基于Conformer的端到端语音识别模型的压缩优化策略
2022-02-10桑江坤努尔麦麦提尤鲁瓦斯
桑江坤 努尔麦麦提·尤鲁瓦斯
(1.新疆大学信息科学与工程学院,新疆乌鲁木齐 830046;2.新疆多语种信息技术实验室,新疆乌鲁木齐 830046)
1 引言
最近,Conformer[1]架构在语音识别任务中表现出优异的性能。无论是在较小的数据集Aishell 上,还是将近1000 小时的Librispeech 数据集上,相比之前 的Transformer[2],Transformer-XL[3],Conformer 都表现出较好的结果。基于Conformer框架的提出,使得端到端ASR 模型的准确率得到进一步的提升,同时在语音识别领域也得到了广泛的应用。
然而,虽然Conformer 模型的准确率得到了提高,但随之而来的是越来越大的模型参数量。基于Conformer的预训练模型已经达到几千万的参数,甚至有时达到了上亿的参数。因此,这也使得模型在资源受限的设备上部署时成为一个重要的问题,因为它具有较高的延迟,而且内存占用和计算量都非常大。
为了解决上述存在的问题,本文采用了三种压缩策略:基于模型量化的改进,基于权重通道的结构化剪枝[4-6],通过奇异值分解进行低秩近似[7-8]。首先,量化是模型压缩中较常用的一种压缩方式,它通过以低精度存储权重来减少内存占用,同时也可以通过专用硬件进行低精度运算来减少推理时间,降低功耗[9-11]。以往的量化操作中,大多采用的量化方式是动态范围内的量化操作。这种量化方式在前期的模型训练过程中不进行任何额外的操作,模型训练好后直接对其量化,在量化操作之前需要先对数据流进行统计,找到最大值和最小值,然后再将其线性变换到(-1,1)范围内。然后后续再进行量化和反量化操作。这种方式在前期的整个统计和变换过程,会造成一定的耗时。此外,量化所造成的精度损失容易受到数据流范围的影响,也就是说由于数据流不可控,当数据流的范围较大时,造成的精度的损失也会较大。本文,基于Int8模型量化并对其进行了改进。其主要操作是,在模型训练过程中对其进行干预,对输入流和权重进行一个范围限制,以此来探究其范围限制对模型精度损失的影响。这样做的好处是,在对模型量化时,可以人为控制模型量化过程中所造成的精度损失,避免在量化实现过程中,输入流范围的差异对模型精度影响较大,同时可以简化量化操作的过程。
此外,结合模型结构的特点还进行了网络剪枝和奇异值分解操作。对于剪枝操作而言,其操作方式有非结构化剪枝和结构化剪枝。非结构化剪枝相比于结构化剪枝虽然可以取得更高的稀疏度,但是需要特定的软硬件支持才可以取得加速效果。而结构化剪枝虽然做不到极限的压缩效果,但由于保留的子结构规整,更容易取得加速效果,拥有广泛的应用场景。这也是本文采用这种方式的一个重要原因。通过网络剪枝操作,可以删除模型中存在的冗余结构和参数,从而减少推理过程的计算代价。奇异值分解方法其主要作用是可以将大规模的矩阵分解为小规模的运算,以此减少模型尺寸,降低模型所占内存空间,减少推理时间。虽然网络剪枝和奇异值分解都可以有效地压缩模型的大小,但如何在保证模型精度不受损失的情况下来尽可能地压缩模型的大小是本文所探究的一个重点。
为减少端到端语音识别模型的大小,保证其精度损失不受到较大影响,本文设计基于Int8 模型的量化方法并对其进行改进。结合模型结构特点,从不同角度来对模型进一步压缩。最后探究如何结合使用来保证模型的性能。
2 模型结构
2.1 Conformer
Conformer 是当下最先进的ASR 编码器架构。由于Transformer 模型擅长捕捉基于内容的全局交互,卷积神经网络(Convolutional Neural Networks,CNN)则可以有效地捕捉基于相对偏移的局部相关信息。所以研究者通过利用二者的特性,将Trans⁃former 和CNN 结合起来。通过对Transformer 进行卷积增强,以参数有效的方式对音频序列的局部和全局依赖性进行建模,使得端到端模型的性能得到进一步的提升。这也使得Conformer 在语音识别领域得到广泛的应用。
Conformer 模型结构如图1 所示,由两个前馈网络模块,一个自注意力模块和一个卷积网络模块组成。前馈网络模块中使用了两个线性变换层和Swish 激活函数,此外还用了Dropout 层和批归一化层。在多头自注意力模块中,Conformer 集成了Transformer-XL 中的相对正弦位置编码方案。相对正弦位置编码可以让自注意力模块在不同的输入长度上更好的泛化。卷积模块内部包含了逐点卷积网络,门控线性单元(GLU)激活函数,1-D 深度卷积网络。Conformer 模型主要特点就是在Trans⁃former模型上加入了深度可分离卷积。

图1 Conformer模型结构示意图Fig.1 Schematic diagram of the Conformer model structure
Conformer 模块参考Macaron-Net[12]结构使用两个前馈网络将多头注意力和卷积网络模块包围其中,并在各模块之间做残差连接。
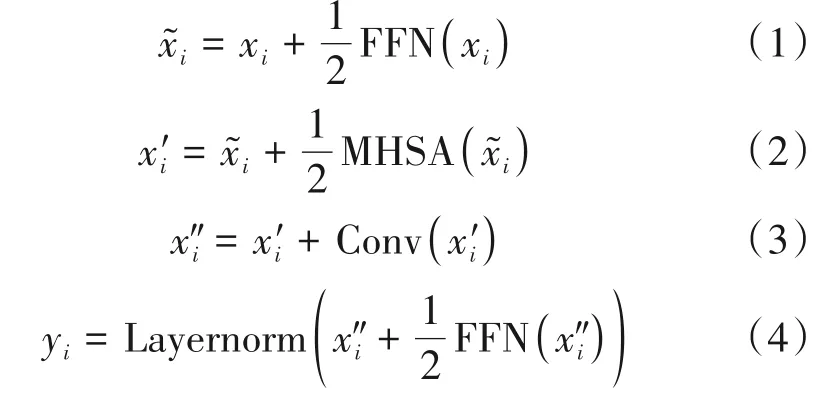
其中,FFN 代表前馈网络模块,MHSA 表示多头注意力模块,Conv 表示卷积网络模块。Layernorm 表示层归一化。研究者经过试验发现,相比于在Con⁃former 中使用单个前馈网络模块,使用两个前馈网络模块将多头注意力模块和卷积网络模块放在其中,可以有效地提高模型的性能。
2.2 联合CTC-注意力机制
联合CTC-注意力机制模型[13]的思想是使用连接时序分类(Connectionist Temporal Classification,CTC)[14]目标函数作为辅助任务,在多任务学习框架内训练Attention 模型的Encoder。CTC 目标函数作为辅助任务附加到共享编码器。该结构有一个共享的编码器网络,由CTC 和Attention 模型共享。CTC 的前后向算法可以实现语音序列和标签序列之间的单调对齐,这有助于减少基于注意力机制编码-解码(Attention-based Encoder-Decoder,AED)模型[15-17]的不规则对齐,从而获得更好的性能。联合CTC-注意力机制模型的训练过程是多任务学习,将CTC 与基于Attention 机制的交叉熵L(CTC)和L(ATT)相结合,联合训练损失函数可定义如下:
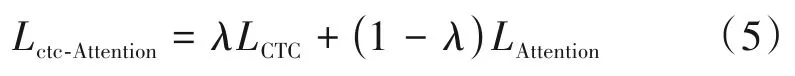
其中,λ是一个可调参数:0 ≤λ≤1,由于CTC,一般作为辅助任务,λ一般取值为0.3。
本文将采用基于Conformer 的联合CTC-注意力模型进行训练,其模型结构如图2所示。
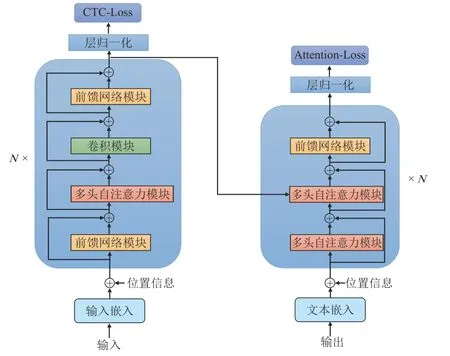
图2 基于Conformer的CTC-注意力模型结构图Fig.2 CTC-Attention Model Structure Diagram Based on Conformer
这个结构的主要特点是在CTC-注意力机制的基础上,在Encoder 部分使用了多个Conformer 层,Decoder 部分使用了多个Transformer 解码层。从图中可以看到模型结构中存在多个多头自注意力模块,不同的是,在Encoder 部分,采用的是具有相对位置嵌入的多头自注意力,通过使用相对位置的正弦编码方式可以允许自注意力模块更好地对输入序列的长度进行泛化,并且使得整个模块可以更好地在长度不一致的输入音频上有更强的鲁棒性。而在Decoder 部分则采用的是标准的多头自注意力模块。
通过采用这种模型结构,一方面可以加快整个模型训练过程,另一方面充分利用训练数据来提高学习能力,以便更好地提升模型的性能。
3 模型压缩优化策略
3.1 基于模型量化的改进
对于端到端语音识别模型而言,里面存在较多的计算,这些计算通常是一些数据流乘以权重的计算。简单的来说,就是矩阵之间的运算,对于矩阵运算而言实际上就是矩阵中的某一行与另一个矩阵的某一列相乘,实际上就是两个向量之间的点积。用正常的浮点类型模型进行运算,不做任何加速操作,其过程可描述为:
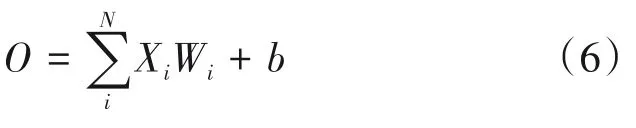
对于模型来说,如果不做任何压缩操作,这个参数量和计算量是巨大的,很难部署在资源受限的设备上。而量化是模型压缩中较常用的一种方法。工业部署中常用的两个模型量化方法有量化感知训练(Quantization-Aware-Training,QAT)和训练后量化(Post-Training Quantization,PTQ)。量化感知训练是在量化的过程中,对网络进行训练,通过模拟量化的效果进行参数更新和优化。标准的量化感知训练包含的是一个离散的函数,如图3(a)所示,它是一个阶梯函数,也即是不可导的,所以带来的问题就是没有办法用一个标准的反向传播的梯度下降方法进行优化。而一般的做法是做一个梯度的近似,如图3(b)所示,利用一个直通估计器在反向传播的过程中忽略掉量化的影响。这样带来的问题就是计算出来的梯度是有误差的,是一种不精确的训练。虽然量化感知训练灵活性比较高,但整个训练过程比较慢,而且操作也极为不便,时间成本,人力成本都是比较大的。
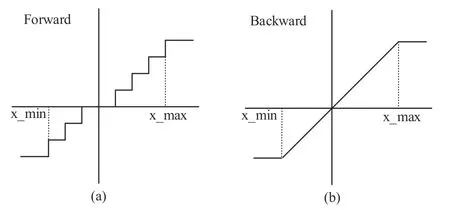
图3 标准量化感知训练Fig.3 Standard quantization-aware-training
训练后量化是指在模型长时间的训练后,模型达到收敛状态后再进行量化的一种方法。本文中的量化方式也是基于这种训练后的量化策略。后量化的流程如图4 所示,这种量化方式在前期的模型训练过程中不进行任何额外操作,模型训练好后然后对其量化。不过在量化之前需要做一些预处理,首先需要先对数据流进行统计,找到最大值和最小值,然后再将其线性变换到-1到1范围内。

图4 训练后量化Fig.4 Post-training quantization
这种量化方式存在的问题:一是前期的整个统计和变换过程,会造成一定的耗时。二是量化所造成的精度损失容易受到数据流范围的影响,也就是说由于数据流不可控,当数据流的范围较大时,造成的精度的损失也会较大。
基于这种量化方式,有人提出了一种在量化之前运用小批量数据来统计最小值和最大值,虽然一定程度上减少了计算量,但会造成额外的精度损失,因为小批量数据统计得到的最小值和最大值不足以反映所有的数据。
基于以上问题,本文对训练后量化策略进行了改进,以此来解决上述后量化方式的不足。本文做出的改进是通过对模型进行训练干预,对输入流和相关权重进行一个范围限制。在训练过程中,将输入流X限制到[-R,R]范围内,权重W限制到[-Q,Q]内。整体流程如图5所示。
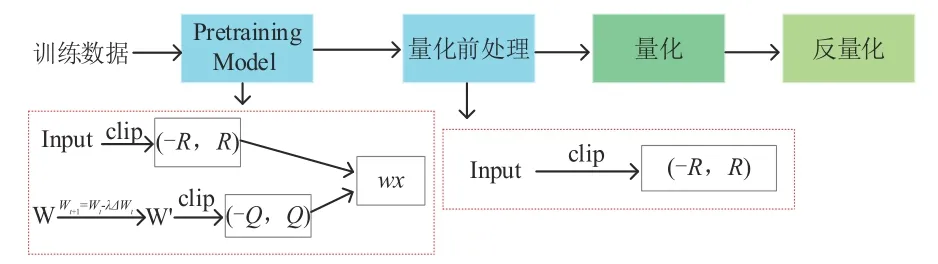
图5 训练后量化改进Fig.5 Improvements to Post-training quantization
通过这种方式量化和反量化可得到简化,本文的操作是基于Int8的量化,量化和反量化过程可表示为:

进一步化简得:

假设有2m=27/R,2n=27/Q,则有:

对于Int8 量化过程而言,是将Xi和Wi进行近似。将其转换为-128 到127 这个区间内的值来表示,也就是说,需要对它们乘以一个较大的整数,来使其转移到量化的范围内。
其量化过程的损失会在round(Xi∙2m)和round(Wi∙2n)取整中体现,round(Xi∙2m)的最大损失为0.5,round(Wi∙2n)的最大损失也是0.5。所以Xi整体的损失是≤1/(2m+1),Wi整体的损失是≤1/(2n+1)。
由2m=27/R,2n=27/Q可知:

在一定范围内,当[-R,R]和[-Q,Q]范围较小时,m和n取值就越大,Xi和Wi整体的损失就越小,所以通过这种方式在对模型量化时,可以较大程度上控制量化过程中所造成的精度损失,避免在量化实现过程中,输入流范围的差异对模型精度影响较大。
而对于输入流和权重的限制范围是不同的,因为对于数据流,它的范围相对来说是比较大的,如果直接将输入流限制到一个较小的范围内,会对模型的精度造成较大影响。所以对于输入流和权重范围限制是相对的,也即是在一定范围内R和Q取值较小时,量化过程所造成的精度损失越小。本文对输入流限制的范围为(-2,2),(-4,4),(-8,8),权重则为(-0.5,0.5),(-1,1),(-2,2)。
此外,关键的一点是每个量化过程还要做一个反量化操作,在进行反量化操作时,如果后面跟着的还是一个矩阵乘法,本文提出的量化操作会在这个过程减少一定的运算。通过神经网络训练得到的模型,一般是包含很多层的,比如说有两个全连接层连接在一起。如下所示:

本文实现的量化方式,对于任何一个输入X,比如我们将其限制到(-4,4),这样再做量化只需要乘以25,然后再取整即可,不再需要繁琐的统计过程。而权重限制到(-2,2)之间,只需要乘以26,进而四舍五入取整即可。而在反量化的过程需要把输入和权重相乘后的结果除以25和26,即211。其除以211得到的输出,又是下一层网络的输入,若下一层还是一个矩阵乘法,即两个全连接层连接在一起的情况,本文改进后的量化不需要再除以211,而仅除以26就完成了上一层的反量化和下一层的量化操作。相当于把上一层的反量化和下一层的量化过程合并在一起,这样一定程度上减少了矩阵乘法的计算时间。如图6 和图7 为两个全连接层连接在一起时不同量化方式的比较示例图。

图6 标准后量化方式线性层示例图Fig.6 Standard quantization-aware-training linear layer example diagram
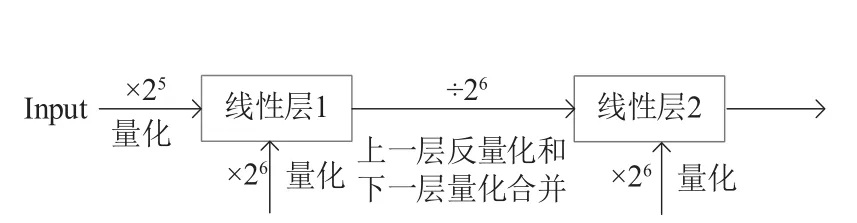
图7 后量化改进线性层示例图Fig.7 Improvements to Post-training quantization linear layer example diagram
本文主要是通过对模型进行训练干预,对输入流和相关权重进行一个范围限制,探究如何能实现最小化精度损失。总的来说,改进后的量化方式去除了前期范围统计和变换这一耗时的过程,简化了整体的量化过程,减少了一定的运算时间。此外,较大程度上可以控制模型量化过程中所造成的精度损失,避免在量化操作过程中,输入流范围的差异对模型精度影响较大。
3.2 基于权重通道的结构化剪枝
本文采用的端到端模型结构中包含了多个全连接前馈网络模块,它是由两个线性变换和一个激活函数组成,其中激活函数放在线性变换的中间。不同的是,在Encoder 部分中,前馈网络模块使用了Swish[18]激活函数,而在Decoder区域则是用了Relu[19]激活函数。此外,这些前馈网络模块,都在激活后使用了Dropout,以此来进一步规范模型网络。其过程可定义为:
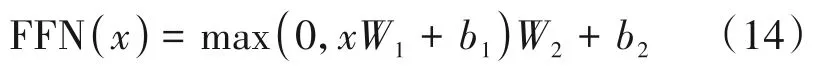
前馈网络模块中,每层都包含着一定的线性单元数,其单元数一般较大。而模型中又存在多个前馈网络模块,整个前馈网络模块中的线性变换过程存在着较大的运算。
因此,本文对模型中的前馈网络模块进行基于权重通道的结构化剪枝。其操作过程如图8 所示。主要操作是:在模型训练过程中使用了未做任何操作的基线模型,即在迭代训练几轮后的模型基础上进行剪枝操作,通过L2范式来得到每个权重通道的重要性,然后裁剪相应比例不重要的通道数。
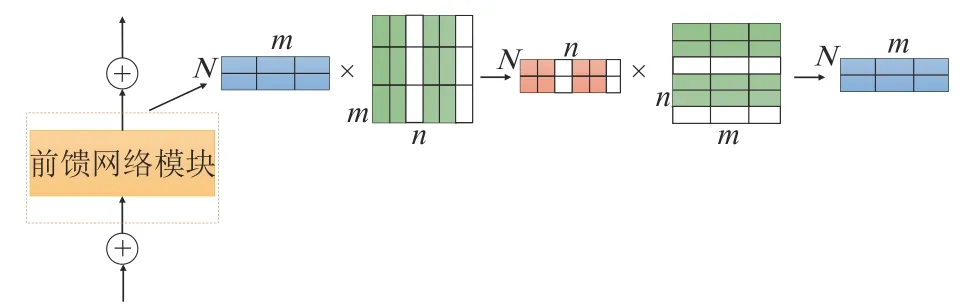
图8 前馈网络模块通道剪枝Fig.8 Feed-forward network module channel pruning
3.3 奇异值分解实现低秩近似
此外,在端到端模型中也存在着多个多头自注意力模块。多头自注意力的机制是由Virwani 等人在2017年发表的一篇论文《Attention is all you need》所提出来的。文中提出将自注意力机制分为多个头,形成多个子空间,以此可以注意到不同子空间的信息,捕捉到更加丰富的特征信息。多头自注意力机制是通过线性变换对Q,K,V,进行映射,然后把输出结果拼接起来。多头自注意力机制的公式如下:
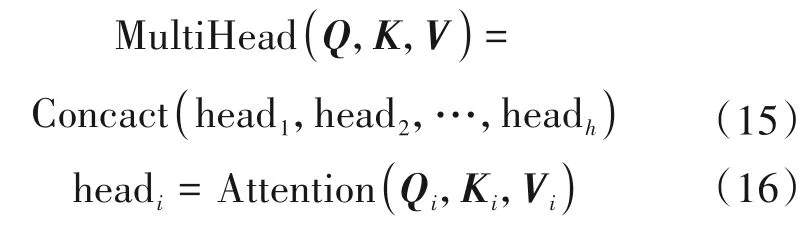
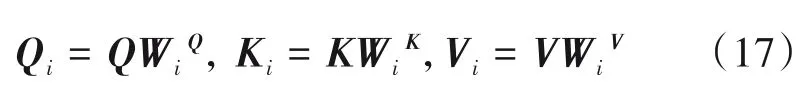
由多头自注意力模块的结构来看,该模块中也存在多个矩阵线性变换,而这些线性变换的主要特点是行列相同的方阵。其特点很适合奇异值分解操作,因此本文对这一模块进行了奇异值分解操作,将大规模的矩阵分解为小规模的矩阵运算,从而降低模型中的参数量。

其中,S是除对角元素不为0,其余元素均为0 的矩阵,U和V都为酉矩阵。为了减少模型的参数量,又将矩阵S分为两个相同的矩阵E,即有E=从而我们可以将W变为两个矩阵相乘,用公式表示为:


图9 多头自注意力模块奇异值分解Fig.9 The bulls decompose from the singular value of the attention module
4 实验配置
4.1 数据集
本文在公开的英语Librispeech[20]数据集上进行了相关实验,约包含1000 小时带标签的数据,其中训练数据约有960小时。有test-clean和test-other两种测试集,时长分别为5.4 和5.1 小时。验证集分为dev-clean 和dev-other,时 长分别为5.4 和5.3 小时。数据均为16 kHz采样率,单声道格式。
4.2 参数配置
实验中使用了80维的fbank进行特征提取。帧长设置为25 ms,帧移10 ms。训练过程使用了Adam 优化器,量化和剪枝实验的学习率设置为了0.004,奇异值分解实验的学习率设置为0.0004。实验中均使用了12 层编码器,6 层解码器,每层包含2048个单元,注意力数目设置为4。卷积网络中卷积核数目设置为15。此外,还使用了标签平滑和Drop⁃out 正则化设为0.1,以防止过拟合。CTC 的权重设置为0.3。所有模型都是在2 块 NVIDIATESLA V100 GPUs 32GB上使用Wenet[21]工具进行训练。epoch 次数为25。此外,文中所有实验的模型是采用BPE[22-23]算法进行建模,生成了一种介于字和词之间的半字(Word Piece)建模单元,输出节点数为5002。
4.3 评价指标
本文中主要采用词错误率(Word Error Rate,WER)和实时率(Real Time Factor,RTF)作为模型的评价指标。

其中,S表示被替换的单词数目,D表示被删除的单词数目,I表示被插入的字符数目,N表示标签序列中的总单词数目。
5 实验结果与分析
5.1 基于模型量化的改进
本文的量化实验,均是对模型做的Int8 量化。对整个模型的线性层和卷积层做权重量化,未涉及偏置的量化。本文所采取的clip范围主要是通过自适应的方法来获取的,我们在clip之前,对float32模型的相关权重进行了统计。模型中线性层和卷积层的权重分布大多如图10所示。
从图10 可以看出他们的权重分布主要集中在(-2,2)范围内。为了实验验证,权重(W)选取的clip 范围有(-0.5,0.5),(-1,1),(-2,2)。同时也对输入数据流进行了统计,通过选取了一部分测试数据在float32 模型进行推理,从而获得输入流的大概范围,统计发现相比于权重的分布,数据流的分布范围主要集中在一个较大的范围内。因此对输入流(Input)验证的clip 范围有(-2,2),(-4,4),(-8,8)。然后在此基础上进行量化实验。

图10 模型中线性层与卷积层的权重分布Fig.10 The distribution of weights between linear and convolutional layers in the model
首先是只进行clip 操作对模型精度损失的影响,其结果如表1所示。
通过观察表1 可以看出,输入的数据流和权重在进行不同的clip 时,精度的损失差别有所不同。由于权重的数据分布大多在-2 到2 这个范围内,将权重clip到(-0.5,0.5)范围内会对模型性能造成较大影响。而因为输入流的数据分布范围较大,若强制将输入流clip到(-2,2)这个过小的范围内同样会对模型的性能造成较大影响。当输入流和权重clip到较小范围时,对模型精度影响较大,因此后面的量化操作也就无需继续进行。

表1 clip操作结果Tab.1 The result of the clip operation
在上述clip 操作的基础上,对其精度损失影响不是很大的情况下进行量化操作。具体结果如表2所示。
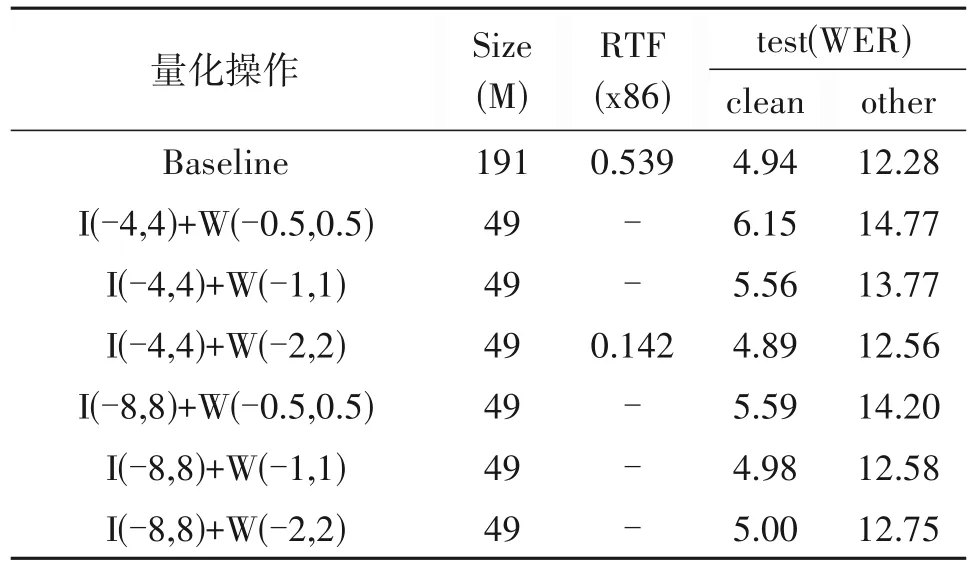
表2 量化操作结果Tab.2 Quantify the results of the operation
通过观察表2 可以看出,当对模型进行int8 量化时,模型大小显著的减少了。模型参数量从原来的191 MB 减少了到了49 MB,RTF 降低了3.8 倍。上文提到为了较大程度上控制量化过程中所造成的精度损失,在一定范围内当[-R,R]和[-Q,Q]范围较小时,Xi和Wi整体的损失就越小。所以权重clip 到(-2,2)范围和输入流clip 到(-4,4)范围内对模型的性能造成较小的影响。从量化结果可以看到,在test-clean 测试集的词错误率几乎没有造成影响,而在test-other测试集上也仅造成0.28的词错误率。这说明了我们改进后的量化方式,可以较大程度上的控制模型量化过程中所造成的精度损失,避免在量化实现过程中,输入流范围的差异对模型精度影响较大。
5.2 基于权重通道的结构化剪枝
其次,根据模型结构的特点,对模型中的前馈神经网络进行了基于权重通道的结构化剪枝。为了得到每个权重通道的重要性,在进行剪枝操作时,首先使用了没做任何操作的基线模型。在训练5 轮后的模型的基础上进行剪枝操作,然后又经过20 轮的迭代训练,作为最终模型。通过L2 范式来得到每个权重通道的重要性,然后裁剪相应比例不重要的通道数。分别对前馈神经网络进行了10%,20%,25%,30%的剪枝。剪枝操作相关结果如表3所示。
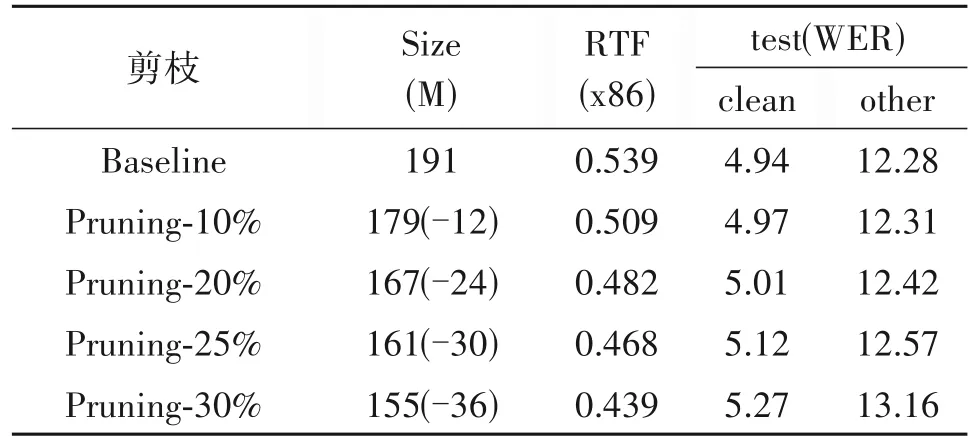
表3 剪枝操作结果(学习率0.004)Tab.3 The result of the pruning operation(learning rate 0.004)
观察表可以看出,对模型的前馈神经网络模块进行一定比例的剪枝操作后,不会影响模型的性能。因为本文主要通过L2 范式来获得每个权重通道的重要性,然后对其进行排列,从而裁剪掉这些不重要的通道数,由于裁剪掉的这些通道数对整个模型起到的作用较小,所以不会对模型的性能造成较大的影响。但如果剪枝超过一定比例后,裁剪掉的通道数对整个模型起到的作用较大,这会严重影响模型的性能。由表也可以看出,当剪枝率超过25%时,对模型的性能影响较大。
此外,实验中发现,在对前馈网络进行剪枝操作时,学习率设置过小时对模型的性能影响较大。结果如表4所示。

表4 剪枝操作结果(学习率0.0004)Tab.4 The result of the pruning operation(learning rate 0.0004)
当学习率设置0.0004 时,在剪枝10%时,对模型的性能就造成很大的影响,这就使得无法再继续增加剪枝率。所以在进行剪枝操作学习率不宜设置过小。
5.3 奇异值分解实现低秩近似
在实验中发现,如果直接对网络层的所有线性变换进行奇异值分解,会对模型精度造成较大的影响,严重影响了模型的性能。因此我们根据多头自注意力模块的特点,对其进行奇异值分解。
由于,直接在原学习率的基础上进行学习,导致了模型的loss越来越大,导致训练无法继续进行。所以,在实验中将学习率在原学习率的基础上减小10 倍,即设为0.0004。然后,在基线的第5 轮模型上进行奇异值分解操作,进行了20 轮的迭代训练。因为在模型中的多头注意力模块,其维度采用的是256,故将分解时,将中间维度分别设为64,48,32。
通过观察表5 可以看出,由于模型中存在的多头注意力模块有限,在进行奇异值分解时,模型大小虽然有所减少,但不是很大。随着中间维度的减小,模型大小也随之减少,但准确率有所下降。所以对模型的多头自注意力模块进行奇异值分解操作,中间维度不宜设置过小。
5.4 不同压缩策略结合
经过以上实验,又对它们的结合进行了探究,从而使得模型大小进一步减少。其具体操作结果如表6所示。
通过表6 可以发现,不同的结合策略对模型性能的影响有所不同,模型大小也有所差异。剪枝,奇异值分解分别单独和量化结合,虽然压缩后的大小基本相同,但奇异值分解和量化结合造成的词错误率低一些。在将量化、剪枝、奇异值分解结合在一起后,原模型的大小由191M 减小到42M,实时率RTF 也很大程度得到了降低,而此时压缩后模型的词错误率相比于原模型仅有2.92%的误差,可见压缩后的模型并没对其性能造成较大的影响。

表6 三种策略融合操作结果Tab.6 Three strategies fuse the results of the operation
5.5 设备测试
为了验证改进后的量化结合其他压缩策略可以有效提高模型的推理速度。本文又设计一个参数较小的模型,分别在X86 服务器和Android 端进行了推理测试。Android 设备采用的是运行内存为8 GB,处理器为高通骁龙855Plus 8 核的Android 手机。其结果如表7所示。

表7 不同设备上的推理测试Tab.7 Inference testing on different devices
观察表可以发现,在X86 服务器上结合压缩策略的模型其RTF 降低了3.85 倍,Android 端其RTF降低了3.46 倍。所以本文使用的模型压缩策略在不同的设备上都可以有效提高模型的推理速度。
最近在语音识别领域中,基于Conformer模型做int8量化的工作并不多。本文参考了最新在语音领域中提出的Integer-Only zero-shot量化[24]方式进行了对比。该方法在Jasper模型[25]和QuartzNet模型[26]有着不错的压缩性能,且对模型的准确率没有较大影响。而在Conformer 模型上对词错误率造成了较大的影响。如表8 所示是zero-shot 量化与本文改进后的量化针对Conformer模型进行量化的结果对比。
通过观察表8 可以看出,相比Integer-Only zeroshot 量化,本文改进后的量化对模型所造成的精度损失较小且模型压缩倍数也较为显著。经测试其推理速度也有着不错的提升。
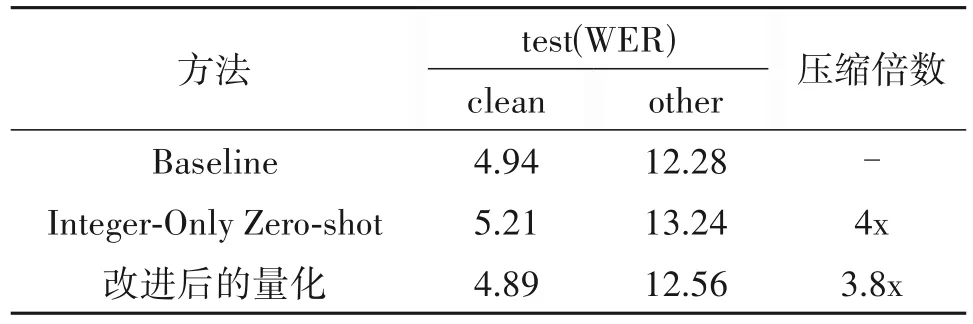
表8 基于Conformer模型不同量化方式的对比Tab.8 Comparison of different quantization methods based on the Conformer model
6 结论
本文,根据端到端语音识别模型参数较多的问题进行了分析探究。为保证模型精度损失不受到较大影响的情况下,尽可能地压缩模型的大小,探究了三种压缩策略。首先对模型量化进行了改进,改进优势在于一方面去除了一般量化方式中前期范围统计和变换的这一耗时的过程,简化了整体的量化操作过程。另一方面较大程度上控制模型量化过程中所造成的精度损失。此外,根据模型结构的特点,对模型的前馈网络模块进行基于权重通道的结构化剪枝,针对多头自注意力模块通过奇异值分解来实现低秩近似,将大规模的矩阵分解为小规模的矩阵运算,来进一步降低模型中的参数量。并根据这些策略进行了相关实验,探究了在保证精度损失不受到较大影响情况下,尽可能地降低模型的大小,提高模型的推理速度。通过在不同设备上对模型的识别速度进行了测试,结果表明相比于基线在其字错误率上升小于3%的情况下,模型推理识别的速度约提升3~4倍。验证了我们改进后的量化结合其他压缩策略可以有效提高端到端语音识别模型的推理识别速度。
