轻量级可形变卷积神经网络DPCNs研究
2022-02-15通信作者周录庆
赵 锞,贾 可(通信作者),李 航,周录庆
(成都信息工程大学计算机学院 四川 成都 610225)
0 引言
目前,基于深度学习的目标检测算法包括两阶段目标检测算法和单阶段目标检测算法两大类。两阶段目标检测算法首先对输入的图像进行候选区域的选择,然后对候选区域进行分类和定位。典型的两阶段目标检测算法有:R-CNN、Fast R-CNN、Mask R-CNN等。而单阶段目标检测算法没有候选区域选择这一阶段。典型的单阶段目标检算法有:YOLOv1、YOLOv2、SSD等。随着科技的发展,目标检测技术在生活中被广泛使用[1-2]。然而卷积神经网络由于其构建模块固定的几何结构天然地局限于建模的几何变换,导致检测效果不理想,而可形变卷积可以提高模型对发生形变物体的建模能力。黄凤琪等[3]提出一种基于可形变卷积的YOLO检测算法。张善文等[4]在VGG的基础上提出一种可形变VGG模型,应用于害虫检测。
虽然可形变卷积网络在检测精度上相较于普通卷积网络有很大提升,但是可形变卷积会产生巨大的计算开销,导致检测速度降低。本文提出了一种方法:采用可形变逐点卷积来提升检测速度。通过实验证明,可形变逐点卷积同样能够增强卷积核对感受野的适应能力,来适应不同形状和大小的几何形变。除此之外,结合使用深度卷积和可形变逐点卷积所带来的计算量相对较少,从而降低计算开销,提升检测速度。
1 本文方法
1.1 可形变逐点卷积
普通的卷积操作使用固定的卷积核,感受野范围也相对固定,因此难以适应目标的非规则几何形变。可形变卷积通过引入可学习的像素偏移量,使得卷积核不受固定位置的限制,可以进行伸缩变化,寻找最合适的感受野。但与普通卷积相比,可形变卷积引入了较高的额外计算量,主要用于其中所需的形变插值计算。针对以上问题,本文提出可形变逐点卷积,能有效地缩减计算量,降低计算消耗,在保持非规则感受野特性并获得精度提升的同时,有效提高检测速度。
在普通卷积中,设输入特征图为x,卷积核为w,x上任意一点P0的一个3×3采样区R={(-1,-1),(-1,0),…,(0,1),(1,1)},则P0点对应输出特征图y上的操作如式(1)所示:

其中Pn枚举了R中的每一个位置,最后对采样点进行加权运算。
在可形变卷积中,引入偏移量{ΔPn|n=1,2,…,N},N=|R|,将经过卷积计算得出的像素偏移量与原始像素位置相加后得到偏移后的位置,同时引入权重Δmn,那么同样位置P0点的操作变为如式(2)所示:
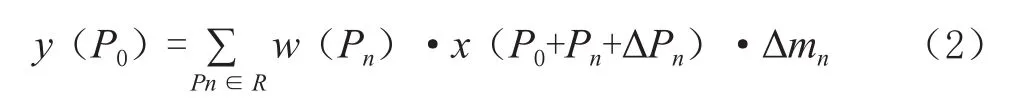
其中偏移量一般是小数,因此可形变卷积是针对不规则区域进行卷积计算,需要进行如式(3)所示的双线性插值:
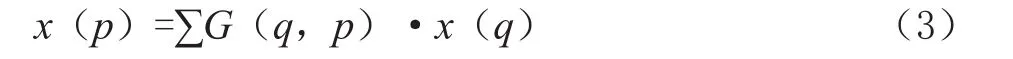
其中p=P0+Pn+ΔPn代表位置,q列举了输入特征图x中的点,G为二维双线性插值的核函数,可以被分为两个一维线性插值核函数如式(4)所示:

其中g(a,b)= max(0,1-|a-b|)。
与普通卷积式(1)相比,可形变卷积引入了较多的额外计算量,主要来自于式(2)中所含的双线性插值计算。对于典型的ResNet-101主干网络而言(如图1(a)所示),常见的方式是将多个残差块中的3×3卷积替换为可形变卷积,即图1(b)所示的结构。在此情况下,对每一次卷积滑窗的计算而言,3×3可形变卷积会进行3×3×C次双线性插值,其中C为该特征图的通道数,而每一次插值计算会进行4次乘加运算,那么总共会额外进行3×3×C×4次乘加运算,带来显著的速度损失。
由于可形变卷积引入的额外计算主要来自于对特征图进行插值,且计算量与卷积核大小呈二次方关系,因此在可形变逐点卷积中,将形变计算移动至残差块中的最后一个1×1卷积上进行,即如图1(c)所示。将其放置于残差块中的第一个1×1卷积之上也可以达到类似的效果,但研究人员实验证明放在最后效果会稍好。在可形变逐点卷积中,由于每次滑窗只需要对一个特征点进行采样插值,其产生的偏移量和进行双线性插值的次数更少,只会进行1×1×C次插值运算,总共进行1×1×C×4次乘加运算,因此其引入的额外计算量仅仅只有传统可形变卷积的1/9。此外1×1卷积核在特征图上进行滑窗卷积时不会因为特征被重复使用而产生额外的计算量。
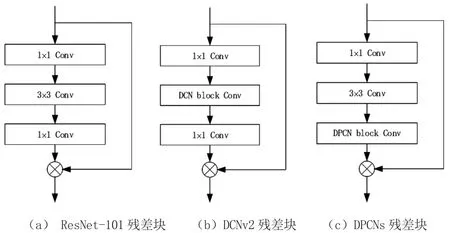
图1 不同类型残差块
将可形变卷积作用于1×1卷积,带来的问题在于每次只表达了一个特征点的整体偏移,是否能够带来足够的形变适应性。对此,研究人员认为,在可形变卷积网络中,可形变卷积一般并不是只用一次,而是在每一个残差块,或是每一尺度的卷积网络阶段中都会引入一个可形变卷积层。虽然每次的形变计算只作用于一个特征点上,但经过前后多次的偏移变换后,这些偏移量几乎不会重复或呈简单线性关系,因此仍然具有足够的形变适应性,能够计算出足够复杂的变形感受野,并因此获得比普通卷积更高的检测精度,研究人员的实验结果也证明了这一方式的有效性。
1.2 深度卷积与可形变逐点卷积
深度可分离卷积是一种常用的轻量级卷积神经网络结构,其主要特点是将普通卷积分解成深度卷积和逐点卷积。相对于普通卷积,这种方式可以在精度损失有限的情况下,减少计算量和参数量,从而提升检测速度。深度可分离卷积的矩阵分解优化方式,与本文所提出的可形变逐点卷积具有天然良好的结合性。通过将深度可分离卷积中的逐点卷积替换为可形变逐点卷积的方式,不仅可以有效保持轻量级卷积神经网络快速敏捷的优点,同时又能改善其性能并提高检测精度。
设定输入特征图为C×H×W,与N个C×k×k大小的卷积核进行卷积得到的输出特征大小为H×W×N,所产生的计算量为C×H×W×k×k。经过深度卷积的输出大小为C×H×W,产生的计算量为C×H×W×k×k。而经过逐点卷积产生的计算量为C×H×W×N。那么总体来说深度可分离卷积和普通卷积的总计算量之比如式(5)所示:

由于一般情况下N取值较大,如果采用3×3卷积,由式(5)可以得出深度可分离卷积相较于普通卷积可以降低大约9倍的计算量。
由于逐点卷积实际上就是卷积核大小为1×1的普通卷积,而可形变逐点卷积同样可以有效适应不规则物体,让感受野发生形变使得检测的精度得到提升。因此研究人员在深度可分离卷积中引入可形变逐点卷积替代普通的逐点卷积。通过实验证明,在速度损失有限的情况下,精度得到了进一步的提升。
2 实验
2.1 实验设置和数据集介绍
本文实验基于Pytorch深度学习框架,测试平台GPU型号为Nvidia GeForce RTX 2080 Ti,CPU型号为Intel Xeon E5-2678 v3。本文实验采用COCO数据集,包含91种类别、32.8万张图像和250万个标注[5]。
2.2 评价指标
本文实验主要使用平均精度(average precision,AP)和帧率(frames per second, FPS)来评价模型的有效性。另外FLOPs是指浮点运算数,param表示模型的参数量。
2.3 实验结果和分析
表1展示了选取Mask-RCNN作为基本检测框架,ResNet-50和ResNet-101分别作为主干网络,常规卷积神经网络、DCNv2以及本文提出的DPCNs在COCO数据集上的性能表现情况。

表1 三种方法检测性能对比
可以看出,以ResNet-101作为主干网络,使用可形变逐点卷积,虽然精度相比3×3可形变卷积有所下降,但是仍然高于普通3×3卷积1.7%,这在数值上说明使用可形变逐点卷积可以通过改变感受野的形状提升检测精度。可形变逐点卷积在FPS上比3×3可形变卷积有所提升,这从数值上表明可形变逐点卷积能有效地提升检测速度。由于整个计算过程除了插值计算还有其他卷积计算,所以可形变逐点卷积达不到减少大约9倍的计算量。在参数量上,可形变卷积最多,其余两个相对较少。图2(a)(b)则分别展示3×3可形变卷积和可形变逐点卷积的特征点感受野,可以看出可形变逐点卷积同样可以自适应的学习感受野的采样位置来符合物体的形状和大小,从而更有效的提取特征。

图2 特征点感受野
表2展示了选取Mask-RCNN作为基本检测框架,MobileNetv2和本文提出的dw-DPCNs在COCO数据集上的性能表现。可以看出,使用本文提出深度卷积结合可形变逐点卷积倒残差块的dw-DPCNs的精度达到了35.6%,相较于使用普通深度可分离卷积倒残差块的MobileNetv2的精度提升了1.3%。此外dw-DPCNs的FPS略微下降,FLOPs则略微上升。这是由于可形变逐点卷积需要进行插值计算,增加了额外的计算量,从而导致检测速度的下降。而这两种模型的参数量一致,能体现出本文提出的dw-DPCNs与MobileNetv2有相同轻量化的优点。

表2 两种方法检测性能对比
3 结语
本文针对使用3×3可形变卷积计算开销过大而导致检测速度变慢的问题,提出一种轻量级可形变卷积神经网络结构,使得模型在检测的速度上有所提升。通过实验证明,可形变逐点卷积相较于3×3可形变卷积同样可以自适应的学习感受野的采样位置来符合物体的形状和大小,从而更有效的提取特征,并且所产生的计算量更少,提高了检测的速度。寻找其他方法来减少可形变卷积的计算消耗是下一步继续研究的方向。
