面向特定领域中文阅读理解数据集研究
2022-02-03孙越凡林鸿飞
孙越凡,杨 亮,林 原,许 侃,林鸿飞
(大连理工大学 信息检索研究室,辽宁 大连 116000)
0 引言
近年来,机器阅读理解成为自然语言理解研究的主流任务之一,它需要模型具有理解文本及回答问题的能力。机器阅读理解的任务主要分为多项选择、完形填空以及自由问答三种形式,其中自由问答的题型需要模型拥有更高的回答问题的能力,这一方向也成为近年来该领域的主要研究方向。与其他类型的问答任务相比,机器阅读理解只提供与问题相关的一段文档,因此可供利用的上下文信息较少,需要模型对文档具有更加深入的理解。与此同时,机器阅读理解源数据多来源于现实世界,问题也是现实世界中互联网用户会提出的问题,具有较高的实际应用价值。在近几年的发展过程中,机器阅读理解已经成为许多自然语言理解任务的组成部分,比如信息检索、关系抽取等。
语料库的发展是机器阅读理解取得巨大进展的主要原因之一。在过去的几十年中,有许多优秀的机器阅读理解数据集涌现出来,Hermann等人在2015年提出了一个完形填空式的英语机器阅读理解数据集——CNN&Daily Mail[1],Lai等人在2016年和2017年发布了RACE[2]数据集,2016年和2018年斯坦福大学发布SQuAD[3]数据集及其2.0[4]版本。在中文领域,百度2018年推出DuReader[5]数据集,同年科大讯飞发布评测数据集CMRC[6],2020年搜狗发布ReCO[7]数据集,这些优秀的数据集为机器阅读理解领域的发展做出了重要的贡献,一些优秀的深度学习模型如BERT[8]在某些数据集上的表现甚至超越人类。
然而,尽管这些数据集规模较大且应用广泛,但本文发现目前的机器阅读理解数据集仍存在缺少对特定领域的关注以及输入文本过长两个问题:
(1) 现有的数据集源数据大多基于维基百科、百度百科等搜索引擎,这些数据在确保数据内容足够广泛的同时却不能兼顾另一个方面,即面向特定领域。每一个领域都有自己的特点,倘若没有对特定领域赋予足够多关注,在现实场景下,可能不会有很好的效果。
(2) 目前的数据集通常基于一篇文档或者文档中的某段,然而现实世界中很多的数据是短文本的形式,比如手机应用程序中的商品评论。面向短文本的数据集,是目前所欠缺的。
基于上述的两点考量,本文提出了Res数据集,Res数据集聚焦于餐饮行业,使用大众点评应用程序中用户对餐饮行业店铺的评论作为初始数据来源,考虑到餐饮行业所具有的特殊性,标注者筛选有效评论,然后针对评论内容以及餐饮行业的特有问题提出问题并给出答案,例如对价格、味道、服务、环境等方面进行提问(问题类型分析见第3节)。
Res_v1版本如表1所示,可以看到,与SQuAD数据集(见表2)相比,Res数据集的问题更聚焦于餐饮领域,提出的多为价格、味道、服务、环境等消费者对该领域最为关心的问题。Res_v2版本如表3所示。

表1 Res_v1数据集示例

表2 SQuAD 1.0数据集示例

表3 Res_v2数据集示例
据我们所知,Res数据是第一个面向特定领域的短文本中文阅读理解的数据集,Res-v1版本中问题的答案皆可在context即用户评论中找到。考虑到现实情景中并不是所有问题都能在原文中找到答案,本文在Res-v1版本的基础上,补充了不能在context中直接找到答案的问题,构成Res-v2版本的数据集,在Res-v2版本的数据集中增加标签is_impossible,若其值为false,说明问题的答案可以在context中找到,answer字段的内容即为该问题的答案;若is_impossible的值为true,说明该问题的答案在原文中无法找到,text字段是context中与真实答案十分相近的文本片段,本文以此进行模型的训练。在测试集上如果对某个问题答案的预测概率低于阈值(本文设置为0.5),本文即认为该问题没有答案,预测答案为空。
本文在Res上应用了BiDAF、QANet、Bert三个模型,其中Res_v1最高的正确率为73.78%,Res_v2最高的正确率为66.93%,人类的正确率分别为91.03%和86.72%,这表明现有的模型在Res数据集上表现一般,该数据集为机器阅读理解领域提供了一个良好的测试平台。
1 相关工作
自机器阅读理解领域诞生以来,涌现出许多优秀的数据集,如表4所示,本文根据答案的类型将该领域划分为三个子任务,分别是多项选择、完型填空以及自由问答。多项选择任务通常是在给出的三或四个选项中选择出正确的一项,完形填空任务与中高考完形填空题型的做法基本一致,需要预测出被删除的一些词语或短语;自由问答任务则是根据原文及问题给出答案。

表4 机器阅读理解领域的中文数据集
斯坦福大学的SQuAD数据集及其2.0版本是最具代表性的数据集之一,获得广大科研学者的认可并被广泛使用,其评测成绩榜单也是该领域最具权威性的榜单之一。CMRC评测数据集发布于2018年第二届“讯飞杯”中文机器阅读理解评测,格式与SQuAD数据集相同,促进了中文阅读理解领域的发展。DuReader数据集根据答案类型将问题分为实体、描述和是非。对于实体类问题,其答案一般是单一确定的回答,比如“iPhone是哪天发布?”;对于描述类问题,其答案一般较长,是多个句子的总结;典型的how/why类型的问题,比如“消防车为什么是红的?”;对于是非类问题,其答案往往较简单,是或者否,比如“39.5度算高烧吗?”。同时,无论将问题分类以上哪种类型,都可以进一步细分为是事实类还是观点类。该数据集在中文应用中具有开创性意义。
相比于以上的中文数据集,Res是一个面向特定领域的短文本数据集。该数据集的源数据都来自于消费者对餐饮行业的评论,问题由标注者提出,主要包含消费者比较关心的共性问题和某家门店的个性问题,共性问题比如价格、口味、环境、服务等,个性问题主要针对不同的门店类型提出,例如对连锁店与其他门店相对比的问题,酒店的座位、空间等问题。
除此之外,Res的另一个显著特点是它的数据源多为短文本。我们知道,相比于长文本,短文本所包含的信息更少,需要模型对语义和代词的理解更为深刻,具有较高的难度。
2 Res数据集构建
Res数据集的数据收集过程主要包括从大众点评App中爬取用户对店铺的评论,接着由机器以环境、口味、价格、服务等餐饮行业常见的五十个关键词对评论类型进行筛选,将不包含这些词汇的评论去除,以200个词为限定条件对评论长度进行筛选,舍弃评论长度大于200个词的长文本评论。
之后由标注人员针对筛选之后的每条评论提出6~7个问题,三个不同的标注人员分别对每个问题给出自己的答案,最后由校验人员进行汇总和检验操作,将三个标注人员给出相同答案的问题和评论作为Res数据的一条数据。数据的收集过程如图1所示。
2.1 数据源选取
饮食作为我们生活中必不可少的一个方面,对于这方面的研究会具有很高的应用价值,同时,对于一部分用户来说,选餐厅前往往会习惯性地在一些手机应用程序中查看关于这家店的评论,大众点评、美团等应用程序已经走进了用户的生活,本文拥有足够真实可靠的源数据。除此之外,充分的数据也为本文提供了足够多的备选数据,有利于本文提高数据集的质量。鉴于以上这两个原因,本文选择大众点评中用户对餐饮行业店铺的评论作为源数据,同时也保留了店铺名称、店铺在环境、服务、口味方面的得分(最高为5分)等数据项。
2.2 评论筛选
考虑到Res是一个面向餐饮行业的短文本阅读理解数据集,本文对初始数据的筛选主要面向两个方面: 评论类型筛选和评论长度筛选。在类型筛选过程中,本文主要保留关于餐饮行业的评论,例如餐馆、酒楼、快餐店、咖啡厅、甜品店等,舍弃源数据中包含的对非餐饮行业的评论,例如游戏厅、电影院等。在长度筛选过程中,本文将保留评论在200个字以内的数据,超过200个字的数据将被舍弃。筛选过后的数据作为输入进行下一个阶段的处理。
2.3 问题提出
得到经过两次筛选的评论之后,接下来标注者对每条评论提出6~7个问题。在提出问题之前,首先对标注人员进行培训,标注者将被分配一份阅读材料,该材料来源于各大购物平台,包括但不限于餐饮、食品、服装等行业的评论数据和用户提出的问题,以培养标注者对用户所关注问题的认识。问题的类型主要包括共性问题和个性问题两种,其中共性问题包括我们关心的价格、口味、服务等,个性问题由店铺的类型决定,例如对于连锁店,会提出和其他门店相比较的问题。这些问题的具体数目和比例将在第3节具体说明。
2.4 答案选取
考虑到标注人员的主观因素对数据集质量的影响,本文回答问题的过程由三个标注人员完成,对于Res_v1数据集中的每一个问题,每个标注人员给出该问题的答案和该答案在原文中的位置。对于Res_v2数据集,由于部分问题无法在原文中找到答案,标注人员需要将is_impossible标记为true,然后给出与真实答案相关的内容以及其在原文中的位置,对于在原文中可以找到答案的问题,标注方式与Res_v1相同。最后,本文得到三份不同标注人员给出的答案文档,将其输入下一阶段。为了避免标注人员对数据集质量的影响,本文从三份不同的答案文档中选出答案相同的问题,三位标注人员给出一致的答案,意味着对于该问题的解答基于客观事实,这样的问答对是本文所需要的,将其加入输出文档中,输出文档即为本文最终数据集。
3 数据分析
本文首先对Res数据集的大小进行分析,训练集和测试集的问答对数量如表5所示,Res_v1数据集大小为808个问答对,Res_v2数据集大小为1 008个问答对。本文采用交叉验证法对数据集进行划分,首先将数据集随机分为互斥的10个子集,接着将10个子集随机分为9个一组,剩下一个为另一组,有10种分法,然后将每一种分组结果中的9个子集的组当作训练集,另外一个当作测试集。数据集经过四位标注人员两个月的标注,具有较高的质量,可以促进面向特定领域短文本机器阅读理解领域的发展。

表5 Res数据集大小
本文对数据集中问题的类型及数据进行分析,Res_v1的数据集中不同类型问题的数目如表6所示,训练集不同类型问题的比例如图2所示,本文首先将所有的问题划分为共性问题和个性问题,共性问题包括对价格、味道、服务、环境四方面的提问,例如: “你觉得这家店价格如何?”“你觉得这道菜味道怎么样?”这种提问形式是消费者在餐饮方面普遍比较关注的问题,共性问题约占总问题数目的52%。个性问题针对不同门店的类型进行提问,例如: “这家星巴克相比国贸的那家怎么样?”,“这家酒楼适合商务宴请吗”这些问题,消费者对酒楼、快餐店、咖啡厅、甜品店有着不同的关注重点,本文将这些问题归为个性问题。

表6 Res_v1数据集中不同类型问题的数目

图2 Res_v1训练集中不同类型问题的比例
在Res_v2数据集中,不同类型问题的数目如表7所示,测试集中不同类型问题的比例如图3所示。在Res_v1数据集的基础上,本文增加了答案无法在原文中找到的问题,本文称其为无法回答的问题,这类问题的比例为20%。v2版本数据集需要模型对原文和问题的理解更加深刻,并判断哪些问题可以回答、哪些问题没有答案,因此Res_v2相比Res_v1具有更高的难度,结合实验结果,Res_v2版本上模型的表现比Res_v1版本上模型的准确率低6%左右,也验证了本文的假设。

表7 Res_v2数据集中不同类型问题的数目

图3 Res_v2测试集中不同类型问题比例
为了衡量该数据的难度,本文选取RI-index(简写为RI)衡量指标[7],RI指标计算如式(1)所示。
(1)
Smodel,Srandom,Shuman分别代表最佳模型得分、系统随机得分和人类得分、在自由问答领域,系统随机回答的正确率近似于0,Res_v1的最佳模型得分为73.78%(具体实验将在第4节描述),Res_v2的最佳模型得分为66.93%,两个版本数据集的RI-index难度指数如图4所示。
可以看到,一些模型在很多数据集上取得了较好的成绩,有一些甚至超过人类水平,然而对Res数据集来说,模型表现仍有上升空间。一方面,这反映了Res是一项相对困难的任务,目前的模型表现不佳。另一方面,大多数Res问题需要深层次的推理技能,因此需要在MRC模型中引入新的机制来实现更高层次的推理,如逻辑推理等,以充分理解原文语义,获得效果上的提升。

图4 数据集难度评价
4 实验
4.1 模型选择
本文选取机器阅读理解领域三个典型的模型作为本文的验证实验,来评估Res数据集的性能:
BiDAF(Minjoon Seo,et al.,2017)[14]: 第一个在MRC上取得显著成绩的深度学习模型,建立在LSTM的基础上,通过引入双向注意力来实现问题与答案的交互。
QANet(Wei Yu,et al.,2018)[15]: 将卷积和自注意力作为编码器的构成模块,分别对问题和语境进行编码,通过标准注意力来学习语境和问题之间的交互。同时QANet也是Bert诞生之前在SQuAD 2.0数据集上表现最好的单模型,具有代表性意义。
Bert(Jacob Devlin et al.,2019)[8]: Bert的发布对于包括机器阅读理解在内的很多研究领域具有划时代的意义,在NLP领域的11个方向大幅刷新了精度。同样,在Res数据集上,Bert相比其他模型的准确率最高,实验结果如表8所示。

表8 不同模型在Res数据集和其他数据集上的结果
4.2 阈值选取
需要特别指出的是,由于Res_v2数据集中存在没有正确答案的问题,观测原文中是否包含答案这两种问题的不同(图5、图6),本文分别在测试集中的预测答案中随机选取五个答案及他们的预测可能性,以这五个答案为横坐标,这五个答案的可能性为纵坐标作图。可以看到,在原文中包含答案的预测结果的图中,每个预测结果的可能性相对较高,基本都在0.8以上,而在原文中不包含答案的预测结果的图中,即对没有答案的问题的预测,每个预测结果的可能性较低,基本都在0.3以下。所以在原文中没有答案的问题,若某个问题的候选答案的可能性小于0.5,本文将答案置为空值,否则将大于0.5的最高预测可能性所对应的预测回答作为答案。

图5 原文中包含问题答案的预测结果

图6 原文中不包含问题答案的预测结果
4.3 案例分析
本文以Bert_base模型为例,将Res_v2数据集按照不同问题类型以及不同答案类型分类,分别对其实验结果进行分析。按不同问题类型分类如图7所示,可以看到,消费者对餐饮行业普遍关心的共性问题,例如价格、味道、服务、环境等,实验结果的正确率较高,可以达到80%左右,其中关于服务的问题正确率最高,达到87.50%。对于不同店铺用户所提出的个性问题,正确率为67.71%,相比于共性问题此类问题的正确率有待进一步提高。
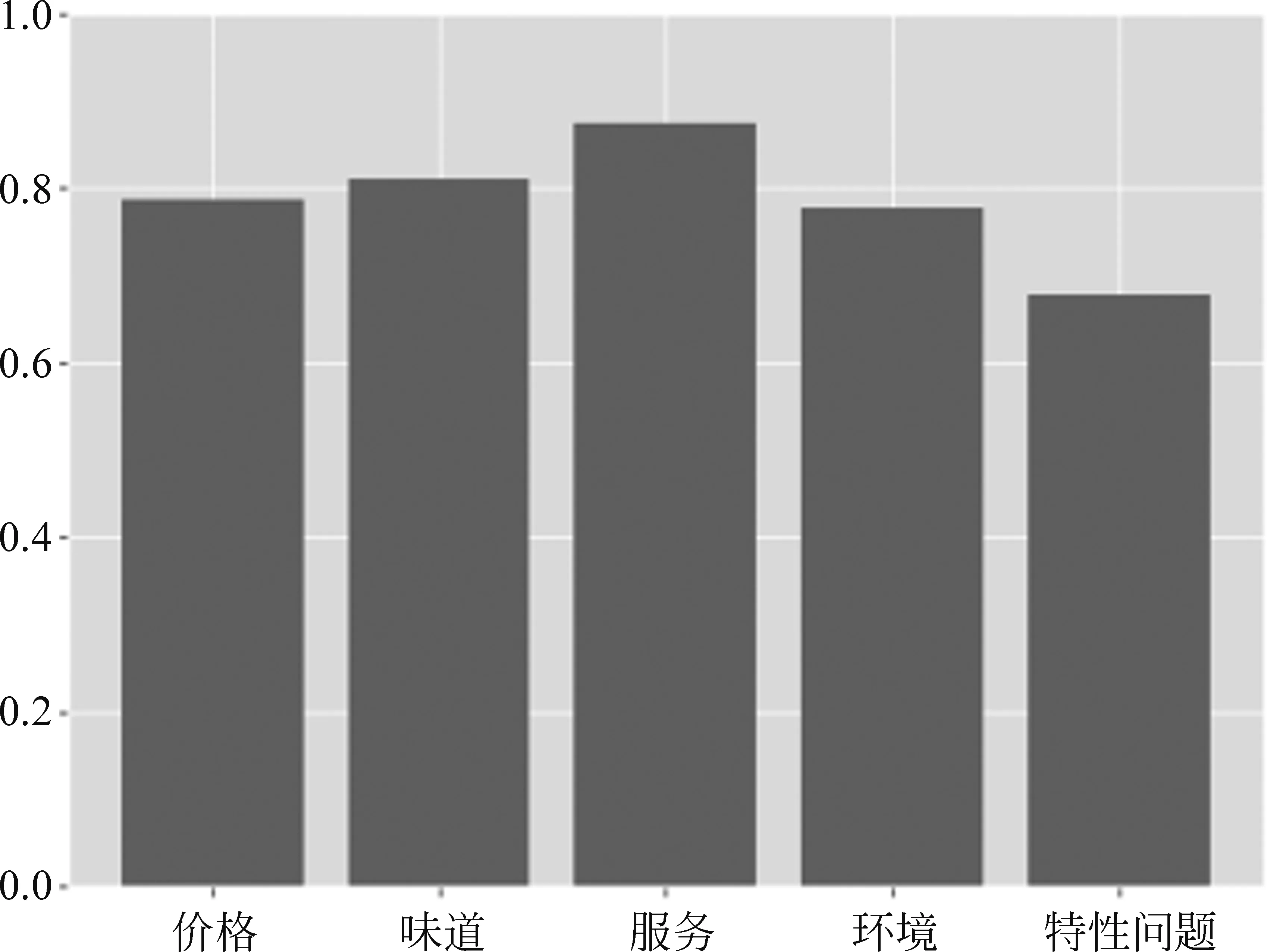
图7 Res_v2数据集中不同问题类型的正确率
按不同答案类型分类如图8所示,本文将其分为三类。可以看到,词匹配类型问题的准确率可以达到85%以上,而数字计算问题和无法回答的问题准确率只有不足40%。
这对本文数据集的设计开发工作具有启示作用,即适当提高数据集中数字计算问题和无法回答的问题在数据集中所占的比例,以提高数据集的难度,从而进一步验证模型性能。
对比实验选用的三种模型可以看到,相比于BiDAF和QANet模型,Bert模型具有更好的性能,本文认为这主要是由于以下两方面的原因: 第一,Bert模型具有更好的模型结构,深层双向的encoding以及其内部独特的注意力模式,可以使模型更好地学习文本的上下文表示,更充分地理解语义。第二,谷歌研究院在发布Bert模型的同时还发布了经过大量语料预训练之后的模型参数,这些语料多来自维基百科,本文认为大量的预训练语料以及其两个预训练任务(next sentence prediction和mask prediction)可以很好地调整模型参数,使其初步拥有对语义的感知,这对本文在下游任务上训练Res数据集具有好处。
综上所述,本文认为Bert模型在机器阅读理解领域具有显著的优势。同样地,在Res数据集上的表现也优于其他模型。独特的内部结构和经过大量语料预训练之后的模型参数对解决机器阅读理解任务很有帮助,这也为我们今后的工作指明了方向,在优化设计数据集的同时,对Bert模型进行进一步的改进以提高实验结果。
5 结论
本文提出了一个面向餐饮领域的中文短文本阅读理解数据集Res,本文采用严格的数据收集处理过程,以保证数据集的质量。同时以原文中是否含有问题答案为区别提出了Res-v1、Res-v2两个版本。数据显示,Res数据集同时考虑到餐饮行业的共性问题和个性问题,共性问题包括我们关心的价格、口味、服务、环境等,个性问题由店铺的类型决定,例如对于连锁店会提出与其他门店相比较的问题。
本文在Res数据集上进行了一系列实验,结果表明,Bert表现最好,但与人类仍有差距,这表明Res数据集具有一定的难度,是中文机器阅读理解领域的一个很好的测试平台,同时也为我们之后的工作指明了方向,在进一步扩展Res数据集规模的同时,对Bert模型进行改进以使其更好地理解语义并做出回答。我们将做出更多的努力,促进机器阅读理解领域的发展。
