基于检修要素感知的检修方案智能生成模型研究
2022-02-10王浩宇
胡 彬,马 越,张 健,王浩宇
(国能大渡河检修安装有限公司,四川 成都 610000)
0 前言
在互联网及移动互联网技术快速发展的背景下,智能城市、智能医疗、智能社区和智能企业都在全力以赴。水电企业的智慧检修、状态检修也开始了不断的研究和探索,特别是以国家能源集团大渡河公司为代表的大型水电中央企业,从2017年开始已经大力发展和探索智慧企业和智慧检修建设。
“基于检修要素感知的检修方案智能生成模型研究”课题的提出,即考虑到在日常工作中遇到的实际问题,如检修资源不足、专家力量紧张等。随着越来越多信息系统的部署,在制定检修方案时,所需要权衡考量的因素也越来越多,此时,如果能将制定检修方案的工作交由大数据分析工具来辅助完成,将显著提高人员效率,降低成本。
1 总体方案
本文的设计是依托于历年的检修数据,以及水电站诸多信息管理系统和生产管理系统中,每天生成的大量的设备运行信息、检修维护信息。
因此在本文中,将借助NLP自然语言处理技术、深度神经网络算法对已有的大量历年检修数据进行收集、归纳、整理,形成与设备运行状态、检修状态相关联的检修要素,纳入到知识库中,再通过大数据机器学习算法,对转化的检修信息数据进行关联匹配,将历史检修方案与检修需求建立关联模型,实现检修方案智能生成模型,模型如图1所示。

图1 检修方案智能生成模型
2 应用方式及成效
本文中尝试将历史检修信息、现场检修需求、检修知识库利用NLP自然语言处理算法及大数据机器学习算法进行归纳、建模,给出检修方案制定建议,并根据检修完成后的评价功能,对前述功能进行反馈,形成迭代优化。
2.1 模型技术要求
首先将其用于对没有纳入模型学习的设备历史故障信息进行验证,将模型的检修方案计算结果与历史检修工单记录进行比对。通过验证后,在检修工作开展的同时,用模型根据设备故障信息和运行状态进行检修方案推荐,形成检修方案参考建议。模型具备以下技术要求。
检修词条的自然语言处理技术,对检修需求、检修要素进行处理识别,包括图表类、文本类的信息,转化为计算机能够识别和查询的结构化知识。
检修知识库自动匹配识别算法,依托大数据机器学习算法,包括模糊聚类以及基于深度学习的KBQA(Knowledge Base Question Answering)技术,快速为其进行画像,并匹配已有检修知识库中对应的检修词条,生成初步的检修建议方案。
检修方案优化算法,系统能根据不同的检修任务关注维度,生成有差异性的检修优化方案,比如安全优先、经济性优先、工期优先等。
检修绩效指标自动评价体系,系统能够根据检修目标,自动为检修任务的完成进行评判。
2.2 模型数据采集
构建模型所需要的数据来源于历年生产管理数据,大部分工作数据每月形成电子表格汇总得到,主要是人身风险预控活动、检修工序卡活动数据、风险预控活动数据、项目管理数据。各个数据源来源不同,人身风险预控活动将采集检修工作的人员姓名、工种、消耗性材料、工器具、工期、防范措施等信息,检修工序卡将采集工艺标准、检修质量等信息,风险预控活动将采集项目风险、风险等级预估等信息,项目管理数据将采集人员、工种工期、检修成本等信息,初步建立智慧检修知识库。
2.3 检修需求画像建立
检修需求画像:检修需求画像的主要工作包括短语挖掘、学习预测和关系分析3部分。
通过实现短语挖掘、关系分析和学习预测的功能,将对新生成的检修需求自动匹配识别算法,系统将根据检修需求中关键字如“瀑布沟”“3号水轮发电机组”“推力轴承”“外循环冷却器”“管路”“渗漏”,快速为检修需求进行画像,并匹配已有检修知识库中对应的检修词条。
在本文中,短语挖掘方法将采用基于有监督学习的短语挖掘算法实现(图2)。

图2 基于有监督学习的检修需求短语挖掘流程
如图2所示,短语挖掘算法主要通过计算候选短语的统计指标特征来挖掘,其中:
(1)学习预测:在深度神经网络模型中,“发电机组”、“推力轴承”、“外循环冷却器”、“管路”、“渗漏”等词或字符将被表示为一个低维稠密空间中的向量。基于这些向量表示,可使用典型的网络结构(如卷积神经网络CNN、循环神经网络RNN)抽取字词之间的组合特征及关联关系。与传统方法相比,深度神经网络能捕捉到更多隐性的语义特征,能取得更优异的性能。
(2)关系分析,检修要素寻优:系统能根据不同的检修任务关注维度,包括人员姓名、工种、消耗性材料、工器具、工期、防范措施、工艺标准、检修质量、风险因素、风险等级10个维度,通过粒子群PSO寻优算法,生成有差异性的检修优化方案,比如安全优先、经济性优先、工期优先等可以作为检修方案的优先项,自动生成与之对应的检修优化方案。
(3)检修绩效指标自动评价:系统为检修任务的完成进行评判,比如量化目标检修工期与实际检修工期差异、人工消耗差异、工器具使用差异、消耗性材料差异、风险因素差异,并作为反馈,指导后续同类型检修任务优化的生成。
2.4 知识应用
检修要素与检修需求匹配关联的构建,是语义识别、自然语言处理与数据挖掘技术的综合应用,核心在于建立起自然语言形式的需求与计算机知识之间的映射关系。在本课题方案中,将把建立映射关系的过程分为两个子过程,即实体链接和属性理解。其中,实体链接是指识别检修需求所提及的内容,并将其链接到构建的数据库中。属性理解则是指识别检修需求提及内容,其对应关联的检修词条和检修要素,这其中便要应用到模糊聚类算法以及基于深度学习的KBQA技术进行匹配计算。本文方案中,知识应用部分的工作流程如图3所示。

图3 检修需求与检修要素匹配以及检修方案智能生成
2.5 工程应用
以某容量63 MW混流式机组A修为例,通过其他类似机组检修历史数据建立模型,模型包含人员姓名、工种、成本、工期、检修质量、风险等因素,通过粒子群PSO寻优算法绘制的工期、质量、成本两两之间的关系图,拟合了相应的函数。
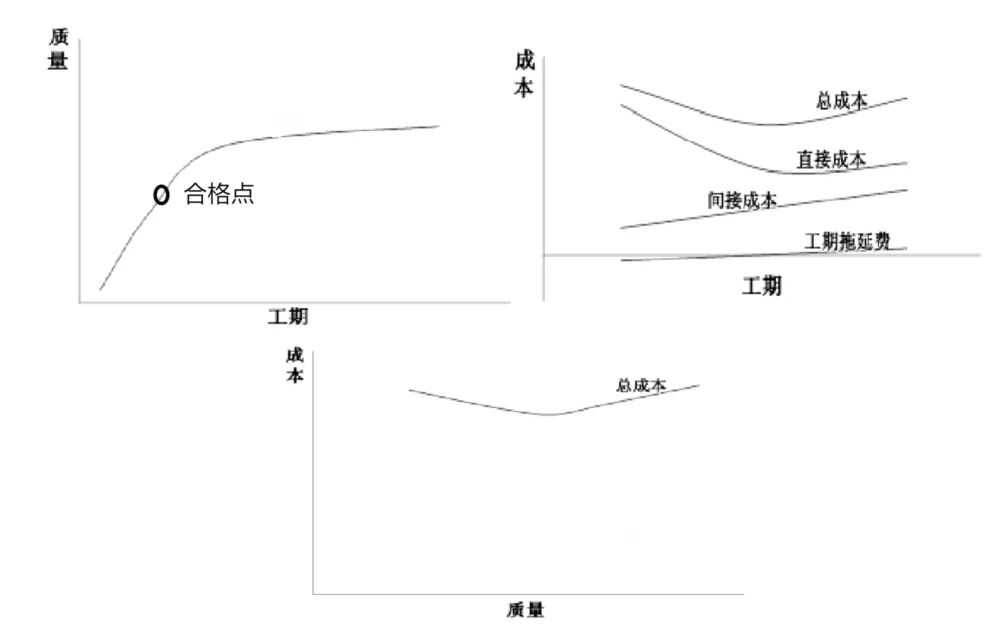
图4 项目工期——质量——成本关系曲线
然后以最高进度要求、最低预算成本、质量达标要求为约束条件,以工期——质量——成本最优化为目标函数,优化生成检修方案,其中包含检修顺序、持续工期优化调整等。
3 结语
本文提出,在应用大数据机器学习算法、自然语言处理技术、深度神经网络算法等先进技术的同时,也充分考虑到公司日常工作中遇到的实际问题与技术需求,如检修资源不足、专家力量紧张,检修方案的确定与实施存在滞后;此外,随着越来越多信息系统的部署,在制定检修方案时,所需要权衡考量的因素也越来越多。通过本课题方案的实现,把制定检修方案的工作交由大数据分析工具来辅助完成,此举将显著提高人员效率,降低成本,切实推动数字化转型。
本文依托NLP自然语言处理技术对检修需求、检修要素进行处理,将图表类、文本类的信息,以及已有的各类检修数据,转化为计算机能够识别和查询的结构化知识。而利用大数据机器学习算法,包括模糊聚类算法以及基于深度学习的KBQA技术,对转化的检修信息数据进行关联匹配,从而建立检修方案智能生成模型,形成检修建议。除此之外,系统还通过粒子群PSO寻优算法,根据不同的检修任务关注维度,完成检修方案自动寻优。在检修任务完成后,系统还可根据目标检修工期与实际检修工期差异、人工消耗差异、工器具使用差异、消耗性材料差异、风险因素差异作为考量维度,对检修任务进行评价,生成反馈并指导后续同类型的检修任务的优化生成。
