基于卷积神经网络的人脸图像超分辨率重建方法*
2022-02-16倪若婷周莲英
倪若婷 周莲英
(江苏大学计算机科学与通信工程学院 镇江 212013)
1 引言
图像超分辨率重建技术分为两类,一类是基于重建的[1~3],另一类是基于学习的。基于重建的技术一般被用于将同一场景的多帧图像序列重建为一帧高分辨率的图像。基于学习的技术通过外部事例学习高低分辨率图像之间的映射关系来对低分辨率图像进行超分辨率重建,常被应用于单帧图像。考虑到获取同一场景的多帧人脸图像仅在基于视频的情况下才有可能获得,并且对非刚性的人脸图像进行重建存在很大的配准困难,因此本文将针对基于学习的技术来展开研究。
近来,基于卷积神经网络的方法在超分辨率重建方面实现了最先进的性能。文献[4]首次将卷积神经网络引入超分辨率重建,并超越了传统重建方法的效果。文献[5]引入残差网络,加深了网络的同时缓解了梯度下降的问题,提高了重建效果。文献[6]开始使用反卷积网络来代替对低分辨率图像的插值,减少由于输入图像尺寸过大带来的计算复杂问题,加快重建速度。文献[7]引入了生成对抗网络,减少了生成的HR 图像和标签图像之间的差距,提高了图像的视觉效果。文献[8]引入迭代反投影算法的思想,将预测得到的高分辨率图像对应的低分辨率图像与原始低分辨率图像之间的误差进行反馈,指导生成更优的高分辨率图像。这些方法适用于通用图像且对于较大分辨率的图像(通常为128px*128px 及以上)取得了满意的效果。但是网络会因为极低分辨率图像(如16px*16px 等)的输入导致性能变差。
由于人脸图像具有结构性,并且结构内的五官、纹理存在差别,区别于其他的图像,简单地将超分辨率重建技术应用于人脸图像的效果往往不理想。最近,一些研究将人脸结构信息应用于人脸图像超分辨率重建并取得了最先进的成果[9]。在检测人脸关键点的同时进行人脸超分辨率重建,对现实生活中的16px*16px 的人脸图像进行4 倍上采样[10]。其中有两个分支,一个分支用于进行超分辨率重建,另一个分支用于预测人脸组成部分显著区域的热图,这些热图鼓励生成具有更高质量细节的人脸图像[11]。将自己的网络结构分为两个分支,一个分支用来进行超分辨率重建,另一个分支用来进行人脸关键点和人脸解析图的预测,最后将两个分支同时用来生成高分辨率人脸图像。
为了还原极低分辨率人脸的结构性,本文在使用通用图像处理方法的同时,引入人脸语义信息,较好地实现了人脸的重建。
2 相关工作
2.1 迭代反投影方法
Irian 和Peleg(1991)[12]提出了迭代反投影方法。该方法首先对LR 图像进行插值,得到初始的高分辨率图像,并将该初始图像通过观测模型得到模拟低分辨率图像。再将LR 图像与模拟LR 图像的误差用来更新初始高分辨率图像。循环迭代上述步骤并得到最后结果。
2.2 深度反向投影网络
DBPN 结构的主要组成部分为上、下投影单元。上投影单元首先将LR 特征图作为输入,将其映射至高分辨率特征后映射回重构特征图,其次将LR 特征图与重构LR 特征图之间的差值再次映射到高分辨率特征图,并更新高分辨率特征图。下投影单元与之相反。
2.3 人脸解析
人脸解析[13~14]为语义分割的一种应用。语义分割即将图像的各个部分按照人们定义的类别进行分类,得到不同的分割结果,该分割作用于图像的像素上。换句话说,语义分割即将图像中的每个像素标注为对应的类别。对一张人脸图像进行人脸解析以后,可以得到n(语义类别分类数+1)类标。
3 结合基于特征的反投影方法以及人脸语义分割的方法
本文算法的框架分为初步重建网络(Coarse Net)、精细编码网络(Fine SR Encoder)、人脸信息先验估计网络(Facial Prior Estimation Network)和精细解码网络(Fine Decoder SR Network),如图1所示。
3.1 初步重建网络
初步重建网络结构如图1 左上部分描述,该网络由一个卷积层、四个残差块构成,并且经过了两次反卷积。该模型的输入为16px 的低分辨率人脸图像,虚线框中给出了残差块的具体结构,即卷积层-Relu-卷积层,并且该生成网络的残差块与反卷积的层数分布为4-1-4-1。通过该网络的低分辨率人脸图像尺寸变成了原来图像的四倍,并且获得较清晰的人脸图像特征,有利于精细编码网络提取特征以及人脸先验信息的估计。初步重建网络中的卷积核大小为3*3,s大小为1,p大小为1,反卷积核大小为4*4,s大小为2,p大小为1。
3.2 精细编码网络
受迭代误差反馈思想的启发,精细编码网络结构引入一系列连续的上下投影单元。网络结构如图1 左中部分描述,该网络通过迭代上下采样,并通过上下投影的误差来指导重建获得更好的结果。上下投影单元如图2、图3所示。
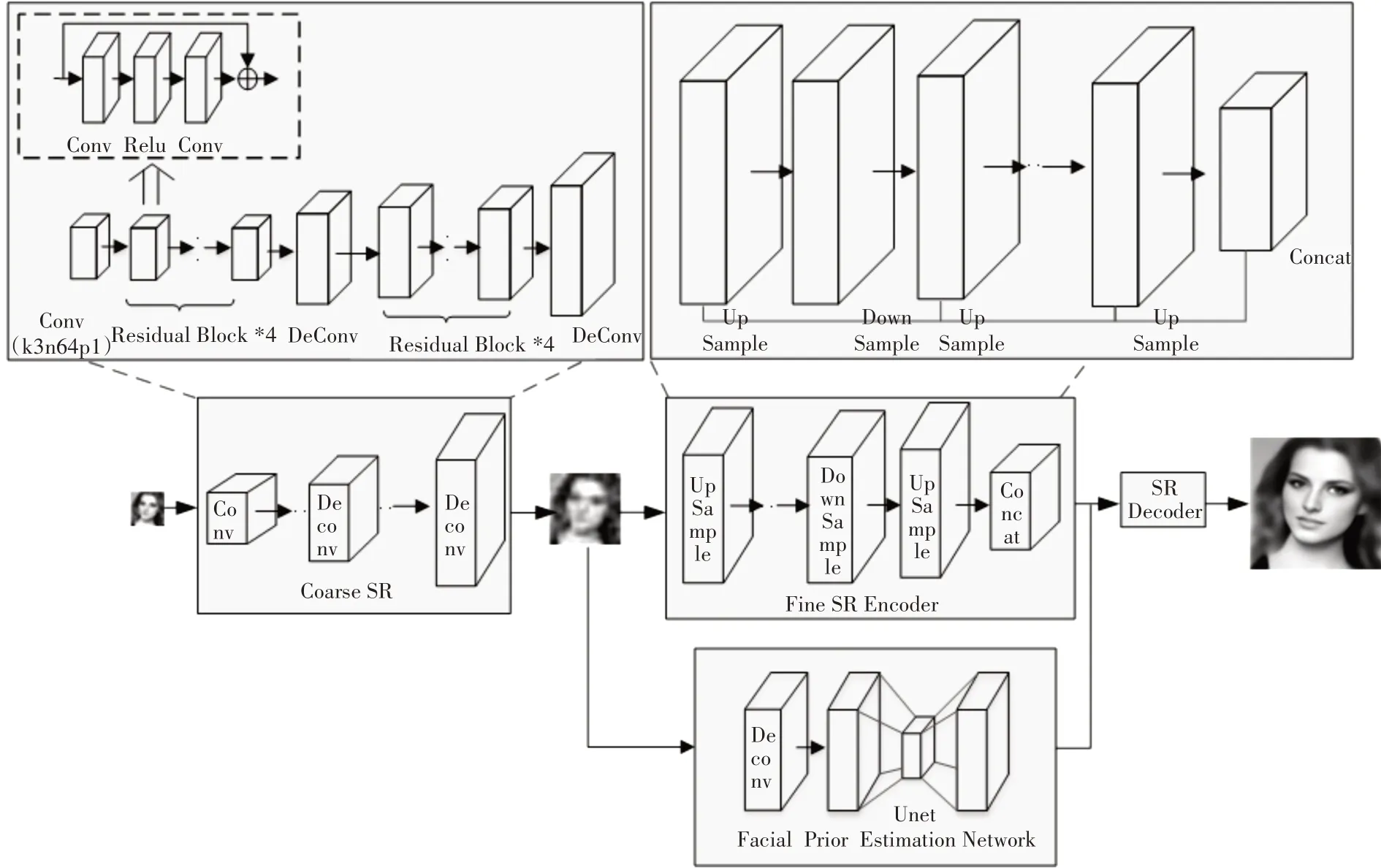
图1 网络结构
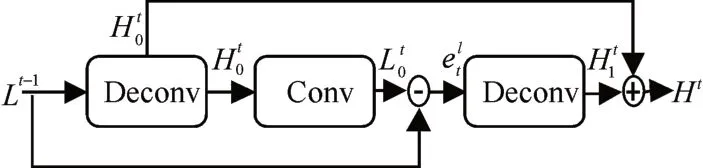
图2 上投影单元

图3 下投影单元
精细编码网络中包含连续的6 个上投影单元以及5个下投影单元,使用的卷积核大小为3*3,反卷积核大小为4*4。
3.3 人脸信息先验估计网络
本文首先对初步重建网络提取的特征进行反卷积操作,并在此基础上使用U-net 网络来估计人脸先验信息。该U-net 网络为左右对称结构,并且加入了Skip Connection。如图4 所示,U-net网络[15]的左侧首先对图像进行特征提取,其次右侧对输出特征进行上采样,并与左侧对称部分经过裁剪的特征进行维度拼接,输出n张heatmap图,最后使用1*1 的卷积核对n 张图像该像素位置进行分类,得到分割后的人脸图像。
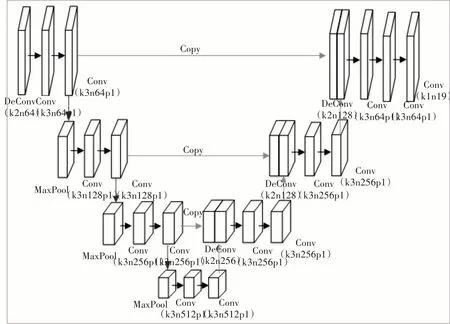
图4 人脸先验信息估计网络
该U-net 网络将人脸图像分为十九部分,包含背景、皮肤、鼻子、左眼、右眼、左眉、右眉、左耳、右耳等。图5 为人脸解析图,从左到右分别为标签图像(a),人脸解析图(b),以及人脸各部分的标签(c)。人脸先验信息的引入有助于恢复人脸的结构。

图5 人脸解析图
3.4 精细解码网络
该精细解码网络由3 个卷积层构成,卷积核大小为3*3。
3.5 损失函数

假设x为低分辨率输入图像,yg为初步重建得到图像,y为最终重建得到的高分辨率图像,p为人脸先验信息。
首先构造初步SR 网络得到粗略的超分辨率图像yg:

其次将yg输入到SR 编码器F及人脸先验估计网络P:

接着将yf和yp输入SR 解码器进行维度拼接,得到最终的重建图像y:

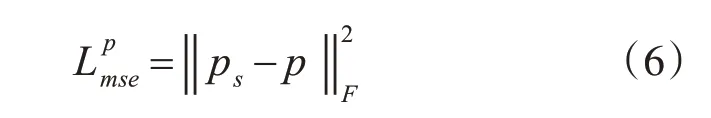
本文将重建得到的图像与标签图像,输入预训练得到的VGG19 网络模型中,并将中间层提取得到的特征用来表示Lvgg,其中Φ(ys)表示标签图像输入VGG19网络模型后提取到的特征,Φ(yg)表示重建得到的图像输入VGG19模型提取到的特征。
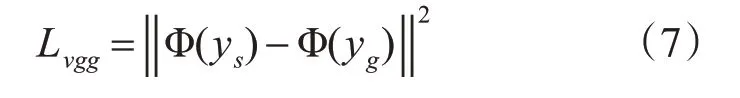
并且对参数w1=0.6、w2=0.3、w3=0.1 进行了经验设置。
4 实验结果及分析
本算法的实验环境为Ubuntu 16.04,使用的服务器为NVIDIA Tesla P100 GPU,开源框架为Pytorch。该模型采用随机梯度下降算法进行训练,初始学习率为10-4,训练迭代次数为600,训练时间为10h。
4.1 数据集
本文实验使用的数据集是CelebAMask-HQ。数据集中图像大小为1024*1024。使用Matlab 对原图像进行双三次插值操作将图像大小调整为128*128,得到标签图像。对标签图像进行双三次插值操作后图像大小调整为16*16,得到输入的低分辨率图像。本文使用3600 张图像进行训练,200张用于验证,500张图像进行测试。
CelabAMask-HQ 中还包含手工标注的19 类面部组件,如背景、面部皮肤、鼻子、眉毛、左眼、右眼等。
4.2 结果及分析
本实验实现了对极低分辨率的人脸图像(16px)进行8倍上采样。并且采用PSNR值及SSIM值来进行评估。该实验提供了与最先进的SR重建方法的比较,包括SRCNN 和DBPN,这些模型都使用相同的训练集CelebAMask-HQ 来进行训练。我们的模型DBFNet 与先前工作的比较如图6 所示。得益于面部先验知识、Vgg 损失函数以及人脸先验损失函数,我们的方法可产生相对较锐利的边缘和形状,以及更清晰的面部纹理。

图6 实验结果示例
4.3 重建模型方法比较
本文提供了DBFNet 与其他先进SR 重建方法的比较,如表1所示。
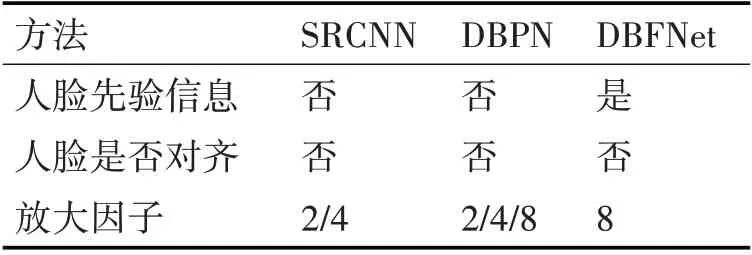
表1 重建方法对比表
4.4 损失函数的影响
损失函数对于重建的效果具有引导意义,我们将除人脸先验信息网络的其他部分称为Baseline,该实验比较了仅使用Baseline 的MSE 损失函数、使用Baseline的MSE损失函数以及VGG损失函数、使用Baseline 以及人脸信息先验估计网络的MSE 损失函数、同时使用两个MSE 损失函数以及一个VGG损失函数下PSNR与SSIM的值。
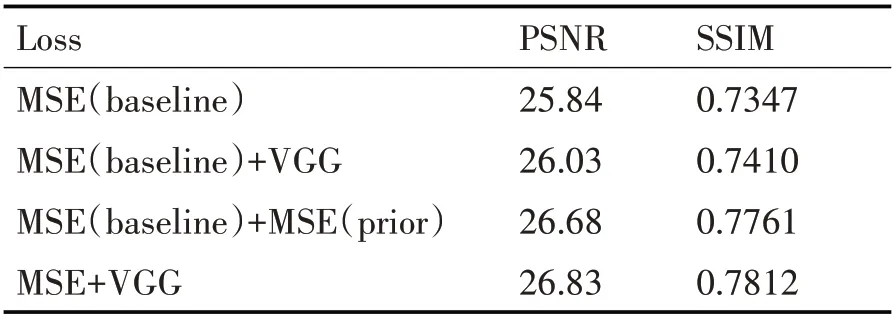
表2 损失函数对PSNR与SSIM值的影响
4.5 PSNR值
本实验提供了DBFNet 与现有技术的比较,表3 总结了不同方法在CelebAMask-HQ 数据集上的定量结果,加粗代表最优结果。

表3 CelebAMask-HQ数据集上PSNR/SSIM值
从表3 可知,当放大因子为8 时,本文方法的PSNR 和SSIM 值分别比BICUBIC 方法高出3.6db 和0.1334。相较于SRCNN方法,PSNR值和SSIM 值分别提升了3.24db 和0.1218。相较于DBPN 方法,PSNR 值和SSIM 值分别提升了1.25db 和0.0519。该实验证明,本文提出的结合基于特征的反投影方法以及人脸语义分割的方法在人脸超分辨率重建中的有效性。
4.6 面部先验知识的影响
为了验证面部先验知识对重建效果的影响,我们分别对Baseline Network 和DBFNet 进行训练,结果如图7 所示。由此可知,增加面部先验知识可以有效提高人脸重建的效果。
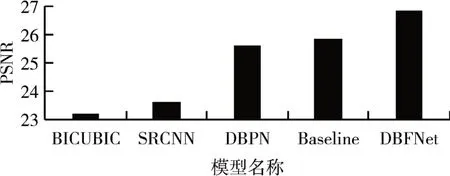
图7 面部先验知识对PSNR的影响
5 结语
针对极低分辨率人脸图像的8 倍重建,本文提出了一种结合基于特征的反投影方法以及人脸语义分割的方法。DBFNet的关键部分为精细编码网络、人脸信息先验估计网络以及人脸先验损失函数。以迭代误差反馈思想为主的精细编码网络有助于尽可能地减小重建后的图像与标签图像的误差。人脸信息先验估计网络以及人脸先验损失函数的引入,为网络引入更多的人脸特征,鼓励网络生成具有更清晰轮廓的人脸图像。本实验证明了人脸先验信息的引入,能够带来更好的人脸图像超分辨率重建的效果。
