基于改进的对数周期幂律模型研究中国股市崩盘预警*
2022-02-17吴俊传唐振鹏杜晓旭陈凯杰
吴俊传 唐振鹏 杜晓旭 陈凯杰
(福州大学经济与管理学院,福州 350108)
基于金融物理学中著名的对数周期幂律模型(log-periodic power law model,LPPL)来预警2015年6月份中国上证综合指数、创业板指数的崩盘.鉴于已有采用LPPL模型预警市场崩盘的研究均只考虑市场历史交易数据.本文将投资者情绪因素纳入到LPPL模型建模过程,以改进LPPL模型的预警效果.采用文本挖掘技术结合语义分析方法对抓取的财经媒体的股评报道进行词频统计,以构建媒体情绪指数.进一步修改LPPL模型中的崩溃概率函数表达式,将其表示为关于历史交易数据及媒体情绪的函数,构建LPPL-MS组合模型预警股市崩盘.实证结果表明,本文所构建的LPPL-MS组合模型相比LPPL模型具有更高的预警精度,其预测的大盘见顶的临界时点与上证指数、创业板指数真实的见顶时点更为接近,并且其拟合结果通过了相关检验.
1 引言
资本市场中投资者之间的拥挤交易行为极易促成资产价格泡沫的形成,并且其泡沫迅速膨胀过程当中呈现出高度的非线性、自组织等复杂特性.Sornette等[1]物理学家提出对数周期幂律模型(log-periodic power law model,LPPL)来刻画资本市场处于泡沫阶段的运行规律,将地震预测模型成功地运用到资本市场泡沫崩溃的预测.股市崩盘使市场参与者蒙受巨额损失,将风险输出到相应上市公司.此外,股市崩溃往往伴随着系统性风险,股市系统性风险的频繁爆发极大地危害资本市场的平稳运行,弱化资本市场的吸引力及竞争力,降低各类投资主体,尤其是境外投资者的入市积极性,严重削弱资本市场的融资及资源优化配置等功能的进一步发挥,并最终扰乱市场经济秩序,对中国经济发展的危害不言而喻.股票市场作为资本市场最重要的组成部分之一,对一国经济发展的重要性十分明显,提前预警并及时管控其系统性风险,对维护中国经济、金融稳定发展大局具有十分重要的意义.
长期以来,诸如随机漫步 (random walk)[2]、有效市场假说(efficient markets hypothesis,EMH)[3]等理论均认为股票价格序列之间不存在长记忆效应,未来的股价无法提前预测.然而,大量研究表明股票价格序列并非满足随机游走的假设,股票价格剧烈波动的背后存在可预测成分[4].股市疯狂暴涨、形成泡沫,并伴随泡沫破裂的现象时有发生[5].自 Sornette等[1]学者以来,越来越多的研究借鉴统计物理学的方法,利用对数周期修正的临界点来识别股市泡沫.该方法后来被称为JLS(Johansen-Ledoit-Sornette)模型或对数周期幂律奇异性模型(LPPL).该模型认为泡沫可以从市场的自然运作中本质上产生,类似于其他统计物理复杂系统,金融资产也具备自组织临界特性,自组织即指复杂系统[6]某一状态的形成主要由系统内部不同组成部分互相作用所驱使,而并非由其他外界因素主导;临界性是指复杂系统当前处于极其敏感的特殊状态,某一微小的局部变化即可引致整个系统的突变.自组织临界性可以解释诸如日辉耀斑、地震、泥石流、山体滑坡、雪崩、物种灭绝及金融市场中的资产价格崩溃现象[7,8].LPPL模型认为由于市场上交易者同一时间段互相模仿,并通过正反馈机制不断强化,致使资产价格在市场的自然运作过程当中逐渐产生泡沫,并最终崩溃.潘娜等[9]和周炜星[10]认为LPPL模型具备两个显著特征:一是对数周期性振荡,在线性尺度下,越接近临界点,振荡频率越快,而在对数尺度下,振荡频率为常数;二是幂律增长,即价格的增长率并非常数,而是单调递增.
金融资产价格泡沫在趋近崩溃边缘时,呈现出对数周期幂律振荡特性.因此,采用LPPL模型可有效识别金融市场是否处于泡沫状态,并对大盘见顶,泡沫崩溃时点进行提前预警.Sornette和Johansen[11]使用了20世纪两次最大的历史崩溃,即1929年10月和1987年10月的崩溃,并表明该方法通过分析泡沫发生前8年间隔内的股指走势可有效识别这两次崩溃.Sornette和Johansen[12]提出了一个简单的股票市场交易员等级模型,其研究结果表明,不管是模型中处于最高等级的国家层面,还是处于次高级的国家内部的银行等金融机构,其交易行为均表现出明显的羊群效应,这种不同层级的相互模仿足以使股票价格产生对数周期幂律振荡,并最终引发市场的崩溃.Sornette和Zhou[13]提出了一个系统的算法预先检测到道琼斯工业平均指数(DJIA)和香港恒生综合指数(HSI)泡沫的崩溃.Sornette等[14]利用LPPL方法分析了 2006—2008 年石油价格的上涨情况,并证明了石油价格的演变过程也呈现出类似泡沫的状态.Kyriazis等[15]采用LPPL方法成功的预测到比特币、以太坊等加密货币2013年、2017年的泡沫崩溃.Omer[16]详细梳理了LPPL模型用于预警金融市场崩溃的成功案例.Sirca和Omladic[17]成功地运用LPPL模型用于预测全球33个主流股票市场泡沫的崩溃.Filimonov和Sornette[18]提出了一种改进的 LPPL公式,将其从 3 个线性参数和 4 个非线性参数的函数转化为 4 个线性参数和 3 个非线性参数,实证结果表明,这种转换显著降低了拟合过程的复杂性,并提高了其稳定性.国内学者在这方面亦展开了广泛的研究.Jiang等[19]利用LPPL模型检测了2005年5月至2009年7月期间中国股市2个重要指数—上证综合指数和深证成分指数的2个泡沫和随后的市场崩溃,并成功地预测了2个指数的崩溃.Yan等[20]利用 LPPL模型,开发了一种基于先进模式识别方法的预警指数用于探测市场泡沫,并对市场崩溃和反弹进行预测.在 10 个主要的全球股票市场上取得了较好的效果.李东[21]针对LPPL模型提出了基于网格的Nelder-Mead Simplex预搜索方法优化LPPL模型的估计参数,并对恒生指数的泡沫崩溃进行提前预警,取得了较好的效果.周伟和何建敏[22]采用LPPL模型成功识别到后金融危机时代不同类型的金属期货价格的集体泡沫,做出了归因分析,并验证了其结论.李斯嘉等[23]借鉴金融物理学方法,分析上证综指和深证成指的崩盘前后动力学特征,采用LPPL模型分别预测2007年、2015年上证综指、深证成指的崩盘,发现股市崩盘的特征符合G-R规律与Omori定律.李伦一和张翔[24]使用LPPL模型对中国房地产市场交易价格泡沫进行测度.文章基于2010年6月至2017年11月中国100个主要城市的房地产交易数据对各城市房地产价格泡沫进行识别.研究结果表明,LPPL模型能够有效甄别各城市房地产价格正向泡沫、反向泡沫.陈卫华和蔡文靖[25]运用改进的LPPL参数估计方法预测2015年上证和创业板指数的崩盘,并对其进行Lomb谱分析和O-U过程检验,取得了稳健的效果.赵磊和刘庆[26]采用LPPL模型拟合比特币价格,结果发现,比特币价格呈现出LPPL模型中所隐含的超指数膨胀、对数周期幂律振荡特性,并预测比特币价格可能在2020年下半年出现泡沫.
纵观已有文献,LPPL模型在预警金融资产泡沫方面已经取得了丰硕的研究成果,然而,该模型并未将金融资产交易价格以外的因素,诸如金融资产价格基本面、政策层面及市场情绪等因素纳入建模过程.为此,本文尝试将市场情绪层面的因素纳入LPPL模型建模过程,对改进LPPL模型的泡沫预警效果.
随着20世纪八九十年代金融市场上一系列金融异象,如股票溢价之谜、股价过度波动之谜、股价长期反转效应等,被逐渐揭示.行为金融理论(behavioral finance)借助行为科学、心理学的研究成果,能有效解释这类金融异象.行为金融理论认为市场上交易者并非完全理性,其交易决策会受到各类心里因素,如投资者情绪等非市场因素影响[27].国内外大量实证研究表明,投资者情绪在股票价格的决定中起着重要的作用.Baker和Wurgler[28,29]将投资者情绪定义为对未来现金流和投资风险的信念,而这些信念并不是由基本面决定的.他们的研究结果表明,投资者情绪会影响股票市场的回报,即积极情绪对股价具有正面影响,消极情绪对股价具有负面影响,并且随着投资者意识到情绪与基本面的偏离时,这种影响在接下来的交易日会发生逆转.García[30]的研究表明,投资者情绪对道琼斯工业平均指数的短期走势的影响符合上述发现.新闻媒体作为投资者获取重要信息的窗口,其对股票市场信息的报道对投资者指定交易决策具有重要影响.媒体报道通过对股票市场的表现状况做出评判及预测,会直接诱导投资者未来预期,影响投资者情绪,进而影响市场未来走势[31,32].Solomon[33]的研究发现,比起负面报道,媒体更热衷于正面报道,即新闻媒体的报道内容往往掺杂着媒体商主观意见,并非完全基于市场上已有的客观事实.Nardo等[34]通过综合采用文本挖掘、情感分析及机器学习技术基于大量互联网新闻报道预测未来股票市场走势,发现互联网新闻报道有助于预测市场未来走势,然而其实际回报很少超过5%.Fisher和Statman[35]的研究显示个人投资者的情绪受新闻媒体撰稿人的情绪影响较为显著,二者相关性较强,并且投资者的情绪与未来股市收益率负相关.国内学者方面,武佳薇等[36]基于前景理论框架,考虑投资者非理行预期因素,构建投资组合决策模型,其采用某券商2007年至2009年近177万个人股票账户交易数据进行实证分析,实证结果表明,投资者情绪与处置效用具有负相关关系.李合龙和冯春娥[37]采用EEMD分解技术提取投资者情绪及股指价格在不同时间尺度下的波动特征,研究结果发现,投资者情绪与股指价格序列在不同时间尺度下呈现出不同的波动关系.由于中国股票市场中,散户投资者占据了绝大部分比例,其活跃程度远超机构投资者,截止2020年8月底,中国股市中,自然人投资者数目达到1.72亿,而非自然人投资者数目仅为40.28万(数据来源于中国证券登记结算有限责任公司).相比机构等专业投资者,广大散户,尤其是刚入市的新股民,其专业知识及实操经验较为缺乏,其对市场运行状况的评价较依赖于各类新闻媒体的股评观点.随着近些年,互联网技术的迅猛发展,互联网步入 Web 3.0 时代,诸如微博、论坛等各种新兴媒体的崛起,投资者可轻而易举地从互联网上获取各类海量并充斥着强烈情感色彩的股评文本信息.游家兴和吴静[38]通过选取2004年至2010年间国内8家财经报纸新闻,运用文本分析方法综合报道基调、曝光程度及关注水平三个维度信息构建媒体情绪指数,发现新闻媒体情绪能够显著引致股价波动.Wu等[39]从新浪财经网站抓取股评短文,采用SVM训练媒体情绪,实证结果表明,媒体股评情绪与股价未来走势具有显著相关关系,并且其在成长股中表现尤为明显.戴德宝等[40]通过抓取东方财富网络论坛文本结合情感词典分析方法生成投资者情绪序列数据,并采用SVM学习机将生成的情绪指数纳入训练过程,其实证结果表明,相比基准模型,考虑情绪指数的SVM学习器具有更高的预测精度.由于每日均有海量的新闻报道产生,投资者受限个人有限的注意力,无法逐一对每日新闻报道内容进行细致阅读[41],作为新闻报道内容的凝练与总结,新闻标题可迅速吸引读者的注意力,甚至有媒体为了博取投资者的关注,故意为媒体报道冠上夸张的标题[42].Huang等[43]研究发现企业管理层可以充分利用投资者的有限注意力,在新闻标题中嵌入更多积极信息,以煽动投资者的乐观情绪.由上可得,采用文本挖掘技术剖析新闻媒体评论稿标题可提取媒体情绪,进而为下文分析媒体情绪对股市未来走势的影响作铺垫.
综上,关于LPPL模型用于预警股市崩盘方面已经取得了丰硕成果,然而已有研究未将交易历史数据以外的因素纳入建模过程.此外,现有研究均表明投资者情绪可在一定程度上解释未来股价走势的变动.本文尝试将投资者情绪纳入LPPL建模过程.以改进LPPL模型股市崩溃预警效果.本文将从以下几个方面开展研究工作:首先,采用文本挖掘技术结合情感词典构建媒体情绪指数;其次,对现有LPPL模型进行改进,将媒体情绪指数纳入建模过程;最后,通过实证数据检验改进模型与 基准模型的预测效果.
2 模型介绍
2.1 媒体情绪指数的构建
2.1.1 中文金融情感词典介绍
本文主要基于Sentiment等[44]构建的中文金融词典对获取的媒体评论文本进行情感标注:首先,采用知网HOWNET、大连理工大学DLUTSD及台湾大学NTUSD作为基础词典;然后,使用在线路演纪要,业绩说明电话会议纪要,IPO招股说明书及公司年报构建基础语料库;最后,基于算法和人工删选,使用多阶段剔除法来构建中文金融情感词典CFSD.具体步骤如下.
步骤1 通过合并HOWNET,DLUTSD和NTUSD中的肯定和否定术语并删除重复项,创建基础情感词典.
步骤2 收集1411个在线路演纪要,7138个电话会议纪要,2043个IPO招股说明书和29737份年度财务报告.运用 jieba分词包(Python分词工具)用于分割这些文档以创建基本语料库.
步骤3 根据步骤1中创建的基础情感词典,计算基本语料库中每个积极词和消极词的词频.排除频率为零的词.在创建基本的中国金融情感词典(CFSD0.0)之前,将与财务文档无关的术语手动排除.
步骤4 CFSD 0.0中的所有术语均来自HOWNET,DLUTSD和NTUSD.由于这3个词典在财务中不包括一些常用的否定词和肯定词,因此手动添加了100个常用的财务否定词和100个肯定词以生成字典CFSD 0.1.
步骤5 Gensim(Python软件包)用于将基本语料库转换为单词向量模型.单词向量模型用于找出CFSD 0.1中每个术语的前50个同义词.在手动删除与财务、金融无关的所有同义词之后,创建CFSD 0.2.
步骤6 将CFSD 0.0,CFSD 0.1和CFSD 0.2合并以删除重复项以获得CFSD.CFSD中有1488个否定词和1107个肯定词.
2.1.2 媒体情绪指数构建
利用前述构建的CFSD词典对媒体评论进行情感标注,在情感标注过程中,对词汇所表达的情感强度不作进一步区分,仅通过统计词汇出现的次数的高低来描述情感得分.每一自然日出现积极、消极情绪得分的表达式如(1)式所示:

式中,kPos,Neg分别表示积极、负面情绪,Sentit,k为第t个自然日的媒体股评文章标题中情绪类型k的得分,mk为隶属于情绪类型k的词汇出现的次数,nt,j为第t个自然日股评文章标题中第j个词汇出现的次数.
由于每一天的股评标题里可能同时包含积极词汇、消极词汇,为了综合评价某一天的情绪值,本文参考王晓丹等[45]的处理方法,得到综合的媒体情绪指数,其表达式为

式中,post表示第t天的积极情感得分,negt表示第t天的消极情感得分.当积极情感得分大于消极情感得分时,判定相互抵消后的综合情绪值大于0,表明情绪偏乐观;反之,当积极情感得分小于消极情感得分时,综合情绪值小于0,表明情绪偏悲观.
2.2 LPPL-MS组合模型的构建
2.2.1 LPPL模型介绍
Sornette等[1]认为金融市场具有典型的复杂系统的特性.发生在复杂系统中的极端事件往往是由于系统内部相互作用、自组织等自然演化的结果,并非由外部冲击驱使.Johansen 和Sornette[2]认为金融市场上由于投资者之间的羊群效应及正反馈机制造成的资产价格泡沫的膨胀与破裂可由LPPL模型进行刻画.LPPL模型具有如下特性:
1)投资者之间相互模仿,呈现集体追涨的交易局面,造成对数资产价格呈超指数暴涨;
2)随着资产价格泡沫破裂的风险逐渐扩大,市场需要更高的回报作为补偿;
3)资产价格泡沫在临界点tc具有最大的崩盘概率;
4)越接近临界点tc,资产价格对数周期性振荡频率越高.
在LPPL模型中,股票价格在泡沫阶段的演化过程如(3)式所示:

式中p是股票价格;µ(t) 为趋势项;W为满足均值为0,方差为1的维纳过程;dj为非连续的跳跃,泡沫崩溃以前,dj0,崩溃之后 dj1 .与发生崩溃对应的价格损失幅度由参数κ确定.假定h(t) 为崩溃发生的概率,则有:Et[dj]1×h(t)dt+0×(1−h(t))dth(t)dt.
在LPPL模型中,假设股价崩盘的概率h(t)如(4)式所示[2]:
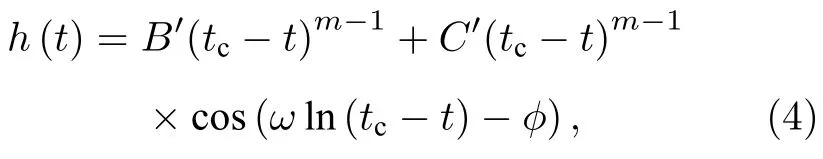
式中B′,C′均大于0;tc为金融资产价格见顶的时刻,也称为崩溃临界点;m为幂增长指数,代表股价增长的加速度,m越小,股价增长的加速度越快,其临近泡沫的可能性也越大.ω为振荡的角频率,φ为振荡的初始相位.
由Et[dj]h(t)dt,Et[dW]0 及满足市场不存在无风险套利条件,即Et[dp]0,对(3)式两端取期望,可得µ(t)κh(t),进一步,假定股价崩盘已经产生,(3)式简化为
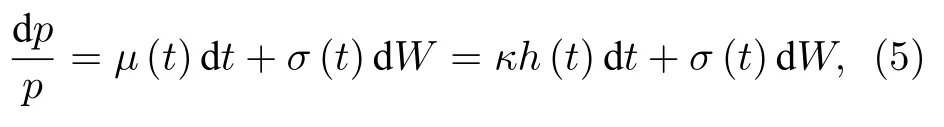
进一步,对(5)式两端取期望,得
传统上,中国人的确并没有意识到“老糊涂”是一种病。近年来,“老年痴呆症”这个病名被人们越来越熟悉,它比阿尔茨海默病听起来更“通俗”。事实上,无论是在中国内地还是香港地区,调查数据显示,阿尔茨海默病的患病率并不比其他地区低——内地的发病率与世界平均水平持平,为6%左右;而香港的发病率则接近10%。

(6)式取积分结合(4)式即得LPPL方程[2]:

式中A>0,为股票在临界点的价格,也即股票见顶时的价格;并且,B(tc−t)m反映了股价由正反馈机制驱使而出现的幂律增长特性,C(tc−t)mcos(ωln(tc−t)−φ)刻画了股价在临近见顶并崩盘时呈对数周期性振荡,是对股价幂律增长行为的修正.图1以中国上证指数2015年泡沫期间走势为例,展示了LPPL模型中呈现的对数周期幂律振荡现象.
如图1所示,在线性尺度下,越接近崩盘的临界点,其振荡的频率越快,其表现为图中指数振荡的间隔周期越来越短,如图1中振荡的周期依次为116(由余弦函数的波峰或波谷数值相减可得,如第一个周期为200减去84为116个交易日,以此类推),67,38,22,13个交易日.而在对数尺度下,其振荡频率为常数,如图1中所示,分别对线性尺度下的振荡周期取对数,则其周期为ln(116)–ln(67)=ln(67)–ln(38)=ln(38)–ln(22)=ln(22)–ln(13)=0.54.并且股价越是接近临界点,股价增长速度越快,即股价增长率呈现单调递增的特点.
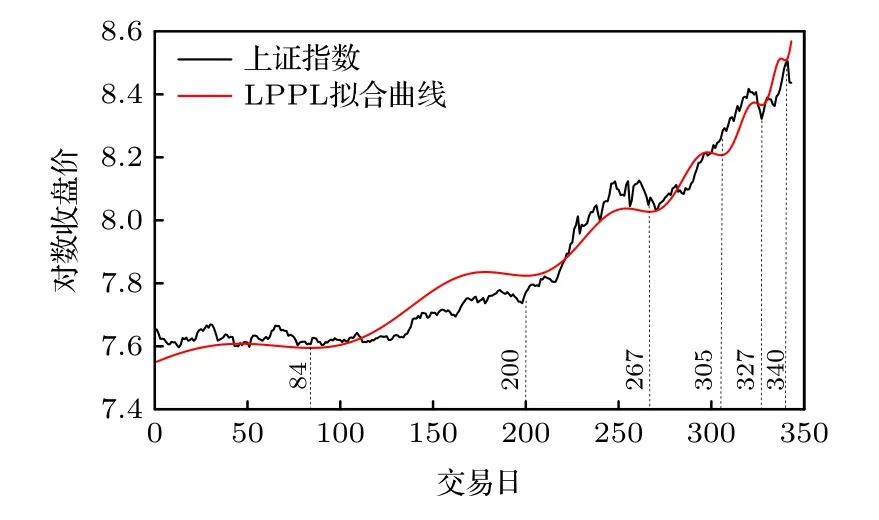
图1 上证指数2015年泡沫期间LPPL拟合图Fig.1.LPPL fitting diagram of the Shanghai stock exchange (SSE) index during the 2015 bubble.
2.2.2 LPPL-MS模型的构建
基础的LPPL模型未将投资者情绪因素纳入到建模过程当中,本文创新性地对LPPL模型中的崩溃概率公式h(t) 进行修改,以刻画媒体情绪因素对崩溃风险的影响.如前文所述,已有研究均已表明,投资者情绪对股价具有显著的影响,因此,本文假定在股市泡沫阶段,媒体积极评论将进一步助推市场情绪的高涨,加速羊群效应,放大市场正反馈机制,驱使股价加速膨胀,导致其崩盘概率增大.反之,媒体负面评论则可能平抑过热的市场情绪,延缓羊群效应,抑制市场正反馈机制,延缓崩盘时刻的到来.考虑媒体情绪(mediasentiment,MS)影响后的股价崩溃函数h(t) 如(8)式表示:
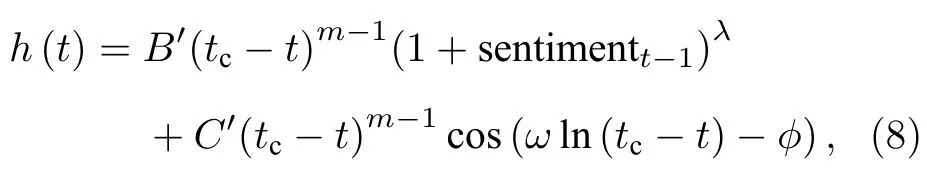
式中 sentimentt−1为t−1时刻媒体情绪值;λ>0,则表明积极情绪会放大正反馈效应,消极情绪会抑制正反馈效应,否则不成立.同上,与2.2.1节中情形类似,可得到考虑媒体情绪后的LPPL方程的表达式:

3 实证分析
3.1 数据来源
Johansen等[46]提到,LPPL模型刻画的股市崩盘具有典型的3个特征:1)股价达到明显的峰值;2)股价至少在6个月内维持上涨的态势;3)股价达到峰值后在短期内便迅速下降.由于自2014年1月1日起,新闻来源众多,而2013年及之前的网站来源少、新闻数据量少,结合LPPL模型所满足的3个特征,本文选择上证指数2014年1月2日至2015年5月29日、创业板指数2014年1月2日至2015年5月20日收盘价数据及对应新闻媒体评论数据作为样本进行拟合.所有样本数据均来源于东方财富旗下Choice金融终端,通过在Choice金融终端抓取关键词“A股”、“大盘”相关的各类媒体评论,汇总每一自然日新闻财经媒体对当下股票市场整体运行状况的评价及未来走势预判.其数据覆盖面较为全面,其数据均来源于诸如,沪深交易所、中国基金报、券商中国、澎湃新闻、21世纪经济报道、中证网、中金网等国内主流媒体.部分媒体评论稿标题信息如图2所示.
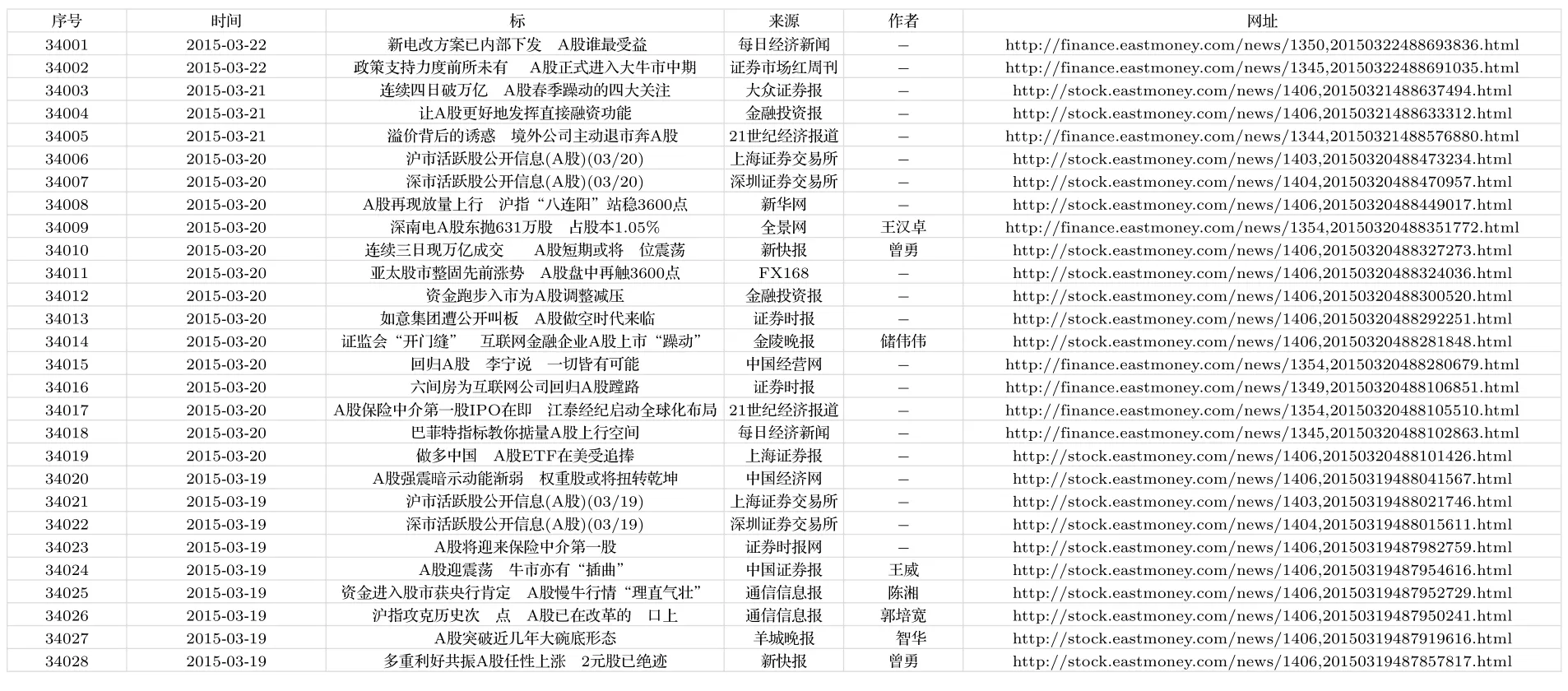
图2 部分财经媒体评论稿标题信息样本Fig.2.Some financial media commentary title information samples.
采用2.1节中构建的情感词典扫描每一条评论的标题,统计每条评论对应的积极词汇、消极词汇出现的次数,再结合(2)式,便得到每一天的情绪值.本文所参照的CFSD金融情感词典部分内容如表1所示.
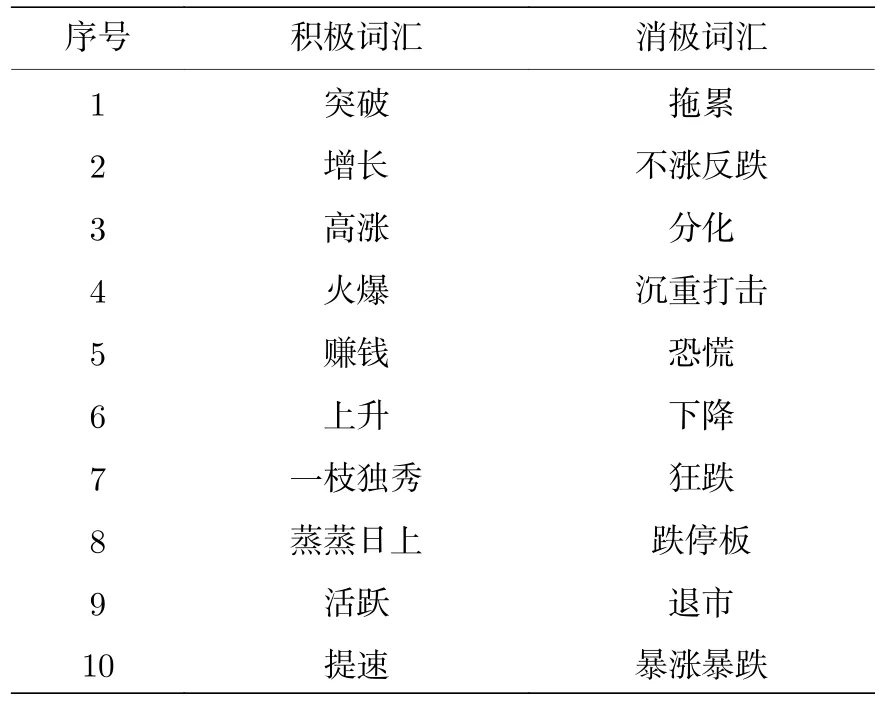
表1 CFSD词典部分积极、消极词汇Table 1.Some positive and negative words in CFSD dictionary.
媒体情绪指数描述性统计分析如表2所示.从表2中可看出,本文所选取的媒体情绪样本中积极情绪指数明显高于消极情绪指数,表明各类财经媒体的评论具有明显的倾向性,其倾向于对市场做出积极正面的评论.受央行多次降准降息,市场无风险利率不断下探,叠加国家实施积极财政政策及国企改革等一系列“利好”因素的推动下,2015年上半年A股市场节节攀升,上证指数在2015年6月12日最高上涨到5178.19点,创业板指数在2015年6月5日最高上涨到4037.96点,随后随着市场泡沫的破裂,仅两个月时间,上证指数从高位滑落至2850.71点,创业板则滑落至1779.18点.上证指数、创业板指数泡沫前后的走势如图3所示.

图3 上证指数、创业板指数泡沫前后走势Fig.3.Trend of SSE index and growth enterprise market(GEM) index before and after bubble.

表2(MS)序列描述性统计分析Table 2.Descriptive statistical analysis of media sentiment(MS) sequence.
3.2 LPPL-MS拟合结果及分析
为了得到模型的参数估计结果,本文采用遗传算法(genetic algorithm,GA)来获取LPPL、LPPLMS参数估计值.其中,上证指数的拟合样本区间为2014年1月2日至2015年5月29日;创业板指数的拟合样本区间为2014年1月2日至2015年5月20日.GA算法的适应度函数为拟合值与实际值的均方误差,其种群规模设为20,交叉概率设为0.5,变异率设为0.05,迭代次数设为100次,为了使预测结果更加稳健,选取适应度最佳的3组拟合结果进行分析.LPPL及LPPL-MS模型的GA算法估计结果如表3、表4所示.
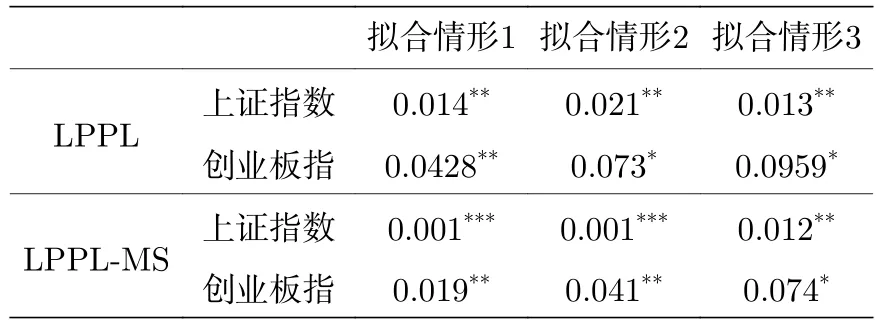
表3、表4中MSE指标为LPPL,LPPL-MS模型拟合值与实际值的均方误差,其余各参数的意义同2.2节中的介绍.所有模型拟合得到的幂增长指数m介于0到1之间,表明市场崩溃的概率h(t)具有不断加速的特征,满足产生崩盘的条件.此外,LPPL-MS模型中,λ均大于0,表明媒体情绪对正反馈效应具有显著影响,即积极情绪会放大正反馈效应,消极情绪会抑制正反馈效应.若N≤tc 表3 上证指数LPPL,LPPL-MS参数估计结果Table 3.Parameter estimation results of SSE index LPPL and LPPL-MS. 表4 创业板指数LPPL、LPPL-MS参数估计结果Table 4.Estimation results of LPPL and LPPL-MS parameters of gem index. 从表5中可看出,LPPL-MS无论是在上证指数还是创业板指数情形下,其预测的见顶时点均更接近真实值,其预测的崩溃临界时点与真实见顶时点的最低绝对误差、最高绝对误差、平均绝对误差均小于LPPL模型.图4直观展示了不同模型的预测表现. 表5 上证指数、创业板指数预警误差比较分析Table 5.Comparative analysis of early warning errors between SSE index and GEM index. 图4中,不同颜色的线条分别对应不同的拟合情形,所有图中上证指数、创业板指数实际的见顶时点所在的时刻均用“^”符号标出.“*,+,<”分别对应情形1,2,3下预测得到的见顶时点.其中,上证指数对应的大盘见顶时点为353,对应的交易日期为2015年6月12日,创业板指数对应的大盘见顶时点为346,对应的交易日期为2015年6月3日.上证指数LPPL三种拟合情形预测的大盘见顶时点分别370,380,362,即分别比实际的见顶时点晚17,27,9个交易日.上证指数LPPL-MS模型三种拟合情形预测的大盘见顶时点分别为363,366,361,即分别比实际的见顶时点晚10,13,8个交易日.从图中也可看出,上证指数LPPL-MS模型预测的大盘见顶时点相比较LPPL模型更为接近真实值.同理,创业板指数LPPL三种拟合情形预测的大盘见顶时点分别为336,342,341,其分别比实际的见顶时点提前10,4,5个交易日.创业板指数LPPL-MS三种拟合情形预测的大盘见顶时点分别为345,353,354,其分别比实际见顶时点提前1个交易日、迟延7个交易日、延迟8个交易日,其相比LPPL模型预测的见顶时点更为接近真实值.图4的直观展示结果亦表明LPPL-MS组合模型预警效果优于LPPL模型. 图4 上证指数、创业板指数不同模型预测表现比较分析Fig.4.Comparative analysis of forecasting performance of different models of Shanghai Stock Exchange Index and Growth Enterprise Market Index. 为了进一步验证LPPL,LPPL-MS拟合结果的稳健性,对其拟合残差进行Ornstein-Uhlenbeck(O-U)过程检验.Lin等[48]指出,如果股票市场在泡沫期间的对数收盘价可以用LPPL模型进行有效解释,则其拟合的残差应该满足 O-U过程.其拟合的残差若满足平稳性,则表明其符合O-U过程.表6列出了上述模型不同拟合情形下残差的单位根检验结果. 表6 上证指数、创业板指数不同拟合情形下残差平稳性检验Table 6.Residual stationarity test of SSE index and GEM index under different fitting conditions. 表6中的数值为LPPL,LPPL-MS不同拟合情形下残差Dickey-Fuller检验的P值.从表6可看出,上述LPPL,LPPL-MS模型不同拟合情形下残差均通过了平稳性检验,表明其拟合残差满足O-U过程,且LPPL-MS模型相比LPPL模型具有更小的P值,其拟合结果更为稳健.本文所采用的LPPL、LPPL-MS模型可有效解释2015年上证指数、创业板指数泡沫期间的运行情况. 本文采用文本挖掘技术生成财经媒体情绪指数MS,通过将MS指数纳入传统的LPPL模型,构建LPPL-MS组合模型对中国上证指数、创业板指数2015年6月份的崩盘进行预警.实证分析得出以下结论. 1)通过文本挖掘技术结合大数据分析,抓取财经媒体对A股的评论信息,通过分析其评论措辞的情感倾向可有效衡量媒体情绪.并且,财经媒体倾向于对市场做出乐观的评价,以煽动其他投资者的情绪.由于中国股市中个人投资者基数庞大,尤其是其中的新进投资者,其缺乏交易经验,往往容易受财经媒体具有煽动性报道内容的影响.以致于媒体情绪一定程度上能影响股票市场的表现. 2)中国A股市场在2015年上半年开启单边暴涨模式,并出现严重的泡沫,其泡沫阶段的运行情况符合LPPL模型中描述的超指数膨胀及对数周期幂律加速振荡特征.采用LPPL模型可有效预警2015年6月份上证指数、创业板指数的崩溃. 3)在股票市场泡沫期间,媒体频繁的带有煽动性正向情感倾向的股评报道可引起市场的极度亢奋情绪,使市场的崩盘概率进一步加速.通过在传统的LPPL模型中纳入媒体情绪指标MS,构建LPPL-MS组合模型预警上证指数、创业板指数2015年6月份的崩盘,具有更高的预测精度,其预测大盘见顶的临界点相比LPPL模型更接近真实值.并且其拟合残差单位根检验的P值小于LPPL模型,其模型拟合结果更为稳健. 本文的研究结果有助于政府相关监管当局提前预警股市系统性风险,为其提前制定风险管控政策做铺垫.同时,投资者也借助该模型提前优化交易策略,及时规避系统性风险,减少投资损失.本文将投资者情绪因素纳入到LPPL模型,以改进LPPL模型预警效果,然而,股票市场本身作为一个复杂系统,其市场运行规律受内外部多维复杂因素影响,其不仅仅受市场情绪影响,还受到诸如市场基本面因素、市场技术面特征、外围市场冲击等因素影响,未来的研究可将上述因素纳入到模型当中,以进一步优化模型预警效果.



3.3 LPPL,LPPL-MS拟合结果O-U过程检验
4 结论
