支持多用户的高效前向安全可搜索加密方案
2022-02-17马昌社李晓聪陈海龙
马昌社, 李晓聪, 陈海龙
(华南师范大学计算机学院, 广州 510631)
随着大数据时代的到来,数据量的高速增长使不少个人用户和企业选择将数据外包存储到云服务器上。云服务器一般被视为诚实且好奇的:诚实地执行程序,却存在窥探用户数据的可能。因此,一般将数据加密后再存储。但是,经过加密算法处理后的数据不支持快速检索,为了满足数据加密后的高效搜索需求,学术界开始研究可搜索对称加密(Searchable Symmetric Encryption,SSE)技术。
2000年,SONG等[1]提出了实用对称可搜索加密的概念,并给出了第1个SSE方案。此后,学者们提出了一系列在搜索性能、功能、安全性之间权衡的静态SSE方案[2-6]。如:为了提高搜索性能,GOH[2]构建了基于正排索引的SSE方案,CURTMOLA等[3]给出了基于倒排索引的SSE方案;为了拓展更多功能特性,CASH等[4]提出了支持大数据集上联合查询的可搜索加密方案(OXT),SUN等[5]将OXT方案拓展到了多用户场景,孙僖泽等[6]提出了一个密态数据库查询框架,将可搜索加密技术应用到了现有的主流数据库中。然而,已有的静态SSE方案无法满足现实中对文件进行动态更新的需求。2012年,KAMARA等[7]提出了首个动态SSE方案(Dynamic SSE,DSSE),该方案实现了次线性级别的搜索效率,但因引入数据更新机制而导致易泄露更多信息;ZHANG等[8]针对DSSE方案的攻击指出,只需要注入不多于100个文件,就可恢复全部的关键字信息。为了减缓动态SSE方案中的文件注入攻击,STEFANOV等[9]给出了DSSE方案中的前向安全定义,指出前向安全为DSSE方案的必备要求,并设计了一个基于茫然随机访问内存[10](Obilivious Random Access Memory,ORAM)的前向安全DSSE方案。
支持前向安全的方案避免了旧的搜索令牌与新加入的密文文件产生关联,从而减缓隐私泄露。从技术角度概括,除了基于开销巨大的ORAM的方案外,实现前向安全的方式主要可以分为以下3种:(1)通过单向函数构建索引。如BOST[11]首次基于公钥密码学原语设计了高效DSSE方案;HE等[12]通过原像不可逆的哈希函数构建索引,减少了客户端本地存储,但引入了更新次数的限制。(2)通过多次更换密钥重构索引。如ETEMAD等[13]提出了基于重构索引的方案,该方案虽然不要求服务器有计算功能,但要求客户端为查询结果重新构造索引,因此在搜索时的通信开销和客户端的计算开销巨大。(3)通过对称加密函数构建索引。如SONG等[14]针对文献[11]中公钥密码学原语带来的性能瓶颈,构造了基于对称密码学原语的前向安全方案,为目前理论搜索性能最优的前向安全DSSE方案。
然而,在现有的前向安全DSSE方案中,大部分方案仅支持单用户环境,这是由于为了生成最新的搜索令牌,这些方案在客户端本地维护了一个存储了所有关键字状态信息的状态表,而关键字状态存储在本地使得方案难以支持多用户检索[15]。目前仅有的2种支持多用户检索的前向安全方案[16-17]增设了一个可信中间件来记录关键字状态,数据拥有者在动态更新后,将状态表保存在可信中间件中,其他用户发起查询时,首先将搜索请求发送到可信中间件,再由可信中间件根据当时的状态表计算出最新的搜索令牌发送给服务器。尽管支持多用户检索的前向安全方案[16-17]为设计多用户前向安全DSSE方案提供了思路,但在资源受限的情况下,增设可信服务器的方法并不实用。
针对上述问题,本文提出了一个基于双链索引结构的支持多用户的高效前向安全可搜索加密方案(Efficient Multi-user Forward Secure SSE,EMFS)。该方案无需增设可信中间件,基于陷门单向函数构建主链索引,基于流密码寻址式结构构建从链索引,利用陷门函数在无密钥时的单向计算性,以及主索引链的长度不依赖于各关键词状态,实现了前向安全和多用户;利用从链高效遍历的特性以及对主链检索长度的缓存优化,达到了搜索的高效性。最后,将EMFS方案与Sophos[11]、FAST[14]、BESTIE[18]方案进行对比实验。
1 预备知识
1.1 伪随机函数
令F:{0,1}λ×{0,1}n→{0,1}n是一个多项式时间可计算函数,如果对于任何敌手,都有
成立,则称F是一个伪随机函数,其中第1个概率依赖于K{0,1}n的均匀随机性,第2个概率依赖于从n比特字符串映射到n比特字符串的函数集合中抽样出f的随机性。
1.2 陷门置换
陷门置换(Trapdoor Permutation,TDP)是定义域与值域相同的陷门单向函数。对于给定的运行在置换域D的一个陷门置换π,使用公钥pk可以快速地进行正向计算,使用私钥sk可以反向计算置换π-1。陷门置换是一个算法三元组(KeyGen,π,π-1),其中:
(1)(pk,sk)←KeyGen(λ)是一个随机生成算法。其输入是安全参数λ,输出是公钥pk和私钥sk。
(2)y←π(pk,x)是一个确定性算法。其输入是公钥pk和原像xD,输出是置换下的像yD。
(3)x←π(sk,y)是一个确定性算法。其输入是私钥sk和像yD,输出是原像xD。
陷门置换还应满足以下安全性质:在没有私钥的情形下,反向计算置换π-1十分困难。任何一个PPT敌手在没有私钥的情况下成功求解反向置换的概率λ)≤negl(λ)。
1.3 多用户SSE参与者
一般来讲,多用户SSE系统的参与者由三方组成:
(1)数据拥有者:数据拥有者将数据加密后存放到云服务器,并为密文数据生成检索索引,为被授权用户生成授权信息。此外,在支持动态更新的SSE方案中,数据拥有者负责给新添加的文件选取关键字,发送相应数据以帮助服务器添加密文文件和更新检索索引。
(2)云服务器:服务器根据存放的加密文件、对应的索引以及用户发送过来的搜索令牌完成搜索,并将正确查询结果发送给用户,同时可以利用自身的计算能力来分析用户的隐私信息。
(3)数据使用者(其他用户):在搜索时,根据数据拥有者提供的授权信息为需要搜索的关键字生成搜索令牌,然后将搜索令牌提交给云服务器,并接收返回来的结果。
1.4 动态SSE形式化定义
根据文献[11]给出的通用动态对称可搜索加密方案的定义,给定安全参数λ, 一个动态对称可搜索加密方案DSSE包含了1个初始化算法和2个客户端与服务器之间的两方协议:
(1)((K,σ);EDB)←Setup((λ,DB);⊥):系统初始化算法。客户端输入安全参数λ、明文数据集DB,服务器无需输入。该算法输出主密钥K、状态值σ和加密数据库EDB,其中主密钥K和状态值σ由客户端存储,加密数据库EDB由服务器存储。
(2)(σ′;EDB′)←Update(K,σ,op,input,EDB):更新协议。客户端输入密钥K、当前状态值σ、更新操作符op和要更新的数据input,服务端输入加密数据库EDB,其中op{add,del}用于指示本次更新为添加操作或删除操作,新数据是形如
(3)((σ′,DB(w);EDB′))←Search((K,σ,w),EDB):搜索协议。客户端输入密钥K、前状态值σ、要搜索的关键字w,服务端输入密文数据库EDB。搜索结束后客户端获得搜索结果集合DB(w),此外客户端输出一个可能更新过的状态值σ′,服务端输出一个可能更新过的密文数据库EDB′。
1.5 安全定义
CURTMOLA等[3]首次给出了SSE方案的安全性的正式定义,通过泄露函数来刻画SSE方案的安全泄露,由2个以上的游戏证明SSE方案的安全性,一个游戏代表真实的协议执行,一个游戏由仿真器根据泄露函数模拟生成。如果敌手无法区分自己是在哪个游戏中,则表明敌手不掌握除了泄露函数之外的任何知识,称这样的方案为-自适应语义安全的。泄露函数维护了一个请求列表q,其中qiq代表第i次请求。常见的泄露函数有搜索模式sp(x)、查询模式qp(x):
sp(x)={i|(i,x)q} (qi为搜索请求),
qp(x)={i|(i,x)qor (i,op,input)qandx
input} (qi为搜索请求或更新请求)。
前向安全是针对动态可搜索加密方案的强安全属性,要求服务器无法将新添加的文件与已存在的文件相关联。换言之,在新添加了一个文档后,该文档包含的关键字信息在下一次搜索查询前不会被泄露给敌手,更新请求不会泄露新添加的文件是否包含之前搜索过的关键字。形式化定义如下:
定义1[11](前向安全)一个-自适应安全的动态对称可搜索加密方案是前向安全的,如果它的更新泄露函数为如下形式:
Update(op,input)=′(op,{idi,|Widi|}),
其中idi为第i个更新的文件的标识符。
2 EMFS方案
本文提出了一个支持多用户的高效前向安全可搜索加密方案(EMFS),该方案在文件更新和搜索时都不需要额外的可信中间件参与。本章首先介绍该方案的索引结构,再介绍协议的具体步骤。
2.1 EMFS索引结构
EMFS方案基于双链索引结构,该结构由两部分组成:陷门单向函数组成的主链和解密后可直接寻址的侧链(图1)。
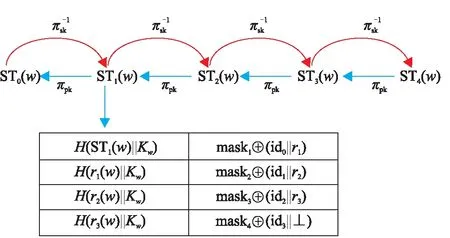
图1 EMFS方案的索引结构示意图Figure 1 The structure of index of EMFS scheme
通过主链上的陷门单向函数,可以实现新加入的文件与以往存在的文件的不可链接性,直到客户端搜索时将最新的搜索令牌发送给服务器。搜索时,被授权用户根据当前的更新次数c计算出最新的搜索令牌STc(w),并将其发送给服务器。由于服务器不拥有私钥,因而只能单向计算陷门单向函数,对于任何的i>c,服务器不能计算出STi(w)。假设下次更新加入的文件包含关键字w,由于新文件存放的地址将由STc+1(w)通过哈希计算得到,因此,直到服务器收到能搜索到新文件的搜索令牌STc+1(w)前,都不能将新文件与以往的关键字关联,从而保证了前向安全。
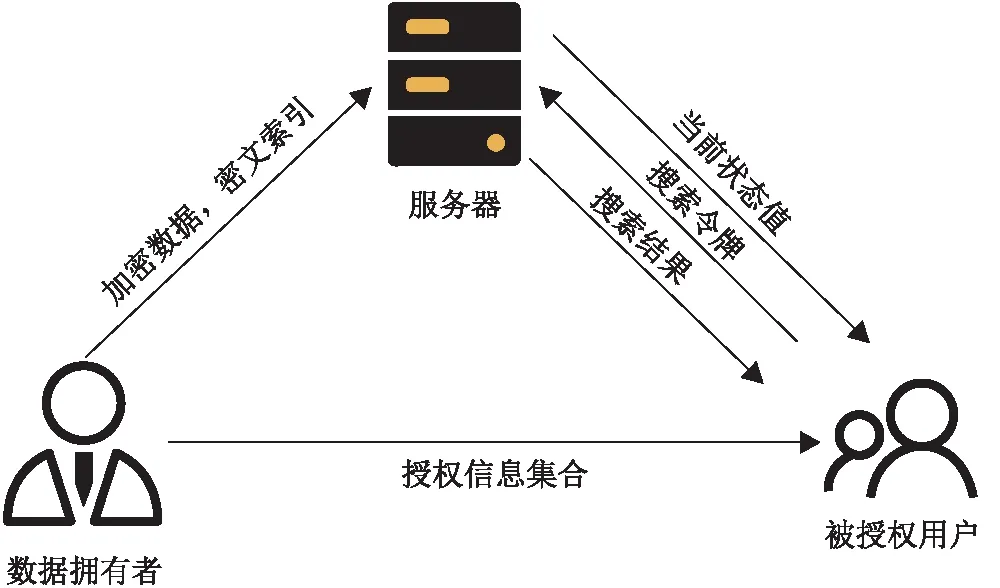
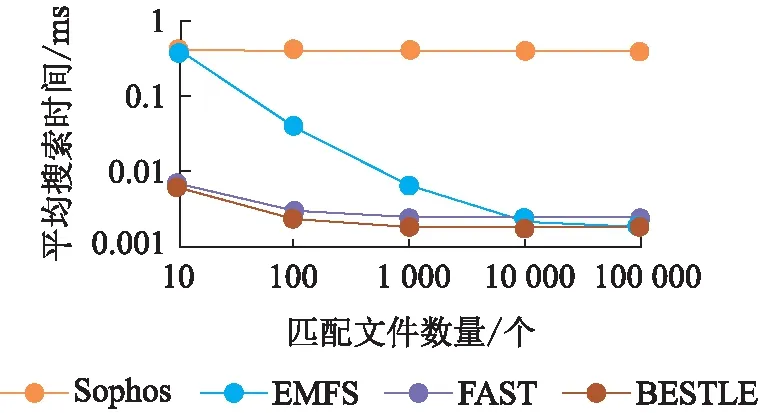
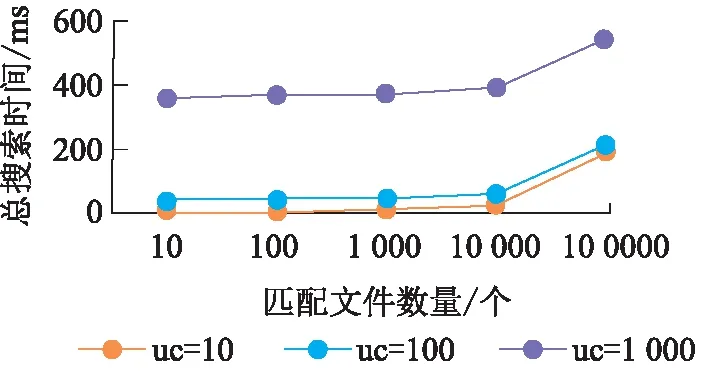
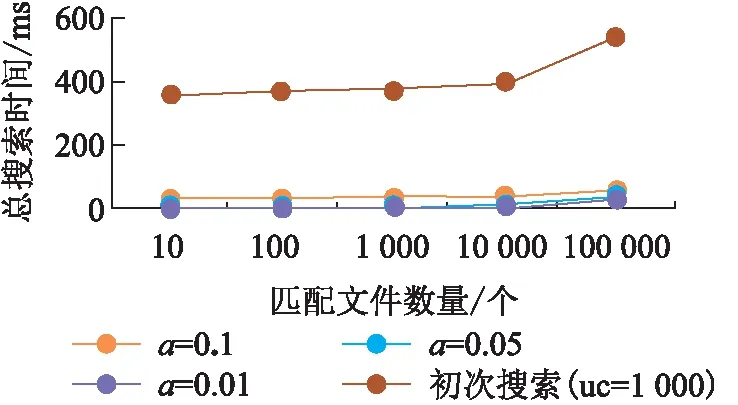
服务器拿到当前最新的搜索令牌STc(w)之后,可以利用公钥计算出所有STi(w),其中i EMFS方案的主链索引结构与Sophos方案相似,但又略有不同。在Sophos方案中,每个搜索令牌下仅包含一个文件,由于搜索令牌在服务端需要通过公钥密码学原语计算得到,开销较大,因此,EMFS方案通过加入侧链结构,使得同一批加入的数据能够共享一个搜索令牌,从而减少主链长度。侧链结构中,链的遍历不包含公钥计算,而是将下一个节点的位置用类似流密码的方式异或保护。收到最新令牌后,可以通过令牌计算出侧链上第一个位置的流密码,通过解密侧链上的第一个位置,可以得到下一个节点的位置。因此,相较于主链的遍历,在侧链中的遍历速度极高。 另外,在Sophos方案中,每个关键字对应的陷门单向函数链长度不同,分别是各个关键字所包含的文件数。 EMFS方案中所有关键字对应的主索引链长度均与更新次数相同,也正是这个设计,使得EMFS方案可以在不需要第三方可信服务器的前提下拓展到多用户的场景。 EMFS方案的系统模型(图2)由数据拥有者、被授权用户、服务器三方以及它们之间的交互协议构成。 图2 EMFS方案的系统模型图Figure 2 The system model of EMFS scheme 在初始化阶段,数据拥有者将外包文件加密并生成密文索引,将加密文件和密文索引上传到外包服务器;针对各个被授权用户允许搜索的关键字,生成不同的授权信息集合,将授权信息集合发送给对应的用户,由用户在本地保存自己的授权信息表。 在更新阶段,数据拥有者对新增的文件加密,并生成一系列更新令牌,然后将更新令牌和加密文件上传到外包服务器;外包服务器根据更新令牌对文件进行插入。更新完成后,数据拥有者和服务器都更新当前系统状态值。 在搜索阶段,被授权用户首先发起搜索请求,服务器将当前状态值发送给用户,被授权用户利用本地保存的授权信息表的信息,根据服务器返回的当前状态值生成最新的搜索令牌。服务器根据搜索令牌搜索索引表得到查询结果,并将结果返回给用户。搜索阶段不需要数据拥有者或代理服务器的参与,被授权用户和服务器两方交互即可完成。 初始化算法的执行步骤如算法1所示。算法的伪代码中,F为伪随机函数,用于生成关键字的初始搜索令牌以及会话密钥;W为存放授权关键字到搜索令牌和会话密钥的映射,由数据拥有者生成后,传给被授权用户存储在本地,同时存放在本地的还有陷门函数的私钥。服务器存放索引表以及陷门函数的公钥。初始化算法还会输出状态值,初始时该状态值为0,该状态值随着更新次数增加而增长。 算法1 初始化算法Setup(λ,keywordSet;⊥) DataOwner: (sk,pk)←KeyGen(1λ) W,T←empty map forwin keywordSet do W[w]←F(ks,w)| |F(kw,w) end for return ((T,pk),(W,sk),c) 搜索算法的执行步骤如算法2所示。当被授权用户需要搜索关键字时,从W表中取出初始搜索令牌ST0(w),然后根据服务端获取到的当前状态值c,利用陷门函数的私钥即可生成最新的搜索令牌STc(w)。服务器利用STc(w)和陷门单向函数的公钥pk,可以恢复其他的搜索令牌STi(w) (i=[0,c-1])。每一个搜索令牌STi(w)代表双链索引结构中主链上的一个节点,利用该搜索令牌可以计算出该位置上的侧链的头节点位置。侧链的遍历不包含公钥计算,而是利用流密码的方式进行保护。以位于主链i位置上的侧链为例,服务器先根据收到的STc(w)计算STi(w)(i 算法2 搜索算法Search(w,W;EDB) Client: 发起查询请求,从服务器获得最新全局状态值c (ST0(w),Kw)←W[w] 将STc(w),Kw发送给服务器 Server: ST(w)←STc(w) ID←empty map ID.add(C2[Kw]) fori=cto 0 do if (ST(w)=C1[Kw]) then C1[Kw]←ST(w),C2[Kw]←ID return ID end if ui←H1(ST(w)| |Kw) if (T[ui]=⊥) then ST(w)←πpk(ST(w)) i←i-1 else r←ST(w) whiler≠⊥ do ui←H(r| |Kw) (id,r)←T[ui]⊕H2(r| |Kw) ID.add(id) ST(w)←πpk(ST(w)) i←i-1 end if end for 把ID发送给客户端 f←dcmod (p-1)(q-1), STc(w)←ST0(w)fmodN。 服务器端则需通过STc(w)进行c次公钥计算,对于主索引链上i[0,c]的位置,检查其侧链上是否包含数据。算法2通过将查询过的结果缓存,从而进一步提高后续搜索效率,搜索结果由C2表和T表中取出的两部分组成,并在搜索结束后,将搜索结果加入C2表,将该关键字对应的最新搜索令牌加入C1表,从而避免在将来的搜索中重复计算。如果对于某关键字的搜索与上次搜索而言,2次搜索期间发生了次更新,服务器搜索过程的公钥计算次数从首次搜索的c次降为次。 算法3 更新算法Update(Doc,σ;EDB) DataOwner: T←empty map parse doc as (id,Wid) forwWiddo ST0(w)←F(ks,w),Kw←F(kw,w) u←H1(STc(w)||Kw) if (T[u]=⊥) then T[u]←H2(STc(w)| |Kw)⊕(ind| |⊥) else tmp←T[u]⊕H2(STc(w)| |Kw) T[u]←H2(STc(w)||Kw)⊕(ind||r) T[H1(r||Kw)]←H2(r||Kw)⊕tmp end if end for end for c←c+1 把T发送给服务器 Server: EDB′←EDB∪T c←c+1 简而言之,EMFS方案的核心思想是将拥有确定性计算结果的陷门函数主链与引入随机性的侧链相结合,从而使得被授权用户与服务器交互获取到当前系统状态值c后,即可计算出确定性的搜索令牌。尽管数据拥有者在计算更新令牌时,通过抽取随机数来生成流密码,引入了随机性,但由于侧链的入口是固定的,故不需要额外增设代理服务器记录更新时引入的随机状态。主链遍历的公钥计算速度是慢于侧链的,因此,EMFS方案通过加入2个缓存表,减少了主链上的遍历长度,通过避免重复计算,进一步提升了后续搜索性能。 定理1设H1和H2是基于随机预言机建模的安全哈希函数,π是陷门单向置换,F是安全的伪随机函数,那么EMFS方案是满足前向安全的-自适应安全动态可搜索加密方案。EMFS方案的-自适应安全定义如下: Setup=⊥, Search(w)=(sp(w),qp(w)), Update(op,docid)=′(op,|Wid|})。 证明通过构造一系列的游戏来进行证明,其中,第一个游戏执行真实世界的协议,最后一个游戏是由仿真器模拟运行的。在这一系列游戏中,相邻的游戏之间只有微小的差异,根据不可区分性的传递性,只要证明任意相邻的2个游戏是不可区分的,则证明了第一个游戏和最后一个游戏是不可区分的。 游戏G2:游戏G2与游戏G1基本相同,除了游戏G2在更新时使用随机字符串表示H1(ST(w)| |Kw)。具体来讲,游戏G2维护一个映射表L,在执行搜索时随机选择一个字符串u保存在L[ST(w)| |Kw]中,用L[ST(w)| |Kw]中的数据为哈希函数H1的随机预言机H1编码。若敌手在搜索前不使用ST(w)||Kw问询随机预言机,则敌手无法区分自己是处于游戏G2或是处于游戏G1中。但敌手如果在搜索前就已经使用ST(w)||Kw问询随机预言机,那么随机预言机会选择随机字符串为H1(STw| |Kw)编码,而这个随机字符串极大概率会与L[ST(w)| |Kw]中的数据不一致,敌手观察到这种不一致的现象时就会知道自己不是与真实世界交互。称这不一致的情形为Bad事件,因此 |Pr[G2=1]-Pr[G1=1]|≤Pr[Bad]。 由于只有敌手在搜索前使用ST(w)| |Kw问询随机预言机,Bad事件才会发生。而如果敌手有提前猜测到ST(w)的能力,则可以利用该能力构建一个陷门单向函数π的敌手,因此 游戏G3: 游戏G3与游戏G2基本相同,除了游戏G3在更新时使用随机字符串来表示H2(ST(w)| |Kw),并保存该随机字符串,搜索时使用该随机字符串为哈希函数H2的随机预言机H2编码。同理,有 游戏G4:游戏G4与游戏G3基本相同,除了游戏G4在更新时使用随机字符串来表示H1(r| |Kw),并保存该随机字符串,搜索时使用该随机字符串为哈希函数H1的随机预言机H1编码。由于r的长度为λ,在游戏G4中发生Bad事件的概率Pr[Bad]≤poly(λ)·(2-λ),因此 |Pr[G4=1]-Pr[G3=1]|≤poly(λ)·(2-λ)。 游戏G5:游戏G5与游戏G4基本相同,除了游戏G5在更新时使用随机字符串来表示H2(r| |Kw)。同理,有 |Pr[G5=1]-Pr[G4=1]|≤poly(λ)·(2-λ)。 游戏G6:游戏G6与游戏G5的主要区别是:在游戏G6中,不是使用已有的搜索令牌,而是随机生成搜索令牌。为了获得搜索结果与更新操作的一致性,使用Updates表记录所有的更新请求。在执行搜索协议时,如果是关键词w的第一次查询,则游戏G6先随机产生ST0(w),再迭代生成STi(w) (i[1,c]),同时根据Updates表的数据更新随机预言机的状态。敌手不能区分这种变化,因为从敌手的视角来看,游戏G6和游戏G5的行为完全相同:更新协议均是输出一个随机字符串,而搜索协议的搜索令牌也具有相同的分布。因此,游戏G6和游戏G5是不可区分的,有 Pr[G6=1]=Pr[G5=1]。 因此,结合上述一系列游戏,有 证毕。 如表1所示,分别以W代表关键字的集合,|W|表示关键字集合中不同关键字的数量,nw代表搜索关键字w的结果集合的元素个数,aw代表被添加到数据库中包含关键字w的元素个数;logM表示搜索令牌的长度,在FAST的方案中搜索令牌由分组密码实现,按AES算法计算,该比特长度一般为128比特;logC和logD分别表示查询次数和更新次数的计数器长度,具体实现时一般为对应程序设计语言的整型变量长度;对于总更新次数,则以uc表示。表1中的客户端存储指的是数据拥有者的本地存储开销。 表1 4种DSSE 方案的性能对比表Table 1 Table of performance among the four DSSE schemes 从计算复杂度、通信复杂度以及客户端存储开销几个方面进行理论评估。3个对比方案均为具有理论最优搜索时间复杂度的方案。其中:Sophos方案[11]包含公钥密码学操作;FAST方案[14]的实现完全基于非对称密码学原语;BESTIE方案[18]进一步减少了FAST方案中不必要的异或操作,为目前实际搜索性能最优的前向安全方案。 由结果(表1)可知:EMFS方案的客户端存储开销是小于其他方案的。究其原因为:由于需要拓展到多用户环境,EMFS方案将原来由客户端存储的搜索关键字状态表用全局状态代替,从而客户端存储开销缩小为常数级别O(1)。搜索前,被授权用户需要先与服务器进行一轮交互,获得当前的全局状态uc。因为不需要关键字存储状态表,这使得客户端存储开销减少了,但也以牺牲一定的搜索性能为代价,即除了至少要对所有添加进数据库的文件检索(即aw次检索)外,还需要进行额外的uc次陷门函数计算。由于EMFS方案支持批量更新,每次更新可以增加不限数量的文件,这使得uc在实际使用中可以保持在一个较小的值,因此这部分额外计算对搜索性能的影响有限。 在测试中,所用环境为6核6线程的CPU AMD3600、32 GB的内存、500 GB的固态硬盘。实验采用C++编写方案代码,使用Cryptopp开源库实现RSA陷门函数、抗碰撞的哈希函数以及伪随机函数,使用Rocksdb数据库存储文件标识符和关键字组成的对,服务器和客户端间采用gRPC框架来实现网络数据传输。 3.3.1 服务端搜索性能 实验通过测量EMFS、Sophos、FAST、BESTIE方案的服务端搜索耗时来对比搜索性能。选取文件数大小为106的数据库,测量服务端搜索10~105个匹配文件的总时间,再将总时间除以对应匹配文件的个数,得到检索出各条目的平均时间(单位:ms)。由于EMFS方案支持批量更新,在构建数据库时将数据分10次更新进数据库。此外,图3中所有方案匹配每个文件的平均时间均与匹配文件数呈反比,这是由于初始化搜索有着一些固定的开销,这些固定开销被分摊到各个匹配条目后,对平均搜索时间的影响可忽略不计,导致平均搜索效率有所提升。 图3 4种DSSE方案的搜索性能对比Figure 3 Comparison of search performance among the four DSSE schemes 平均搜索时间测量结果(图3)表明:(1)在匹配文件数较少时,EMFS方案与基于公钥密码学原语构建索引的Sophos方案相差无几。这是由于EMFS方案有一个与更新次数成正比的陷门函数计算开销,但是当匹配文件数量增大时,该方案的检索效率与目前现有前向安全方案中搜索性能最优的FAST方案和BESTIE方案相似,搜索每个文件的时间均在0.01 ms以下。这是因为当搜索结果较大时,EMFS方案的搜索开销主要在遍历支链上,而支链上的操作和FAST、BESTIE方案一样只涉及非对称密码学原语操作,效率极高。(2)所有方案的平均搜索效率都随着数据集的增大而提升,其中EMFS方案的提升效率尤其明显。EMFS方案是以合理的搜索性能为代价换取支持多用户的拓展,而随着匹配文件集越大,这项代价的开销在EMFS方案总开销的占比越小,因此EMFS方案尤其适合匹配结果较多的大数据集。 实验进一步探究了不同的总更新次数uc对EMFS方案搜索效率的影响。显然,随着匹配条目数的增大,总的搜索时间也会增大。由结果(图4)可知:(1)uc分别为10、100、1 000时,搜索时间随匹配文件数量的增大而增长的幅度都是相似的,搜索时间的差异主要还是源于不同的初始固定开销。(2)uc为一个较大的值(uc=1 000)时,对应了系统在批量更新的场景下,每天批量更新一次,运行约3年,EMFS方案匹配十万个结果的时间仅比系统初始运行化时匹配相同数目的结果所耗的时间增加约0.3 s,不会影响用户的实际搜索体验。 图4 不同更新次数下EMFS方案的搜索性能对比Figure 4 Comparison of search performance of the EMFS scheme at different updates 事实上,上述实验并没有完全反映EMFS方案的搜索性能,反映的仅是“最坏情况”下的搜索结果。回顾EMFS方案的搜索算法,方案通过利用旧的搜索进行了效率优化,只遍历上一次查询到最新更新这段时间没有遍历过的节点,从而得到部分搜索结果,结合旧的搜索结果得到最终结果,避免了在搜索时重复遍历节点,并且不会带来超出搜索模式sp(w)以外的新的泄露。在相邻的几次查询中,仅首次查询会消耗较多时间,后续的搜索查询可以利用上一次的查询结果。因此,上述实验仅代表了初次搜索的效率。同理,在多用户的环境下,任一用户搜索过某关键词后,其他用户再次搜索时效率也会显著提升。 为了显示再次搜索时效率的显著提升,动态模拟了更新请求和搜索请求交替执行的情况:令搜索请求和更新请求的比值为a,即请求序列为搜索请求的概率为a,为更新请求的概率为1-a,实验测量了不同比例下的服务端的搜索时间。实验结果(图5)表明:与初次搜索相比,后续的搜索效率提升幅度较大,并且执行搜索的频率越高,对搜索性能的提升越大。这表明引入缓存机制后,频繁的更新对EMFS方案实际性能的影响进一步降低,EMFS方案具有很强的拓展性和实用性。 图5 模拟请求下EMFS方案的搜索性能对比Figure 5 Comparison of search efficiency of the EMFS scheme by trace simulation 3.3.2 客户端存储开销 实验测量EMFS、Sophos、FAST、BESTIE方案的客户端实际存储开销。实验选取文件数大小为106的数据库,该数据库包含105个关键字。实验数据来源于存放了客户端本地状态的Rocksdb数据库文件。 实验结果(表2)表明:(1)Sophos方案和BESTIE方案的客户端存储开销相似,并且都远小于FAST方案的。究其原因为:Sophos方案里的每个关键字有1个计数器,BESTIE方案里的每个关键字有2个计数器,而在FAST方案中,每个关键字除了有1个计数器以外,还对应存放了一个固定大小的随机字符串。(2)EMFS方案的客户端存储开销是最小的,因为该方案不需要存储每个关键字独立的状态,只需要1个表示更新次数的整型变量,约为4个字节。 表2 4种DSSE方案的客户端存储对比表Table 2 Table of client-side storage among the four DSSE schemes 本文提出了一个不需要代理服务器的高效多用户前向安全可搜索加密方案(EMFS),该方案通过陷门单向函数构建主链索引来实现前向安全,被授权用户仅与服务器交互即可获取当前全局统一的系统状态值,然后计算搜索陷门,从而实现前向安全SSE方案向多用户的拓展。实验结果表明:以合理的搜索性能为代价,EMFS方案实现了支持多用户搜索的拓展;在数据集较大时,EMFS方案的搜索效率趋近于目前搜索效率最优的前向安全方案(BESTIE)的,并且EMFS方案的客户端存储开销小于Sophos、FAST、BESTIE方案的。2.2 EMFS方案设计
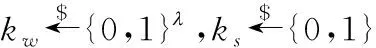


3 方案评估
3.1 安全性分析
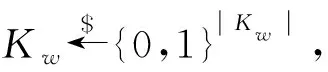

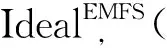
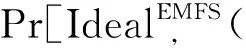

3.2 理论评估

3.3 实验评估

4 结论
