用于自动驾驶仿真测试的车—车事故场景复杂度评价
2022-02-01李平飞金思雨胡文浩车瑶栎谭正平董小飞
李平飞,金思雨,胡文浩,高 立,车瑶栎,谭正平,董小飞
(1.西华大学 汽车与交通学院,成都 610039,中国;2.四川西华交通司法鉴定中心,成都 610039,中国;3.国家市场监督管理总局缺陷产品管理中心,北京 100191,中国;4.上海机动车检测认证技术研究中心有限公司,上海 201805,中国)
自动驾驶汽车需要大量的测试[1]来证明其各项功能及其性能可靠性、稳定性等。基于场景的测试方法[2]凭借应用方式灵活、针对性强、可重复性高等优点成为目前自动驾驶汽车主要的测试方法之一。与自然驾驶场景不同,事故场景更易提取危险工况,以测试自动驾驶汽车应对危险的能力。目前事故场景的研究多集中于事故场景再现分析[3-5]及典型场景的提取与构建[6-9],有关场景综合评价的研究较少。其中对场景进行复杂度评价,可为自动驾驶仿真测试场景提取、筛选等技术难点提供解决思路,提升测试效率。
在场景复杂度理论研究方面,多数学者主要结合驾驶员的生理、心理响应展开研究[10-12]。张海潮[10]通过驾驶员对交通环境的认知负担定义复杂度,提出基于引力模型的道路交通环境复杂度计算方法。毕蕊[11]提出了一种基于脑电特征指标的交通因素复杂度的量化方法。张朋[12]利用人工势场法量化道路动态交通环境复杂度,并研究其与驾驶人的工作负荷、主观复杂度和次任务反应时间之间的关系。此外,也有学者从不同工况对复杂度展开研究。王宇雷等人[13]提出一种面向复杂超车场景的行驶任务复杂度量化评估方法。董汉等[14]提出了一种对危险驾驶工况场景数据采集和复杂度评估的方法。而面向自动驾驶场景的复杂度研究正处于初步阶段,李江坤[15]围绕自动驾驶系统提出一种结合影响传递模型和层次分析法的场景复杂度评价方法,但场景元素对自动驾驶系统的影响还需进一步研究;王荣等[16]采用引力模型和信息熵相结合的方法从静态和动态场景两个方面综合评价自动驾驶场景复杂度。目前的方法均有不同侧重,少有基于事故场景对自动驾驶场景复杂度展开研究。
本文利用车-车事故预碰撞数据,从场景不同维度出发,建立场景复杂度评价模型,实现场景的量化分级,有助于筛选复杂且事故严重程度高的场景,为自动驾驶仿真测试典型场景的选择提供依据。
1 数据来源
本文的道路交通事故数据来源于(中国)国家车辆事故深度调查体系(National Automobile Accident In-Depth Investigation System,NAIS),NAIS 是由国家市场监督管理总局缺陷产品管理中心牵头建立的道路交通事故深度调查体系[17]。NAIS 制定了统一的数据采集标准,在采集点的分布上充分考虑了中国交通地域分布的特点和差异,2011—2020 年期间,NAIS 数据库共采集约5 500 起道路交通事故案例。表1 为NAIS 数据与《中华人民共和国道路交通事故统计年报(2017 年度)》的对比,表中数据为指标水平占全部样本的百分比及相应差值(统计年报占比-NAIS 数据库占比)。

表1 NAIS 数据库与道路交通事故统计年报的对比
结果表明:NAIS 数据库的事故特征与全国道路交通事故统计年报信息较为吻合,整体数据具备一定代表性。从5 500 余起事故案例中初步筛选涉及汽车与汽车碰撞的事故1 702 例,进一步筛选符合标准的数据进行分析,筛选标准如下:
1)事故参与方数目为2;2)参与方类型均为汽车;3)事故信息采集完整,满足场景构建需要。
按照筛选标准,最终有670 个案例符合要求,作为后续研究的原始数据。670 例事故中,死亡案例占比达30.6%,这与NAIS 的采集条件“人员损伤等级不低于AIS3”有关。
2 场景信息提取
2.1 场景维度划分
在自动驾驶领域内,场景被看作是在特定的时间和空间范围内周围环境对行驶车辆产生一定影响的综合反映。驾驶场景的描述包括驾驶人因素、车辆因素、道路因素、环境因素4 个方面[18]。在自动驾驶场景中,驾驶人因素被弱化,结合NAIS 数据库车-车事故信息及相关研究[19],本文将场景信息分为主车信息、目标车信息、道路信息与环境信息4 个维度。
2.2 各维度变量选取
按照场景4 个维度信息,共选取NAIS 数据库中13 项变量。由于在自动驾驶测试场景中默认主车为乘用车(包括轿车、运动型多用途汽车(sport utility vehicle,SUV)、多用途汽车(multi-purpose-vehicles,MPV)、和面包车),因此在主车信息中未考虑车辆类型,各维度具体变量选取情况如图1 所示。13 个变量具体水平如表2 所示,各变量水平来自670 例事故数据。

图1 场景信息
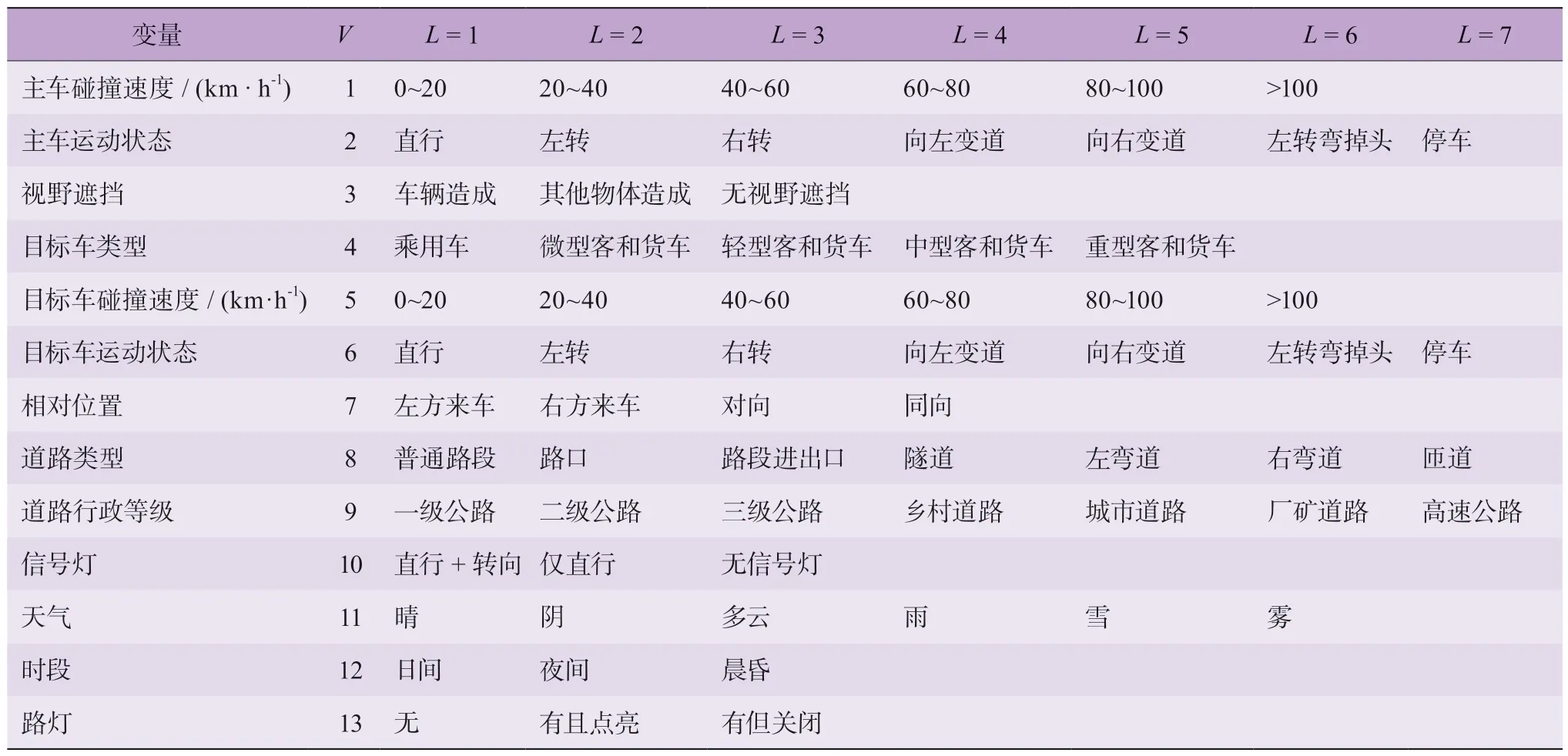
表2 各变量(V)水平(L)及赋值情况
3 场景复杂度评价
3.1 场景复杂度模型
根据信息熵思想,自动驾驶测试场景每个维度蕴含不同的信息量。若某类事故场景发生概率较低,场景库中信息量不足,熵值高,自动驾驶预期功能安全系统对其没有充分的认识和准备,就无法对此进行准确的把握从而无法精准的执行相关避撞措施,事故难以避免,即此类场景对于自动驾驶系统来说可定义为复杂场景;反之即为简单场景。
参考中国汽车技术研究中心提出的关于场景复杂度的概念,借用信息熵理论计算变量下各水平的信息量,即场景各水平的复杂度为[20]

式中:ω为不同场景变量某一水平的权重,c为某变量单个水平复杂度。
场景中每个变量水平对应一个熵值,即复杂度。对于某一具体场景,一个变量仅对应一个具体的水平,即各场景维度下的每个变量均对应一个复杂度,某一维度的复杂度为该维度下所有变量复杂度的加权总和,再对4 个维度的复杂度进行加权求和,得到某一具体场景的整体复杂度为
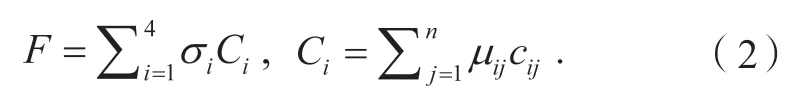
式中:Ci为第i个维度的复杂度,σi为第i个维度的权重系数,i=1,2,3,4;cij为第i个维度下第j个变量的复杂度,μij为第i个维度下第j个变量的权重系数,n为某维度的变量个数。
3.2 逻辑回归确定变量水平复杂度
1)逻辑回归模型及验证。
本文筛选的670 例事故案例中死亡案例为30.6%。由信息熵理论,变量水平权重与场景中指标发生危险事故的概率有紧密联系,利用逻辑回归方式[21]可有效计算事故造成人员死亡的概率,将其概率转换为变量水平权重。本文采用SPSS 软件建立二元逻辑回归模型,将事故是否造成人员死亡作为因变量:1 表示有;2 表示无,自变量为前文从NAIS 数据库中选取的13 项变量,变量水平以数字1~7 赋值,如表2 所示。在二元逻辑回归模型中,造成人员死亡的概率可表示为
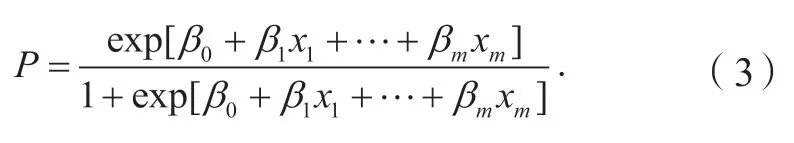
式中:x1、x2、…、xm为选择的影响因素;β0为常数项;β1、β2、…、βm为影响因素x1、x2、…、xm的回归系数,表示自变量与因变量之间的相关性。
由此,造成人员死亡的概率与未造成人员死亡概率的比值,即优势比(odds ratio,OR)为
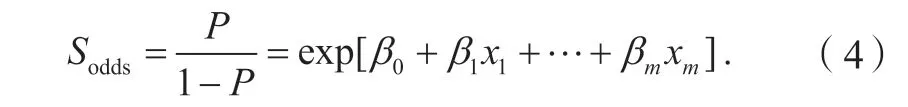
根据模型测试集(由2.2 节变量数据得到)预测概率绘制受试者工作特征(receiver operator characteristic,ROC)曲线,如图2 所示。得到测试集ROC 曲线下的面积(area under curve,AUC)为0.901,预测正确概率为82.8%,模型预测能力较好。Omnibus 检验是模型系数的综合检验,根据表3 显著性小于0.05,表示逻辑回归模型总体有意义,即模型有效。Hosmer Lemeshow 检验是检验模型的拟合优度,显著性大于0.05,可以认为:该逻辑回归模型拟合度较高。
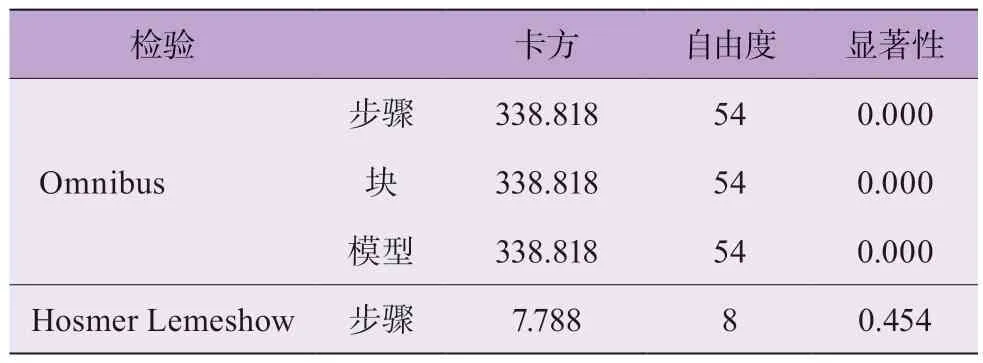
表3 模型的检验

图2 预测模型ROC 曲线
2)水平权重及各水平复杂度确定。
由上述逻辑回归分析模型得到每个变量水平对应的优势比,即得出以每个变量最后一个水平为参考,其余水平发生致死事故的概率,如当主车运动状态为左转,相对于运动状态为停车时发生致死事故的概率为0.254;将每个变量下所有水平的权重值总和设为1,根据OR 值中各水平之间的倍数关系计算每个变量下各水平的权重,即归一化后所得结果,以衡量每个变量水平在该变量下对场景复杂度影响的重要程度。根据式(1),计算得到每个变量各水平的复杂度值,按照表2 定义以V=x(x为变量序数)表示变量,以L=y(y为各变量水平序数)表示水平,如表4 所示。
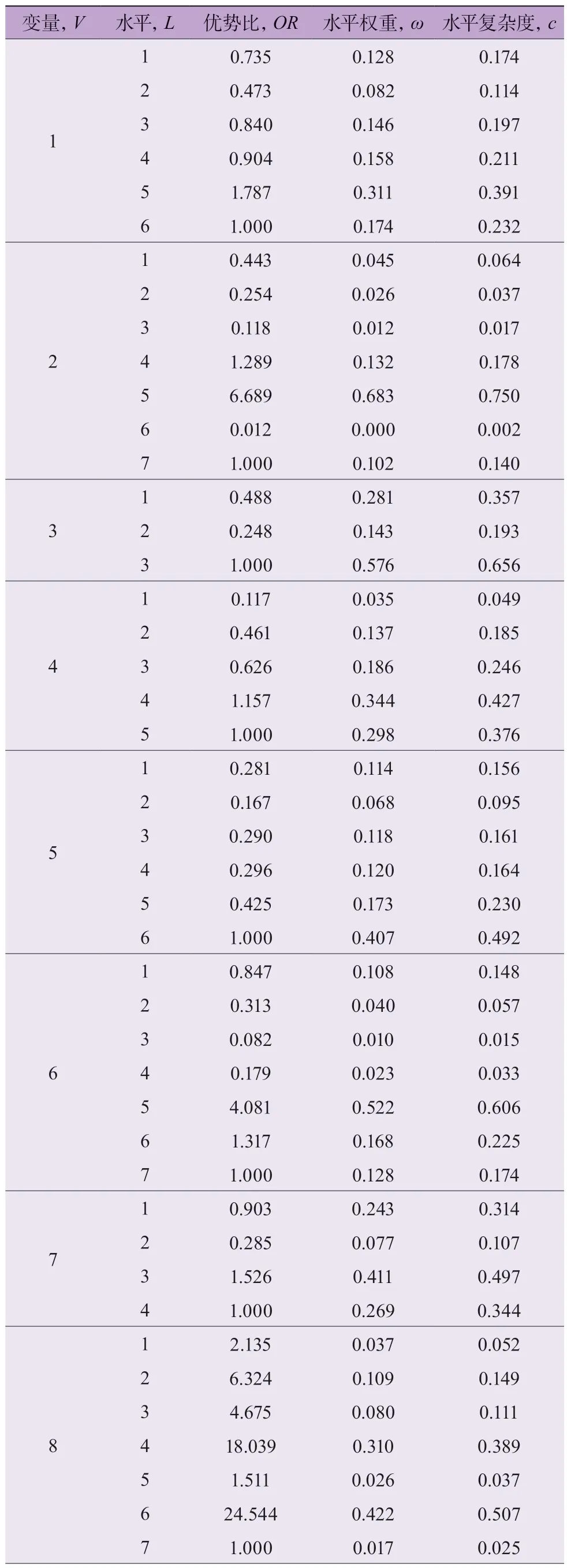
表4 水平权重及各水平复杂度
3.3 BP 神经网络确定各维度及其变量权重
场景中每个维度因素对于场景复杂程度的影响不一致,故不同维度及变量应有不同的权重系数,若仅靠人为决定某个因素对场景的复杂程度的影响程度的大小,忽略了实际案例的客观性将造成主观因素对结果影响过大,故在此需要一种模仿人类思维的深度学习方法对维度权重系数进行计算。选择反向传播(back propagation,BP)神经网络算法[22]可以科学有效地确定每个维度及变量在场景复杂程度中的权重系数。
对670 例车-车碰撞数据进行BP 神经网络训练,BP 神经网络的输入层数据为13 项变量的所有数据,根据数据需要设置隐藏层层数为1,隐藏层中神经单元设置为10 个,输出层为事故是否造成人员死亡的数据,设置一个单元层。选用均方误差(mean square error,MSE)、平均绝对误差(mean absolute error,MAE)和相关系数(R)作为评估模型性能的指标;若这2 个误差值越小、R值越接近于1,则表示模型的准确性越好[23]。模型训练完成后,所得均方误差为0.103 9,平均绝对误差为0.008 6,相关系数R为0.845 6,总体来看,该模型准确性较好。其中得到输入层与隐藏层之间的权值系数ωki,以及隐藏层与输出层之间的权值系数ωjk,将各神经元之间的权值系数转化为各相应权重,再经过权重影响处理后得到各维度下变量权重μ和各维度权重σ,如表5 所示。
3.4 车-车场景复杂度计算及等级划分
根据得到的场景4 个维度及变量的权重和3.1 节场景复杂度的计算公式,最终得到车-车场景复杂度模型为
由这4 个权重系数可知:主车信息和环境信息对场景的复杂度影响比目标车辆信息和道路信息对场景的复杂度影响低。主车作为可控因素各方面性能可以进行调节,也能减轻恶劣天气或照明情况不佳带来的影响,故在场景复杂度中主车信息和环境信息权重不高。道路信息对场景的复杂度影响较大,道路几何结构和道路状况在一定程度上决定了车辆行驶中交通状况的复杂度,若道路几何结构较复杂便会加剧车辆的冲突关系,同理道路行政等级较低也可能伴随路况不佳增加车辆行驶复杂度。而作为场景复杂度中权重最高的目标车辆因素,同时也是自动驾驶预期功能安全主要研究的对象,其不可控也难以精准预测,造成的信息变化对主车产生巨大影响,在场景复杂度评价中起到显著作用。
根据式(5)对本文中670 例车-车事故进行场景复杂度计算,得到每例事故场景复杂度指数,分布如图3所示。
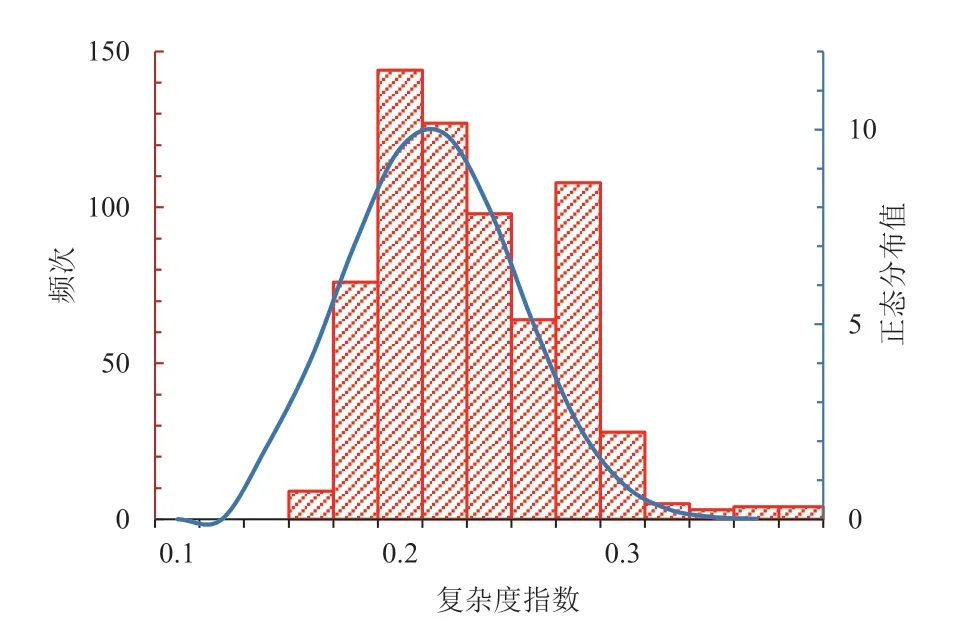
图3 670 例事故场景复杂度指数分布
根据计算结果对复杂度等级进行划分。对场景复杂度进行等级划分时,若使用传统的等量分割人为影响因素过大,且容易忽略数据的聚集性,故本文采用K-means 聚类方法对场景复杂度指数进行聚类分析,将场景复杂度指数作为聚类样本划分数据集,将样本间距离最紧密的数据划分为一个数据集,使多个数据之间形成明显的阈值界限便可得到场景复杂度等级。本文采用常见的“肘部法”来确定聚类个数K,将曲线肘部位置对应的聚类数K确定为最合适的聚类数K(见图4)。由图4 可知:肘部位置处(红点)对应的聚类数K为4 时,聚类效果最好。根据复杂度指数大小将场景复杂等级划分为4 个等级,复杂程度依次递增,并界定其取值范围,如表6 所示。
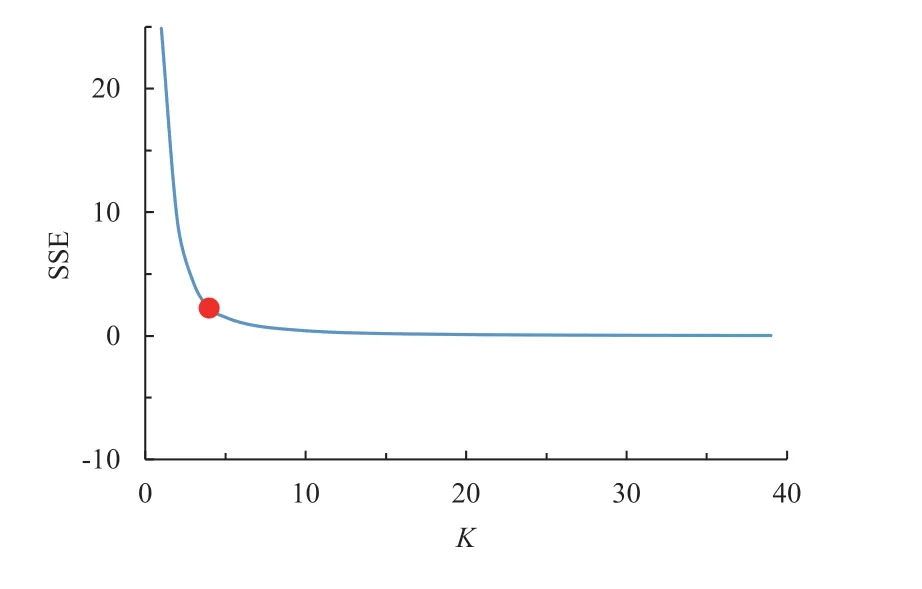
图4 聚类数(K)与误差平方和(SSE)关系图

表6 场景复杂度等级划分
由等级划分结果,场景复杂度指数小于等于0.183的复杂等级为1 级,场景复杂度指数在(0.183,0.227]范围内的复杂等级为2 级,3 级复杂场景的复杂度指数在(0.227,0.290]范围内,复杂等级最高的4 级场景复杂度指数大于0.290。
结合场景复杂度指数分布图及等级划分可以看出,在670 例事故案例中,场景复杂程度较低的1 级和2级所占比例较大(共计71.6%),且占比较接近。随着复杂程度增加,案例占比依次减小,其中复杂程度最高的4 级场景占比最小(1.6%),符合真实交通事故场景分布规律。
3.5 场景特征提取
由场景复杂程度评价结果,按场景复杂等级分别对670 例车—车场景的13 项变量数据进行统计,以具有明显占比优势的变量水平作为场景特征,各等级场景主要特征占比如表7 所示,其中“其他”为单个变量其余水平占比总和。
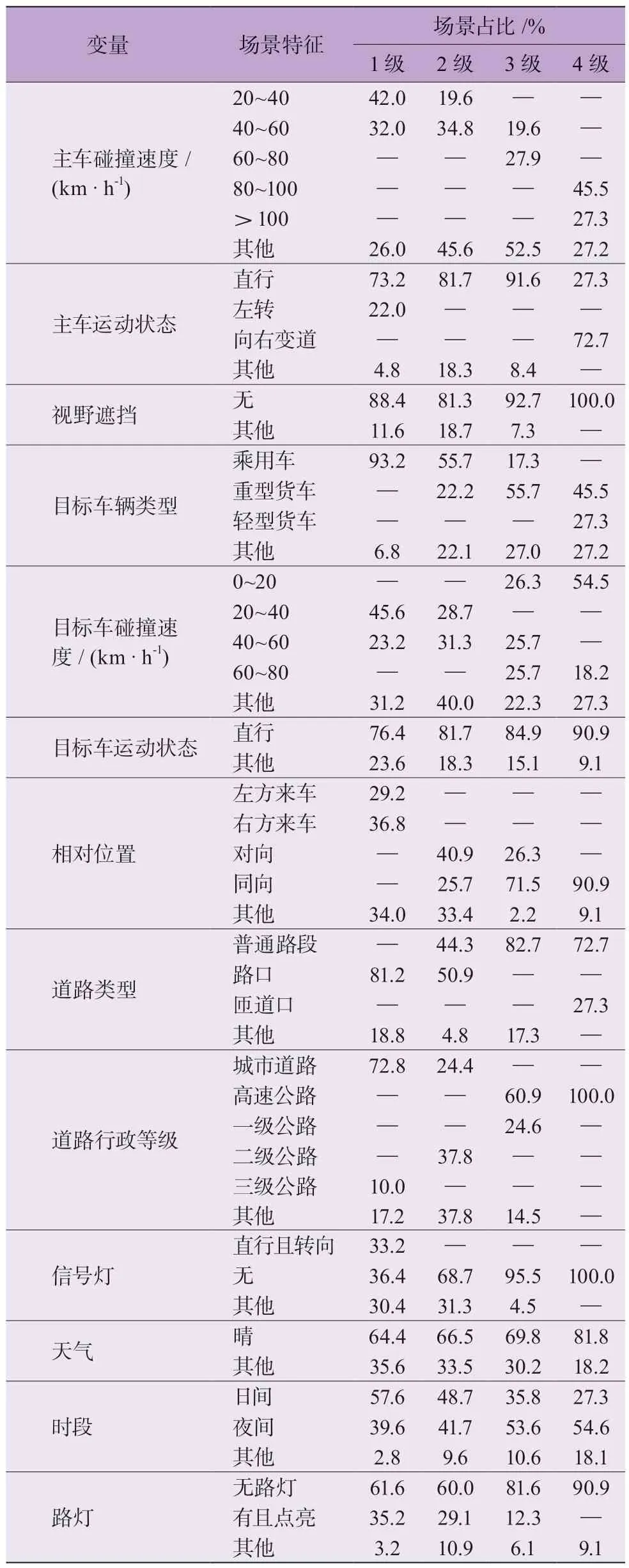
表7 场景特征提取
从各复杂等级场景特征最高占比情况来看,1 级复杂场景以白天城市道路路口的垂向冲突形式为代表,复杂等级为2 级的场景以路口对向冲突为主,1、2 级场景的主车行驶速度相对较低;而3 级、4 级复杂场景主要发生在夜间高速公路,分别以同向追尾和向右变道为代表,主车行驶速度相对较高;随着复杂度增加,主车碰撞速度主要分布区间由1 级的20~40 km/h 增长到4级的80~100 km/h,而4 级复杂场景中目标车碰撞速度降低到0~20 km/h,且目标车以重型货车占比最多,对于同向行驶车辆发生的碰撞事故而言,由于相对速度较大导致事故后果较严重。
从事故后果严重程度方面,统计不同复杂度场景的伤亡情况发现,1 级和2 级复杂场景事故死亡率分别为1.6%、28.7%,复杂等级为3 级的场景事故死亡率为69.8%,4 级复杂场景事故死亡率为90.9%。4 级复杂场景占比最小(1.6%),但死亡率高达90%以上。结合相应场景特征,这类高复杂度且事故后果严重程度较高的场景值得重点关注。
4 结论
本文基于信息熵理论,从事故场景主车信息、目标车信息、道路信息与环境信息4 个维度提取变量,通过逻辑回归分析模型获取优势比确定变量各水平复杂度,利用BP 神经网络算法得到各维度及变量权重,综合加权建立车-车事故场景复杂度模型。基于复杂度评价模型计算670 例案例的场景复杂度指数,在此基础上运用K-means 聚类方法聚类得到了4 个场景复杂等级,复杂等级为1 级和2 级的比例较大且较接近,复杂等级最高的场景占比最小。对13 项变量数据及伤亡情况进行统计,得到各复杂度场景具有明显占比优势的场景特征。4 级复杂场景占比1.6%,但死亡率高达90.9%,此类场景值得重点关注。本研究结果可为面向自动驾驶的车-车仿真测试场景的选取提供依据和方向,具有一定实际意义。
