基于大数据的UserBased 推荐算法的研究*
2022-02-16闫仁武
任 悦 闫仁武
(江苏科技大学计算机学院 镇江 212000)
1 引言
随着现代科技与网络的飞速发展,计算机技术及其相关知识已经广泛应用到各行各业中。科技的发展敲开了新世纪的大门,更多的购买方式渐渐被人们挖掘出来,例如亚马逊、淘票票、天猫以及京东等,推荐系统的推荐效果对电商的发展有着巨大的影响。为了让人们在电商平台上更有效地购买商品,大数据时代下的基于用户的推荐算法[1]发挥了至关重要的作用。
数据挖掘[2]是通过采集大量的数据,分析数据并进行对比,并将隐含在其中且又潜在有用的知识挖掘出来的过程。通过数据挖掘,我们可以减少对比较隐蔽性的知识的忽略,从而提高一些搜索的精准性。个性化推荐系统是推荐系统最为重要的研究方向,它可以通过对用户的需求及爱好等的分析,利用推荐算法[3]从海量数据中挖掘出用户感兴趣的项目,并将结果推荐给用户。推荐算法成为了个性化推荐系统中最为重要的部分,其一些属性会在推荐系统的性能方面有着直接或者间接的影响。
当今社会拥有着庞大的信息体,我们需要在有效的时间内,将信息进行筛选、过滤,提取出对用户需求有益的数据进行反馈。本文通过对协同过滤算法[4](Collaborative filtering algorithm)的介绍与研究,着重于对基于用户推荐算法(UserBased)的研究与改进,对原有的UserBased推荐算法进行提升,有效改善个性化推荐以及冷启动方面的问题。
2 相关介绍
2.1 协同过滤算法
传统的协同过滤主要任务是找到与目标对象相似的相邻用户,然后将相邻用户所喜欢的项目推荐给该用户。该过程不关注商品的具体内容,可以实现跨类别推荐,提高用户的惊喜度和用户满意度,能应用于复杂的非结构化的推荐系统中[5]。主要过程是构建用户项目评价数据模型;邻居相似性计算与最近邻形成;预测评分与产生推荐,即算法的输入、算法处理和算法的输出。
协同过滤推荐技术是推荐系统中最为常见的方法,类型主要有两种:基于用户的协同过滤和基于项目的协同过滤[6]。基于用户的算法是将和目标用户有相同兴趣爱好的用户所心仪的物品且目标用户没有购买的物品推荐给目标用户。基于项目的算法则是通过目标项目的相似项目集合预测用户对相似物品的喜欢程度。基于用户的协同过滤推荐算法的步骤有建立用户评分表,寻找相似用户,推荐物品,其所存在的问题如下。
1)冷启动问题
当一个项目第一次出现的时候,肯定没有用户对它做过详细评价,因此无法对该项目进行评分预测和推荐。同时,因为新物品出现时,用户评价少,所以准确性也较差[7]。
2)稀疏性问题
在庞大的数据量并且数据稀疏的状态下,首先最近邻用户集的存在比较难发现,其次计算相似性所损耗的费用也会很大。同时,信息常常会丢失,导致推荐效果降低[8]。
3)可扩展性问题
随着推荐系统用户和项目数量的不断增长,协同过滤推荐算法的计算量也会随之增长,导致系统的性能逐步下降,从而影响用户体验[9]。
2.2 数据预处理
数据预处理技术[10]是对数据信息进行提前处理,以此来提升数据挖掘的精准度,比如,在进行关键词检索时,数据预处理能够对数据库内的信息资源进行相关的排序处理,来提升检索精度和效率等。该技术一般经过数据审核、数据筛选、数据排序等,达到数据信息处理效率加强的效果。
预处理技术的工作原理一般包括对数据进行清理、集成、变换、归约等方面的技术处理,来提升后期数据检索的精准性。
1)数据清理通过填充缺失值,识别离群点,纠正数据中的不一致等技术进行[11]。
2)数据集成需要考虑许多问题,如冗余,常用的冗余分析法有皮尔逊积距系数、卡方检验、数值属性的协方差等[12]。
3)数据转换将数据转换为适合学习的形式,包括数据光滑、聚集、泛化、规范化等[13]。
4)数据归约技术是用来得到数据集的归约表示,在接近原始数据完整性的同时将数据集规模从维度到数量大大减小[14]。
3 基于UserBased推荐算法
3.1 传统UserBased推荐算法
基于用户的协同过滤算法(UserBased)是最早出现的协同过滤算法的基本形式,其工作流程分两步[15]。第一步是求出用户之间的相似度,第二步是根据用户之间的相似度找出与待推荐的用户最为相似的几个用户并根据他们的兴趣爱好向待推荐用户推荐其可能会感兴趣的商品。用户u和v之间的相似度的计算主要可以通过Jaccard 公式如式(1)和余弦相似度公式如式(2)得到。
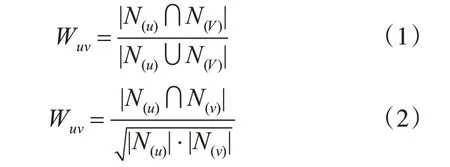
其中,N(k)为用户k 感兴趣的商品集,·为普通乘法。计算用户u 对商品i的兴趣度加权打分公式如式(3):
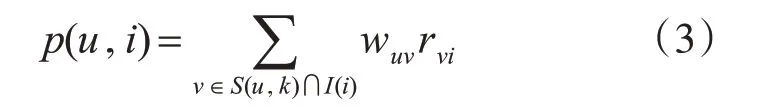
S(u,k)包含了和用户u兴趣最接近的k个用户集合,I(i)表示对商品i 有过打分行为的用户集合,Wuv表示计算出的用户u和用户v的兴趣相似度,rvi表示用户v 对商品i 打的分数。得到了用户u 对所有商品的感兴趣程度分数后,将分数最高的几个商品作为用户u 最有可能感兴趣的商品推荐给用户u。
3.2 UserBased推荐算法改进
本文采用余弦相似度算法对两两用户进行相似度的计算。首先要建立商品-用户倒排序如图1,图1中a、b、c、d 为用户,I1、I2、I3、I4、I5为商品,左边部分表示用户喜欢的商品,例如用户a 喜欢的商品是I1、I2、I4,右边部分表示喜爱每个物品的用户,例如喜爱商品I1的用户有a 和b;然后建立用户相似度矩阵W,如表1,表1 中行和列代表用户,内部表示两两用户共同喜欢的商品数量;最后计算用户相似度。
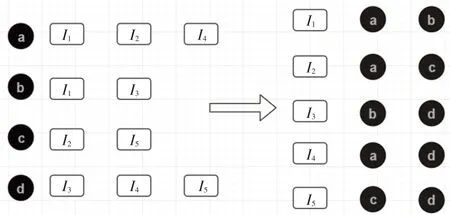
图1 物品-用户图

表1 用户相似矩阵W
遍历用户相似度矩阵中所有的两两用户,根据共同喜欢的商品数量,计算相似度,用到的公式为式(2)。比如a 和b 这两个用户,根据式(2)计算如下。
基于相似矩阵的基本运算:
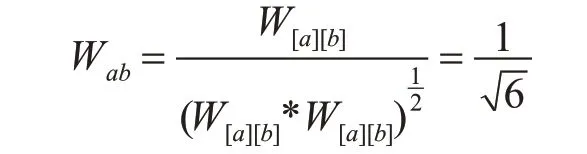
基于物品-用户图的解释:

为了改善冷启动问题的实时性和提高个性化推荐,对相似度的计算公式修改为如式(4):

其中,i 表示用户u 和v 都有过正反馈的商品集合,I(i)表示对商品i有过正反馈的用户数。该公式降低了用户u和v共同喜欢的物品中热门物品对他们相似度的影响。简言之,如果不同用户对冷门项目采取过同样的行为,则更能说明他们兴趣的相似度是比较高的。
3.3 UserBased改进推荐算法
伪代码是一种非正式的,类似于英语结构的,介于自然语言和计算机语言之间的文字和符号(包括数学符号)来描述算法。本文UserBased 改进算法的伪代码如下。

4 实验结果与分析
4.1 实验环境及数据
本文涉及的实验所在环境是一台配置为Intel(R)Core(TM)i5-8250U 处 理 器2.6GHz CP 和1.8GHz 的笔记本。本文实验选取的数据是使用Movielens 电影评分数据集合,利用其中1482 个用户对943 个物品的评分记录,每个用户至少评价过20 部电影,评分的取值位于整数1~5 之间,通过数值的高低来判断用户对该电影的偏爱程度。
4.2 实验结果评估标准
本文的实验结果评估方式主要是两方面,一个是精准度Precision,一个是召回率Recall。
精准度Precision 描述的最终推荐列表中有多少比例是发生过的用户-物品评分记录,如式(5):
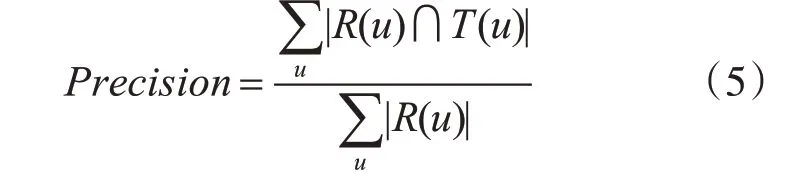
召回率Recall反映了有多少比例的用户-物品评分记录包含在最终的推荐列表中,如式(6):
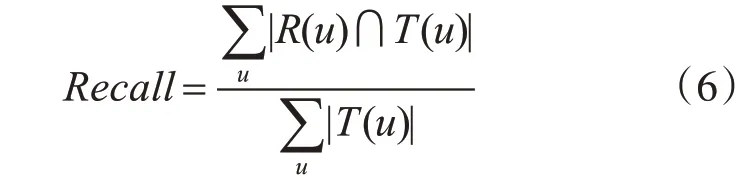
对于这两方面的评估标准,其中,对用户u 推荐的物品集合定为R(u),用户u喜欢的物品集合为T(u)。
4.3 实验结果分析
本文选取精准度和召回率作为推荐算法质量的衡量标准,那么,精准度和召回率的数值越高,说明推荐结果效果越好。从Movielens 电影评分数据集合中选取五组实验数据分别是50、200、400、800和943。五组数据中选四组为训练集,另一组为测试集,数据信息如表2。
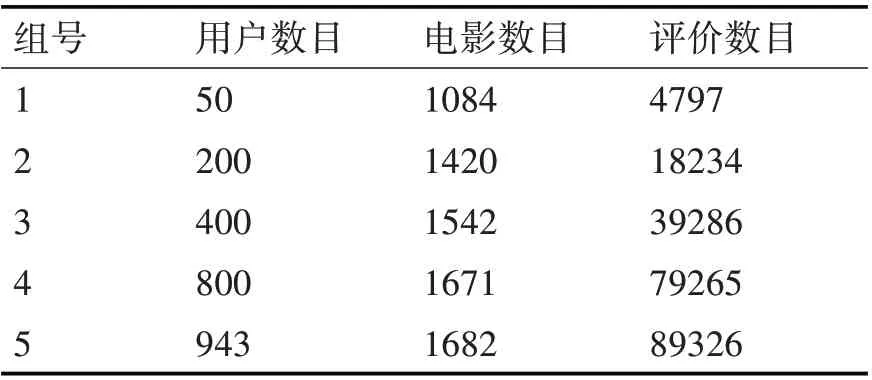
表2 五组数据信息
在五组实验数据下将本文提出的算法分别进行推荐,并计算精准度和召回率,最终结果如图2、图3所示。
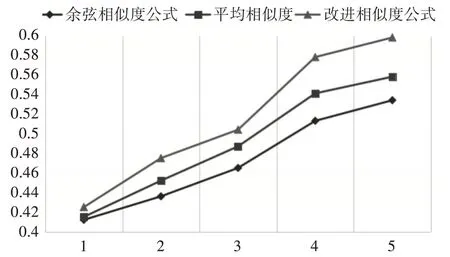
图2 精准度分布图
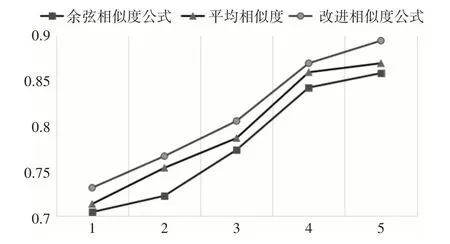
图3 召回率分布图
图2 中,纵轴为精准度值,横轴为五组实验数据的组号,根据折线图,我们很明显地会发现,本文提出对余弦公式的优化是可取的,精准度越高说明,算法的效果越好,也就是,为用户推荐的商品越精确。
图3 中,纵轴为召回率,横轴同样为五组实验数据的组号,根据折线图,很明显发现,召回率得到很好的提高,说明为用户推荐的商品集合R(u)与用户喜欢的商品集合T(u)的公共商品,在用户喜欢的集合T(u)中覆盖更广。
5 结语
传统的协同过滤推荐算法中存在着冷启动和个性化推荐两个问题,本文针对这两个问题进行深入的研究,并通过相关实验得到了改进方案后的优化实验结果。本文将UserBased 推荐算法稍作优化,增加了推荐结果的精准度,并根据数据集分组进行相关实验。通过实验得到,本文的改进算法可以优化推荐算法的冷启动和个性化推荐问题,从而提高大数据环境下的数据处理能力,给用户得到更好的使用体验。
