简要案情的命名实体识别技术①
2022-02-15陈柱辉张明键张达为
陈柱辉,刘 新,张明键,张达为
1(湘潭大学 计算机学院·网络空间安全学院,湘潭 411105)
2(湖南警察学院 信息技术系,长沙 410138)
1 引言
简要案情是指警务人员在接到被害人或者目击者报案时,使用警务信息系统生成的简短并蕴含重要信息的文本序列,并便于警务人员管理和存储的警务记录.简要案情中的案发地点、涉案人员、涉案财产和涉案事件关键词等实体是整个案件的核心信息,通过这几类实体,警务人员可以迅速判断出案件的严重程度以及犯罪的类型.因此,对简要案情文本的深度挖掘是掌握案件始末和分析案情的有效手段之一.结合自然语言处理相关技术,围绕简要案情等警务文本的相关研究,可为智慧警务、案情问答等场景提供有效的支持与应用.
命名实体识别(named entity recognition,NER)是信息抽取和信息检索中一项重要的任务,其目的是识别出文本中表示命名实体的成分,并对其进行分类,也是信息提取过程中的关键技术,旨在从非结构化文本中抽取各类所需实体,为语料库的建设和知识图谱的搭建提供了技术支持[1,2].通识领域凭借其大量标注数据集,吸引众多研究人员争相投入其中,通识领域的命名实体识别技术因此迎来迅速的发展,然而,受限于警务领域的简要案情文本的开放,在简要案情命名实体识别上的研究呈一片空白.因此,本文先对小规模简要案情文本进行合理标注,提取的实体包括案发地点、涉案人员、涉案财产和涉案事件关键词4 个类别,为了提高简要案情文本中复杂的专业名词的识别率,本文对字符向量生成的方法进行了改进,提出RCBiLSTM-CRF 神经网络模型,通过Roberta 预训练模型增强训练语料的语义表示并根据上下文特征动态生成字向量,通过设计合理的卷积神经网络对字向量的局部重要特征进行提炼,解决了通过预训练模型带来的字符向量冗长的问题,通过减少模型的参数量进而增加了模型整体参数收敛的速度,在一定程度上弥补了标注数据集稀缺的缺陷.本文在湖南省省公安机关提供的简要案情数据集上做了大量的对比实验,本文提出的网络框架取得了比较理想的实体识别效果.
本文组织结构:第2 节介绍相关工作,包括对通识领域命名实体识别和特定领域命名实体识别的详细阐述;第3 节主要介绍本文设计的卷积神经网络,还对Roberta 预训练模型,BiLSTM 层和CRF 层进行详细的介绍;第4 节对实验数据集、模型参数设置、模型评估标准和实验结果与分析进行介绍;第5 节为结束语.
2 相关工作
近年来,深度学习技术在命名实体识别上的应用成为新的浪潮.深度学习方法为科研理论的验证提供了一种新的解决思路,最典型的深度学习模型为循环神经网络(RNN),卷积神经网络(CNN)的系列架构[3,4],本文将对通识领域命名实体识别跟特定领域命名实体识别的研究成果进行介绍.
2.1 通识领域命名实体识别
Huang 等人[5]提出了BiLSTM-CRF 模型,凭借巧妙设计的双向LSTM 结构,BiLSTM-CRF 模型可以有效地使用过去和未来的输入特性,该模型通过CRF 层可以使用句子级标记信息.BiLSTM-CRF 模型可以在POS、分块和NER 数据集上产生最先进(或接近)的准确性,并且具有较强的鲁棒性,对词嵌入的依赖性更小,可以实现准确的标注精度,而不需要借助于word的嵌入.
Zhang 等人[6]提出了Lattice LSTM 模型,该模型对输入字符序列以及所有与词典匹配的潜在单词进行编码,与基于字符的方法相比,Lattice LSTM 明确地利用了单词和单词序列信息,与基于词的方法相比,Lattice LSTM 不存在切分错误.Lattice LSTM 模型使用门控循环单元从一个句子中选择最相关的字符和单词,以获得更好的实体识别结果.Lattice 方法完全独立于分词,但由于可以在上下文中自由选择词典单词来消除歧义,因此在使用单词信息方面更加有效,在MSRA数据集中取得了93.18%的F1 值.
Gui 等人[7]提出了LR-CNN 模型,采取CNN 对字符特征进行编码,感受野大小为2 提取bi-gram 特征,堆叠多层获得multi-gram 信息,同时采取注意力机制融入词汇信息(word embed)以解决Lattice LSTM 模型[6]存在不能充分利用GPU 进行并行化的问题,LR-CNN最终相比于Lattice LSTM 快3.21 倍;LR-CNN 采取rethinking 机制增加feedback layer 来调整词汇信息的权值以解决Lattice LSTM 模型存在无法有效处理词汇信息冲突的问题.
Li 等人[8]提出了FLAT 模型,该模型将其lattice 结构转换成由跨度(spans)组成的平面结构,每个span 相当于一个字或者一个词在其原始lattice中的位置,得益于Transformer和position encoding,FLAT 可以充分利用lattice 信息,具有出色的并行化能力.FLAT 解决了在中文NER中,lattice 模型因为其复杂度和动态性问题,导致其无法很好的利用GPU,限制了其运行速度的问题.在数据集(OntoNotes、MSRA、Resume和Weibo)上,FLAT 在性能和效率方面均取得了很理想的效果.
2.2 特定领域命名实体识别
在社交领域,李源等人[9]为解决基于词粒度信息或者外部知识的中文命名实体识别方法存在中文分词(CWS)和溢出词(OOV)的问题,提出一种基于字符的使用位置编码和多种注意力的对抗学习模型,联合使用位置编码和多头注意力能够更好地捕获字序间的依赖关系,而使用空间注意力的判别器则能改善对外部知识的提取效果,该模型分别在Weibo2015 数据集和Weibo2017 数据集上进行了实验,实验结果中的F1 值分别为56.79%和60.62%.
在军事领域,李健龙等人[10]为了减少传统的命名实体识别需要人工制定特征的大量工作,通过无监督训练获得军事领域语料的分布式向量表示,采用双向LSTM 模型解决军事领域命名实体的识别问题,并且通过添加字词结合的输入向量和注意力机制对双向LSTM 网络模型进行扩展和改进,进而提高军事领域命名实体识别,提出的方法在军事领域数据集上的F1 值达到了87.38%.
在军用软件测试领域,韩鑫鑫等人[11]针对字词联合实体识别方法准确率不高的问题,进行字符级特征提取方法的改进,提出了CWA-BiLSTM-CRF 识别框架,该框架包含两部分:第一部分构建预训练的字词融合字典,将字词一起输入给双向长短期记忆网络进行训练,并加入注意力机制衡量词内各字对特征的语义贡献,提取出字符级特征;第二部分将字符级特征与词向量等特征进行拼接,输入给双向长短期记忆网络进行训练,再通过条件随机场解决标签结果序列不合理的问题,识别出文中的实体,所提出的框架在军用软件测试数据集上的F1 值达到了88.93%.
在医疗领域,宁尚明等人[12]针对电子病历实体的高密度分布以及实体间关系的交叉互联问题,提出一种基于多通道自注意力机制的“recurrent+transformer”神经网络架构,提升对电子病历专有文本特点的学习能力,同时显著降低模型整体复杂度,并且在该网络架构下提出带权学习的交叉熵损失函数以及基于权重的位置嵌入的辅助训练方法,该框架相继在2010 i2b2/VA及SemEval 2013 DDI 医学语料中进行验证,相较于传统自注意力机制,多通道自注意力机制的引入在模型整体F1 指标中最高实现10.67%的性能提升,在细粒度单项对比实验中,引入类别权重的损失函数在小类别样本中的F1 值最高提升近23.55%.
3 本文提出的网络框架
本文针对简要案情文本存在实体稠密分布、实体间相互嵌套以及实体简称的问题,对字符向量的生成方法进行了改进,提出了RC-BiLSTM-CRF 网络框架.RC-BiLSTM-CRF 整体算法框架如图1所示,主要分为输入模块、字符向量生成模块和输出模块,先对待标注文本进行数据清洗,用正则方法将待标注的文本的噪声信息过滤掉,有利于本文所提模型提取出重要特征信息;将清洗后的数据输入到字符向量生成模块,字符向量生成模块中首先通过Roberta 预训练模型将文本生成字符向量,经过本文合理设计的卷积层能够提取字符向量中的局部关键特征,并能将冗长的字符向量进行浓缩,紧随的激活层能够有效提高卷积层的特征学习能力和提升网络的性能;经过字符向量生成模块后,将字符向量输入到BiLSTM 层,BiLSTM 层对字符序列进行上下文特征以及字符间依赖性学习,通过Dropout 层随机删掉网络中一定比例的隐藏神经元,可以有效缓解模型过拟合情况,TimeDistributed 层将所有字符的向量维度进行约束,使得字符向量的维度等于实体标签数,最后通过CRF 层得到输入文本的标注序列.
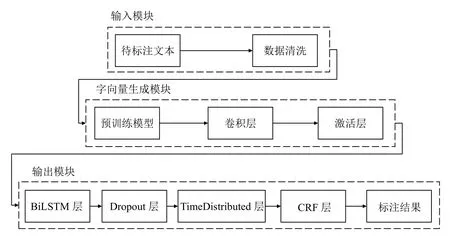
图1 本文提出的整体算法框架
本文提出的RC-BiLSTM-CRF 模型的整体结构如图2所示,网络结构包括一个Roberta 预训练层,一个CNN 层和BiLSTM-CRF 模型.下面将对RC-BiLSTMCRF 网络结构的各个部分进行详细阐述.
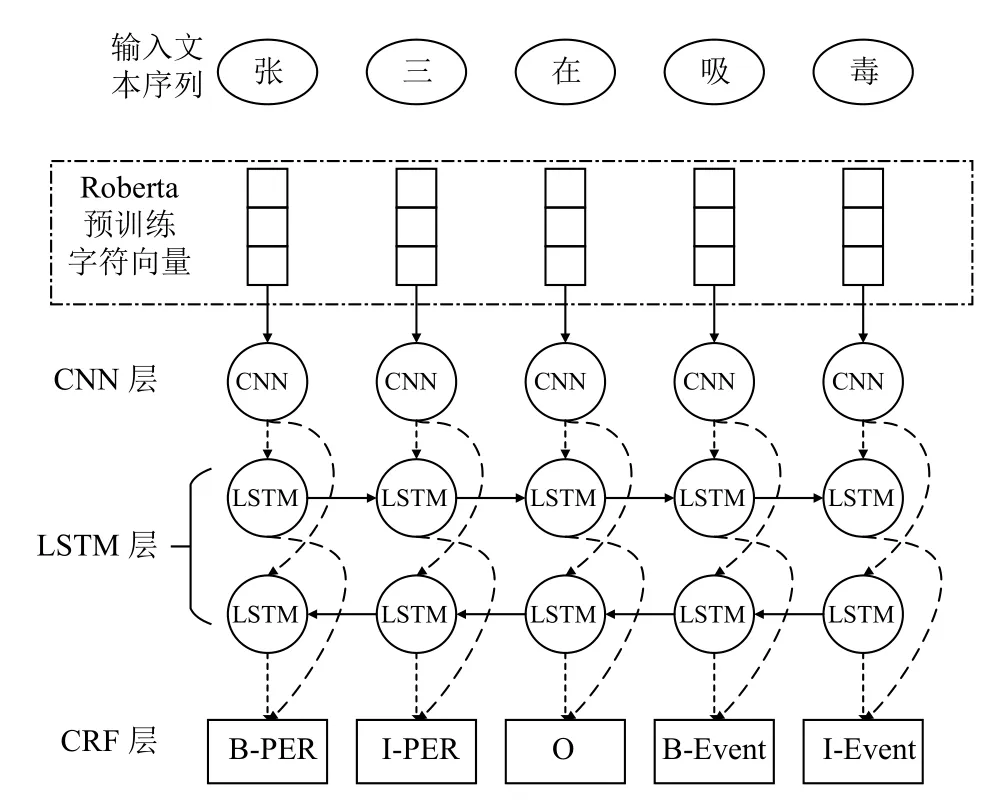
图2 模型整体结构
3.1 Roberta 预训练层
预训练模型本质上运用了迁移学习[13]的思想,利用大规模训练语料为预训练模型的参数进行训练,然后将训练好的模型应用到下游任务,避免了深度学习模型重新训练参数和减少了对标注数据的需求,缩短了字、词向量训练的耗时.Roberta 预训练模型是BERT (bidirectional encoder representations from transformers)预训练模型的改进模型,Liu 等人对BERT 预训练模型进行精细调参和调整训练集,训练得到的Roberta 模型在性能上相较于BERT 模型提升显著[14–16].Roberta 预训练模型充分考虑字符级、词语级、句字级和句间的关系特征,增强了字向量的语义表示,把这些学习到的语义知识通过迁移学习应用到数据规模和
标注量较少的简要案情的命名实体识别具体任务上,能使模型更好的挖掘简要案情文本的特征信息.
将字符序列chars=(char1,char2,…,charn),输入到Roberta 预训练模型中,Roberta 预训练模型通过在其他大规模语料上训练好的参数将chars中所有的字符生成向量,即char=(embedding1,embedding2,…,embedingm).相较于构建word2id 词典,通过id 匹配id2vec 词典的方法,预训练模型可以缩短字符向量的维度,有效解决文本特征稀疏问题,学习上下文信息来表征字词的多义性.
3.2 卷积神经网络层
卷积神经网络在本文所提出的字符向量生成方法中起着关键性作用,卷积神经网络层可以为Roberta 预训练模型生成的字符向量进一步提炼,去除冗长字向量中的噪声,提取出简短并蕴含局部重要特征信息的字符向量.卷积操作的计算公式如下所示:
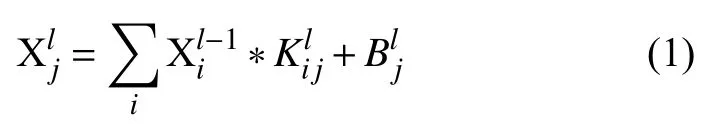
其中,* 表示卷积计算,Xlj表示第l层的第j个字符特征向量,Xlj-1表示第l-1 层的第j个字符特征向量,Kilj表示用来连接第l层的第i个字符特征向量和第j个字符特征向量的卷积核,Blj表示第l层的第j个字符特征向量的偏置量[17].
由于从Roberta 预训练模型中生成的字符向量是一维向量,于是本文使用一维卷积层对字符向量进行细粒度特征捕捉操作.为了合理选择卷积层的滤波器的数量,本文选取了10–40 个滤波器进行实验,实验参数中epochs 均为50,batch_size 均为16,卷积核大小均为3,实验结果如图3所示.
如图3所示,使用28 个滤波器的卷积层在本模型中的效果是最好的,所以本文针对简要案情命名实体识别设计了包含28 个滤波器,卷积核大小为3的卷积层.由于池化层是一个下采样的过程,在减小特征向量长度的同时,会使得部分案情实体特征信息丢失,从而降低下一步BiLSTM 进行上下文特征提取的性能,收敛速度变得缓慢,从而影响模型最终的实体标注的准确率,因此在本文的网络结构中取消了池化层的使用.经Roberta 预训练模型处理得到每个字符向量的维度为3072 维,通过综合考虑设计的包含28 个滤波器,卷积核大小为3的卷积层,对字符向量的特征进行提取,使得字符向量序列从100×3072 降维到100×28 维,解决了预训练模型带来的字符向量冗长的问题,框架参数量的减少促使模型整体参数收敛的速率提高了9.46%,同时F1 值提高了1.73%.
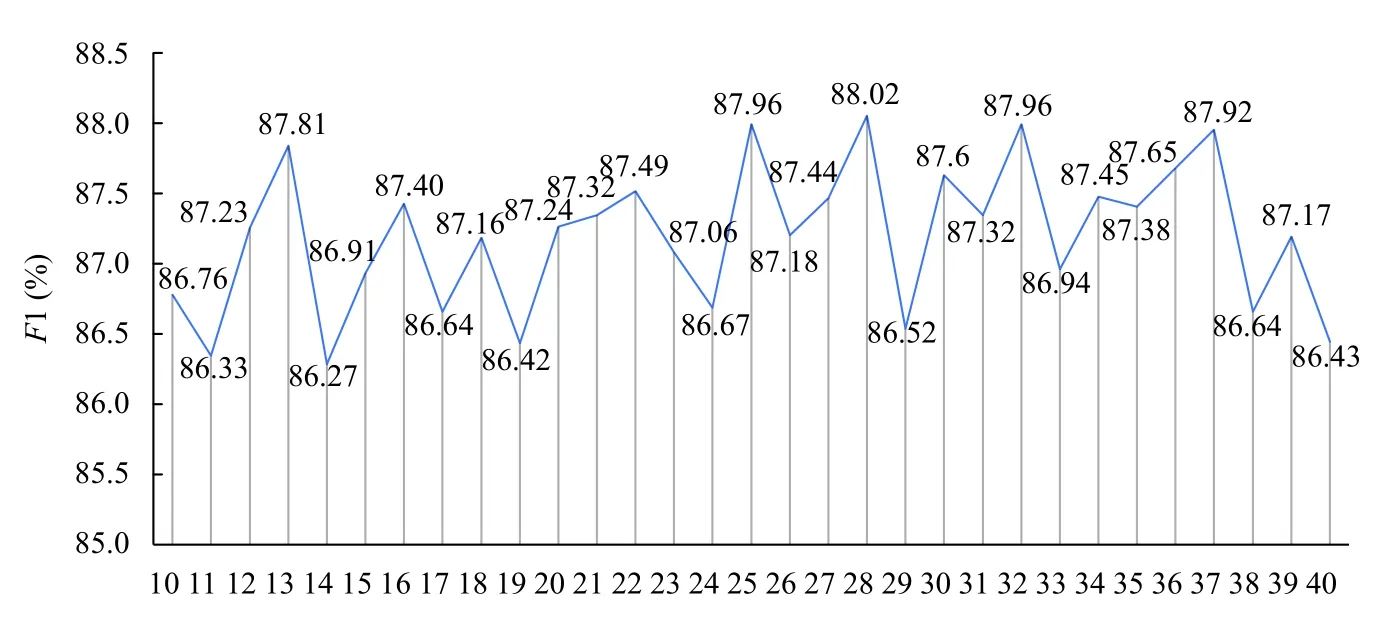
图3 滤波器实验对比
3.3 BiLSTM-CRF 模型
BiLSTM-CRF 模型拉开了命名实体识别深度学习时代的序幕,使得命名实体识别模型更加简洁高效,鲁棒性更强.本文针对简要案情本文构建基于BiLSTMCRF的实体识别模型,模型分为2 部分,接下来进行详细介绍.
3.3.1 BiLSTM 层
将已标注训练文本输入到上文提及的字符向量生成方法中,生成字符向量.将字符向量输入到BiLSTM层中.BiLSTM 包含了前向和后向的长短期记忆(LSTM),通过BiLSTM 可以更好地学习上下文信息以及捕捉双向的语义依赖,弥补了LSTM 不能向前编码信息的能力.在LSTM中,有两个状态向量C和h,其中C作为LSTM的内部状态向量,可以理解为LSTM的内存状态向量Memory,而h表示LSTM的输出向量.相对于基础的RNN 来说,LSTM 把内部Memory和输出分开为两个变量,同时利用3 个门控:输入门(imput gate)、遗忘门(forget gate)和输出门(output gate)来控制内部信息的流动,公式如式(2)–式(7)所示:
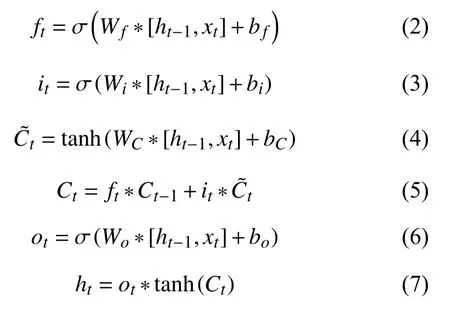
其中,W、b分别表示LSTM的隐藏层权重矩阵和偏置向量,ft,it,ot分别表示时间戳t的遗忘门、输入门和输出门,σ是Sigmoid 激活函数,t anh是tanh 激活函数,ht和Ct分 别表示时间戳t的输出和细胞单元状态.正向LSTM的输出值为反向LSTM的输出值为BiLSTM 则是将正向LSTM跟反向LSTM 所得的向量进行拼接,即
3.3.2 CRF 输出层
CRF 在整个模型中起着至关重要的作用,因为经过BiLSTM 层处理,得到的字符向量是字符对应的所有标签的概率,最终输出的结果是每个字符对应的最大概率值的标签,这样会导致输出的标签序列可能不符合命名实体识别规范.CRF的维特比算法在解码时候拥有较高的效率,通过CRF 层的约束,让输出标签序列符合实体规则.标签序列的最终标注由Emission-Score (发射状态矩阵)跟TransitionScore (转移分数)决定.当输入序列,标注序列,公式如式(8)和式(9)所示:
x=(x1,x2,···,xn)y=(y1,y2,···,yn)
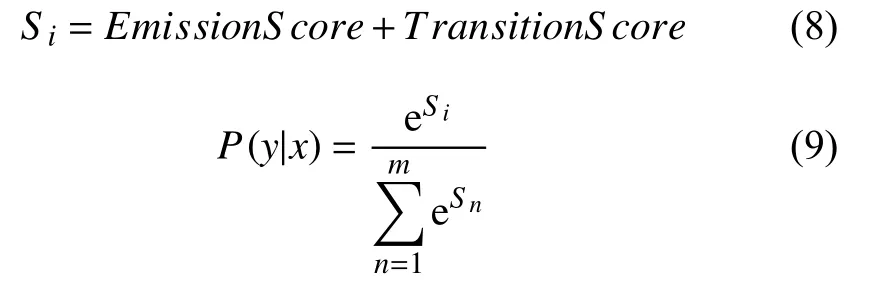
其中,EmissionS core表示BiLSTM 输出标签的分数,TransitionS core表示标签之间转移的分数,eSi表示当前标签序列分数,是所有标签序列的分数的总计,最大P(y|x) 值对应的y为序列x的正确标注序列.
4 实验及分析
4.1 实验数据集
本文所使用的数据集来自湖南省省公安机关的简要案情数据集(JW_data),数据的格式为tsv,本文先用正则方法将待清洗的数据集的噪声信息过滤掉,有利于本文模型提取出重要特征信息,清洗后的数据集中训练集占60%,测试集占20%,验证集占20%.数据统计信息如表1所示.

表1 数据实体统计
清洗后的简要案情数据集在标注平台doccano 进行人工标注,将案发地点、涉案人员、涉案财产和涉案事件关键词4 类实体作为本实验的标注实体,对简要案情数据集采用BIO 标注方式,B (Begin)对应字符序列中实体的起始位置,I (Intermediate)对应字符序列中实体的中间位置或者结束位置,O (Other)对应字符序列中非实体的字符,案发地点的标签包括(B-LOC,ILOC),涉案人员的标签包括(B-PER,I-PER),涉案财产的标签包括(B-Property,I-Property),涉案事件关键词的标签包括(B-Event,I-Event),非实体字符的标签为(O).实体统计如表2所示.
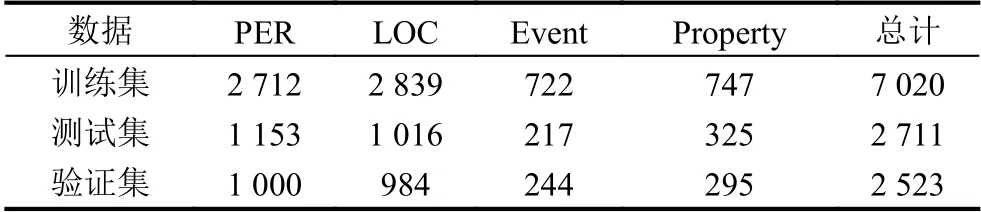
表2 数据实体标签统计
4.2 模型参数设置
本文选择Roberta 预训练模型生成简要案情数据集的字符向量,字符序列长度设置为100,所生成的字符向量维度设定为3072,所以输出字符向量序列的维度为100×3072.本文实验使用的Batch_size 设定为16,epochs 设定为50,学习率为0.001.卷积神经网络中卷积层的过滤器数量为28,kernel_size为3,padding为“same”,激活函数为ReLU 函数,卷积层的权重初始化方法为“glorot_uniform”,偏移初始化方法为“zeros”,输出的字符序列维度为100×28;双向长短期记忆的units 设定为128,故输出的字符序列维度为100×256,dropout为0.4.
4.3 模型评估标准
本文采用准确率(precision),召回率(recall),F1 值作为模型的评价标准,对简要案情数据的实体识别结果进行全方面的评价.精确度、召回率和F1 值的公式如式(10)和式(12)所示:

其中,T p表示实际为正被预测为正的实体数量,Fp表示实际为负但被预测为正的实体数量,Fn表示实际为正但被预测为负的实体的数量.
4.4 实验结果与分析
本文采用BiGRU、BiBRU-CRF、BiLSTM、BiLSTMCRF 及CNN-LSTM 作为基线模型与本文所提的模型进行对比,各模型的基本信息如下:
(1)BiGRU:采用BiGRU 提取特征并通过全连接层直接对字符向量序列进行标注的模型.
(2)BiBRU-CRF:采用BiGRU 提取特征并结合CRF 对输入字符向量序列进行标注的模型.
(3)BiLSTM:采用BiLSTM 提取上下文特征并通过全连接层直接对字符向量序列进行标注的模型.
(4)BiLSTM-CRF:采用BiLSTM 提取上下文特征并结合CRF 对输入字符向量序列进行标注的模型.
(5)CNN-LSTM:采用本文设计的卷积神经网络对字符
向量的局部特征进行捕捉,再通过LSTM 层对字符向量序列的正向特征进行学习,最后通过全连接层直接对字符向量序列进行标注的模型.
为验证本文所提模型加入Roberta 预训练模型的必要性,本文对所提出的模型和基线模型进行了验证,性能对比如表3所示.
从表3的结果可以看出以上6 种模型通过加入Roberta 预训练模型训练数据集的字符向量,准确率、召回率和F1 值都能大幅度提升,Roberta 预训练模型通过在大规模训练语料训练模型参数,一定程度上减少了对本文实验标注数据的依赖性,避免了本文实验数据较少导致模型效果不理想的情况.以上6 种模型,相较于未加入Roberta 预训练模型的框架,准确率提高了5.94%~10.75%,召回率提高了5.56%~9.36%,F1 值提高了5.78%~10.12%,由此可见在本文所提的模型中加入Roberta 预训练模型是必要的.
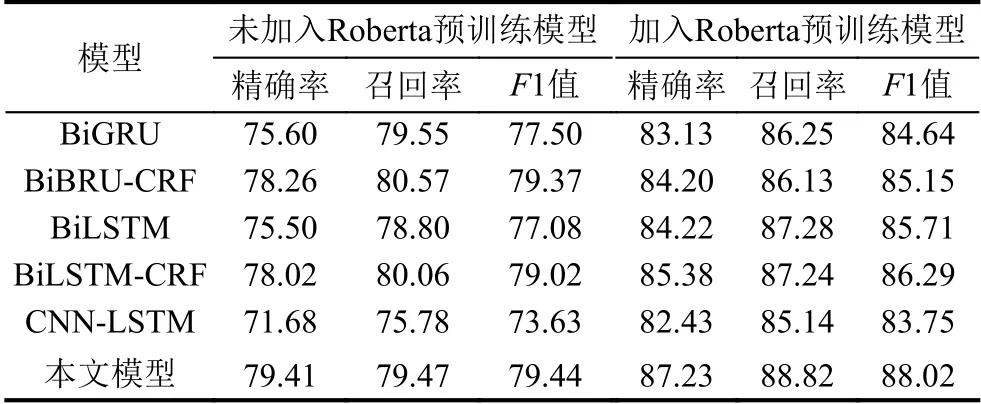
表3 对比实验结果(%)
通过表3,可知基于本文的简要案情数据,加入Roberta 预训练模型可以全方面提升模型的性能,于是本文将R-BiGRU、R-BiBRU-CRF、R-BiLSTM、RBiLSTM-CRF和R-CNN-LSTM 这5 种模型相互之间进行性能对比,模型性能对比如表4所示.
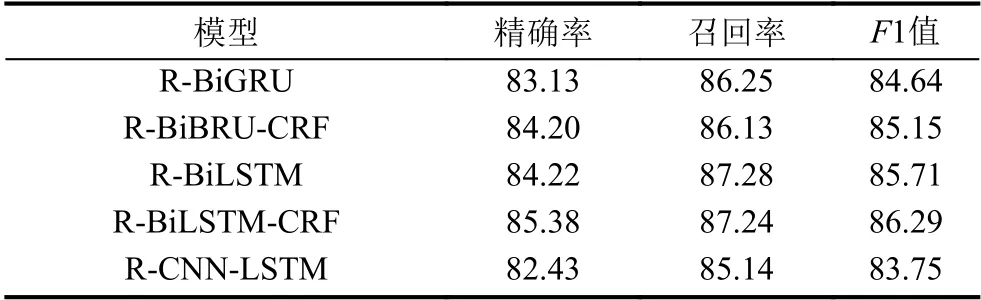
表4 模型性能对比(%)
由表4所示,在加入Roberta 预训练模型后,以上5 种模型在简要案情文本上的准确率、召回率和F1值上都表现出了不错的性能,其中R-BiLSTM-CRF 模型的precision 值为85.38%和F1 值为86.29%,相对于其它4 种模型来说有较大的领先优势.
为了验证本文设计的卷积神经网络能大幅度提升模型的效率跟模型的性能,将CNN-BiLSTM-CRF 模型与BiLSTM-CRF 进行实验对比,RC-BiLSTM-CRF 与加入Roberta 预训练模型的BiLSTM-CRF 模型(RBiLSTM-CRF 模型)进行实验对比,多方面的实验对比结果如表5所示.
由表5可知,CNN-BiLSTM-CRF 模型相较于BiLSTM-CRF 模型,准确率提高了1.39%,F1 值提高了0.42%,以及耗时减少了7.10%.RC-BiLSTM-CRF模型相较于R-BiLSTM-CRF 模型,准确率提高了1.85%,召回率提高了1.58%,F1 值提高了1.73%,以及耗时减少了9.46%.由此可见,本文所提出的卷积神经网络能大幅度提升模型的效率跟模型的性能.
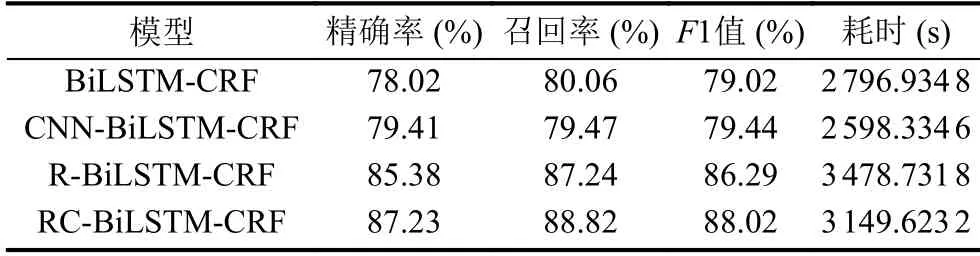
表5 多方面对比实验
综合表3–表5所述,本文针对简要案情的实体识别方法,与基线模型的对比之下,在准确率、召回率和F1值均表现出了突出的性能优势.得益于本文合理设计的卷积神经网络,使得本文所提出的RC-BiLSTMCRF 模型相较于R-BiLSTM-CRF 模型,在大幅度提高模型识别性能的同时,还降低了训练模型所耗费的时间.
5 结束语
本文主要研究了面向简要案情的命名实体识别任务,考虑到目前尚无针对该领域命名实体识别的研究,本文首次尝试对该方向进行了学习和探讨,构建了用于命名实体识别的简要案情文本的标注数据集,并在前人研究的基础之上提出了一种改进的识别框架(RCBiLSTM-CRF),通过改进的字符向量生成方法对简要案情数据的字符进行了有效的表示,生成字符向量,通过该方法中合理设计的卷积神经网络层对字符向量的局部细粒度特征进行提取,降低了字符向量维度,解决了预训练模型带来的字符向量冗长的问题,框架参数量的减少促使模型整体参数收敛的速率大幅度提高,为弥补一维卷积层在字符序列上下文特征和依赖关系提取的缺陷,在模型中引入BiLSTM 层,最后利用CRF 层对文本序列标签进行约束输出.本文提出的RC-BiLSTM-CRF 网络框架,相对于未加入本文设计的卷积神经网络的网络框架,在准确度、召回率和F1 值上分别提高了1.85%、1.58%和1.73%,总耗时减少了9.46%,与其它4 种模型相比较,在准确率、召回率和F1 值3 个评价标准上均取得了最好的效果.由于本实验是在标注量少的简要案情数据集上进行的,在接下来的工作中,可拓展简要案情的数据规模,使得模型的鲁棒性更好.
