HRTNSC: 基于混合表示的藏文新闻主客观句子分类模型
2022-02-03孔春伟吕学强
孔春伟,吕学强,张 乐
(1. 青海师范大学 计算机学院,青海 西宁 810008;2. 北京信息科技大学 网络文化与数字传播北京市重点实验室,北京 100101)
0 引言
主客观文本分类,是分析文本表达的观点、产品、服务、事件、主题及其属性主客观性的研究领域,一般通过理解文本内容判断其主客观性,文本分析技术是主要的研究方法。主客观文本分类本质上是基于语义的分类任务,目的在于将文本划分为表达对人物、产品、事件的想法、看法的主观文本,以及基于事实描述服务、事件、对象的客观文本[1]。主客观文本分类是文本情感分析的上游任务,通过挖掘文本的主客观信息,可以提高文本情感分析的针对性。但是随着文本规模的急剧膨胀,仅靠人工已经难以完成主客观文本分类工作。因此,使用计算机进行高效、准确的主客观文本分类具有重要的价值。
进入大数据时代,藏文官方新闻也爆炸式、多样式增长,信息过载现象严重,快速从繁杂的藏文官方新闻中获得所需信息成为了一种重要需求[2]。藏文官方新闻数据中蕴含大量体现国家意志的领导人讲话、事件评论、纪念贺词等评论信息,主动挖掘评论信息的主观倾向,是落实国家意志、践行为民服务理念的具体行动,是引导藏区群众树立良好社会风气、维护和谐稳定发展环境的必然要求。
针对上述需求,本文以藏文新闻文本数据为研究对象,提出基于混合表示的藏文新闻主客观句子分类模型。首先,根据特征粒度的不同,将特征分为音节级特征、包含当前音节的单词级特征。音节级特征采用Word2Vec向量、BERT向量表示。在单词级特征获取过程中,通过单词特征提取方法获得音节的BMES单词集合,应用注意力机制计算BMES集合中单词向量的权重,通过加权求和BMES集合中单词向量并拼接加权求和结果,获得音节的单词级特征。其次,将音节级特征向量和单词级特征向量拼接后输入到BiLSTM+CNN网络进行语义提取。最后,采用Softmax分类器实现句子的主客观分类。同时,分析音节和单词的不同特征组合对主客观句子分类性能的影响,探索出最优的特征组合。测试结果表明,HRTNSC模型在Word2Vec向量+BERT向量+注意力机制加权的单词特征向量组合下F1值达到90.84%,表现出了较好的分类效果。
本文的贡献归纳如下:
(1) 提出了基于混合表示的藏文新闻主客观句子分类模型HRTNSC,采用音节级特征融合单词级特征方式,增强序列语义理解,通过特征提取和分类网络实现藏文新闻主客观句子分类。
(2) 提出了藏文音节序列的词嵌入表征方法,通过融合Word2Vec音节向量、BERT音节向量、单词向量得到特征表达充分的序列向量,分类效果优于音节向量,实验证明了特征融合对藏文新闻主客观句子分类的有效性。
(3) 提出了单词向量静态加权与动态加权方式,分析两种加权方式对藏文新闻主客观句子分类性能的影响,实验证明了动态加权方式比静态加权方式更加有效。
1 相关工作
当前主客观文本分类的研究主要分为三种方法: 基于规则的方法、基于机器学习的方法和基于深度学习的方法。基于规则的方法[3]通常要求人工编写分类规则,根据满足的规则条件,输出主客观类别。例如,张晓梅等[4]通过组合特征选择方法,融合内容、单词信息,得到主客观分类特征。在新浪微博数据集上测试结果证明,特征融合算法的分类效果优于单一特征选择方法,其F1值达到69.35%。基于规则的方法具有分类准确、易于理解、直观高效等优势,不足之处是分类规则的编写需要消耗大量的时间与人力,有时由于背景知识的匮乏或者文本表达的多样性,存在规则无法覆盖全部语言现象的问题。此外,规则的方法忽略了文本的上下文语义信息,无法从语义理解的角度解释分类问题。
基于机器学习的方法[5-6]通过预先标注的数据获取文本的词汇、句法、语义等特征,然后构造分类器(如支持向量机[7-8]、条件随机场[9]、朴素贝叶斯[10-12]等)实现分类。例如,张乐[13]通过获取文本的语义、语法和符号特征,选用不同的特征组合,运用朴素贝叶斯分类器完成主客观分类。分类效果证明,结合上述三类特征可获得较好的分类性能,其F1值达到84.20%。基于机器学习的方法擅长小样本数据集的分类,其在具体应用中可大幅度降低规则的使用。缺点是文本特征的提取耗时耗力,且特征提取的优劣严重影响分类效果,特征提取过程中大量自然语言处理工具的使用,会引入新的错误。
近年来,神经网络在语音、图像等领域的成功应用,为文本主客观分类任务采用基于深度学习的方法开展研究提供了一种新思路[14]。例如,王剑等[15]提出在BiLSTM(Bi-directional Long-short Memory Neural Network)网络中融入关联特征的汉越双语主观句识别方法。首先利用汉越双语句子的情感和事件要素构建关联图,并采用TextRank算法获得句子关联特征,然后通过BiLSTM网络将汉越双语文本映射到同一语义空间,最后融合句子关联特征和编码特征,通过分类网络实现主观句识别。
注意力机制是自然语言处理领域引入的一个重要概念,其核心是对观察到的数据分配权重,通过权重分配达到提取文本核心语义信息的目的。Bahdanau等[16]率先在机器翻译领域应用注意力机制,其后,黄彪[17]将注意力机制和神经网络结合,开展主客观文本分类研究。林思琦等[18]提出融合多特征的汉越双语主观句识别方法;首先,针对汉语和越语标注语料不平衡的问题,构建汉越双语词向量模型,采用汉文标注资源补充越语标注资源的不足;其次,在词向量和注意力机制中分别融入句子的主题、位置和情感特征,实现句子语义信息与上述特征的结合。测试表明,上述方法能有效地检测出越语主观句,准确率达到了64.50%。
使用深度学习进行主客观文本分类,除需要选择合适的神经网络分类模型之外,获得合适的词向量表示同样十分重要。词语的表征最早使用one-hot、bag-of-words等离散表示,后来基于神经网络的词嵌入方法被用来生成词语的紧致连续表示,代表方法有Word2Vec[19]和GloVe[20]。由于此类方法不需要先验知识,只需提供文本语料就能训练出有效的语义表示,因此逐渐成为主流。
基于现代藏文文法,参考英文和汉文句子的识别及分类成果,对藏文句子的识别及分类方法进行了研究,为藏文句子的自动识别及分类提供了理论依据。当前,针对藏文句子自动识别及分类的研究只见数篇零散的文献报道。柔特等[21]研究了基于循环卷积神经网络的藏文句类分类模型,该模型在陈述句、疑问句、祈使句、感叹句分类任务上取得了较好的分类效果。Ban等[22]研究了基于短语特征的藏文疑问句分类模型,分类准确率达到了96.98%。然而,针对藏文句子主客观分类任务的研究目前未见相关文献 。

2 藏文新闻主客观句子分类模型(1)https://gitee.com/wellkong112/tibetan-soclassify.git
模型首先对爬取的藏文新闻文本进行预处理,然后把按音节和单词切分的文本映射成向量表示,把音节级特征向量和利用注意力机制获得的单词级特征向量拼接起来,并将拼接后的向量输入到BiLSTM+CNN网络进行语义提取。最后通过全连接层和分类层实现藏文新闻句子的主客观分类,其模型结构图如图1所示。
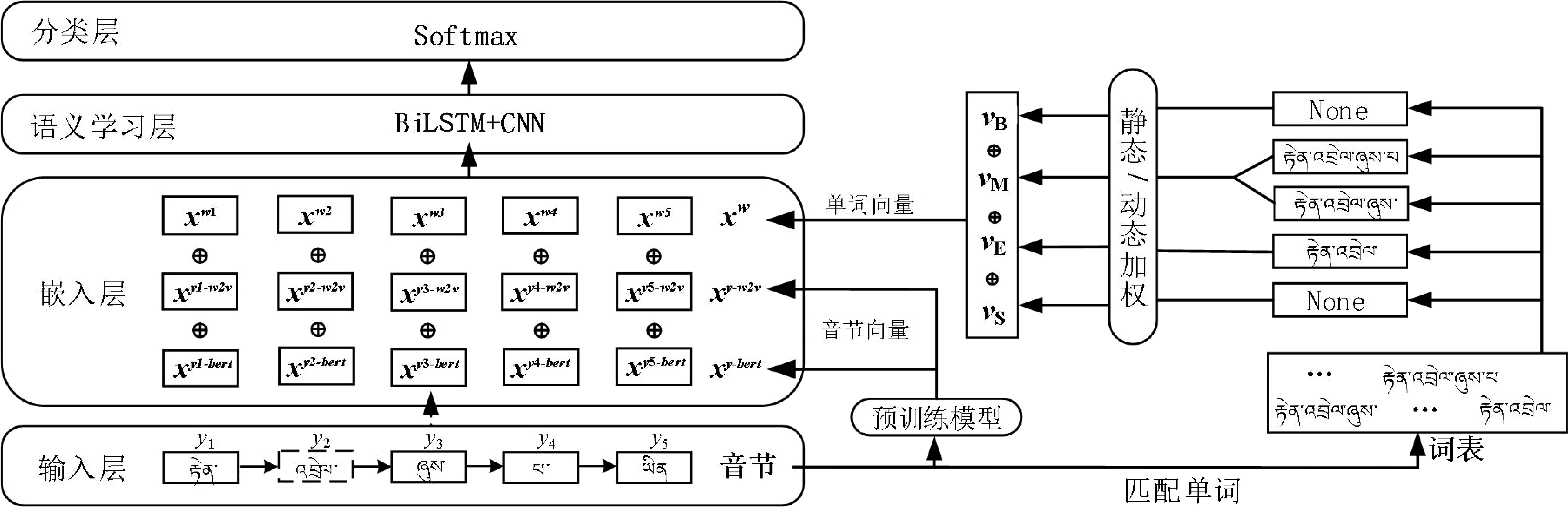
图1 混合表示的藏文新闻主客观句子分类模型结构图
2.1 预处理
2.1.1 删除非藏文字符
由于藏文文本中含有一定数量的阿拉伯数字、英文字母、中英文标点符号等非藏文字符,但模型输入需为纯藏文字符,因此需将文本数据中非藏文字符全部删除。
2.1.2 藏文分词
藏文没有空格等形式的自然分隔符,但本文研究涉及藏文单词的语义理解,因此在预处理环节需对文本进行分词处理,本文采用青海师范大学Tibetan_sgm_utf[23]藏文分词器实现分词,其在封闭数据集上的分词正确率可达到95.70%。
2.1.3 藏文音节切分
为了缓解藏文分词操作对主客观分类任务的影响,本文采用音节作为模型的输入单元,因此预处理操作需根据音节分隔符完成对藏文文本的切分。
2.2 网络结构
2.2.1 嵌入层
模型在嵌入层将预处理的文本以向量形式表示,具体通过Word2Vec框架和BERT预训练模型[24-25]转化成文本特征为恒定维数的紧密向量,然后运用拼接的方法融合音节级特征向量和单词级特征向量,进而获得输入语义学习层的向量。
(1) 音节级特征
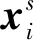
其中,es表示使用Word2Vec框架训练得到的音节向量查找表。BERT表示BERT预训练模型音节向量查找表。
(2) 单词级特征
通过分析发现,音节级特征融入单词级特征,将有益于提升模型的分类效果。本文在嵌入层实现音节级特征和单词级特征的融合,音节的单词级特征定义为包含当前音节的单词集合的特征,集合中单词的获取通过词表L实现。词表L约定为本文藏文新闻热点事件句子原始语料分词结果去重后得到的单词列表。
音节的单词特征提取方法描述如下: 首先,运用词表得到藏文音节序列中所有的单词;然后,根据音节出现在某个单词的开头、中间、结尾和音节本身单独成词四种情形,分别将单词加入B、M、E、S单词集合。如果BMES集合中不存在匹配单词,则填充None标识。基于BMES的单词特征提取方法示意图如图2所示。
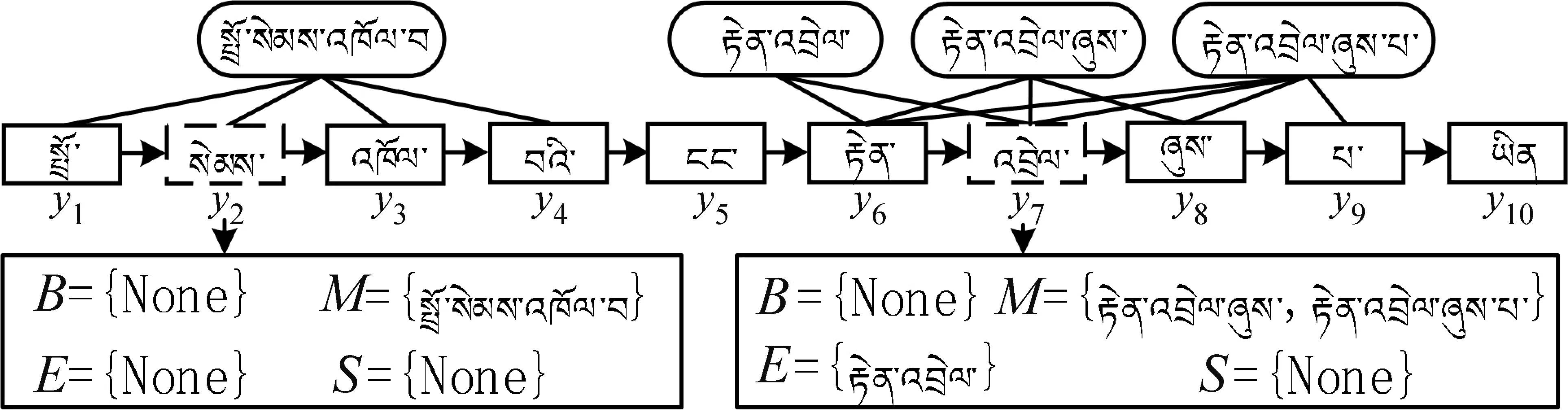
图2 基于BMES的单词特征提取方法示意图

在获得音节对应的单词后,音节si的四个单词集合表示如式(3)~式(6)所示。
其中,L为本文所用词表。
在得到音节的BMES单词集合后,接下来加权求和单词向量,即可得到单词集合向量。为了得到合理的单词集合向量,本文分别探索静态单词向量加权方式和动态单词向量加权方式。两种加权方式的性能对比如表4所示。
静态加权方式采用单词词频表示单词向量权重。单词w的静态加权方式如式(7)、式(8)所示。
其中,Vw(B∪M∪E∪S)是单词w的静态加权表示,z(w)是单词w在词表L中的词频,Z是B∪M∪E∪S集合中所有单词在词表L中的词频之和。ew(w)是单词w在向量查找表ew中的词向量。上述方法中,由于词表L固定,因此,单词词频为静态值,可以离线获取,且当单词w被词表中另一个单词覆盖时其频率不会增加,这可大大加快单词权重的计算效率。
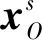
(9)
(10)
(11)
其中,n表示藏文句子序列O中的音节个数,Wo,bo为训练参数。
其次,计算BMES单词集合中单词的向量表示,本文仅给出单词集合M中单词向量的获取方法,集合B、E、S的单词向量可类比表示。集合M中第j个单词的向量xj计算如式(12)所示。
xj=ew(wj),wj∈M
(12)
其中,ew表示运用Word2Vec框架训练获得的单词向量查找表。
接下来,计算集合M中单词与藏文句子序列O的语义关联程度。集合M中第j个单词与藏文句子序列O的语义关联程度aj,O计算方法如式(13)所示。
(13)
其中,m表示集合M中的单词个数。·为点乘运算,用于计算向量内积。
最后,加权求和集合M中的单词向量得到集合向量VM,VM计算方法如式(14)所示。
(14)
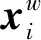
(15)
其中,VB(si)、VM(si)、VE(si)、VS(si)分别表示音节i的单词集合B、M、E、S的向量。
将音节的单词级特征向量融合至对应的音节级向量,获得融合后的向量为xi,xi计算方法如式(16)所示。
(16)
2.2.2 语义学习层
将上述嵌入层获得的融合向量输入至语义学习层进行特征提取,语义学习层由BiLSTM+CNN两重网络构成,下面对BiLSTM网络和CNN(Convolution Neural Network,CNN)网络分别进行介绍。
(1) BiLSTM网络
藏文的音节之间存在时序关系,为了学习音节的语义依赖,本文采用BiLSTM作为语义学习层的第一重特征提取网络。BiLSTM由正反两个LSTM(Long-short Memory Neural Network,LSTM)网络构成,实现从正反两个方向提取序列的词汇、语义信息,进而达到提高藏文新闻主客观句子分类效果的目的。
下面对正向LSTM网络的特征提取过程进行定义,如式(17)、式(18)所示。
其中,X表示t时刻的输入,如式(19)所示,wc,bc为模型参数。it、ft、ot分别代表输入门、遗忘门、输出门的激活值,如式(19)~式(22)所示,σ表示Sigmoid函数。
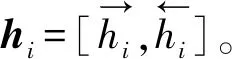
(2) CNN网络
在文本特征提取领域,CNN因稀疏交互、参数共享、计算高效等优点被广泛应用。本文选用CNN作为语义学习层的第二重特征提取网络,CNN网络主要包含卷积和池化两种操作。采用多个卷积核与BiLSTM网络的输出进行卷积计算,通过卷积网络自动挖掘音节序列的深层特征,再将卷积结果拼接,得到CNN网络的输出。
卷积过程中特征音节mi的计算如式(23)所示。
mi=f(w·xi:i +h -1+b)
(23)
其中,f是非线性激活函数,b为偏置参数,w是卷积核权重,xi:i+h-1为音节向量矩阵,h为卷积核感受野大小。
包含l个音节的句子序列{x1:h,x2:h,…,xl-h+1:h}经过卷积处理后得到特征图M,M计算如式(24)所示。
M=[m1,m2,…,ml-h+1]
(24)
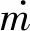
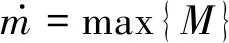
(25)
拼接最大池化结果,得到池化后的输出h,其计算如式(26)所示。
(26)
其中,k为卷积核个数。
2.2.3 分类层
分类层将语义学习层提取的特征放入分类器进行拟合和测试。拟合过程中将特征和类别传入网络进行学习,当训练数据全部拟合完毕,使用测试数据对拟合好的模型进行检验。本文将前一层得到的藏文新闻句子的最终表示h,通过全连接网络输入至Softmax分类模块,经分类得到最终的类别。分类计算如式(27)所示。
Y=softmax(Wh+b)
(27)
其中,Y代表分类层输出,表示文本属于主观文本、客观文本的概率。W∈Rd×2为网络权重矩阵,b∈R2为网络偏置。
采用交叉熵损失函数衡量真实分布和预测分布之间的差距,利用反向传播方式对模型中的参数进行更新。交叉熵损失函数如式(28)所示。
(28)
其中,D为训练数据集大小,j表示分类类别,YPi,j表示第i个样本对应第j个类别的期望输出概率,Yi,j表示第i个样本对应第j个类别的模型实际输出概率。在模型训练过程中,采用Dropout方法随机控制网络中部分隐层节点停止工作,防止模型过拟合。
3 实验及结果分析
3.1 实验数据
在藏文新闻主客观句子分类领域,尚无公开的测试数据集。本文通过网络爬虫抓取并经预处理整理出2020年8月至2021年8月,在人民网藏文、中国西藏网、中国西藏新闻网、中国藏族网通、青海藏语网络广播电视台中的原始藏文新闻热点事件句子60 000条。定义热点事件为持续在同一网站报道或者在不同网站多次报道的新闻事件,例如同时在上述五家藏文网站报道的“习近平视察海军陆战部队”“习近平祝贺‘摆脱贫困、政党责任’国际学术研讨会召开”“深圳经济特区建立四十周年庆祝大会举行”等事件。采用人工方式从原始数据中抽取出5 000条主观句子和5 000条客观句子进行标注作为实验数据集,Word2Vec向量直接通过原始数据训练获得,BERT音节向量采用BERT-BOD预训练模型得到[24]。
3.2 评价指标
为了评价基于混合表示的藏文新闻主客观句子分类模型的有效性,本文选用正确率(Precision,P)、召回率(Recall,R)和F1值作为性能评价指标,具体如式(29)~式(31)所示。
其中,TP为正确分类的主观句子数,FP为错误分类的主观句子数,FN为错误分类的客观句子数。
3.3 实验参数设置
为了有效开展实验,本文运用Gensim工具获得Word2Vec向量,设置上下文窗口尺寸为5,向量维度为50,最小出现频次为1,其余参数均为默认值。在训练模型时,固定上述参数且冻结Word2Vec向量查找表。模型的输入以每批次中最长句子为基准,同一批次中其余句子通过
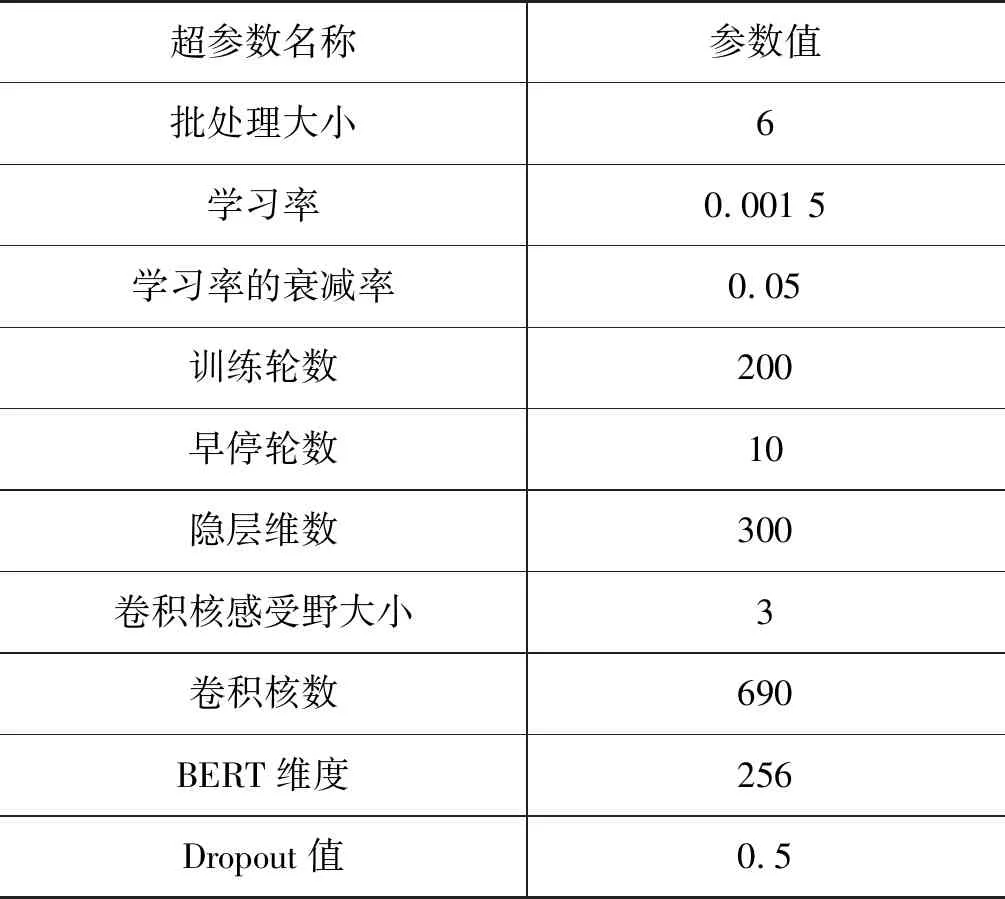
表1 模型超参数
3.4 对比实验设置
为了验证HRTNSC模型的优势,本文从两个维度开展对比实验。横向维度上,HRTNSC模型与其他3种分类模型进行对比测试。对比分类模型介绍如下:
基于CNN的分类模型模型输入及特征融合与本文方法相同,然后运用卷积、最大池化等操作学习语义特征,最后采用Softmax激励实现主客观分类。其中,设置卷积核感受野大小为3,卷积核数为300。
基于BiLSTM+ATT的分类模型模型输入及特征融合与CNN模型相同,通过BiLSTM网络学习句子时序及语义信息,运用注意力机制加权输出向量,最后通过Softmax分类网络实现主客观分类。其中,设置LSTM网络隐层维数为300维。
基于Transformer的分类模型模型输入及特征融合与CNN模型相同,采用基于多头自注意力机制的网络提取音节序列的语义特征,通过Softmax激活网络实现主客观分类。其中设置多头个数为4。
纵向维度上,通过六个不同的特征组合探究音节和单词的融合方式对主客观句子分类性能的影响。对比实验的特征组合设置如表2所示。
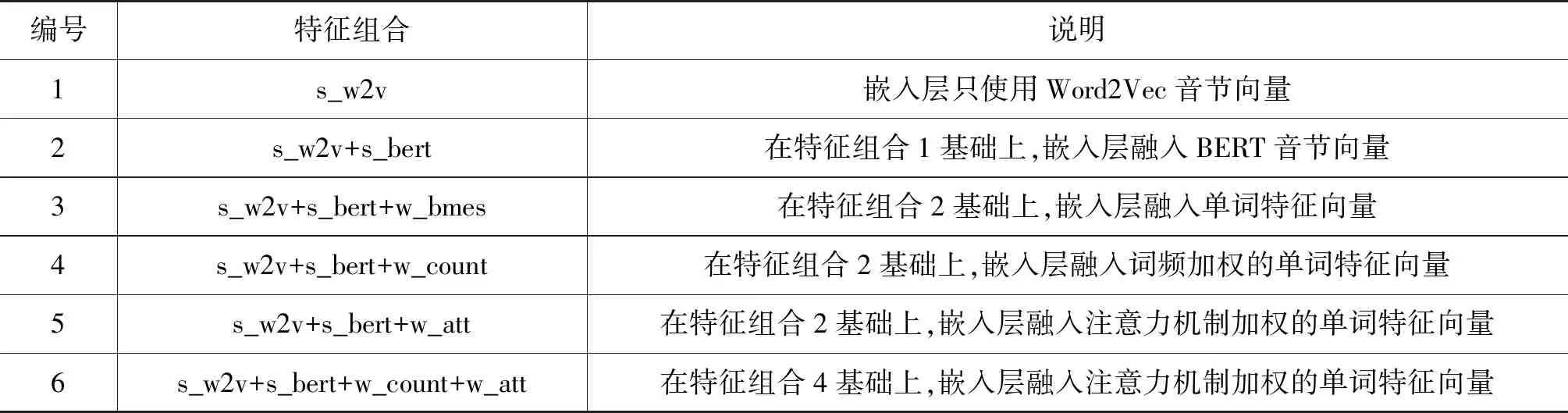
表2 对比实验的特征组合
3.5 实验结果与分析
本文实验的模型在服务器上运用GPU训练,GPU型号选用NVIDIA Tesla V100。在训练模型时,将标注数据均匀切分为10份,按7∶2∶1比例分为训练集、验证集、测试集,使用交叉验证方法训练每个模型3次,最后将实验结果取平均值得到最终结果。
3.5.1 横向维度实验结果
根据评价准则,HRTNSC模型和对比模型分别采用s_w2v+s_bert+w_att特征组合在本文数据集上进行实验,具体实验结果如表3所示。
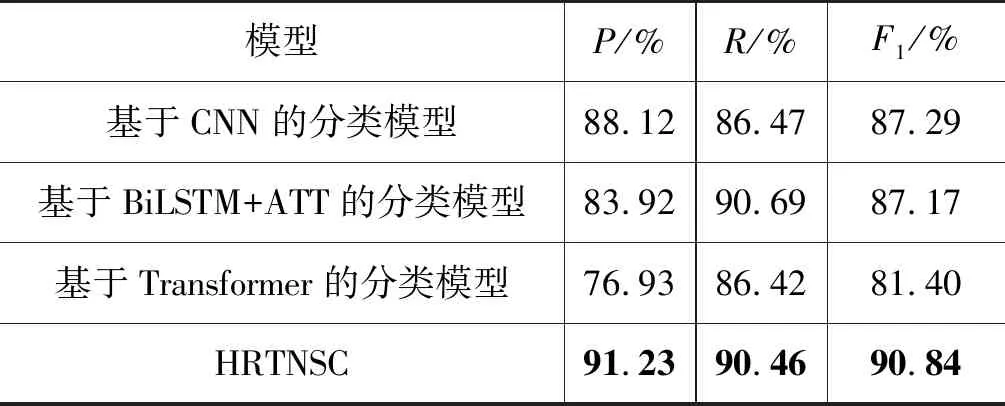
表3 横向维度对比实验结果
分析表3的实验结果不难发现,HRTNSC模型在F1值上均取得了最优性能,并且明显高于第2好的基于CNN的分类模型,相比基于BiLSTM+ATT的分类模型,F1值提高了3.67%。基于Transformer的分类模型F1值最低,仅为81.40%,这是因为藏文新闻主客观句子分类任务中音节位置信息的引入有益于分类性能的提升。BiLSTM网络由于循环运算的结构天然地获得了音节序列的位置信息,而Transformer网络则要运用增加绝对位置编码方式获得音节序列的位置信息。由于本文实验的训练集数据规模较小,导致Transformer的绝对位置编码难以准确获得音节序列位置信息,进而导致分类效果的不理想。
对比基于BiLSTM+ATT的分类模型和基于CNN的分类模型可知,这两种模型的F1值差别不大,而且基于CNN的分类模型正确率还高于基于BiLSTM+ATT的分类模型。这是因为CNN网络使用的卷积是一维卷积,类似于获取句子中N-gram的特征表示,其重点关注音节序列中有利于主客观分类的重要局部特征,重要局部特征的引入增强了对句子序列语义的理解,进而提高了藏文新闻主客观句子分类的正确率。
本文提出的HRTNSC模型采用BiLSTM+CNN的两重特征提取网络学习音节序列的语义信息。第一重网络运用BiLSTM结构有效捕获音节序列的位置信息,增强对序列语义的理解。第二重网络采用CNN结构在第一重网络BiLSTM的基础上,重点提取序列中的重要局部特征,进一步强化对序列语义的理解。因此,融合基于BiLSTM+ATT的分类模型和基于CNN的分类模型优势的HRTNSC模型获得了最优性能。
3.5.2 纵向维度实验结果
纵向维度上,HRTNSC模型和对比模型在表2的特征组合下进行实验,实验结果如表4所示。
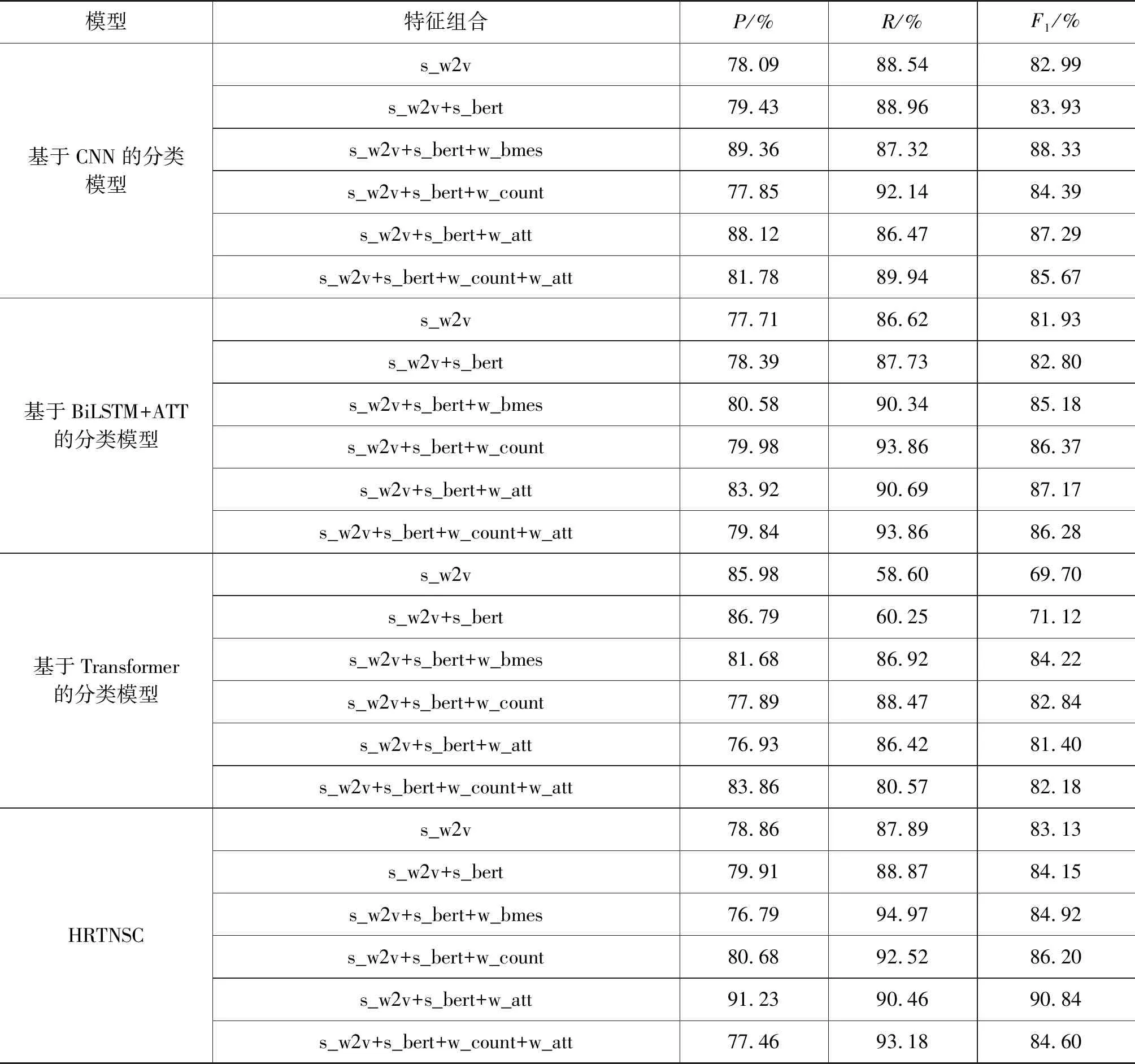
表4 纵向维度对比实验结果
通过表4将对比实验从纵向维度观察,可以看出当各模型的嵌入层特征组合仅为s_w2v时,分类结果的F1值均较低,表明特征融合拥有一定的提升空间。当特征组合为s_w2v+s_bert时,各模型的F1值都得到一定提升,证明BERT音节向量在增强序列语义理解方面具有积极价值,但本实验中BERT音节向量的作用并不显著,这是因为本文使用的藏文BERT预训练模型是一个自制的小型模型,规模偏小,性能不及当前的中英文BERT预训练模型。
进一步观察不同特征组合下各模型的分类效果,可以看出s_w2v+s_bert+w_bmes组合下,所有模型的F1值较s_w2v+s_bert均有相对明显的提升。分析原因可知,s_w2v+s_bert+w_bmes组合在s_w2v+s_bert的基础上融入了单词信息,单词信息的引入增强了模型对句子语义的理解,进而提升了模型的主客观分类性能。
除去上述情况,通过图3分析s_w2v+s_bert+w_count、s_w2v+s_bert+w_att组合下单词向量加权方式对藏文新闻主客观句子分类效果的影响,可以得出除基于Transformer的分类模型外,本文模型和其他对比模型在动态单词向量加权方式下的F1值较静态加权方式有较明显提升。原因在于模型通过注意力机制动态表示单词向量权重时,能够比词频加权方式更加有效地增强影响文本主客观分类的重点单词的语义表达,从而表现出更好的分类效果。基于Transformer的分类模型难以在小数据集下表现出多头注意力的特征提取优势,因此,在本文数据集下Transfomer分类模型未表现出与其他模型一致的特点。
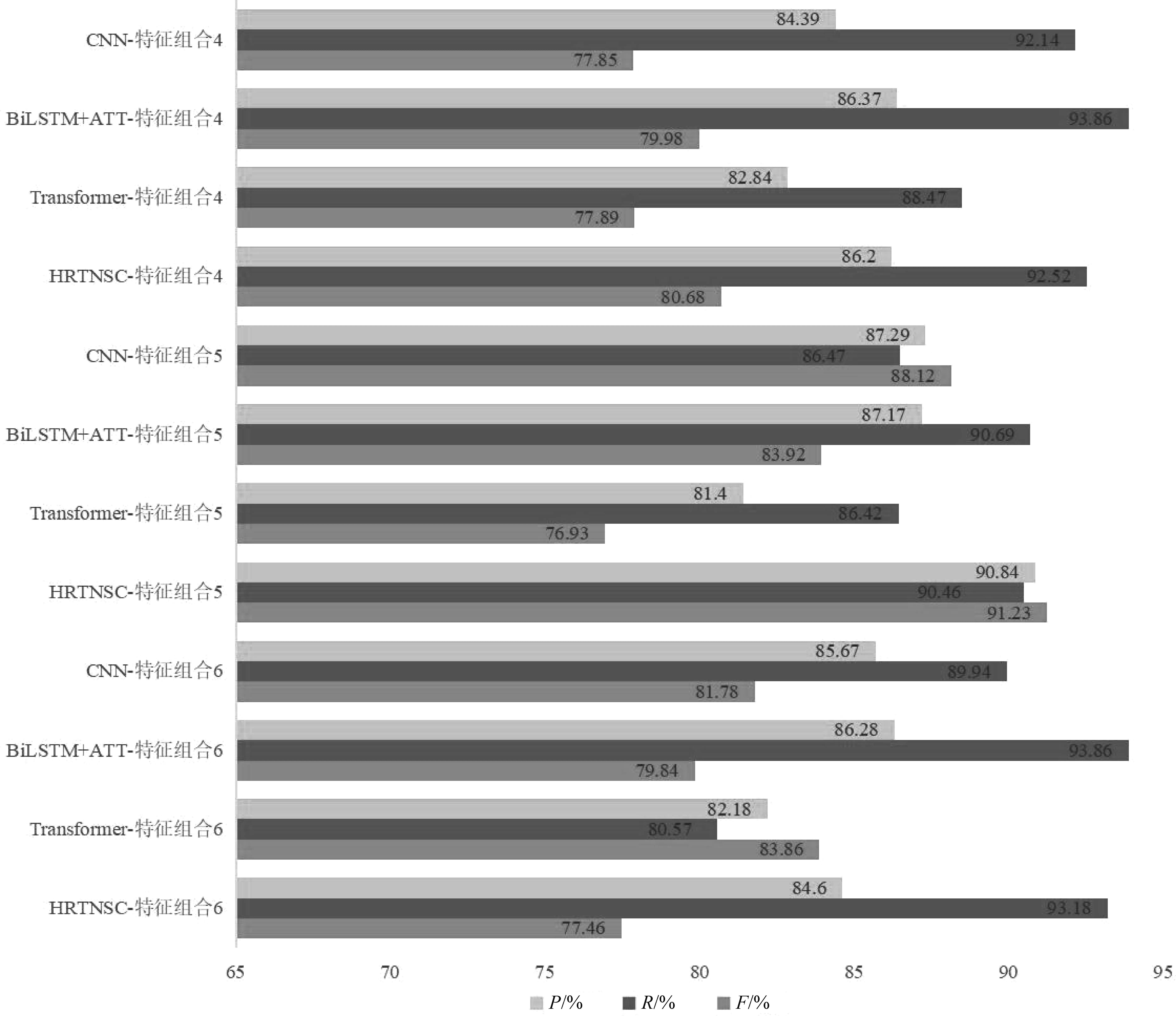
图3 纵向维度对比实验结果
s_w2v+s_bert+w_count+w_att特征组合展示了静态加权方式和动态加权方式同时作用于单词向量的情形,实验数据表明,分类结果的F1值并未叠加增长,反而表现出了总体低于单一加权方式的特点,说明在藏文新闻主客观句子分类任务中,盲目叠加单词加权效果,有时不仅不会带来模型性能的叠加式提升,甚至会弱化单一加权方式的分类性能。
4 总结与展望
针对藏文新闻主客观分类的现实需求,本文提出基于混合表示的藏文新闻主客观句子分类模型。根据特征粒度的不同,将特征分为音节级特征、包含当前音节的单词级特征。音节级特征采用Word2Vec向量表示、BERT向量表示。计算单词级特征时,通过特征提取算法获得音节的BMES单词集合,运用注意力机制动态表示BMES集合中单词向量权重,通过加权求和BMES集合中单词向量并拼接加权求和结果,得到音节的单词级特征。将音节级特征向量和单词级特征向量融合后输入BiLSTM+CNN网络实现语义提取,运用Softmax分类器得到分类结果。同时,本文分析音节和单词的不同特征组合对主客观句子分类效果的影响。测试结果表明,HRTNSC模型在Word2Vec向量+BERT向量+注意力机制加权的单词特征向量组合下能够较为有效地分类藏文新闻主客观句子,分类效果优于对比方法,具有一定的应用价值。
由于HRTNSC模型采用的BiLSTM+CNN特征提取网络已经较为常见,未来工作中,我们将尝试对HRTNSC模型本身进行一定程度的改良与创新,进一步增强是语义学习能力,进而提升藏文新闻主客观句子的分类性能。
