深度学习方法在干旱预测中的应用
2022-01-28米前川高西宁李馨仪任传友
米前川 高西宁 李 玥 李馨仪 唐 莹 任传友
(沈阳农业大学农学院, 沈阳 110866)
引 言
干旱是一种周期性自然灾害[1],对全球大多数农业区的粮食生产构成极大威胁[2-3]。干旱是中国发生频率最高、分布最广的农业灾害之一,每年造成粮食损失2.0×1010~2.5×1010kg、经济损失150~200亿元[4]。在全球气候变化背景下,中国干旱灾害的发生频率和强度均显著增加,未来可能面临更加严重的干旱现象[5-7],作物生产和粮食安全将面临更多风险。干旱的监测预警是实现防灾减灾的重要前提,准确的干旱预测可为风险管理与预警提供有价值信息,最大程度降低灾害损失。因此,干旱预测长期以来一直是农业气象研究关注的重点。
干旱指数能够定量描述干旱的持续时间、严重程度、受灾范围等特征,是农业干旱灾害监测与预测的基础[1,3,8],其中标准化降水蒸散指数[9](standardized precipitation evapotranspiration index,SPEI)使用常规观测气象要素计算,能够描述干旱系统的多尺度特性,且受地理、气候条件限制较小,适用于气候变化背景下的干旱研究[8-10],在国内外得到广泛应用。在农业生产中,土壤水分是影响作物产量的主要因素,表征农业干旱受灾情况,研究表明:较短时间尺度(1~6个月)的SPEI与浅层土壤含水量显著相关,适用于农业干旱监测与早期预警[11-13]。但受土质、地形、土地管理和气候条件的影响,土壤水分和SPEI的时间相关存在空间变异性,为更全面地监测农业干旱,本研究选择SPEI的时间尺度为1个月(SPEI1)、3个月(SPEI3)和6个月(SPEI6)。
在气候变化背景下,干旱指数以及降水、蒸散量等气象要素的随机性与非线性变化导致干旱预测仍是具有挑战性的科学问题[14]。干旱预测方法主要包括物理模型[15-16]、统计模型和物理-统计混合模型[17-18]。物理模型模拟海洋、大气、海冰以及陆面之间的相互作用,但对月或季尺度降水的预报精度限制了其干旱预测能力[19-20]。统计模型主要包括回归模型[21]、时间序列模型[22]和机器学习模型[12],因其结构复杂度小,数据需求量少,计算成本低[19,23],应用十分广泛。随着气候变化日趋明显,多数统计模型适用性受限,需要尝试更多新方法[10,24-25]。人工神经网络(artificial neural network, ANN)能够处理非平稳数据[14,25],突破了时间序列模型单变量的限制[26],具备非线性特征与灵活的拟合能力,对降水[20,27-28]、温度[29]、蒸散[30]、潜在蒸散量[31]以及干旱指数[19,20,23,25]的预测精度高于传统时间序列模型。但统计模型并不能完全取代物理模型,更合理的策略是综合物理模型和统计模型的优势构建混合模型[12]。
近年深度神经网络(deep neural network,DNN)的应用使语音识别、计算机视觉、机器翻译等领域取得突破性进展[32]。典型深度学习系统包括多个处理层,能够从大量数据中自适应提取多层级、抽象特征,利用丰富的信息实现高质量预测[33-35]。循环神经网络(recurrent neural network,RNN)是一种动态系统,可从数据中自适应提取时序信息,适用于时间序列预测[36-37],但传统RNN难以获取时序数据间的长程依赖关系[33],为修正该问题,许多研究采用长短期记忆网络(long short-term memory network,LSTM)建立干旱预测模型[23-24,31]。输入变量同样影响模型的预测性能,增加预测因子可提供更多信息,但也可能因引入过多噪声而降低预测精度[38],而编码输入变量是一种简单有效的特征提取与降噪方法[39];许多研究利用海表温度、南方涛动指数、太平洋年代际振荡等大尺度气候变量提升预测精度[12,19,38],但此方法依赖于对目标区域干旱灾害的深入研究,且大部分地区缺乏直接可用的气候变量。卷积神经网络(convolutional neural network, CNN)可从输入要素场中自适应识别并提取关键空间模式[40-41],为获取大尺度环流信息提供全新思路。
本研究使用旋转正交分解(rotated empirical orthogonal function,REOF)方法对研究区域进行区划,以气象要素和大尺度环流要素为干旱预测因子,在每个地理分区分别利用传统的整合移动平均自回归时间序列模型(ARIMA)[22]、传统的LSTM模型(TLSTM)[23-24]、改进的LSTM模型(ILSTM)以及附加卷积层的ILSTM模型(CLSTM)4种预测模型对未来1~3个月SPEI区域性变化特征建模,并对比分析各模型预测效果,以期为中国农业管理、灌溉系统规划以及农业干旱灾害预警提供有价值的信息,同时为DNN模型的改进及在干旱预测中的应用提供参考。
1 数据与模型
1.1 数 据
本研究所用数据包括气象要素、大尺度环流要素和SPEI序列。
气象要素为1948—2020年降水量、潜在蒸散量、平均气温、最高气温、最低气温和水汽压。
研究表明:ENSO事件与季风的年际变化是影响中国干旱变化的大尺度环流要素[11,42],同时考虑环流形势以及水汽输送对中国降水和气温变化的关键作用[43-44],故选取1948—2020年的海表温度距平场、500 hPa位势高度距平场、700 hPa和850 hPa经向和纬向水汽通量距平场、地面10 m经向和纬向风速距平场为大尺度环流要素。
SPEI由站点降水量与潜在蒸散量计算得到,具体计算方法可参考文献[45]。
本研究将1948—2007年数据作为训练数据集,2008—2020年数据作为测试数据集。
本文插图中所涉及的中国国界基于审图号为GS(2017)3320号标准地图制作,底图无修改。
1.2 预测模型
1.2.1 TLSTM模型
TLSTM模型由1个LSTM模块和1个全连接层(FC)模块组成[23-24]。LSTM模块包含输入门、遗忘门和输出门3个门控件,以及1个记忆细胞。输入门控制输入变量中可流入记忆细胞的信息,遗忘门控制上一时刻记忆细胞中存留信息的遗忘,两者共同实现记忆细胞中状态信息的更新,最后输出门控制从记忆细胞到输出隐藏状态的信息流动。LSTM模块通过门控件控制不同时刻的信息在记忆细胞中保存、累积,或在未来某些时刻遗忘、流出,进而实现长期记忆功能。FC模块负责将LSTM模块输出的隐藏状态映射为下一时刻的预测因子。
1.2.2 ILSTM模型
ILSTM模型由1个预处理FC模块和TLSTM模块组成,干旱预测因子在输入TLSTM模块前需通过FC模块的预处理。与TLSTM模型相比,ILSTM模型的主要优势为预处理FC模块可依据优化目标自适应地对干旱预测因子进行特征提取与降噪处理。ILSTM模型的超参数对预测精度有一定影响,经交叉验证选定ILSTM模型的输入序列时间步长为20个月,预处理FC模块输出节点数为512,LSTM模块为1层,隐藏节点数为512,使用丢弃法处理其输出隐藏状态,丢弃率为0.25,模型的输出为下一时刻预测因子的估计值。
1.2.3 CLSTM模型
CLSTM模型由预处理CNN模块和ILSTM模块组成,其中预处理CNN模块的网络架构参考VGG-16网络模型[46]中13个卷积层的设计,负责大尺度环流要素的预处理工作。CNN模块中较浅的卷积层可从大尺度环流场中提取简单环流模式特征,随着网络加深,简单环流模式经过多次非线性映射与组合得到更抽象、更复杂的模式信息,最终大尺度环流模式信息被压缩到CNN模块的输出中。同时受益于互相关运算以及池化层对特征图的下采样操作,CNN模块对输入场中的随机误差和局部变异性均不敏感,适用于大尺度气候特征的识别与提取[41]。经交叉验证选定CNN输出的16个标量(即影响区域干旱变化的大尺度气候变量),与气象要素和SPEI组合成输入ILSTM模块的预测因子。CLSTM模型仅利用ILSTM模块实现预测。
1.2.4 ARIMA模型
为与深度学习方法对比,本研究还使用ARIMA模型进行预测。ARIMA模型首先通过1个或多个初始差分步骤消除时序数据的非平稳性,再利用数据自身的滞后效应和误差值对时间序列进行回归拟合,详细建模过程参考文献[22]。
1.3 对比试验与评价指标
为对比预处理FC模块与CNN模块对SPEI预测精度的贡献,本研究设计两组对比试验:第1组用于验证特征提取与降噪处理对SPEI预测精度的影响,因此仅使用1.1节中的气象要素和SPEI序列作为预测因子,分别训练TLSTM和ILSTM模型并进行对比评估;ARIMA模型与上述两种DNN模型的对比结果也在该组试验给出。第2组对比试验用于验证大尺度环流信息对干旱变化的贡献,为此在输入变量中加入大尺度环流要素训练CLSTM模型,并与ILSTM模型的评估结果对比。
选择Pearson相关系数、均方根误差和误差绝对值的平均作为评价模型预测结果拟合优度的指标,用于评估预测精度。误差绝对值的平均(E)定义如下:
(1)
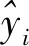
2 结果分析
2.1 研究区域划分
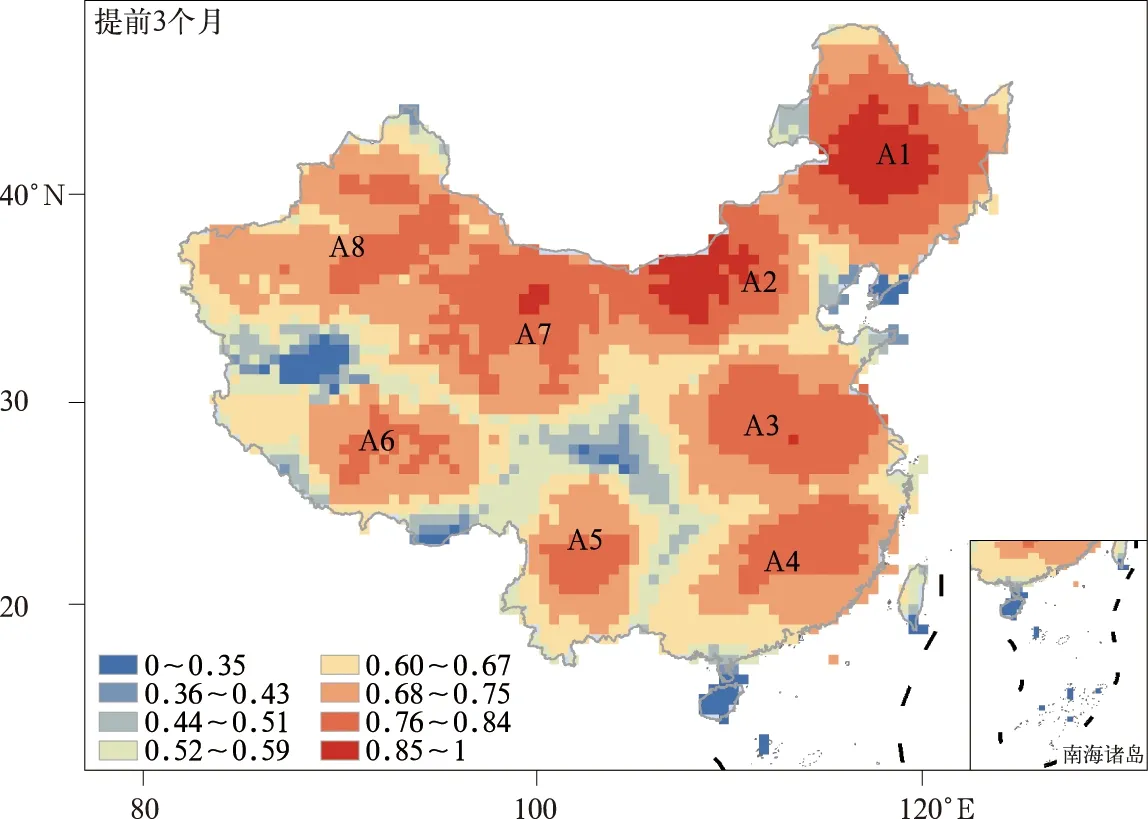
使用REOF方法识别并提取1950—2020年中国干旱变化特征的空间模态,分别对月尺度SPEI1,SPEI3和SPEI6序列进行REOF分析,旋转后前8个空间模态的累计方差贡献率分别为63.5%,64.0% 和63.8%,3组结果中各主成分的主次顺序与方差贡献率并不一致,但累计方差贡献率基本一致(表1)。因子荷载矩阵元素绝对值大于0.05表征区域干旱变化特征具有连续性与一致性[42],以此为阈值可以得到8个主要空间型(A1~A8)。按照上述主要区域调整主成分与因子荷载矩阵的符号,确保各主成分时间部与对应子区域干旱变化为正相关关系,再以因子荷载最大原则确定分区结果。3组分析获得的地理区划十分相似,仅边界存在差别(图略)。考虑到SPEI的预报难度随时间尺度减少而不断增加[38],本研究采用SPEI1的最终分区结果(图1)。
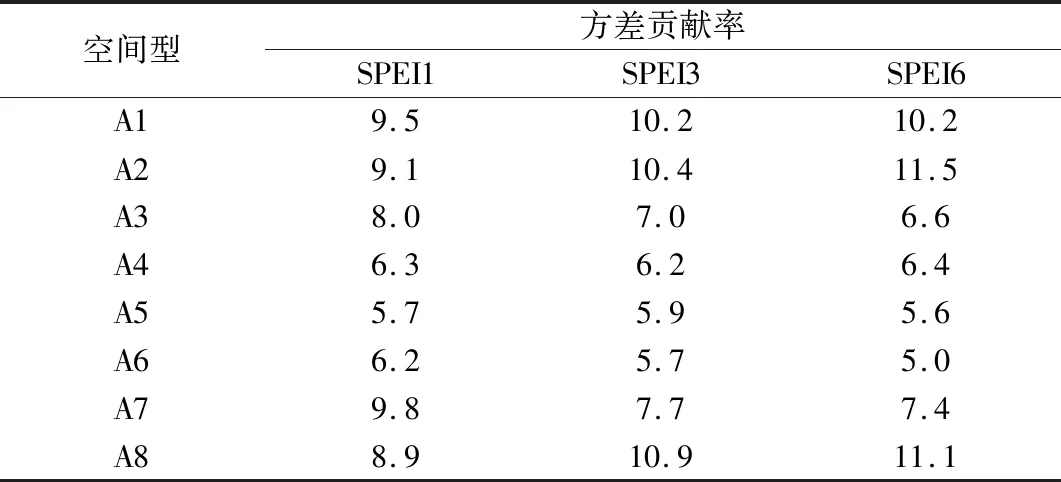
表1 3组REOF分析前8个模态的方差贡献率(单位:%)Table 1 Variance contribution rate of the first 8 modes of REOF analysis among 3 groups(unit:%)
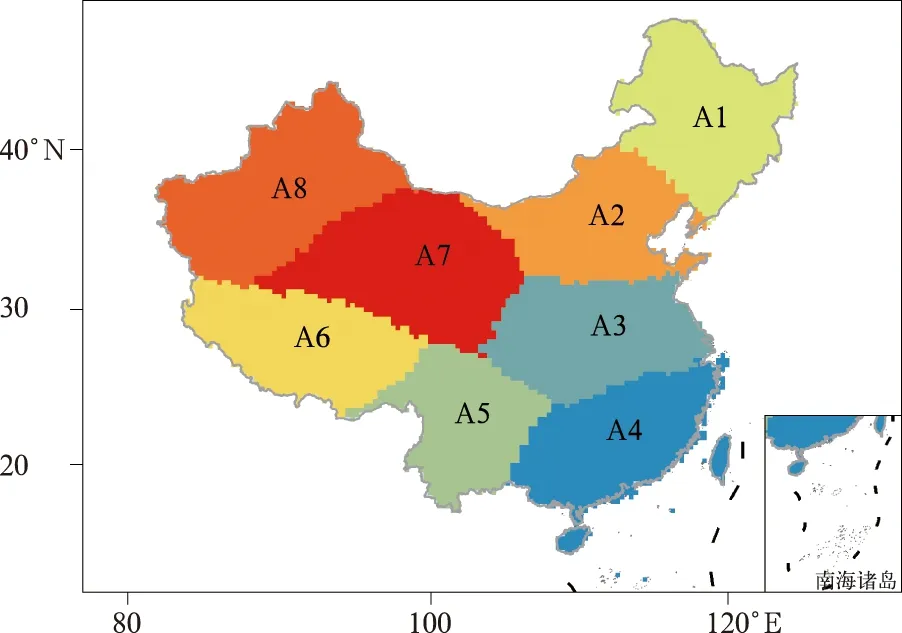
图1 中国月尺度SPEI1的区划图Fig.1 Subzoning of monthly SPEI1 in China
2.2 预处理FC模块对SPEI预测精度影响
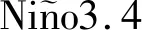
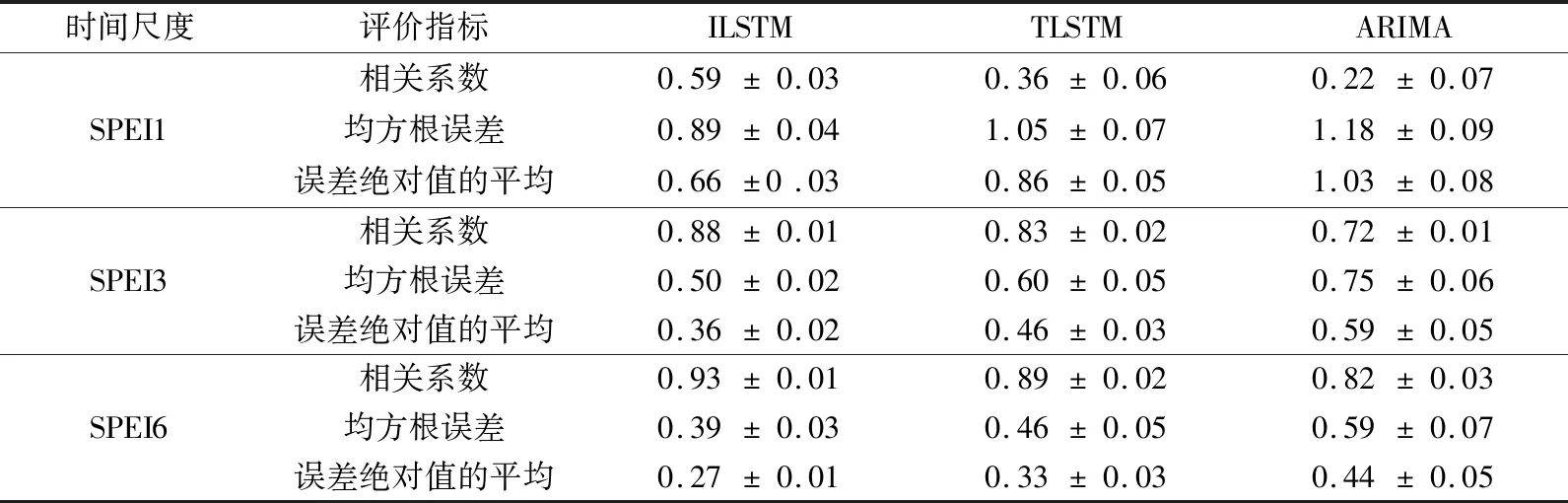
表2 测试阶段不同模型在1个月提前期预测的性能评估Table 2 Evaluation of 1-month lead time prediction performance of different models in test period
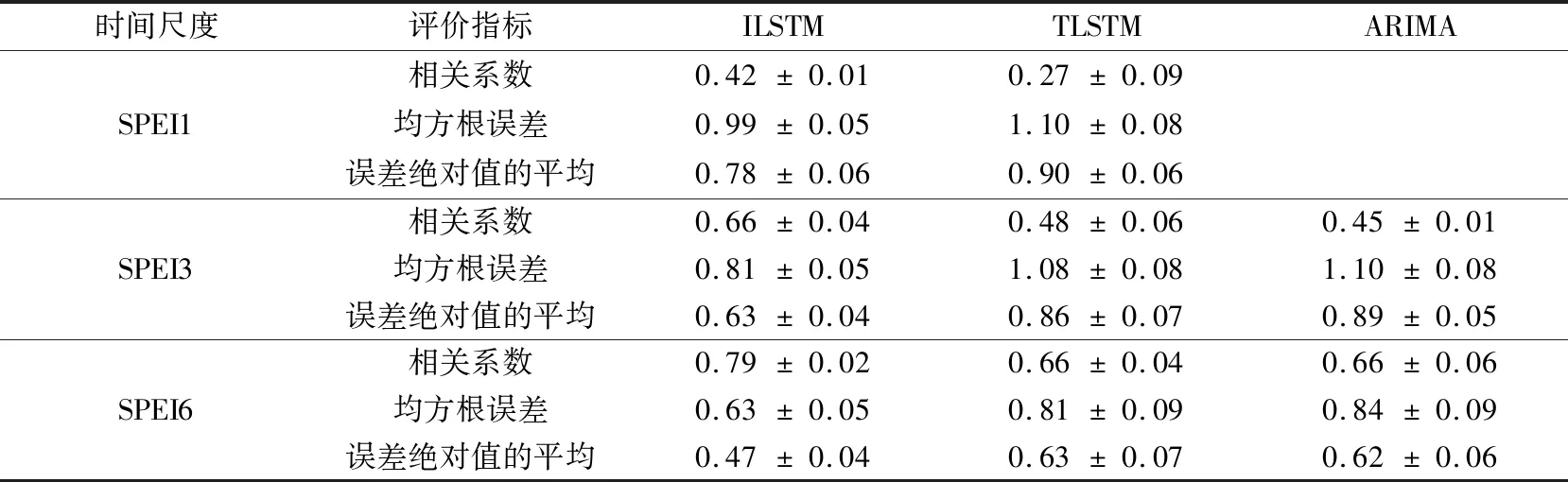
表3 测试阶段不同模型在2个月提前期预测的性能评估Table 3 Evaluation of 2-month lead time prediction performance of different models in test period

表4 测试阶段不同模型在3个月提前期预测的性能评估Table 4 Evaluation of 3-month lead time prediction performance of different models in test period

图2 ILSTM模型提前1个月预测的SPEI1,SPEI3和SPEI6与观测的相关系数Fig.2 Pearson correlation coefficient between prediction and observation for SPEI1, SPEI3 and SPEI6 with 1-month lead time based on ILSTM model
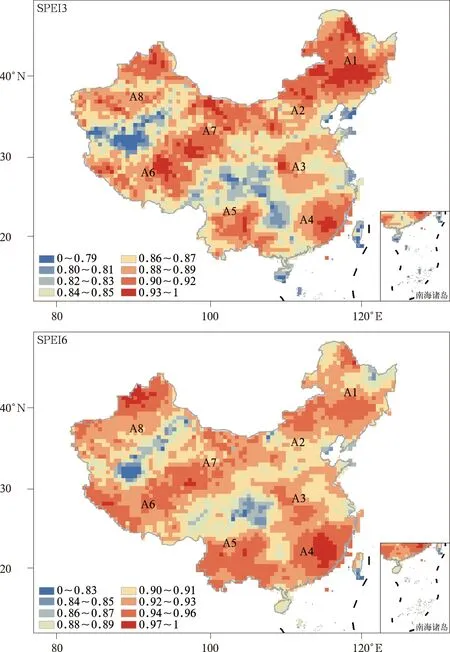
续图2
2.3 预处理CNN模块对SPEI预测精度影响
CLSTM模型对8个区域内SPEI变化的预测能力较ILSTM模型有所提升(表5),其对提前期为1~3个月的SPEI1与提前期为2~3个月的SPEI3和SPEI6的预测能力提升尤为明显;精度提升同样表现在降水(相关系数为0.70~0.95,达到0.01显著性水平)和水汽压(相关系数为0.74~0.99,达到0.01显著性水平)的预测,这些提升均表明:预处理CNN模块提取的大尺度环流特征为降水变异性提供有效信息,同时减小模型中误差累积与传递,即使预测时间延长,该模型仍有良好预测能力。图3表明湿润地区降水变异性带来的预测困难在很大程度上被大尺度环流场提供的有效信息量补偿,此外均方根误差的下降表明CLSTM模型对极端事件的预测精度同样有所提升,但极端事件出现的频次较低,模型对其描述能力仍有欠缺。滞后效应使LSTM模块记忆细胞中保存的历史环流信息仍可对区域干旱变化有贡献,因此在短期预测中CLSTM模型的预测精度能保持在较高水平,随着预测提前期的进一步延长(4~6个月),预测误差累积的影响使预测精度快速下降(图略)。图3还表明,即使环流要素可以为干旱变化提供有效信息,边界区域预测精度提升仍有限,这意味着边界区域与所属分区的干旱变化一致性较低。当训练集中包含过多一致性较低样本时,CLSTM模型可能引入大量误差降低预测性能,而更精细的区域划分可能是进一步提升模型预测性能的有效方法。对比图2与图3可知,由于大尺度环流要素场的贡献,中国东部地区出现相关系数高值中心,这体现出CLSTM模型提取的环流信息对区域干旱变化的作用十分显著,为干旱机理分析提供潜在可能性。然而DNN模型所提取的是抽象综合特征,模型深度较大且层间连接复杂,在这些条件限制下权重分析法并不适用,使干旱变化的机理推断较为困难,一些研究尝试可视化DNN的抽象信息[47-48],为关键环流模式的识别提供可能,但这些方法在地球科学领域仍需要进一步的尝试与验证。

表5 测试阶段CLSTM模型的预测性能评估Table 5 Evaluation of prediction performance of the CLSTM model in test period
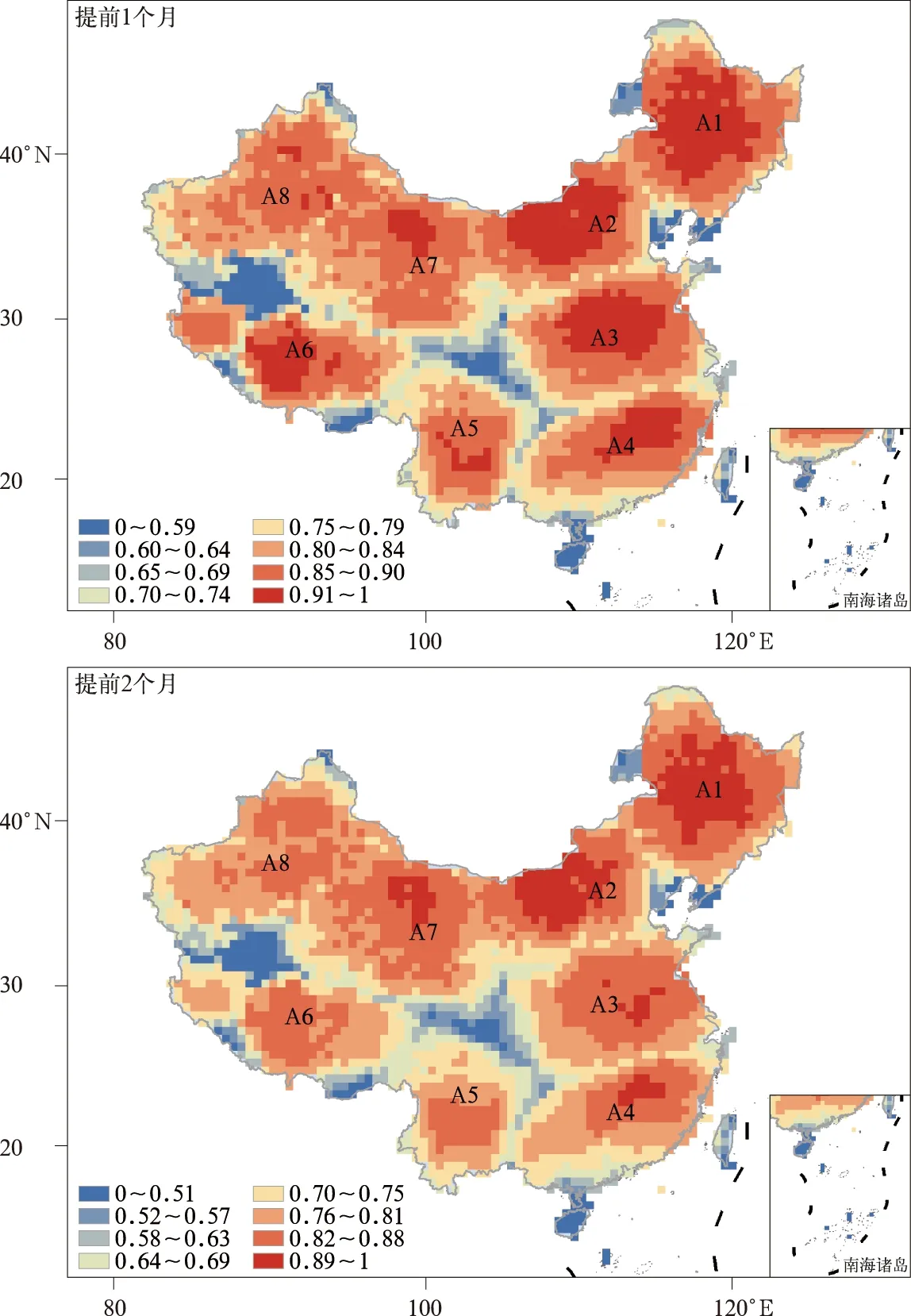
图3 CLSTM模型提前1~3个月预测的SPEI1与观测的相关系数Fig.3 Pearson correlation coefficient between prediction and observation for SPEI1 with 1-month to 3-month lead time based on CLSTM model
续图3
3 结论与讨论
本文使用REOF方法将中国划分为8个地理区域,以站点气象要素和大尺度环流要素为驱动变量,在每个区域独立训练TLSTM,ILSTM和CLSTM 3种不同深度网络模型和ARIMA时间序列模型,对区域内未来干旱状况进行预测。通过对比分析不同模型对1~3个月提前期SPEI变化的预测效果,得到以下主要结论:
1) TLSTM模型增加预测因子预处理FC模块可提升对区域性干旱状况变化的预测效果。利用预处理FC模块自适应提取对目标站点干旱变化有作用的综合信息,同时达到降噪目的,使其预测能力优于TLSTM模型和ARIMA模型。但ILSTM模型缺乏对降水变异性有贡献的信息,使干旱预测能力受限。
2) ILSTM模型增加大尺度环流要素预处理CNN模块能进一步提升对区域性干旱变化的预测效果。利用CNN模块自适应提取大尺度环流要素场中对区域干旱变化有贡献的综合环流信息,增强模型对于降水变异性的预测能力,丰富模型中的有效信息量,因此提高短期干旱变化的预测精度,同时减缓精度随预测时间的延长而降低的速度。
3) CILSTM模型利用深度学习算法,实现从输入数据到输出变量的自适应学习,通过自适应识别并提取数据中的丰富信息,减少人工选择干旱预测因子与滞后效应时空变异性带来的限制,即使在干旱变化机制研究与验证不够充分的地区,该深度学习方法仍具有可行性。
作为一种非线性统计模型,DNN模型对时间序列数据的建模依赖于时序变量间的内在联系,但预测序列和观测序列间不可避免存在误差,随着预测提前期的延长,预测序列中的误差不断累积,使模型的预测能力迅速下降。大气环流模式可对大尺度环流要素以及部分气象要素提供较为准确的预报[16],因此今后的研究可利用物理模型和DNN构建混合模型,订正预测序列的误差,提升模型对中长期干旱变化预测的性能。此外,3种深度网络模型间的对比展示出网络架构在特征提取、降噪处理、学习数据间滞后效应等方面的关键作用,因此,改进深度学习方法是提升干旱变化预测性能的重要途经。近几年许多研究提出更先进、深度更深的网络模型[49-50]以及更具技巧性的深度学习方法[51],这些深度学习方法在地球科学领域拥有巨大潜力,有待应用于天气、气候事件的预测。
