Web信息增量采集与保存管理平台的设计与实现
2022-02-16赵丹阳
赵丹阳
(国家图书馆,北京 100081)
0 引言
2022年中国互联网络信息中心发布的第49次《中国互联网络发展状况统计报告》[1]中显示,截至2021年12月,全民互联网普及率已经超过80%,尤其在即时通信、在线医疗、远程办公等领域,互联网在新冠疫情常态化防控等方面发挥了积极作用。网络已经成为全国亿万网民衣食住行、获取信息、在线交流等的重要平台,互联网资源更是成为了人类社会重要的信息载体,及时完整地保存网络资源,记录时代记忆非常重要。但互联网信息的体量庞大、结构复杂、易变易消失等独特的资源特性,导致其保存难度极大,因此,准确有效地保存瞬息万变的网络资源是图书馆工作者在数字时代的重要使命。
1 国家图书馆网络资源保存工作进程
国家图书馆自2003年着手对国内发生的重要事件和特大事件进行专题收集;2007年正式加入国际互联网保存联盟(IIPC);2014年联合全国图书馆共同开展网络资源的保存和服务;2018年研发并推广地方图书馆部署网络资源采集和保存平台,实现互联网资源高效和规范化的采集、编目、回放、发布和服务[2]。经过多年探索,在保存策略方面,主要采用全域采集和专题性采集相结合的采集策略;在采集工具方面,使用IIPC研发和推广的开源工具Heritrix进行采集、openwayback进行数据回放、国际广泛应用的WARC格式[3]进行数据存储。截至目前,国家图书馆已累计采集保存国内外网站超过5万余个、专题网络资源超过300个,保存数据量达到300 TB,网络采集资源成为图书馆数字资源建设的重要组成部分。
2 Web信息增量采集与保存管理平台的设计
2.1 平台设计思路
基于网络资源采集和保存项目的业务特点和需求,平台选用成熟的开源技术和工具,并对开源工具的功能进行适当调整,通过一定量的个性化定制开发以满足网络资源增量采集、精准的增量回放等个性化需求。在此基础上,整合构建成一个模块化的、开放架构、易于扩展升级的网络信息增量采集与保存管理平台,它既能实现个性化的采集策略定制、流程化的完整采集管理和数据保存管理等功能,又能提供准确完整的网页回放服务。
2.2 平台架构
平台在技术实现上,进行了多个个性化功能的改造和研发,平台架构如图1所示。UI交互界面层提供用户方便快捷、可视化的使用界面;展示层进行业务请求渲染和交互,采用异步JavaScript和 XML技术,实现网页异步更新;服务层提供任务管理、性能优化模块、参数配置、定制模块等相关接口;采集层应用Heritrix爬虫,处理抓取、队列、监测等核心工作;存储层校验和保存采集回来的数据;运行环境支持整个平台的稳定运转。
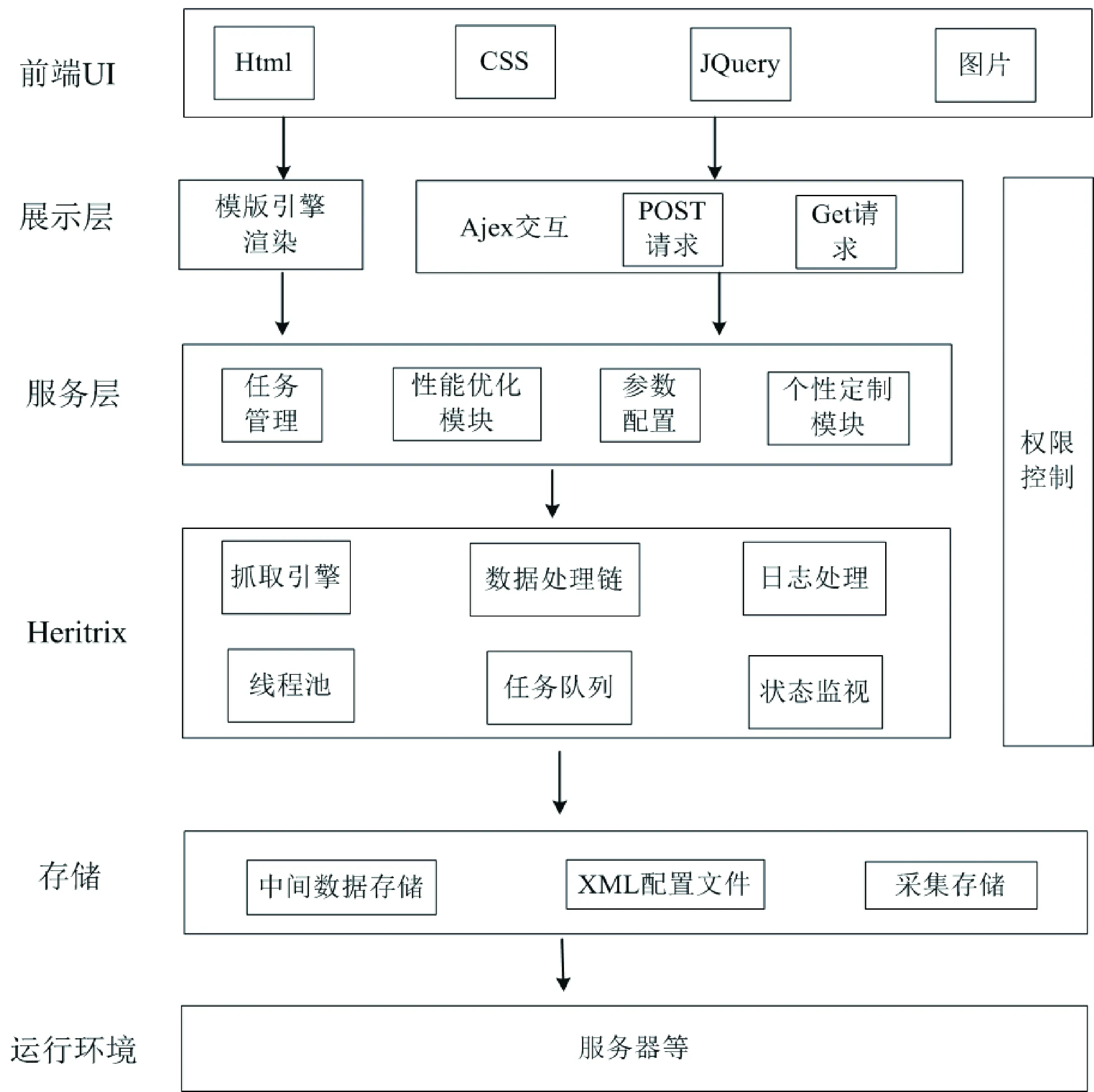
图1 平台架构
2.3 Heritrix爬虫系统
Heritrix爬虫系统主要由4个模块构成:Web管理平台、编辑处理模块(边界控制器Frontier)、线程池和处理器,其工作流程,如图2所示。管理平台通过Web页面设置Heritrix的运行配置;编辑处理模块存储爬取范围内的URI队列,根据调度策略分配URI到线程池;线程池采用多线程的方式处理URI任务,并将处理后的URI送给预加载处理器;预加载处理器主要处理DNS,robots.txt的认证,裁定抓取范围;抓取处理器处理http,dns等协议;内容提取器提取页面链接;写入链以warc或其他格式写入采集文档;更新状态链负责更新抓取状态及检查链接是否在抓取范围内。处理器通过对接收到的URI 的预处理、抓取、过滤等上述系列操作,将筛选出的URI再次送回至边界处理器,进行下一个操作的循环。

图2 Heritrix爬虫系统工作流程
2.4 平台的关键技术实现
2.4.1 增量采集技术的实现
平台的增量采集是在采集整站Web网页数据基础上,以采集新出现的和变更的网页为目标的采集。平台采用Heritrix 3.4版本进行采集程序定制开发,沿用WARC文件格式标准,选用默认的WARC Writer Processorwen文件处理器,在此基础上做增量文件的处理。网站增量采集流程,如图3所示。在采集源分析过程中,平台采集程序首先判断是否需要增量爬取,如果不需要,则进入全站抓取业务流程。如果判断需要增量爬取,则需要确定爬取目标。先要获取增量爬取需要比对的版本号,通过计算对当前的Crawl URI和版本号内的爬取目标进行对比。如果文件存在且大小无变化,则说明爬取对象不需要增量爬取,直接返回结束状态并跳过;如果文件不存在或文件存在但运算结果发生了变化,则认为需要增量爬取的对象,需要把采集的URL放入采集队列进行爬取流程,并且将当前版本和URI等对象信息痕迹进行保存。增量采集判断的业务逻辑会根据采集源的情况循环执行,直到采集源分析全部完成,进入下一个采集操作流程。

图3 增量采集流程
增量抓取的任务要区分于普通的整站抓取任务,是需要做任务标记的,增量任务的标记过程放在任务链接爬取启动开始前。平台中设计的增量采集程序,会在任务运行中检查job State状态,增量采集过程中note Frontier State会调用接口job状态。
2.4.2 增量回显一站式服务的实现
平台集采集和回显一站式服务,采集结束后,平台自动针对当前任务状态进行变更并对采集任务进行预览发布,以人工核验方式对本次采集任务进行审核。图4是平台增量回放模型,平台将采集数据中的目标网站按照URL+批次区分的方式进行索引,索引数据库建立完毕后需将索引记录进行存储。在检索过程中,按照目标网站的批次索引进行相对应的数据检索,并将检索结果反馈给前端页面呈现,其中,增量采集数据仅建立增量部分数据的索引。在检索过程中,可能会出现历史网站数据本批次不存在的情况,此时检索模块通过自动匹配网站历史批次记录检索查询数据,以达到未变化的网址通过历史数据进行全站无缝对接呈现,进而大幅度地节省数据库容量和查询时间,并减轻了网站冗余。
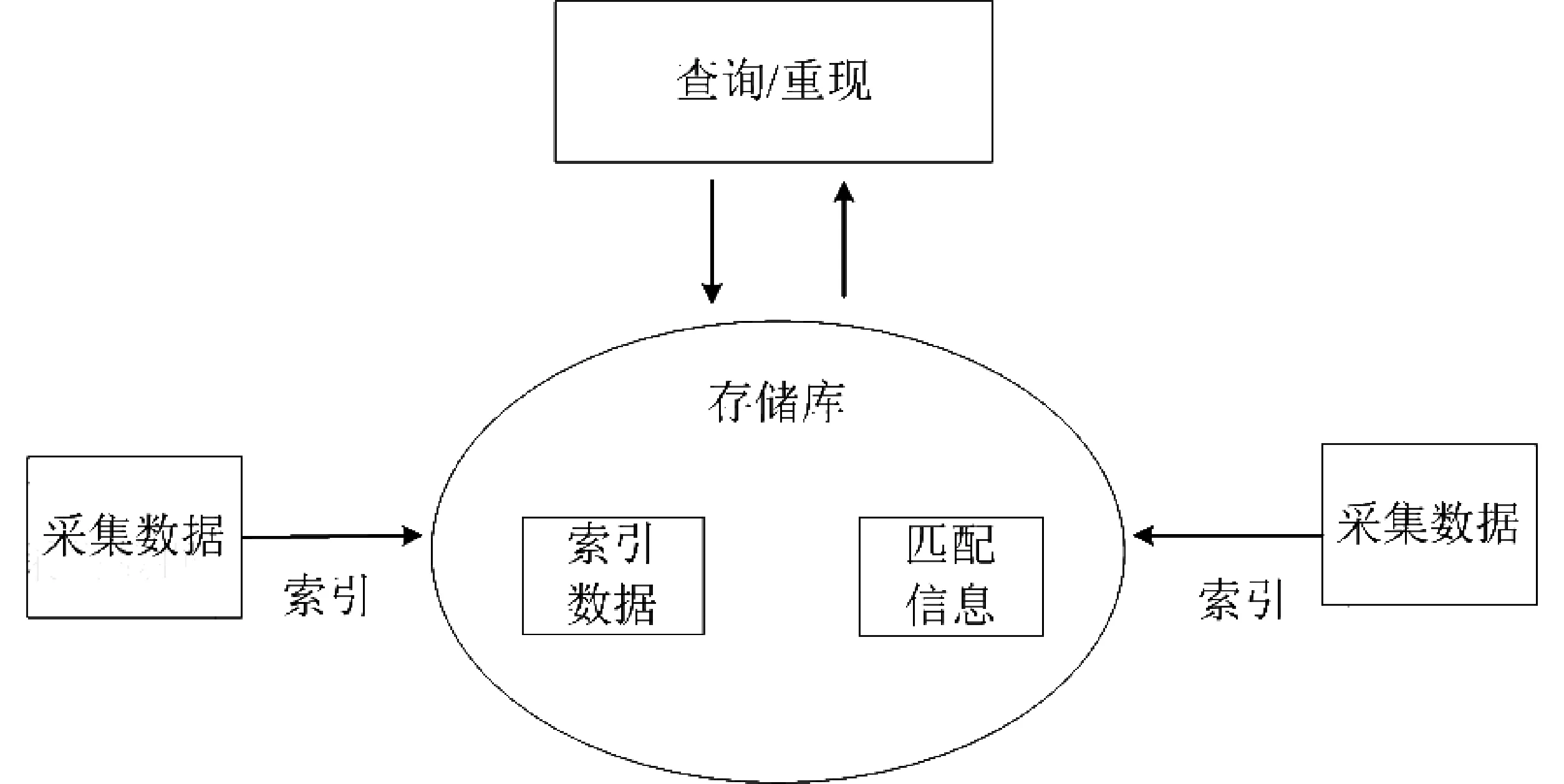
图4 增量回放模型
3 平台实例效果
平台实现了静态网站的增量采集和回放的一站式管理,采集效率比全站采集明显提升,保证采集内容时新性的同时,有效地解决了存储空间不够和带宽有限等问题。
从表1中可以看出,在实际业务中,平台对同一网站采用全站采集和增量采集两种采集方式下,在采集数据量、HTML数量和时长上有明显的差别;两种采集方式可以较为清晰地看出增量采集效率远远高于全站采集效率,较为显著地缩短了采集周期,尤其实例中北图文化网站,相比较于社会媒体网站新华网,其网站的更新频率更低,增量采集效果更明显。

表1 不同采集方式的效率比对
4 结语
本文基于Heritrix 3.4和OpenWayback开源架构构建了Web增量采集和保存管理平台,实现了大部分静态网站的增量抓取和增量回放,切实有效的解决了目前工作中亟待解决的存储和带宽问题,缩短了采集周期,保证了采集内容的时新性。但近年来伴随5G 网络的普及和智能终端的发展,催生出了多样化的网络信息载体形态,这对网络资源的采集又提出了更高要求,网络资源保存工作者也应该不断地思考采集业务在网络资源采集策略、范畴、技术、知识挖掘以及服务模式等方面的优化和创新,以提升网络资源“保存”与“应用”的价值。
