ERA5降雨数据的降尺度评估及水文模拟
——以横江流域为例
2022-02-13肖梓明张行南方园皓
肖梓明,张行南,方园皓
(河海大学水文水资源学院,南京210098)
0 引 言
近年来随着人口上涨、农业产业升级,农业灌溉对水资源的需求越来越大,为了解决水资源短缺问题,水资源规划管理愈发重要。为了构建合适的水资源规划管理模型,实现准确的水文模拟必不可少,例如徐宗学、程磊[1]认为,灌区模拟问题难以运用传统的方法进行研究,考虑时空变异的分布式水文模型能够处理这一问题。在流域水文模型中,降水作为重要的数据输入,对水文模拟的准确性起着至关重要的作用;在农业灌溉中,准确的降雨对灌溉制度及灌溉决策起着指导作用,例如孙晋锴等[2]基于多年降雨数据对豫东地区夏玉米灌溉制度进行了优化;侯静文等[3]对桂林市降雨预报准确度进行了分析,并应用到当地水稻灌溉决策中。传统的水文模拟中,降水数据主要采用地面站点的观测值,存在着空间分布性差、站点布设受地形限制等诸多问题,导致数据获取及准确性方面存在影响,进而影响水文模拟。所以如果能在流域尺度上提供准确的降水数据,将会使水文模拟的准确性大大提高。
大气环流模式(GCM)作为当前全球气候模拟的有力工具,是获取降雨数据的重要来源之一,其准确性、可靠性和精度也获得了众多学者的肯定[4,5],但是由于计算条件的限制,GCM 一般在比较低的空间分辨率下进行运行(通常是2°或者更低),有学者[6]认为0.125°的空间分辨率才能满足流域尺度的水文模拟,因此不能将GCM 的降雨数据直接运用在水文模拟中。
此前,已有不少学者将GCM 降雨数据运用到水文模型中的先例,例如:张徐杰[7]采用GCM 集合数据,在降尺度处理下,利用SWAT 水文模型对兰江流域未来的径流量进行了模拟,发现兰江流域径流量和可利用水资源量在未来有减小的趋势;宣伟栋[8]通过LARS-WG 天气发生器对5 种全球气候模式的结果进行降尺度,对奴下等站点未来降雨径流进行模拟,做出趋势分析;宋小园[9]对于最新的CMIP5 气候模式,将气候情景预测结果和SWAT 水文模型耦合,构建了未来径流模拟,效果显著。由此可见,GCM 降雨数据作为水文模型降雨输入存在一定的合理性。但是为了弥补GCM 降雨数据在流域尺度上分辨率过低的问题,还需要经过降尺度处理,将尺度大分辨率低的数据转化为尺度小分辨率高的数据,使其满足流域尺度要求。
为了应对GCM 数据分辨率过低问题,本文以横江流域为例,运用统计降尺度方法,结合4种机器学习方法,对欧洲中期天气预报中心(ECMWF)发布的ERA5 再分析数据中的降水数据,结合19个大气环流因子建立模型,进行降尺度分析,并将结果输入新安江水文模型[10],进行径流模拟,以此分析ERA5 再分析数据降尺度后作为流域水文模型降水数据来源的可靠性,以此来确定是否可以为农业灌溉提供数据支撑。
1 数据与方法
1.1 研究区概况
横江是长江上游金沙江下游一级支流,源自贵州威宁草海,位于东经103°18′至105°57′、北纬26°45′至28°36′之间,全长307 km,流域面积约为1.486 万km2,多年平均降雨量1 150.9 mm,年内降水集中在6-10月,占全年降水的80%左右,以横江水文站为控制站。图1为流域概况图。横江流域境内主要农作物为水稻、冬小麦、玉米、甘薯、马铃薯等,农业需水量大,需要合理的水资源规划管理。
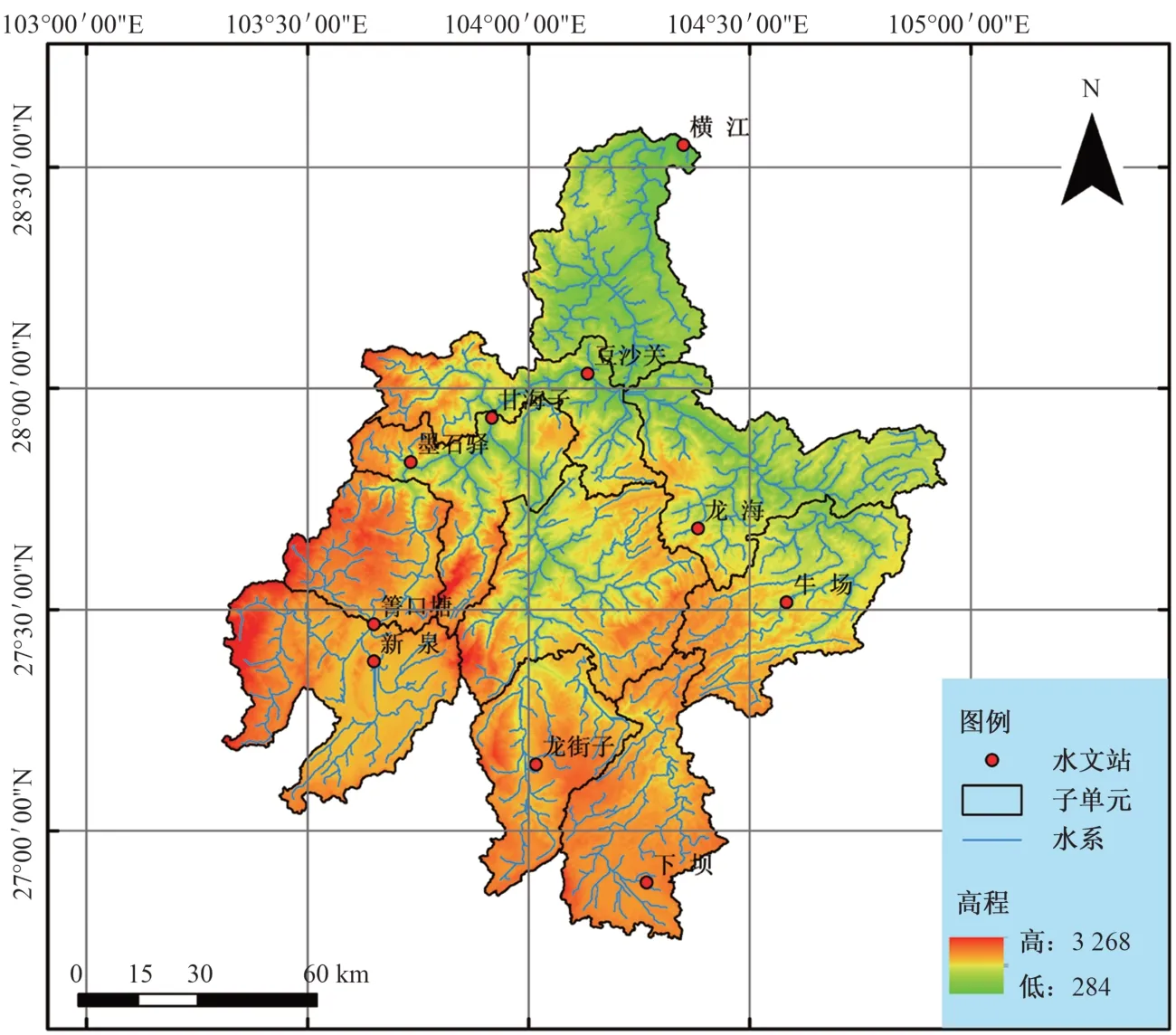
图1 横江流域概况Fig.1 Overview of Hengjiang River Basin
1.2 数据来源
(1)ERA5再分析数据。ERA5是ECMWF发布的第五代再分析全球气候数据,空间分辨率0.25°×0.25°,本文所采用的降水数据下载地址为https://cds.climate.copernicus.eu/cdsapp#!/search?type=dataset,数据集为“ERA5 hourly data on single levels from 1979 to present”。
(2)大气环流因子数据。本文所采用的大气环流因子来自于ECMWF 发布的TIGGE 数据集,空间分辨率0.5°×0.5°,数据下载地址为https://apps.ecmwf.int/datasets/data/tigge/levtype=sfc/type=cf/。
(3)实测水文数据。降雨数据为横江流域内的10 个水文(雨量)站的实测数据,分别为豆沙关、甘海子、横江、龙海、龙街子、墨石驿、牛场、箐口塘、下坝、新泉;径流数据为横江水文站实测径流数据。以上数据均摘录自水文年鉴,数据的时间长度为2009年1月1日至2014年12月31日。
1.3 研究方法
在建立统计降尺度模型时,我们认为局地降雨与大气环流因子存在某种统计关系,即:

式中:Y为局地降雨数据;F为统计关系;xi为大气环流因子。
因子详情如表1 所示。建立统计关系的示意图如图2 所示(●代表气象格点,★代表雨量站),气象格点为ERA5降雨数据,雨量站点为实测雨量数据。每个气象格点的控制范围如图中阴影区域,为每个雨量站匹配大气环流因子时,保证距离最近,即雨量站要被阴影所覆盖。由于因子数量较多,确定统计关系式时较为复杂,本文借助机器学习方法进行关系拟合,共选取四种机器学习方法:人工神经网络(ANN)[11]、支持向量机(SVM)[12]、决策树(DT)[13]、随机森林(RF)[14],以2009-2013年为训练集,2014年为测试集,检验降尺度后的降雨数据精度,并将结果输入至新安江模型,检验其在水文模拟中的效果。

图2 统计关系建立示意图Fig.2 Schematic diagram of statistical relationship establishment

表1 大气环流因子信息表Tab.1 Predictor information table
本文所采用的4种机器学习方法的具体模型如下:
ANN模型为:

式中:y(t)为模型t时刻输出的降雨;xi(t)为t时刻第i个因子值;vij为连接输入层和隐层的权重;wj为连接隐层和输出层的权重;n为因子个数;m为隐层维数;θj为隐层阈值;θ0为输出层阈值;f为Sigmoid函数:f(x)=(1+ e-x)-1。
SVM模型为:

式中:ai、a*i、b为最优超平面参数;N为支持向量数;样本空间X和Xi经映射得到。
DT 模型的核心思想为切分点确定,本文以最小二乘法为切分点选择原则。RF 则是以多个决策树组成,每个决策树之间互不影响,其最重要的参数为决策树个数和随机选择特征的最大数量,目标则是均方误差最小和决定系数最大。
由于降雨量为0时会对机器学习的回归运算产生影响,所以本文将整个降尺度过程分为3步,首先利用机器学习的分类思想,对ERA5降水数据进行晴雨准确率(即是否有雨)的模型运算;其次利用机器学习的回归思想,对第一部分有雨的部分进行降雨量准确率的模型运算;最后将前两部分整合,得出整个ERA5降雨数据的降尺度结果。
本文所采用的水文模型为新安江模型。新安江模型是河海大学赵人俊于1973年提出的水文模型,该模型主要运用于湿润半湿润地区,产流方式为蓄满产流,蓄水容量曲线为核心部分,其结构分为蒸散发、产流、分水源、汇流。经过众多学者的不懈努力,已成为国内广泛运用的流域水文模型。
2 结果与分析
2.1 降尺度降雨对比
ERA5 的空间分辨率为0.25°×0.25°,而预测因子的空间分辨率为0.5°×0.5°,为了保证模型在同样的分辨率下进行,对数据进行插值处理,保证其分辨率相同。
(1)晴雨准确率。将所有的降雨数据分为两类:有雨和无雨,采用机器学习的分类思想进行模型运算。在质量评估方面采用TS 评分进行评价,ERA5 降尺度后在10 个站点的TS评分如图3 所示。从图3 可以得出以下结论:①ERA5 数据降尺度前的TS 评分大多在0.4~0.6 之间,只有在龙海站的TS 评分较高,达到了0.726,总体效果并不是很理想;②ANN、SVM、DT、RF 4 种方法在10 个站的均值分别为0.737、0.745、0.684、0.746,而ERA5 在降尺度前的均值为0.508,可以看出,在4 种降尺度方法下TS 评分均有较大幅度的提高,以SVM 和RF 效果最优,DT 效果最差;③ERA5 对横江流域的晴雨准确率并不理想,但可以选用SVM 和RF 方法对其进行优化,优化后的效果更为准确。
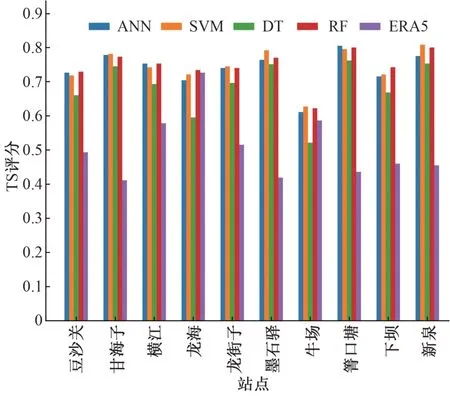
图3 各个站点晴雨准确率TS评分Fig.3 TS scores of sunny or rainy accuracy at various stations
(2)降雨量准确率。在晴雨准确率的基础上,对有雨部分进行降雨量计算。在质量评估方面采用相关系数r、平均绝对误差MAE进行评价,ERA5 降尺度后在10 个站点的两项指标如图4 和图5 所示。从图中可以得出以下结论:①ERA5 数据降尺度前与实测站点的相关系数大多在0.5~0.7 之间,属于显著相关,在横江站更是达到了0.721,只有在龙街子和下坝较低,分别为0.492和0.441,而在平均绝对误差方面,大多集中在3~5 mm 之间,下坝更是达到了7.398 mm,误差较大,精度较低;②ANN、SVM、DT、RF 4种方法在10个站的相关系数均值分别为0.578、0.632、0.431、0.553,而ERA5 为0.596,可以看出ANN 和RF 方法在降尺度后仍然保持着相当的相关性,SVM 有所提高,DT 则大幅度下降;在平均绝对误差方面,4 种方法的均值分别为4.813、4.283、5.670、4.779,而ERA5 为5.063,可以看出ANN、SVM、RF 均有所提高,SVM更是提高了0.78 mm,反观DT 精度有所下降;③综合以上可以得出结论:ERA5 在横江流域的降雨精度不足,在降尺度方法方面可以选择SVM 方法,使得结果在相关系数和平均绝对误差上均有所提高。
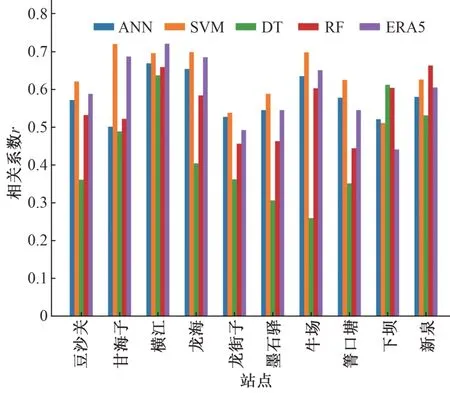
图4 各个站点降雨量相关系数Fig.4 Correlation coefficients of rainfall at various stations
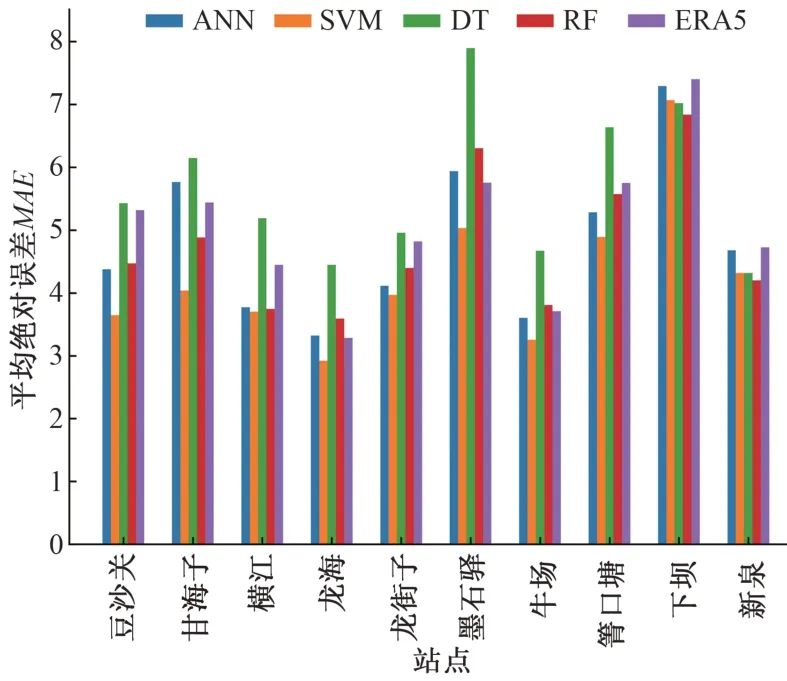
图5 各个站点降雨量平均绝对误差Fig.5 Average absolute error of rainfall at each station
2.2 水文模拟
为了检验4 种方法对ERA5 降尺度后的降雨数据在水文模拟中的效果,本文计算了4种降雨结果在研究区的面雨量,再将面雨量输入新安江模型进行径流模拟。面雨量的计算采用泰森多边形法。
横江流域以横江水文站为控制站,以其实测流量作为横江流域的出口断面流量,同样的将2009-2013年划分为率定期,2014 划分为验证期,基于率定期实测数据对新安江模型的各项参数进行率定。新安江模型有16 项参数,其中敏感参数率定结果详见表2。表中参数意义如下:KC为蒸散发折算系数、SM为自由水蓄水容量、KG为自由水蓄水库对地下水的日出流系数、KI为自由水蓄水库对壤中流的日出流系数、CG为地下水消退系数、CI为壤中流消退系数、CS为地面径流消退系数。

表2 敏感参数率定结果Tab.2 Calibration results of sensitive parameters
在模拟精度方面采用纳什效率系数(NSE)、径流深相对误差(Bias)、均方根误差(RMSE)对验证期径流模拟结果进行评估。图6为径流模拟过程。在不同方法下径流模拟结果如表3 所示。从图表中可以看出,实测降雨在验证期的表现良好,NSE达到了0.61,Bias也控制在正负5%以内,为-1.17%。而ERA5 的模拟效果很差,NSE为-0.36,Bias为59.44%,从图6可以看出,ERA5模拟径流与观测径流整体过程基本吻合,造成NSE和Bias效果差的原因可能是ERA5 的整体雨量较大,造成了模拟值比实测值偏高的情况。4种降尺度方法在模拟精度上,相对ERA5 都有不同幅度的提高,其中ANN 和RF 方法较好,ANN的NSE相对实测数据提高了0.07,Bias相对实测数据下降了1.81%,RF 的NSE与实测数据相同,但在Bias上比实测数据低了6.1%。SVM 方法在汛期表现很差,存在着峰值严重低估的情况,在水文模拟中不可取。DT 方法与ERA5 存在着相同的问题,即径流过程较好,但整体水量偏高。

图6 径流过程模拟Fig.6 Runoff process simulation
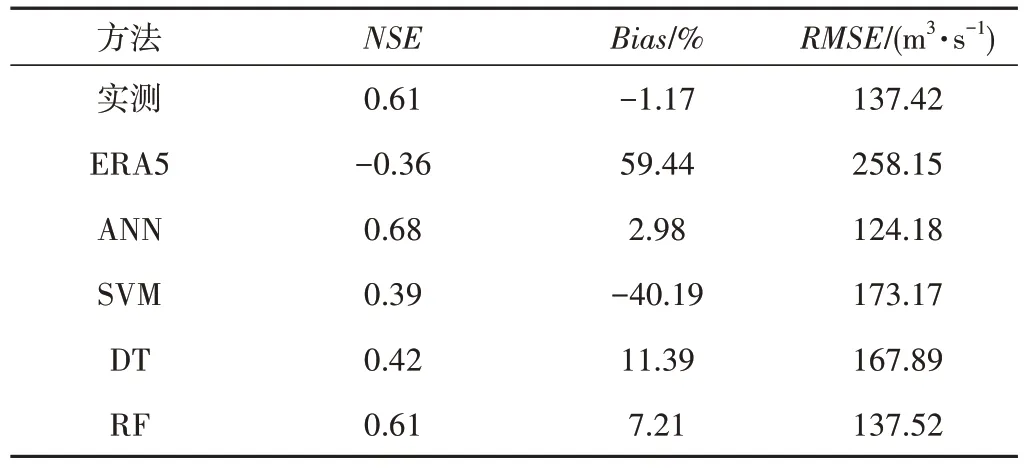
表3 不同方法下的径流模拟结果Tab.3 Runoff simulation results under different methods
3 结 论
(1)ERA5 降雨数据在横江流域精度较低,在水文模拟上虽然统计指标较差,但径流过程与实测吻合,造成这种现象的原因可能是整体水量偏大,在模拟过程中可适当调大蒸散发折算系数KC,在农业灌溉中,可根据当日降水量适当减小计算需灌水量。
(2)建立了从ERA5低分辨率的网格到实测站点的统计降尺度模型,并从晴雨准确率和降雨量准确率两个方面检验降尺度后的数据精度,结果表明:在晴雨准确率和降雨量准确率方面,可选用SVM进行降尺度研究。
(3)在水文模拟中,4种降尺度方法表现各不相同,使用ANN方法进行降尺度的效果最优,验证了将ERA5降雨数据降尺度后,作为流域水文模型降水输入的可行性,进一步为农业灌溉提供数据支撑。
