面向文本推理的知识增强预训练语言模型
2022-02-03熊凯,杜理,丁效,刘挺,秦兵,付博
熊 凯,杜 理,丁 效,刘 挺,秦 兵,付 博
(1. 哈尔滨工业大学 社会计算与信息检索研究中心,黑龙江 哈尔滨 150006;2. 建信金融科技有限责任公司 基础技术中心,北京 100032)
0 引言
文本推理是自然语言处理 (Natural Language Processing) 社区中具有巨大挑战性的任务之一,它要求机器同时拥有语义理解能力和利用丰富的知识进行推理的能力。预训练语言模型比如 BERT[1]的出现使得文本推理任务有了跨越式的发展,如阅读理解[2],事件预测[3]等,BERT 使用 Transformer[4]的编码器在大量无标注的文本上进行预训练,无标注文本中丰富的语言学和语义知识使 BERT 具有很强的语义理解能力,在大量的文本推理任务上仅进行微调就能得到很好的效果。

图1 阅读理解数据集实例
之前的研究表明,机器进行文本推理不仅需要较强的语义理解能力,还需要利用丰富的知识来支撑机器进行复杂的推理[5-6]。所以丰富的知识对机器解决文本推理任务来说非常重要。以机器阅读理解任务中的ReCoRD数据集[7]为例,如图1所示,ReCoRD数据集展示的任务是给定一个上下文篇章(Passage),需要从上下文篇章中抽取出实体来填补问题(Question)里面的空缺(×××),ReCoRD已经将上下文中包含的实体标注出来(图中的下划线词),图1中上下文篇章给出的信息为英国某动物园给熊猫“甜甜”进行人工授精,预计在8月“甜甜”能产下幼崽。而问题给出的信息为幼崽在两岁的时候要被送回四川,“×××”这个时间点也是它在野外离开父母的时间。模型需要从上下文中抽取实体来回答问题。如果我们的机器有着(四川位于中国)、(熊猫是哺乳动物的下位词)以及(熊猫是野生动物的下位词)这样的外部知识,结合对上下文篇章以及问题的理解,机器就能很容易得到图1中的答案为中国。
如何融入知识也是一个具有挑战性的问题,前人对BERT的分析表明,BERT同层的输出倾向于编码的信息是不同的[8-9],较低层BERT的输出倾向于编码比较低级的信息,例如语法等一些语言学的信息,较高层BERT的输出倾向于编码更高级的信息,例如语义信息甚至是抽象信息等。此外,以前融入知识的方法大部分都是使用检索-编码的方法[10-11],对预训练语言模型直接融入知识进行文本推理的方法[2]只是在最外层对知识进行融入,上下文和知识没有进行深度交互。所以本文认为在已得到知识的情况下,在什么位置融入知识,以及如何使知识深度融合到上下文中也是非常关键的。
基于以上分析,我们提出了一个基于预训练语言模型的知识深度融合框架(Pre-trained Language Model Based Knowledge Deep Aggregation Framework,PLM-KDA),使用丰富的知识对预训练语言模型进行增强,并对知识融入的位置进行设置以使知识和上下文的充分融合,最终支撑机器进行文本推理。对比于一系列的基线方法,本文模型达到了很好的性能表现。本文工作的贡献可以总结为以下几点:
(1) 通过使用预训练语言模型,对文本进行深层的语义理解;
(2) 通过在模型中间层的输出融入知识,使得知识的融入更加充分;
(3) 通过对模型融入丰富的知识,支撑模型进行更高效的推理。在机器阅读理解和脚本事件预测任务上,模型超越了一系列基线方法。
1 相关工作
1.1 预训练模型
最早的预训练模型可以追溯到词向量[12](Word2Vec),词向量通过无监督的方法,在大量的非结构化文本中进行训练得到每个词的向量表示。后续斯坦福大学通过引入语料库的全局特征以及局部上下文特征对词向量进行改进,得到GloVe词向量[13]。为了解决自然语言文本中多义词问题,ELMo[14]的出现使得相同的词在不同的上下文中拥有不同的向量表示。
随着深度学习及机器算力的发展,大型的预训练语言模型几乎占领了自然语言处理绝大部分任务的榜单。最有代表性的预训练语言模型有BERT[1],RoBERTa[15],XLNet[16]等。近两年超大型预训练语言模型的发布也使得预训练语言模型的能力得到进一步的提升,代表性的工作有GPT-3[17]等。
1.2 知识增强的预训练语言模型
虽然BERT等预训练语言模型在文本理解上取得了巨大成功,但是其中缺少了知识。为了解决预训练语言模型中知识缺失的问题,Zhang等人[18]使用知识图谱嵌入方法TransE[19]将知识图谱进行编码并融入到预训练语言模型中,Sun等人[6]通过显式的方法将知识图谱的三元组引入到预训练语言模型中,Yamada等人[20]通过使用一个实体级的注意力机制得到深层上下文相关的实体表示。为了编码图结构的知识以进行文本生成,一些工作对知识图谱的图结构信息进行检索,并用一个编码器将图结构进行编码[21-23]。
1.3 机器阅读理解与脚本事件预测
人类进行推理时利用了很多潜在知识[24],但是机器原本并不具备这种潜在的知识,所以给机器提供额外的知识以进行推理是非常重要的。
近些年来,很多阅读理解数据集(CNN/DM[25]、SQuAD[26-27]、MS-MARCO[28]等)的出现推动了机器阅读理解的发展。很多新颖的方法被提出用来解决机器阅读理解任务,比如Match-LSTM[29]、AoA Reader[30]以及QANet[31]等,这些端到端神经网络的结构比较类似,都是用一个编码器对上下文以及问题进行编码,然后经过一个注意力机制,最后进行预测。随着预训练语言模型的出现,这些方法很轻松地被预训练语言模型超越。
Gronroth-Wilding和Clark[32]在2018年提出从新闻生文本中无监督地归纳出叙事事件链的研究,使用事件填空的形式对模型的性能进行评价,开创了脚本事件预测的工作,后续也有一些序列建模的方法被提出来解决脚本事件预测的问题[33-34],但是这些方法忽略了对事件间关系的建模。Li 等人[35]首次提出通过构建一个时序事理图谱来建模事件之间的邻接关系,并利用图神经网络对事件图进行建模。Lv 等人[36]使用注意力机制隐式地建模图结构的事件关系,最后使用一个事件链级别的注意力机制进行事件预测。
2 问题定义
本文关注于文本推理的两个子任务: 阅读理解和脚本事件预测。
2.1 阅读理解
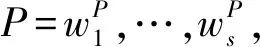
基于以上定义,机器阅读理解任务定义为,对于问题查询中的空缺,模型需要在上下文篇章P的实体E中选择一个正确的实体ec填入空缺。
考虑到不同实例中上下文篇章实体数量的不均衡,本文将任务定义为一个片段抽取的形式,即对于给定的上下文篇章P与问题查询Q,从上下文篇章P中抽取出一个实体片段espan,将其填入问题查询Q中。
2.2 脚本事件预测
如图 2 所示,脚本事件预测任务定义为: 给定X发生的一系列事件EX=x1,…,xl,其中l表示事件的数量,每个事件xi=Pi(Si,Oi,Ii)是一个四元组,Si为主语,Pi为谓语,Oi为宾语,Ii为间接宾语。对于给定的上下文事件链,需要从后续事件集合CX=c1,…,ck中选择出可能发生的后续事件,其中k为候选事件的数量,每个候选事件定义与上下文事件一致。

图2 脚本事件预测数据集实例
3 方法
为了解决如何在预训练语言模型中融入外部知识的问题,本文提出了一个基于预训练语言模型的知识深度融合框架PLM-KDA,整体的框架结构如图3所示,PLM-KDA框架主要包括5个模块: 编码器,对输入文本进行编码及语义理解;聚合器,阅读理解任务中聚合器将检索到的知识聚合到上下文的表示中去,脚本事件预测任务中聚合器将字符的表示聚合为事件的表示;更新器,在阅读理解任务中建模上下文信息与知识的充分交互,在脚本事件预测任务中使用检索到的图结构知识对事件表示进行更新;融合器将知识相关的上下文表示融合到编码器中并传入后续的编码层;预测器,对答案进行预测。本文使用阅读理解任务进行具体方法的举例。
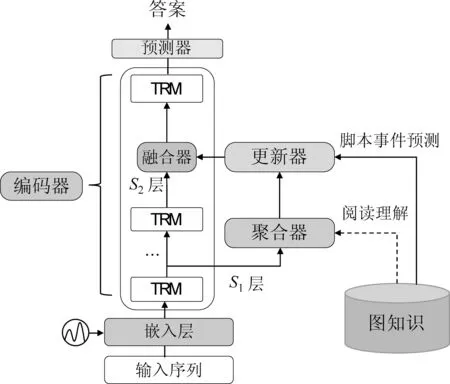
图3 PLM-KDA 框架结构图
3.1 阅读理解任务知识检索
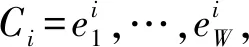
对于每个候选外部知识词,使用知识图谱嵌入对其进行初始化表示,如式(1)所示。
(1)
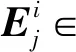
3.2 编码器
为了将上下文篇章及问题查询文本表示为稠密的向量,并得到上下文相关的表示,我们使用预训练语言模型BERT对上下文篇章及问题查询进行编码,BERT由S层Transformer层堆叠而成,我们将H(i)记为BERT第i层的输出,首先我们将上下文篇章及问题查询文本拼接在一起输入到BERT的嵌入层得到一个初始化的表示,如式(2)所示。
H(0)=Etoken+Eseg+Epos
(2)
其中,H(0)代表输入文本中每个字符的初始化表示,Etoken代表字符向量,Eseg代表片段向量,用来区分上下文篇章和问题查询,Epos为位置向量,给文本中的字符引入位置信息。最终每个字符的初始化表示由字符向量、片段向量和位置向量相加得到。
基于得到的字符的初始化表达,定义经过一个Transformer层后得到的向量更新如式(3)所示。
H(i)=transformeri(H(i -1))
(3)
其中,H(i-1)为经过了i-1层Transformer层后得到的输入文本的上下文相关的表示,Transformeri为第i层的Transformer层,H(i)为H(i-1)经过Transformeri得到的向量表示。
由于BERT不同层倾向于编码不同的信息,而检索的外部知识是实体词,是比较简单的知识,所以选择BERT哪一层的表示向量来进行知识的聚合非常重要,在此处本文选择第S1层输出的向量表示进行知识的聚合操作,第S1层的输出可以定义如式(4)所示。
H(S1)=Transformer1→S1(H(0))
(4)
其中,Transformer1→S1为第1层至第S1层 Transformer 层的堆叠,H(S1)∈L×d为经过了S1层 Transformer得到的输入文本的上下文相关的表示,d为BERT的隐层维度。
3.3 聚合器
为将候选的外部知识聚合到输入文本的上下文表示H(S1)中,本文使用一个聚合器将外部知识聚合到H(S1)中。聚合器的输入为第S1层Transformer层的输出H(S1)以及输入文本的候选外部知识表示E。
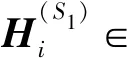
(5)
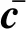
(6)
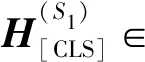
(7)
其中,Uc∈dkb×d为可训练的向量。
在得到所有候选外部知识词以及哨兵向量的权重后,每个候选外部知识词以及哨兵向量的权重可以被定义如式(8)所示。
(8)
基于以上结果,字符ti的候选知识表示可以聚合如式(9)所示。
(9)
其中,ki∈dkb为字符ti选择后的知识聚合表示。最后,我们将ki与ti的上下文表示拼接在一起作为ti更新后的表示d+dkb,这样字符ti的表示既包含了上下文的信息,也包含了相关外部知识的信息。
3.4 更新器
为了使ui中的上下文信息和相关外部知识信息充分融合,本文引入一个注意力机制,使上下文信息和相关外部知识信息进行更深入的融合。与Yang等人[2]一样,同时建模字符之间直接的交互和间接的交互。
对于直接的交互,本文根据Seo等人[39]的方法,对于第i个和第j个字符来说,使用一个线性函数来计算它们的相似度如式(10)所示。
rij=wT[ui,uj,ui⊙uj]
(10)
其中,w∈3d+3dkb为可训练的向量,⊙表示逐点乘法,rij为相似度分数,所以我们可以得到一个相似度矩阵R,其中rij为R第i行第j列的值。然后,根据相似度矩阵,可以得到权重矩阵A,并且得到每个字符关于字符ti的加权求和向量i如式(11)所示。
(11)
其中,aij为A中第i行第j列的值,i反映的是所有字符与字符ti直接交互的程度。
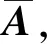

(12)
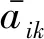
3.5 融合器
为了将更新后的字符表示融入到BERT的表示中并输入到后续的Transformer层中,我们选用第S2层Transformer层的输出S2对O的表示进行融合,首先我们将O映射到d维如式(13)所示。
Od=OUO
(13)
其中UO∈(6d+6dkb)×d为可训练的向量。其次我们使用Vaswani等人[4]提出的多头注意力机制,H(S2)为查询,Od为键和值,计算更新后的表示如式(14)所示。
M=MultiHead(H(S2),Od,Od)
(14)
最后,我们将M输入到BERT中第S2层之后的transformer层中得到所有字符的最终表示如式(15)所示。
H=Transformer(S2+1)→S(M)
(15)
其中,H∈L×d为融合了上下文以及相关知识的字符向量的最终表示。(S2+1)→S表示第S2+1层到S层的Transformer层。
3.6 预测器
由于本文将问题建模为抽取式问题,所以我们通过预测答案片段的开始位置和结束位置对答案片段进行抽取。具体地,本文使用两个线性变换分别预测每个字符为答案片段开始位置的概率以及每个字符为答案片段结束位置的概率,两个概率的计算可以表示如式(16)所示。
(16)
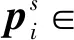
最终,使用交叉熵对模型的损失进行估计如式(17)、式(18)所示。
(17)
LMCNC=∑iCE(pi,yi)
(18)
其中,LReCoRD为阅读理解任务的损失函数,CE(CrossEntropy)为交叉熵损失,LMCNC为脚本事件预测任务的损失函数。
4 实验
4.1 数据及知识库4.1.1 阅读理解
本实验选用ReCoRD数据集[7]进行实验及评估。ReCoRD是一个大规模的机器阅读理解数据集,从CNN和Daily Mail中的新闻收集而来,每个实例由上下文篇章、问题查询、答案以及上下文篇章中包含的实体构成。数据集的统计数据如表1所示。本实验使用的知识库为WordNet[37],WordNet是存储上下位关系的知识库,沿用Yang等人[2]的方法,我们使用NLTK[40]工具来检索每个词在WordNet中的相关词作为候选的知识词。对于某一个词分词后得到的字符集合,每个字符的候选知识词与其所在词的候选知识词一致。候选知识词进行初始化表示时使用的是训练好的知识图谱嵌入[41]。
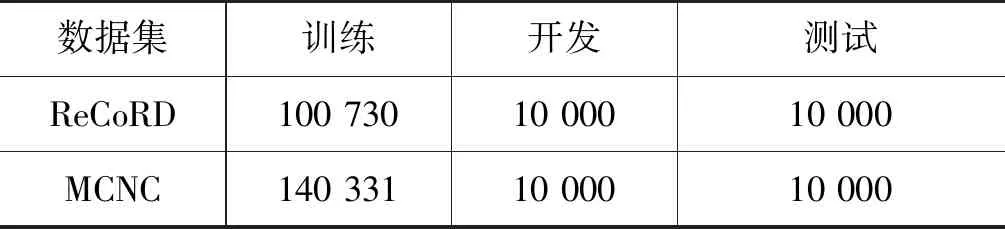
表1 文本推理数据集统计数据
4.1.2 脚本事件预测
脚本事件预测实验中,使用的数据集为MCNC[32],这是一个大规模自动构建的事件预测数据集,通过对纽约时报进行信息抽取获取事件,再将事件根据同一主角连接在一起得到数据样例,详细的数据集统计指标如表1所示。本实验中,使用的知识是事理图谱图结构知识,通过对数据中事件之间的连接关系进行统计,使用训练集构建事理图谱,它是一个有向有环图。通过使用输入事件在事理图谱中进行检索,得到输入事件之间的邻接关系,将这种图结构关系作为知识对预训练语言模型进行增强。
4.2 实验细节
4.2.1 阅读理解
在我们的实验中,使用的是预训练语言模型BERT-base,隐层维度d为768,使用的知识图谱嵌入维度dkb为100。S1和S2分别为4和5。学习率设置为5e-6,batch_size为8。每个词的知识词数量上限设置为27。
4.2.2 脚本事件预测
本实验使用的预训练语言模型为BERT-base,隐层维度d为768,事件在事理图谱中进行检索的方法使用的是BM25算法[42],若两个事件之间检索不到邻接关系,则相应邻接矩阵中的值为0,最后我们将邻接矩阵进行行归一化。S1和S2分别为7和9,学习率为1e-5,batch_size为32。实验使用的多头注意力机制与Vawani等人[4]一致。
4.3 实验结果及分析4.3.1 阅读理解
我们在 ReCoRD 数据集上进行了实验,相关基线方法如下:
(1) DOCQA[43]首先根据TF-IDF检索到相应的篇章,然后使用一个基于注意力机制的推理模块对缺失的实体进行预测。
(2) SAN[44]提出了一个基于注意力机制的随机答案网络,模拟机器阅读理解中的多步推理过程。
(3) BERT-base[1]使用预训练语言模型BERT-base在ReCoRD数据集上进行微调。
(4) DOCQA+ELMo使用基于RNN的模型ELMo对DOCQA的推理模块进行增强。
(5) KT-NET[2]采用注意力机制从知识图谱WordNet中自适应地选择所需知识,然后将所选知识与BERT融合用于阅读理解任务。在本文中,KT-NET是基于BERT-base的。
实验结果如表2所示。基于表中结果,我们可以得到以下结论:
(1) 基于预训练语言模型的方法(BERT-base,KT-NET,PLM-KDA)与没使用预训练语言模型的方法(DOCQA,SAN,DOCQA+ELMo)比较,使用了预训练语言模型的方法有着明显的性能优势,这表明预训练语言模型中包含的丰富的语义知识能够更好地对文本进行语义理解。
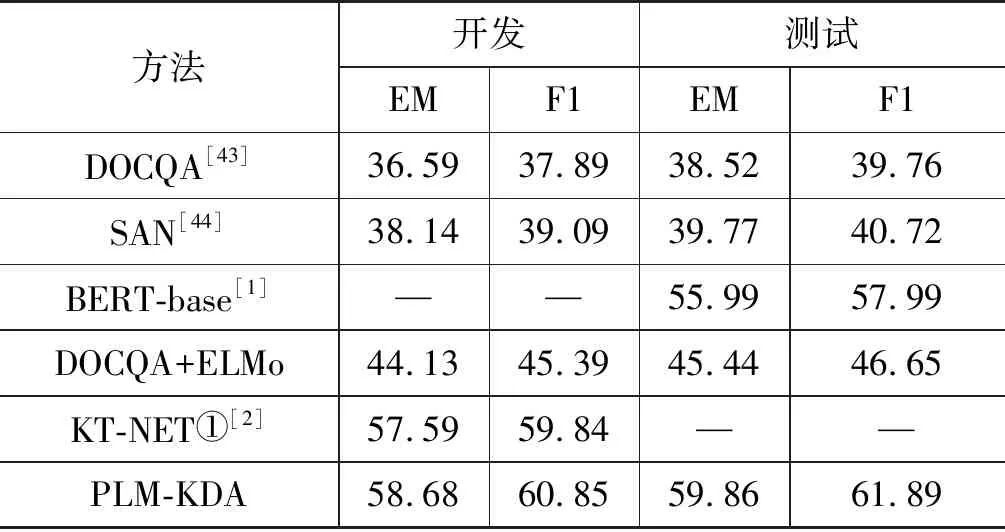
表2 阅读理解实验结果 (单位: %)
(2) 对比于只使用预训练语言模型的方法(BERT-base),使用了知识增强预训练语言模型的方法(KT-NET,PLM-KDA)能够获得更好的性能表现,说明引入丰富的知识能够提供额外的信息并帮助解决机器阅读理解任务。
(3) 对比于在BERT最后一层进行知识融入的方法(KT-NET),PLM-KDA在BERT中间层融入知识,得到了更好的性能表现,说明在什么位置融入知识中的信息也是非常重要的。
4.3.2 脚本事件预测
我们在MCNC数据集上进行了实验,相关基线方法如下:
(1) Word2Vec[45]在大规模的数据集上学习到了词向量表示,上下文事件中动词及其他元素的向量被用来与候选事件中的元素计算相似度,通过相似度的值进行预测。
(2) EventComp[32]使用了一个孪生神经网络计算事件之间的相似度。
(3) PairLSTM[33]将事件的序列信息以及事件对之间的关联信息融合在一起进行后续事件的预测。
(4) SGNN[35]构建了一个叙事事件演化图谱,即事理图谱,对事件之间的邻接关系进行表示,并提出了一个缩放的图神经网络对后续事件进行预测。
(5) SAN-Net[36]使用事件级的注意力机制来显式地建模图结构的事件关系,最后通过一个事件链级的注意力机制来进行预测。
(6) BERT-base[1]使用预训练语言模型在MCNC数据集上进行微调。
(7) ERNIE[18]使用知识图谱嵌入方法TransE[19]将知识图谱中的图结构进行编码,将实体的嵌入当作他们模型的输入。
(8) GraphTransformer[22]在知识图谱中检索结构化的信息并在他们基于Transformer的模型顶端引入了一个额外的图编码器,利用检索到的结构化信息来指导文本生成。
所有的实验结果如表3所示,根据实验结果,我们能得到如下结论:
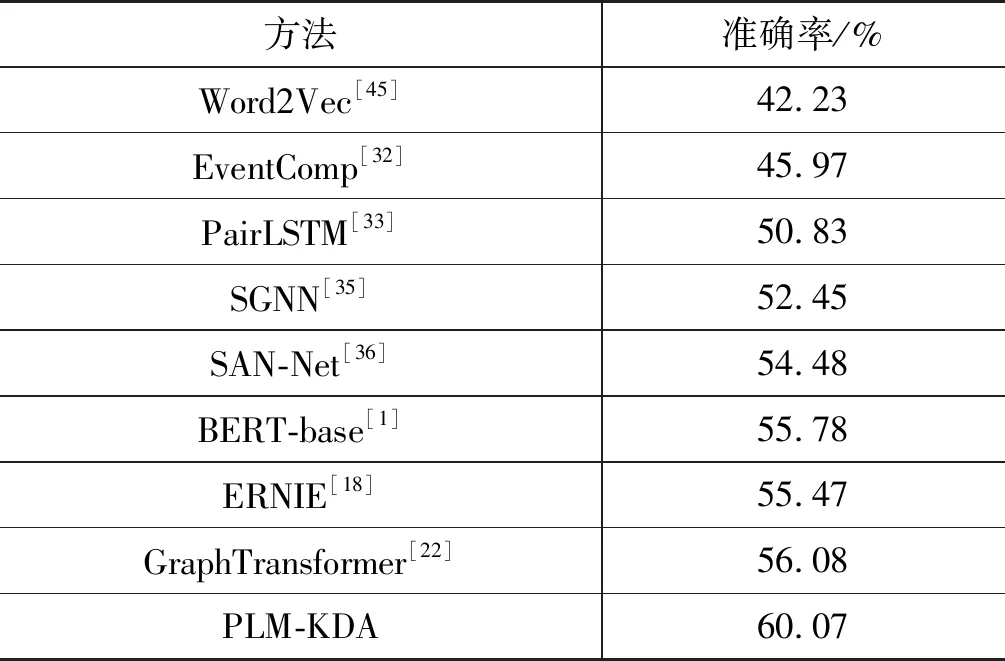
表3 脚本事件预测实验结果
(1 )与基于事件对(链)的方法(EventComp及PairLSTM)对比,基于事件图的方法(SGNN,SAM-Net,ERNIE,GraphTransformer及PLM-KDA)拥有更好的性能,表明图结构能够更好地理解事件关系。
(2) 与无预训练语言模型的方法(EventComp,PairLSTM,SGNN及SAN-Net)对比,使用了预训练语言模型的方法(ERNIE,GraphTransformer,BERT-base及PLM-KDA)在性能上有较大提升,表明预训练语言模型能够更好地理解事件来帮助后续事件的预测。
(3) 与BERT相比,有图结构信息增强的模型(GraphTransformer及PLM-KDA)能够更进一步地提升脚本事件预测的性能,这是因为引入图结构信息能够更好地理解事件之间的关系,并给预测过程提供指导。
(4) 与ERNIE及GraphTransformer对比,PLM-KDA将图结构知识进行深层的编码,对图结构信息的融入更高效。
5 结论
本文提出了一个基于预训练语言模型的知识深度融合框架以进行文本推理任务,实验证明预训练语言模型中丰富的语言学知识能很好地理解文本。由于机器进行文本推理还需要额外的外部知识进行辅助,我们基于此使用了知识图谱和事理图谱对预训练语言模型进行增强,并且我们在中间层进行知识融入,将预训练语言模型与丰富的知识进行深层次的融合。实验结果表明,我们的PLM-KDA框架对比于无预训练语言模型的方法有着很大的优势,对比于无知识融入的方法也有着较大的优势,并且我们通过改变知识融入的位置,使得丰富的知识和预训练语言模型融合更加有效。
