多重索引加时间戳校正的科学卫星源包排序法①
2022-02-15马文臻邹自明黎建辉孙小涓
马文臻,邹自明,黎建辉,李 冰,石 涛,孙小涓
1(中国科学院 计算机网络信息中心,北京 100190)
2(中国科学院 国家空间科学中心,北京 100190)
3(中国科学院大学,北京 100049)
4(中国科学院 电子学研究所,北京 100190)
1 引言
在卫星地面数据处理的全部流程中,对正确性和时效性要求最高的一个环节就是数据预处理,其中最关键的技术就是载荷源包排序算法.卫星载荷获取的探测或者实验数据,以载荷源包的形式存储在星上存储器中,在记录数据之后需要尽快下行到地面执行预处理,去除传输层的结构,将载荷源包还原成载荷执行探测并记录下来的原始数据内容序列,并尽最大可能保障数据的正确性和完备性,以支持后续的科学研究.
从星上各载荷打源包、数管将各路源包统一组成信道传输帧、数传发射机传输数据、地面接收站接收数据、地面数据处理系统进行数据解帧、源包提取与正确性校验、源包时间码处理、源包排序到数据连续性及完备性验证[1],每一个步骤都可能发生异常.地面系统需要识别发生的各种异常,判断是否可以通过容错处理进行地面修复,确认是否可以还原得到源包顺序及内容都正确的、连续而完备的载荷科学数据源包序列[2].如果确认存在无法修复的异常,地面系统需要权衡缺失数据的科学重要性、星上存储是否已经覆盖、地面测控站是否有余量进行指令上行、地面接收站是否有余量进行增量接收等各种情况,尽快决定是否上行指令点播发生异常的载荷源包数据,以免在点播完成之前星上存储器中的数据被覆盖[3].
如果数据标定处理和数据反演处理不够理想,都可以事后重新进行处理和验证.只有预处理,如果星上数据发生错误或者缺失,是无法重新获取的.关键位置的一个源包的残缺或者误码,都可能导致科学实验结果失效或者观测事例不完备.例如,在量子科学实验卫星中,科学数据源包存储了星地量子密钥,地面实验数据的分析处理中,需要对密钥进行逐bit的基矢比对,一个bit 都不能错,否则该次实验就失效.所以,空间科学卫星对于载荷源包还原的正确性和完备性有着极为严苛的要求,这是不同于其它任何业务应用卫星的.其它的对地观测卫星、气象卫星等,都是允许一定的误码率,个别的源码错误或者缺失不影响整张图片的产出或者探测量的监视.
在航天领域,通用的卫星数传误码率指标为纠错后达到1e–5,这是按照bit 位计算的,换算为帧计数的异常率平均在几百分之一.在空间科学卫星数据中,误码率通常优于1e–6,那么每个卫星下行原始数据文件中发生帧计数异常的概率为几千分之一,也就是在每个文件中都会遇到几次帧计数错误.卫星上对源包赋予计数和时间码的时候也可能不定时发生异常.因此,排序依据的标志位发生异常情况下,如何能提高处理正确率,是非常值得研究的[4,5].
在与美国航天局(NASA)和欧空局(ESA)地面数据处理机构的学术交流活动中了解到,其空间科学卫星地面系统对卫星数传原始数据进行源包排序处理的整体文件正确率平均达92%左右.最终发生错误导致失效的源包占总源包的比例大概在百万分之一的级别.然而,对于空间科学卫星来说,也许失效的那几个源包,恰好是一个实验或者一次观测的关键数据,会导致一次实验或者观测的失败;也许失效的那几个源包,正好错过了百年难遇的重大发现.为了支持科学发现上可能的突破,地面数据处理领域值得付出持续不断的改进努力,向着100%的正确率去靠近.
2 问题背景与现状分析
2.1 星地数传数据的组织结构
空间科学卫星的数据组织与通信采用国际航天领域通用的CCSDS 标准.卫星数据有科学数据、载荷工程数据和平台工程数据3 大类,科学数据是载荷设备通过开展观测得到的原始观测数据或者开展实验得到的原始实验数据,载荷工程数据是表征载荷运行状态的工程参数,平台工程数据是表征卫星平台设备运行状态的工程参数.卫星平台及载荷的各设备使用应用过程标识符对卫星数据采集和传输过程中不同数据源设备进行区分,构成可变长度的面向应用的数据包,称为“源包”.遥测源包的格式如表1所示[6,7].

表1 CCSDS 遥测源包格式
同步码长度为16 bit,一般用‘E225’h (十六进制).每一种不同类型的源包依据应用过程标识符(APID)来区分.硬X 射线调制望远镜卫星(HXMT)有35 个APID,暗物质粒子探测卫星(DAMPE)有14 个APID,量子科学实验卫星(QUESS)有11 个APID,实践十号返回式科学实验卫星(SJ-10)有48 个APID.按照APID对飞行器上每个特有的源应用过程产生的源包分别进行包序列计数,长度14 bit,模16384.
副导头标志长度为1 bit,‘0’b (二进制)表示源包内没有副导头,‘1’b 表示源包内有副导头数据.空间科学卫星由于科学数据采集频率极高,源包序列计数在一次下行中就会回滚很多次,所以必须联合使用源包时间码来区分源包,副导头标志均为‘1’b.分组标志为长度为2 bit,标记该源包是独立源包还是分组源包,用来提供源包在组内位置的信息.副导头长度8 字节,自定义内容,目的是为任何辅助数据(如时间,内部数据域格式,航天器位置/姿态等)编入源包提供一种CCSDS定义的手段.在空间科学卫星中,副导头为时间码,其高2 字节为0,然后4 字节为秒计数,最后2 字节为毫秒计数.
E-PDU 数据域是可变长度的N字节,是应用过程在每个源内运行产生的真正的科学探测或科学实验信息.
卫星数管设备将众多遥测源包分成几大类,分别组成不同的虚拟信道数据单元(VCDU),每个VCDU包括主导头和数据域,VCDU 加上同步码就构成了数据传输帧(AOS frame).不同的虚拟信道的AOS 帧用虚拟信道标识符(virtual channel identifier,VCID)来区分.针对工程参数区回放数据、科学数据区回放数据和实时工程参数数据等,数据传输帧划分不同虚拟信道,以支持不同的数据应用.第一层的遥测源包的连续二进制码流截断填充到第二层AOS 传输帧的数据域部分.AOS 传输帧的格式如表2所示[8–10]:

表2 AOS 传输帧格式
数据处理系统解析“AOS 帧—遥测源包”的双层结构的过程如图1所示.首先依据虚拟信道标识符、虚拟信道帧计数、回放标志等进行信道区分,从一个或多个传输帧的数据域中解析得到有效的源包数据,然后解析源包结构,依据应用过程标识符、源包计数、包长进行分路处理,还原出每一类的遥测源包,对其数据内容进行有效性验证,之后依据时间码或源包计数进行源包排序,使其还原为星上探测的原始顺序[9–11].只有排序正确、计数连续的源包序列,其数据域的内容依次连接,才可以形成正确的用户数据单元(protocal data unit,PDU),也就是正确、完备的原始科学探测或实验数据.

图1 传输帧与源包组织结构的地面解析过程
2.2 传统的源包排序处理算法及问题
在遥感卫星、气象卫星等应用卫星的地面数据预处理工作中,源包排序算法是基于“虚拟信道帧计数+源包计数”进行的.其基本排序策略为先按照源包计数进行排序,如果源包计数相同,则按照VCDU 计数进行排序.这种排序策略并未考虑到计数溢出而重置的情况,也不支持同一轨接收过程中进行历史数据点播的操作[12–14].
在空间科学卫星数据处理领域,由于两层计数循环速度太快,重置频率高,单轨数据中常出现源包计数和VCDU 计数都相同的情况,所以“虚拟信道帧计数+源包计数”的双重计数排序法不满足空间科学卫星数据的处理需求.所以空间科学卫星在源包结构的副导头中都增加了“时间码”字段,扩展为“源包时间码+源包计数+虚拟信道帧计数”的源包排序处理策略,时间码相同的源包按照源包计数进行局部排序,虚拟信道帧计数和源包计数仅仅是作为局部变量来使用的.虚拟信道计数主要用来拼接跨两个虚拟信道的源包数据,使其按照下行顺序首尾衔接.由于存储空间有限,CCSDS为避免大量冗余,源包的时间码一般精确到秒,最多精确到毫秒,而很多观测数据的采集频率极高,最高情况下1 s 可以产生上万个源包,源包计数的深度为14 bit,计满16 384 条数据就会循环重新开始一个计数周期,所以源包计数主要用来区别时间码相同的源包的真实采集顺序[15–17].
这种“源包时间码+源包计数+虚拟信道帧计数”的通行方法对于星上数据和时间码都正常的情况下是没有问题的,但是如果帧计数、源包计数和时间码等关键索引信息由于各种异常发生错误而不能代表源包的真实采集顺序呢?
不同的空间科学卫星,由于载荷对数据采集记录时间的精度要求的不同,给星上时间系统的设计带来了不同的要求和实现难度.源包中的时间码,一般有两种来源,有的来源于GPS 设备,有的来源于自身时钟累计的相对秒数和毫秒数.如果载荷组源包的过程发生通讯或者软件异常,没有取到时间码,那么源包中时间码字段会变成默认值[17].如果时钟的秒和毫秒计数不完全同步,会导致时间错齿跳变.如果受到单粒子时间打翻存储器的某一位或者某几位的记录,那么时间码会发生无规则的跳变.源包计数和虚拟信道帧计数也都是如此,当接收设备故障、雨雪天气、突发信号干扰等原因造成的误码率超出可纠错范围时,当星上数传设备出现故障时,遭遇单粒子打翻某些bit 位时,当点播历史数据时,都可能出现重复、错误、乱序等异常情况,而且有时候多种异常情形会联合发生.这时候,“源包时间码+源包计数+虚拟信道帧计数”的算法就会发生排序错误,而且很难有一种万全的源包排序算法,能够保证在所有异常情况下都能百分百正确地实施源包排序.对于发生排序错误的源包,有的可以通过耗时漫长(可能几天到几个月)的人工分析去修复,有的没有得到彻底修复,造成个别科学数据源包失效.
纵观国内外的主流航天总体机构,都针对性地开展了卫星数据源包提取与排序技术的研究,尽量提高排序正确率,降低因各种时间码异常情况而导致的大量人工干预工作和对科学研究的负面影响.
3 多重索引加时间戳校正的源包排序算法
经过对我国空间科学先导专项一期发射的DAMPE、QUESS、HXMT和SJ-10 四颗卫星的星上数据组织结构与地面数据预处理过程进行研究,本文设计了一种把诸多异常情形综合考虑在内的“多重索引+时间戳校正”的源包排序方法.
3.1 多重索引构建
AOS 帧解析、源包提取与多重索引构建的整个处理过程如图2所示.

图2 多重索引构建
首先,构建信道级帧索引.获取数传原始数据文件后进行文件解析与校验,之后进行AOS 帧的完整性和有效性校验,然后进行虚拟信道区分、直传与回放数据的区分,按照虚拟信道的不同,形成每个信道的帧文件,分别进行帧的排序与连续性校验,提取帧索引表所需的信息,构建信道级的帧索引,如图3所示.
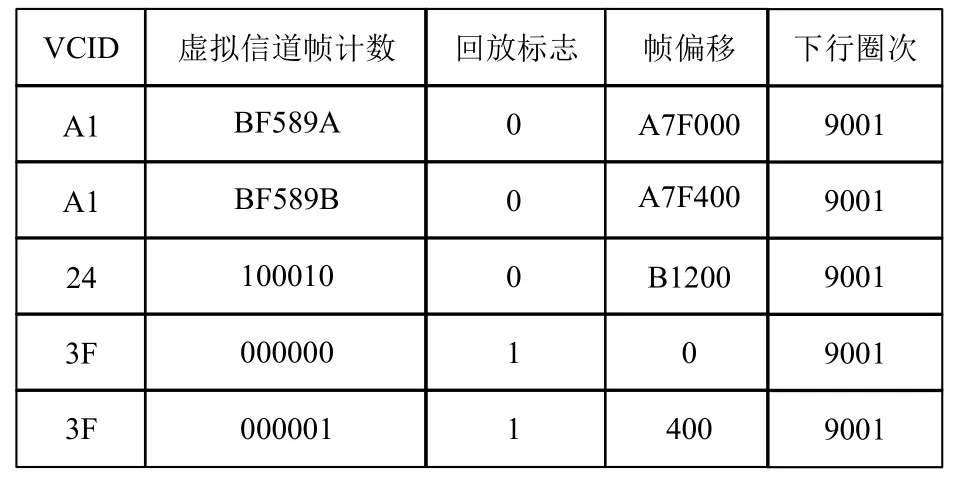
图3 帧索引表
帧索引信息不仅包含传输帧的虚拟信道标识符(VCID,十六进制)、虚拟信道帧计数(VCDU Count,十六进制),还包括直传回放标志(Flag,二进制0 或1)、帧B-PDU 数据域在原始数据文件中的偏移位置(VCDU Offset,十六进制字节数)、下行轨道圈次(Track No,十进制)等信息[18].
其次,构建应用过程级源包索引.对每个虚拟信道的帧文件中的帧进行数据的连续性校验,在校验正确的情况下从帧中提取源包数据域,按照不同的APID拼接形成完成的源包(其中,一个虚拟信道标识符VCID 对应一个或者多个应用过程标识符APID),并进行源包的有效性校验,通过校验的源包,将其信息解析后提取源包索引表所需的信息,构建应用过程级的源包索引,如图4所示.
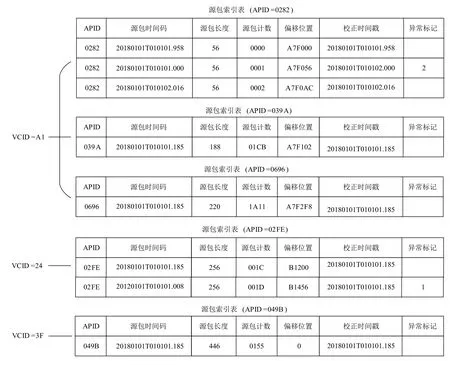
图4 源包索引表
源包索引信息不仅包括最重要的应用过程标识符(APID,十六进制)、源包时间码(packet time,转化为统一的时间格式“年月日T 时分秒.毫秒”)、源包计数(packet count,十六进制),还包括源包长度(packet length,十六进制字节数)和源包E-PDU 数据域在原始数据文件中的偏移位置(packet offset,十六进制字节数)等信息,还包括一个格外重要的字段,就是校正时间戳(corrected time stamp,格式与源包时间码相同),这个字段存放的是经过时间戳校正之后的源包时间码,本文提出的算法将主要依据这个校正时间戳进行源包排序,此外,还有异常标记(anomaly flag,十进制),代表不同的时间戳校正策略.
帧索引和源包索引中的信息按照一定规则组合起来,就构成了多重索引.多重索引与数据帧及源包中的相关字段一一对应,于是把对数据本身的处理转化成为对索引的操作,而索引的数据量相对于数据本身是非常小的,所以可以全部在内存中处理,避免了对数据本身进行处理而产生的大量内外存数据交换,提高数据源包排序处理的效率.
3.2 时间码提取与时间戳初标
针对不同卫星的不同源包,依据时间码来源与异常情况的不同,其时间码提取、时间戳初次标记、异常标记的策略也有所不同,可以配置不同的处理流程和参数.
以HXMT 卫星的几个典型APID为例进行说明,源包时间码提取与时间戳初标的过程如图5所示.高能望远镜(HE)的科学和工程参数源包时间码来自于GPS 设备,因此需要判断GPS 设备是否处于非定位状态来确定时间码的正确性,当其处于正常的定位状态时,时间戳初始标记为GPS的时间码,在处于非定位状态时,时间戳初始标记为0,同时进行异常标记.中能望远镜(ME)的源包时间来自于UTC 事例,而且多组FPGA 源包与UTC 事例源包轮流排列,因此需要判断FPGA 分组编号的连续性并查找对应的UTC 事例,时间戳初始标记为UTC 事例中的时间码,存在异常时时间戳初始标记为0.平台工程数据由一系列不同类别的源包首位相接组成,需要检查源包组的完整性,如果恰好有不完整的源包组,则与之前20 轨数传下行数据的不完整缓存进行拼接,内容完整的源包从GPS 定位数据包或者时间数据包中获取时间码.
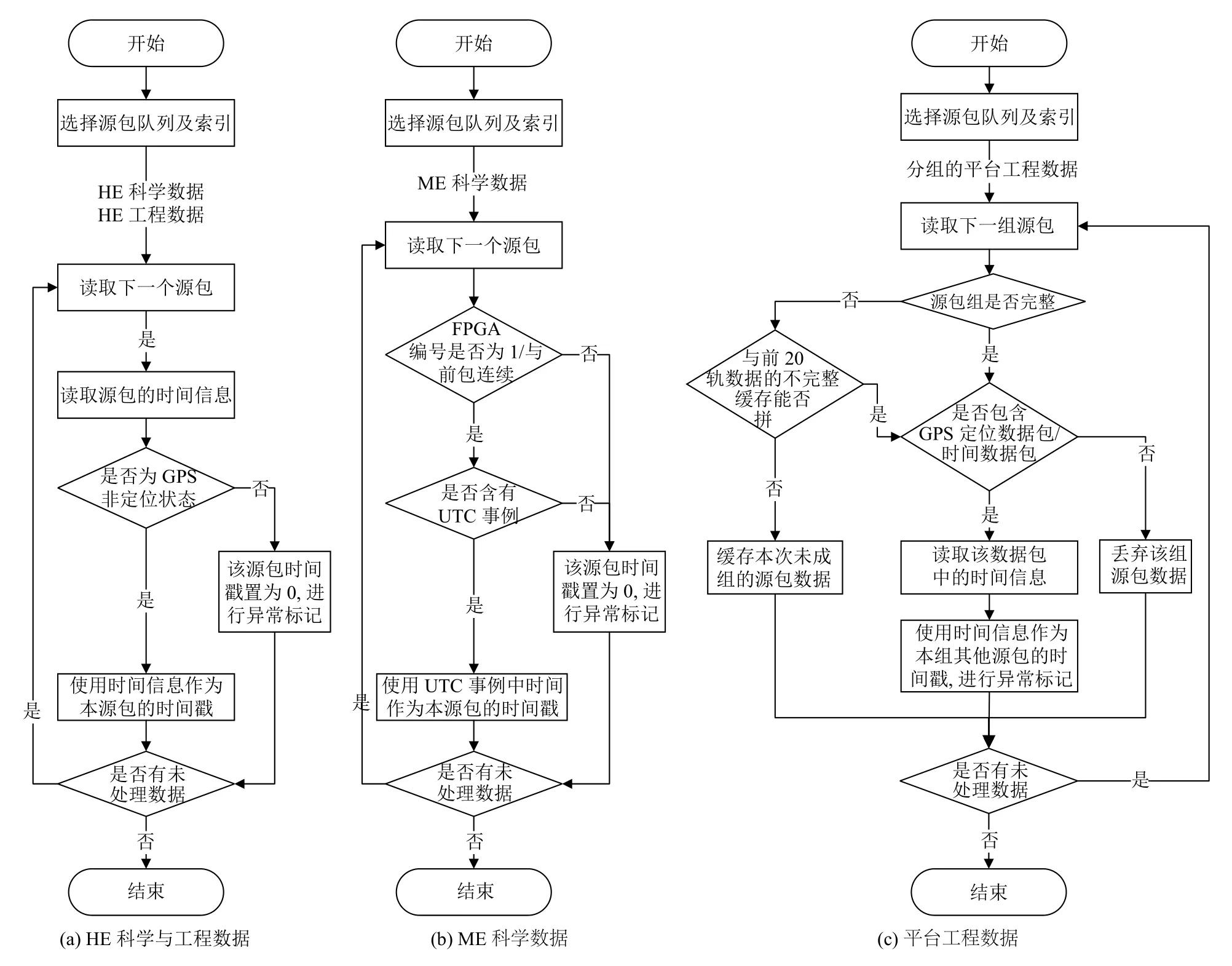
图5 源包时间码提取与时间戳初标过程
关键参数之一是队列连续性判别参数.根据虚拟信道与应用过程标识符的对应关系、源包的分组特性,对各APID的源包队列连续性判别参数进行分别设置.举例如下:
(1)对于HXMT 卫星的低能望远镜LE 科学数据,判断队列连续性时使用源包计数差小于6 且帧计数差小于FFF 进行判定.因为LE 科学数据包含3 个独立的APIDI,分别为LE 科学1、LE 科学2、LE 科学3,它们共用一个虚拟信道,而每一帧数据存储2 个独立的源包,各源包最大计数为0x3FFF,因此每类源包一个计数循环最多占用1FFF 个帧计数.为保证源包排序,使用半个源包计数周期占用的帧计数FFF.通过对发现问题当轨数据比对,两个源包间帧计数差未超过FF,因此使用FFF 作为参数可以满足要求.
(2)对于HXMT 卫星的高能望远镜HE 科学数据、中能望远镜ME 科学数据,判断队列连续性时使用源包计数差小于6 且帧计数差小于3 进行判定.存储HE和ME 科学数据的每个虚拟信道仅存储一类源包,HE 科学数据虚拟信道每帧数据存储1 个源包,ME 科学虚拟信道每帧数据存储2 个源包,当对3 帧数据容错时,可能丢失源包数应不大于6.
(3)对于HXMT的载荷工程数据,判断队列连续性时使用源包计数差小于27 且帧计数差小于3 进行判定.各载荷的工程数据虚拟信道仅存储该载荷的工程数据源包,每帧数据存储9 个源包,当对3 帧数据容错时,可能丢失源包数应不大于27.
关键参数之二是成组源包的不完整数据回溯文件数参数.对于分组源包,一组连续源包共同组成一条探测记录的情况,占用多个传输帧进行传输,因此需要判断该组源包的完整性.举例如下:对于某些类型的源包组不完整的数据,回溯20 轨数据尝试进行源包组的补全.
3.3 时间戳校正
从卫星原始数据中提取出来的各种索引字段,没有一个是随着源包的真实顺序而永远递增的,帧计数、源包计数都会周期性回滚归零重新累计,源包时间码可能发生各种错误和乱序而没有依据源包真实的先后顺序而递增,因此作为排序依据使用起来有一定困难.而想要对乱序下行的多份重复源包进行正确排序,必须建立一个真正随着源包的先后顺序一直递增的标志,基于这种情况,本文设置了“校正的时间戳”.源包时间戳校正环节的主要流程如图6所示.

图6 源包时间戳校正
根据不同的异常标记采取不同的时间戳校正策略.
(1)当因无法获取GPS 时间导致源包时间码变成默认的填充码时,将其时间戳校正为该源包之前的最近一个正常的源包时间码;
(2)当载荷异常开关机导致累积秒归零,造成时间码复位到初始位置,重新累积,将发生复位后的源包的时间戳校正为当前累积秒叠加复位之前累积秒的总秒数经换算得到的时间码;
(3)当时间的秒部和毫秒部的进位不完全同步造成“跳秒”现象,也就是判断当前源包的时间码小于上一个源包,并且很接近(设置为2 s 之内),那么将当前源包的时间戳校正为增加1 s,并判断校正后的时间码大于上一个源包的时间码,且不大于下一个源包的时间码,如果不满足则把时间戳校正为上一个源包的时间码;
(4)当源包时间码因单粒子事件等造成无规则异常时,检索当前源包时间码,如果小于上一个正常源包的时间码或大于下一个相邻源包的时间码,将其时间戳校正为上一个正常源包的时间码;
(5)如果本队列中在当前源包之前不存在非0 时间戳的正常源包,那么依据其之后相邻最近的非0 时间戳的正常源包来进行时间戳校正,如果本队列时间戳均为0,即时间码有误,那么回溯上一轨数据继续寻找时间戳正常的源包作为校正基准.
3.4 源包排序
源包排序流程如图7所示.首先依据校正后的源包时间戳对数据进行排序,进行时间大小比较时,当时间戳无法区分时,借助源包计数、帧计数、源包偏移量、轨道圈次等索引信息进行联合判断.对于时间差在一定时间内的数据(这个时间是可以对不同的卫星和载荷进行区分设置的),作为时间相等的数据进行处理.例如在HXMT 卫星中,依据卫星系统的设计,卫星的GPS 非定位时间状态不会超过20 min 就会复位正常,因此设定时间差在20 min 作为判断依据.

图7 源包排序流程
4 方法应用与验证
本文使用HXMT、QUESS、DAMPE 三个卫星任务2018年度的全部数传原始数据进行了实验验证,数据资源来自国家科技资源共享服务平台-国家空间科学数据中心.
三星共5347 个数传原始数据文件,总体量22.78 TB,使用传统的“源包时间码+源包计数+虚拟信道帧计数”源包排序算法处理,源包排序完全正确的文件占比平均为93.55%.处理错误的文件中,平均约15%是由多种异常联合发生所引起.使用本文提出的“多重索引+时间戳校正”源包排序处理算法处理,源包排序完全正确的文件占比平均为99.84%,其中排序错误的几个文件均是由于星上本身设备故障引起的数据错误.可见,本文提出的算法,大大提升了源包排序处理的正确率,具体实验结果如表3所示.运行环境为12 个处理节点的服务器集群(4 个CPU Intel Xeon E7-4820v2,主频2 GHz,内存64 GB),由中国科学院国家空间科学中心公共技术服务中心提供.

表3 原始数据文件源包排序处理的正确率
在同一个HXMT 卫星数传原始数据文件中分别截取源包计数无循环、源包计数有3 次不完整循环的大小为1 GB的数据片段,帧长为1024 字节,源包长度为488 字节.使用本文提出的处理方法和传统处理方法进行源包提取与还原排序,分别记录两种方法的处理时长及最大占用内存,实验结果如表4所示.为增加运行时长而使性能指标对比明显,选择低配置的运行硬件环境,在一台普通台式计算机(Intel Xeon CPU E5649 @2.53 GHz 16 GB RAM)上进行实验.结果说明“多重索引+时间戳校正”源包排序算法能够实现源包计数有不完整多次循环和无循环情况下的正确源包提取与排序还原,同时相较于传统的“源包时间码+源包计数+虚拟信道帧计数”的源包排序算法,所需的处理时间缩短(约3%),内存的占用量减小(约28%).这是由于传统处理算法是对帧数据本身进行操作的,本文所提算法是对源包的多重索引进行操作,而源包多重索引的长度明显小于帧长,所以在处理时间和内存占用量方面有性能优势.

表4 两种源包排序处理算法的性能比较
使用本文提出的算法对HXMT 卫星的不同大小的同类型数据进行源包提取与排序处理(运行环境同上),测试数据大小分别截取或者拼接成1 GB 到12 GB的大小,记录处理时长和最大内存占用量等性能指标,测试结果如图8所示,虚线条代表处理所用的时长与数据量之间的关系,实线条代表算法的最大内存占用量与数据量之间的关系.
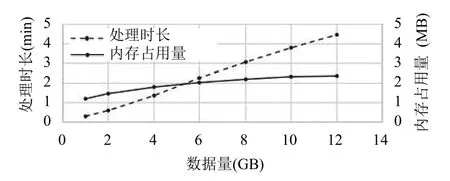
图8 源包排序处理的时间与内存占用量
结果表明,处理时长随着数据量增加而有明显增长,因为源包排序所占用的时间随着数据量的增加而成倍增加,程序的内存占用量随着数据量增加变化不明显,因为而由于采用索引进行处理,而非数据本身,索引本身占用内存不大,主要是程序运行占用的部分,随着数据量的增加变化不大.
5 总结
“多重索引+时间戳校正”源包排序处理算法,可以解决源包时间码秒部与毫秒部进位不一致导致的“跳秒”问题、两次地面站接收数据之首尾源包不完整导致的丢包问题、源包计数深度不足导致的源包计数循环问题、GPS 非定位状态导致源包时间码缺失的问题、载荷异常导致累积时间码异常归零的问题等多种排序困难,是一种相对完备的自动解决方案.经过对HXMT、QUESS、DAMPE 三个卫星的大量数据进行实验验证,结果表明该算法可以将卫星原始数据文件的源包排序整体正确率明显提升,同时有效提升处理效率.此外,该算法从原理上来说适用于所有卫星的源包排序处理,具有通用性和推广价值.
