倾斜摄影测量像控点自动识别技术研究
2022-02-04刘春阳
丁 涛 刘春阳
(1. 安徽省核工业勘查技术总院, 安徽 芜湖 234001;2. 安徽理工大学 空间信息与测绘工程学院, 安徽 淮南 232001)
0 前 言
倾斜摄影测量技术可以获得测摄对象的纹理特征,抓取相关属性信息,被广泛应用于城市管线排查、灾害预警救治、国民建设等领域[1]。但在航测作业过程中可能会受到云雾遮蔽、大气折射干扰、航摄相机镜头畸变等因素的影响,导致影像出现多类型形变,进而对原始影像产生影响,降低了数据处理精度。通过高精度控制点进行几何校正,能够减小误差,得到符合要求的数字产品。因此,在无人机倾斜摄影测量中,内业刺点精度会直接或间接影响三维模型精度[2]。但由于人工内业像控点识别的像片分辨率有限,导致像控点角点放大时像素模糊,从而影响刺点精度。
当像控点图像混在大量像片数据中时,像控点中心标志的识别效果较差。借助深度学习特征训练模型,对大量像控点图像数据进行训练,以获取高精度、高效率的像控点图像识别模型。模型在像控点特征提取上具有鲁棒性,泛化能力强,可实现计算机端到计算机端的深度网络训练。首先,通过HSV色彩空间图像增强技术来优化无人机图像;然后,以深度学习目标检测识别增强算法为基础,结合线段检测算法,对像控点进行自动角点识别,以提高像控点的识别效率与精度。
1 图像增强
Retinex是90年代中期由Edwin Land提出的一种理论[3]。该理论将人眼能接收到物体影像归因为自然光源或人工光源在物体上发生了反射,被广泛应用于人工智能、图像处理、信号分析等领域。物体能够成像的两大不可或缺的因素为入射光和反射光,而Retinex通过减少或抵消外源光照(如日照、灯光等)对最终成像的影响来增强影像质量。文献[4] 以RGB色彩空间和小波变换为基础,采用Retinex算法进行井下暗色背景的影像增强,但可能出现图像失真现象。无人机拍摄的像控点像片为高空影像,相较于贴近摄影,失真几率更大。
HSV是根据颜色的直观特性构建的一种色彩空间,包括色调(H)、饱和度(S)、明度(V)。相较于RGB色彩空间,HSV色彩空间在图像增强上有一定优势。针对Retinex算法可能出现图像失真的情况,将RGB与HSV互换。对于HSV色彩空间而言,考虑到无人机倾斜摄影的影像可能会受到稀薄云层、雾霾等因素的影响,利用明度分量的递增变化对包含像控点的航摄影像饱和度进行校正,以达到目标像控点图像增强的目的。
在提取明度分量的基础上,结合原始无人机影像数据照度分量,运用多尺度Retinex算法计算提取后影像数据的照度分量估计值[5],如式(1)所示:
(1)
其中:
L=lg (IV(x,y))×Hk(x,y)
(2)
式中:IV(x,y)为原始无人机影像数据照度分量;wk为第k个尺度的加权系数;N为尺度个数;L为照度分量;Hk(x,y)为中心环绕函数。
饱和度分量会随着亮度分量的改变而改变,因此,在增强亮度分量的同时需要控制饱和度分量。在HSV色彩空间中,光谱色占比越大,颜色与光谱色的贴合度越高,颜色的饱和度也就越高。为了避免图像失真,对饱和度分量进行加强处理[6]。另外,还需进行噪声滤除。将无人机航摄影像由HSV色彩空间转回到RGB色彩空间即可达到图像增强的目的。
分别采用单尺度Retinex算法、多尺度Retinex算法和基于HSV色彩空间的改进Retinex算法对明亮度较暗的无人机倾斜摄影影像进行图像增强。由图像增强效果对比(见图1)可知,采用3种算法获取的图像的明亮度均得到了提高。其中,采用单尺度Retinex算法获取的图像亮度增强效果较差;采用多尺度Retinex算法获取的图像亮度增强过度,导致图像真实性较差;采用基于HSV色彩空间的改进Retinex算法获取的图像明亮度、真实度的增强效果更优。
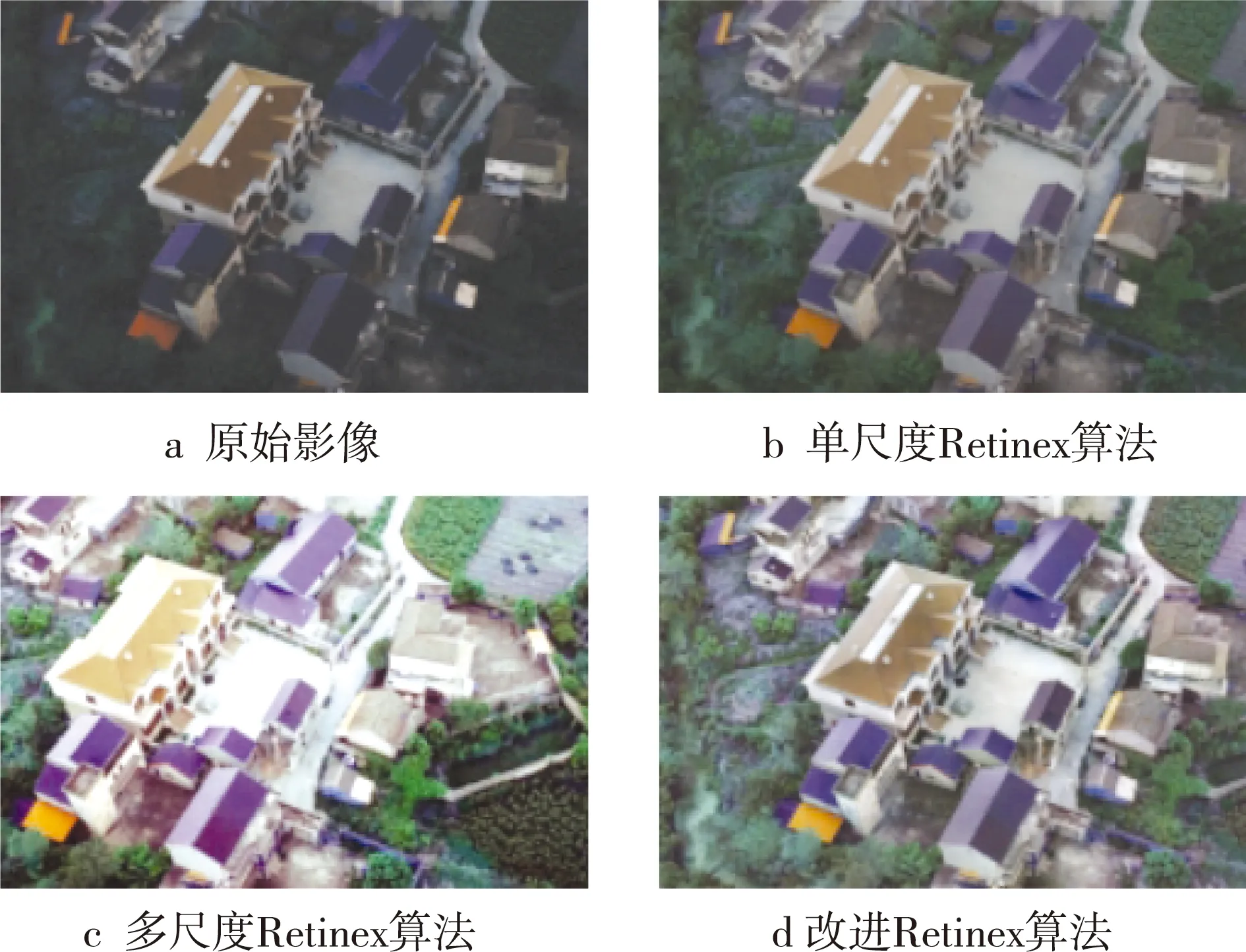
图1 图像增强效果对比
2 深度学习增强算法
深度学习(deep learning,DL)是由Geoffrey Hinton教授在借鉴了人类大脑学习方式后,提出的类比于计算机智能处理解算的一种方法。DL将初代特征向量转换到新的特征空间中,使机器自主训练并学习,有助于归类并识别目标所包含的多层次特征属性,可从表层的类神经网络转向深层的神经网络。目前常见的DL目标检测模型主要有:单步多目标检测(single shot multibox detector,SSD)模型、基于区域的全卷积神经网络(region-based full convolutional network,R-FCN)模型和基于快速区域的全卷积神经网络(fast region-based full convolutional network,Fast R-CNN)模型。以卷积神经网络(convolutional neural network,CNN)衍生算法为代表的算法在图像检测领域的应用较为广泛,图像识别精度较高。但由于CNN算法可能导致大量图像边界冗余,从而使检测周期延长,生产成本增加。与R-CNN的双步检测衍生算法不同,目标检测(you only look once,YOLO)算法只需单步检测,省略了从目标图像候选框中分离出衍生分支这一步骤[7],避免了特征图候选区域堆积的情况,以网格的形式分割图像,选取非单一的默认候选框进行独立网格的特征分类和坐标回归[8]。这简化了网络运算步骤,提高了计算机处理速度,保证了目标检测精度。但对于较小的目标而言,该算法可能出现遗漏或者检测错误的情况。相较于YOLO算法,SSD算法在目标特征检测精度和计算机处理速度等方面有着良好的表现,可达到亚像素级别的识别精度,通过简单的参数调整即可处理数字图像。基于此,本次研究采用线段检测(line segment detector,LSD)算法来增强SSD算法,以提取具有特殊线性条件的像控点标志目标特征。
2.1 目标检测
无人机拍摄的图像数据量较大,人工挑选包含像控点的像片时间过长;另外,像控点标志较小,肉眼挑选难度较大。因此,考虑到像控点的检测准确度和周期,提出基于深度学习的SSD300目标检测增强算法,在保证机器识别速度的前提下,提高像控点标志识别的精度和能力。像控点目标检测包括以下3个步骤:
(1) 将尺寸为300×300×3的包含像控点的影像数据输入到主体网络中,在提前训练好的基础网络中截取非单一尺寸的特征图,同步输出卷积层的相关特征图像,6个卷积层分别为C4_3、C7、C8_2、C9_2、C10_2、C11_2。
(2) 根据输出特征图中的像素点建立候选框。由于类别不同,导致默认框数不同,根据不同尺寸将其分成6个类别。
(3) 筛选候选框,分离出需要的包含像控点目标的无人机影像数据。
由于相邻卷积层之间无紧密联系,导致其他卷积层可能出现无特征信息补充,因此提出一种加强卷积层与卷积层联系的基于LSD算法的SSD增强算法。将C4_3、C7、C8_2、C9_2、C10_2、C11_2作为目标特征层,结合浅层和深层等2种特征层,采用空洞卷积底部采样的方法,以达到识别模型对无人机影像中小目标像控点标志学习的目的。
浅层与深层特征层相互融合形成的低特征层C4_3分为2层结构。第1层通过第1卷积核,不改变特征图大小。第2层通过第2卷积核进行C7反卷积上采样处理,获得256个尺寸为38×38的特征图,改变了特征图大小,变化尺寸翻倍。
通过上述步骤获得的新C7特征层可分为3层结构。第1、2层分别通过第1、2卷积核,利用新的C7特征层自主卷积运算处理获得512个尺寸为19×19的特征图。第3层通过第3卷积核进行 C8_2反卷积上采样处理,获得256个尺寸为19×19的特征图,改变了特征图大小,变化尺寸翻倍。
新C8_2特征层与新C7特征层的结构大体相同。经过C4_3、C7、C8_2的分层卷积运算后,特征图的尺寸逐级递减。在兼顾目标检测算法精度的前提下,还应考虑实际检测效率,因此,自C9_2特征层后,不进行浅层与深层的融合操作[9-10]。
损失函数的计算如式(3)所示:
(3)
其中:
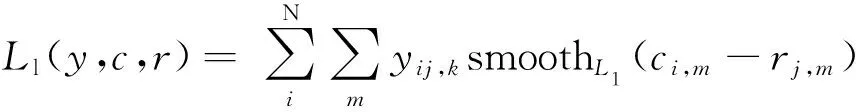
(4)
(5)
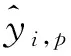
在进行包含有像控点的无人机倾斜摄影像片检测时,检测框正确识别目标图像为正样本,无法识别或识别错误的为负样本。
采用草地、水泥道路、柏油道路、人行道、泥地和石子路等6种环境背景下布设的像控点标志图像进行实验。图像宽度为5 472像素,长度为3 648像素。像控点数据集共包含200张影像,其中100张作为已标注的像控点数据集,100张作为待检测的像控点数据集。训练数据均经过图像增强和降噪处理,采样阈值设为0.5。根据SSD卷积层输入尺寸的要求,采用滑窗采样方法(学习率为100%,滑动窗口为300)将待检测的像控点数据集中的像片尺寸裁剪为300×300。
采用基于梯度下降的动态自适应梯度方法[11]进行像控点识别训练。利用Arcmap10.2图像处理软件对无人机影像数据进行掩膜裁剪,获得像控点图像的训练数据GCP.tif。创建待检测的像控点数据集的矢量标签GCP.shp,将图层属性列表中的数值修改为300。在进行栅格数据转化后,设置像控点范围使其与起始图像保持一致,从而获得标注好的标签。对标注好的标签进行裁剪,分离出1 100张300×300像素的像控点标志像片,随机选择其中的60%作为训练影像,30%作为测试影像,10%作为验证影像。通过增强SSD算法对无人机倾斜摄影的像控点影像数据进行提取,能正确识别的像控点为矩形红白相间的标靶像控点。
2.2 评价指标
选取的评价指标包括:(1) 回收率(Recall),待检测的像控点数据集中能被准确识别的像控点比例;(2) 精确率(Precision),模型预测的像控点图像中能识别出像控点的数量占比;(3) 重叠度(intersection over union,IOU),识别出的像控点图像和实际包含像控点图像的重叠量与实际像控点的比值;(4) 均值交并度(mean intersection over union,MIOU)是图像分割的关键指标,首先计算出所有的IOU值,然后求解总体均值;(5) 准确率(Accuracy),模型识别出的像控点数量占整体样本数量的比例。对YOLO算法、SSD300算法和SSD300增强算法性能进行比较分析,结果如表1所示。SSD300增强算法的回收率为86.1%、精确率为77.9%、重叠度为75.3%、均值交并度为76.9%、准确率为89.7%,可见SSD300增强算法性能优于YOLO算法和SSD300算法。

表1 3种算法评价指标的对比
3 线段检测算法
3.1 算法原理
LSD算法主要检测图像中的直线信息,当直线属性达到检测阈值,即被判断为目标线段信息。对于无人机倾斜摄影图像而言,包含像控点的图像梯度与直线交替变化至关重要。首先,计算每个像素的水平线角度,产生一个单位向量场,使图像中的所有矢量线段均与其基点的水平线段相切;然后,这个向量场被分割成像素的连接区域,这些像素共享相同的水平线角度。
基于反向原则和Helmholtz原则,LSD算法在满噪声的图像中无法检测出目标线段[12]。在反向模型中,一条线段上的对齐点数量应该和被检测到的线段上的一样多,或者更多。假设给定1个图像i和矩形r,k(r,i)为对齐点的数量,n(r)为矩形r中的像素总数,则与检测到的兴趣点数量相同的期望点数量如式(6)所示:
NE=NtestPH0,k(r,I)≥k(r,i)
(6)
式中:NE表示期望点数量;Ntest表示测试次数,为所有可能的矩形数量之和;PH0表示反向模型H0的概率;I为反向模型下的随机分布图像。
可以看出,H0随机模型确定了对齐点的数量分布k(r,z),其只取决于与I相关的水平线场的分布。因此,H0为图像梯度方向的噪声模型,而非图像的噪声模型。作为一种自动图像检测工具,需要设置比例因子、图像缩放比例、梯度阈值、容差值、图像面积、线段长短阈值等6个内部参数。
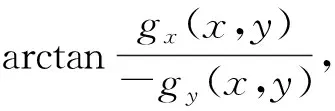
当梯度幅度较小时,处于较缓和过度区域的像素会由于其数值的量化性而导致计算时出现梯度误差,因此设置梯度阈值ρ对像素进行标记,当梯度小于阈值时像素不参与线性支撑区域和矩形的构建。
3.2 像控点线段检测
本算法与PPHT算法、Radon算法[12]识别效果的对比如图2所示。当蓝色交叉线位置与像控点 X型几何中点重合时,表示识别出像控点。对于不同深浅绿色及道路交替背景下的像控点,本算法与PPTH算法能较好地识别出像控点几何中心,而Radon算法则出现了定位错误,直接定位到了标志边角。对于道路砖石交叉直角背景下的像控点,PPTH算法将红色砖块与白色路牙交替处错误识别为像控点,Radon算法将砖石交叉处错误识别为像控点几何中心。

图2 3种算法识别效果的对比
像控点中心识别准确率的计算如式(7)所示:
(7)
式中:Pall表示像控点中心识别准确率;NT表示像控点中心识别正确的数量;Ng表示实际检测出的像控点数量。
定位中心精度的计算如式(8)所示:
(8)
式中:Pacc表示定位中心精度;n表示参与识别的像控点数量;p(xi,yi)为真实图像的像素坐标;p′(xi,yi)表示识别出的像素坐标。
无人机镜头曝光一次会同时收集到5张包含同一像控点影像的数据,将这5张像片归为一组,则其识别准确率的计算如式(9)所示:
(9)
式中:Pg表示识别准确率;NTG表示像控点中心识别出的组数总和;NGG表示实际检测出的组数总和。
由3种算法检测精度的对比(见表2)可知,本算法的检测精度高于PPHT算法和Radon算法,这是由于Radon算法主要借助于二值边缘提取像控点;PPTH算法对背景环境要求较高,当背景中出现颜色或者直线交叉线条干扰时,容易导致定位紊乱。
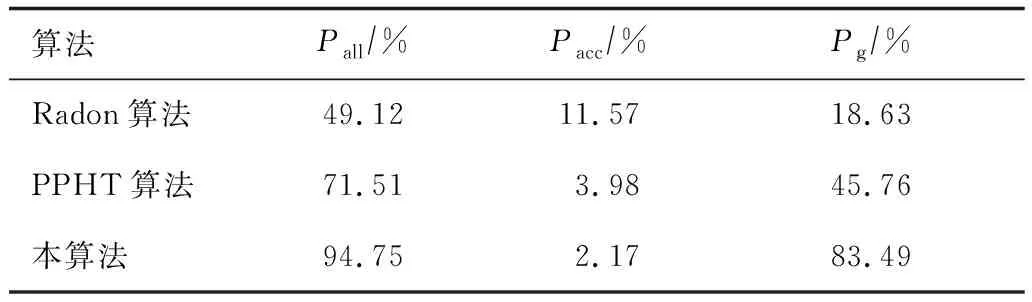
表2 3种算法检测精度的对比
4 结 语
根据像控点标志的颜色和角度等几何特征,提出了多算法联合识别像控点标志的方法。首先,利用改进的Retinex色彩增强算法对原始影像进行优化处理;然后,采用SSD增强算法对包含有像控点的影像数据进行训练识别;最后,利用LSD算法进行多阈值筛选,以实现像控点的识别与提取。本算法提高了内业像控点的识别精度,提升了作业速度,为倾斜摄影测量内业工作提供了技术参考。
