基于机器学习算法的县域台风灾害经济损失风险评估
2022-02-07杨绚张立生王铸
杨绚,张立生,王铸
(国家气象中心,北京 100081)
1 引 言
中国是全球台风灾害最严重的国家之一,台风灾害发生频次高,具有明显的地域性和季节性特征。据世界气象组织和我国有关部门统计,21世纪以来(2000—2013 年),每年平均登陆我国的台风个数达7.6个,每年造成约251人死亡,平均每年造成的直接经济损失约441 亿元[1]。随着我国经济的快速增长,台风造成我国的直接经济损失有显著增加的趋势[2-4]。因此,科学防台除了要提高台风预报水平之外,及时、准确的评估台风灾害的影响同样重要,这在一定程度上可提高防台减灾的主动性和针对性,对台风灾害防御、居民财产安全保障等具有重要意义。
如何有效评估台风灾害影响一直是国内外有待突破的热点和难点之一[5]。随着灾害观测技术的提高,巨灾损失概率模拟和评估的巨灾模型应运而生[6]。国际上的巨灾模型公司(如AIR、RMS等)、保险或再保险公司(如Swiss Re 等)以及美国政府(如HAZUS-MH 飓风模型[7])、澳大利亚政府等纷纷开发了巨灾风险模型对台风灾害影响进行评估[8]。近些年,我国台风灾害影响评估方面也取得了显著进展,许多学者相继在台风致灾因子危险性及对承灾体脆弱性[9-11]、台风灾情的时空特征及等级评估[3,12-18]、结合风、雨等致灾因子与损失关系构建定量评估模型[19-20]、利用灾损脆弱性曲线预评估台风灾害影响[21-23]、台风灾害风险评估与区划[24-25]等方面开展了大量研究。
台风灾害评估主要以单个台风过程为主,通常基于历史台风灾情,建立致灾因子、孕灾环境与灾情因子之间的关系模型,但这三者具有复杂的非线性关系。已有许多学者利用非线性神经网络[26]、灰色关联分析法[27-28]、信息扩散技术[29-30]、风险熵-极限学习机[31]等方法对台风灾害影响评估进行分析和建模。近年来,随着人工智能技术快速发展,诸多学者趋向于把机器学习等算法应用到气象灾害影响评估工作中[32-34]。机器学习算法能直接通过训练样本确定模型结构、参数,对变量间依赖关系进行拟合,它的非线性特性使其适用于多变量预测。随着数据挖掘技术的发展和历史灾害损失数据的积累,运用机器学习算法发掘灾情数据中隐藏的规律对台风灾害损失进行评估,是台风灾害影响评估新的尝试。
机器学习算法在气象灾害等领域已经有了一些应用研究,但以往的研究多利用单一算法构建模型,对多个算法的对比研究还较缺乏;另一方面,以往的研究,基于县(区)域的台风灾害研究通常只针对某个省或某一区域[20,26],利用我国东部和南部地区的县(区)域灾情的台风灾害损失模型还较少。本文基于2008—2019 年影响我国的109 场台风的县(区)域灾情记录,将直接经济损失对应的风险分为五个等级,运用五种经典的机器学习算法,包 括 SVM、RF、AdaBoost、XGBoost 和LightGBM,挖掘台风损失风险等级与致灾因子和环境变量之间的关系,对比不同机器学习算法构建的模型的性能指标,选择最优算法建立我国县域台风灾害经济损失风险评估模型,并应用于台风“天鸽”进行性能检验和评估。该模型拟为防灾减灾为目的的台风灾前预评估提供科学支撑。
2 数 据
2.1 台风灾情数据
台风历史灾情数据主要来源于中国气象局气象灾害管理系统的灾情直报(以下简称为“直报系统”)和国家减灾中心,该数据为2008—2019 年由台风灾害造成的,以县(区)域为单位统计收集的灾情记录,该记录包括灾情开始和结束时间、灾害类型、灾害影响描述及直接经济损失等信息。对直报系统的原始灾情进行数据清理:(1) 去除明显奇异值或错误值、重复报送及信息不完整的灾情记录;(2) 对台风影响期间,灾害类型填写为“暴雨灾害”的灾情进行分析和判断,根据灾害影响描述里表述为受台风影响的暴雨灾害,归为台风灾情,并参与建模。经过数据清洗和整理,本研究得到用于建模的台风灾情包括2008—2019年影响我国的109 场台风,县(区)域灾情事件共4 212 件,其中有直接经济损失数据的有4 055件。
收集到的台风灾情记录主要分布在我国东部和南部省份,例如黑龙江省、湖南省、湖北省等地也有台风灾情记录的上报,但由于数据量较少,数据分布不均,因此本文的研究区域取台风灾情较完整的地区(图1)。图1a给出2008—2019年期间,收集到的台风灾害事件数,浙江、福建、广东、广西和海南的沿海地区台风灾害事件数均超过5次,浙闽交界地区及广东西南部、广西东南部沿海和海南的部分地区台风灾害事件达9 次以上。图1b 给出2008—2019 年期间,单次台风造成县(区)最大的直接经济损失,辽东半岛、山东中北部、浙江东部和北部、福建东部、广东南部、广西东南部和海南的部分县(区)受台风灾害的损失较大,最大直接经济损失超过5亿元。
2.2 致灾因子数据
2.2.1 台风数据
采用中国气象局上海台风研究所整编的西北太平洋热带气旋最佳路径数据[35]。该数据在2008—2019 年共有296 场热带气旋,根据2.1 节的台风历史灾情数据,选取了影响我国的109场热带气旋作为建模样本。最佳路径数据包括每个热带气旋的国际编号、中国热带气旋编号、英文名称、台风路径点的年、月、日、时、等级、经度、纬度、近中心最低气压以及最大风速等,记录时间间隔为6 h。
2.2.2 台风风雨数据及应用
台风暴雨和大风是台风灾害的主要致灾因子。本文采用国家信息中心提供的2008—2019年全国区域气象观测站逐小时降水量和极大风速数据。区域气象观测站的站点数量在近12年来得到了飞速的增长,2008 年全国区域气象观测站有7 000多站,到了2019 年,全国区域气象达6 万多站。其中2008—2010年区域气象观测站的极大风速数据存在部分缺测,因此,对缺测的县(区)用国家气象观测站的逐小时极大风速代替。
在分离和提取台风降水和风速的范围时,本文参考任福民等[36]提出的模仿人工识别热带气旋降水和风速思路的客观天气图分析法(OSAT),该方法对台风大风和降水的识别能力较好,且得到了较多的应用[37-38]。利用该方法,对2008—2019年影响我国109场台风的风、雨范围进行判定和提取,结合热带气旋路径及影响时间,整理了6 个致灾因子的解释变量,分别为每场台风过程的极大风速、大风(6 级以上)持续时间、最大日雨量、最大小时降雨量、短时强降雨(小时降雨量超过20 mm)的持续时间、过程总降雨量。为了与台风损失灾情匹配,将区域站在县(区)范围内致灾因子的最大值,作为该县(区)的致灾因子进行建模。
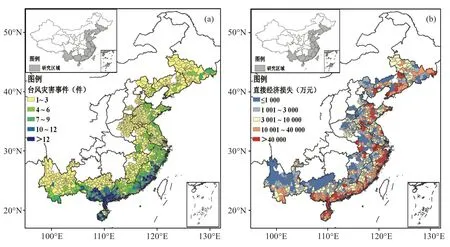
图1 2008—2019年台风县(区)灾害事件数(a)、最大直接经济损失(b)
2.3 孕灾环境数据
本研究选用的孕灾环境解释变量有4个,包括县(区)域的数字高程模型(Digital Elevation Model,DEM)平均值、DEM 标准差、地形指数标准差、河网密度数据。
2.3.1 DEM数据
DEM 数据来源于美国奋进号航天飞机的雷达地形测绘SRTM(Shuttle Radar Topography Mission,SRTM)数据。本研究将1 km×1 km 网格的DEM 数据匹配至研究区域县(区)空间,得到县(区)域空间内的平均高程值(图2a)和高程标准差(图2b)。
2.3.2 地形指数
地形不仅影响地表和近地表径流的流向和流速,而且对累积降水量的空间分布起着控制作用。为了研究流域地形、地貌对降雨径流形成和变化的影响,本研究在孕灾环境中引入地形指数。地形指数是1979 年Beven 等[39]提出的以地形为基础的半分布式流域水文模型(TOPMODEL,Topography based hydrological model)的重要参数。它用来近似表征流域径流源面积和地下水水位的空间分布特征,可反映土壤蓄水能力以及产流的空间分布[40]。地形指数的表达式为:

其中α表示通过单位等高线长度的汇水面积,β为局部地表坡度。本研究利用Arcgis 软件基于1 km×1 km 网格DEM 数据提取得到相同分辨率的网格地形指数数据,并将该数据匹配至县(区)空间上。有研究表明,地形指数标准差可反映区域内陡坡、河谷及冲积平原所占比重[41]。因此,选择县(区)域地形指数的标准差值作为该空间的孕灾环境特征之一(图2c),地形指数标准差较大的区域与主干河流基本相吻合。
2.3.3 河网密度
河网是基于中国科学院资源环境科学数据中心提供的由DEM 提取的中国河网数据集[42],本文由县(区)域内的河流长度除以其面积得到县(区)的河网密度(图2d)。
2.4 承灾体数据
本研究利用国内生产总值(GDP)数据作为台风灾害损失的主要承灾体,选用的县级GDP 数据来源于国家统计局发布的2015年全国县级统计年鉴(图2e)。
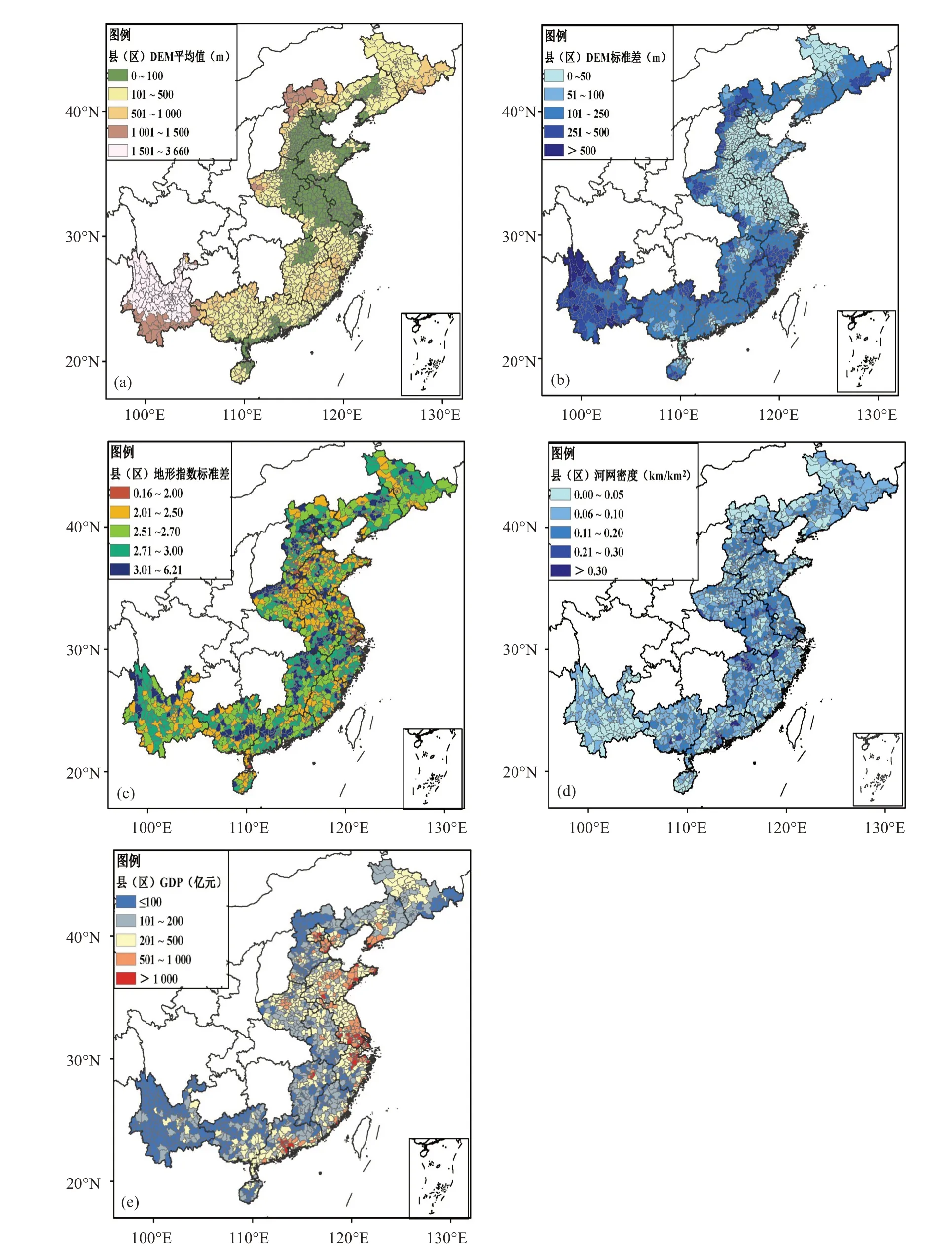
图2 研究区域的县(区)DEM平均值(a)、DEM标准差(b)、地形指数标准差(c)、河网密度(d)、GDP(e)
3 台风灾害风险评估模型的构建方法
3.1 台风灾害损失等级的分类方法
直接经济损失是反映台风灾情损失严重程度的重要定量指标之一,也是救灾备灾、风险转移的重要参考。本研究参考殷洁等[24]对台风灾害损失等级的分类方法,即利用灾害损失与承灾体暴露度的比值(损失率)作为划分台风灾害等级的标准。在本研究中,利用直接经济损失与GDP 的比值作为台风灾害损失的损失率,把中国台风灾害损失等级划分为五类,将直接经济损失率小于0.15%、0.15%~0.35%、0.35%~0.50%、0.50%~0.58%和大于0.58%作为台风灾害损失最低风险、较低风险、中等风险、较高风险和最高风险的阈值。
3.2 五种机器学习算法介绍
针对多分类问题,本文选用典型的五种机器学习算法,基于SVM、RF、AdaBoost、XGBoost 和LightGBM 的分类算法,构建台风灾情与孕灾环境和致灾因子之间的非线性关系模型。
SVM 算法于1995 年正式发表[43],很快成为机器学习的主流技术,并掀起了统计学习在2000 年前后的高潮。SVM 方法是通过一个非线性映射提高样本空间维度,使得在低维度的样本空间中非线性问题映射后变为高维度空间中的线性问题。SVM 是针对二分类任务设计的,之后对多分类任务也有了专门的推广[44]。本研究利用随机梯度下降分类器SGDClassifier(Stochastic Gradient Descent)对SVM算法实现多分类任务。
机器学习算法中,集成学习(Ensemble Learning)通过将多个学习器进行结合,常可获得比单一学习器显著优越的泛化性能。集成学习方法大致分为两大类,即个体学习器间存在强依赖关系、必须串行生成的序列化方法,以及个体学习器间不存在强依赖关系、可同时生成的并行化方法[45]。前者的代表是Boosting,后者的代表是RF算法[46]。其中,Boosting 算法的最著名的代表是AdaBoost[47],并且,XGBoost[48]和LightGBM[49]均是近几年性能好、应用广的基于梯度提升决策树(Gradient Boosting Decision Tree)模型的Boosting算法。
3.3 样本数据处理
台风灾害损失的原始数据样本,在构建训练集和测试集时,是一个非常不平衡的数据集,主要有两个方面的原因导致的数据类别不平衡。一方面,由于较低风险的样本数大于最高风险的样本数,根据2.1 节介绍的2008—2019 年台风灾情数据,有直接经济损失的数据为4 055 个,按照台风灾害损失等级分类标准,将该数据集分别划分为较低风险、中等风险、较高风险和最高风险的样本数为:1 647、1 197、760 和451 个。因此,对于这四类样本采用SMOTE 方法在数据层进行过采样处理[50],将中等风险、较高风险和最高风险的样本数均增加至1 647个。另一方面,在一次台风影响过程中,由于有灾情损失的县(区)远小于无损失但受台风风雨影响的县(区),在原始数据样本中,该类样本数超过30 000个,因此,需要通过在最低风险类别的数据层进行欠抽样处理,减少该类样本数,为了与其他类的数据样本数保持一致,对最低风险类的数据抽取1 647个样本。同时,为了避免在最低风险类别欠抽样导致的数据信息偏差等问题,本文采用对最低风险类别抽样5次结果的平均值,作为模型的最后结果。
3.4 模型评估检验方法
对于分类模型的评估,在机器学习方法中通常使用混淆矩阵来评估分类效果,混淆矩阵是以矩阵的形式将数据集中真实的类别与分类模型预测的类别进行汇总,以进行精度评价。在机器学习分类模型的性能评估中,常用的性能测量指标是准确率(Accuracy)、精确率(Precision)、召回率(Recall)和F1分数。
本文为了更全面地评估模型,还引用在天气预 报 运 用 的TS 评 分(threat score,TS)、空 报 率(false alarm ratio,FAR) 和 漏 报 率(prediction omission,PO)以及错分率(err ratio,ER)来检验每个台风灾害风险等级的分类效果,计算公式如下:
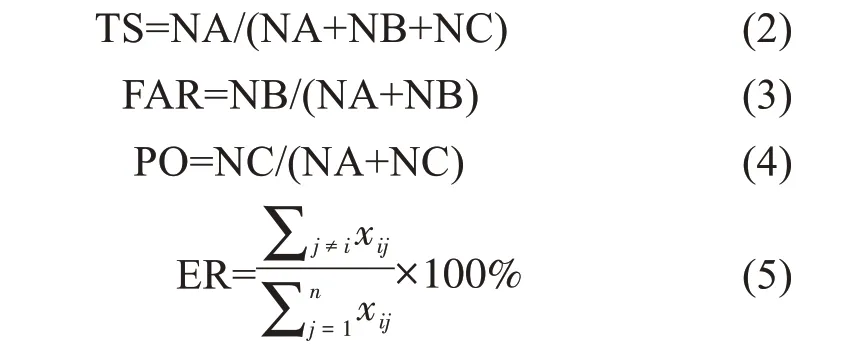
式中:NA 为分类正确的样本数;NB 为空报样本数;NC 为漏报样本数;xij为混淆矩阵。当模型评估的风险等级与实况灾情等级相同,判定为分类正确; 当模型分为某等级而实况灾情没出现在该等级内,则为空报;当模型评估不在某等级内,而实况灾情出现在该等级内,则为漏报。
4 模型建立、对比与应用
4.1 建立台风灾害损失风险评估模型
本研究选取以致灾因子和孕灾环境为基础的10 个解释变量(自变量),与台风灾害损失风险类别(因变量)构成数据集,分别利用SVM、RF、AdaBoost、XGBoost 和LightGBM 五种机器学习算法构建台风灾害损失风险模型。
在训练过程中,均采用五折交叉验证方法,即将数据集D 随机分为相等容量的5 份子数据集D1、D2、D3、D4 和D5,选取其中一份子数据集Di作为测试数据集Testi,其他4 份作为训练数据集Traini,从而构成第i组训练测试集(Traini,Testi,i=1,2,3,4,5)。 分 别 对SVM、RF、AdaBoost、XGBoost和LightGBM 算法参数进行不断调优,找到平均准确率最高的对应参数。通过对5组训练-测试数据集进行训练和测试,得到5组结果的平均分类准确率进行精度评判。
4.2 不同机器学习算法模型的性能对比
表1 给出基于不同机器学习算法构建的台风灾害损失风险模型的性能评估结果,其性能考核指标包括了准确率、召回率、精确率和F1 分数。基于RF 算法的台风灾害损失模型的性能是最好的,多分类任务的平均准确率和精确率达0.68 和0.67,召回率有0.68,F1 分数为0.67。XGBoost、LightGBM、AdaBoost 和SVM 算法的准确率依次为0.63、0.62、0.45 和0.41。因此,下一节我们将重点针对RF 算法构建的台风灾害损失模型进行详细评估分析和应用检验。
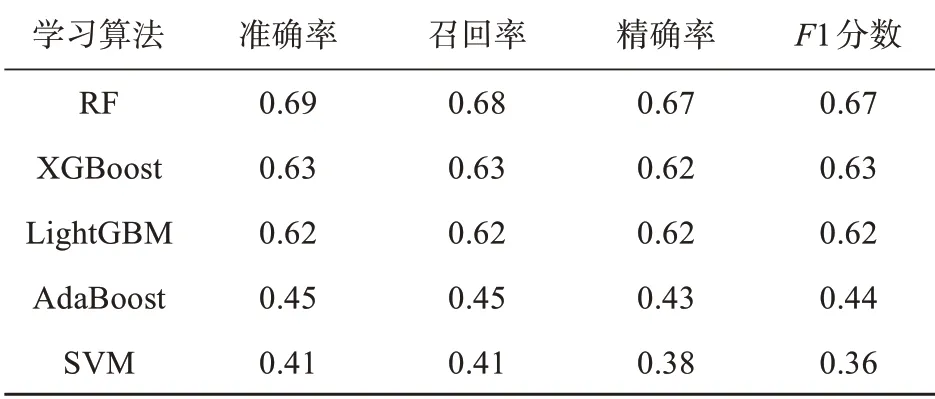
表1 基于不同机器学习算法构建台风灾害损失模型的性能对比
4.3 基于RF算法的台风灾害损失模型
4.3.1 解释变量重要性
RF算法用精度下降率来表示解释变量的重要性,即去除某个解释变量后分类准确率的降低程度,精度下降率越大,表示该解释变量越重要。图3 给出台风灾害风险模型10 个解释变量的重要性排序,相对孕灾环境,致灾因子的解释变量对台风灾害风险的影响更大,解释变量排序的前五位均为致灾因子变量,这五种致灾因子变量的精度下降率均超过10%,致灾因子解释变量的重要度累计达67.7%,孕灾环境解释变量占32.3%。
在致灾因子变量中,降雨导致灾情损失的重要性要大于风速,Wen 等[23]的研究也指出,对于我国台风造成的损失,降雨的相关性要高于风速。在台风灾害损失风险模型中,最大日降雨量是最重要的解释变量,精度下降率达13.3%,其次是短时强降雨的持续时间,精度下降率有12.4%,最大小时降雨量和过程总降雨量的重要度几乎相等,为11.7%,过程极大风速的贡献率为10.9 %,而6级以上大风的持续时间的重要性在致灾因子变量中最小,其精度下降率为7.7。四种孕灾环境解释变量的重要性均低于10%,相对而言,河网密度的重要性最大,精度下降率为8.8%,其他孕灾环境解释变量的重要性从大到小依次为:DEM 平均值、DEM标准差和地形指数标准差。
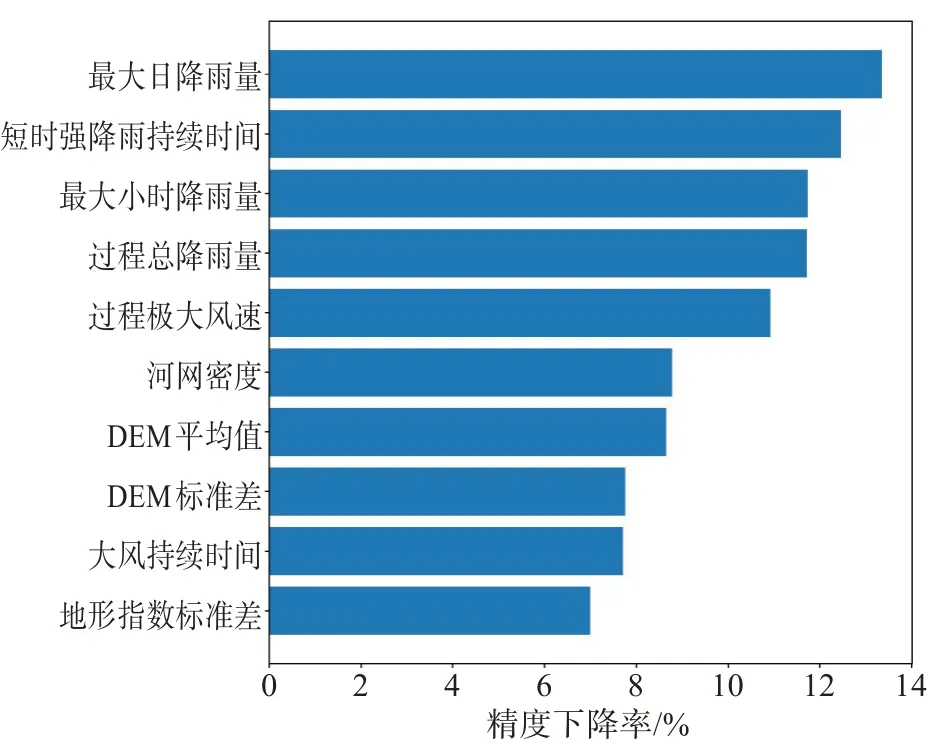
图3 解释变量重要性排序
4.3.2 模型分类效果评估
为了评价台风灾害风险评估模型的性能,我们不仅计算每个风险类别的准确率,还引用天气预报中的TS评分等方法检验模型的效果。表2给出台风灾害损失风险评估模型分别在训练集和测试集中的准确率、TS 评分、空报率和漏报率,结果表明,该模型对于台风灾害损失风险评估效果较好,在训练集和测试集的平均准确率为0.69 和0.65,TS 评分的平均值为0.55 和0.51,空报率的平均值为0.34 和0.37,漏报率的平均值为0.33 和0.38。其中,模型对于最低风险分类的准确率是最高的,训练集和测试集的准确率达0.95 和0.93,TS评分分别为0.72 和0.71,其空报率和漏报率也在0.25 以下;模型对于最高风险也有较好的辨别能力,训练集和测试集的准确率在0.7 以上,TS 评分分别为0.62 和0.57,空报率和漏报率控制在0.32以下。相对而言,模型对于较低风险、中等风险和较高风险的分类能力略有不足,测试集对于这三类的准确率分别为0.57、0.48 和0.59,TS 评分分别为0.42、0.38和0.45,空报率和漏报率在0.38~0.58之间。
为了分析模型产生错误的种类,图4给出测试集混淆矩阵的错分率示意图,模型对于较低风险、中等风险和较高风险的分类能力出现错误的原因。模型把实况为中等风险的类别分到较低风险的类别里,这种情况的错分率是所有错误率里最高的,达25.5%,即模型对于中等风险存在较高概率的低估;同时,中等风险被错误的分为较高风险的概率有19%,这是中等风险类别的准确率和TS评分相对较低的原因。模型将较低风险类别预测为中等风险的概率也较高,达到了25.3%。模型将较高风险分至中等或最高风险的概率在19%~21%之间。模型对于最高风险的识别能力相对较好,但也有19%的概率将其低估至较高风险的类别里。模型对于最低风险的识别能力是最好的,其错误率不超过4%。
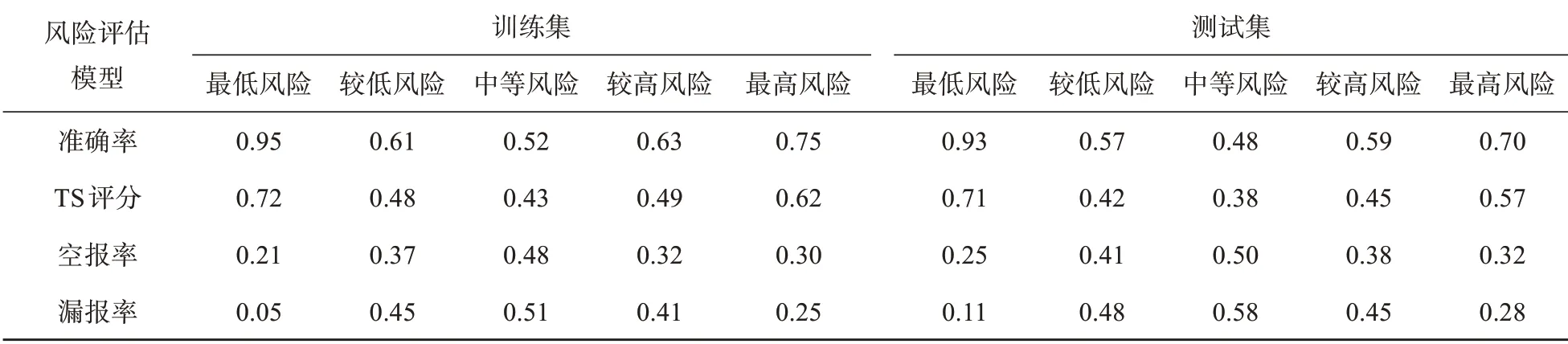
表2 模型在训练集和测试集的准确率、TS评分、空报率和漏报率
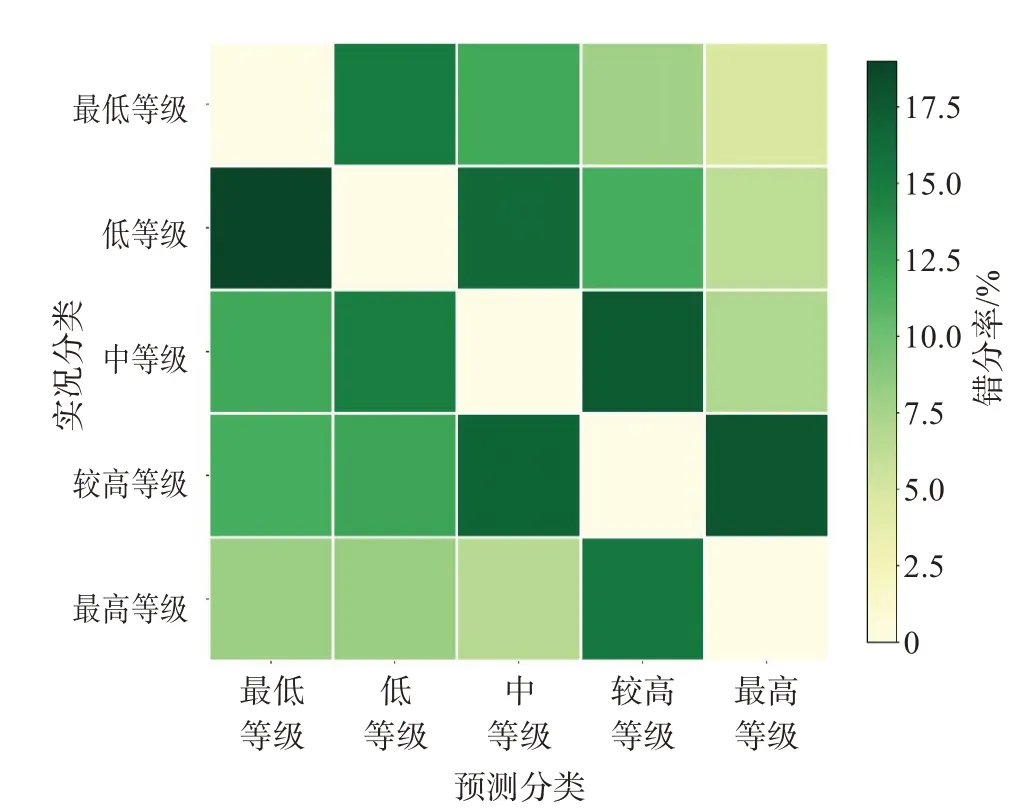
图4 测试集混淆矩阵的错分率
4.3.3 案例应用
为了更直观反映台风灾害风险模型的评估效果,选择一次典型台风灾害过程进行应用和检验。2017 年第13 号台风“天鸽”是近几年造成我国华东及云南等地严重灾情的台风之一,台风“天鸽”于北京时间2017 年8 月23 日12:50 前后以强台风级在广东珠海南部沿海登陆,登陆时风力达45 m/s (14 级),受其影响,广东珠江口及西南部沿海阵风普遍达12~14 级,局地达15~17 级;广东西南部和沿海地区、广西西部和中南部、云南东北部和东南部等地累计雨量有100~250 mm,局地300~400 mm。据国家减灾中心消息,“天鸽”造成广东、广西、云南等地严重的灾情,累计直接经济损失超过200亿元。
图5a 给出收集到的台风“天鸽”县(区)域灾情直接经济损失的灾害风险类型分布,受灾较严重的地区主要位于广东珠三角、广东西南及云南部分地区。最高风险区位于广东省珠海和江门市的各县(区),云南昭通的部分县也受灾严重,属于高风险区;广东茂名、阳江、云浮及云南文山、普洱和玉溪等地的县(区)属于较高风险区;广西中南部、云南南部的部分县(区)出现了较低至中等风险类型的灾情。
利用台风灾害损失风险模型评估台风“天鸽”的损失风险类型(图5b),同时,给出实际直接经济损失的风险类型与模型评估风险类型的检验评分(表3)。结果表明,台风灾害损失风险评估模型对于台风“天鸽”的损失风险评估与实际损失风险等级较一致。五类风险等级的准确率均达到0.7 以上,平均准确率达0.79;TS评分在0.58以上,平均TS评分0.66;空报率在0.31以下,漏报率在0.25以下。
从模型对广东、广西和云南的整体评估效果来看,广东和广西损失风险等级的评估与实际损失灾情较吻合,而对云南部分县(区)的评估表现不足,尤其是对云南中部和西部的损失风险等级存在一定的高估,即实况损失灾情是较低(或较高)风险的地区,模型错误评估为了中等(或较高)风险。
从不同风险等级的评估效果来看,模型对于最低风险和最高风险的评估效果最好。广东北部、广西中北部和云南东北部的部分地区没有发生(或没有收集到)经济损失灾情,模型对上述地区评估为最低风险区,其准确率和TS 评分分别达0.91 和0.76;模型评估的最高风险在广东江门、珠海以及云南昭通等地与实际灾情基本吻合,最高风险类型的评估准确率有0.86,TS 评分有0.72,空报率和漏报率也相对较低,分别为0.13 和0.19。对于较高风险等级,模型在广东云浮、云南文山和玉溪等地得到了准确的识别,但是,例如广东茂名和阳江等地实际损失风险等级为较高风险,被模型评估为中等风险,存在一定的偏差,该模型对于较高风险等级的准确率和TS 评分分别为0.74 和0.63,空报率和漏报率为0.22和0.21。模型对于较低风险和中等风险主要误差出现在云南大理、保山和临沧等地的部分县(区),模型对上述地区的风险普遍存在一定的高估,因此,在此案例中,模型对于中等风险的空报率和较低风险的漏报率均相对较高,分别为0.31 和0.25,较低风险和中等风险的准确率分别为0.72 和0.70,TS评分为0.61 和0.58。
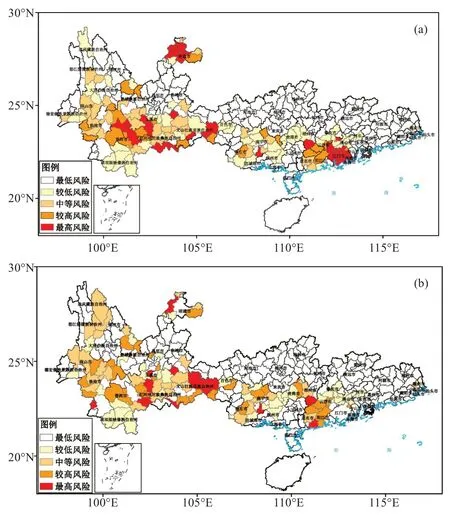
图5 台风“天鸽”实际灾情损失(a)、模型对台风“天鸽”评估(b)的风险类型
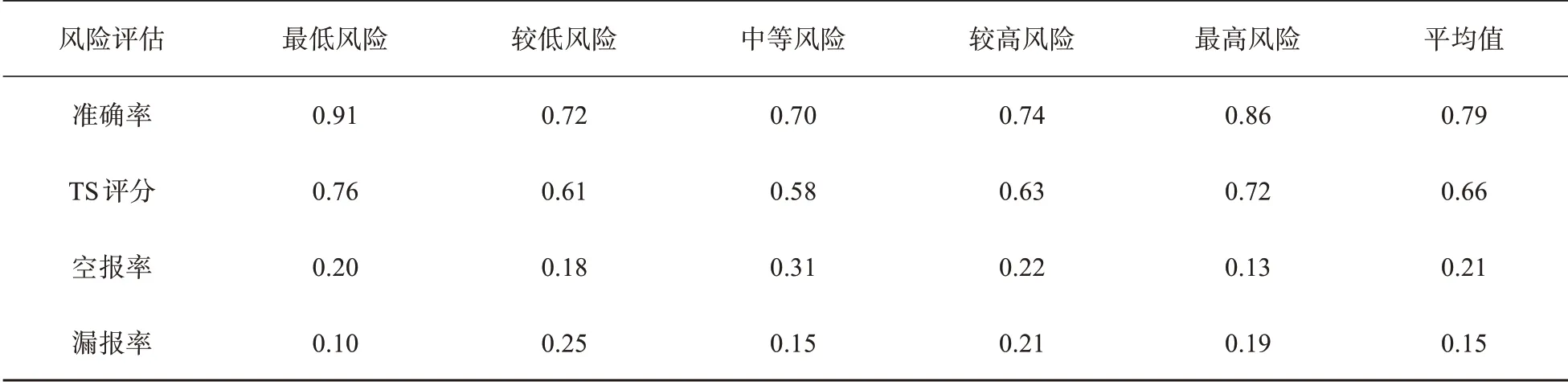
表3 台风“天鸽”损失风险评估的准确率、TS评分、空报率和漏报率
5 结论与讨论
本研究利用2008—2019 年台风县(区)直接经济损失灾情数据,根据经济损失率将台风灾害损失风险分为五类,综合考虑致灾因子和孕灾环境因素选取10 个解释变量,利用SVM、RF、AdaBoost、XGBoost 和LightGBM 算法,构建台风灾害经济损失风险评估模型,并对其进行对比、选择和案例应用。
(1) 基于RF 算法的台风灾害经济损失模型的准确率最高;利用RF、XGBoost、LightGBM、AdaBoost 和SVM 算法构建模型的准确率依次为0.69、0.63、0.62、0.45和0.41。
(2) 基于RF 算法构建台风灾害经济损失模型的结果表明,相较于孕灾环境,致灾因子解释变量对台风灾害损失风险的影响更大,累计重要度达67.7%。在致灾因子变量中,降雨导致损失的重要性超过风速。该模型在训练集和测试集上对风险分类的TS 评分平均值为0.55 和0.51,但各类别的辨别能力存在差异,根据模型在测试集的评分,分类效果依次是:最低风险、最高风险、较低风险、较高风险和中等风险。
(3) 该模型对台风“天鸽”的经济损失风险评估与实际损失风险等级较一致,评估结果与实际损失风险等级较一致,准确率均达到0.7 以上,TS评分在0.58 以上,空报率和漏报率分别在0.31 和0.25 以下。但模型对云南部分县(区)较低风险和中等风险的评估表现存在一定偏差。
本研究经过对五种机器学习算法构建模型的性能对比,选择了RF 算法的台风灾害经济损失模型进行建模,总体取得了较好的效果,但模型对于某些损失风险的分类能力存在不足,分析其原因主要有三个:一是在台风灾害过程中导致损失的因素较多,尤其是灾害链等事件发生的不确定性较大,在构建模型时,除了考虑文中的解释变量,还存在着其他因素,例如地形坡度、不透水地表组成、耕地百分比等孕灾环境因子,而人口结构和分布、当地安置转移情况和防灾减灾能力等社会因子对灾情损失也有很大的影响;二是灾情直报系统的灾情主要是由当地气象部门的值班员填写上报,会存在一定程度的漏报,并且在灾情结束后没有更新最终灾情信息的情况,由于灾情信息不够完善而导致的模型构建不充分是该模型较难避免的难题之一;三是本研究为了与台风历史县域灾情匹配,选用县域孕灾环境和致灾因子作为解释变量,但县域分辨率较粗,无法体现孕灾环境和致灾因子的局地特点,这会在一定程度上影响模型的效果。
在今后的工作中,一方面要适当增加解释变量,使模型进一步完善;另一方面,对模型的精细化程度做更大的改善,尤其是要结合我国无缝隙精细化智能网格预报技术的发展[51],将孕灾环境和致灾因子匹配至智能网格预报的网格分辨率上,并结合全国5 km×5 km 分辨率网格天气预报产品,对台风灾害损失风险进行应用和预评估,拟为台风防灾减灾、灾害风险转移等提供科学依据。
