基于预训练模型和图卷积网络的中文短文本实体链接
2022-02-03郭世伟马玉鹏杨雅婷
郭世伟,马 博,马玉鹏,杨雅婷
(1. 中国科学院 新疆理化技术研究所, 新疆 乌鲁木齐 830011;2. 中国科学院大学, 北京 100049;3. 新疆理化技术研究所 新疆民族语音语言信息处理实验室, 新疆 乌鲁木齐 830011)
0 引言
将文本中出现的指称(mention)自动地链接到知识库(knowledge base,KB)中相应的实体(entity)上,该过程一般被称为实体链接(entity link)。实体链接是许多文本理解任务的关键技术之一,如自动化构建知识库(automatic KB construction)、问答系统(question-answering)、文本摘要(text summarization)以及关系抽取(relation extraction)。由于指称具有歧义性和语义等价性,导致实体链接过程存在诸多困难,仅通过规则设计很难达到预期目标。当前实体链接研究主要在两种文本上进行: 长文本和短文本。前者的语料多来自Wikipedia文章、领域专业文献、新闻等,后者则主要来源于微博、论坛等。由于短文本缺乏足够的主题信息,而长文本往往包含主题信息,因此短文本实体链接与长文本实体链接在方法上存在一定的差异性。本文主要关注于中文短文本实体链接。
实体链接面临主要的挑战是指称的歧义性,即指称和知识库中多个实体的链接概率不为零。如表1所示,知识库中的“吴京(演员)”和“吴京(教授)”为指称“吴京”的候选实体,根据短文本描述,“吴京(演员)”是最佳候选实体(真候选实体),“吴京(教授)”应该是被消歧的假候选实体。基于长文本的实体链接方法利用主题信息计算实体或指称间的共现概率,完成实体链接或提高链接的精度,如Cucerzan[1]等、Globerson[2]等和Heinzerling[3]等提出的方法。相对而言,如表1所示,短文本如微博,通常过于简短,缺乏实体共现信息和主题信息,如何充分利用短文本和实体间的语义相关性,成为短文本实体链接的关键。受益于BERT[4]、GPT[5]等语言预训练模型在诸多语言任务上的优异表现,本文使用预训练模型提取短文本和实体间的语义相关性特征。但BERT[4]在提取语义相关性特征时并不能显式地利用短文本和实体间的文本交互模式,如BERT[4]并不能显式地约束实体是对短文本中指称的附加描述或解释性说明。

表1 短文本中的指称与相关候选实体
为了添加交互模式信息,本文提出短文本交互图(Short Text Interaction Graph,STIG)的概念,STIG可以有效地描述短文本中的字词和实体描述中的字词之间的交互关系。通过在STIG上使用图卷积网络[6](Graph Convolutional Networks, GCN)机制为短文本-实体语义相关性特征添加字词上的交互信息。此外,我们发现对于STIG,若在GCN[6]处理后的各节点向量上作均值池化操作会使GCN[6]发生退化问题,为了有效提取STIG的特征并缓解GCN[6]的退化,本文提出了一个同时保留STIG中节点和边信息的方法。
在中文短文本实体链接数据集CCKS2020上的实验表明,本文方法较多个基线模型可以实现更高的链接精度,同时消融实验表明,所提出的双步训练策略可以有效地提高模型的性能。
1 相关工作
现有的实体链接方法大致分为两种类别。早期的工作聚焦于利用文本的局部信息启发式地设计一些特征实现实体消歧,进而达到实体链接的目的。如Zhang[7]等根据词法、实体类型等设计特征,结合二分类方法,利用SVM(Support Vector Machine,支持向量机)完成候选实体的排序。最近得益于深度学习的发展,基于深度神经网络的方法相继出现,Raiman[8]等提出实体类型坐标系的概念,每种实体类型被视为坐标系的一个轴,并使用神经网络拟合实体类型坐标系,根据局部文本在实体类型坐标系上的坐标实现候选实体的消歧及指称的链接。最近的工作多关注于利用文档主题和实体共现频率结合局部语义信息实现全局实体链接,Ganea和Hofmann[9]等通过预先训练实体嵌入,计算局部文本和实体嵌入的注意力系数,得到局部语义相关性信息,同时使用多层神经网络及LBP(loopy belief propagation)算法模拟CRF(conditional random fields)模型,据此计算出文档中候选实体的极大后验概率(Maximum A Posteriori,MAP),进而实现全局实体消歧。李明扬[10]等则在Ganea和Hofmann[9]等工作基础上结合高速网络、自注意力机制以及更新的知识库进一步提高链接的性能。
同时使用局部语义信息和实体共现频率能显著提升模型的性能,但对于短文本,由于缺乏主题信息以及文本中的实体较少,难以实现全局实体链接。周鹏程[11]等使用N-gram结合词性和多个指称-实体字典获得候选实体,通过多知识库(Wikipedia和Freebase)和实体类别计算实体序列的相关度,选择相关度最大的实体作为链接结果。Nie[12]等提出使用两个不同的网络分别计算短文本和实体在字词级和文本级的相关性,并使用TrueSkill[13]算法量化多个相关性特征的重要程度,进而提高短文本的链接性能。
最近随着BERT[4]、GPT[5]等语言预训练模型的发展,Logeswaran[14]等基于BERT模型将文本视为阅读文档,将候选实体作为答案选项,从而把实体链接问题等价为机器阅读理解,该方法具有较强的泛化能力,在零样本实体链接中有较高的精度。Chen[15]等通过BERT和指称所在上下文计算实体隐类型,并将隐类型加入实体链接模型,提高链接性能。
2 实体链接模型
本文提出的实体链接模型重点关注短文本和实体在文本上的交互信息以及短文本-实体相关性特征表示。整体网络架构如图1所示,主要由基于BERT 的相关性特征提取模块和定义在STIG上的图卷积模块构成。根据短文本中指称出现的位置构建STIG并使用邻接矩阵表示STIG边的信息,节点的信息由BERT模型计算获得。为了使BERT模型更好地学习到短文本-实体相关性特征,本文采用一个双步训练策略精调BERT模型,在第一步训练中STIG不参与训练,精调后的BERT称为先验知识模型(Prior-Bert),第二步训练使用Prior-Bert作为预训练模型的初始化参数,并且STIG以图卷积的方式参与训练,精调后的模型称为后验知识模型(Posterior-Bert)。同时本文使用一个线性变换将GCN后的STIG中的节点信息和边信息变换成一个稠密向量。

图1 模型整体架构
2.1 预训练语言模型BERT
BERT[4](Bidirectional Encoder Representations from Transformers)是一个多层Transformer[16]架构的堆叠,并利用自监督的学习方式在大语料上进行预训练。自监督学习主要通过两个自监督任务实现: 单词MASK和下邻句预测(Next Sentence Predict)。单词MASK机制学习单词或字在双向语境中的表示,具体地,BERT在训练过程中以一定的概率随机替换输入的单词或字符为特殊标记[MASK],预测[MASK]原本对应的单词或字;下邻句预测机制学习句子级的相关性,具体地,BERT在训练过程中,可以一次性输入两个句子,形成一个句子对,使用可学习的token类型嵌入对句子加以区分,并在两个句子间添加一个[SEP]特殊分割标记符分割句子,同时分别在输入的起始位置和结束位置添加特殊标记[CLS]和[SEP],[CLS]主要用来表示句子级的信息,表示输入的句子对是否具有连贯性。
2.2 先验知识模型
本文使用预训练语言模型BERT[4]计算短文本和实体之间的相关性,并获得相应的特征向量。首先将CCKS2020知识库中每个实体的三元组集合拼接形成一个字符串(简称实体描述文本),单个三元组元素拼接得到的字符串称为三元组文本。本文假设实体和实体描述文本在语义上是等价的,考虑到每个三元组文本的长度不一样,而BERT[4]最多只允许输入512个符号,因此对于过长的实体描述文本进行截断操作,即只保留其前512个字词,超出部分直接丢弃。由于截断操作会造成部分实体信息的丢失,所以本文假设每个三元组文本的长度与所包含的信息成正比,对每个三元组文本按照长度进行降序排序,降序排序可以尽可能地保证由于截断被丢弃的字词属于包含信息较少的三元组(三元组文本较短),保证截断后的实体描述文本包含尽可能多的信息。由于中文BERT[17]以单字符为最细粒度进行预训练,且中文分词存在歧义性,故本文提出的方法不对短文本以及实体描述文本进行分词预处理。本文定义指称在知识库中所对应的真实实体项为最佳候选实体(真候选实体)。
如图1中所示的输入,在第一步训练中,我们沿BERT[4]模型Next sentence 自监督任务的输入与输出,以短文本-实体描述文本句子对作为BERT[4]的输入,同时在句子对起始位置添加[CLS]特殊标记符,以[SEP]特殊标记符分割句子对,并在句子对的结束位置添加[SEP]特殊标记符,以BERT最后一层输出中的[CLS]标志位向量表示短文本和实体间的相关性特征。由于句子对输入实质上是对两个不同句子的拼接,为使BERT[4]模型区分输入句子对中不同的句子,按照BERT[4]的处理方式,需要为每一个输入符号添加一个Token类型信息,以指明每个字符所属句子。
在实体链接过程中即模型推理阶段,若依靠模型的二分类结果实现实体链接,其性能对候选实体集的大小较为敏感。例如,对于包含n个实体的候选集C={e1,e2,…,en},ei表示第i个候选实体,其正确链接的概率如式(1)所示。
(1)
其中,Acc表示二分类器的分类准确率。从式(1)可以看出,模型在单个样本上的正确链接概率与候选实体集的大小成反比,当n取比较大的值时,对正确链接概率R的影响较大。为了缓解候选实体集合大小对正确链接概率的影响,本文将实体链接问题归类为在候选实体集上建立相关性大小的概率分布问题,使用BERT拟合该分布,如图2所示。
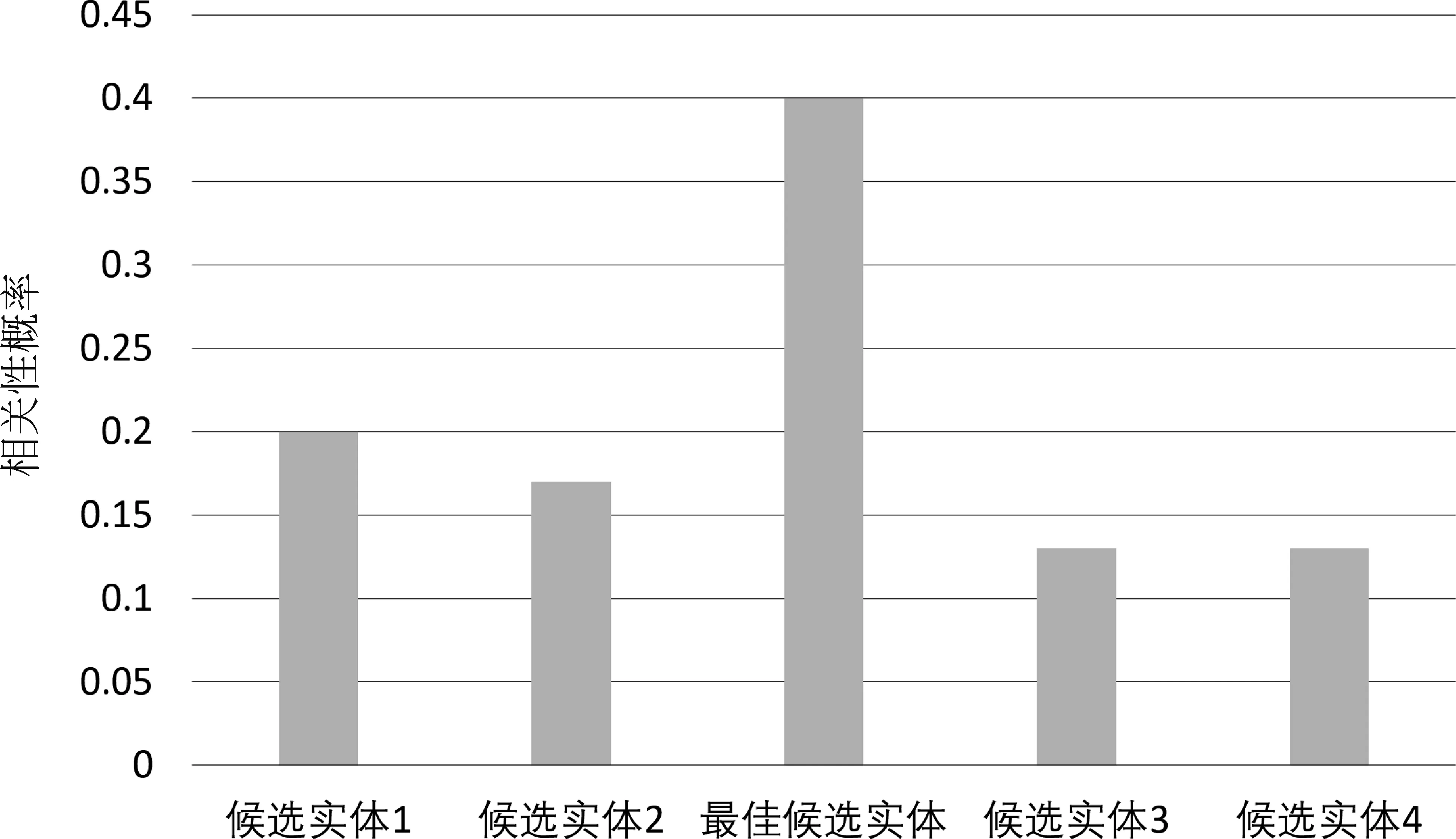
图2 在候选实体集上的概率分布
首先假定候选实体集合的大小为固定值n,若候选实体的个数大于n,则将其分为多个大小为n的候选实体集合,对于不足n个元素的候选实体集合,则通过采样候选实体的方式将其补充至n个元素。候选集合中包含n-1个假候选实体,以及1个真候选实体。概率分布的具体计算方法如式(2)所示。
(2)
其中,si∈Rm表示第i个候选实体描述文本与短文本的相关性特征,ti∈Rm表示可学习参数,m为向量的维度,d表示短文本。实体链接的目的在于使模型能够从候选实体集中识别出正确的实体,在本文的方法中等价描述为最佳候选实体(真候选实体)所对应的概率大于其他候选实体对应的概率,即:
p(s*|t,d)=max(p(si|t,d)),i=1,…,n
(3)
其中,s*表示最佳候选实体和短文本间的相关性特征。为了使模型拟合符合式(2)和式(3)的概率分布,本文使用以下目标函数作为训练时的损失函数。
object=-argmint(log (p(s*|t,d))
(4)
由于短文本和候选实体间的相关性特征仅由最后一层BERT输出的[CLS]标志位向量表示,并未利用句子对中其他词向量,本文认为该相关性特征只包含句子级的信息,即粗粒度相关性特征,这些特征会作为细粒度相关性特征的先验知识,故将第一步训练得到的模型称为先验知识模型(Prior-Bert)。
2.3 后验知识模型
尽管仅通过粗粒度相关性特征就可完成实体的消歧,但在某些特殊情形下粗粒度的信息并不能表达两个实体间的细微差异。例如,若两个实体只在个别名词上有差异,则需要依靠个别词汇区分两个实体。本节引入短文本交互图(STIG)的概念,并在STIG上使用GCN机制计算字词级别细粒度相关性特征。由于本节的模型使用Prior-Bert模型的参数进行初始化,故称为后验知识模型(Posterior-Bert)。
2.3.1 短文本交互图
短文本交互图(STIG)是一个无向图,其节点由短文本或实体描述中的字词构成,并由2.2小节中的Prior-Bert模型计算节点的表示向量,如图3所示。STIG描述了构成短文本、指称和实体间的字词在词序上的关系,STIG可视为由两个子图构成: 短文本子图(Short Text Sub-Graph,STSG)和实体描述子图(Entity Description Sub-Graph,EDSG)。对于STSG,其节点由短文本中的字词组成,边用于刻画两个字词在词序上的关系,若两个词在文本序列上是相邻的,则对应的STSG上的节点之间就有一条相连的边。EDSG中的节点由实体描述文本中的字词构成,与STSG类似,EDSG的边也刻画两个字词在词序上的关系,不同之处在于EDSG同时刻画短文本中的指称和实体间的关系,每一个指称中的字词和每一个实体描述中的字词之间均有一条边,显式地标出指称在短文本中的位置,以及指称中的字词和实体描述中的字词之间的关系,STIG由STSG和EDSG取并集而得。如图3所示,圆形节点表示短文本中的字词,方形节点表示指称中的字词,三角形节点表示实体描述文本中的字词。
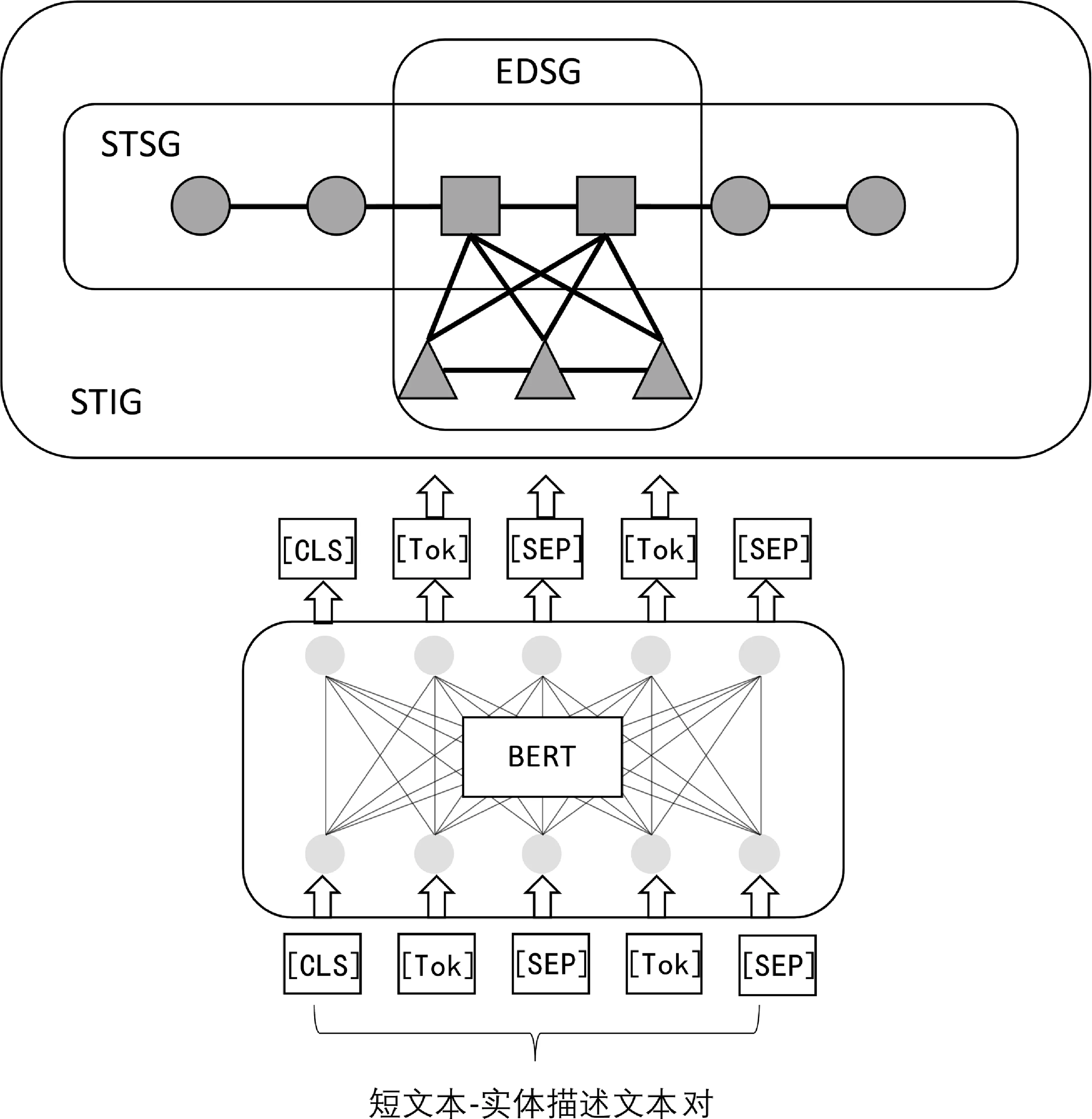
图3 短文本交互图的构造
假设短文本-实体描述文本句子对共有n个字词,{w1,w2,…,wj,…,wj+m,…,wn},定义STSG为Gst={Vst,Est},其中,Vst={w1,w2,…,wl}为STSG的节点集合,wi为短文本中的一个字词,Est={(1,2),(2,3),…,(l-1,l)}为STSG的边集合,同理可定义EDSG为Ged={Ved,Eed},其中,Ved={wl+1,wl+2,…,wn}为子图的节点集合,Eed={(l+1,l+2),(l+2,l+3),…,(n-1,n)}为子图的边集合,则STIG可定义为G=Gst∪Ged。本文使用邻接矩阵A表示STIG,矩阵每个元素的定义如式(5)~式(7)所示。
显然邻接矩阵仅描述了节点间边上的信息,节点本身的信息由Prior-Bert模型计算获得。
2.3.2 图卷积计算模块
STIG描述了短文本和实体间字词与字词的关系,为了在实体链接中能利用这些信息,本文在STIG上使用一层图卷积网络[6](GCN)计算细粒度相关性特征。图卷积网络是卷积神经网络[18]的变种,用于实现图上的卷积操作,由于图结构并非标准的欧氏空间,因此GCN[6]将图从空域转移到频域上,利用卷积定理把空域上的卷积操作等价转化为频域上的乘法。
考虑一层的GCN有如下的计算公式:
(8)

(9)
矩阵Θ相当于卷积核的参数,是一个可学习的参数,X∈RN×D表示STIG的输入节点矩阵,即Prior-Bert模型的输出,其中N表示节点个数,D表示节点的特征维数。经过一层GCN后短文本和实体之间根据STIG重新计算每个字词之间的相关性特征。特别的,由于短文本中的指称字词在STIG中有更多的边与实体相连,因此指称节点的特征包含了更多的相关性信息,这正是实体链接所需要的。
在获得卷积后的节点特征向量后,将特征向量按行堆叠为一个矩阵H∈RN×S。为了计算损失,需要将矩阵H变换成一个向量。一个比较直观的方法是平均矩阵的每一行,即执行一个大小为N的均值池化操作,将池化得到的向量作为最终表示向量。然而均值池化操作会使图卷积退化,我们不妨假设:
(10)
(11)
对于STIG的L矩阵,可以写成分块矩阵的形式:
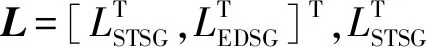
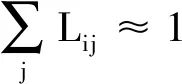
(14)
由式(14)发现,若对GCN后的特征向量执行均值池化操作,会使图卷积退化(L矩阵蕴含的邻接信息被丢弃)。为了缓解该问题,本文使用两个简单的线性变换将节点特征H和L映射到两个向量中。
h,l=Hb,Lz
(15)
其中,b,z为可学习的参数。最终的相关性特征由[CLS]的标志位向量、h向量和l向量拼接获得。
与2.2节的Prior-Bert模型相对,后验知识模型(Posterior-Bert)学习细粒度相关性特征。Posterior-Bert同样将实体链接问题视为在候选实体集上建立相关性大小的概率分布问题,使用式(4)作为训练时的目标函数。
3 实验设置与结果分析
本节使用中文短文本实体链接数据集CCKS2020[19]验证所提方法的有效性,与多个基线模型的对照均表明所提方法在该数据集上有更好的性能,并对实验结果进行了分析。
3.1 实验数据集
本文使用CCKS2020中文短文本实体链接数据作为实验数据,由于该数据集的测试数据集并未公开,我们使用验证集CCKS2020-dev作为测试数据集,并将训练数据集CCKS2020-train划分成训练集和验证集,具体划分方法为随机采样相应数量的样本,分别作为训练数据和验证数据。表2列举了实验所用相应数据样本的具体数量。

表2 数据集样本数量统计
CCKS2020数据集包含两种不同类型的数据,一种是指称在知识库中有对应的实体,记为KBID,另一种是指称在知识库中没有对应的实体,记为NIL,两种数据的样本数量如表3所示。
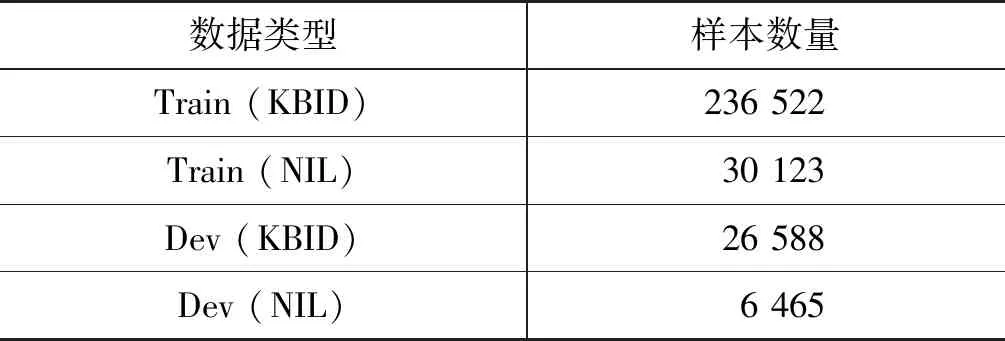
表3 数据类型及数量
该数据集的知识库中每个实体均有一个别名表,用于保存实体的一些常见别名。我们统计了别名表对训练集和测试集中指称的覆盖率,覆盖率指文本中指称的字符和别名表中的别名字符可以精确地匹配。如表4所示,表项“覆盖率(KBID)”表示只统计在知识库中有对应实体的指称,由于别名表对指称的覆盖率相当高,因此实验直接使用别名表构造的字典生成候选实体。

表4 别名表对指称的覆盖率
由于候选实体的个数对实体链接的性能有一定的影响,本文也统计了在测试集上短文本中不同指称根据别名表所生成的候选实体个数,表5给出了相应的统计结果。
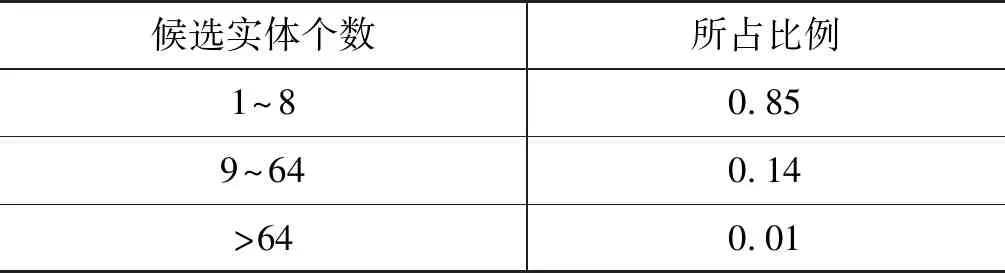
表5 测试集中候选实体数目统计结果
3.2 实验设置
本文中的实验使用Pytorch 1.2.0框架,并使用一块NVIDIA Tesla K80 GPU进行加速计算。首先按照2.2节中的方法对候选实体三元组进行拼接,得到一个实体描述文本,然后将包含指称的短文本和实体描述文本以[SEP]特殊标记为分隔符拼接成一个句子对,在首尾分别添加[CLS]和[SEP]特殊标记符,并对大于512个字符的文本对进行截断。表6采样了几条最终输入到模型的样本。
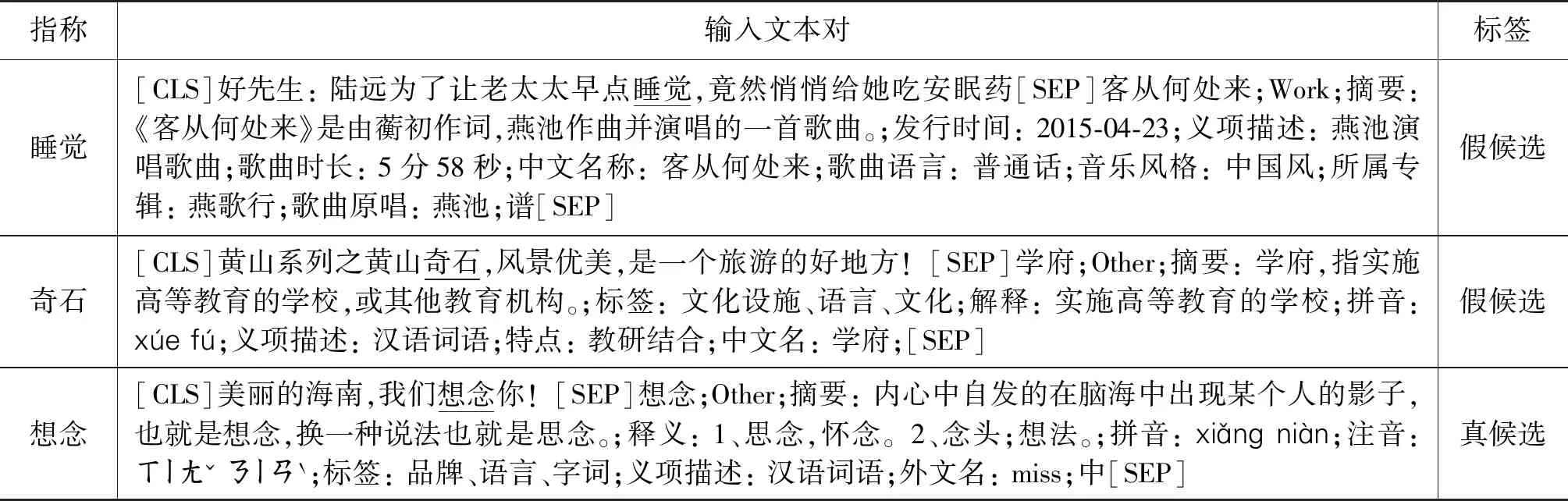
表6 输入样例
本文采用两组不同的实验配置验证所提方法的有效性。实验配置一使用一个三层的BERT[4],该实验配置采用2.2节中提出的建立候选实体概率分布的方法进行训练。建立候选实体的概率分布,需要一个完备的候选实体集。由于数据样本中包含NIL指称,为了构建出完备的候选实体集,实验配置一为每一个指称的候选实体集添加一个NIL候选实体,以保证每个候选实体集中都有一个正确的候选实体。NIL候选实体描述文本在实验中被设置为: “所有的候选实体均是假的,该说明用于收集阈值信息。”
实验配置二使用一个标准的12层BERT[4],为了加速模型的训练,本文使用二分类的方法近似估计候选实体的概率分布,具体的方法如下:
(1) 从训练数据集中按1∶1的比例采样负样本,即将一个指称的真实的候选实体作为正样本,随机地从候选实体集中采样一个假候选实体作为负样本。
(2) 使用二分类交叉熵损失作为目标函数训练Prior-Bert和Posterior-Bert。
(3) 在推理阶段,使用训练后的Posterior-Bert计算候选实体集中所有候选实体为正样本的概率,取概率最大的候选实体,若该候选实体的概率大于预设的阈值,则判定为最佳候选实体;反之,对应的最佳候选实体为NIL。
实验配置一的具体参数: 候选实体集的大小取16,若候选实体的数目超过16则将其划分成多个候选实体集合,每个候选实体集合大小为16,大小不足16的候选实体集合则通过负采样的方法将其补充至16,并确保每个候选实体集均含有NIL候选实体。优化方法使用AdamW[20],一个Adam[21]优化算法的变种,Bert层的学习率lr设置为1e-5,GCN层的学习率lr设置为1e-3,batch大小设置为64,并且使用线性学习率衰减策略,其预热步设置为4 000,dropout设置为0.1。
实验配置二的具体参数: batch大小设置为32,采用AdamW[20]作为优化算法,Bert层的学习率lr设置为1e-5,GCN层的学习率lr设置为1e-4,预设阈值为0.35,预热步设置为4 000,dropout设置为0.1。
实验以Xue[22]等提出的方法、Bi-LSTM、Yin[23]等提出的方法、二分类BERT[4](Bin-Bert)及GCN[6]作为基线模型,同时我们也对照基于对抗学习Fast Gradient Method(FGM)[24]的方法。对于Xue[22]所提出的方法,由于数据是短文本,我们只能对照其局部模型并移除其他辅助特征。同样地,移除Yin[23]所提方法中用到的先验特征,因为这些特征在短文本中很难被计算。GCN[6]基线模型则在STIG上以随机初始化的词嵌入向量作为节点特征做图卷积操作,Bi-LSTM基线模型由两个双向的LSTM构成,其中一个计算短文本特征,另一个计算实体描述文本特征,并使用余弦相似度衡量两个特征的相关性。
3.3 实验结果与分析
实验配置一中的实验均使用准确率P作为实验的评价指标。
表7给出了本文所提方法与其他基线方法的实验结果,表7中的实验均采用实验配置一。由于训练数据集中KBID类型的样本数量要远远大于NIL的数量,因此我们分开报告两种类型数据的准确率。从实验结果看,本文所提方法较基线模型有更好的准确率,由于GCN在NIL类型的数据上准确率过低,不具有一般的参考价值,因此表中并未报告其具体结果。Yin[23]和Bin-Bert[4]的方法都是基于二分类BERT的实体链接方法,如2.2节所述,二分类方法对候选实体集的大小较为敏感,进而影响到准确率。
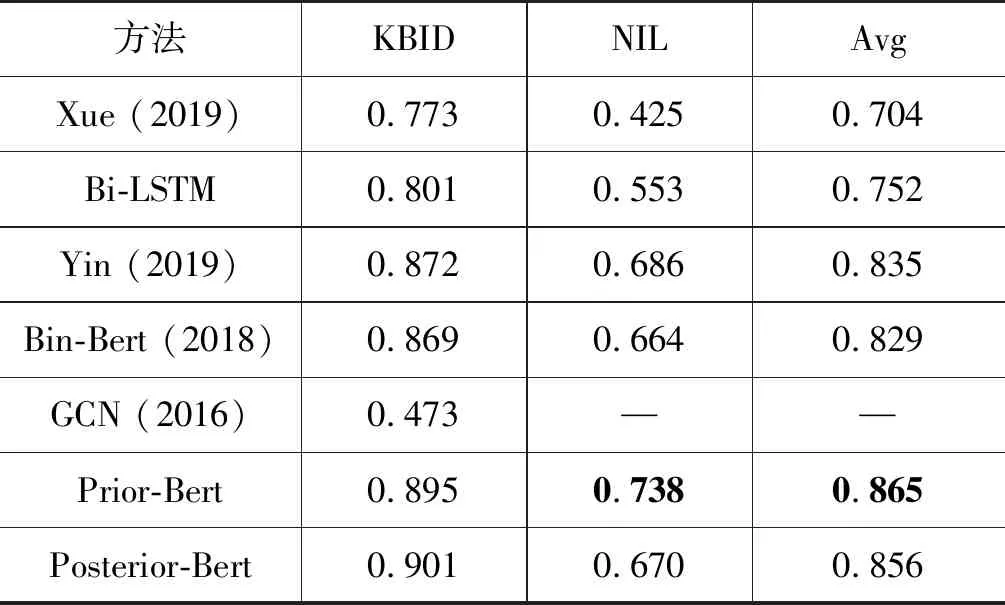
表7 实验结果

图4 链接错误样本中的候选实体数目分布情况
图4给出了基于二分类的方法(Bin-Bert)和基于概率分布的方法(Posterior-Bert)在错误链接样本中不同候选实体数目所占比例。
相对地,候选实体集合的大小对本文提出的方法影响较小,因此有更高的准确率。同时发现,尽管Posterior-Bert在KBID类型的数据上具有较好的性能,但在NIL类型的数据上表现却不如Prior-Bert,我们推测其原因可能在于引入的NIL候选实体由于不是从真正的数据集中采样而得的实体,而Posterior-Bert更注重字词上的细粒度相关信息,对于构成NIL实体描述文本的字词,与短文本中的字词并无词上的相关信息,因此模型不能较好地识别出短文本中NIL类型的指称。
相反,对于Prior-Bert,只需要将短文本-NIL候选实体的相关性概率值设为一个大于假候选实体概率而小于真候选实体概率的值即可。换句话说,NIL候选实体的作用是使模型学习到一个区分真候选实体和假候选实体的阈值。
为了验证Posterior-Bert是否真的可以利用Prior-Bert的参数作为先验知识,我们绘制了}Posterior-Bert和Prior-Bert在KBID数据上的准确率随训练步的变化曲线,如图5所示。可以看出,Posterior-Bert的准确率曲线基本在Prior-Bert之上,特别在训练的前期尤为明显,这说明Posterior-Bert确实利用到了Prior-Bert的参数作为先验知识。同时,本文也训练一个Bert+GCN模型,对照在没有先验知识的情形下,引入定义STIG上的GCN是否可以提升模型的准确率,表8给出了对照结果,并在图5中给出了Bert+GCN模型的准确率随训练步的变化曲线。由表8和图5知,在没有先验知识的情况下,Bert+GCN并未达到Posterior-Bert的性能,验证了先验知识有助于模型学习细粒度相关性特征。

图5 KBID数据上准确率随训练步数的变化曲线

表8 Bert-GCN与Prior-Bert的对照结果
在2.3.2节中,我们发现若对GCN后的特征向量执行均值池化操作会发生退化现象,表9的实验结果验证了退化问题,其中,Mean-Poling表示均值池化GCN的特征,Linear-Mean表示均值池化线性映射后的特征,不做图卷积运算。表9的结果表明,在STIG上使用均值池化处理的GCN特征,可以近似为直接平均线性映射后的特征。
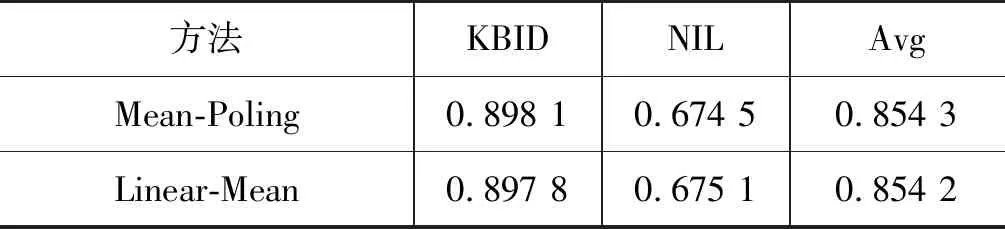
表9 GCN与线性映射在均值池化上的等价性验证结果
为了验证GCN层数对Posterior-Bert模型精度的影响,本文在实验配置一下验证了GCN层数对模型精度的影响,图6绘制了在KBID数据上精度随GCN层数增加的变化曲线。从图6可以看出,GCN层数的加深,会导致精度略微下降,我们推测原因在于过深的GCN会导致字词特征被过度平滑,导致模型不能捕获字词级的相关性特征,使模型退化成Prior-Bert。
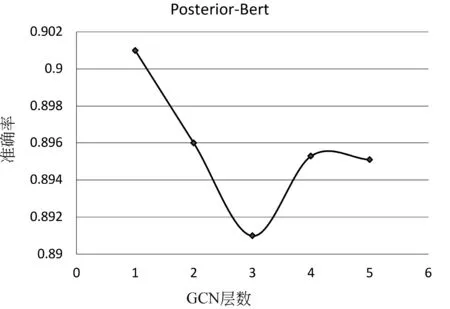
图6 精度随GCN层数增加的变化曲线
同时,本文使用实验配置二对照了基于对抗学习FGM[24]的方法,使用F1值作为评价指标。表10给出了实验结果,除了Posterior-Bert外,表中其余结果均来自于吕[27]等,表10中Bert-base-adv、Bert-wwm-ext-adv、UER-base-adv均是添加对抗学习的方法。其中,参数layers表示BERT[4]的层数,参数lr表示学习率。从表8的实验结果发现,本文提出的Posterior-Bert模型比一些添加对抗学习的模型取得了较好的性能。

表10 与对抗学习方法的对比实验
4 总结
本文提出了一个拟合候选实体集上相关性概率分布的实体链接方法,同时提出短文本交互图(STIG)的概念。采用一个双步的训练策略,在第一步训练中模型学习先验的粗粒度相关性信息(Prior-Bert),在第二步训练中模型使用Prior-Bert的参数作为先验知识,结合在STIG上的GCN学习后验的细粒度相关性信息(Posterior-Bert)。同时提出使用线性变换计算STIG中节点和边的特征,以缓解均值池化造成的GCN退化问题。
未来考虑对多个不同的预训练模型实施模型融合,同时使用更适合动态图的图神经网络去学习相关性信息的表示,寻找更好地融合先验知识模型和后验知识模型的方法也是未来工作方向。
