语料库译学研究范式:继承与革新
——基于WoS的文献可视化计量分析
2022-02-12张瑞娥韩名利
王 翊, 张瑞娥, 韩名利
(1.安徽科技学院,安徽 凤阳 233100;2.马来西亚理科大学,槟城 11800)
一、引言
研究范式指包括定律、理论应用、仪器设备在内的一系列公认的科学活动范例,为某种科学研究传统的出现提供模型[1]。纵观译学发展史,研究范式的嬗变与更替贯穿始终。这既反映了译学共同体对翻译本质特征及规律在认识视角及层次上的转变,同时成为译学研究不断推进深化的外在动力。
20世纪50年代以前的译学研究多采用以经验、直觉及内省为主要方法的“语文学范式”,将翻译视为一种二次创作的艺术形式,主张译者依靠自身天赋素质,传达原作思想内容,再现作者风格手法,并根据不同文体调整翻译方法,如Jerome基于《圣经》翻译的经验总结及Tytler的“翻译三原则”等。20世纪50年代之后,译学研究从属于同期语言学的研究分支,借助Saussure结构主义语言学、Chomsky转换生成语法、Halliday系统功能语言学等理论,以“语言学范式”构建了较为完整的理论体系。该研究范式将翻译视为语言转换活动,以实现源语、目的语之间的“对等”转换为核心目标,认为翻译应“以自然对等的语言从语义到文体再现源语信息”[2],并从层次、结构、类别、单位、内部系统等维度考查转换的具体表现形式和实现手段[3]。
1972年Holmes发表《The Name and Nature of Translation Studies》一文,标志着翻译研究开始脱离语言学的从属地位,逐渐发展成一门独立学科。此后,在解构主义“去中心化”思潮及翻译“文化转向”的影响下,译学研究摒弃传统以文本为中心的世界观,不再囿于封闭的语言结构系统,从而将翻译置于“更为广阔的语境、历史和常规背景之中”[4],并在文化范式下以解构学派、多元系统、后殖民主义等理论视角,探讨翻译与主体、历史、文化、社会及意识形态的互动关系。然而,解构主义带来自由曙光和人文气息的同时,预示着巴别塔的倒塌,其元语言观所具有的形而上性质与翻译语言的经验性内禀不相符。20世纪90年代至21世纪初期,学界曾一度陷入对翻译研究方向的迷茫和焦虑,文化范式在面对翻译中出现的具体语言现象时显得解释力不足,以此构建的译学理论体系备受质疑。为使译学研究重新回归对翻译“本体”的关注,转向由内而外的研究路径,学界进行了语言主义回归、翻译归结主义及译学研究建构等尝试,其中最具影响力的当属语料库译学研究范式的建立和发展。
1993年Mona Baker发表《Corpus Linguistics and Translation Studies: Implications and Applications》一文,阐发了建立在数理统计和语料分析基础之上的翻译研究路径,为语料库译学研究的滥觞之作。此后,翻译英语语料库(TEC)、德语—英语文学平行语料库(GEPCOLT)、欧洲会议口译语料库(EPIC)等早期译学专用语料库逐步建成,Baker、Laviosa、Kenny等学者开始借助语料库开展如译者风格和翻译共性等译学研究课题。21世纪以来,语料库译学研究在世界范围内呈现蓬勃发展的态势:国际性研讨会议接连举办,如2003年南非Pretoria、2009年Univ Ghent、2010年UnivEdge Hill、2018年Univ Louvain等,语料库译学研究论著相继出版[5-9]。语料库译学研究已由最初的研究路径及方法论手段逐渐演变为一种系统的、综合性新兴研究范式,其发展历程、热点及前沿议题在一定程度上反映了译学研究的发展动态。
有鉴于此,本文以Web of Science核心数据库为来源,运用CiteSpace软件对1993—2020年间语料库译学研究发文状况进行可视化计量分析,旨在尝试回答以下问题:语料库译学研究的历时进程及研究力量的空间布局是怎样的?语料库译学研究的热点和前沿议题有哪些?相较于以往研究范式,语料库译学有何新的内涵与意义?
二、数据收集及研究方法
数据收集以WoS核心数据库合集为检索平台,选择其中SSCI(社会科学引文索引)、A&HCI(艺术与人文科学引文索引)、CPCI-SSH(人文社科会议录引文索引)、BKCI-SSH(人文社科图书引文索引)等为检索数据库,数据更新时间为2020年6月19日;检索式使用布尔逻辑运算符,设置为TI=(Corpus OR Corpora) AND(Translat*OR Interpret*);时间跨度为1993—2020年;检索共获得有效文献877篇,精炼剔除相关度较低的学科领域后,得到文献862篇(共含被引文献15 896条),提取全记录数据并以纯文本格式储存。数据收集完成后使用CiteSpace 5.5.R2版可视化计量工具绘制科学知识图谱,考查分析文献所反映的语料库翻译研究的内部结构及发展动态;参数设置Years Per Slice(时间切片)为1年;Links(连接算法)为Cosine,Top N(阈值)为50;勾选Pruning最小网络分割,可视化形式选择Cluster View Static,具体研究路径为文献历时分布、研究力量布局、学科结构及热点、知识基础及前沿、结构变异分析。
三、数据可视化分析
(一)文献分布及构成
文献发文量的历时分布能够在一定程度上体现该学科领域的总体发展态势。WoS文献检索后可自动生成分析报告,其中文献分年度统计如下。1993—2020年间语料库译学研究的文献发文总体分布呈现明显上升趋势,大致可分为三个阶段:第一阶段(1993—1999)研究处于低缓期,年均发文量仅5篇,1998年出现短暂的峰值,发文量13篇;第二阶段(2000—2014)研究文献基本保持线性增长,2014年发文量达到65篇;第三阶段(2015—2019)文献发文量维持在较高水平波动,年均发文量达到82篇,2016年为峰值102篇,2020年因数据不足未纳入计算。
从文献类型上看,862篇文献中期刊文献479篇(55.6%)、会议文献247篇(28.7%)、书评104篇(12.1%)、书章/专著32部(3.7%);从研究范围上看,文献主要涉及语言学602篇(69.8%)、计算机科学130篇(15.1%)、教育研究51篇(5.9%)、人文学科39篇(4.5%)、文学39篇(4.5%)、文化研究23篇(2.7%)等领域;从刊物来源上看,上述文献主要发表于《Meta》《New Frontiers in Translation Studies》《Perspectives Studies in Translation Theory and Practice》《Babel》《Cadernos De Traducao》《Across Languages and Cultures》《Language in Contrast》等出版物。
(二)研究区域及影响力
某一学科的区域力量分布状况反映了该学科学术共同体的内部结构特征及演变轨迹,以下分别从国家地区、学术机构、高产作者等方面考查语料库译学研究的区域影响力。
语料库译学研究在世界范围内的分布主要集中在中国(159篇)、西班牙(131篇)、英国(59篇)、意大利(49篇)、美国(46篇)、法国(35篇)、德国(30篇)、比利时(28篇)、日本(25篇)、巴西(22篇)等。激增数据显示,英、美研究集中于1997—2006年的10年间,且中心度较强,为该领域的先行者和传统研究发源地;21世纪以来,中、日、西、法、德、意等后起之秀颇具规模和影响力,已然成为亚欧的研究中坚;比利时作为2010年后出现的新兴力量,发文数量跃居第8位,且连线密度表明其与欧洲各国合作关系较强,有望形成新的研究中心。此外,语料库译学研究已扩展至波兰、印度、巴基斯坦、韩国、澳大利亚、埃及等国家和台湾地区,逐渐形成较为广泛的学术共同体。
发文量较高的科研机构依次为Univ Bologna(15篇)、上海交通大学(15篇)、Univ Ghent(13篇)、Univ Malaga(13篇)、Univ Jaume I(12篇)、Univ Autonoma Barcelona(11篇),其中后三者均属西班牙大学,足见其作为欧洲研究重镇的影响力。从节点年轮圈数及连接密度看,Univ Ghent显现出较强的辐射能力,与Univ Sunderland、Univ Coll Ghent、Univ Turin、Univ Saarland等的合作关系脉络清晰,该机构主要作者有Gert De Sutter(8篇)、Bart Defrancq(4篇)、Camille Collard(2篇)、Koen Plevoets(2篇)等。Univ Bologna及上海交通大学总发文量并列第一,高产作者分别是Mariachiara Russo(4篇)和胡开宝(9篇),相较而言,其机构间合作关系稍弱且单核心作者现象比较明显,有待向双/多核心合作模式转变。
(三)学科结构及热点

文献关键词是对研究核心要点的总结凝练,共现网络在一定程度上映射了学科相关概念、方法、原理之间的关联,即学科结构状况,高频/高中心度关键词反映出研究所关注的热点领域。将节点类型设为“Keyword”,对862篇施引文献进行关键词共现网络分析,得到125个节点,其中高频/高中心度关键词如表1所示。
依据各关键词出现的年份,将关键词分布状况概括为三个阶段:第一阶段,1993—2003年。语料库译学处于萌发期,此时研究多注重概念的阐释及研究方法手段的建立,核心关键词为corpus-based和parallel corpus,且与example-based、construction、representativeness等词呈共现关系;该阶段研究主要涉及引介基于语料库的自然语言处理技术、语料库方法用于机器翻译的尝试,以及探讨平行语料库的设计问题,包括双语语料获取方式、收集分类标准、语料对齐的粒度划分等。第二阶段,2004—2010年。以建成的平行/可比语料库为载体,围绕英语语种开展实证翻译研究,关注的热点有corpus、translation、English、corpus linguistics、machine translation、comparable corpus等,且相互之间共词关系明显,形成强连接的共现网络;该阶段研究多在语言学理论框架下借助语料库词频统计工具,以不同语言单位提取分析原/译语文本特征及翻译转换信息,涉及感叹词、程度副词、名词短语、动词搭配、迭代句对、语篇标记语、双向翻译对比等。第三阶段,2011—2020年。对翻译语言特征的考查由表层逐步深入,译学研究范围拓展至多种视角、语种、语域,相关研究热点有translation teaching、translation universal、explicitation、audiovisual translation、language、Spanish、simultaneous interpreting等;该阶段研究分布较均匀,涵盖翻译共性、具体语言对翻译语言特征、翻译实践、翻译教学、口译研究等,主要特点体现在实证研究中考查参量的不断丰富,如涉及形/类符比、平均句长、词汇密度、词性分布、结构容量、语义信息强度等,以及出现跨学科研究趋势。
(四)知识基础及前沿
1.知识基础
某学科研究文献所引参考文献的共现状况是该学科领域知识构成的一种表征,通过对参考文献共被引网络的分析,能够揭示学科研究的知识基础,一定程度考查其知识体系状况。使用CiteSpace创建新项目,将“look back years”(回溯年份)设置为“-1: Unlimited”(不限),对862篇文献的15 896条引文进行共被引数据分析,聚类处理后如图1所示。
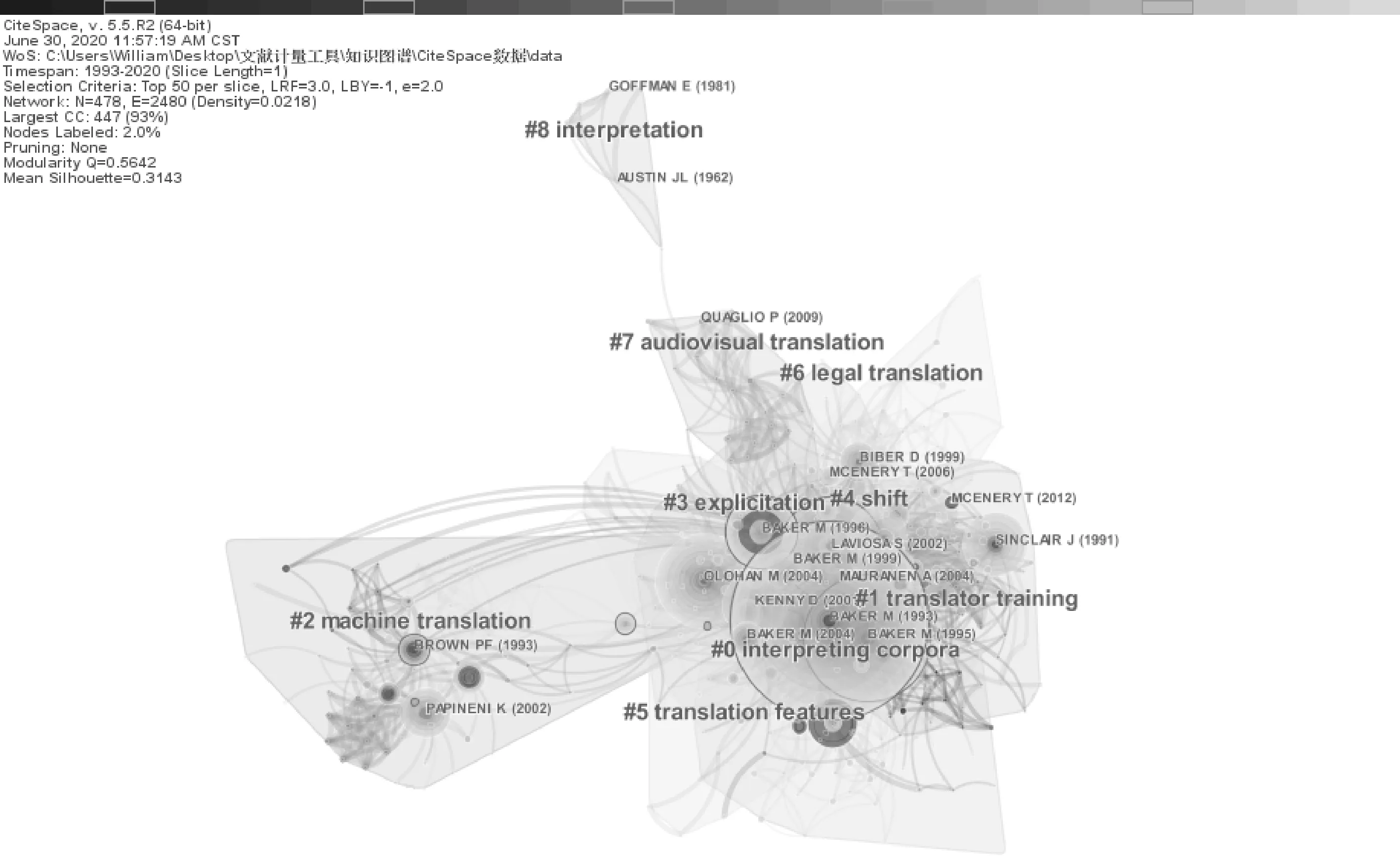
图1 1993—2020年语料库译学研究文献共被引聚类(回溯期不限)
聚类处理后显示:最早的共被引文献可追溯至1951年伦敦派语言学家J. R. Firth的“Modes of Meaning”一文,收录于《Papers in Liguistics 1934—1951》一书。该文延续其“意义语境论”的核心思想——完整的意义存在于情境语境中,并进一步提出语境对意义具有决定作用[10]。这种语境语义观与语料库译学研究在进行客观描写与阐释时注重的语境还原相契合,且其继承者——Halliday系统功能语言学所提出的概率语言观及Sinclair语料库语言学所倡导的词汇主义语言观,与语料库译学研究的方法论基础和理论构架有着深厚的渊源。Summary Table报告显示half life(半衰期)最长(61)的文献是布拉格学派翻译理论家Jakobson于1959年发表的“On Linguistic Aspects of Translation”,收录于《The Translation Studies Reader》。该文将翻译活动划分为语内、语际、符际三种类型,并从词汇及语法范畴空缺两个方面探讨转换、对等、不可译性等译学核心问题[11],其颇具开创性的符号语言学观对译学研究从纯语言范畴向文化研究领域延伸具有指导意义。
图谱中光圈最大、被引频次最高(139次)的文献为1993年Mona Baker的“Corpus Liguistics and Translation Studies: Implications and Applications”,收录于《Text and Technology: In Honor of John Sinclair》。作为语料库译学的奠基之作,其从原文地位及对等观念的演变回顾了译学研究的发展历程,指出以Zohar为代表的多元系统学派理论对翻译文学地位的重新审视,引发了译学研究由对等到规范再至描写的转变,进而为基于语料库的译学研究提供了理论条件,并展望了语料库在翻译共性特征、特定语境下翻译规范等研究领域的前景[12]。Baker的另两篇文章《Corpora in Translation Studies:An Overview and Some Suggestions for Future Research》(95次)、《Corpus-Based Translation Studies: The Challenges that Lie Ahead》(51次)分列被引频次表第2、第8位。前者介绍语料库技术在术语编撰及机器翻译方面的应用,并以译者培训和翻译批评为例,阐述以语料库作为一种描写方法论可增强译学应用领域跨学科能力的设想[13];后者则对翻译共性假设中的显化、简化、范化做了进一步阐释和概念细分[14]。
Toury在论著《Describe Translation Studies and Beyond》(73次)中提出的描写译学理论框架强调,通过对具体翻译现象的描写,分析探究翻译的行为模式,进而重构翻译规范[15],其所推崇的实证主义方法对语料库译学研究影响深远。此外,Quirk、Brown、Sinclair、Granger等出现过明显的引文激增,均为高影响力经典文献[16-19]。
从以上共被引文献可一窥语料库译学研究范式自语言学范式、文化范式的演变痕迹及其知识基础,分析文献聚类状况,能够进一步考查其知识体系的结构及动态变化。图谱显示出#0 interpreting corpora(口译语料库)、#1 translator training(译者培训)、#2 machine translation(机器翻译)、#3 explicitation(显化)、#4 shift(转换)、#5 translation features(翻译特征)、#6 legal translation(法律翻译)、#7 audiovisual translation(视听翻译)、#8 interpretation(口译)9个主要聚类,将聚类结果按照timeline(时间区域)视图排列,可以较清晰地看出该研究范式知识体系不断丰富完善,逐渐涵盖研究工具建设、传统译学、描写性译学,并逐步走向语料库译学特有研究领域的发展过程。
2.研究前沿
在CiteSpace计量分析中,某一学科的研究前沿被视为由共被引文献构成的知识基础所激发的领域[20],具体表现为一组突现的动态概念对应的文献集合所探讨的研究主题及其潜在问题。将回溯年份设置为5年,时间分区设置为2005—2020年,即重点考查语料库译学研究知识基础上近20年共被引文献,涉及776篇施引文献和14 953条引文,生成聚类图谱如图2所示。

图2 2005—2020年语料库译学研究文献共被引聚类(回溯期5年)
将图2显示的主要聚类与图1不限回溯期的聚类比照后发现,#0 asymmentry hypothesis(非对称假说)、#1 news translation(新闻翻译)、#3 overall quality(整体质量)、#4 children literature(儿童文学)、#5 translation process(翻译过程)、#9 qualitative consideration(定性问题)为新兴聚类,一定程度上反映了语料库译学的前沿主题,限于篇幅,选取#0、#5两个代表性聚类具体考察。
#0 asymmentry hypothesis为图谱中最大聚类(32条文献),该假说基于Vinay、Darbelnet提出的显化、隐化概念[21]及Blum-Kulka的显化假说[22],进一步假设译者在原语、目的语转换过程中总是倾向于使用显化策略,从而造成显、隐不对称现象[23]。提取该聚类施引文献信息创建concept tree(概念树)。图3corpus、analysis两个概念层级图可以较直观地显示该聚类的基本框架——借助单/双/多语/平行/可比语料库,定量与定性方法并用的双向翻译实证研究。此外,feature、data、change等概念子项反映出该主题更为清晰的内部结构:研究多以频次/分布为量化指标对显/隐化等翻译共性特征进行描述,涉及语义、语用、文体、类型等领域,变迁方向为历时分析及翻译过程研究。

图3 Asymmentry hypothesis聚类概念层级图(部分)
#5 translation process为图谱中第6大聚类(17条文献),其研究主题与Holmes提出的描述性译学研究框架中“过程导向”范畴的关联度较高。如process、approach概念层级如图4所示,该研究主题利用语料库及神经/认知领域技术手段,通过对译者大脑运作机制的考查,探究翻译过程的性质和规律。聚类中较具代表性的文献为《Simplification in Inter-and Intralingual Translation——Combing Corpus Linguistics, Key Logging and Eye-Tracking》,该实证研究综合运用语料库、击键记录、眼动追踪等工具方法,将准备(orientation)、起草(drafting)、修订(revision)三个翻译阶段中,发生的个体时长(individual duration)、文本消除(text elimination)、暂停时间(dwell time)以及产出译本的平均句长(mean sentence length)等作为参量,对比考察语内/语际翻译过程中的风格简化(stylistic simplification)现象及其制约因素[24]。该研究主题涉及描写性译学、语料库译学、认知翻译学、认知心理学等领域,跨学科特征显著。

图4 Translation process聚类概念层级图(部分)
(五)结构性变异分析
传统意义上对于研究文献影响力及其潜在学术价值的考查多采用引文索引法,主要涉及访问数、下载数、引用数等定量因素,或者从作者名望、过往成果、机构/期刊声誉等定性视角入手。然而,前者由于数据的效度受时间影响明显,往往易于忽略对新发表文献的关注,后者则过于依赖外部因素,缺乏对研究观点、结论本身与其所在领域知识体系互动关系的考量。
CiteSpace提供的结构性变异分析(structural variation analysis)基于“科学知识的发展是新发表科学文献所承载的一系列新的思想与现有知识结构之间相互作用的过程”构架,以及“若一种新思想连接了之前互不相干的知识板块,则它比那些囿于现有知识结构中较为成熟路径的思想更具变革潜质”判断,以模块变化率(modularity change rate)、聚类间连接(intercluster linkage)、中心度发散(centrality divergence)为主要度量指标衡量新发表文献的影响力[25]。在analytics设置里勾选“SVA”选项,对共被引文献进行结构变异分析,依据以上指标筛选出40条文献,其变革轨迹显示,共被引文献中《Towards a Corpus-Based, Statistical Approach to Translation Quality: Measuring and Visualizing Linguistic Deviance in Student Translations》一文最具变革潜质(聚类间连接0.46,变革连接21),该文献基于语料库及相关数理统计方法,以专业译文为比照,确立对学生译文的语言及文本评价指标,并通过原/译文语言特征对比衡量译文的可接受度,结论显示学生译文中的语言变异行为源于对译入语语言规范及惯例的背离,造成译文整体质量下降,对于学生个体译文可接受度的评价则表明,学生译文和依据专业译文所建立的规范之间的语言距离与译文质量呈负相关[26]。研究连接了翻译质量、翻译语言特征、翻译规范、翻译教学等领域,语料涵盖小说、新闻等文体,且涉及英、法、荷三种语言,是系统探索译文可接受度量化考查方法的尝试。文献《Using Translation and Parallel Text Corpora to Investigate the Influence of Global English on Textual Norms in Other Languages》运用复合型语料库从功能偏向、共性特征、信息结构、语序差异等,综合考察了英语—德语语言中英语原语对德语翻译语言的文本规范所造成的影响[27]。该研究以语料库方法探索翻译活动带来的语言变化,为译学研究提供了新的路径,具有较高变革潜质。《Corpus-Based Studies of Translational Chinese in English-Chinese Translation》一文结合平行/平衡及可比语料库,研究英语—汉语语言对中汉语翻译语言特征[28],是对以往较多关注英语—印欧语系语言对,以及以英语为中心研究翻译语言特征/翻译共性的重要拓展。此外,引起结构变异的代表文献还有Hassani、Kruger、Rodriguez-Ines、Jimenez-Crespo、Peraldi等发表的文献[29-33]。
四、内涵与意义
语料库译学研究基于翻译/平行/可比等译学用途语料库,通过对大量文本语料进行数据统计,从而系统分析考察翻译现象及其内在规律。该范式汲取语料库语言学和描写性译学的养分,将对翻译语言特征及相关翻译现象的考查置于语言学诠释和社会文化因素互动关系研究的双重视域下,可视为语言学范式和文化范式的有机结合[34]。
从本体论上看,语料库范式若要引领译学研究的再一次范式转向,势必对解构主义引发有关“翻译本体”的争论做出回应。“文化范式”的倡导者和批评者各执一词,前者将翻译视为特定语境下涉及诸多制约因素的文化交际,反对传统翻译理论的二元性及忠实、等值等价值取向;后者则认为其过度依赖外部因素的理论偏向及改写、操纵等激进论调,“将翻译本体研究消解于文化研究之中”[35]。以上分歧的核心在于不同理论体系下译论范式的不可通约性,且若细辨翻译本体和翻译研究本体之间的关系[36],则不难发现无论将翻译视为独立的语言行为还是文化存在,抑或是对语言转换、文化互动研究持厚此薄彼的态度,对于译学研究皆无裨益。语料库范式认为翻译是一种以语言文化为载体的社会现象,将译语特征、翻译现象/事实的语言学阐释和外部因素的互动关系考查置于同等地位,其对翻译本质、翻译研究方向及范围的重新审视和定义,对于译学独立学科的构建具有里程碑意义。
从认识论上看,语料库研究范式的兴起反映了20世纪50年代以来语言研究领域唯理论与经验论对立发展的结果——经验主义的回归。唯理论的代表Chomsky及其转换生成语法将一切对语言的认识归源于理性,主张通过“直觉”构造素材对语言进行描写和解释,从而把握人类习得语言的能力及生成言语事实的规则。相反,在英国传统语言思想中经验处于决定地位,真实文本/语言事实为研究的起点,对语言行为的关注则是核心问题。此外,结构主义语言学从言语事实归纳语言共性的研究肯定了真实语言素材的作用。译学研究受语言学范式的影响,理性主义、经验主义兼而有之,以往的技术条件很大程度上限制了语料的收集,造成后者长期处于弱势。一方面,现今语料库技术的进步使得大规模数据采集成为可能,语料的标注不再限于词性、句法、元信息等表层/结构信息,对语言特征、翻译/文化信息的标注成为重要议题,语料效度得到极大提升,实证研究已然不可或缺;另一方面,对翻译语言/事实/现象的描述和阐释同样依赖现有理论或研究者的内省推理,经验主义与理性主义的融合亦成大势所趋。
从方法论上看,语料库方法主要表现为实证研究下的假设检验(hypothesis testing),具体步骤包括提出假设、设定目标、检验假设、分析数据、理论阐述、假设精确化、提出新假设等[37],其中前三者和后四者分别体现了自上而下与自下而上的研究路径及演绎和归纳的逻辑方法,形成了基于语料库、语料库驱动两种基本研究路径。总体而言,语料库方法可视为定量、定性方法的有机结合,相较以往以定性为主的研究更具客观性、科学性。语料库方法用于译学研究,基于对大量真实语料的数据提取、检验和分析,系统考察描述翻译事实,阐释其成因及内在规律,从而对现有译学理论/假说进行证实/伪或提出新的理论构想。其传统研究模式为借助平行/可比语料库的平行/类比模式,随着研究对象和研究情景的拓展,以及研究重心由描写向阐释转变,基于语料库的语言变化与多重复合对比模式逐渐成为主流。
五、结语
自发轫以来的近三十年间,语料库译学经历了从研究路径到研究方法论再到研究范式的演变进程,形成了自身较完善的理论框架和相对固定的研究模式,在国际学界拥有广泛、稳定的学术群体,并且取得了颇为丰硕的研究成果。语料库译学将翻译作为一种以语言文化为载体的社会现象,置于语言学阐释和社会文化因素互动研究的双重视域之下,在本体论和认识论上是对以往研究范式的继承与革新,定量与定性相结合的实证研究方法极大增强了相关研究的科学性和解释力。综合来看,不失为解决当下译学范式危机的有效出路。
继概念形成、学科地位确立之后,语料库译学已开始“向各个文化延伸”[38],或者说进入了研究能力和范围不断增强拓展下的“扩散阶段”[39],其学科内部的发展促使研究不断深化,与相邻学科间的融合触发多元视角,并催生新的领域。翻译语言特征的考查由表层形式的数理分析发展到对深层语义结构的探索;翻译共性的研究重心由分析—描写转向对其动因的解释,以及翻译作为一种“语言接触”对目的语的影响;翻译实证研究不断尝试将语料库工具与其他学科研究方法结合,全面关注翻译的过程、产品及功能。语言、文化、社会、认知等因素的多维交织及研究方法的交叉综合,凸显语料库译学研究的跨学科性质,对跨学科研究团队的建立提出了要求。
