面向历史灾害地震的Web信息精确抽取与分析方法
2022-01-28文鑫涛郑通彦王钟浩李华玥李晨曦吕文超
文鑫涛 郑通彦 王钟浩 李华玥 李晨曦 吕文超
1)中国地震台网中心,北京 100045
2)防灾科技学院,河北三河 065201
0 引言
基于地震灾害评估报告、地震应急基础数据等形成的地震宏观震情、灾情等真实调查信息是灾害评估和应急处置建议等研究的重要参考依据,但在深入分析灾情特点和提出处置建议时,结构化的数据形式仍存在诸多局限。
近年来,互联网信息的抽取技术发展迅速,其主要分为基于模板的抽取方法和与模板无关的全自动抽取方法(张儒清等,2017)。封化民等(2005)提出含有位置坐标树的Web页面分析和内容提取框架,在对网站信息的内容提取时,考虑了位置特征和空间关系,并通过对120个网站的5000个网页进行测试,结果表明该方法的准确率可达93.78%。张儒清等(2017)实现与模板无关的全自动抽取算法,并开展基于模板的抽取算法的融合研究,结果显示,这种融合机制能有效提高抽取准确率,从而建立一个适用于任意网页、具有实用价值的信息抽取框架。张恺航等(2019)引入通配符节点话题权重的Web新闻抽取方法,降低Web新闻内容边缘噪音文本的错误识别率,提高抽取的新闻内容准确率。
目前Web提取与分析技术在其他相关领域得到了广泛应用,但在地震应急领域方面的应用较少(庞晓克等,2019)。因此,本文以灾害地震目录为基础,截取2010年1月1日至2019年12月31日发生的总计362个灾害地震(图1),以“发震时间、震中位置、震级”为关键词,爬取百度搜索前100位的网页正文文字内容,实现历史灾害地震互联网信息爬取、数据存储的全流程自动化,即通过读取历史灾害地震数据库、自动生成搜索关键词、依据关键词生成搜索引擎地址链接、获取该链接的前10页(100条)URL地址,爬取、解析网页正文文本内容。此外,按照既定的文本清洗策略和文件存储规则,对爬取到的数据进行预处理、数据清洗、分词和统计归类等工作。通过以上工作,一方面为震后灾情网络信息的快速获取探索可实现的方法,另一方面通过“历史灾害地震网络灾情信息数据库”的建立,为引入大数据分析方法提供一定的数据基础。
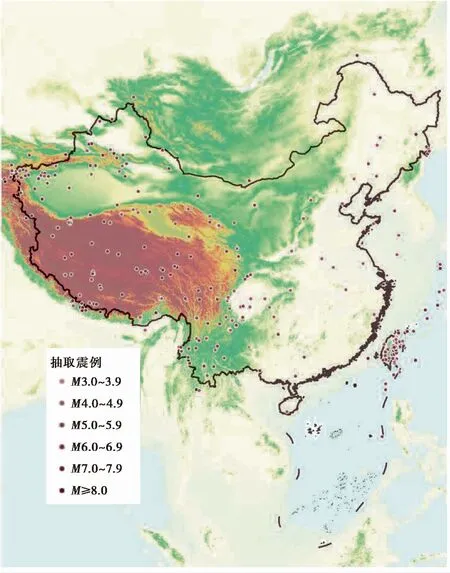
图1 爬取震例的震级和空间分布
1 Web信息精确抽取与分析框架
根据历史地震获得的关键词,从互联网中抽取相关信息,再对相关信息进行文本数据的预处理,包含文本信息去重和清洗过滤垃圾文本等,建立地震网站信息基础语料库,并在此基础上对地震信息进行统计与分析(张开敏,2014)。具体步骤如下:
(1)采用基于搜索引擎的信息获取技术,针对互联网地震信息的特点,设计地震信息搜索链接的URL生成规则,并生成地震信息URL链接列表。对地震信息URL链接列表中的网页站点进行访问,针对网页结构一致性要求较高、算法复杂和实现效率较低的问题,采用并行的网页解析算法,对网站信息进行批量化解析,建立地震信息基础语料库。
(2)使用Simhash算法,结合BP神经网络对地震信息基础语料库中的重复文本信息和垃圾文本信息进行清洗,形成去重过滤后的地震信息基础语料库,为下一步的数据规范化处理做好准备。
(3)读取地震网站信息基础语料库,采用改进的TF-IDF算法对语料库中的地震信息文本进行训练、统计与分析,探索灾害信息间的关联,挖掘地震文本中包含的人员伤亡、地质条件、次生灾害等灾害发生后的急需信息,为震后互联网灾情信息快速获取建立基础(图2)。
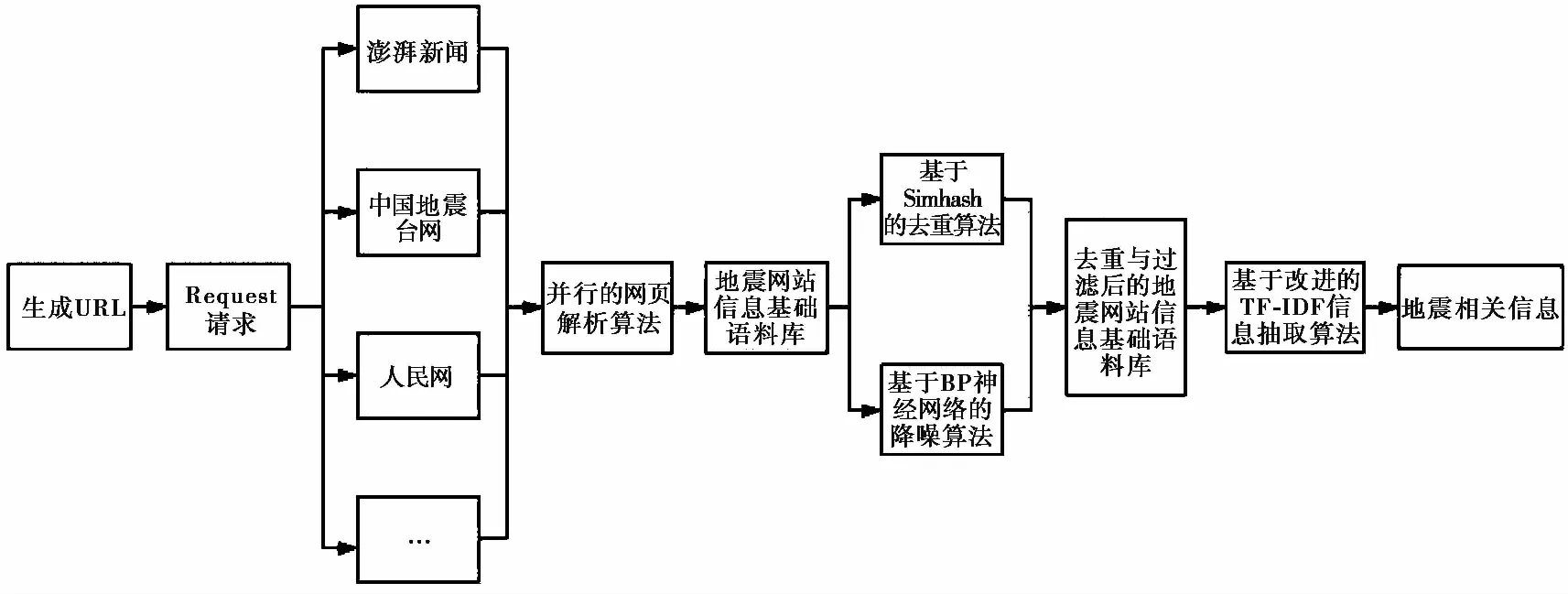
图2 Web信息精确抽取与分析框架
2 关键技术及算法
2.1 地震Web信息的精确抽取方法与数据获取方法
2.1.1 基于百度搜索引擎的URL数据获取
在互联网时代,搜索引擎是获取信息的最佳选择,也是获取地震Web信息的常用工具。百度、谷歌、必应(bing)为常见的搜索引擎,其中百度搜索引擎支持中文编码标准,基于字、词结合的信息处理技术符合地震三要素的中文提取方式。同时,百度搜索引擎的检索结果能够标识出网页的基本属性(如标题、网址、时间、大小、编码、摘要等),方便进行地震相关信息的提取。因此,本文采用基于百度搜索引擎的震后Web信息获取技术。
基于历史灾害地震信息数据库,获取2010—2019年的所有地震震例的三要素信息,构建地震关键词基础语料库,再结合百度搜索链接的URL生成规则和基于禁忌搜索算法的爬虫主题分析技术,进行地震专题Web页面URL数据获取。
以2017年四川九寨沟7.0级地震为例,依据历史灾害地震数据库数据“2017年8月8日四川九寨沟7.0级地震”,对其字符进行中文编码,结合百度搜索链接的URL生成规则,进行URL的拼接,生成一级URL; 进一步采用Requests库,基于一级URL地址对浏览器进行请求,获得一级URL对应的所有二级URL地址; 最后使用BeautifulSoup库对二级URL地址中的HTML源文件进行解析,得到震后Web信息的二级URL元数据。表1 为根据地震关键词信息所获取的不同地震的二级URL数量。
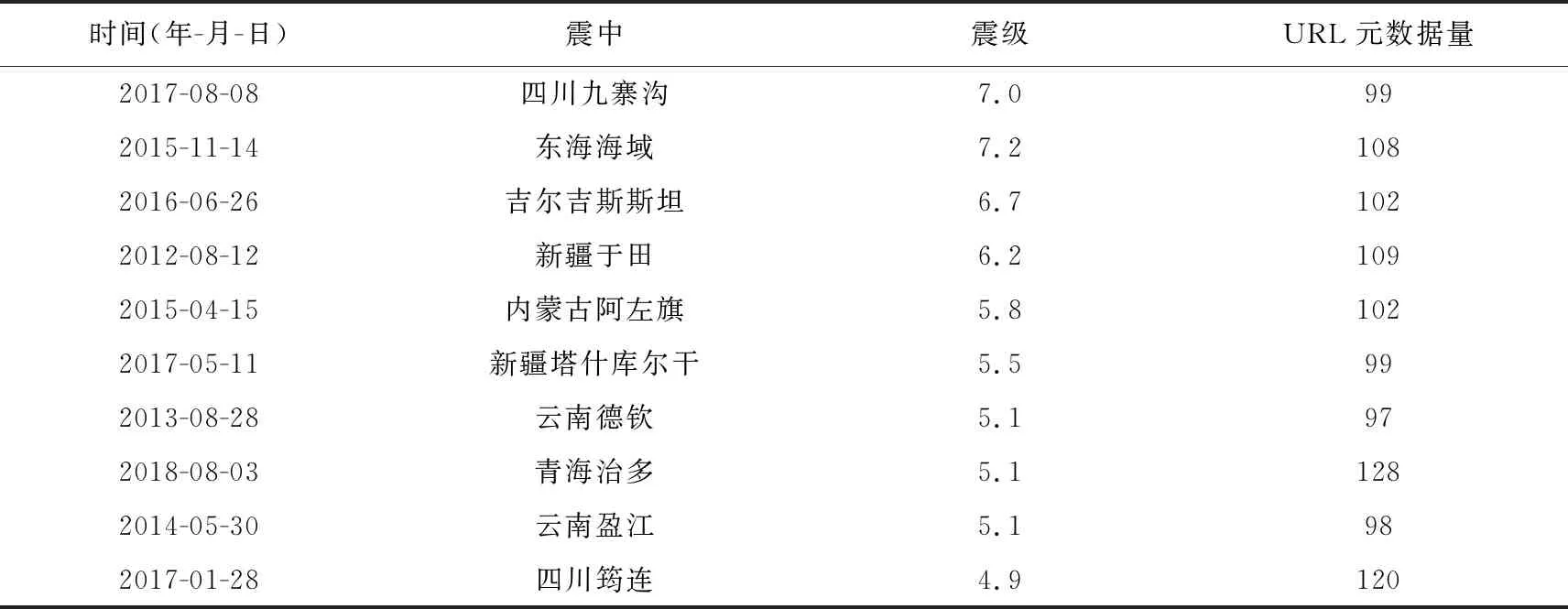
表1 二级URL元数据爬取数量
2.1.2 网页站点信息的精确抽取方法
基于二级URL元数据进行网页正文信息的抽取是地震Web信息抽取的核心工作,对这些正文信息进行深入分析,可获得更有价值的地震灾害深层信息。
常用的正文抽取方法包括:采用DOM树结构抽取、应用机器学习中的聚类分析抽取以及隐马尔可夫模型等方法,这些方法或存在对网页结构一致性要求较高的问题,或存在算法复杂、实现效率较低的问题,对地震网页信息的多源异构和震后信息快速获取要求时效性较高的情况均不适用。因此,本文采用了一种并行的异构网页解析算法,该算法基于数据并行的方案,通过将输入数据划分成多个部分,对其进行并行处理,再合并各个部分的结果以得到最终结果。
该算法的基本思想是将HTML文档划分成多个片段,每个片段包含1个或多个HTML单元,随后使用传统的串行解析算法同时解析多个片段,最后将片段的解析结果归并得到此文档最终的解析结果。以2017年四川九寨沟7.0级地震为例,对获取到的1个二级URL内容进行解析,算法的运行过程分为以下3个步骤:
(1)分段:逐字符地扫描HTML并找出所有“<”字符。将HTML分割成N个片段F1、F2、…、FN,其中每个FN均以“<”起始。由于地震文本信息中的地震三要素、地形地貌、人口信息与伤亡人数等关键信息大概率分布在不同的HTML标签内,且内容相对独立,因此这些内容被分割到了不同片段中,可以用于下一步的并行解析。
(2)并行解析:并行解析分段步骤所得到的片段F1、F2…FN,并将解析出的HTML单元放入全局集合R中(初始化为空)。对1个片段FK解析时,首先创建并初始化1个空白的有限状态机FSMK,然后从FK的起始位置SFK开始,使用FSMK解析HTML文本。每解析出1个HTML单元U,将U加入R中,如果U引用了外部内容(例如引用其他地震网站的数据信息),则根据引用的URL下载此内容。
(3)归并:为了保证最终结果的正确性,归并是1个串行的过程。按照在HTML文档中出现的顺序对R中的HTML单元进行排序,随后依次合并HTML单元形成DOM树,并使用BeautifulSoup提取出所有的文本内容,包括地震三要素、地形地貌、人口信息、伤亡人数等有用信息和一些无用信息(垃圾信息)。
基于上述并行异构网页解析算法,可对二级URL元数据所指向的HTML内容进行正文信息的快速精确抽取,并建立地震信息基础语料库(图3),并对2010—2019年地震web正文信息进行入库操作,为后续数据清洗和分析操作提供数据支持。
图3 地震信息基础语料库
2.2 地震信息清洗
在精确抽取后形成的地震网站信息基础语料库中,会产生许多地震重复文本信息和垃圾文本信息,而地震网站信息基础语料库是后期地震分析的基石,其准确性会影响后期研究结果的可靠性。基于重复文本去重和过滤地震无关文本(垃圾文本)的原则,需要对地震网站信息语料库进行信息清洗处理。
在去除冗余数据方面,首先对地震网站信息基础语料库进行数据预处理,过滤特殊字符和大量重复字符,如“地震”、“九寨沟”、“震级”、“@:”、“【】”等,并删除多余空白。其次调用Python的jieba库函数,完成文本数据的分词处理,并结合现有的“中文停用词表”、“哈工大停用词表”、“百度停用词表”、“四川大学机器智能实验室停用词库”等4个词库共3843个停用词,去除文本中的空格、符号、乱码及中、英文常用的停用词。最后使用Simhash算法去除重复数据,Simhash算法是当前公认去除重复数据的算法,该算法是一种局部敏感哈希算法,优势在于处理速度快、结果准确度高。
Simhash算法的具体实现为,对于2个给定的变量x、y,hash函数H总是满足
PrH∈F(H(x)=H(y))=Sim(x,y)
(1)
其中, Pr表示H(x)=H(y)的可能性,Sim(x,y)∈[0,1]为相似度函数。
该算法可以将高维的地震文本数据进行概率性的降维,并映射成为位数少且固定的指纹,随后再对指纹进行相似度计算、比较,其结果可以反映地震文本数据间的相似度。本文使用海明距离算法进行地震文本的相似度计算(张彦波,2018),假设有2个等长(长度为K)的地震数据信息:A=(九,寨,沟,地,震)、B=(阿,左,旗,地,震),二者的海明距离为
(2)
其中,SK表示为
(3)
式中,aK和bK分别代表A、B语句中的字符。因此,文档A和文档B的海明距离为3。
对于垃圾文本过滤,本文采用Word2vec方法中的CBOW模型构造词嵌入文本特征矩阵,将各词向量相加作为文本的向量,进行文本特征提取(图4)。
图4 CBOW词嵌入模型
采用BP神经网络结合地震文本特征矩阵,构建地震信息垃圾文本过滤模型,首先使用BP神经网络分类器处理地震文本信息,再对文本进行分类。BP神经网络主体由输入层、隐藏层和输出层组成,各层之间采用权值为W的连接线连接,结合sigmoid激活函数,分类并检测出垃圾文本。
BP神经网络分类器的基本原理为,输入数据Xi通过隐藏层作用于输出层,经过非线性变换输出的值包括输入向量X和期望输出值t、输出值Y与期望输出值t之间的偏差,通过调整各层的权重值Wij(输入层—隐藏层)、Wjk(隐藏层—输出层)以及阈值,经过反复学习训练确定误差最小的权值和阈值。
隐藏层输出模型表示为
Oj=f(∑Wij×Xi-θj)
(4)
输出层输出模型表示为
Yj=f(∑Tjk×Oj-θk)
(5)
其中,f表示非线性作用函数;θ表示神经单元阈值。
激活函数本文用到(0,1)内连续取值的sigmoid函数,即
(6)
爬取网页数量最多的前10个震例URL元数据与经过去重过滤后的URL数量的对比,如表2 所示,去重过滤后的地震网站信息基础语料库为下一步的数据规范化处理奠定了基础。

表2 URL数量对比
2.3 地震信息抽取
通过Simhash算法已经删除掉大量重复信息,但网页中通常还存在一些与“人员伤亡、地质条件、次生灾害”等无关的干扰信息。地震文本内的信息通常为非结构化的数据,因此本文采用了基于词频与逆文档频率的关键字提取算法(Term Frequency-Inverse Document Frequency,TF-IDF)对干扰信息进行清除。结合信息论中的信息熵和相对熵2个概念,同时引入词语位置权重因子,采用基于TF-IDF的改进算法对地震文本信息中的地形地貌、人口信息与伤亡人数进行抽取。
使用TF-IDF算法对地震文本信息进行计算,首先需计算地震文本信息中每个单词的出现频率。假设所有地震文本信息中共有words个单词,其中某个单词的出现次数为counter,那么该单词的词频TF的计算公式为
(7)
其次,需要计算地震文本信息的逆文档频率(IDF)。假设共有docs条地震文本信息,其中包含某个词的地震文本信息条数为have_docs,那么该单词的逆文档频率IDF的计算公式为
(8)
最后,计算出TF-IDF的整体词频值,计算公式为
TF-IDF=TF×IDF
(9)
根据上述公式可以发现,如果一个词越常见,那么分母就会越大,逆文档频率就越小,对TF-IDF频率的影响则越小。
根据历史灾害地震,选取爬取到的337例地震文本信息中的9731个字作为TF-IDF算法的训练样本,对地震文本形信息中的地形地貌、人口信息与伤亡人数进行抽取。
3 结果分析
针对2010—2019年360个历史灾害地震,共搜索得到29565个页面信息,其中有337个地震可以爬取出有效的文本数据,可通过Web信息自动抽取方式抽取出文字内容的网页有9731个(图5),经文本数据清洗处理后,实际共解析得到2480567字,有效震例和文本数据的总量较为可观。

图5 2010—2019年灾害地震网页搜索和文字内容提取情况
当以100个页面为限时,平均每个震例通过百度搜索得到的网页数为82.125个,可以解析出7360.7个有效文字,为进一步文本分析和数据挖掘工作提供了丰富的数据基础。
以“发震时间、震中位置、震级”为关键词进行百度搜索,当“震中位置”为空值时,搜索引擎会采用模糊搜索策略(模糊搜索策略指当搜索关键词不存在时,扩大搜索范围),搜索内容的精确性存在一定偏差,因此不作为进一步分析的样本。
通过计算爬取网页个数、爬取文字字数与地震发生时间、震中位置和震级之间相关系数(表3),可以看出通过互联网爬取的地震信息与目标地震的发震时间和震级相关性较低,但结合爬取的网页信息散点图(图6)分析,爬取网页的信息量与震中所在省份紧密相关,因此可以通过该手段较稳定地获取地震相关信息。

表3 地震参数与爬取效果的相关系数

图6 爬取网页信息字数散点图
同时,基于信息论的改进TF-IDF信息抽取算法对于地震文本信息的抽取有可靠的精度,能够成功对地震文本信息中的地质地貌、人口信息与人员伤亡信息进行提取(表4)。

表4 地震文本信息抽取结果(以2017年九寨沟7. ̄0级地震为例)
4 结论
本文提出了一种基于百度搜索引擎、以地震信息作为关键词的地震信息获取与并行的网页解析算法,采用Simhash算法去重、word2vec结合BP神经网络过滤垃圾文本和TF-IDF算法对获取到的地震信息文本进行处理与分析。实验表明,该算法能够准确且有效地提取互联网上存在的“人员伤亡、地质条件、次生灾害”等地震文本信息,并进行统计分析,生成地震文本信息的关键词以及历史灾害地震网络灾情信息数据库。但该方法在数据抽取的速度、地震应急灾情网络的形成速度等方面仍有欠缺,对此还需要进行深入的研究。
