基于改进动态时间弯曲的PMU 频率异常检测及类型识别
2022-02-02黄子蒙向明旭张江南李文沅
黄子蒙,余 娟,向明旭,张江南,李文沅
(1. 输配电装备及系统安全与新技术国家重点实验室(重庆大学),重庆市 400044;2. 国网河南省电力公司电力科学研究院,河南省郑州市 450052)
0 引言
随着中国“双碳”目标的提出[1],可再生能源在电力系统中的接入比例将逐年提高,电力系统不确定性、复杂性和脆弱性问题也将日益凸显[2],为电网安全稳定运行带来重大挑战。在此背景下,电网运行数据实时监测分析愈发重要。同步相量测量单元(PMU)具有高分辨率、高精度及时钟同步等优势[3-5],以此为基础的广域测量系统(WAMS)是实现电力系统动态安全监控的有效手段。
然而,由于数据通道受到传感器误差、WAMS组件故障等因素影响,PMU 量测数据存在不同程度的质量问题,表现为恒定偏差、时延等异常[6]。据统计,中国约有20%~30%的PMU 数据存在质量问题[7],导致系统可观性降低,威胁到电网安全稳定运行[8]。为此,亟须研究PMU 异常数据的分析检测方法。数据驱动方法因不依赖于准确的系统拓扑和参数,日益受到国内外学者关注。现有数据驱动方法大致可分为以下3 类。第1 类方法基于逻辑判断,若量测数据超出阈值,则判定为异常数据[9-10]。第2 类方法基于机器学习,通过已标注的异常数据集训练机器学习模型,实现异常数据检测[11-12]。但因实际电力系统动态过程复杂多样,第2 类方法存在适应性不足、带标注数据获取困难等问题。第3 类方法根据系统各节点正常PMU 量测数据在相同系统动态下的趋势相似性来进行异常数据检测,可避免系统正常扰动数据的干扰[7,13-15]。其中,动态时间弯曲(DTW)[16]因具有良好的序列形态度量效果,被用于度量各PMU 测点数据间的相似性[15]。然而,常规DTW 存在以下不足[17]:1)DTW 的时间复杂度为两个时间序列长度的乘积,因而在面对大规模、高分辨率的PMU 数据时将付出高昂的计算代价;2)由于DTW 仅追求动态弯曲距离最小,因而易出现过度弯曲现象,无法准确选择最优弯曲路径进行相似性度量。提取趋势特征后,现有文献大多利用局部离群因子法(LOF)[7,13-15,18]等无监督算法识别趋势特征数据集中的离群点,进而实现异常测点数据检测。然而,现有方法仅通过提取单一特征来进行异常检测,无法区分不同类型异常数据所表现出的不同特征,进而无法实现异常类型的识别。而结合实际工程经验,异常类型的识别将有助于PMU 数据通道的问题检测和消缺处理。对此,本文将以PMU频率量测数据为切入点,结合PMU 频率数据的特点,提出一种数据驱动的PMU 频率数据异常检测及类型识别方法。
本文提出适应于时延、偏置等多种频率数据异常类型的异常检测及类型识别方法。基于频率数据典型异常类型及特点,从多个维度构造与各类典型异常类型相匹配的异常特征;并通过DTW 改进策略及LOF 来量化检测各类异常特征的离群情况,进而实现异常检测及类型识别。本文提出DTW 弯曲窗口动态调整策略,针对常规DTW 时间复杂度高、易出现过度弯曲等问题,基于迭代搜索的时延信息动态调整弯曲窗口范围,对最优弯曲路径进行合理约束,保证异常特征的快速准确量化。
1 PMU 频率数据异常类型分析及其特征
1.1 PMU 频率数据的典型异常类型
由于电力系统时刻处在源荷不平衡的调整过程中,导致正常运行时频率在额定值(50 Hz)附近不断变化,因此仅凭单一PMU 测点的量测频率数值难以判断其是否存在异常。而考虑到PMU 采样数据的时间同步性,本文选取某经检测无误的PMU 测点作为参考测点,并与其余PMU 测点的频率数据对比,以判别数据异常情况。
系统各节点频率虽然在系统动态过程中存在些许不一致,但由于区域电网以交流同步机制运行,而频率响应统一性是交流同步电网的本质属性,因而在系统不发生功角失稳的情况下,系统各处的频率变化趋势相似[19-20]。基于区域电网这一频率响应特点,对2021 年在中国某省WAMS 中获取的PMU 频率数据进行统计分析,发现部分PMU 测点的频率数据存在异常。本文从中归纳了5 种典型异常类型,各异常类型的特点描述及示例分别如附录A 表A1 和 图A1 所 示。
1.2 频率数据异常特征构造
为了从大规模、高分辨率的PMU 频率数据中准确辨识1.1 节所述的异常类型,针对性地构造以下各类异常特征,以表征测点数据中关键的异常信息。
1)相似特征fCOR:用以表征“无法跟随”异常信息。相似特征通过测点与参考测点频率序列数据间的距离进行量化,有

3)偏置特征fDEV:用以表征“整体偏高/偏低”异常信息。偏置特征通过测点和参考测点频率序列数据差值的均值进行量化,具体如式(3)所示。此特征值的正/负情况表示测点频率序列相对参考测点存在的正/负偏差,有
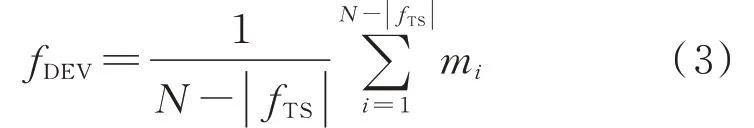
式中:N为测点和参考测点频率序列数据的长度;mi为测点和参考测点频率序列数据的差值序列M中的第i个元素,0 ≤i≤N-|fTS|。其中,为了消除可能存在的fTS干扰,需要经过式(4)的处理,得到合理的mi。

2 基于DTW 弯曲窗口动态调整的异常特征量化策略
2.1 基于常规DTW 的特征量化技术
为实现相似特征fCOR的量化,需计算频率序列R、E间的距离。常用的欧氏距离(ED)算法因其只能够实现序列数据间的同步匹配,所以根据距离计算结果难以区分“存在时延”异常类型和“无法跟随”异常类型。而DTW 在面对存在滞后/超前关系的时间序列对时,可以通过序列数据间的弯曲匹配来计算序列间的距离,具有更好的序列形态度量效果。因此,本文采用DTW 进行fCOR的量化。
将参考测点和测点的频率序列数据分别表示 为:R= {r1,r2,…,ri,…,rN}、E= {e1,e2,…,ej,…,eN},其中,i、j表示序列中的数据点序号。fCOR的量化过程如下:
1)计算序列R、E中各元素间的ED,构成距离矩阵DN×N,其中,距离矩阵中的各元素数值由式(6)计算得到:
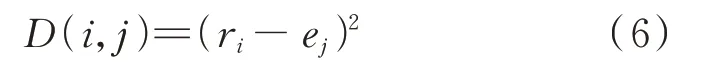
式中:ri为序列R中第i个数据点的频率值;ej为序列E中第j个数据点的频率值。
2)在满足边界性、连续性和单调性约束[16]的情况下,在距离矩阵DN×N中基于动态规划思想搜索一条最优弯曲路径(如图1 的阴影部分所示),使得路径经过的距离矩阵元素累加和最小。由此计算得到动态弯曲距离DTW(R,E),完成相似特征fCOR的量化,如式(7)所示。
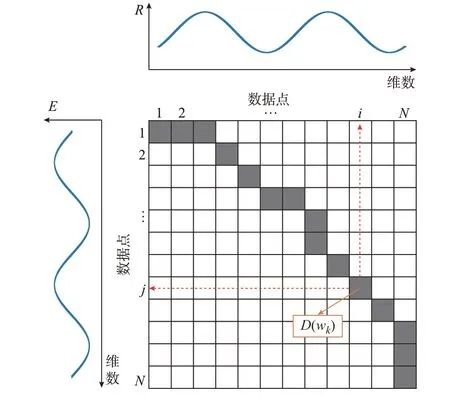
图1 DTW 最优弯曲路径示意图Fig.1 Schematic diagram of DTW optimal warping path
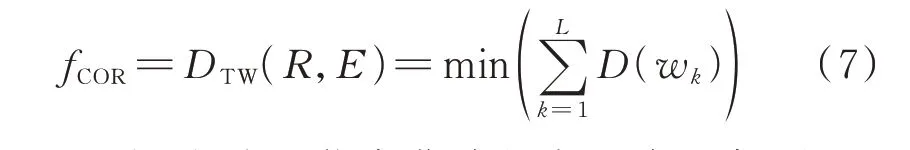
式中:wk=(i,j)k为最优弯曲路径中矩阵元素k的坐标,表示ri与ej进行弯曲匹配;D(wk)为距离矩阵元素k的数值;L为最优弯曲路径的长度,且须满足N≤L≤2N-1。
R、E序列数据间的弯曲匹配情况如图2 所示。可以看到,当序列间存在时延fTS时,DTW 为了追求式(7)目标最小,将尽可能使序列中的ri和ej(j=i+fTS)弯曲匹配在一起,以使两个时间序列的波峰和波谷分别匹配对应。因此,最优弯曲路径中距离矩阵元素的坐标wk=(i,j)k可以反映序列间的时延信息。
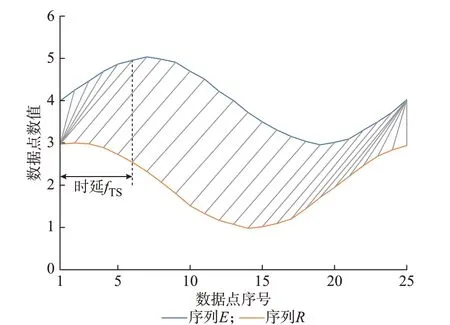
图2 R、E 序列数据间的弯曲匹配情况Fig.2 Warping matching between R and E sequential data
然而,现有DTW 方法尚未实现时延的量化计算。对此,本文提出了一种时延计算方法,具体过程如下。
1)计算最优弯曲路径中距离矩阵元素的坐标差值,如式(8)所示。
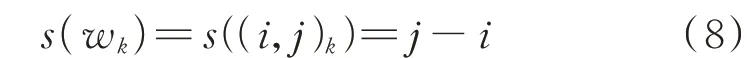
2)统计最优弯曲路径中坐标差值出现的次数,由此构成坐标差值的分布情况(sp,Nsp),其中,sp为各坐标差值构成的向量;Nsp为各坐标差值统计次数构成的向量。
3)通过式(9)计算测点频率数据的时延,并将其作为时延特征fTS量化的依据:
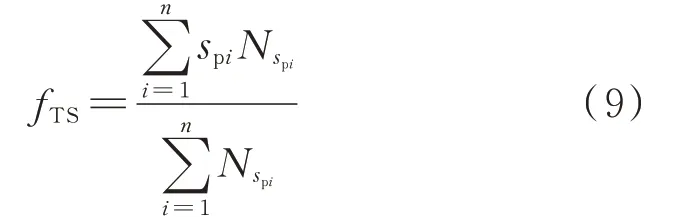
式中:spi、Nspi分别为(sp,Nsp)中第i个坐标差值及其统计次数;n为向量sp长度。
通过式(8)和式(9)即可量化时延特征fTS,进一步又可由式(3)至式(5)量化偏置特征fDEV和波动特征fVOL。至此,即基于DTW 实现了频率数据各类异常特征的量化工作。
由式(3)至式(5)可知,fDEV和fVOL量化的准确性取决于fTS量化的准确性,而fCOR和fTS的量化均取决于DTW 输出的最优弯曲路径。然而,常规DTW 方法在搜索最优弯曲路径过程中存在以下不足。
1)DTW 搜索过程中易出现过度弯曲现象。由于DTW 仅追求式(7)所示目标DTW(R,E)数值最小,因而可能出现过度弯曲现象,即一个时间序列中的一个数据点错误匹配到另一个时间序列中一大块区域的数据点[17]。常规DTW 计算结果如附录A 图A2 所示,序列R、E间无时延,而图A2(a)显示序列R、E间却出现了过度弯曲现象。进一步由图A2(b)所示,最优弯曲路径中出现了较大的错误坐标差值,从而将影响最优弯曲路径的准确性。
2)DTW 的时间复杂度高。为了得到最优弯曲路径,DTW 将遍历DN×N中所有的矩阵元素,因而DTW 的时间复杂度T如式(10)所示。
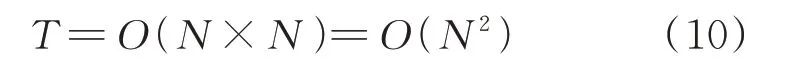
式中:O( ⋅)为时间复杂度计算函数。
对于采样率为20 ms 的PMU 测点,5 min 时间尺度的频率序列数据长度N可达到15 000,由式(10)可知DTW 将面临高昂的计算时间代价。
2.2 DTW 弯曲窗口动态调整策略
针对常规DTW 量化特征时存在的过度弯曲和时间复杂度高的问题,进一步引入Sakoe-Chiba 窗口[21]约束最优弯曲路径的弯曲范围,以改善DTW量化的效率和准确性。
Sakoe-Chiba 窗口利用宽度参数r形成对称型的弯曲窗口,如附录A 图A3 所示。此时仅有弯曲窗口内的元素(i,j)需参与DTW 计算,因而大大降低了DTW 的时间复杂度,其中i、j满足式(11)。

同时,联立式(8)和式(11)可知,最优弯曲路径中矩阵元素坐标差s(wk)的绝对值不能超过设定的弯曲窗口宽度r。进而,若r设置合理,则可以避免最优弯曲路径中矩阵元素的坐标差值过大,即抑制过度弯曲现象。
窗口宽度r越小,则对过度弯曲现象的抑制程度越高。然而,窗口宽度r并非越小越合理。根据2.1 节所述,fTS通过最优弯曲路径计算得到。若设置的r比序列间的真实时延小,将导致最优弯曲路径中矩阵元素的坐标差偏小,进而导致量化的fTS偏小。此时,为了追求式(7)所述目标最小,DTW 将尽可能使序列中的ri和ej=i+r弯曲匹配在一起,因而经式(9)计算得到的fTS绝对值将接近于窗口宽度r。
综上所述,弯曲窗口宽度r的合理设置是Sakoe-Chiba 窗口约束的关键所在。但在DTW 计算前,测点频率数据的时延信息未知,进而难以合理设置窗口宽度r对弯曲路径进行约束。对此,本文提出一种DTW 弯曲窗口动态调整策略,以实现弯曲窗口宽度r的合理设定。该策略的流程如图3 所示,其具体步骤如下:
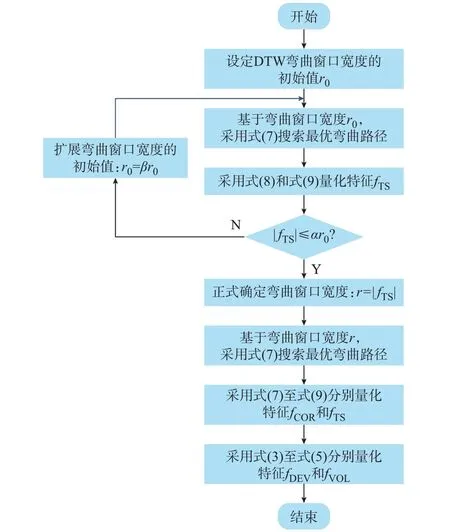
图3 DTW 弯曲窗口动态调整策略流程图Fig.3 Flow chart of dynamic adjustment strategy for DTW warping window
1)设定DTW 弯曲窗口宽度的初始值r0,其取值范围为[0,N]。
2)基于弯曲窗口宽度r0,采用式(7)搜索最优弯曲路径,并根据搜索的最优弯曲路径,采用式(8)和式(9)量化时延特征fTS。
3)对fTS绝对值与r0进行如式(12)的判别:

式中:α为|fTS|与r0的贴合系数,其取值范围为[0,1]。
4)当fTS不满足式(12)时,则r0设置不合理,将按照式(13)对r0进行扩展,并重复步骤2)到4),直至满足式(12)的判别。

式中:β为r0的扩展系数,其取值范围为(1,N/r0]。
5)当fTS满足式(12)时,则r0设置合理,进一步将计算的| |fTS设为弯曲窗口宽度的确定值r,并基于弯曲窗口宽度r,采用式(7)再次搜索最优弯曲路径。
6)根据最终搜索得到的最优弯曲路径,采用式(7)至式(9)分别量化相似特征fCOR和时延特征fTS;进一步采用式(3)至式(5)分别量化偏置特征fDEV和波动特征fVOL。
基于上述策略,在量化特征fCOR和fTS时,只需要计算DN×N中弯曲窗口范围内的矩阵元素即可(如附录A 图A3 的阴影部分所示),其时间复杂度Tcor如式(14)所示。
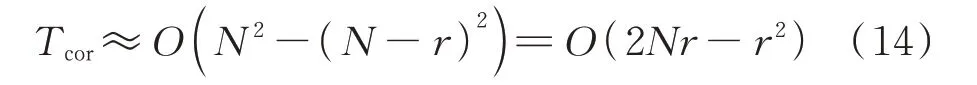
考虑到工程实际中已发现的时延数量级为10~102个数据点,设定合理的弯曲窗口宽度r将具有相同的数量级,而5 min 时间尺度的频率序列数据长度N可达到104数量级。因而,弯曲窗口宽度r满足:r≪N。进而对比式(10)和式(14)可知:

因此,相较于常规DTW,本文所提DTW 弯曲窗口动态调整策略可显著降低DTW 量化异常特征的时间复杂度。
3 基于LOF 的PMU 频率数据异常检测及类型识别策略
3.1 基于LOF 的异常检测及类型识别策略
LOF 是一种基于密度的无监督异常检测算法,其通过计算对比数据集中样本点与邻近样本点的密度,量化判断样本点是否为异常离群点[18]。LOF 的输入信息为数据集D,输出信息为D中各样本点px的局部离群因子YLOF,x,其计算如式(16)所示[15]。

式中:LOF( ⋅)为LOF 计算函数[18];YLOF为各YLOF,x构成的向量。
在检测中,YLOF,x超过LOF 所设阈值的样本点将被认定为离群点。为实现PMU 异常数据检测,现有文献通常将从测点数据中提取的单一特征作为样本点[7,13-15],并将该单一特征数据集作为LOF 的输入信息以进行离群点检测,离群点数据将被判断为异常数据。然而,仅通过单一特征判断离群点将无法区分不同异常类型所表现出的不同特征,进而无法实现异常类型的识别。因此,为了实现频率数据异常检测及类型识别,本文基于DTW 弯曲窗口动态调整策略量化所有测点的各类异常特征,构成各异常特征数据集,并作为LOF 的输入信息。以相似特征fCOR为例,异常特征数据集DCOR的构成如式(17)所示。
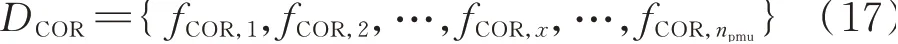
式中:fCOR,x为第x个测点的相似特征fCOR;npmu为测点数量。其余异常特征数据集DTS、DDEV、DVOL构成方法同式(17)。
LOF 算法将分别检测各异常特征数据集的离群情况。进而,结合1.2 节所述各异常特征代表的异常信息,将离群点分别判断为相应的异常类型。
3.2 基于DTW 改进策略的PMU 频率数据异常检测及类型识别流程
本文所提适应于时延、偏置等多种异常类型的异常检测及类型识别方法具体步骤如下。
1)PMU 频率数据准备:通过WAMS 获取PMU参考测点和各个测点的频率序列数据R、Ex。
2)基于DTW 弯曲窗口动态调整策略的异常特征量化:
(1)动态调整DTW 弯曲窗口:采用2.2 节所述的DTW 弯曲窗口动态调整策略为每个测点确定一个合理的DTW 弯曲窗口宽度rx。
(2)基于弯曲窗口的异常特征量化:各测点基于相应的弯曲窗口宽度rx,采用2.1 节中式(7)至式(9)所述的DTW 量化方法,量化频率序列数据Ex的相似特征fCOR,x和时延特征fTS,x;进一步,采用式(3)至式(5)量化偏置特征fDEV,x和波动特征fVOL,x。
3)基于LOF 的数据异常检测及类型识别:
(1)构成异常特征数据集:根据步骤2)各测点数据的异常特征量化结果,由式(17)构成异常特征数据集DCOR、DTS、DDEV、DVOL。
(2)基于LOF 的异常检测及类型识别:将各异常特征数据集分别输入式(16)所示的LOF 算法中进行异常检测及类型识别。
4 算例分析
4.1 算例说明
为验证所提方法的有效性,本文选取2021 年中国某省WAMS 中162 个PMU 测点的频率数据作为检测对象,涵盖在输电网和电厂(含新能源场站)中部署的PMU 测点,涉及的电压等级有35、110、220、500、1 000、±800 kV。本文所有算例均在3.59 GHz CPU AMD Ryzen 5 3500X、16 GB RAM 的硬件环境下进行测试。
本文将对比以下3 种方法:
方法1(M1):本文所提异常检测及类型识别方法,其中DTW 弯曲窗口动态调整策略的r0为100、α为0.8、β为2。
方法2(M2):与M1 相同,但在异常特征量化过程中未采用本文所提DTW 弯曲窗口动态调整策略。
方法3(M3):文献[15]所提异常检测方法。
4.2 DTW 弯曲窗口动态调整策略的有效性验证
下面将从DTW 的时间复杂度和特征量化准确性两方面分析本文所提DTW 弯曲窗口动态调整策略的有效性。由于M2 和M3 在异常特征量化过程中均未采用DTW 弯曲窗口动态调整策略,此处选取M2 与M1 进行效果对比。
1)时间复杂度分析
此处将以测点异常特征的量化时间反映DTW的时间复杂度。M2 量化测点异常特征的平均计算时间为625.51 s;而M1 仅需13.45 s,计算速度较M2提高45 倍以上。由此可知,采用本文所提DTW 弯曲窗口动态调整策略对路径的弯曲范围进行约束,可显著降低时间复杂度。
2)特征量化准确性分析
根据2.1 节所述,时延特征fTS是各特征量化过程中的关键所在,因此,将着重关注fTS的量化情况。由于无法知晓测点和参考测点频率数据间的实际时延,本文将借助ED 评估fTS量化的准确性。同时,为了消除频率序列数据可能存在的恒定偏差干扰,对测点和参考测点频率数据均进行了归一化处理,将序列中的频率值映射到[0,1]。若fTS量化准确,则根据fTS校正PMU 数据的时标后,测点与参考测点频率数据间将具有较高的相似程度。序列间的相似程度越高,则ED 计算值越小。
此处首先对某一测点频率数据进行分析。M1和M2 量 化 得 到 的 时 延fTS,M1、fTS,M2分 别 为96 和5。根据fTS,M1、fTS,M2校正时标后,该测点的ED 计算值分别为3.15、5.64,从而可知M1 量化的fTS,M1更为准确。进一步,附录A 图A4 展示了根据fTS,M1、fTS,M2校正时标后,该测点与参考测点的局部频率序列数据对比情况。由图A4 可知,根据fTS,M1校正时标后,该测点与参考测点的频率数据更为相似。
为进一步验证M1 在特征量化准确性方面的有效性,采用M1 和M2 对162 个PMU 测点频率数据进行了测试。采用M2 的ED 平均计算值为4.65,而采用M1 的ED 平均计算值仅为4.55。相比于M2 而言,根据M1 量化的fTS校正时标后,各测点的平均ED 下降了2%,从而表明采用M1 量化的fTS更为准确。
综上所述,采用本文所提的DTW 弯曲窗口动态调整策略后,DTW 的时间复杂度和特征量化准确性均有所改善,可以有效保证异常特征量化的效率和准确性。
4.3 PMU 频率数据异常检测及类型识别方法的有效性验证
通过对比M1 和M3 对于162 个PMU 测点频率数据的异常辨识效果,来验证所提方法M1 在异常检测及类型识别方面的有效性。
采用M1 对4 个异常特征数据集中LOF 计算结果如图4 所示,偏置特征fDEV的分布情况如图5 所示。进一步,将结合图4(c)所示的异常检测结果和图5 所示的fDEV数值正负情况,区分“整体偏高”和“整体偏低”异常类型。表1 展示了M1 所辨识出的数据异常测点,以及经专家确认存在频率数据异常的PMU 测点。由表1 可知:M1 可以检测出所有数据异常测点,并实现数据异常类型识别。
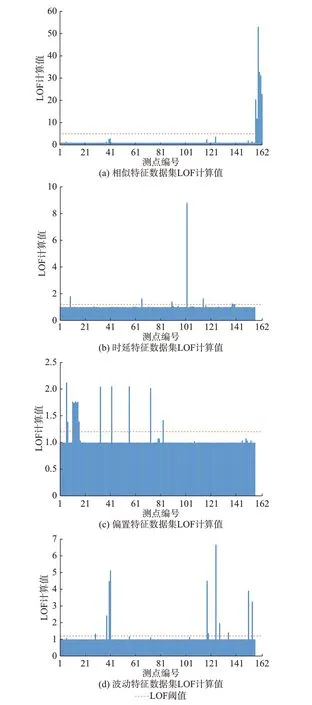
图4 基于M1 的异常特征数据集中LOF 计算结果Fig.4 LOF calculation results in abnormal characteristic datasets based on M1
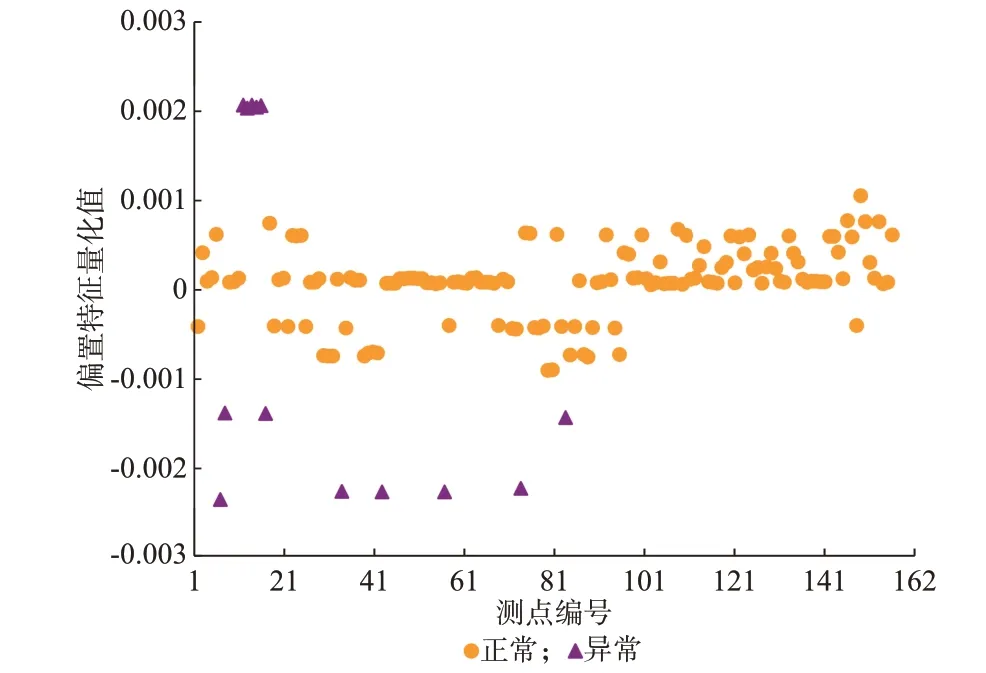
图5 M1 量化的偏置特征fDEV数值分布Fig.5 Numerical distribution of bias characteristic fDEV quantized by M1
基于M3 的LOF 计算结果如图6 所示。对比表1 可知,M3 仅检测出了部分数据异常测点,具体测点编号 为:29、38、40、41、102、118、125、128、151、154、157~162。而且通过M3 的LOF 计算情况,无法分辨测点的数据异常类型。进而,表2 对M1 和M3 的异常数据辨识能力进行了归纳。

表2 M1 和M3 的异常辨识能力对比Table 2 Comparison of anomaly identification capabilities of M1 and M3
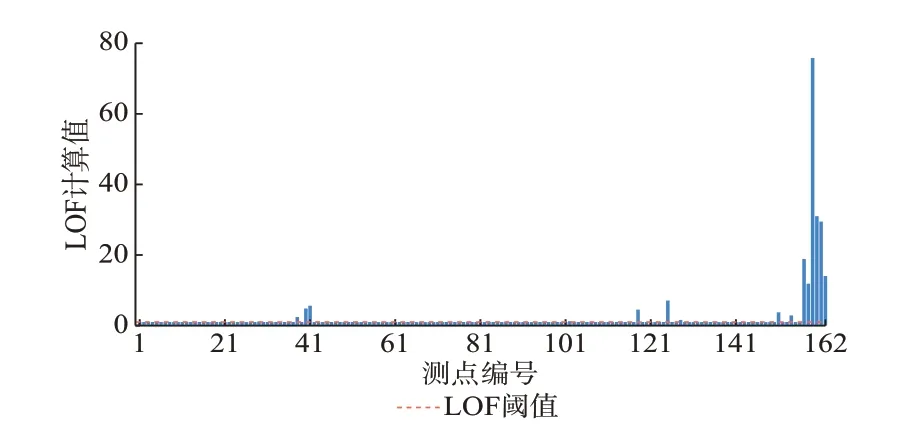
图6 基于M3 的LOF 计算结果Fig.6 LOF calculation result based on M3
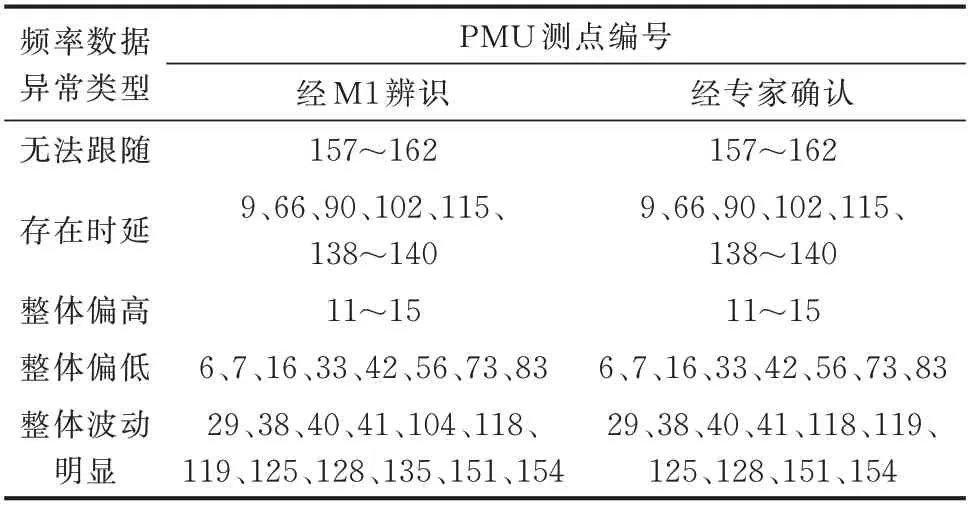
表1 PMU 异常测点编号及M1 的异常辨识结果Table 1 PMU abnormal measuring point number and anomaly identification results of M1
为了直观展示M1 的有效性,采用准确率和召回率[22]对M1 和M3 的辨识结果进行评价。其中,准确率表示辨识出的真实异常测点数占辨识出的总测点数的比例;召回率表示辨识出的真实异常测点数占总真实异常测点数的比例。
由于M3 无法识别异常数据的类型,故只对比了M1 和M3 的总体异常检测情况,没有区分各类数据异常的检测情况,如表3 所示。为进一步验证所提方法在异常类型识别方面的有效性,表4 展示了M1 针对各类典型频率数据异常的辨识情况。由表3 可知,M1 的总体异常检测召回率优于M3,其原因为:M3 仅从相似性这一维度提取测点时间序列数据的特征信息,无法精细化地考虑测点时间序列数据中其他特征维度的异常信息,进而导致部分类型的异常测点数据与正常测点数据难以区分开来。虽然M1 的总体异常检测准确率略低于M3,但可以通过后续巡检环节排除少量不存在数据异常的PMU测点。同时,在应用于实际电网时,为了避免因漏检导致PMU 频率数据存在质量问题,进而影响到后续的高级应用分析,异常检测召回率相比于准确率更为重要。因此,总体而言,M1 的辨识性能优于M3。此外,由表4 可知,M1 针对各类数据异常的召回率均达到了100%,即没有出现漏检现象。虽然针对“整体波动明显”异常类型的检测准确率略微偏低,但如前所述,这一准确率是可接受的。
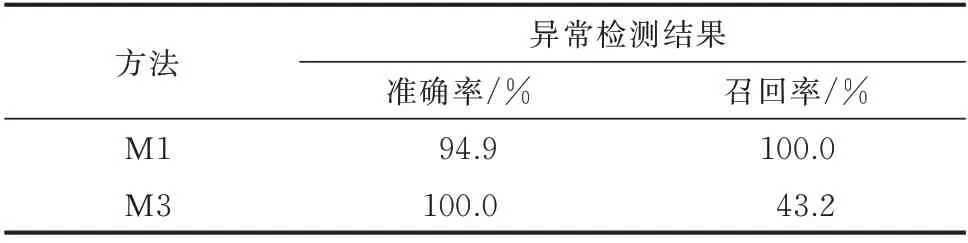
表3 M1 和M3 的总体异常检测结果对比Table 3 Comparison of overall anomaly detection results between M1 and M3
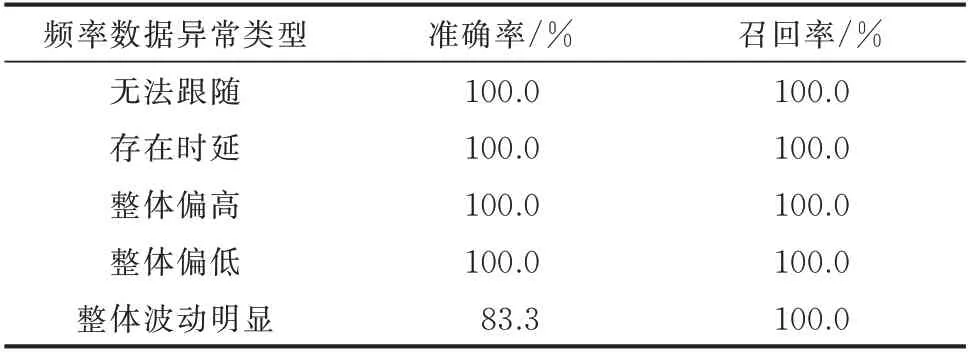
表4 M1 辨识各类异常数据的准确率和召回率Table 4 Precision and recall rate of identifying various abnormal data based on M1
综上所述,本文所提方法有助于减少巡检所耗费的人力物力。PMU 测点数量众多、位置分散,传统依次巡检每个测点的方式需要耗费大量的人力物力。本文所提方法仅需通过WAMS 主站数据便可对各PMU 测点进行异常辨识,从而指导巡检人员有针对性地开展现场问题分析。
此外,所提方法仅根据各节点PMU 量测频率数据的变化趋势相似性来进行异常检测及类型识别,与输电网类似,配电网中各节点的频率变化趋势均相似,故所提方法同样适用于配电网PMU 频率数据的异常辨识。同时,因本文所提方法无须利用PMU 数据通道的相关信息,故PMU 数据通道的差异性不会影响本文所提方法的辨识效果。因此,所提方法具有应用于实际电网的可行性和实用性。
5 结语
高质量的PMU 量测数据在电网动态安全监测、电网事件分析等方面发挥重要作用。然而,PMU 量测数据受到各类因素影响,存在不同程度的质量问题。为此,本文提出PMU 异常数据的高效辨识方法,主要结论如下:
1)本文所提适应于时延、偏置等多种异常类型的异常检测及类型识别方法,能够基于DTW 改进策略量化表征频率数据异常信息的特征,进而利用LOF 检测异常特征的离群情况,能够实现各类典型异常频率数据的检测及类型识别。基于中国某省级电网实际数据的算例分析验证了所提方法有效性。
2)本文所提DTW 弯曲窗口动态调整策略,能够动态调整DTW 的弯曲窗口以对最优弯曲路径进行合理约束,有效改善了常规DTW 存在的时间复杂度高和过度弯曲问题。
系统各节点频率一般均围绕额定值50 Hz 变化,基于此性质,本文所述方法可以检测频率数据中存在的长时间尺度偏置异常(如互感器造成的系统性误差异常)。然而,由于系统拓扑结构等原因,即便PMU 测点数据量测无误,系统各节点间的电压、相角等量测量仍存在长时间尺度的固定差异,这一固定差异与偏置异常难以区分,加剧了偏置异常的辨识难度。因而,如何将本文所提方法扩展应用到其他类型的PMU 数据异常辨识将是本文后续重要的研究方向之一。
附录见本刊网络版(http://www.aeps-info.com/aeps/ch/index.aspx),扫英文摘要后二维码可以阅读网络全文。
