一种基于时空位置预测的空间众包任务分配方法
2022-02-11徐天承乔少杰易玉根黄发良元昌安
徐天承 乔少杰 武 俊 韩 楠 岳 昆 易玉根 黄发良 元昌安
1(成都信息工程大学软件工程学院 成都 610225) 2(西南财经大学证券与财经学院 成都 610074) 3(成都信息工程大学管理学院 成都 610225) 4(云南大学信息学院 昆明 650500) 5(江西师范大学软件学院 南昌 330022)6(南宁师范大学计算机与信息工程学院 南宁 530023)7(广西教育学院 南宁 530023)
众包的概念源于“外包”、“承包”,外包与承包强调的是专业化团队长期稳定的合作,而众包则不同,将复杂的任务拆分为细粒度的任务,调动个体用户积极参与,寻求跨专业领域知识为工作成果带来创新.当前移动和可穿戴设备的普及不仅丰富了人们的日常生活,同时开辟了一种新的工作模式:空间众包(spatial crowdsourcing).空间众包相较传统众包,需要众包工作者在真实世界中,物理移动到任务所标注的特定地点,完成任务要求,这一模式在生活中存在广泛的应用场景(例如:滴滴打车、美团众包),它可以帮公司企业节省大量成本.
空间众包框架中任务请求人可以通过众包平台发布空间任务,例如观察咖啡店是否拥挤、监控某条路段的交通状况等,并交付给真实世界中的众包工作者来完成空间任务.服务器需要基于空间任务和众包工人的位置以及其他约束对其进行分配,这一过程被称为众包任务分配问题.在真实的空间众包平台中任务和工人都是动态出现的,如果不考虑任务/工人的动态性,则无法获得最佳的分配结果.而现实生活中众包任务的发布和众包工人的登录往往具有非常复杂的动态规律,使得传统的机器学习和统计学方法难以对任务/工人的发布分布进行准确预测.
通过分析滴滴出行分享的GAIA数据集,可以发现每天同一地点的任务发布数量均是随时间呈周期变化的.如图1所示,该图统计了以各兴趣点(point of interest, POI)为中心,半径500 m内每日不同时间发生的任务数量.横轴为按小时划分的一天,纵轴为任务发布的数量.每个种类的线均有7条,代表一周内的7天,每种线后的阴影区域代表该POI处发布任务数量随时间变化的趋势.从图1中可以发现,景点2附近在19点时大概率会出现任务数量的下降,而景点1却没有这种现象;火车站每日的任务数量高峰期在16~18点产生,而景点1一般在19~23时达到高峰.这表明,同一区域每日任务发布的数量具有相似的变化走势.通过上述分析,可以得出结论:进行未来时刻任务时空分布预测时需要依据过去的任务分布,将时间和空间作为预测所需的特征学习.
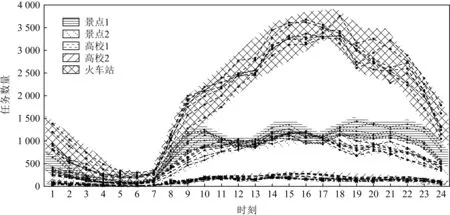
Fig. 1 Quantity trend of different released POI tasks图1 不同POI任务发布数量趋势图
目前已有许多关于空间众包任务分配的研究,但现有的空间众包任务分配方法通常存在2个方面的局限,有待进一步完善.
1) 传统的任务/工人分布预测方法很少使用工人和任务的时空特征,且一般基于网格进行预测,但网格的不同划分会影响到预测结果的准确性,并且很难找到最优的网格划分方法.本文提出基于轨迹的任务分布预测方法和基于二维核密度估计的工人分布预测方法,学习历史数据中任务/工人的时空特征,实现更精确的任务分配.
2) 空间众包需要较快的任务分配效率,面对大规模的时空数据,计算分配的时间代价过大会导致结果没有应用价值.本文提出了一种基于任务/工人预测进行任务分配的方法,以最大化目标函数为目的,可以在线性时间内得到有效的任务分配结果.
针对上述不足,本文对在线情景下空间众包任务分配问题进行了研究,设计了一种基于位置预测的空间众包任务分配方法,可以有效地计算全局最优的任务分配问题.本文的主要贡献有3个方面:
1) 提出了基于轨迹的任务分布预测模型.不同于网格划分的整体分布预测方法,本文基于拐点划分轨迹,使用轨迹聚类算法获得高流量的热点轨迹,基于轨迹使用图卷积来捕获任务分布的空间特征,并使用核密度估计预测任务在轨迹上发布的具体位置,给出了计算预测所得任务价值的方法,方便后续任务分配时寻找最优解.
2) 提出基于核密度估计的工人分布预测模型.先通过二维核密度估计来表示空间任务的分布,使ConvLSTM能更好地提取任务分布的空间特征,对于预测得到的空间分布核密度估计矩阵,提出了一种基于消减数量的方法来还原真实的任务分布.
3) 提出了一种基于位置预测的任务分配方法.依据任务和工人间的位置关系,计算每个任务的可用工人集,以此来创建二分图,设定搜索增广路径上限次数,优先选择权值高的任务进行分配,并针对预测任务设置了单独的权值比较方法,能在多项式时间复杂度内寻找尽可能好的任务分配组合.
1 相关工作
与传统众包技术不同,空间众包需要基于位置信息进行工人任务间的分配.按照任务复杂度可将任务分为原子任务和复杂任务2种,原子任务可视为能由一位工人完成的简单任务,复杂任务可以划分为多个原子任务,需要多种特定技能才能完成,本文将任务设定为原子任务.按照任务发布模式,可分为服务器分配任务(server assigned tasks)模式和工人选择任务(worker selected tasks)模式2种,现有的空间众包系统大多使用服务器分配任务模式,在该模式中由服务器将任务分配给适当的工人,这种方法相较后者可以尽可能地减少无人接受的任务,并实现一些系统优化目标,如:技能覆盖且成本最小.按任务的物理位置,可以分为特定点、特定区域和特定路线3种,这3种任务位置种类分别要求:到达一个特定的坐标点,到达特定的建筑区域,从起始点提取特定物品交付给目标客户.为了简化问题,现有的研究大多是基于特定点的众包任务研究.按照服务器分配策略中数据的状态,可以分为离线场景和在线场景,离线场景下服务器在一开始就可以获取完整的信息,在线场景下工人和任务的登录信息是动态的,算法将以数据流的形式接受工人和任务的登录信息.现有的大部分研究都是基于离线场景的假设,没有考虑到空间众包任务分配的时空特性,不能得到全局最优分配结果.
文献[7]首先提出了空间众包平台上的任务分配问题,设定服务器统一管理所有的任务和工人位置信息,以最大化任务分配数量为目的利用贪心策略将任务分配给各个工人.文献[8-11]仅考虑了当前系统中存在的工人和任务,忽略了动态变化的任务和工人,无法得到最优的分配策略.文献[12]最大化工人的收入为目标,并针对任务的动态性设计了一种平衡影响因素的路线推荐算法,但是该算法没有考虑动态加入系统的工人.文献[13]提出了一种基于位置熵最小优先级的候选工人算法,通过计算曼哈顿距离获得候选工人,再基于决策树进行任务分配;文献[14]考虑到工人是动态移动的,设计了贪心算法和极值算法2种近似算法,并提出了一种基于反馈的合作机制进行任务分配;但文献[13-14]均忽略了动态加入系统的任务.文献[15-16]以在线算法(online algorithm)的方式来解决新加入系统的空间众包任务分配问题.文献[15]考虑工人—项目—任务的三色效用,设计了基于skyline查询的解决方案;文献[16]提出了一种基于空间感知多智能体的动态优化算法,并通过基于网格的空间优化方法来分解众包问题,以便解决大规模数据;但这些方法的时间复杂度较高,难以应用于真实的众包平台.文献[17]通过预测的方式预估工人和任务在未来时刻的空间分布,基于预测得到的数据以最大化分配质量分数为目标,基于贪心算法进行分配.文献[18]提出了三阶段的启发式算法求解最佳任务分配,通过预估每个工人的可用时间预测工人未来时刻的轨迹,尽可能地最大化工人完成任务的数量,使得工人的移动距离均匀.但上述基于预测的方法没有考虑到任务的分布与时间变化的关系,且在分布预测中均使用基于网格的预测方法.本文将以最大化分配价值,最小化工人移动距离为目标设计任务分配方法.
2 问题描述
本文要解决的问题中包含2种实体对象,在一个时间实例集P
={1,2,…,p
,…}中,实体定义如下:定义1.
空间任务t.
表示为t
=〈t.s
,t.l
,t.e
,t.v
〉是一个在t.s
时刻发生t.l
位置的任务,该任务在t.e
时刻前完成被认为是有效的.
完成该任务后会产生t.v
的价值,其中t.l
为真实空间中的坐标(x
,y
),实验中将其视作二维数据空间的一个点.
定义2.
众包工人w.
表示为w
=〈w.l
,w.v
〉,表示一个在时刻p
位置在w.l
处的众包工人,其移动速度为w.v.
为简单且不失一般性,本文假设每个空间任务只需要分配一个众包工人,任务需要的处理时间为0,即众包工人只要到达任务处即完成任务.
定义3.
最大价值最小成本任务分配问题.T
为时刻p
系统中现有的空间任务和预测得到的空间任务组成的集合;W
为时刻p
系统中现有的众包工人和预测得到的众包工人组成的集合;I
为时刻p
的任务分配集,由一组有效的〈t
,w
〉分配对组成,其中t
∈T
,w
∈W
,分配对〈t
,w
〉需要满足工人能在任务截止时间前到达任务所在的位置,且同一时间一个工人只能被分配到一个任务.
基于任务和工人相关定义,最大价值最小成本任务分配问题可以定义为:在给定的时间实例集P
中,最大价值最小成本任务分配问题的目标为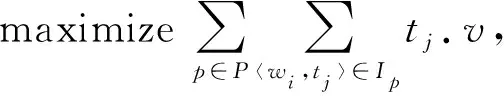
(1)
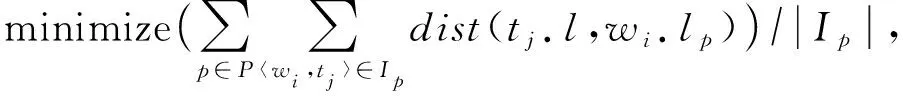
(2)
其中,dist
(t.l
,w.l
)表示任务t
到工人w
的欧氏距离,真实情景下的轨迹分布难以类比为“棋盘格”状,利用曼哈顿距离计算得工人距离并不准确,本文计算dist
(t.l
,w.l
)是为了对比不同分配间距离的相对大小进行择优,使用欧氏距离计算的效果更准确,故本文选择使用欧氏距离作为不同分配对间的成本度量.
|I
|表示分配对的个数.
最大价值最小成本任务分配问题的目标是最大化分配集I
的价值和,并最小化分配集I
中众包工人到空间任务的平均距离.
3 基于轨迹的任务分布预测模型
空间众包中任务的出现受物理世界中时间和空间因素影响,其中任务请求人的行为模式在任务分配中发挥关键作用.空间众包平台中,众包工人接收任务后需要移动到任务标注的位置,可以认为众包任务的发布位置依附于众包工人的轨迹,分析数据集可知不同地点的任务发生数量按时间呈周期性的模式变化.本节给出一种基于图卷积神经网络的模型,该模型利用轨迹聚类捕捉任务分布时间空间相关性,可以高效地估计未来的任务分布及数量.
3.1 基于轨迹的位置信息提取
受到Lee等人提出的分段及归组框架通过轨迹挖掘得到路网信息的启发,本节通过基于特征点的街角提取(characteristic point-based road corner extraction, CP-RCE)选取工人轨迹中的拐点,使用拐点划分轨迹,并设定轨迹间的距离函数使用DBSCAN算法得到处理后的轨迹图.此外,分时段选出任务发生数量高于阈值的轨迹,作为预测任务发布位置的基础,通过后续模型学习其中的空间特征进行任务分布的预测.由图1的分析可知每日不同POI中任务发生的数量随时间变化的趋势是相似的,可以认为每日相同时间段有相同的任务分布模式.假设前后两日拥有相似的任务分布模式,那么在第a
日的p
时使用的图结构是基于第a
-1日的p
时的数据生成的.本文提出的基于轨迹的位置信息提取方法包含如下2个关键步骤.1) 提取轨迹拐角.通过分析数据集中的GPS轨迹,使用基于特征点的街角提取方法提取轨迹中的拐角.具体的说,CP-RCE方法以定宽的窗口来遍历GPS轨迹,在中心点的左右通过线性拟合的方法生成2条直线,通过计算轨迹点在两直线上投影间的夹角,夹角大于阈值的轨迹点就是代表拐角的特征点.
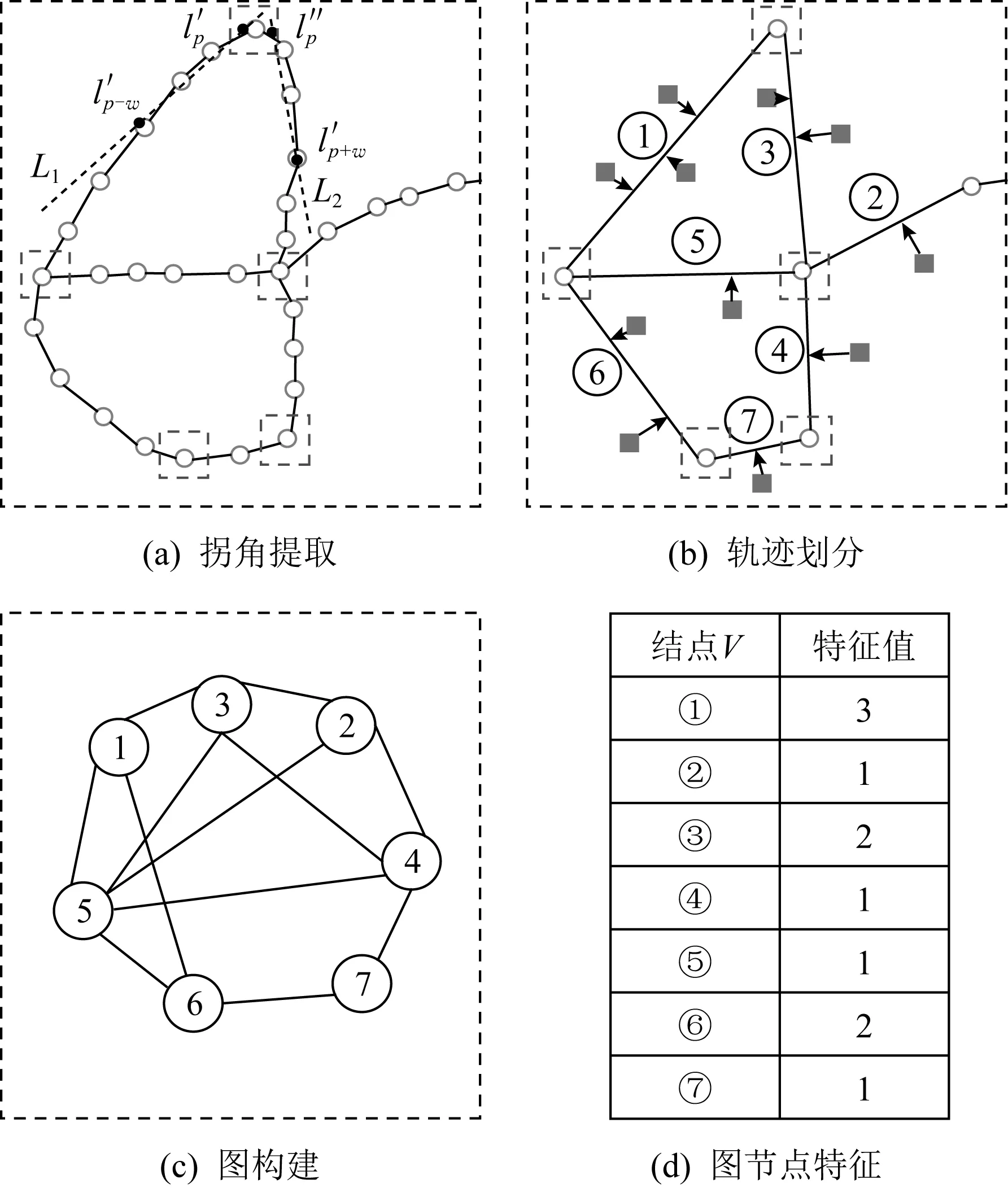
Fig. 2 The process of graph construction图2 图构建过程

G
=(V
,E
),以图的形式来存储轨迹信息.
图G
中的V
为结点集,将轨迹聚类后得到的每一条轨迹视作一个结点,故轨迹的个数就是图G
中结点的个数;E
为边集,如果2条轨迹间有连接,则两结点间就有边.图使用邻接矩阵和特征矩阵存储.邻接矩阵表示各结点间的连接关系,邻接矩阵的值为0或1,如果两结点之间有连接则为1,反之则为0.特征矩阵包含各结点代表路段的特征信息,数据空间中众包任务视作发生在最近的轨迹路段,p
时结点的特征值为p
时内轨迹路段上发生的任务数量.图2(b)图所示的轨迹被5个拐点划分为7条路段,分别被标记为①~⑦,方块代表空间众包任务.最终生成的图结构如图2(c)所示,将各任务划分到距离最近的轨迹路段上,可得到各结点的特征值如图2(d)表格所示.如果图有很多结点的特征长时间为0的结点,会影响模型的效果.为提高模型预测的效果,在每一时间段筛选掉任务发布数低于阈值的轨迹路段,将这些轨迹代表的结点从该时段中删除.3.2 基于图卷积的任务分布预测模型
本节将基于3.1节得到的图结构数据通过基于图卷积的任务分布预测模型来预测路段的流量,再使用核密度估计的方法预测各路段任务发生的具体位置,最后给出了预测要发生价值的方法.具体为如下3个步骤:

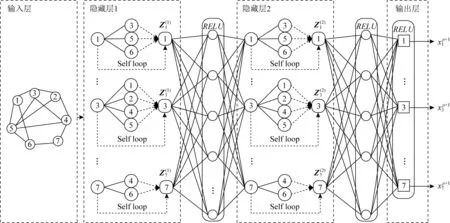
Fig. 3 Prediction model of task distribution图3 任务分布预测模型
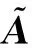
(3)
(4)
=ReLU
(·ReLU
(··)·),(5)
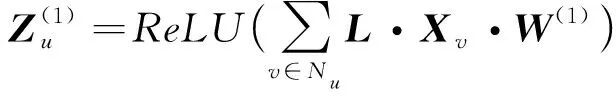
u
=1,2,…,k
),(6)
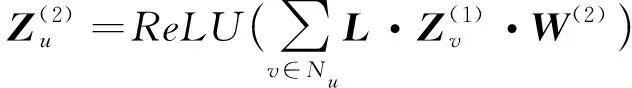
u
=1,2,…,k
),(7)
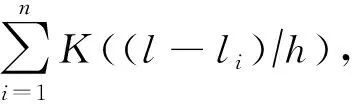
h
={R
(K
)}(15)/
{m
(K
)}(25)R
(f
″)(15)n
(15),(8)
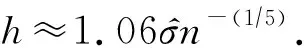
l
,l
,l
.
使用核密度估计函数f
计算可以得到任务发生位置的概率密度函数f
(x
) 如图4(b)所示.
假设预测得到下一时刻任务发布的数量为m
,路段从上至下的两侧的端点坐标为(x
,y
)、(x
,y
),概率密度函数f
(x
)前m
高的横坐标集合X
={x
,x
,…,x
,x
+1,…,x
},则预测得到的m
个任务发布坐标(x
,y
)可通过式(10)得到:
(9)
(x
,y
)=
(10)
其中,d
为轨迹路段的长度,(x
,y
)和(x
,y
)分别表示轨迹路段左端点和右端点的坐标,d
由轨迹路段两端的坐标求欧氏距离计算;(x
,y
)为轨迹路段上预测得到的第i
个点的坐标,i
的取值为1到m.
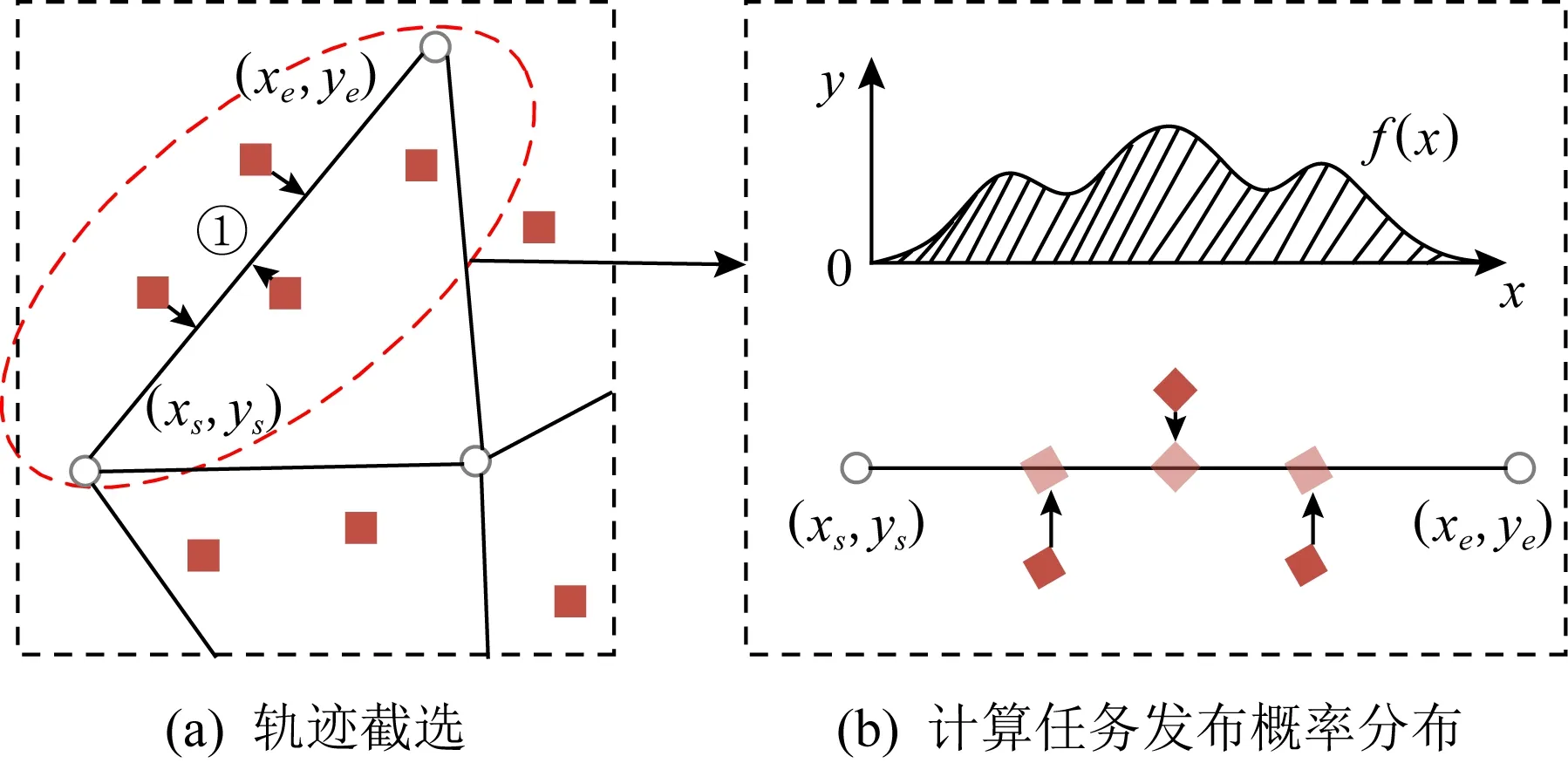
Fig. 4 Diagram of specific location prediction of task publishing图4 任务发布具体位置预测示意图


(11)

(12)
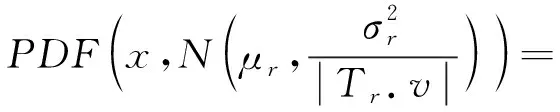
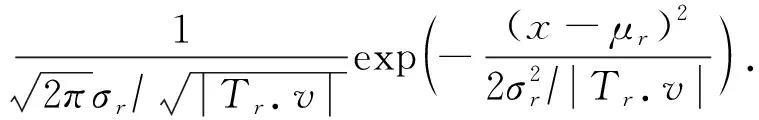
(13)
任务价值的预估可分为如下3种情况:
(14)
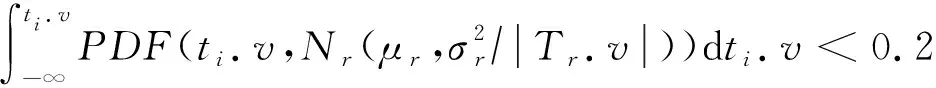
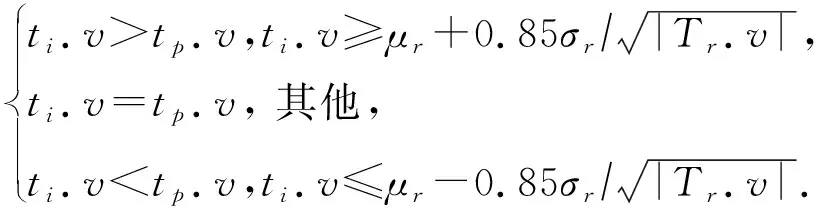
(15)


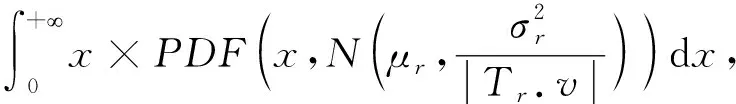
(16)
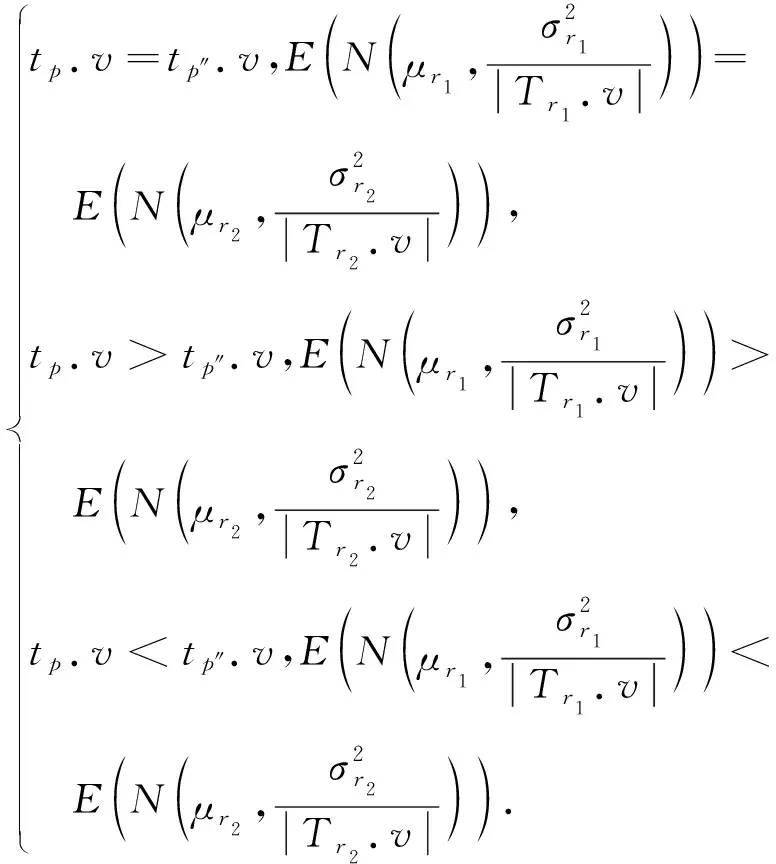
(17)
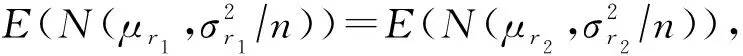
4 基于核密度估计的工人分布预测模型
由于空间众包系统中工人位置信息的强时效性,为了实现全局更优的分配,需要对新加入空间众包系统的工人的位置信息进行精确预测.本节将介绍一种基于ConvLSTM的工人签到位置预测方法,它可以有效地估计未来时刻工人的数量和位置分布.工人分布预测过程的总体结构图如图5所示,从左向右,首先通过二维核密度估计进行过去时间工人签到位置分布平滑化处理,使得ConvLSTM模块可以更容易地提取到空间分布的特征.然后,构建基于ConvLSTM的2层网络模型,在输入层按照定宽的窗口滑动划分各时刻的二维核密度估计矩阵,得到时序的核密度估计矩阵投入模型,经过隐藏层的ConvLSTM模块提取空间特征,接着通过输出层预测得到下一时刻的工人分布的二维核密度估计矩阵.最后,通过删减策略的数量还原过程来精确预测未来时刻工人位置的分布.
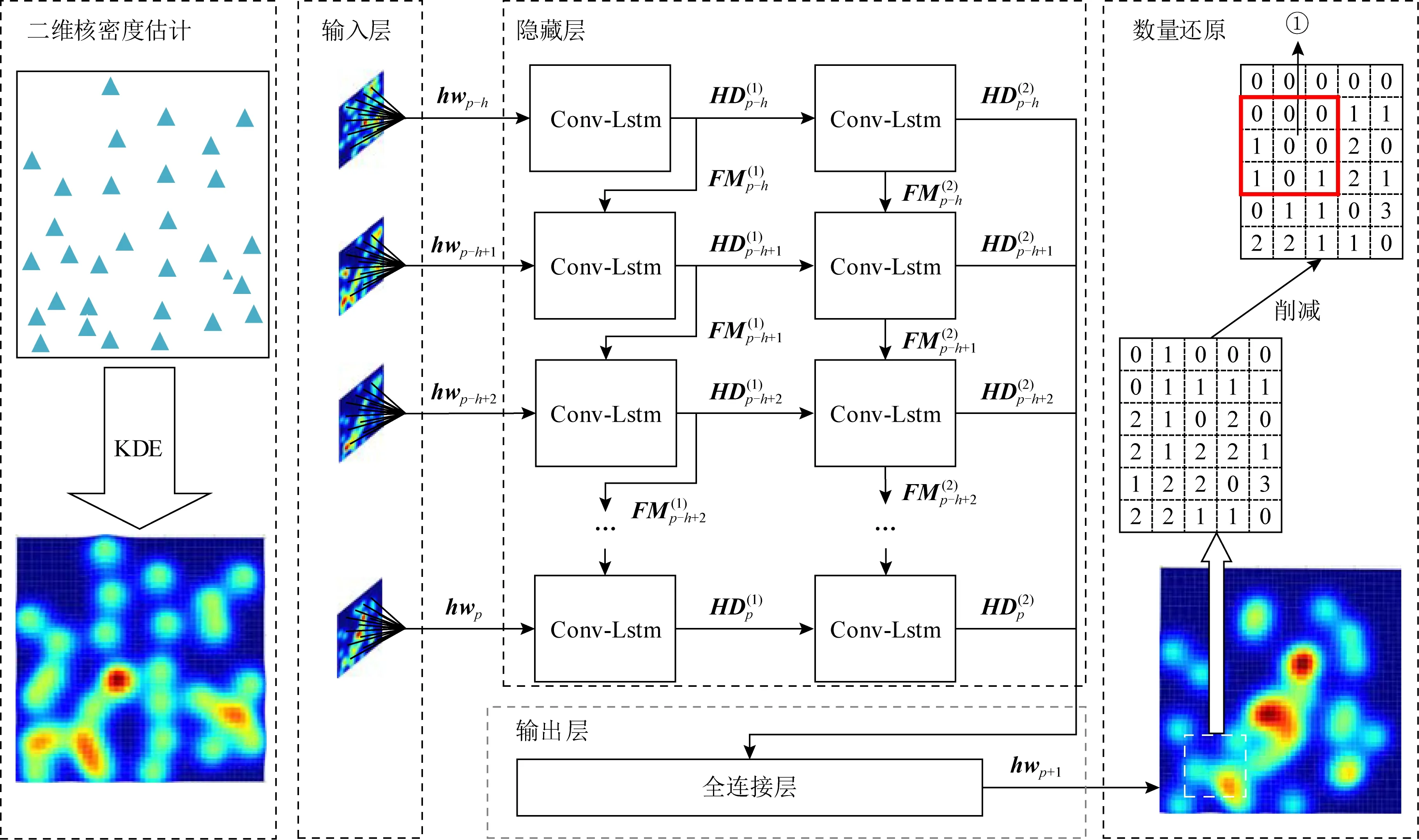
Fig. 5 Working mechanism of worker distribution prediction图5 工人分布预测工作原理
4.1 二维核密度估计位置分布
本节将任务的位置分布信息使用其二维核密度图进行表示.
将真实世界的地图视作一个U
=[0,1]的二维数据空间,对于每个时间实例的工人签到位置分布样本,使用二维核密度估计可以得到工人分布的概率分布曲线.
对数据空间U
中的概率分布曲线进行模拟,数据空间二维长度均为0到1,如果不对估计函数归一化处理,数据空间中对应位置的函数值就是该位置可能签到的工人数量.
二维核密度的估计函数为
K
((x
[dim
]-x
[dim
])/H
),其中,K
(·)为核函数,dim
表示维度(dim
=1表示二维数据空间的第一维),由于后续分配工人时会对核密度估计矩阵进行向下取整的操作,为避免向下取整丢失较大的小数值(比如1.
9取整为1)此处使用均匀核函数K
(x
)=1/
2,-1≤x
≤1,H
为平滑参数带宽,计算方法与3.
1节中计算核密度估计滑窗的方法类似(H
,H
需要分别计算).
通过如图5所示方法可以得到工人的分布矩阵,该步骤如图5中二维核密度估计部分所示,得到的分布矩阵类似图中的热力图,核密度估计将稀疏的样本通过带宽H
扩散到相邻区域,使得工人分布矩阵密度变高,方便后续卷积过程更好地捕捉工人空间分布的特征.
但也是由于该原因,工人矩阵中的数量和并不是真正的工人数量.
4.2 基于ConvLSTM的工人分布预测模型
本节将通过工人分布预测模型提取工人分布核密度估计矩阵的时空特征来预测下一时刻的工人分布,并基于核密度估计原理复原真实工人数量,具体分为如下2个步骤:
1) 工人预测模型网络结构.由于ConvLSTM模型在时空数据特征提取上性能较佳,本文将其应用于预测众包工人登录位置分布.在ConvLSTM中,要预测时间实例p
+1时的工人位置分布,需要基于设定的滑窗宽度s
输入一组过去工人分布的核密度估计矩阵的时间序列H
={-,-+1,…,-1,},H
表示核密度估计矩阵的时间序列,为时刻p
的核密度估计矩阵.
时间序列H
为图5中输入层的输入.
网络结构中各参数的形式化表达如式(18)~(23)所示:=Sigmoid
(Conv
(;)+Conv
(-1;)+),(18)
=Sigmoid
(Conv
(;)+Conv
(-1;)+),(19)
=Sigmoid
(Conv
(;)+Conv
(-1;)+),(20)
=Tanh(Conv
(;)+Conv
(-1;)+),(21)
=⊙-1+⊙,(22)
=⊙Tanh(),(23)
其中,⊙符号表示矩阵的哈达玛乘积,,,分别表示输入门、遗忘门、输出门3个门的程度参数,是常规循环神经网络(recurrent neural network, RNN)步骤得到的特征,为短时记忆,表示长时记忆,/
分别为输出给下一单元/
最后输出的特征.
在隐藏层网络中,如图5隐藏层部分,各ConvLSTM单元的长期记忆随着输入序列时间方向传播,各单元的输出随网络的深度方向传播.
经过2层网络提取的时空特征,输出结果经图5中输出层的全连接网络后,可以预测得到p
+1时刻的工人分布核密度估计矩阵+1.
2) 复原真实工人数量.
通过上述步骤预测得的工人分布核密度估计矩阵+1是p
+1时刻工人分布的核密度估计矩阵,分配工人前需要先对矩阵进行取整操作.
根据核密度估计的原理,核密度估计矩阵是通过核函数K
(·)以带宽H
对每一个样本进行观察,并拟合样本点附近的概率,将所有的概率密度函数合并得到的,故每个样本影响概率分布的范围为±H
.
所以,核密度估计矩阵中对应位置的值并不是真实工人数量,若要得到+1中的真实工人数量,需要在减少矩阵某位置的数量时,同时减少该位置±H
范围的值.
复原真实工人数量方法如下:假设核密度估计时使用的H
为矩阵的len
个宽度,如果分配矩阵中(i
,j
)位置的一个工人,需要将(i
,j
)位置和{i
-len
,…,i
,…,i
+len
}⊗{j
-len
,…,j
,…,j
+len
} (⊗表示笛卡尔积)中元素位置中工人数量大于零的部分全部减少1.
以图5中数量复原部分使用虚线框截取矩阵中的一部分为例,箭头连接的矩阵为该部分工人的分布矩阵,矩阵中的数字表示对应位置的工人数量.
通过模拟分配2个工人的过程来展示消减数量策略的过程,如图6所示: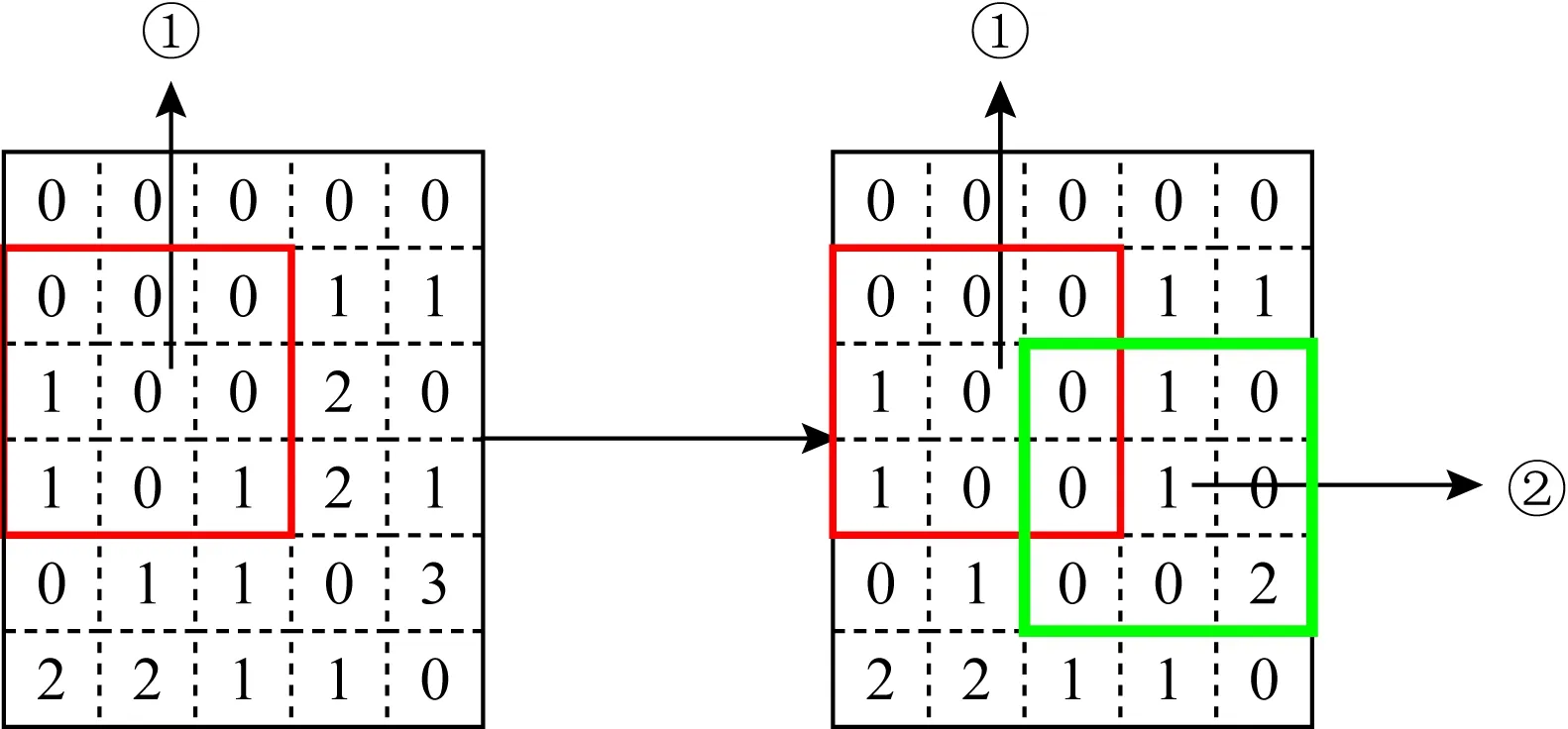
Fig. 6 Example of quantity reduction图6 数量削减过程示例
首先,将图6中标注①的(3,2)位置处的1个工人进行分配,假设进行核密度估计时计算出的H
在核密度估计矩阵中宽度为1,则以集合{2,3,4}⊗{1,2,3}={(2,1),(2,2),(2,3),(3,1),(3,2),(3,3),(4,1),(4,2),(4,3)}的九宫格内,数量大于零的位置工人数量均要减少1;将标注②的(4,4)位置处的1个工人进行分配,矩阵中{3,4,5}⊗{3,4,5}={(3,3),(3,4),(3,5),(4,3),(4,4),(4,5),(5,3),(5,4),(5,5)}位置的网格中人数均减1.
分配可以持续到矩阵所有位置的数量都为0.
5 基于位置预测的任务分配算法
传统的任务分配问题一般可视为最大流问题,本文提出的最大价值最小成本任务分配问题可以分类为一种包含位置预测数据,任务为结点和工人为权值的二分图最大流问题,并且结点和边均带权值.解决最大流问题的传统算法有匈牙利算法和Kuhn-Munkras算法,若图中结点有|V
|个,边有|E
|个,则前者的时间复杂度为O
(|V
|×|E
|),但不能解决带权值的二分图最大流问题,后者可以解决带权值的二分图最大流问题,但时间复杂度为O
(|V
|),难以应用于现实场景.传统的方法没有完全适配本文问题的求解方法.故本节提出一种基于贪心算法和匈牙利算法的启发式算法,通过搜索任务的可用工人集,构造二分图,尽可能寻找符合目标函数式(1)(2)的最优分配.定义4.
任务可用工人集.
在理想的众包系统中,每个空间任务的有效工人集由任务需要的技能和工人拥有的技能、工人的可信度等几个因素决定,但现有的数据集中缺少这几种属性,故本实验中仅考虑工人是否可以在任务结束前到达任务位置(不考虑工人执行任务的时间).
在p
时,若已存在系统中和预测将要加入系统的空间任务和众包工人分别有M
和N
个,空间任务t
的可用工人集表示为AW
,且应该遵循以下条件:∀w
∈AW
,1)dist
(t
,w
)≤(t.e
-p
)×w.v
;
ind
(w
,t
)表示一个指示器,若工人w
被分配给任务t
,则ind
(w
,t
)=1,否则ind
(w
,t
)=0;dist
(t
,w
)为任务位置t
.l
到工人位置w
.l
之间的欧氏距离,若任务t
为预测得到的任务,则任务位置t
.l
为式(4)计算得到的坐标(x
,y
),若工人w
为预测得到的任务,则任务j
的位置w
.l
为任务j
所在核密度矩阵位置对应网格处的中心坐标.
5.1 基于预测数据的任务分配算法
假设时间序列P
中系统中一共存在任务及工人分别有M
和N
个,算法目的为在多项式时间复杂度内将N
个工人分配给M
个任务,并使分配对间的平均移动距离尽可能低,分配对的总价值尽可能高.
算法1给出基于预测数据的任务分配算法的伪代码.
算法1.
基于预测数据的任务分配算法.输入:时间序列P
={1,2,…,p
,…}、时刻p
任务集T
、时刻p
工人集W
;输出:任务分配集I.

p
=1 ton
then③T
←T
+T
,W
←W
+W
,T
←∅,W
←∅;④I
←∅,W
←∅,T
←∅,C
←∅;
t
,w
〉在时刻p
存在 then⑦I
←I
+〈t
,w
〉;⑧ else 将已有的对象加入T
或W
;⑨ end if
⑩ end for





i
←-1;













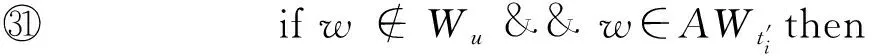





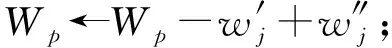















5.2 算法复杂性分析
本文算法中生成所有AW
的复杂度约为O
(N
×M
),分配步骤的复杂度约为O
(M
×logM
+M
×N
×logN
),故从整体的角度分析其平均时间复杂度约为O
(N
×M
×logM
),此处N
表示工人的数量,M
为任务的数量.

Fig. 7 Example of task assignment图7 任务分配示例
例1.
如图7所示,共有4个任务(t
~t
)和5个工人(w
~w
),任务的价值和工人到各任务的距离如表1和表2所示.
首先分配价值较高的空间任务t
,在t
的可用工人集中,距离最近的是工人w
,故首先将w
分配给t
.
然后分配价值为4的空间任务t
,在t
的可用工人集中,距离最近的是工人w
,并且w
没有分配给别的任务,故把w
分配给任务t
.
接着分配任务t
,t
可用的工人中距离最近的工人是w
,故将w
分配给任务t
.
最后分配t
,t
的可用工人w
和w
均已经被分配,故可以得出冲突任务集T
为{〈t
,w
〉,〈t
,w
〉},两冲突分配对的距离分别为2和4,首先尝试替换t
的分配,但t
没有其他可用工人,故选择替换〈t
,w
〉为〈t
,w
〉.
最终得到的分配I
={〈t
,w
〉,〈t
,w
〉,〈t
,w
〉,〈t
,w
〉},而剩余无法被分配的w
会留到下一时刻继续参与分配.
经过本文方法分配后,得到的总价值为14,平均距离为2.
75;而从价值高的任务开始遍历,每次选取距离最近工人的贪心法取得的总价值12,平均距离为3,14>12且2.
75<3,本文的方法明显更优.
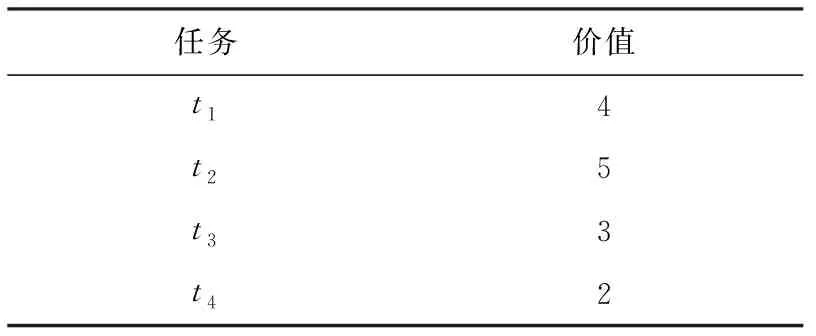
Table 1 Task Value

Table 2 Distance of Task and Worker
6 实 验
6.1 实验设置
本文实验部分使用滴滴盖亚开放数据计划提供的真实数据集,具体在滴滴提供的KDD CUP 2020网约车数据集上测试提出的算法.该数据集中包含30天的用户订单数据和司机轨迹数据,共有7 065 937个订单数据,来自1 181 180个司机的6 105 003条轨迹数据,数据均来自滴滴公司的网约车服务.本实验以该数据集范围内的区域(经度104.042 102°~104.129 591°和纬度30.652 828°~30.727 818°范围内的区域)作为实验的背景地区.实验将订单数据和司机轨迹数据分别视作最大价值最小成本任务分配问题中的空间任务和众包工人,具体地说,订单的发布时间视作空间任务的发布时间,订单的发布位置视作空间任务的发布位置,订单价值视作空间任务的价值;将每条轨迹的首个时间戳和首个轨迹点坐标视作一个众包工人的登录时间戳和登录位置.经过处理得到的数据集包含7 065 937个众包任务和6 105 003个众包工人.
本实验在该数据集上通过3.1节的轨迹聚类得到315个拐角和384条轨迹,经过图构建过程建立出一个384个结点,806条边的图(根据各路段间的连接情况得到).为验证所提方法的性能,对最大价值最小成本任务分配问题中需要但数据集里不存在的属性进行合成,本实验使用高斯分布来模拟每个任务的持续时间和工人的速度,此处任务持续时间指的是任务发布后的有效时间,也就是t.e
-p
,工人速度指的是工人的移动速度,也就是w.v.
如表3所示,任务持续时间和工人移动速度在N
((p
+p
)/
2,(p
-p
))和N
((v
+v
)/
2,(v
-v
))中随机取值.
实验中选择前20天的数据作为训练集,第21天的数据作为验证集,22~30天的数据作为测试集.

Table 3 Experimental Parameters
6.2 评价标准及对比算法
本实验根据预测结果的准确率以及误差来评估本文预测方法的有效性;以式(1)中定义的最大化总分配价值和式(2)最小化分配中工人到空间任务的平均距离目标,衡量分配策略的质量,并以最小化计算所消耗的CPU时间为目标,来衡量分配策略的效率.表3给出本文的实验参数设置,其中默认值以黑体显示.在实验过程中,每组实验都会改变一个参数,其他参数均会设置为默认值.
在本文的实验中,任务预测方法的有效性验证采取2种对比方法:1)单层图卷积网络(GCN-α).该方法使用本文3.2节中去掉隐藏层2的任务位置预测模型进行预测;2)基于网格的任务预测方法(grid-based task prediction, GTP).使用基于网格划分的方法划分数据空间,并在各单元格内使用线性回归的方法进行任务数量预测,并假设任务发生在单元格的中心位置.工人位置预测方法的有效性验证采取2种对比方法:1)不使用核密度估计处理工人分布图的ConvLSTM模型(ConvLSTM-α).该方法为本文的基于ConvLSTM的工人分布预测模型,去掉4.1节和4.2节(2)中二维核密度估计预处理和还原步骤的工人位置预测模型;2)基于网格的任务预测法(grid-based worker prediction, GWP).与GWP相似,网格划分数据空间,使用线性回归法进行工人数量预测.
分配方法的有效性和效率采用了2种基础的对比算法:1)贪心分配算法(greedy).以任务价值从高到低的顺序选择任务,每个任务均在其可用工人集中选择距离最短的工人进行分配,若没有可用工人集,则该任务当前时间实例无法分配.与本文基于预测数据的任务分配算法相比较,贪心分配算法把其中分配部分替换为贪心算法,平均时间复杂度约为O
(2M
×N
+M
×logM
).2)随机分配算法(random).随机选择一个任务,在其可用工人集中随机选择工人进行分配,若没有可用工人集,则该任务当前时间实例无法分配,该分配算法的平均复杂度约为O
(M
×N
+M
),其中M
为任务数量,N
为工人数量.本文所有实验均是在AMD Ryzen 5 3600 CPU@3.6 GHz,16 GB内存以及Nvidia GTX 1660s硬件条件下使用Python语言实现实验中算法.
6.3 工人和任务预测效果分析
本节实验对工人预测效果表现进行评估,并评估其对后续任务分配步骤的影响.使用前20天的数据作为训练集,后9天为测试集,并通过改变滑窗宽度和训练集大小,来测试模型准确度的变化,同时设定模型的其他参数如表3中默认值(加黑)所示 .
1) 滑窗宽度的影响.
首先通过改变滑窗宽度来评估工人和任务分布预测的准确性,实验的epoch设置均为100,分别使用平均绝对误差(mean absolute error, MAE)和均方根误差(root mean square error, RSME)2种误差来衡量模型的准确度情况,滑动窗口带宽的取值为4,6,8,10,12.如图8(a)~(b)所示,对于任务分布预测模型,可以观察到随着滑窗宽度从4增大到8的过程中,预测的误差略有下降,但从8增大到12的这个过程中,预测的误差基本上停止变化.这是因为在3.2节对任务预测的模型设定中,滑窗宽度代表投入模型的历史数据量大小.3.1节中基于时间划分不同模型一定程度上消除任务位置分布随时间变化的影响,对于任务位置预测模型来说不需要太多的历史数据进行学习.图8(c)~(d)中工人分布预测中滑窗宽度从8增大到12的过程中,误差反而有所增加,这是因为工人的分布随时间变化较为迅速,使用较多的历史数据反而会导致模型不能专注于近期的变化,产生较大的误差.总的来说,2个模型对于带宽的敏感程度都不大,且预测效果均较好(MAE和RMSE均小于1),根据实验结果选择默认的滑动窗口大小为8.

Fig. 8 Task/worker prediction model effect图8 任务/工人预测模型效果
2) 训练集大小的影响.
① 任务分布预测分析.通过改变训练集大小来评估工人位置预测算法的性能和该部分对后续任务分配的影响.数据集的前20天设定为训练集,训练集的大小取值为30%,40%,60%,80%,100%.对于任务位置分布预测,使用了2种对比方法:基于网格的任务预测方法(GTP),单层图卷积网络(GCN-α).为衡量模型性能,使用一种基于网格的准确率:将二维数据空间分为等大小的网格,通过比较单元中工作者/任务的估计数量q
′和实际数q
得出准确率ACC
=|q
′-q
|/q
×100%.为了测试位置预测效果对分配结果的影响,使用本文所提基于位置预测的任务分配算法,基于位置预测进行了任务分配,并计算了分配的总价值.在准确率评估实验中,在图9(a)中可以观察到,随着训练集变大,3种方法均有一定程度的准确率提升.本文方法的准确率从64.4%提升到了89.1%,比排名第2的GCN-α最终的82.1%高出了7个百分点,而GTP方法的准确率最后稳定在73.5%左右.在图9(b)中可以发现分配得到的价值随着3种方法准确率的增加均有明显上升.GCN-α和GTP方法在训练集从40%增加到60%的步骤中有较大的价值提升,这是因为训练集大小在30%~40%左右时,GCN-α和GTP的准确率仅有50%左右,导致产生了大量无效分配,在准确率提高后分配效果才有所提升.而本文方法的准确稳定在64%以上,故总的分配价值比较稳定.本文方法在3种方法中表现最好,原因在于本文方法使用轨迹路段作为预测任务分布的基础,相较GTP和GCN-α预测方法更加精细,更加符合工人接受任务的位置.
② 工人分布预测分析.对于工人的位置分布预测,对比本文方法选择了2种对比方法:基于网格的工人预测方法(GWP),不进行二维核密度估计的本文方法(ConvLSTM-α) .为了衡量模型性能,同样使用ACC
=|q
′-q
|/q
×100%做为准确率评价标准,与任务预测算法效果实验中相似,使用基于位置预测的任务分配算法进行任务分配,并比较分配的总价值.准确率评估实验如图10(a)所示,随着训练集增大,3种方法工人预测的准确率均有的增加.本文方法准确率最高,其次是GWP和ConvLSTM-α.原因在于本文方法通过核密度估计把数据空间划分为比GWP方法更精细的子区域,使用核密度估计弥补了工人分布矩阵的稀疏性,相较ConvLSTM-α方法中直接使用ConvLSTM提取时空特征的做法,可以更好的提取工人分布的空间特征.本文方法工人预测准确率最高可达73.6%,相比GWP方法高出18.8个百分点.ConvLSTM-α方法的准确率最终仅达到52.3%,这是由于没有经过预处理的工人分布图过于稀疏,模型不能提取到空间特征,导致预测结果不理想.图10(b)中,在训练集大小从30%增加到40%的过程中可以观察到基于ConvLSTM-α方法预测的分配结果反而有所下降,这是由于任务分配很大程度上依赖位置预测的结果,而ConvLSTM-α预测结果平均准确度仅有21%,较差的预测准确率会使分配得到的价值不稳定.

Fig. 9 Performance comparison of task prediction under different training sets图9 不同训练集下任务预测性能对比
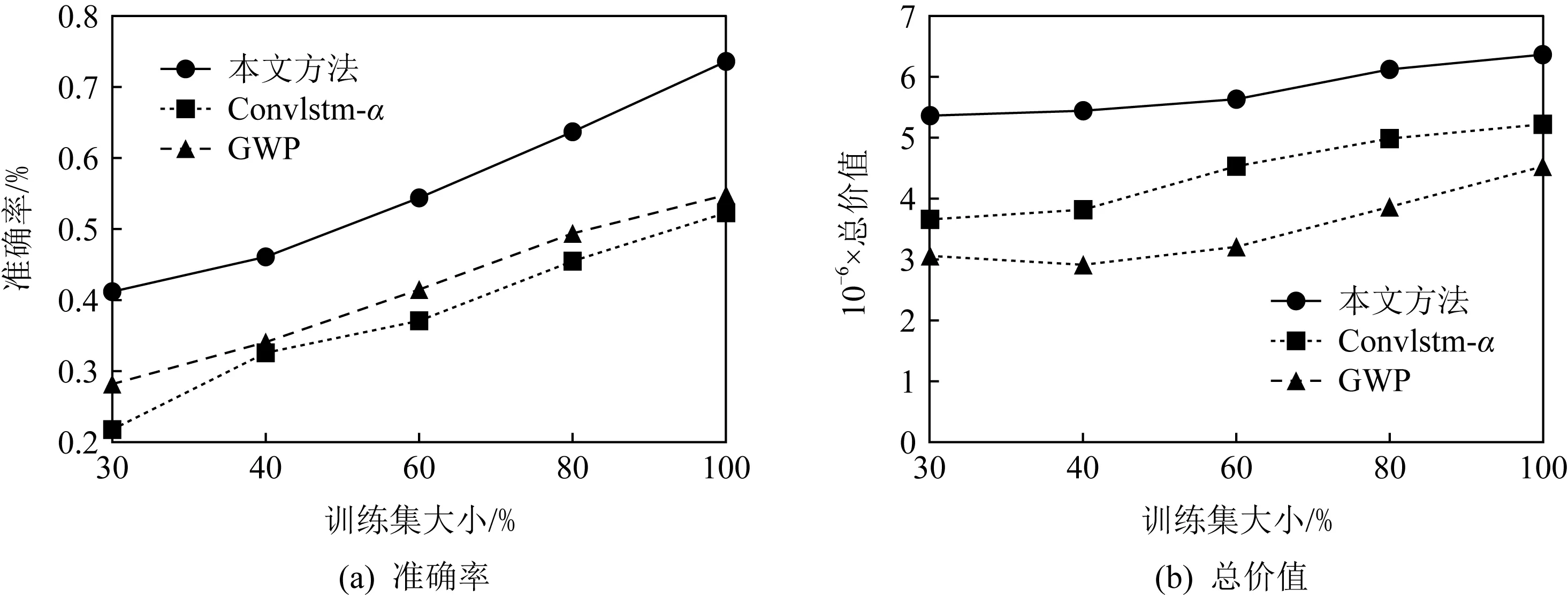
Fig. 10 Performance comparison of worker prediction under different training sets图10 不同训练集下工人预测性能对比
6.4 任务分配效果分析
本节实验评估本文提出的基于位置预测的任务分配算法的有效性,本节使用任务分配的总价值和分配对任务/工人间的平均距离评价分配策略的效果,使用计算分配所需的CPU时间评价分配策略的效率.对比算法选择贪心分配算法(Greedy)和随机分配算法(Random).除了2种基础的对比算法,还实现了3种朴素对比算法,即3种预测算法不使用位置预测数据,在仅考虑当前时刻任务/工人分布的情况下进行分配.对比算法分别为:基于位置预测的任务分配算法(本文方法)、贪心分配算法(Greedy)、随机分配算法(Random),和不加位置预测的任务分配算法(本文方法-α)、不加预测的贪心分配算法(Greedy-α)、不加预测的随机分配算法(Random-α).
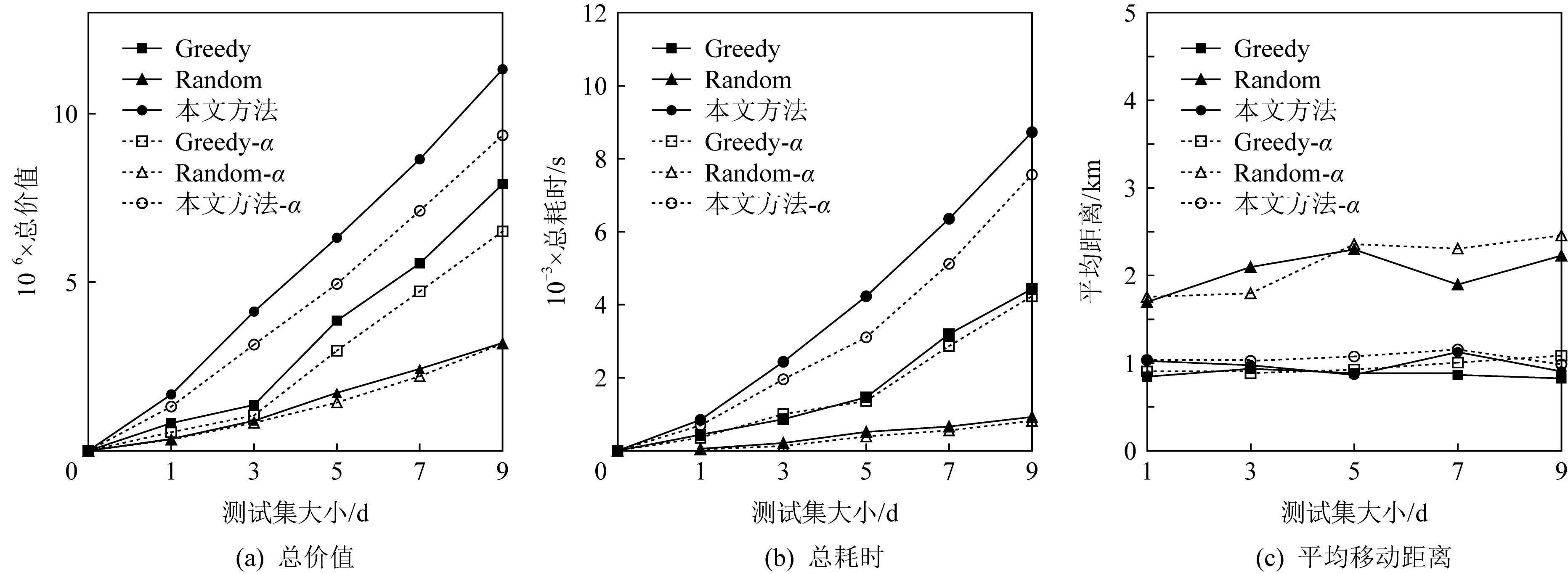
Fig. 11 Comparison of task assignment performance under different datasets图11 不同测试集下任务分配性能对比
1) 测试集大小的影响.实验选择22~30天的数据作为测试集,训练集大小取值分别为1天,3天,5天,7天,9天.首先改变测试集的大小来研究分配算法的性能和时间效率,也即通过改变参加分配的任务和工人数量来测试算法.价值评估实验如图11(a) 所示,所有算法分配得的总价值随着测试集大小的增加而增长;同时可以观察到Random算法和Random-α算法计算得到的分配总价值最低,而本文提出任务分配算法得到的分配总价值最高,随后是本文方法-α、Greedy和Greedy-α,这是由于本文方法在有任务无法被分配时,会考虑替换已有的分配实现更好的分配组合.总体上讲,所有使用了位置预测算法效果均要比没有使用预测的算法好,这是由于基于位置预测的分配算法从全局的角度进行了分配.而Random-α在一些情况下优于Random算法是由于随机分配算法有较强的随机性,实验结果均符合预期.图11(b)所示为各算法时间对比,该部分统计的CPU时间是分配所消耗的总时间.随着训练集的增大,各算法计算所用时间均呈线性增长,因为3种算法的时间复杂度均与任务/工人数量相关,任务/工人数量的增加导致耗时增加.可以观察到所有使用位置预测的算法时间消耗均高于不使用预测的算法,这是因为预测数据本身需要消耗时间,且预测得到的任务/工人也参与分配增加了3种算法要分配的任务数量.本文方法的耗时最高,这是寻找尽可能多的分配对需要消耗时间.图11(c)为各分配对间的任务和工人间的平均距离变化情况.随着训练集大小的增长,Greedy算法和本文提出的任务分配算法的变化较为稳定,基于位置预测的分配平均距离与不考虑位置预测的平均据接近,同样稳定.但Random算法的平均距离并不稳定,这是因为随机分配有较强的随机性,这种分配结果显然效果较差,真实的空间众包平台中工人的移动距离必然是越短越稳定越好.Greedy算法和本文方法的平均距离接近,但Greedy算法的效果略优,这是因为Greedy算法为每个任务都分配了最近的工人,而本文方法为了分配更多的任务,选择将一些工人分配给了较远的任务,这也是本文方法总分配价值远高于Greedy算法的原因.
2) 任务持续时间的影响.接下来通过改变任务持续时间测试分配方法的效果和效率,任务持续时间为高斯分布[p
,p
]区间内随机取值.如图12(a)所示,随着任务持续时间的增长,所有方法的分配总价值均有增长,这是由于任务有更长的持续时间意味着原本无法被分配任务可以在更多的时间实例参与分配,使该任务更可能得到分配.本文分配方法同样取得了最高的总价值,所有含位置预测的分配方法均要优于不含位置预测的分配算法,可以证明本文方法的可行性,和预测方法的有效性.图12(b)中统计的耗时为进行一个时刻任务分配消耗的CPU时间.可以观察到,随着任务持续时间的增加,所有方法的计算分配所需的时间都有所增长,这是因为任务的持续时间增长,导致任务的可用工人集变大,而分配算法的时间复杂度与可用工人集大小也有关,与预期结果相符.在最极端的情况下本文方法平均耗时也仅高于Random算法4.20 s,属于可以接受的范围.从图12(c)中可以观察到除Random算法外各算法的平均距离均较为稳定,同样证明了本文方法的可行性.3) 工人移动速度的影响.实验通过改变工人移动速度测试分配方法的效果和效率,工人移动速度为高斯分布[v
,v
]区间内随机取值.图13(a)中,随着工人移动速度增加,所有方法得到的分配总价值均有增长,原因与任务持续时间增长带来的影响类似.工人移动速度增加相等于增加了每个任务的可用工人集,而所有的分配算法均是在可用工人集上进行的,更多的可用工人可能让原本无法被分配的任务更可能得到分配,同样这增加了需要计算的任务/工人数量,导致了图13(b)中Random算法外所有算法的耗时均有明显增加.图13(c)所示本文分配算法计算得的工人平均移动距离依旧稳定.本文方法仅比Random算法平均多耗时仅为4.89 s的情况下,取得了优于Greedy算法32.7%的分配价值和稳定的工人移动距离,可以证明本文方法的有效性.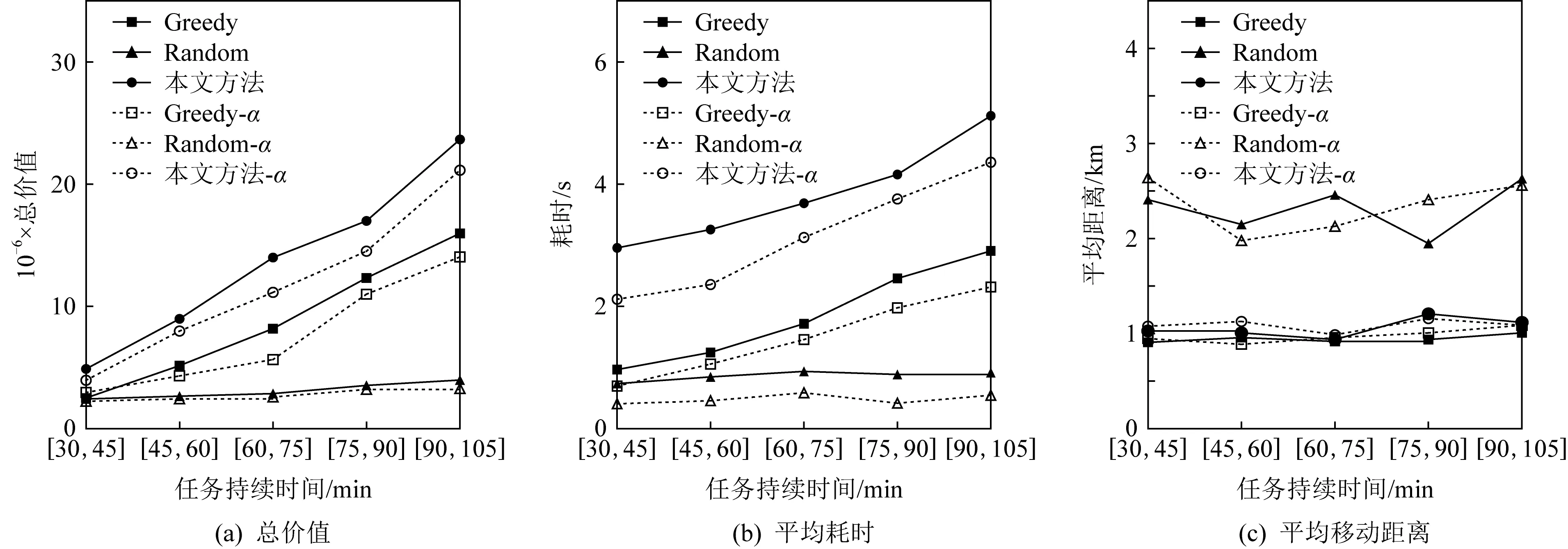
Fig. 12 Comparison of task assignment performance under different time of duration图12 不同持续时间下任务分配性能对比
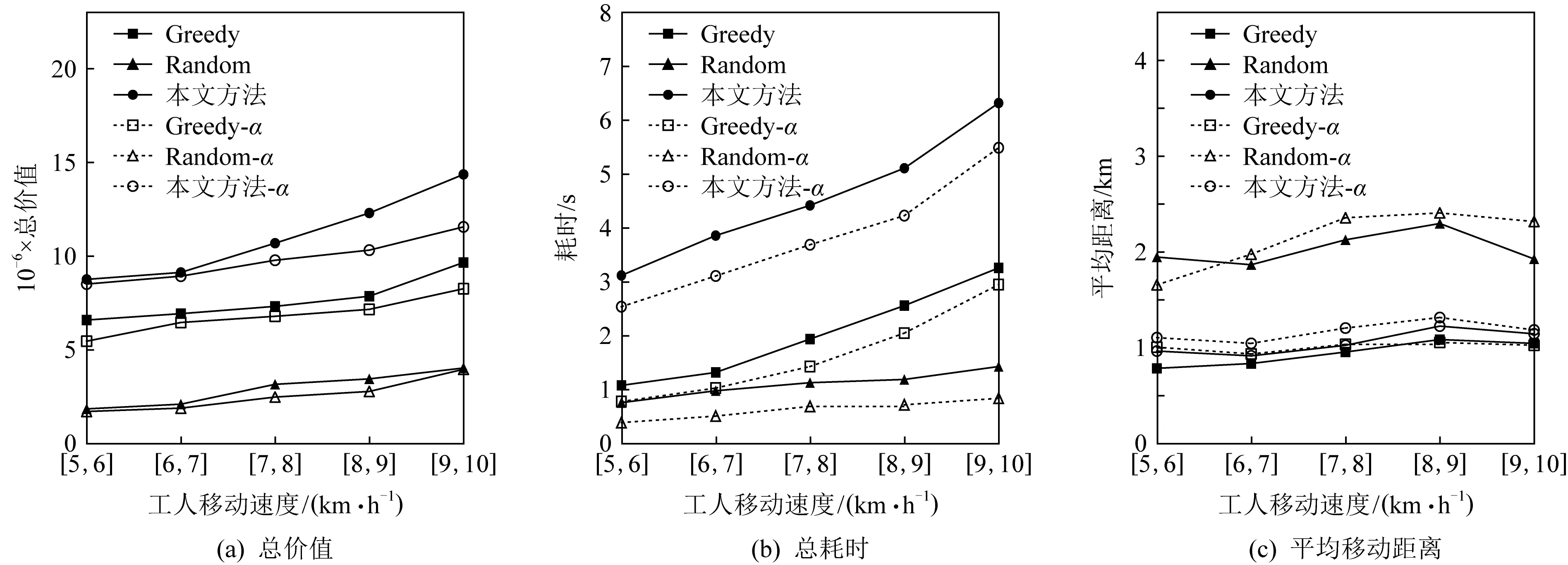
Fig. 13 Comparison of task assignment performance under different movement speed of workers图13 不同工人移动速度下任务分配性能对比
7 结束语
本文提出一种解决空间众包任务分配问题的方法,使用基于轨迹的任务位置预测模型和基于核密度估计的工人位置预测模型预测了未来时刻任务/工人的分布,设计了一种基于位置预测的任务分配方法来寻找尽可能好的分配.本文通过大量实验证实了所提方法的效率和有效性,任务预测和工人预测的准确率优于其他算法,且分配方法能取得远优于基础算法的分配效果.本文通过大量实验证实了所提方法的效率和有效性,任务预测和工人预测的准确率优于其他算法,且分配方法能取得远优于基础算法的分配效果.但在工人预测和分配工作中,没能计算出预测工人的出现概率,只是在预测工人没有出现的情况下尽可能早地把配对的任务重新分配,导致工人预测不精准时分配效果变差.在未来进一步研究中会针对该问题寻找更优的解决办法,研究更复杂情景中的任务分配方法,实现空间众包中复杂任务(多个工人分配一个任务),及特定路线任务(根据工人移动路线分配多个任务)的分配方法.此外,将应用文献[24-27]中位置预测算法提高众包任务分配的准确性.
致谢
:本文实验部分使用的数据来自滴滴出行“盖亚”数据开放计划(Didi Chuxing GAIA Initiative).作者贡献声明
:徐天承参与研究和文章撰写,包括算法研究、设计论文框架、起草文章和实验等工作;乔少杰参与研究和文章撰写,包括算法提出、设计研究方案、修订论文和指导性支持等工作;武俊参与研究,包括采集整理数据统计分析和实施研究过程等工作;韩楠参与研究,包括采集整理数据、算法设计等工作;岳昆参与工作支持,包括理论基础和数据支持;易玉根参与研究,包括数据采集与处理;黄发良参与工作支持,包括数据和实验支持;元昌安参与研究,包括算法设计及修订研究方案.