公共管理研究中潜变量指标误用问题及其改进策略
2022-01-28郭晟豪萧鸣政
□郭晟豪,萧鸣政
一、引言
有效测量问题被视作公共管理的大问题,准确得当的测量既是实践改进方向的基础,也是公共管理研究可信可用的前提。对于实践而言,有效测量问题是导向问题。量化的准确性能够决定研究能否是“好的定量研究”,也是当前我国公共管理量化研究中亟待重视的问题[1]。但是,量化的实际操作并不简单,尤其是潜变量,最为复杂。具体而言,有的研究变量可以直接测量,如国内生产总值(GDP)、人口数量等被称为显变量或观察变量,在测量时并无技术难度;还有部分研究变量难以直接测量,如当前颇受重视的干部领导能力、治理效能、公共价值、合作生产等,这些无法直接观测的变量被称为潜变量,相关研究在对其测量时存在相当的挑战。但是,社会中的现实问题往往绕不开潜变量。因此,早在现代统计学出现之前,人们已经开始使用系统观察的方式测量一些不易直接衡量的社会变量。在实证主义运动的推动下,日益完善的数理统计方法为量化研究提供了有力的工具支持,难以直接测量的潜变量可以通过多个题项共同测定,以避免单一题项测量潜变量存在测量不完整、精确性不足以及存在随机误差等内生缺陷。在潜变量测量时,一般可以应用两种不同的指标进行,即反映型指标(reflective indicator)与形成型指标(formative indicator)。但是,在具体的潜变量测量时,反映型指标和形成型指标并不完全相同,且非常容易混用。
变量测量偏误最直接的后果就是估计的严重偏误,对于研究结论有致命影响。这一现象已经得到心理学、社会学和工商管理学等具有定量研究传统的学科的广泛反思和讨论[2]。值得注意的是,在公共管理等定量研究兴起较晚的社会科学领域,仍有不少定量研究在测量指标选用问题上“重蹈覆辙”。这一方面源于学科间的知识优势差异,另一方面则是因为公共管理研究对象更为复杂特殊。公共管理研究涉及政府、社会以及非营利机构等中宏观治理主体,还有领导干部、群众等微观行为个体,且许多构念往往具有多学科源流,相应潜变量的测量指标选用难度进一步提升。近年来公共管理研究热点问题,诸如干部能力素质、政府治理效能等都是难以直接观测的潜变量。这些潜变量只有正确使用相应类型的反映型指标或者形成型指标,完成准确测量,才能在量化研究中实现对理论构念的正确分析,避免测量误差、遗漏变量乃至因果关系的错误推断等严重后果。
必须指出的是,公共管理领域对于反映型指标和形成型指标的讨论尚未引起足够重视。在实际的公共管理研究中,上述两种测量方式存在的混淆和误用已经导致部分公共管理错误的研究结论,更无法有效解决现实问题。选取一个与研究设计不相符的测量方式,将意味着在变量的测量和变量关系研究中出现第一类和第二类错误(1)第一类错误:原假设是正确的,却拒绝原假设。第二类错误:原假设是错误的,却没有拒绝原假设。的概率大大增加,研究结论的可靠性存疑。已有研究发现,在地方治理绩效的测量中,将形成型指标误用为反映型指标,导致地方治理绩效指标无法通过所谓的统计检验,治理绩效的所谓统计结构难以解释,部分绩效内容被遗漏,极大地削弱了研究结果对于现实问题的回应力和解释力[3]。但是,类似的问题不仅在地方治理绩效中存在,在整个公共管理领域的量化研究中,只要涉及难以直接测量的潜变量,就绕不开反映型指标和形成型指标。而这些诸如效能、能力、价值的变量正是当前公共管理研究的热点、重点、难点,因此有必要对变量指标进行系统的回顾和辨析。
在广泛借鉴其他学科关于潜变量测量方法论的研究成果、系统考察当前公共管理领域定量研究的基础上,本文认为公共管理研究领域的变量与指标问题需要注意以下三个要点。第一,指标不仅仅是揭示变量的方式,合适的指标更体现着对于变量的合意理解。如果研究者在构造指标和指标统计检验时,本该使用形成型指标却使用反映型指标,或在本该使用反映型指标时却使用形成型指标,尽管仍能得出统计上的结果,但是,可能存在匹配上的误差,也将无法形成契合理论构想和恰当解释实践的研究结论。第二,公共管理学领域本身使用的研究方法有多学科交叉的特征,在统计分析方面,心理学变量测量常用的内部一致性、区别效度、聚合效度等统计标准均有其适用范围,如果在公共管理学领域未经判断就沿用这些统计标准,有可能造成量化统计的严重错误。第三,尽管在变量关系模型中,潜变量结构方程的使用正日益成为公共管理学领域量化研究的一大热点,但含有形成型潜变量的结构方程在统计时并不适用传统的基于协方差的结构方程(CB-SEM),如不遵循判别和使用原则,同样会产生谬误[4]。
在当前社会科学实证主义运动持续推进却也饱受质疑的时代,对公共管理研究中潜变量测量原则的方法论进行辨析,不仅可以明晰量化研究在公共管理领域的使用前景并从长远角度影响着公共管理学科的未来发展,而且可以为社会科学领域的潜变量测量系统理论的构建贡献来自公共管理学科的智慧。因此,本文旨在从三方面对上述问题做出回应:一是辨析潜变量测量中的反映型指标与形成型指标的区别以及误用的后果;二是明确指标选用的条件与情形,从而避免指标混用;三是阐明针对不同类型的潜变量指标所适宜的统计策略。
二、公共管理领域反映型和形成型指标选择的异同分析
在公共管理领域的变量测量问题中,显变量通常可以直接测量,因此测量较为简单;难点主要在于潜变量的测量,具体体现在对反映型指标和形成型指标做出正确的选择。本文认为,有必要对两种类型的指标进行辨析(表1)。
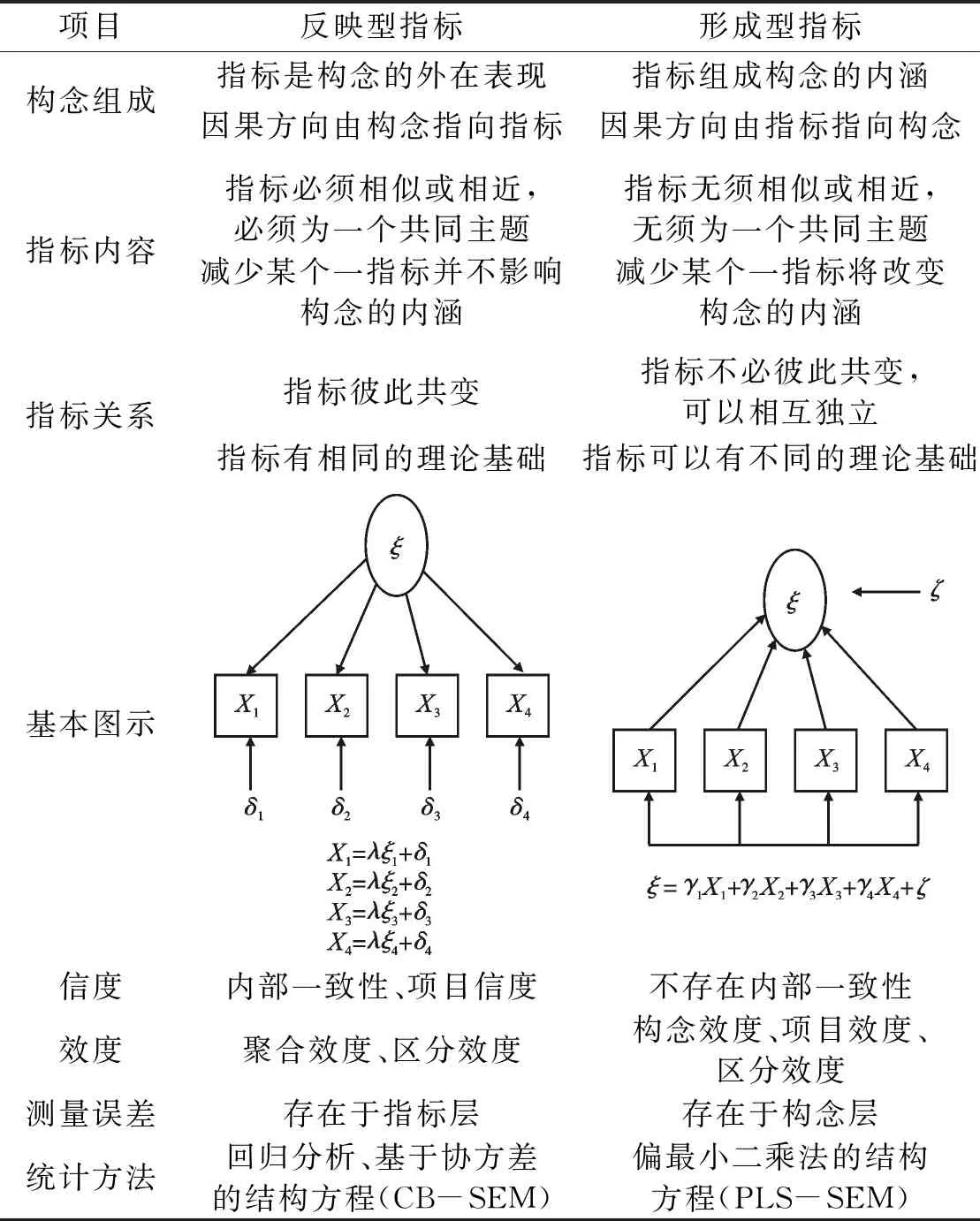
表1 反映型指标与形成型指标
(一)反映型指标与形成型指标
反映型指标是变量理论构念的一组外在表现,各指标的含义相近,有相同主题,多个指标共同“反映”出要测量的构念。该类指标起源于经典测评理论和心理测量学,指标可以被视为潜变量的函数,潜变量的变化反映在可观测指标的变化上,因果关系由理论构念指向测量指标。如果用δ来表示构念(潜变量),X1,X2,X3为该构念的一组反映型指标,λi为构念δ对指标Xi的影响,εi为第i个指标的测量误差,则Xi=λiδ+εi,i=1, 2, 3,…,n。反映型指标是构念本身的外在表现,是由构念决定的,因此反映型指标也被称作效果指标(effect indicators)。在大多数情况下,因为承袭心理学的研究习惯,当前管理学相关的研究量表和关于量表开发的方法研究几乎以反映型指标为主。
形成型指标是指定义理论构念的一组指标,该组指标共同“形成”理论构念的内涵,这些指标不相似或相近,也不必有一个共同主题。在许多情况下,指标可以影响它所测量的潜变量,而不是被潜变量影响。在这种情况下,这些指标被称为形成型指标,因果关系由测量指标指向理论构念。如果同样用δ来表示构念(潜变量),X1,X2,X3为该构念的形成型指标,γi为指标Xi对构念δ的影响,i=1, 2, 3,…,n,ξ是误差项,则δ=γ1X1+γ2X2+γ3X3+…+γnXn+ξ。形成型指标不是构念本身的外在表现,而是由指标组成构念的内涵、决定潜变量的构念,因此形成型指标也被称作原因指标(cause, causal indicators)。形成型指标对于实践中的潜变量测量,尤其是具体内容复杂的潜变量有着独有的适用性,因此在近些年得到越来越多的关注。
(二)潜变量的指标类型辨析
反映型指标和形成型指标的特点可以通过二者的比较得到更为明显的体现。具体地,反映型指标和形成型指标的差异体现在以下几方面。第一,在构念组成方面,反映型指标是构念的外在表现,因果方向由构念指向指标,构念的变化会引起指标的变化;形成型指标组成构念的内涵,因果方向由指标指向构念,指标的变化会引起构念的变化。第二,在指标内容方面,反映型指标必须相似或相近,必须要有一个共同的主题,减少某一个指标并不影响构念的内涵;形成型指标无须相似或相近,不需要有一个共同的主题,减少某一个指标将改变构念的内涵。第三,在指标关系方面,反映型指标可彼此共变,且指标有相同的理论基础;形成型指标不必彼此共变,可以相互独立,且指标可以有不同的理论基础。第四,在信度方面,反映型指标关注内部一致性、项目信度;形成型指标不存在内部一致性。第五,在效度方面,反映型指标关注聚合效度、区分效度;形成型指标关注构念效度、项目效度、区分效度。最后,反映型指标常用统计方法包括回归分析、基于协方差的结构方程(CB-SEM),测量误差存在于指标层;形成型指标常用统计方法为偏最小二乘法的结构方程(PLS-SEM),测量误差存在于构念层。
(三)公共管理领域潜变量测量指标适用类型
本文选择公共管理学研究中具有代表性的部分潜变量,并根据反映型指标和形成型指标在概念上的区别进行类型举例(表2)。首先是一些反映型指标在公共管理学领域的使用情况。被测量的潜变量往往在微观层面、以行为公共管理学为主,如公民义务式公共服务动机、人事管理的繁文缛节以及政策感知的薪酬和晋升政策。可以发现,反映型指标的题项有明显的相似性,每一个题项可以由另外相近的题项代替,题项是潜变量的外在表现。例如,公民义务式公共服务动机中的“我认为公共服务是我的公民义务”“有意义的公共服务对我来说是非常重要的”具有一定相似性,“我认为公共服务是我的公民义务”得分高的被试者在“有意义的公共服务对我来说是非常重要的”得分也会高。因此,某个题项的剔除不会对公民义务式公共服务动机的内涵本身产生影响,这也是研究者可以通过信效度检验剔除反映型指标原量表中题项的原因。
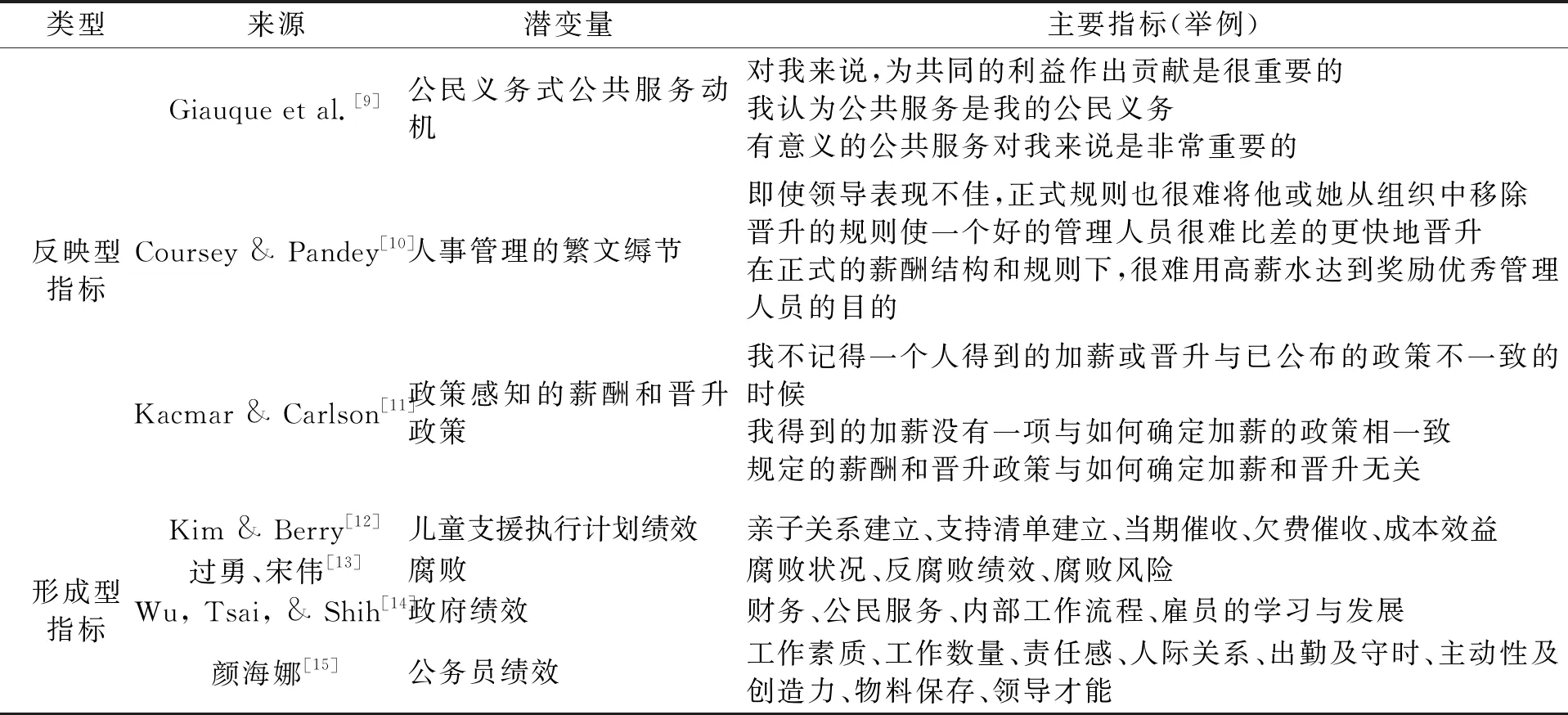
表2 反映型与形成型的公共管理评价指标举例
然而在更多时候,公共管理学研究中的高维变量是由多方面共同组成的,测量题项之间不具有相互的替代性,尤其是中、宏观层面的变量。同样地,本文对一些形成型指标在公共管理学领域的使用情况进行梳理,被测量的潜变量包括儿童支援执行计划的绩效、腐败、政府绩效、公务员绩效等。可以发现,形成型指标的题项之间彼此独立,每个题项均具有自身的特征和独有性,题项间重复度低,各个题项共同组成潜变量的具体内涵,如果缺失某一个题项,测量的对象也会发生变化。例如,公务员绩效中“出勤及守时”“领导才能”并没有高相似度,“出勤及守时”得分高的被评价者不意味着“领导才能”得分也会高;如果测量指标中不包含“领导才能”,那么公务员绩效这一构念将缺少一部分内容,构念内涵将发生重大变化。这也是形成型指标不适宜以内部一致性作为评价标准,也不可以随意剔除原量表中题项的原因。
三、公共管理研究中反映型与形成型指标的误用
(一)指标类型误用产生的错误
在选择测量指标时,如果不能对反映型与形成型指标进行区分,研究者可能会犯第一类错误或第二类错误,如表3所示。如果在应该选用形成型指标的构念上选取反映型指标,就会产生第一类错误。此时因果关系错误地从构念指向指标,指标不再被用于定义构念,而是成为构念的一系列外在表现(2)尽管出现第一类错误,统计结果依然会显示具有较适合的单维性、高度可靠的子量表以及较好的整体模型拟合度。但是从理论构念本身具有的特质来说,这种测量方法并不可取:从内容上来说,犯第一类错误会产生内容不同的指标体系;从指标删减过程来说,犯第一类错误会导致在指标构建过程中为降低多重共线性而删去高度相关的项目,在量表开发过程中为增加内部一致性而保留高度相关的项目;从效标效度来说,不同的指标构建和量表开发过程也会导致不同的效标效度。。如果在应该选用反映型指标的构念上选取形成型指标,就会发生第二类错误。此时因果关系错误地从指标指向构念,指标不再是构念的一系列外在表现,而是定义了构念。由于反映型指标在管理学占据主导地位,一些学者甚至在测量潜变量时会下意识地使用反映型指标及其统计方法。

表3 指标类型选择正误与结果
Jarvis、Mackenzie和Podsakoff的元分析显示,大多数测量中出现的错误都是由于在本应该使用形成型指标时却使用反映型指标[16]。Diamantopoulos、Riefler和Roth对先前的研究进行总结,发现第一类错误发生的次数远远多于第二类错误,且犯第一类错误的后果十分严重[17]。研究者往往难以解释实质性的结构模型关系,结构参数要么被高估,要么被低估;在某些情况下,甚至能使结构参数由不显著变为显著(3)当本应使用形成型指标却误用反映型指标时,会减少构念的方差,因为以反映型指标测量的构念的方差等于各个测量的公方差,而以形成型指标测量的构念的方差等于各个测量的方差之和。因此如果犯第一类错误,就会减少外生变量的方差并保持内生变量的方差,从而增加对它们之间关系的参数估计,相反,如果降低内生变量的方差,而外生变量的方差保持不变,那么相关的参数估计就会降低。由于指标类型的错误使用,结构路径系数要么被高估,要么被低估,对结构模型关系的实质性解释产生不良影响。。
(二)公共管理领域变量指标误用的表现
在目前的公共管理领域,同样由于沿用心理学测量习惯,研究者们更多地选择使用反映型指标的统计标准,形成型指标并没有得到广泛重视和使用,因此,将反映型误用为形成型的情况比较罕见。而且,反映型指标在公共管理领域常见于微观;微观的行为公共管理是公共管理学与心理学的交叉学科,许多潜变量(如公务员的离职倾向)本来就化用的是心理学的反映型指标量表,因此反映型指标的思维更容易在公共管理研究中先入为主。相应地,当前公共管理研究的突出问题是将形成型指标误用为反映型,尤其是使用反映型指标的统计标准和流程进行变量测量和变量关系的检验,其直接后果是形成型指标的潜变量被反映型指标的统计标准束缚,从而因统计错误导致结果谬误。
其一是在测量工具的信效度检验时采用不适当的检验指标。这是当前公共管理学研究测量指标首当其冲的问题。由于公共管理学的测量统计方法往往借鉴心理学测量,部分统计分析的教材直接以心理学量表为范例介绍信度与效度等检验方法和判断标准,但是如前所述,大多数的心理学测量量表属于反映型指标,因此指标的评价流程往往会受到“先入为主”的影响,采用的默认统计技术其实是反映型指标的标准。如果指标其实是形成型指标,那么用反映型的标准去检验指标是否合格就会出现第一类错误,将原本好的指标以为是不好的。例如,部分研究者在开发测量量表或者量表验证时,通常直接采用探索性因子分析、内部一致性检验(如判定Cronbach’sα)等反映型指标的标准,但是对于大多数的公共管理变量,如政府绩效评价,因为绩效往往由多方面共同组成,一系列指标共同构成政府绩效的内涵,指标的数量、含义变化都会影响政府绩效内涵[18],因此应该属于形成型指标。误用为反映型指标的最为突出的表现是采用探索性因子分析对题项“降维”,造成所谓的“共同因子”难以合理命名,以及因绩效指标内部一致性较差,所以剔除所谓“不合理”题项,导致评价内容缺失[3]。
其二是在变量关系检验时采用不恰当的统计技术。目前,对于公共管理领域的变量关系检验,潜变量实际上往往被处理为观察变量(所谓结构方程模型其实只是路径分析),即计算潜变量的全部题项平均数作为潜变量的取值,但是可以计算平均数的前提是题项的内部一致性系数信度高。显然这是反映型指标的计算方式,形成型指标并不适用,因此不可以直接以Cronbach’sα大于0.600或0.700为由,计算形成型指标的平均数并作为潜变量的观测值。此外,随着潜变量结构方程的日益流行及其在公共管理研究中的应用,另一个问题也将涌现,即在使用潜变量结构方程时,研究者同样容易囿于潜变量结构方程通常被默认为基于协方差的结构方程(CB-SEM)而直接使用,但是对于形成型指标而言,CB-SEM并不适用。错误的结构方程使用会造成模型估计的严重不准确,变量间关系的结论也不可靠。
(三)公共管理研究中指标误用及后果举例
关于公共管理领域指标误用的情况,国内的研究以县域政府治理绩效和乡镇工作治理绩效为例加以说明[3]。县域政府治理绩效的测量指标的研究,原本根据理论和实践提出行政服务态度、行政审批效率、民主决策水平、政策执行能力、公务员廉洁情况、政务公开程度、执法公正性、市场监督能力以及对区政府总体治理水平的评价等较为完整的诸多方面,共同组成县域政府治理绩效。这本属于形成型指标,但是由于在统计检验时使用反映型指标的标准,进行内部一致性的检验并剔除题项,最终得到话语权与问责制、政府有效性、管制质量、法治和腐败控制等内容,这与研究的构想存在较大差距并难以解释,实际上造成县域政府治理绩效测量的损失,其根源就是指标类型选择不当,使得应该测量的题项未能被纳入。此外,在乡镇工作治理绩效的测量中,乡镇日常工作包括基本生活、日常服务、政策制度等不同方面,每个方面也由具体的内容组成,同样属于形成型指标。研究发现,当使用形成型指标的统计检验标准时,原先维度区分不明显或难以解释的窘境将得到解决,也更符合研究者测量乡镇工作治理绩效的构想,且不会无端造成信息的损失[3]。
国外的研究以出口方面的绩效测量为例。出口协调绩效的测量指标包括出口的沟通、责任共担和合作等内容,这应该属于形成型指标,但是研究者如果误用为反映型指标,那么使用同样的数据进行分析,将发现出口的合作对工作者的工作绩效没有影响,这并不符合实际的情况,并且难以解释[6]。类似地,在出口绩效的测评上,Zou、Taylor和Osland的量表包括财务、战略性和满意度三个方面[19],每个方面三个题项,并被一直作为反映型指标使用。但是,战略性中的题项“盈利额度”和 “长期高增长”两项在内部一致性检验时会彼此干扰,导致内部一致性较差。而现实情况是,“盈利额度”和“长期高增长”两者在统计上并不具有绝对一致性,也就是说这里并不符合反映型指标的标准,本就不存在所谓的内部一致性。但是,类似这种误用使诸多研究者在满足本就不应检验的题项在内部一致性的问题上遇阻。而当将出口绩效的测量指标转化为形成型指标时,发现问题即可迎刃而解[5],研究结论更能体现理论和实践的情况。
四、改进当前误用问题的建议
实证研究中的测量模型经常被误用,往往体现着研究人员和评论员对两类指标不够了解[16]。针对目前公共管理学潜变量测量指标中存在的反映型指标与形成型指标误用的现象,本文首先进行指标的类型辨析,在对比反映型指标与形成型指标各自特点的基础上,进一步介绍指标的选择策略以及相应的统计方法。面对指标误用问题,本文将公共管理量化研究中的潜变量测量初步划分为“指标类型选择”“指标统计检验”“模型使用”以及“模型判别”四个阶段,提出潜变量测量的操作流程指南(图1),以有助于研究者尤其是公共管理学科领域的研究者参考借鉴。

图1 公共管理学潜变量指标选择与研究流程图
(一)明确研究问题的性质与特点
明确研究问题的性质和特点是研究的起点。针对某一构念,在反映型指标和形成型指标之间进行选择并不容易,必须依靠理论分析。研究者应该考虑,对特定问题的回应在理论上应当是如何的,测量模型应该从理论考虑出发去设计。比如,对于政府绩效的测量,不同的研究之中可以不同,取决于具体要研究什么样的政府绩效(如县域政府绩效、职能部门绩效、干部工作绩效等),是关注多方面的组成还是某一方面的具体表现,应当有所差异。也就是说,应该通过研究问题和理论分析来决定指标的类型,而不是直接默认指标类型或者根据统计结果更改原先的指标类型设计。形成型指标和反映型指标之间并没有绝对的优劣之分,部分变量可以有不同的解释和测量角度,为避免第一类错误和第二类错误,研究者应立足特定问题进行研究设计,秉持回应、改进现实的初衷,并充分考虑具体构念和指标之间的逻辑因果关系,以此选择最恰当的指标类型。
在理论构念的定义阶段,要仔细考虑后续统计时潜变量及其指标之间可能的因果优先级。尽管Bollen和Lennox已经呼吁研究者不应该自动地将自己局限于单维的经典测评模型中[20],但是目前在研究中反映型指标仍占主导地位。这样的反映型指标主导通常是不假思索的下意识行为,意味着存在未经审慎判定即做出错误选择的可能。这样的错误会导致无法准确评估构念之间的理论关系,即真实的因果究竟是怎样的。因此,研究者在为感兴趣的理论构念开发多题项的量表之前,就要依据特定问题和研究目的,明确问题的性质和特点,充分考虑反映型指标和形成型指标的潜在适用性,究竟哪一种更为适合。
(二)指标类型的选择与设计
指标类型的选择同样应当由理论而非研究者的统计目标驱动。Gerbing和Anderson指出,反映型指标适用的CB-SEM适合于测评和发展理论,形成型指标使用的PLS-SEM适合于对未来的预测[21]。Fornell和Bookstein指出,如果研究可观测的差异,反映型指标更合适;如果研究抽象的解释或无法观测的差异,形成型指标会有更强的解释力[22]。虽然这仿佛说明,可以依据研究目的的不同而选择指标类型,但是这些说法其实并不准确,因为测量手段应该服务于变量构念。
构念与其指标之间的认知关系并非可以被“操纵”并由此适应研究者的目标。这种“操纵”与理论主导(theory-driven)的原则不一致。在检查构念间的实质关系之前,构念与指标之间关系的性质和方向是已经确定的[6]。也就是说,反映型指标和形成型指标之间的选择必须在根本上是理论驱动,而不是测评驱动。
指标设计需要考虑指标内容的充分性和统计的有效性之间的平衡。具体地说,在构建指标时,必须将理论驱动的测量操作化与期望获得的统计有效性相协调。例如,为提高信度(在反映型指标中)或减少多重共线性(在形成型指标中)而盲目剔除项目,很可能会对所有指标的效度产生不良后果。虽然对如何平衡内容充分性和统计有效性并没有硬性规则,但如果只关注统计上的有效性,则不太可能产生说服力强且具有可重复性的测量工具。也就是说,尽管可以判断采用反映型指标或者形成型指标哪一种的统计有效性更好,但是这并不应该成为指标类型选择的理由。如果在理论基础上已经选择反映型指标(这意味着形成型指标已经被仔细考虑过,但最终未被采纳),不管在量表开发过程中获得何种结果,转换为形成型指标并不可取,反之亦然。
Jarvis、Mackenzie和Podsakoff建议思考以下原则:通过指标与构念之间因果关系的指向、指标之间的互换性、指标是否应彼此一致、指标是否具有相同的前因和后因等四组问题,在反映型指标和形成型指标之间进行选择,研究者可以参考比照(表4)[16]。
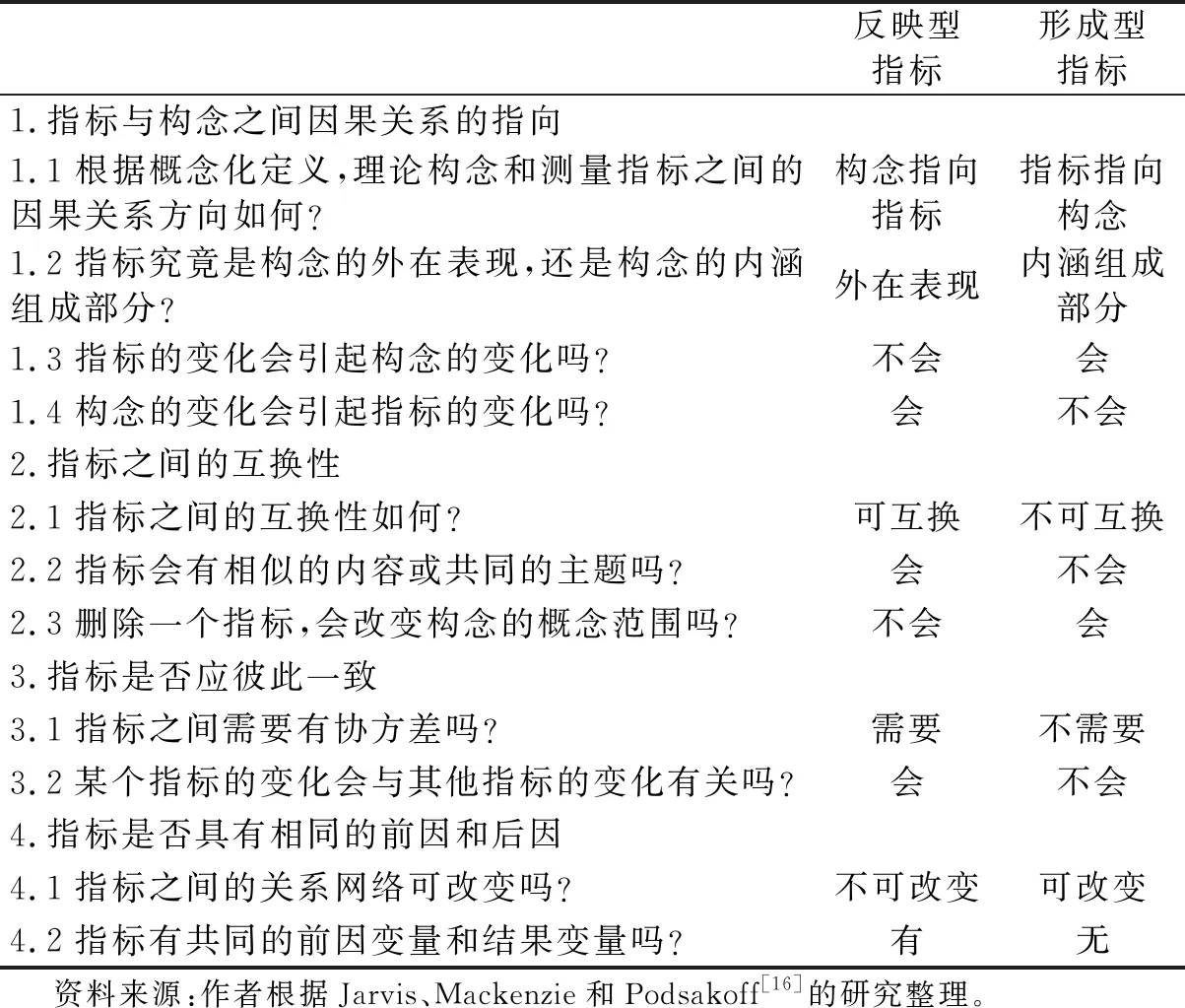
表4 反映型指标和形成型指标的选择原则
(三)指标统计检验
对于指标的评价必须首先判断其类型,然后再采用相应的统计评价方法。在选择符合潜变量的理论指标类型后,即应选择与之相应的信度、效度检验标准,从而避免前文所述在统计上存在的第一种错误。此时可以参考本文中的信度、效度部分,反映型指标关注内部一致性、项目信度、聚合效度、区分效度,形成型指标则关注共线性、构念效度、项目效度、区分效度。
反映型指标的评价相对成熟,可以从单维性、内部一致性、项目信度、聚合效度、区别效度等标准进行判断。其中,单维性方面,探索性因子分析后应为同一因子且载荷在0.600以上;内部一致性方面,Cronbach’sα应该在0.600以上,CR值应达到0.600以上;项目信度方面,指标载荷应大于0.700并达到显著水平;聚合效度方面,AVE值应大于0.500;区别效度方面,交叉载荷应不高于内部载荷,且AVE的平方根大于所有相关系数。
形成型指标的评价相对有限,主要判断标准有项目效度、共线性和区别效度。其中,项目效度方面,指标权重应在0.200以上或至少大于0.100,并且应达到显著水平;共线性方面,指标应不存在严重的共线性[7],即VIF低于5或公差大于2、状况指数(condition index)低于30;区别效度方面,指标间的相关系数应低于0.700[23]。
(四)潜变量模型使用与判别
如果研究者在检验潜变量的指标信、效度后,通过计算平均数或加权平均数将潜变量整理为一个数值,那么在使用模型统计分析时,变量的处理与显变量的模型无异。需要补充说明的是,真正意义的潜变量模型,即测量模型与结构模型均存在于完整的模型统计中。
如果采用的是反映型指标,那么采用潜变量结构方程最常使用的CB-SEM完成即可。这也是众多潜变量结构方程操作教程中介绍的方法,模型结果的判定可以参考CFI、TLI(大于0.800)、RMSEA(小于0.080)等判别指标。这一部分的内容已经较为成熟。
如果采用的是形成型指标,为确保模型被正确识别,那么统计分析则需要使用PLS-SEM完成[4]。常用准则包括:对于每个外部权重,使用1作为初始值;使用路径加权方式[24];最大迭代次数不超过300;使用交叉冗余;遗漏距离(omission distance)设置为5-10,且有效观测数除以遗漏距离不得为整数[25];Bootstrap样本设置为5000,必须大于有效观测值的个数;模型结果的判定可以参考R-square、Q-square、F-square和GOF等判别指标[26],只是与已经颇为成熟的CB-SEM相比,目前PLS-SEM模型的判别指标依然存在争议[25]。
五、应用案例与进一步探索
(一)公共管理领域潜变量测量应用案例
本文以“乌干达民主和治理质量数据(2015)”中选举公正的测量为例(4)乌干达民主和治理质量数据(The Quality of Democracy and Governance in Uganda)调查于2015年5月7日至2015年5月26日间,在乌干达全国范围内进行,对该国18岁及以上公民进行随机抽样调查,共计调查2400人,应答率达84.7%,搜集得到乌干达公民对政治腐败、区域关系等社会公共议题的态度。本文所选取关于选举公正的测量选自该数据的题项Q48A-Q48F。资料来源:Golooba-Mutebi F, Kibirige F. Afrobarometer Round 6: The Quality of Democracy and Governance in Uganda, 2015[DB/OL],(2018-05-21) [2021-08-01]https://doi.org/10.3886/ICPSR36900.v1.,说明前述指导框架中指标判定以及统计检验的应用思路。乌干达民主和治理质量数据是一系列关于公众态度的调查,用于搜集非洲人对民主、治理、经济、公民社会及相关问题的看法,在公共管理领域的研究中得到研究者的重视和使用。本文用于示例的选举公正的测量共有6个题项,分为选举环境和选举行为两个方面,每个方面各三题,具体见表5。首先,选举环境的公正水平高,选举行为的公正水平并不一定也高,虽然建立的环境可能足够公正,但在实际投票行为中也可能被干扰,反之亦然。所以应该是选举环境和选举行为两个方面(还可能存在其他方面)组成选举公正,因此指标应为形成关系。具体到选举环境的测量,包括选票统计公正、反对派候选人被阻止竞选(R)、媒体对所有候选人公正报道三个具体题项,同样地,三者不一定同时处于高水平或低水平,选举环境在这3个题项中可能各有不同,同时也可能存在其他的内容,因此,应该为形成型指标。同理,选举行为也属于形成型指标。所以,应该采用形成型指标的统计检验。本文使用SmartPLS进行偏PLS-SEM的验证性因子分析。如表5所示,选举环境和选举行为的3个题项外部权重均大于0.200,达到标准,并且显著。此外,两个变量的相关系数为0.606,低于0.700,说明区分效度较高。因此,数据适合进行量化统计分析。

表5 指标判定以及统计检验的差异举例:选举公正的测量
但是,如果没有进行潜变量指标类型的判断,而是依照研究的惯性直接采用计算变量的内部一致性,即采用反映型指标的统计检验标准,如表5所示,选举环境的Cronbach’sα为0.347,并未达到0.600以上的标准;CR为0.357,也未达到0.600以上的标准;AVE为0.168,同样未超过0.500。这就意味着从指标统计检验的标准来看,选举环境的3个题项无法通过统计检验,不可以以平均数的方式计算为显变量。同样的情况,对于选举行为而言依然存在,即选举行为3个题项的内在一致性信度很低,无法进行平均数的合并计算。
不仅如此,使用潜变量结构方程进行验证性因子分析方式的情况依然堪忧。例如一般而言最为常用的CB-SEM,使用Mplus进行分析,即选举公正有选举环境和选举行为两个维度,每个维度使用3个题项测量,即二阶CFA。可以发现,选举环境3个题项的标准化因子载荷都低于0.600的标准,选举行为3个题项也只有1项在0.600以上。这同样意味着,选举公正的测量在潜变量的统计中无法使用。这就给研究者带来研究的困境,即无法有效测量选举公正。但是,问题的症结并不在于测量的题项,而是因为构念本身是形成型,采用反映型指标的统计检验标准本身就是误判。
(二)公共管理领域变量指标的进一步探索
好的定量研究的基础必定是价值思考。值得再次强调的是,指标类型判断必须理论先行,必须考虑特定公共管理问题,不可依赖统计结果。当变量同时兼备反映型与形成型指标的特征情况时,无论采用何种统计或者检验方式,结果都可能通过统计标准。一方面,反映型指标可能存在是形成型的可能。例如,本文中举例的人事管理的繁文缛节量表属于反映型指标;但是繁文缛节本身包括人事管理的繁文缛节、沟通的繁文缛节、采购的繁文缛节、信息系统的繁文缛节、预算的繁文缛节等5个维度。对于繁文缛节这个构念,既可以理解为如果一个组织的繁文缛节程度高,那么将表现为人事管理、沟通、采购、信息系统、预算的繁文缛节程度都高,因此属于反映型的结构;也可以理解为繁文缛节包括人事管理、沟通、采购、信息系统、预算等5个方面,5个方面的内容共同组成繁文缛节。因为,人事管理的繁文缛节程度高并不意味着信息系统的繁文缛节程度也高,5个子维度之间没有高度的相关性,因此属于形成型指标。针对繁文缛节究竟是形成型概念还是反映型构念,这一问题有着持续的讨论。Coursey和Pandey认为将繁文缛节视为反映型构念的观点,源于政治问责制和其他外部影响;而将繁文缛节视为形成型构念的观点,则源于各种管理子系统(如预算、人员)的不灵活性。另一方面,形成型指标也存在属于反映型的可能。在这种情况下,如果从统计的角度出发,部分研究的指标采用反映型指标的标准或者形成型指标的标准都可以达到较高的信效度,这同样容易引起研究者的困惑。因此,反映型指标和形成型指标的实际运用中非常有必要在类型辨析的特点之外明确指标类型选择的思路。
最后,需要指出的是,反映型或形成型指标并不是研究者唯一的选择。在某些情况下,理论构念的概念化可能需要一个高阶模型,研究者可以调用更加复杂的测量模型,比如在所有阶段都使用同一类型指标(反映型-反映型、形成型-形成型),或者交替地使用反映型或形成型指标(反映型-形成型、形成型-反映型)。研究者应该意识到这些复杂结构操作的存在,并且在决定测量策略时仔细考虑它们潜在的适用性。比如前文提到的公共服务动机,在理论分析的基础上,第一阶段分为由四组题项,各自测量一种公共服务动机(政策取向、公民义务、同情心、自我牺牲),每一种均是一个反映型指标,而第二阶段四种公共服务动机共同组成完整的公共服务动机构念,为形成型指标。这样公共服务动机的测量就是一个反映型-形成型模型。比如Wright就提出,公共服务动机可能是在一阶时是反映型指标;在二阶时,是形成型指标[27]。Kim实证验证了这种可能性。在比较“反映型-反映型”和“反映型-形成型”的公共服务动机后,发现在理论分析和统计上“反映型-形成型”指标更适合测量公共服务动机[28]。再如前文提到的关于繁文缛节的争论,Coursey和Pandey在比较繁文缛节是反映型还是形成型时,实质上也是“反映型-反映型”和“反映型-形成型”的比较,只不过他们发现“反映型-反映型”更适合作为测量指标。这也恰恰说明,指标类型应该因变量而异,并无绝对的优劣。本文再次强调公共管理研究应该结合理论分析和实践,强调公共管理研究应与现实社会场景相结合;量化统计只是技术手段,研究者务必防止僵化教条地使用。
