改进SSD的服装图像识别方法
2022-02-16楚雅璐顾梅花
楚雅璐,顾梅花,刘 杰,崔 琳
(西安工程大学 电子信息学院,陕西 西安 710048)
0 引 言
服装图像识别是服装图像分析和处理的重要基础步骤[1],为后续的服装语义分析[2]、服装姿态估计[3]等问题研究提供了技术保障。在计算机视觉和模式识别相关领域中,服装图像分析与识别技术是最近非常活跃的研究课题,其在服装图像检索[4]、搭配推荐[5]以及行人描述[6]等领域都有着重要应用。然而,复杂场景下因为人体坐姿、站姿以及运动状态的变化,存在不同程度的服装形变问题,在一定程度上增加了服装图像识别的难度。
在早期服装图像识别研究中,采用数字图像处理和模式识别技术提取服装特征。对于全局特征,常用的方法有傅里叶描述子[7]、几何不变距[8]、灰度共生矩阵(GLCM)[9]等,此类方法容易受到环境的干扰。对于局部特征,常用的方法有尺度不变特征变换(SIFT)[10]、加速鲁棒特征(SURF)[11]和方向梯度直方图(HOG)[12]等,此类方法只适合于对图像进行匹配、检索,对图像理解则不太适合。近年来,出现了大量基于深度学习的图像识别方法,典型算法有R-CNN[13]、YOLO系列[14-15]、GoogleNet[16]、ResNet[17]、Fast R-CNN[18]、SSD[19]、Mask R-CNN[20]、Faster R-CNN[21]等,此类方法提取的图像特征鲁棒性更强,泛化能力更好。研究者也已将深度学习方法应用于服装图像识别任务中,典型算法有:Fashion Net[22]、Match R-CNN[23]等,此类方法可以分阶段完成服装图像分割、识别、检索等任务,但对服装图像识别没有针对性,服装易变形,识别准确率偏低,并没有针对形变服装图像识别给出解决方案。
SSD算法因其通过提取不同尺度的特征图进行目标识别,采用不同尺度的先验框提升算法对不同尺度目标的识别能力而得到广泛应用。因此本文将SSD算法应用于服装图像识别任务中,通过大量实验发现算法对形变服装的识别准确率偏低,在复杂场景下,服装着装在人体上容易发生形变,会出现漏检或识别错误的现象。针对上述问题,本文提出了一种基于改进SSD的服装图像识别方法,首先采用空间变换网络进行数据增强,接着采用可变形卷积提取更丰富的服装特征信息,最后通过几何信息融合网络进行特征融合,旨在提升算法对形变服装的识别精度。
1 方法概述
改进SSD的服装图像识别方法网络结构如图1所示。

图1 改进SSD的服装图像识别方法网络结构图
首先输入服装图像,经过卷积神经网络对其进行特征提取,采用空间变换网络对服装图像特征进行数据增强,通过对Conv3_x特征层进行仿射变换,得到适合于形变服装的特征图,以增强其空间不变性,减少数据变形的偏差;然后采用可变形卷积来改进Conv4_x特征层的标准卷积,采用偏移方法使特征抽取过程聚焦于有效信息区域,对偏移修正后的区域分配不同权重,实现更加准确的特征提取;最后通过几何信息融合网络,将Conv3_x和Conv4_x两个特征层进行特征融合,获得更多的几何细粒度特征信息,采用更多的浅层几何特征信息进行预测,提高网络对服装图像几何信息的表达能力,从而提升模型对形变服装图像的识别准确度。
2 优化方法
2.1 基于空间变换网络的数据增强优化
为了改善SSD对服装图像特征区分能力不强而造成其对形变服装识别不敏感的问题,采用空间变换网络[24]对服装图像特征进行数据增强,提高其数据质量,通过仿射变换增强其空间不变性,减少数据变形的偏差。并对SSD的Conv3_x,Conv4_x,Conv5_x网络层采用空间变换网络进行实验,结果表明,将空间变换网络设计在Conv3_x处网络识别精度最高。
空间变换网络结构如图2所示,将服装特征图U输入到空间变换网络,首先由定位网络采用3×3的卷积操作提取特征,进而通过隐藏层预测出2×3维的仿射变换参数θ,学习仿射变换矩阵Aθ;随后由网格生成器利用规则的空间网格G和Aθ创建与输出图像中的每个像素相对应的采样网格Tθ(G),根据θ得到变换前后像素点坐标的对应关系,如式(1):
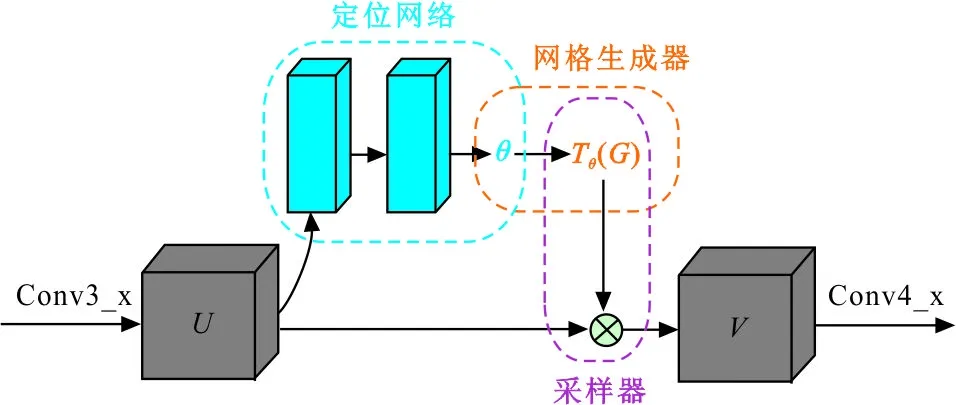
图2 空间变换网络结构
(1)
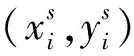
(2)
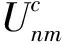
2.2 基于可变形卷积的特征提取优化
为了改善传统卷积核对形变服装图像描述不足的问题,在Conv4_x特征层对空间变换网络增强后的服装图像特征采用可变形卷积替换传统卷积核的方式进行优化。可变形卷积[25]在传统卷积的基础上增加了调整卷积核的方向向量,使卷积核的形态更贴近特征物,可根据识别目标的复杂空间结构而改变,提高输出特征对目标旋转变换的敏感性。
可变形卷积操作过程如图3所示,首先利用3×3的传统卷积核提取输入图像的特征图,作为可变形卷积操作的输入,对特征图再施加一个3×3的卷积层,获得与输入特征图相同尺寸的偏差尺寸,生成通道维度为2N的原始输出特征和偏移特征,做加权和得到可变形卷积的变形偏移量,用带偏移的采样来代替原来的固定位置采样,然后通过将每个像素的相邻相似结构信息压缩到固定网格中,生成可变形特征图像。卷积操作后提取的服装图像特征信息能够更好的表征形变服装,对于形变服装图像的几何形体有更好的适应性。

图3 可变形卷积操作过程
2.3 基于几何信息融合的特征融合优化
为了能够融合更多形变服装的特征信息,在SSD模型的基础上增加了几何信息融合[26]模块,通过将优化后的Conv4_x深层次的语义信息与Conv3_x浅层次的语义信息相结合,使更多的浅层几何特征信息用于预测,提高网络对服装图像几何信息的表达能力。
几何信息融合模块如图4所示。该模块在Conv3_x特征层后采用2×2的卷积核进行下采样,使下采样后的特征层与Conv4_x特征层为相同尺寸512×512,然后分别对每个特征层连接3×3的卷积核与归一化层,最后分别对两个特征层进行融合,作为SSD网络中的一个预测通道,并与其他输出特征进行多尺度预测输出。
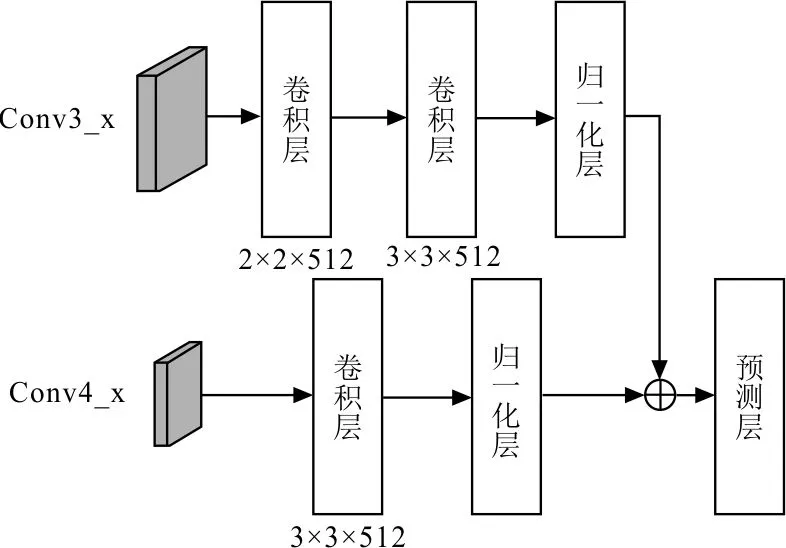
图4 几何信息融合模块
3 实验结果与分析
实验平台采用PyTorch深度学习框架,操作系统为Ubuntu16.04,CPU为Inter Core i5-9400F,GPU为RTX2070 s。本文实验提取DeepFashion2中的形变服装制作成子数据集,其中训练集图片30 000张,测试集图片1 000张。模型训练迭代100次,前50次迭代batch_size为8,后50次迭代batch_size为4。
为更好地评估本文算法的性能,选择精确率、召回率、准确率以及平均精度均值作为评价指标,用来评价模型的识别精度。精确率(Precision记为P)表示算法对服装图像正确识别结果占所有识别结果的比例,定义为式(3);召回率(Recall记为R)表示所有被正确识别的服装图像与真实服装图像标注的比值,定义为式(4);准确率(Accuracy记为A),是指服装图像识别结果正确的比例,定义为式(5);平均精度均值(Mean Average Precision,mAP)表示该模型对服装数据集中所有类别图像的识别准确度。将模型对所有样本的预测和值依据置信度大小排序,并逐个绘制Precision-Recall曲线(即P-R曲线),平均精确度(Average Precision,AP)就是某一类别P-R曲线下的面积,在计算过程中对所有类别的AP取平均得到mAP,定义为式(6)。
(3)
(4)
(5)
(6)
式中:TP为正样本识别为正;TN为负样本识别为负;FN为正样本识别为负;FP为负样本识别为正;k为当前类别的序号,且k∈(1,2,…,N);N为总类别数;APk是第k个类别的AP值。
3.1 消融实验
采用DeepFashion2数据集中的形变服装子数据集对SSD算法及其不同改进方法进行测试。消融实验结果如表1所示,其中S-SSD表示SSD网络进行空间变换优化后的模型;D-SSD表示SSD网络采用可变形卷积优化后的模型;SD-SSD表示对SSD网络采用空间变换网络以及可变形卷积优化的模型;本文方法表示对SD-SSD网络进行浅层特征几何信息融合后的模型,通过mAP值评价模型的识别精度。从表1可看出,各种改进方法都能显著提升模型的识别精度,本文方法取得了最高的mAP值,比SSD原模型提高了3.63%。
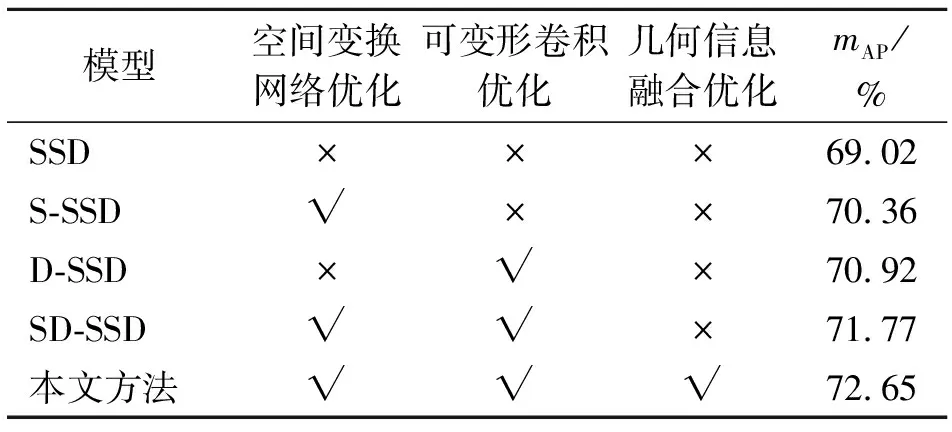
表 1 消融实验结果
采用热力图分析法[27]验证不同改进方法的有效性。不同改进方法可视化生成的热力图如图5所示,可以看出,由于坐姿状态导致连衣裙发生形变,图5(b)SSD网络热力图中的鲜亮区域主要集中在形变连衣裙上半身;图5(c)D-SSD网络热力图中的鲜亮区域主要集中在连衣裙上半身以及少部分下半身;图5(d)S-SSD网络热力图中的鲜亮区域主要集中在连衣裙的下半身并且上半身有少部分鲜亮;图5(e)SD-SSD网络热力图中的鲜亮区域主要集中在连衣裙的大部分,但是鲜亮的部分较为分散;图5(f)本文方法热力图中的鲜亮区域覆盖了连衣裙,并且比较集中。采用不同改进方法都可以不同程度地增强模型对形变服装的几何特征提取能力,而将三种改进方法综合而成的本文方法可以更好地表征形变服装图像,减少服装形变的影响。

(a)原图 (b)SSD (c)D-SSD
3.2 定性评估
为评估本文方法对形变服装图像识别的有效性,在形变服装子数据集上进行定性分析。将本文方法与SSD算法对不同程度形变服装图像的识别效果进行比较,结果如图6所示。

(a)样例1 (b)样例2 (c)样例3
可以看出,图6(a)中由于坐姿,外套发生形变,SSD算法将其错误地识别为短袖上衣;图6(b)中由于躺姿,连衣裙发生部分形变,SSD算法将连衣裙上半身错误地识别为背心;图6(c)中由于坐姿,短裙平铺发生严重形变,SSD算法没有识别到短裙。结果表明,本文方法对不同形变程度的服装都能准确识别。
本文方法与SSD算法对形变服装识别置信度比较如图7所示。

(a)样例4 (b)样例5 (c)样例6
可以看出,图7(a)中的连衣裙由于坐姿发生形变,SSD算法对连衣裙的识别结果置信度为0.87,本文方法识别结果置信度为0.98,置信度提升了0.11;图7(b)中的短裙由于坐姿发生形变,SSD算法对短裙识别结果的置信度为0.74,本文方法识别结果置信度为0.95,提升了0.21;图7(c)中的连衣裙由于坐姿发生严重形变,SSD算法对连衣裙的识别结果置信度为0.77,本文方法识别结果置信度为0.91,提升了0.14。结果表明,与原SSD算法相比,本文方法对不同程度形变服装图像的识别均能取得更高的置信度,对形变服装的识别更具有鲁棒性。
3.3 定量评估
为进一步评估本文所提改进方法的性能,利用DeepFashion2数据集中丰富的标注样本,在形变服装子数据集上,对SSD原模型与各种改进方法进行定量分析,其识别精度比较如表2所示。结果表明,各种改进方法对各种不同形变服装的识别精度都有明显提升,其中通过空间变换网络优化后的S-SSD网络比SSD算法的mAP提升了1.34%;通过采用可变形卷积优化后的D-SSD网络比SSD算法的mAP提升了1.9%;通过采用空间变换网络以及可变形卷积优化后的SD-SSD网络比SSD算法的mAP提升了2.75%。与SSD算法相比,本文方法对形变服装的识别精度提升最显著,其平均mAP值提升了3.63%,对形变短袖上衣的识别精度mAP提升高达7.88%。

表 2 SSD原模型与各种改进方法对形变服装识别精度比较
将本文方法与其他模型(YOLOv4[15]、GoogleNet[16]、ResNet-50[17]、Fast-RCNN[18]、SSD[19])对形变服装的识别精度进行比较,结果如表3所示。可以看出,相比于其他模型,本文方法对不同种类形变服装图像的识别精度最高,其平均mAP提升最高可达16.51%。
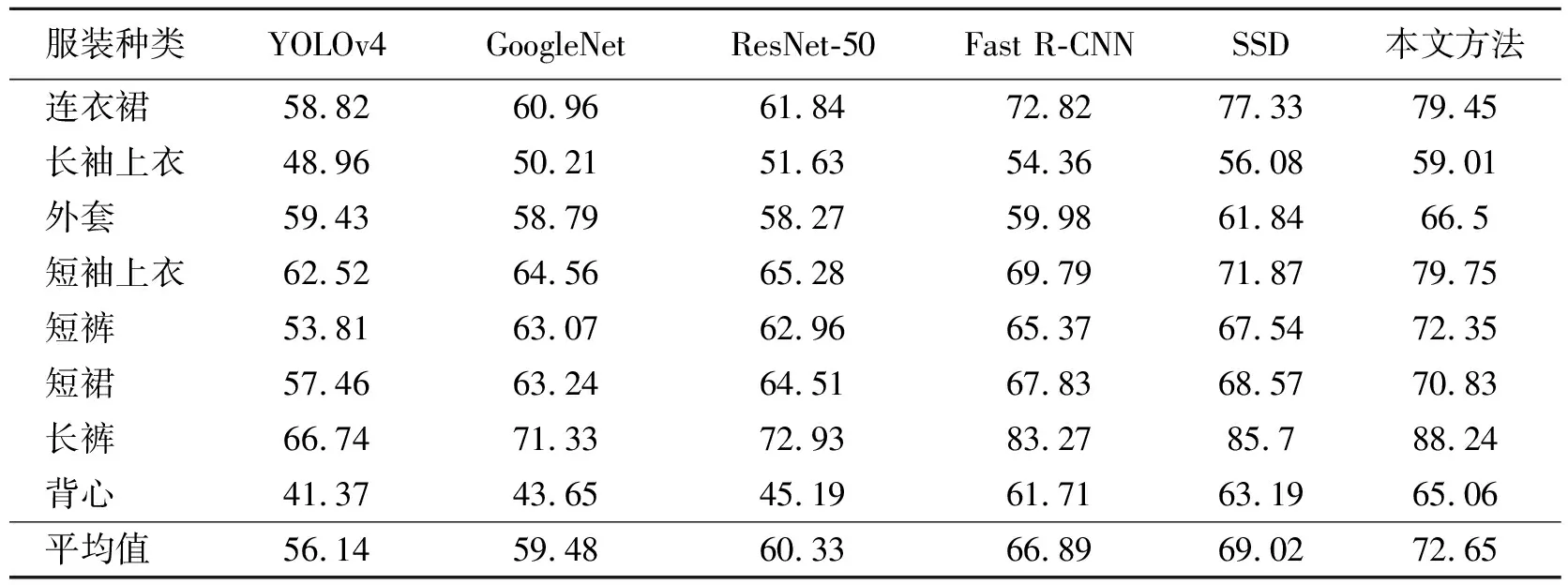
表 3 本文方法与其他模型对形变服装的识别精度比较
4 结 语
本文提出一种改进SSD的服装图像识别方法,以改善形变对服装图像识别的影响。采用空间变换网络对服装图像特征进行数据增强,使网络具有空间不变性;采用可变形卷积提取更丰富的服装特征信息,提高网络对于形变服装的适应性;通过几何信息融合网络获得更多的几何细粒度特征信息,提高网络对几何信息的表达能力。实验结果表明,本文所提方法能显著提升对形变服装图像识别的准确度。
