基于数据同化的深水湖库水温中短期预报
2022-02-15孙博闻杨晰淯刘晓波高学平
孙博闻,杨晰淯,暴 柱,刘晓波,刘 畅,高学平
(1.天津大学 水利工程仿真与安全国家重点实验室,天津 300350;2.水利部海河水利委员会引滦工程管理局 海河流域滦河水质监测中心,河北 唐山 064309;3.中国水利水电科学研究院 水生态环境研究所,北京 100038)
1 研究背景
深水湖库通常存在季节性温度分层现象,水温不仅影响水体的运动规律,也影响着水体中生化反应以及水生生物的新陈代谢过程,包括溶解氧饱和度[1]、微生物和藻类生长[2]、沉积物向水体释放化学成分[3-5]以及鱼类对栖息地适宜性[2,6];由温度分层引起溶解氧等环境指标的分层还会诱发水环境水生态问题[7-8],进而威胁供水安全及下游生态系统健康。在气候变化与水库调控的共同影响下,上述变化更加趋于复杂[9-10],因此研究水温变化对湖库水质管理与生态安全十分必要。
当前对水库水温的研究大多关注其长期演变规律[11-13],中短期预报方面的研究相对较少。事实上,在未来10天这一时间尺度上预报湖库水温变化对管理者具有重要意义[14],如Weber等[15]利用水温-深度变化数据动态确定Grosse Dhuenn水库取水深度,在优化下泄水温同时还抑制了水库缺氧的发展;Baracchini等[16]在日内瓦湖的观测发现,强风驱动产生的剧烈涌升流使部分湖区的上层水温在2天内骤降10 ℃,直接影响下游的供水与河流生态。此外水温垂向分布还决定了湖库热分层强度,进而决定湖库的分层或混合状态[17]。秋季湖库由分层状态过渡到混合状态时,库底积累的营养物质和重金属在整个水体混合,此时冷雨等气象条件诱发的翻库过程则会使垂向混合在短时间内发生[18],这类由剖面水温骤变引发的水动力过程也会对湖库生态安全产生较大冲击。通过上述分析可见,中短期湖库水温预报能够在调控湖库下泄水温这类常规管理中发挥作用,还能在应对极端天气(如风暴)等诱发的翻库、涌升流这类威胁供水与生态安全的应急管理工作中提供决策支撑。
数学模型是湖库水环境管理与决策分析的重要工具,初始条件与模型参数的确定是提升模型预报准确性面临的挑战[19-20],随着实时观测数据的获取和传输得到飞速发展,使得将原型观测数据引入水环境预报,以提高预报精度成为可能[21]。数据同化融合观测数据与模型计算结果,综合考虑模型结构误差、边界条件误差和观测误差,对模型状态变量进行最优估计,实现了模型状态和参数不断更新[19,22],目前已应用于提高河流磷迁移估计和湖泊富营养化等方面的模拟精度[23-24]。集合卡尔曼滤波是应用最为广泛的数据同化算法,该方法能够提供状态量的均值及其相应的误差协方差,同时由于引入了集合的思想且不需要伴随或线性算子,因此具有适用于非线性系统、程序设计相对简单等特点[25]。
本文以引滦入津工程源头水库—大黑汀水库为研究对象,建立大黑汀水库的二维水动力模型,基于集合卡尔曼滤波算法构建可综合考虑模型参数、边界条件以及观测数据不确定性的湖库水温数据同化系统。系统利用未来水库调度数据与气象数据等作为预报条件,能够进行未来1~10 d内的湖库水温预报,高精度的水温中短期预报方法可以为深水湖库供水与生态安全提供理论与技术支撑。
2 研究方法
2.1 CE-QUAL-W2模型CE-QUAL-W2是一个考虑纵向和垂向的二维水动力水质模型(简称W2模型)[26],模型假设水体横向平均,适宜模拟河道型水库的水动力与水质变化,模型主要控制方程如下。
连续性方程:
(1)
X方向动量方程:
(2)
Z方向动量方程:
(3)
状态方程:
ρ=f(Tw,ΦTDS,ΦSS)
(4)
水面线方程:
(5)
质量/热量守恒方程:
(6)
式中:U与W为河道纵向与垂向流速,m/s;q为单宽流量,m3/s;B为网格宽度,m;g为重力加速度,m2/s;α为河底线与水平面夹角, °;η为水面线高程,m;Bη为水面宽度,m;ρ为密度,kg/m3;τxx与τxz与分别纵向流速的垂直梯度在x方向和z方向所产生的单位面积的剪切应力,Pa;P为大气压,kPa;f(Tw,ΦTDS,Φss)为考虑水温、总溶解固体、无机悬浮物的密度函数;h为沿河道底坡法线方向的水深,m;Φ为各组分浓度,g/m3;Dx为纵向扩散系数,m/s2;Dz为垂向扩散系数,m/s2;qΦ为入流组分浓度,g/(m3·s);SΦ为源汇项,g/(m3·s)。


图1 基于数据同化的湖库水温中短期预报工作流程
(7)
(8)
(9)
(10)
(11)
(12)
(13)
2.3 湖库水温中短期预报流程基于数据同化的湖库水温中短期预报包括四个阶段(图1):(1)建模阶段,根据获取的地形、气象等数据建立W2数学模型;(2)参数优化阶段,对影响W2水温模拟的敏感参数增加噪声扰动,运行N组W2模型,将水温模拟值与观测值输入EnKF算法,得到关键参数的优化结果,此阶段模拟时长不少于20 d;(3)变量同化阶段,在得到的关键参数后验分布基础上,为边界条件增加噪声扰动以体现其不确定性,再次运行N组W2模型,将水温模拟值与观测值二次输入EnKF算法,得到水温同化结果;(4)预报阶段,将同化结果作为本阶段的湖库水温初始条件与参数组合,在获取未来气象数据、水库入流条件以及调度计划作为预报边界条件后,运行CE-QUAL-W2模型实现对湖库水温在未来1~10 d的中短期预报。
3 研究实例
3.1 研究区域与数据来源大黑汀水库位于河北省唐山市迁西县滦河干流上,是引滦枢纽工程体系中的骨干水库工程,通过承接其上游来水与潘家口水库泄水为天津、唐山等地供水。水库总库容约3.37亿m3,为大Ⅱ型水库,库区回水长度约23 km,具有河道型水库狭长的地形特征(图2)。坝前水深可达25 m,全库表现出典型的季节性水温分层特征(图2(d))。水库温度分层直接影响着水体理化过程,是目前大黑汀水库供水所面临的难题之一[29]。对大坝下游而言,大黑汀水库下泄水温是控制河道水温的主要因素,进而影响着下游生态系统及耕种活动;对库区而言,水温分层诱发的库底缺氧环境使得沉积物中的污染物发生厌氧分解,加速水质恶化并威胁供水安全[30]。本文水温观测数据包括长期定点观测与定期走航观测(图2),定点观测位于大黑汀水库坝前500 m,在该断面1、7和13 m等深度布置自动水温记录仪,观测频率30 min/组;气象数据源自国家气象中心以及布设于水库的在线气象站;入库水温、流量及水库调度数据由水利部海河水利委员会引滦工程管理局提供。
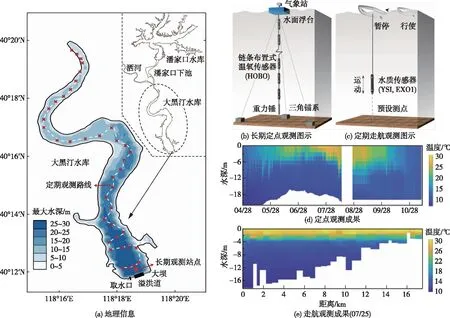
图2 大黑汀水库概况与2019年水温观测数据
3.2 大黑汀水库水动力模型本文将大黑汀水库纵向网格间距(DLX)设为300 m,垂向层厚度(H)设为1 m,模型底部高程设为103 m,顶部高程为133 m,包含虚拟网格共划分69个单元(segment)、最多33层(layer),考虑到大黑汀水库水面波动较小,因此设水面坡度(slope)为0。W2模型中影响水温计算的关键参数及取值列于表1。

表1 模型关键参数取值
对于垂向扩散系数W2模型要求用户选定计算模式后,由模型内部计算得出,本文选定的计算模式为W2N。率定过程中发现,AX和DX对水温结构影响较小,因此选取默认值1,这与李娟等[31]的研究结果一致。采用W2模型中的TERM算法计算水面热量交换,该算法考虑了日照短波与长波辐射的直接入射和反射、水面-大气反向热辐射、空气-水面热传导以及蒸发潜热几方面的影响。率定结果表明模型模拟的水动力过程与实测值符合较好,可用于模型计算。模型参数率定与验证过程参照姚嘉伟[32]研究成果,本文不再赘述。
3.3 数据同化方案设计合理的同化方案与参数设置是保证同化效果的前提,EnKF算法利用集合思想解决了实际应用中背景协方差矩阵估计和预报困难的问题,集合数越多,集合均值协方差与真值协方差越接近,但计算负荷会显著增加,集合数过少,则可能导致模型误差协方差估计错误[33]。为此本文设置7组集合数(3、10、20、50、100、200和400)进行数值试验,寻找可兼顾模拟精度与效率的集合数。数据同化通常包括只同化状态变量以及同时同化状态变量与模型参数两种模式,根据徐兴亚等[24]等的研究,后者表现通常优于前者,因此本文也采用该模式。参考相关研究,选择底部热交换系数(CBHE)、太阳辐射吸收系数(BETA)和风遮蔽系数(WSC)这三个对W2模型水温模拟最敏感参数[34-35],作为参数优化阶段考虑的模型参数。虽然数据同化方法能够在理论上实现模型模拟结果和观测数据的最佳融合,但这种“最佳”与模型的模拟误差协方差和观测误差协方差的精度密切相关,因此选择合适的模拟误差和观测误差对提高同化精度同样至关重要。参考李港等[36]研究,将观测误差与模拟误差分别设置为1%、10%、20%、30%,筛选观测误差和模拟误差的最优组合。
在此基础上,选择W2模型的入流流量以及气象数据中的太阳辐射热量和风速作为增加噪声扰动的边界条件,以坝前测点1、7和13 m水深处的水温观测为同化数据(观测频率12 h/次),对W2模型的参数和水温进行数据同化。首先将4月28日至5月9日的数据进行同化模拟,再自5月10日起开展基于数据同化结果和未来气象数据、水库入流条件以及调度计划作为预报边界条件的水温预报,每次预报未来1~10 d的水温,直至10月27日(预报流程详见图1)。采用均方根误差(RMSE)、一致性系数(IOA)和百分比偏差系数(PBIAS)评价数据同化系统的表现。IOA用来表征模拟值和观测值的一致性,IOA取值在0~1之间,越接近1表示二者之间的一致程度越高。PBIAS结果以百分比定量化给出模拟值比观测值整体被低估或高估的平均趋势[37],PBIAS为0表示模拟效果最佳,PBIAS>0表示模拟值倾向于低估,反之PBIAS<0表示模型倾向于高估。IOA和PBIAS的计算公式分别为:
(14)
(15)
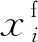
4 结果与分析
4.1 数据同化方案确定对坝前断面处不同集合数下的数据同化水温模拟结果与实测水温进行对比(图3),可以看出随着集合数增大RMSE逐渐减小,当集合数达到100后RMSE减小幅度大幅降低,同化结果趋于稳定。将观测误差与模拟误差分别设置为1%、10%、20%、30%共4种情况,图3展示了不同的误差组合下的同化结果。可以看出,当观测误差取1%,模型误差取10%、20%时,数据同化结果的RMSE均较小。综上,本文的数据同化方案为:集合数取100,模拟误差与观测误差分别取10%和1%。
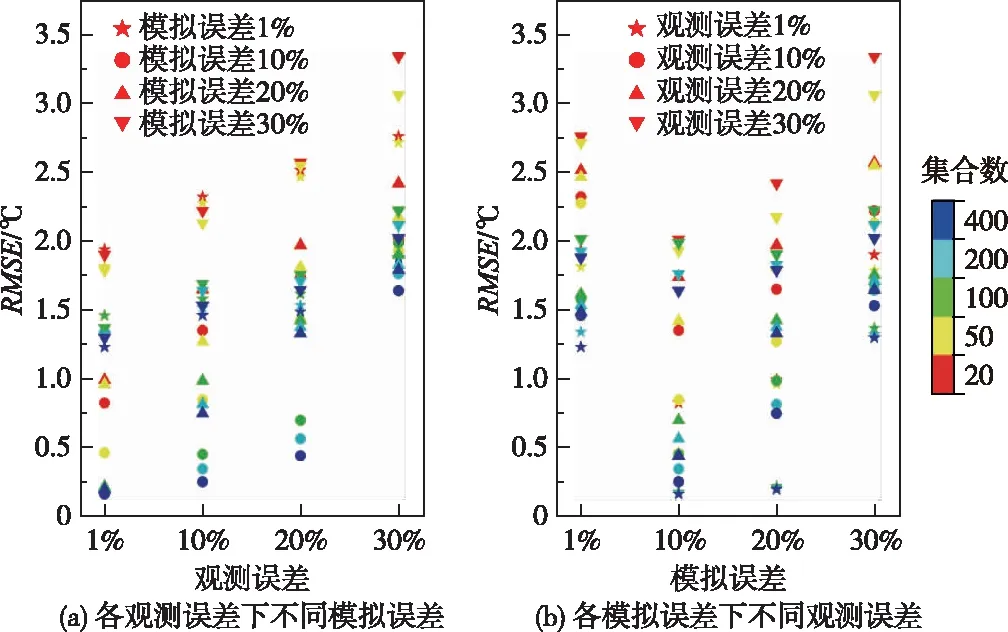
图3 不同同化方案模拟结果对比
4.2 数据同化效果图4为有无数据同化情况下,坝前500 m断面1、7和13 m水深处W2模型模拟结果与数据同化系统模拟结果相比实测水温的偏差值。可以看出,在经过EnKF算法对模型参数和状态变量同时进行更新后,数据同化系统在1、7和13 m水深处的平均模拟偏差分别为1.01、0.31和0.21 ℃,较无数据同化的模拟结果分别提升了68.8%、51.6%和41.2%,模拟精度显著提升。本文参考Zhang等[38]提出的方法,以垂向温度梯度1.5 ℃/m为阈值识别温跃层,当某日所有观测水温剖面全部出现温跃层时,认定进入分层期,否则为混合期。针对分层期(6月5日至10月3日)、混合期和全时段分别评价W2模型与数据同化系统的模拟结果,结果列于表2。可以看出,无论是分层期还是混合期,W2模型的均方根误差(RMSE)明显大于同化系统,最大可达到1.37 ℃;W2模型的一致性系数(IOA)相比1的偏差值也均大于同化系统;W2模型的百分比偏差系数(PBIAS)同样大于同化系统。可见数据同化方法可以有效的提升模型的模拟效果,为提高湖库水温的中短期预报精度奠定了基础。
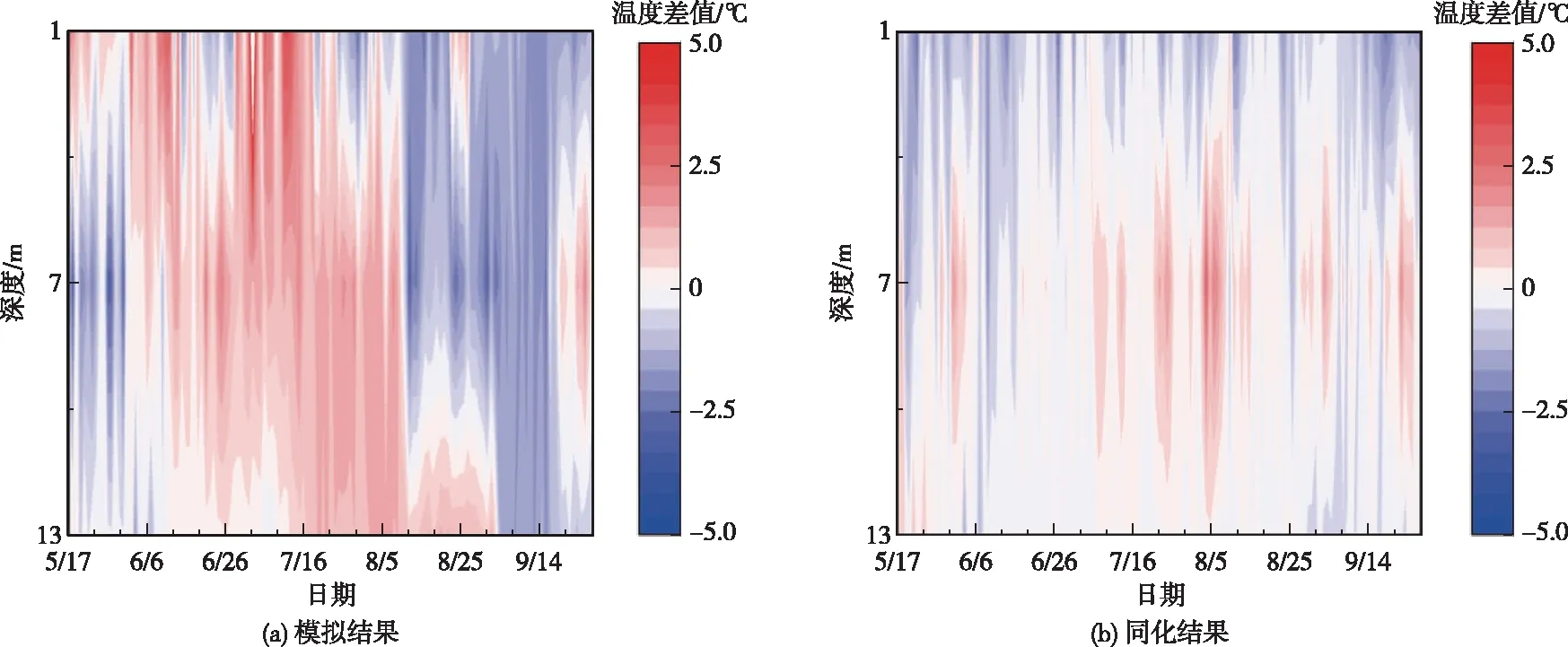
图4 W2模型模拟结果与数据同化系统模拟结果相比实测水温的偏差值(2019年)

表2 W2模型与数据同化系统的模拟结果评价
4.3 数据同化系统预报性能数据同化系统可为湖库水温预报提供可靠的模型参数与初始状态,在此基础上利用未来气象数据、水库入流条件以及调度计划作为预报边界条件,在考虑边界条件的不确定性前提下,运行W2模型进行湖库水温预报。为分析数据同化系统的水温预报性能,对分层期、混合期与全时段下各水深处未来1~10 d的水温预报结果进行评价,结果如图5所示。可以看出,在1与13 m处分层期的预报性能优于混合期,7 m处两阶段预报性能各有优劣。从RMSE指标来看,随着预报时段由1 d延长至10 d,预报误差由0.22~0.35 ℃增大至0.77~1.09 ℃,可见随着预报时段延长,不确定因素的累计效应对预报会产生一定影响。从IOA指标来看,分层期7 d预报期内各深度的IOA值均超过0.65,具有较好的一致性;预报期延长至10 d后,7 m处的IOA由0.78降至0.57,降幅远超1与13 m深度。近年来引滦工程常采用潘家口水库大流量调度抑制大黑汀水库缺氧发展[39],该现象可能与此种调度有关。从PBIAS指标来看,1和13 m处预报均倾向于高估,7 m处则倾向于低估,但高/低估均在±3%以内。从各统计指标结果可以看出,构建的数据同化系统能够较好的预报水库1~10 d内水温变化。
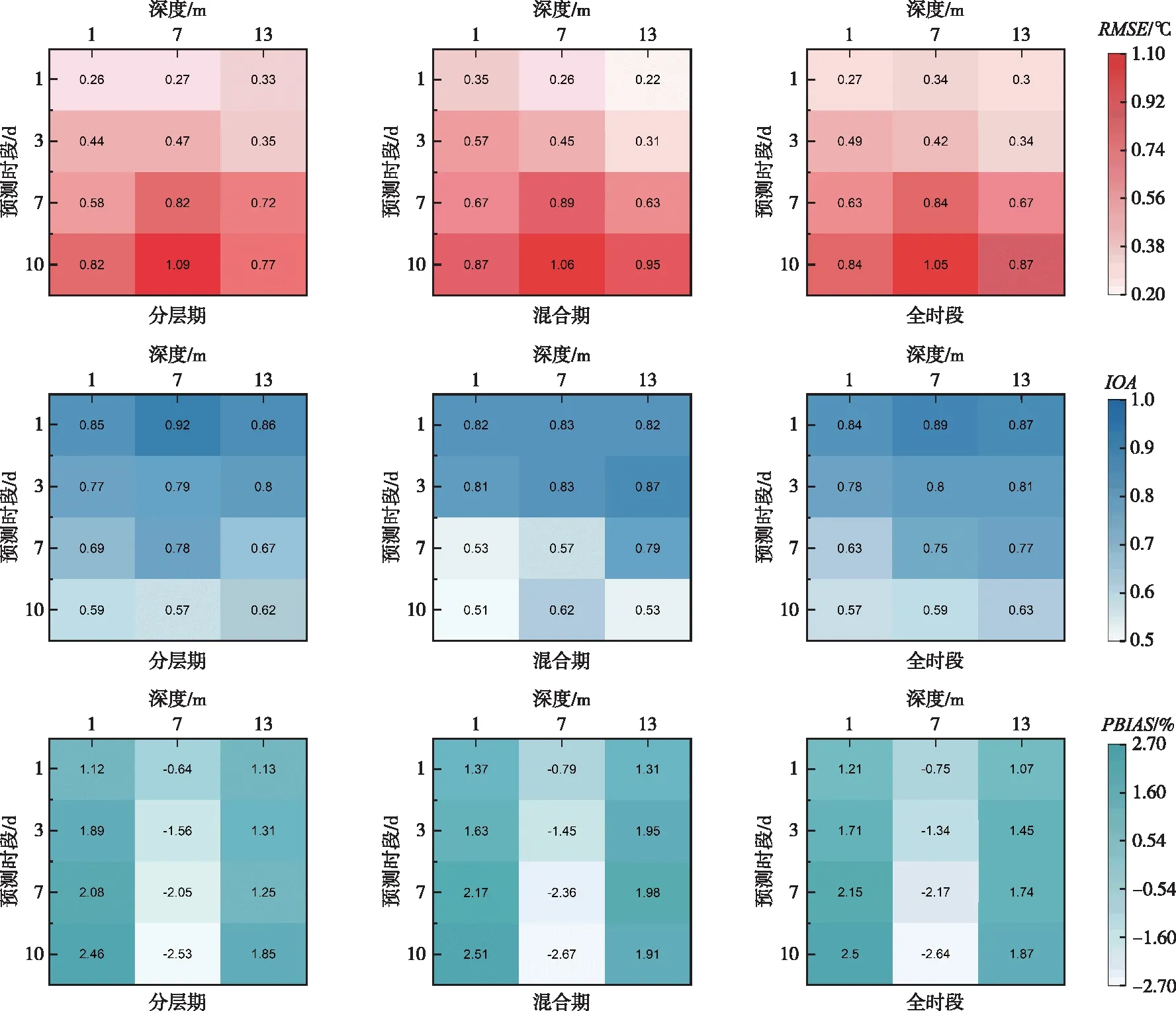
图5 不同预测时段水温预报效果对比
以10 d预报期为例,在整个模拟周期内选择湖库水温分层发展、稳定和减弱的三个典型时段进一步分析,对应时段分别5月10—19日、8月2—11日和10月18—27日,预报结果如图6所示,图6中虚线为95%预报置信区间。由图6(a)可以看出,热分层形成阶段受气象条件的影响,库区水温整体缓慢上升、表底温差逐渐增大,1与13 m的温差由4.3上升至8.6 ℃。沿水深方向来看,1 m处的预报误差始终保持在1.3 ℃以内,7和13 m处预报误差也始终保持在0.8和0.3 ℃以内。7和13 m处水温受气象条件影响较小,受入流条件和水库取水等的影响较大,5月18日预报得到的水温上升现象即由水库取水所致,这也表明同化预报系统能够较好的预报湖库调度对水库水温的影响。由图6(b)可以看出,此时水库热分层已完全形成,入库水温和气温均维持在全年的较高水平,整体而言7和13 m的预报精度依然高于1m。数据同化系统预报出了8月6日受短期强降雨和降温引起的水库在1和7 m处1.6~2.3 ℃的降温过程,13 m处水温波动不大。由图6(c)可以看出,水库水温整体逐渐降低且1和7 m处水温已基本相等,此时较弱的热分层使10月24日时在大风降温驱动下,水库可能产生较强的垂向掺混,发生“翻库”等危害供水安全事件的风险较大,在运行管理中值得关注。整体而言,数据同化系统在受气象条件及水库调度等内外部因素影响下,能够在10 d的预报期内维持较高准确性,为湖库调度管理提供依据。
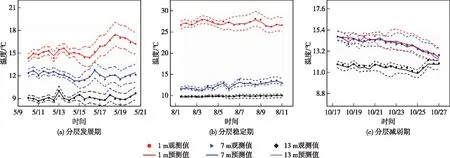
图6 2019年3个典型时段未来10 d水库水温预报结果
5 讨论
5.1 观测数据密度的影响观测数据在数据同化过程中扮演着关键作用,观测数据的密度与同化模型的预报精度息息相关。但较高的观测频次往往需要投入更多的设备成本,此外由于设备、通讯等软硬件限制,并非所有观测点都能保证有时间序列上的完整数据,因此有必要分析观测数据密度对数据同化效果的影响。在对本文预报期内9个时段进行10 d的同化预测中,分别设置3个深度的观测数据密度为12、24和36 h/个,图7为不同深度水温预报结果(RMSE)。
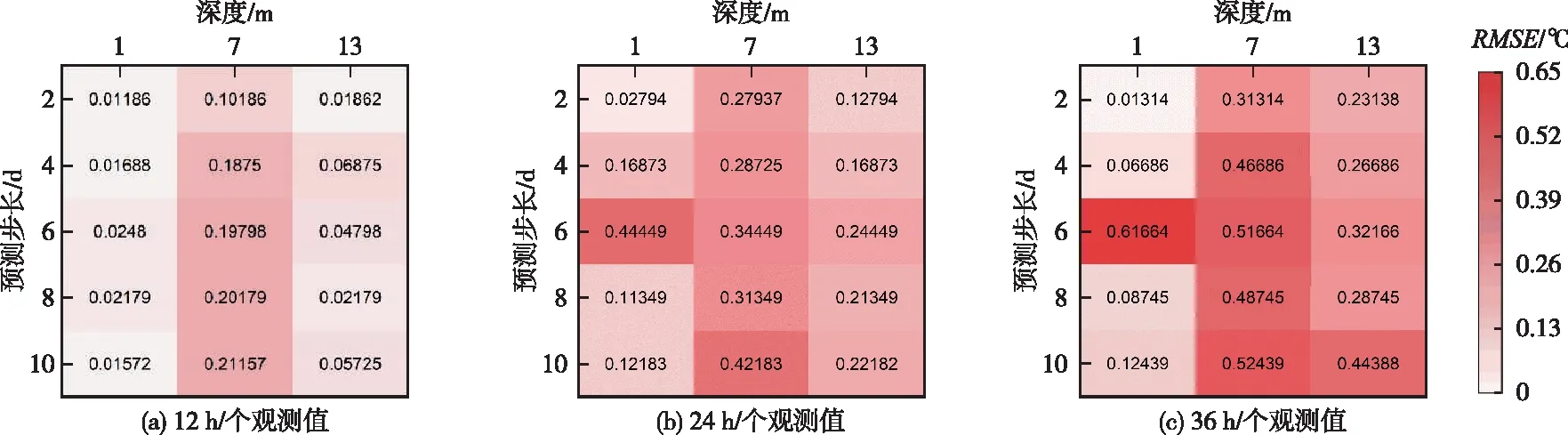
图7 不同观测数据密度下各深度预测RMSE结果对比
从图7可以看出,在本文的数据同化模型中,当预报点位与W2模型模拟时间一致的条件下,观测数据密度从12 h/个降低至36 h/个时,水温预报的精度逐渐降低。但观测数据密度并非越高越好,崔凯鹏等[40]的研究表明,过高的观测时间密度可能会产生信息冗余,Thomas等[14]的研究也发现由于设备故障产生的数据损失并未对同化表现产生持续影响。因此在兼顾效率和模型预测准确性的同时,确定合适的观测数据密度,并在模拟期内明确哪些时段的观测数据能带来最大价值,对选取观测资料有着重要意义。
5.2 同化方案设定的影响基于EnKF算法的同化方案设定中,集合数(N)、观测误差、模拟误差等的选取对模型精度有较大影响,对于上述指标选取均需要进行大量的模拟测试。集合数方面,Houtekamer等[41]的研究表明N在100这一量级对于数据同化研究是足够的;Evensen[42]的研究表明模型误差与N-1/2相关,当该值更接近于0后会有利于系统的误差控制。相关研究中N的取值通常在20~500之间[14,23,33],本文根据调整集合数后模型的RMSE表现确定N取值为100,结果表明该值能够较好地兼顾同化系统的模拟精度与计算效率。观测误差和模拟误差也会对模型预报精度有较大的影响,通常认为观测数据精度较高且更接近真实值,因此观测误差取值往往小于模拟误差[23,43]。从本文16组误差组合下的模拟结果看,当模拟误差一定时,RMSE随观测误差的增大而增大;当观测误差一定时,RMSE随模拟误差的增大而增大的趋势并不明显,刘卓等[23]认为观测误差对同化精度的影响较模拟误差大是产生这一现象的主要原因,因此设置较小的观测误差是合理的。
6 结论与展望
本文基于集合卡尔曼滤波算法与CE-QUAL-W2模型,构建可综合考虑模型参数、边界条件以及观测数据不确定性的湖库水温数据同化系统,将其应用于大黑汀水库进行1~10 d的中短期水温预报,主要结论包括:(1)同化方案设计对数据同化系统具有重要影响,当集合数为100、模拟误差和观测误差分别为10%和1%时,本文构建的同化系统能够兼顾较高的计算效率与模拟精度。(2)采用双重假设方法,经过两次集合卡尔曼滤波算法对W2模型的水温敏感参数和水温状态变量进行同步更新后,数据同化系统在1、7和13 m水深处的水温模拟准确性较无数据同化的模拟结果分别提升了68.8%、51.6%和41.2%,模拟精度显著提升。(3)利用数据同化系统进行水温预报时,随着预报期由1 d延长至10 d,不同水深的预报误差由0.22~0.35 ℃增大至0.77~1.09 ℃。无论水库处于分层期或混合期,数据同化系统均能够在预报期内的气象条件及水库调度等内外部因素驱动下维持较高准确性,为水库中短期调度管理提供理论支撑。此外本文是针对W2模型开展数据同化研究的首个案例,所构建的同化系统对于其他应用W2模型开展水动力水质模拟与预报的研究具有参考价值。
本项研究还能在以下四方面进行提升:(1)不确定性分析方面。本文的预报效果除了与模型参数和边界条件有关,还会受观测数据密度与同化方案的影响,因此系统分析上述要素对预报结果的不确定性很有必要。此外本文只选取了3个对W2模型水温模拟最敏感的参数进行数据同化,这也可能造成一定的不确定性低估。(2)观测数据获取方面。本文采用同一点位、不同深度的原位观测数据进行同化系统构建,但在对空间异质性较强的湖库进行预报时,增大观测数据的空间密度十分必要。布设多个观测站点,提升观测数据的空间密度较容易实现,但也意味着需要投入成倍的观测成本。遥感数据具有较强的空间代表性,利用该方法获取观测数据已有研究在开展[33,36],多源观测数据的融合将会进一步提升数据同化系统的预报性能。(3)从信息融合角度而言,数据同化与机器学习在数学原理上采用的均为贝叶斯估计策略[44],融合机器学习和与机理模型的水温预测研究已经逐渐开展[45],数据同化方法可能再次扮演重要角色。(4)数字孪生是当前水利工程领域的重要研究方向,建设数字孪生水利工程就是为了服务预报、预警、预演、预案四项基本功能,其中预报功能要实现对水安全要素的高精度短期预报和中期预测,本文也可为开展数字孪生水利工程的中短期预报研究提供思路和方法。
