从算法偏见到算法歧视:算法歧视的责任问题探究
2022-02-17孟令宇
孟 令 宇
(复旦大学 哲学学院, 上海 200433)
提到算法的伦理问题,算法的公正问题是一个绕不开的话题,这一问题通常被称为“算法歧视”问题或“算法偏见”问题。目前对算法偏见和算法歧视问题的解决主要有两种进路:第一种进路是设计进路,该进路致力于从算法的设计出发来解决算法偏见与算法歧视的问题。 从设计进路出发,算法的设计应当具有伦理向度,开发者在开发算法时应当有伦理考量。 人们要意识到算法可能造成的不公正后果,并在设计中避免这些可能的不公正的后果成为现实。 第二种进路是法律与政策进路,该进路试图通过建立健全相关的法律法规和社会政策来避免或缓解算法偏见与算法歧视的问题。 例如,“通过建构人工智能学习权和借鉴美国平等权保护领域中的差别性影响标准以识别算法歧视,同时采用法律与代码相结合的双重保护模式,把握平等权保护与科技创新之间的平衡”[1]。 又如,“结合全国人民代表大会立法规划,我国对算法歧视应采取个人信息保护法和合理算法标准相结合的综合治理路径”[2]。然而,无论学者们是从何种进路来解决算法偏见与算法歧视的问题,算法偏见与算法歧视这两个概念通常是被放在一起讨论的,鲜见对二者的区分。似乎从算法偏见转化为算法歧视是一个理所当然的过程。正如杨庆峰所说的那样,如今在有关大数据和人工智能偏见问题的讨论中逐渐形成了一种独特观念,即偏见等同于歧视[3]。 在很多场合,算法偏见与算法歧视都被视为一个问题,在表述中处于一个“你中有我,我中有你”的混淆状态。然而,偏见是否等同于歧视?算法偏见是否必然导致算法歧视?这是值得追问的。 事实上,在人工智能伦理领域需要解决的问题是算法歧视问题而非算法偏见问题。 算法偏见是不可避免的, 某种程度上来说它是算法技术得以应用的前提。算法歧视才是人工智能技术领域中的那个会造成不良后果的、值得被反思和追问的伦理问题。 本文试图从这个角度切入, 通过区分算法偏见与算法歧视这两个概念, 找出算法偏见导致算法歧视的内在逻辑, 从而提出算法偏见是不可避免的, 真正地应当引起人们重视的伦理问题是算法歧视问题, 而算法的开发者和使用者要为算法歧视负责。
一、 偏见与歧视
算法偏见与算法歧视之间的区别本质上是偏见与歧视之间的区别,算法只是为这一问题提供了新的语境。“偏见”通常是指一个哲学认识论层面的概念或一个心理学概念。偏见的具体概念很难定义,“偏见是人类生活的一个特征,它与许多不同的名字和标签交织在一起,或者可以互换使用——刻板印象、偏见、隐含的或潜意识持有的信念,或者思想封闭”[4]。算法偏见与算法歧视在人工智能技术领域被视为同一个伦理问题的一个可能的原因是自启蒙运动以来的对“偏见”概念的误解。在启蒙时期,“偏见”曾被视为是全然消极的,但随着人们对“偏见”概念的深入分析,“偏见”的合理性得到了辩护。
最初对于“偏见”的误解,是由于对“理性”的过度推崇导致的。“偏见一词,对于启蒙时代以来的理性主义传统来说,意味着与正义和理性对峙的力量。由于文艺复兴以来的对传统和权威的鞭笞,对理性的崇尚,偏见也就理所当然地成为正确认识的大敌。”[5]例如,培根提出的“四假象说”就是一种对人类认识的偏见的批判。他认为偏见是人类进行认识活动中的障碍, 要想获得真正的知识就必须要消除偏见。笛卡尔也说:“第一就得把我们的偏见先撇开,那就是,我们必须先细心怀疑我们以前所承认的意见,直到重新考察之后,我们发现它们是真的,然后才同意它们。”[6]
然而,进入20世纪以来,随着解释学作为一种哲学学派诞生并发展,有关“偏见”的看法随之逐渐发生了变化。
在海德格尔那里“偏见”成为“理解的前结构”,或者说,至少成为了其中的一部分。他称:“把某某东西作为某某东西加以解释,这在本质上是通过先行具有、先行见到与先行掌握来起作用的。解释从来不是对先行给定的东西所做的无前提的把握。”[7]这里的先行具有、先行见到与先行掌握就是所谓的“理解的前结构”,这其中就包含了“偏见”。先行具有是指人的存在首先是置于一个特定的历史文化之中,在理解和解释活动展开之前,存在着的人本身就已经具备这些历史和文化了;先行见到是指人在思考时所必然会涉及的语言体系,这包括了具体的语言、概念和使用语言的方式,脱离了这一语言体系,人实际上是无法思考的;先行掌握则是指人在展开理解和解释活动之前就已经具有的一些内在的观念、前提和假设,人的理解和解释活动的展开必然将这些观念、前提和假设作为参考。可以看出,无论是先行具有、先行见到抑或是先行掌握,偏见都不可避免地居于其中。
在海德格尔之后,波普尔和伽达默尔的观点也为“偏见”的合理性提供了辩护。
波普尔从自然科学知识的角度出发,提出了“培根问题”,并借此表达了他的偏见观。所谓“培根问题”就是波普尔提出的在培根哲学中所存在的一种矛盾,它关涉“偏见”与 “观察证实理论”的关系问题,即“一方面培根承认一切观察都是按照某种理论对事实的解释,或者说他把从已有理论或偏见出发对观察到的事实的解释视为一种普遍现象,另一方面他同时又意识到这一点与其通过经验获得知识之基本主张相抵牾”[8]。波普尔认为培根这种摒弃“偏见”的观点是错误的,并不是“偏见”污染了“自然观察”,而是根本就不存在所谓的“自然观察”状态。他认为无论是对整个人类还是对个人来说,对自然的解释是且只能是从“偏见”出发的,“自然观察”是不存在的,所有的观察都是建立在“偏见”的基础之上的。“偏见”概念本身是中性的,在人的认识中“偏见”不可能也不应该被排除掉。
伽达默尔更是直接提出“偏见”是不可消除的,启蒙运动所一直致力于的驱赶“偏见”的行为不过是“以偏见反对偏见”而已(1)伽达默尔使用了德语Vorurteile一词,英文翻译为prejudice,汉语多译为“前见”。出于概念统一的考虑,除了译本原文外,本文中将统一使用“偏见”一词。。他提出“偏见”是由理解的历史性所构成的,而理解的历史性是必然的,他认为:“一种诠释学处境是由我们自己带来的各种前见所规定的”[9]416。在这一点上他继承了海德格尔有关理解的前结构的观点,认为人的理解活动是被人所固有的偏见所限制的,人的解释和理解活动的展开是不可能不受“偏见”的影响的。此外,由于“偏见”是理解的历史性所导致的,这也就意味着“偏见”是开放的,向过去开放,也向未来开放。过去的偏见形成了现在的偏见,现在的偏见也将成为未来偏见的一部分。也就是说,与我们对“偏见”的刻板印象恰恰相反,“偏见”并非是顽固的、一成不变的,就“偏见”概念自身而言,反而是包容的和开放的。“偏见”随着人的认识活动而改变,或消解,或强化,从而在某一天演化成为和原有的“偏见”截然不同的新的“偏见”。伽达默尔还区分了“生产性的偏见”和“阻碍理解或导致误解的偏见”,前者是构成我们认识和理解的前提,是从历史中来的,而后者对我们的认识和理解活动起阻碍作用,是后天得来的。与此同时,尽管从概念上这两者是可区分的,但在事实层面上却又是不可区分的,伽达默尔认为:“占据解释者意识的前见和前见解,并不是解释者自身可以自由支配的。解释者不可能事先就把那些使理解得以可能的生产性的前见与那些阻碍理解并导致误解的前见区别开来”[9]402。
至此,“偏见”这一概念作为人类认识和解释世界的前提获得了合理性。
与“偏见”不同,通常意义下,“歧视”在当今社会被视为一个法律概念。根据《联合国人权事务委员会关于非歧视的第十八号一般性意见》(CCPRGeneralCommentNo.18:Non-discrimination)第7条中的规定,“歧视”一词指的是基于任何种族、肤色、性别、语言、宗教、政治或其他见解、国籍、族裔或社会出身、财富、残疾、出生或其他地位等特征的任何区别、排斥、限制或偏好行为,其行为的目的或效果否认或妨碍了任何人认识、享有或行使平等的权利和自由。朱振在《论人权公约中的禁止歧视》一文中也指出:“任何形式的歧视都是基于区分,而区分的基础则是个人的特征,诸如种族、肤色、性别、语言、宗教、政治或其他意见、国籍或社会出身、财产、出身或其他身份。个人的这些不同的特征构成了歧视的前提,但并不是所有形式的区分都是歧视性的,人权法所反对的区分是建立在不合理的和主观的标准之上的区分。”[10]徐琳在其《人工智能推算技术中的平等权问题之探讨》一文中将“歧视”概念总结为:“其核心是客观上具有存在不合理的区别待遇,而区别待遇的类型和理由是法律所禁止的,以及客观上由于区别待遇,所造成非公平公正等的不良后果。”[11]总之,构成“歧视”有两点必要因素,其一是基于他者的某些特征区别对待,其二是对被歧视者造成了不良后果。
“歧视”与“偏见”的不同可以从两个维度来看。从本质层面上看,“歧视”是一种行为,而“偏见”则是一种认知状态。“歧视”作为一种行为必然会带来结果,而“偏见”作为一种认知状态与结果无涉。“歧视”通常是由“偏见”导致的,但并非所有的“偏见”都会导致歧视。我对他者的偏见是存在于我心中的一种认知状态,由于偏见的存在我可能会在对他者的认知上产生偏差,这种认知偏差不一定会对他者带来影响,它仅仅存在于我自身内部。“歧视”则代表着我已经对他者作出了价值判断与价值选择,已经产生了后果。这一后果是在客观世界中现实存在的,而不再是仅仅存在于我自身内部。
从价值层面来看, “歧视”必然是消极的,会带来不良的后果, 而“偏见”既可以是消极的也可以是积极的,甚至可以是价值中立的。 从构词上看,偏见的英文为prejudice(2)Bias在计算机领域也被译为“偏差”,但是在人工智能伦理领域通常与prejudice混用。, 意为在判断之前,明显是无关价值的;而歧视的英文为discrimination,以一个否定词缀“dis”开头, 表明了消极的意义。 我对他者的“歧视”必然蕴含着贬义,这意味着我在价值上贬低了他,没有作出公正的评价;而我对他者的“偏见”则未必如此。 我对他者的“偏见”可以和“歧视”一样是一种贬低。但是,我对他者的“偏见”也可以并非是一种贬低, 而是一种褒奖,表现为偏好。 当然这也是不公正的, 甚至,我对他者的“偏见”可以是价值中立的, 即我的偏见仅仅是我认识和理解的前提条件,这与价值无关。
结合这两个维度综合来看,“歧视”是基于“偏见”的,但“偏见”并不必然导致“歧视”。“歧视”与“偏见”之间最大的区别就在于“歧视”是一种行为, 它必然导致一个不良的后果; 而“偏见”仅仅是一种认知状态, 既可以是积极的也可以是消极的甚至可以是价值中立的, 其中只有部分消极的“偏见”有可能会转化为“歧视”。 从二者的生成逻辑来看, 偏见是先于人的认知而存在的, 人的认知被偏见所影响从而形成了基于偏见的判断,而将其中一部分包含消极偏见的判断不加反思地直接付诸于行动就有可能会构成歧视行为。 一个歧视行为产生的过程可以被写作“偏见-认知-判断-行为-歧视”。 可以看出,偏见转化为歧视的关键一步在于基于偏见的认知直接转化为行为而没有经过反思。 此时,作为一个理性人,尤其是在道德领域,应当在判断和行为之间层加一个反思环节, 考虑到偏见对人的认知的影响对之前的判断进行再判断, 如此一来便可以最大限度地避免偏见直接转化为歧视。 此时,理性人的行为应当被写作“偏见-认知-判断-反思-行为”。 简言之,从“认知-行为”的逻辑来看,偏见先于歧视, 且只有部分消极的偏见会转化为歧视; 从概念的内涵来看,偏见大于歧视, 偏见既可以是积极的也可以是消极的甚至可以是中性的,而歧视只能是消极的。
二、 算法偏见及其来源
算法偏见是指在算法中存在的偏见,本质上与解释学意义上的“偏见”概念是一致的,是人认识世界和解释世界的前提条件。算法偏见主要有三种来源,分别是数据中的偏见、开发者的偏见和算法本身的偏见。算法吸收并强化了这些偏见并使之成为了算法的一部分重新进入社会之中。但算法偏见仍然只是一种偏见,而非歧视,它并不会直接造成不良的后果。
在具体讨论算法偏见之前,有必要先对算法进行解析。
算法可以被简单地理解为一种通过计算机语言实现的解决问题的方法。本文中所使用的“算法”概念,主要是指机器学习算法及其进阶版的深度学习算法,许多算法相关的伦理问题都是建立在机器学习算法和深度学习算法的特性之上,例如黑箱特性。
目前被广泛使用的机器学习算法的原理见图1。
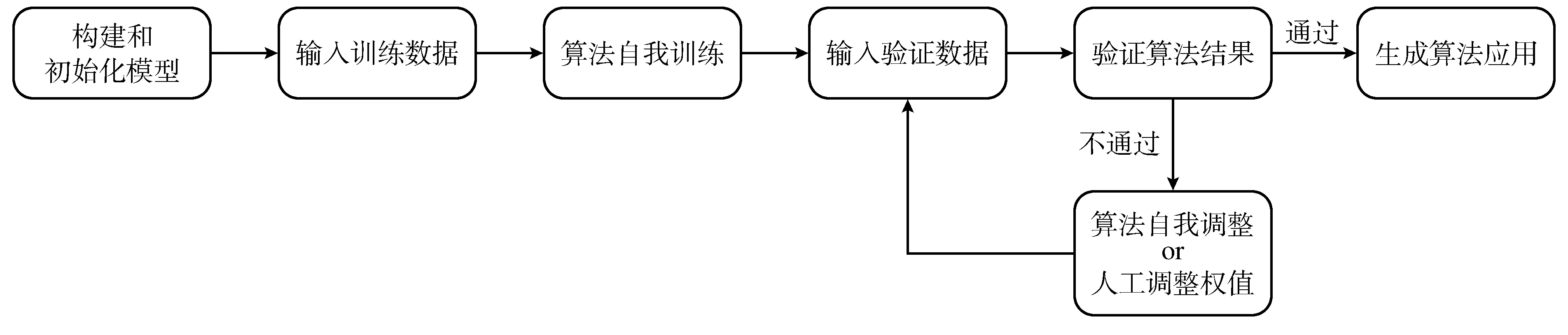
图1 机器学习算法原理
更进一步的深度学习算法的原理见图2。
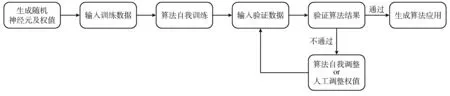
图2 深度学习算法原理
二者的主要区别就在于第一步,前者是人为地去构建模型,后者则是随机产生神经元和权值。此后在步骤上二者是一致的:首先输入一组训练数据(3)这组训练数据可以是由开发者选择录入系统的,也可能是从一个大数据库中随机选取的。,算法会根据输入的训练数据进行自我训练,初步形成一套算法系统;在自我训练完成后,开发者会输入一组验证数据来检验算法的训练成果,如果初步形成的算法系统给出的结果没有通过验证,则需要重新调整权值。调整权值可以通过人为调整或算法自我调整两种方式进行。在调整权值之后,将重新进行结果验证;如果验证通过,则算法训练完成,生成算法应用。深度学习区别于传统机器学习的另一点就在于其算法的“黑箱”性,即在整个深度学习的过程中人类无法理解算法的运作原理,即使是通过人工调整权值,开发者所能知道的也仅仅是“调整这个权值会让算法更加符合预期”,但其背后的原理仍是未知的。
算法偏见主要有三种来源。
第一,数据中的偏见。在计算机领域有一个很著名的“GIGO”定律,即“garbage in,garbage out”,意思是如果你输入的是一个垃圾数据,那么计算机给你的输出结果也只能是一个垃圾。《自然》杂志2016年的一篇社论中化用了这一著名定律,提出“BIBO”定律,即“bias in,bias out”[12]。也就是说,当你输入的数据中隐含偏见时,那么你输出的算法必然也是隐含偏见的。由于多种原因,日常生活中的数据常常包含了人类社会固有的隐性偏见。所谓“隐性偏见”就是指那些深藏在我们自身内部的、难以察觉的偏见。Brownstein将“隐性偏见”定义为:“相对无意识和相对自动的偏见判断和社会行为特征。”[13]我们在持有这些偏见时甚至都意识不到它们,与之相对的可以被称之为“显性偏见”。解释学意义上的“偏见”就是一种隐性偏见。即便是客观记录现实的数据也不免要含有这些隐性偏见。正如一些学者所说:“数据是社会数据化的结果,其原旨地反映了社会的价值观念,不仅包括先进良好的社会价值观念,也包括落后的价值观念。”[14]“数据既有真实的,也有虚假的,而且真实的也不等于是客观的,即数据并不具有天然中立性。”[2]数据的客观性仅仅体现在记录方面,它如实地将人类社会中的隐性偏见记录下来,再作为算法的训练数据或验证数据使这些偏见作为算法偏见呈现出来。例如,人类社会长期以来存在着对男女能力评价的偏见,诸如“平均来讲,男性的理性分析能力要高于女性”之类的论断。基于以上的论断,可能对于一些理性分析能力要求高的职位会录取较多的男性,如此一来,这一偏见就隐藏在一系列录取信息之中,这些录取信息作为算法的训练数据就会将算法训练成一个带有“偏见”的算法。
第二,开发者的偏见。开发者的偏见既包含显性偏见也包含了隐性偏见。开发者的显性偏见是指那些开发者有意为之的设计中的偏见。例如“大数据杀熟”,将同一件商品以较高的价格卖给用户黏度相对更高的人群,而以较低的价格卖给用户黏度相对更低的人群,这种算法通常是人为设置出来的而非算法自动学习的。只要开发者本身不怀有主观恶意,这种有意的显性偏见是容易被发现并且剔除的。此外,这种有意的偏见有可能是有益的也可能是无益的,这取决于开发者的偏见与事实的契合度,或者说,这取决于开发者的直觉或经验。如果开发者的直觉准确或经验老到,则通过引入开发者的偏见有可能使得算法程序更加高效,这就是有益的偏见,也被称为“偏见优势”。反之,如果开发者的直觉不准确或欠缺经验,将之引入算法系统就不会使算法程序变得高效甚至会使其变得低效,这就是无益甚至是有害的偏见。开发者的偏见也可能是隐性的,开发者与所有人一样,在认识和解释世界的过程中不可避免地要带有偏见,这种偏见也会被带入到算法之中。例如在男女识别系统中将“胡子”作为一项重要的识别特征,这可能会使得一些毛发旺盛的女性被识别为男性。然而这并非是开发者有意为之,而是受限于他的一个固有认知,即“有胡子的是男性而没胡子的是女性”。此外,由于存在“验证算法结果”这一环节,验证数据乃经开发者筛选后具有一定的开发者的认知痕迹的数据,因此任何机器学习算法都不可避免地在不同程度上具有人赋予其上的内在目的和价值指向。换句话说,由开发者验证算法结果的预设就是开发者知道算法结果的正确与否,并会纠正算法去按照开发者的预期重新进行训练。这一纠正并重新训练的环节可以通过开发者手动调节,也可以是算法进行自我调节。无论是哪种方式,训练最终的结果总是算法的输出结果服从开发者的预期,而这种预期显然带有开发者的判断和选择,开发者的偏见因而也就被带入到了算法之中。
第三,算法本身的偏见。Diakopoulos从算法的原理角度提出使用算法本身就可能是一种歧视。算法的按优先级排序、归类处理、关联选择、过滤排除等特点使得算法本身就是一种差别对待系统[15]。“在算法系统中,基于算法分类进行的优先化排序、关联性选择和过滤性排除是一种直接歧视,涉及差别性地对待与不公正。”[2]换句话说,算法运算的原理本身是一种“贴标签”的行为,而这些“标签”毫无疑问也是一种或显性或隐性的偏见,算法也因此必然带有偏见。人在这个意义上被当作了一个“数据主体”,拥有了一个“数据身份”。然而,这种方法并非算法所独有,这实际上是算法对人类认知的学习和模仿。心理学家Allport在TheNatureofPrejudice一书中指出:“人类心智必须在范畴的帮助下才能思考……范畴一旦形成,就会成为平常的预前判断的基础。”[16]可以看出,人类心智的这种认知方式与算法本质上是一致的。所谓的“范畴”与“标签”本质上是一样的,都是伽达默尔所谓的“偏见”。正如之前已经论证过的,人的认知活动本身就离不开偏见,算法也是如此。可以说,算法偏见是算法技术得以应用的前提,正如偏见是人认识和解释世界的前提一样。结合算法的原理,偏见进入算法的过程如图3所示。
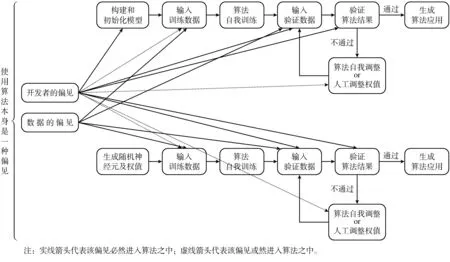
图3 偏见进入算法的流程图
首先,使用算法本身就是一种偏见。其次,在“构建和初始化模型”这一环节,开发者的偏见会被带入到算法中。在“输入训练数据”这一环节,数据中的偏见会被带入到算法中,开发者的偏见可能会被带入到算法中(4)如果在一个开源的数据库中随机选取训练数据就可以避免开发者的偏见被带入到算法之中,但数据本身的偏见仍是不可避免的。。在“输入验证数据”环节,数据的偏见和开发者的偏见都会被带入到算法中。在“验证算法结果”环节,开发者的偏见不可避免地进入算法之中。此外,如果采用“人工调整权值”的方式,开发者的偏见在这一环节也会进入到算法之中。
综上所述,无论偏见是在哪个环节进入算法的,算法都接收并强化了人类的偏见,尤其是隐性偏见。因此,与人的偏见一样,算法偏见是不可避免的。毕竟,虽然主观的、显性的偏见是容易被识别的并被剔除的,但真正让算法偏见无孔不入的正是那些不容易被我们觉察到的隐性偏见,它们是我们认识和解释世界的前提,也是算法技术得以实现的必要条件。
三、 算法歧视及其责任主体
正如偏见可能会引发歧视一样,算法偏见也可能会引发算法歧视,但并非所有的算法偏见都会引发算法歧视。正如已经论证过的,算法偏见是不可避免的,从数据收集阶段到最终的决策阶段,人类社会的偏见会以多种形式进入到算法之中,从而使算法最终输出一个有偏见的结果。这并不意味着算法偏见一定是不好的,如我们之前提到过的“偏见优势”,算法偏见有时甚至是一件好事。只有那些表达消极意味的算法偏见才有可能会导致不好的结果,从而转化为算法歧视。总的来说,算法偏见之所以会转换为算法歧视,归根结底是因为人的作用。
从概念上看,与算法偏见的概念类似,算法歧视指的应当是算法中存在的歧视。然而,在人工智能伦理中被讨论的算法歧视其实分为两类:一类实质上是人的歧视,另一类才是真正的算法的歧视。
大多数的算法歧视归根结底是人的歧视,人们对于算法含有偏见的结果不经审查就作出决策的行为构成了所谓的算法歧视。从算法的原理来看,基于大数据的算法所能够提供的只是相关性结论,即通过数据表明的相关关系。本质上,算法所做的是归纳推理,给出的输出结果也只是一个归纳假设。“归纳假设无法为其真实性提供逻辑上的保证,而且往往不得不在以后的某个时间点向与之相反的证据低头。”[17]人们应当理解,基于大数据的算法所能输出的结果仅仅只是一个相关关系,如果将这种相关关系视为因果关系,那么算法偏见将不可避免地导致算法歧视(5)尽管Judea Pearl等人提出了“因果机制造成相关”的理论,并试图证明机器学习不仅仅可以学习相关性也可以学习因果性,但是,这一理论的本质仍然是一个归纳假设,最多只能被认为是科学上的因果性而非事实上的因果性。。美国前任司法部长Holder针对算法量刑的问题曾说过:“我担心它(量刑时使用的算法)无意中破坏了我们确保个性化和平等司法的努力……刑事判决必须以事实、法律、实际犯罪、每个案件的情况以及被告人的犯罪历史为依据。它们不应基于一个人无法控制的不可改变的因素,也不应基于未来尚未发生的犯罪的可能性。”[18]这句话道出了算法歧视的一个真相:人们不加审查地盲目信任算法的结果,反而忽视了一个道德判断或价值判断所真正应当考虑的因素,导致算法偏见毫无障碍地通过人们的决策转变为了算法歧视。只要人们对其保持警惕,而非盲目轻信,很多算法偏见都是可以被识别出来并进行改正的。
算法给出的方案和建议或许带有歧视性,但这不是算法的选择,而是算法本身的框架和权重所导致的一个必然结果。算法的框架和权重都是由算法开发者们设计的,即使是通常称之为“黑箱算法”的深度学习算法也是如此,而使算法给出的歧视性方案和建议最终转化为歧视行为的是算法的真正的使用者们。正是他们不加审查地服从含有偏见的算法的建议,才引发了算法歧视。所以,算法歧视应当有明确的责任人。算法偏见虽不可避免,但不必然导致算法歧视,真正设计和使用算法的人应当为歧视行为负责。要避免算法偏见导致算法歧视的关键就在于规范人,尤其是规范算法的开发者和使用者。
至于算法的歧视,它存在且只能存在于自主决策算法之中。因为歧视首先是一种道德行为,只有道德主体才能够对他人进行具有价值判断与价值选择色彩的歧视行为,而一个道德主体最基本的特性就在于能动性。在人工智能领域,许多学者研究智能机器的道德主体地位,但是算法与人工智能之间还是存在区别的,尤其是非自主决策的算法。非自主决策的算法所能做的仅仅是提供一种解决问题的方案或方法,但智能机器可以使得算法给出的方案或方法直接转化为一种实践,即将算法提出的方案付诸现实。非自主决策算法不具备直接的实践能力,也就不具备主体地位。所以我们说算法歧视就只能是从自主决策算法的这个角度来说,非自主决策算法的歧视归根结底是人的歧视。非自主决策算法可以给出带有“偏见”的方案和建议,却无法直接对他者实施价值层面上的“歧视”。
当然,即使是自主决策算法导致的算法歧视也并非不可避免的,也是有责任主体的,那就是将自主决策算法付诸于某一实践领域的那个人。从定义上看,算法可以被简单理解为一种使用计算机语言实现的解决问题的方法。因此,任何算法的诞生都必然是含有内在目的的,即具有内在的价值。这一价值是由人赋予算法的。事实上,在“算法偏见是不可避免的”这一前提下,人类应该知道自主决策算法不应当适用于那些容易引起歧视的领域。所以,试图将自主决策算法应用于那些可能会引起歧视的领域的人应当为此类算法歧视负责。
或许,有观点认为,“开发者会辩称,他们的算法是中立的,只是容易被置于有偏见的数据和社会不当使用的错误环境中。而使用者则会声称,算法很难识别,更不用说理解,因此排除了使用者在使用中的道德含义的任何罪责”[19]。面对算法,人类事实上是有选择的。如果算法给出的答案就是真理,或者说所有人都百分百确信算法给出的答案,或许我们就可以忽视这一问题。现实情况恰恰不是这样,算法通常应用在这样的环境中:更可靠的技术要么是不可用的,要么是实现成本太高,因此很少意味着是绝对可靠的[20]。所以,讨论算法的伦理问题显然要基于这一现实情况,即“算法是不完善的,算法偏见是不可避免,即使是自主决策算法也是如此”。因此真正的决策权自始至终都掌握在人类自己的手中。
正如“算法偏见”作为算法的伦理问题已经被人类识别出来一样,算法的黑箱属性实际上并不影响人类对它的掌控能力。或许有人会说,虽然目前的可能会导致算法歧视的算法偏见是可以被识别出来的,但是,人们担心的是,随着技术的发展,有一天它无法被识别出来怎么办?可是,既然如今算法偏见是可以被识别出来的,而且伦理学家们也普遍认识到了这一点,那么在解决这一问题之前,我们有什么理由在一个可能会诱发歧视的领域去发展一种自主决策算法呢?如今的经验告诉我们,对于自主决策算法,至少目前,应当处于人们的控制之下,应确保算法偏见最终不会转化为算法歧视。对于已经存在的自主决策算法,一方面要反思其存在的必要性,取消那些非必要的自主决策算法,另一方面算法的开发者和使用者应为其提供相应的监管和补偿措施,以尽量减少算法歧视的危害。
笔者认为,人类作为道德主体,是算法歧视的责任人。算法的开发者和使用者有责任去识别算法中可能存在的或显性或隐性的偏见,应当对算法的应用与决策始终保持审慎的态度和全面的考察,以确保算法偏见不会转变为算法歧视。
四、 结 语
综上所述,算法歧视的责任人是算法的开发者和使用者,他们要对算法歧视的行为负责。我们每一个人,作为潜在的算法的开发者或使用者,对待算法偏见与算法歧视的正确态度应当是正视算法偏见,避免算法歧视。正视算法偏见要求我们认识到:首先,算法偏见是不可避免的,它来自人类的偏见,其中以隐性偏见为主;其次,算法偏见虽然是不可避免的,但是却是可识别的,尤其是来自显性偏见的算法偏见;最后,算法给出的方案和建议是基于大数据的相关性结论,并不具备因果必然性。
要避免算法歧视需要我们在正视算法偏见的基础上:一方面始终对算法保持审慎态度,在开发和应用算法时应禁止带入个人的显性偏见并努力识别出其中的显性或隐性偏见,避免算法歧视,对于算法给出的方案与建议不要盲从,而应当三思而后行;另一方面,对于自主决策算法的可适用领域应当谨慎选择,对于那些可能直接造成歧视的领域应当尽量避免使用自主决策算法,至少在使用自主决策算法时应确保具有相应的监督机制和补偿机制。具体来说,一个可能的区分在于:算法的开发者应当为由算法本身导致的结构性的算法歧视负责,即因设计的不合理导致的算法歧视应当由算法的开发者负责,无论是其出于故意的选择还是无意的偏见;算法的上层使用者(例如公司、政府部门)应当为宏观层面的结构性的算法歧视负责,即在不应当使用自主决策算法的领域使用自主决策算法或使用自主决策算法的同时没有确保具有相应的监督机制和补偿机制所导致的算法歧视应当由算法的上层使用者负责;算法的下层使用者,即每一个使用算法的理性人,应当为由明显错误的消极的算法偏见导致的算法歧视负责,这是因为明显错误的消极的算法偏见直接转化为歧视行为是由算法的下层使用者造成的,因为他们没有对这种明显错误的消极的偏见进行理性人在道德领域所应当进行的反思。
