新计算一次。
(5)得到第二次的计算结果后,将它与第一次的结果进行比较,如果第二次结果减去第一次的结果小于某个极小数,相当于收敛,那么说明质点的位置没有太大改变,这就是我们所预期的结果已经达到了,不需要再次进行计算。
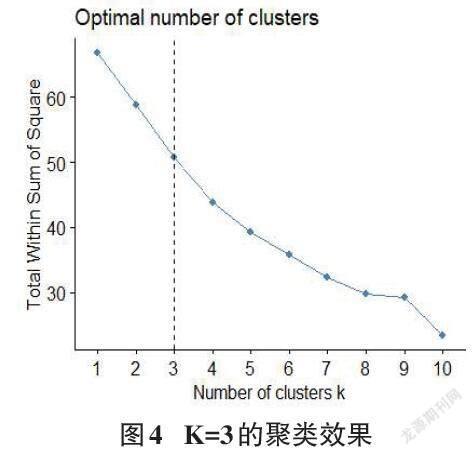
(6)如果第二次结果减去第一次结果值得变化比较大,则需要再次聚类,即转到3~5进行循环迭代,直到满足条件为止[19]。当K=3的时效果最佳,选择聚成三类,将航空事故致险因素分为人为造成事故伤害、天气环境以及设备故障三大类因素,如图4所示。
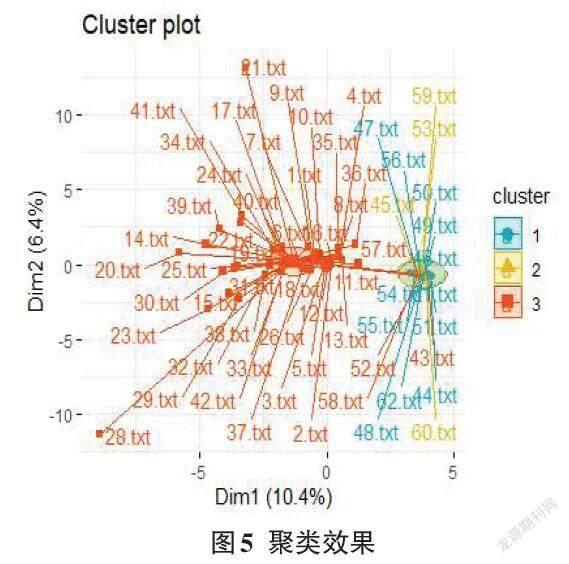
具体的聚类效果如图5所示。
4 聚类可视化
实验的最终结果以造成航空安全事故的因素的词云图展现,通过利用R语言的Word cloud程序包方式进行可视化展示。实验得到的最终结果以词云图形式进行可视化展示,如图6所示。
虽然作为本文数据来源的90份航空安全事故报告,它们的语言表达方式多种多样,内容结构也不尽相同,而且造成每一起航空事故的原因都存在很大差异,但通过实验最后得出的词云图,根据词语字体在图中的居中位置不同、词语方向大小以及明暗颜色都是有一定差别,如误操作、疲劳驾驶、能见度低、安全意识薄弱、管理员决策不当、鸟群撞击、飞机设备故障及失灵等频率较高的词位置居于中央,字体明显比其他词语较大,颜色也较为醒目,我们把它们看成是主要致险因素。而飞行员情绪波动、失压、人员安排、缺氧、低云、无线电通信阻塞、载荷过载等频率低的词字体比较小,位置处于词云图的边缘部分,颜色较不明显,我们把它看成一般致险因素。
5 结语
本文主要借助了文本挖掘和R语言技术,通过文本分词,停用词过滤、无效词过滤、关键字提取,建立向量空间模型,及K-means聚类的方法,从90例飞行事故报告,挖掘航空事故致险因素,最后通过可视化进行显示,显示出的实验结果进行分析得到:
基于对实验所得的航空事故致险因素词云图中字体的大小、位置、颜色等的分析,一起航空安全事故的发生是由一些主要的致险因素和一般的因素造成的,从词云图来看,误操作、疲劳驾驶、能见度低、安全意识薄弱、管理者决策不当、鸟群撞击、飞机设备故障及失灵等这些是主要的致险因素;一般致险因素有:飞行员情绪波动、失压、人员安排、缺氧、低云、无线电通信阻塞、载荷过载等。而一个航空事故的发生不可能是由某个单一的原因造成的,可能由多个致险因素相互叠加而导致,所以每个致险因素都是不容忽视的。为了能够有效地防止航空安全事故的发生,主要从“人为造成事故伤害-天气环境-管理者的管理-设备故障”这四大致险因素出发制定切实可行且有效的措施防止悲剧的发生。
参考文献:
[1] 徐佳迪.公务航空飞行安全的关键风险因素研究[D].天津:中国民航大学,2019.
[2] 薛楠楠,张建荣,张伟,等.基于文本挖掘的建筑工人不安全行为及其影响因素研究[J].安全与环境工程,2021,28(2):59-65,85.
[3] 陈芳,陈茜,徐碧晨.基于文本挖掘的管制运行风险主题分析[J].中国安全生产科学技术,2020,16(11):47-52.
[4] 刘梦娜.基于文本挖掘的航空安全事故报告致因因素分析和风险预测[D].合肥:安徽建筑大学,2019.
[5] 吴伋,江福才,姚厚杰,等.基于文本挖掘的内河船舶碰撞事故致因因素分析与风险预测[J].交通信息与安全,2018,36(3):8-18.
[6] 李解,王建平,许娜,等.基于文本挖掘的地铁施工安全风险事故致险因素分析[J].隧道建设,2017,37(2):160-166.
[7] 侯熙桐.基于多维关联规则的民航事故数据挖掘研究[D].天津:中国民航大学,2016.
[8] 刘俊杰,李华明,梁文娟,等.基于内容分析法的航空安全自愿报告信息分析[J].中国安全科学学报,2012,22(4):90-96.
[9] 张磊.基于文本挖掘的项目风险分析方法研究[D].济南:山东大学,2015.
[10] 张雯雯,许鑫.文本挖掘工具述评[J].图书情报工作,2012,56(8):26-31,55.
[11] 张雪英.国外先进数据挖掘工具的比较分析[J].计算机工程,2003,29(16):1-3.
[12] 马准中.对三种数据挖掘工具的比较[J].实验科学与技术,2005,3(1):45-46,29.
[13] Yang Y Y.Text mining and visualization tools - Impressions of emerging capabilities[J].World Patent Information,2008,30(4):280-293.
[14] Gemert J V.Text mining tools on the Internet an overview[J]. Intelligent Sensory Information Systems,2000(25):1-68.
[15] 张建娥.基于TFIDF和词语关联度的中文关键词提取方法[J].情报科学,2012,30(10):1542-1544,1555.
[16] 章志华,陆海良,郁钢.基于TFIDF算法的关键词提取方法[J].信息技术与信息化,2015(8):158-160.
[17] 施聪莺,徐朝军,杨晓江.TFIDF算法研究综述[J].计算机应用,2009,29(S1):167-170,180.
[18] 回玥婷,夏懿嘉,陈紫荷,等.基于Synonyms、k-means的短文本聚类算法[J].电脑知识与技术,2019,15(1):5-6.
[19] Lee E,Schmidt M,Wright J.Improved and simplified inapproximability for k-means[J].Information Processing Letters,2017,120:40-43.
【通聯编辑:王力】
