基于国家项目视角下的德国科研数据管理发展及启示
2022-01-28袁汝兵
周 雷 袁汝兵 燕 娜 杨 萍
(1. 北京市科学技术情报研究所 北京 100044;2. 北京市科技战略决策咨询中心 北京 100044)
0 引 言
科研数据是科学技术研究、试验开发等研究过程中产生的原始及其衍生数据,是支撑研究论文和科研项目的重要依据。随着科学研究“第四范式”的到来,科研数据已成为信息化时代推动科技发展、社会进步的重要战略资源。目前各国科研机构都围绕这一战略资源开展了从基础设施建设到数据管理服务的研究与实践。检索re3data[1](检索时间2020年9月21日),注册数据知识库的最多的国家是美国(1 086个),排名第二的就是德国,共423个,并大幅领先于第三名的英国288个,因此,在国际科研数据管理领域德国占有重要地位。自1998年德国研究基金会(Deutsche Forschungsgesellschaft,以下简称DFG)出台《确保良好科学实践的建议》[2]以来,德国对于科研数据的目的、用途都有了重新认识,陆续开展了包括基础性项目,如科研数据基础实施的框架项目“Radieschen”、数据知识库注册项目“re3data”等;机构科研数据管理项目,如政策工具类项目“FDMentor”、高校管理实施项目“UniV-FDM”等在内的大量各类国家级科研项目。在工作实践上,比勒菲尔德大学、柏林洪堡大学、哥廷根大学等第一批德国高校自2013年逐渐开始科研数据管理服务以来,在反复面对问题、解决问题的过程中积累了较为丰富的实践经验,而国家级科研项目对于当时基础性、关键性问题的解决具有良好的示范作用。因此,分析德国国家科研数据管理项目的历史和发展趋势,对于我国相关机构开展科研数据管理服务具有重要参考价值。
1 数据来源
本研究科研项目数据来自DFG和德国相关部委。在DFG项目数据库GEPRIS中[3],检索forschungsdaten(科研数据),共检索出科研项目156项。此外,在德国科研数据知识网站forschungsdaten.org检索科研数据类项目共102项 ,两者消重归并后共计207项用于本研究分析使用。
2 分析结果
2.1总体趋势德国科研数据项目变化趋势如图1所示。正如上文所述,最初德国科研数据政策始于自身保证科学研究的严谨、规范和道德,再利用未引起关注。2001年10月“数字档案、图书馆和e-Science”研讨会上,提出将数据管理和数字保存整合在一起的数字管理概念。2002年,计算机图灵奖获得者Jim Gray指出需要创建数据馆藏和专门机构,以保障科研数据可以永久使用[4]。因此德国也在该阶段逐步开展科研数据管理类项目,并且随着数据的作用愈发重要,项目数量也呈现直线上升的趋势,并且在2011年和2016年经历了两次发展高峰。由于德国国家级科研项目主要由DFG进行资助监管,因此,检索DFG政策文本中包含“forschungsdaten”(科研数据)的条目,可以清楚的看出,政策层面在2011年和2016年前后,也都存在较为明显的高峰,如图2所示。具体来看,2010年,DFG发布“Informationsinfrastrukturen für Forschungsdaten”(科研数据信息基础设施),作为科研文献保障和信息系统开展科研数据项目资助[5],因此第一个波峰到来。之后随着科技的发展和信息时代的到来,科研数据有了更多用途,DFG2013年又发布了《确保良好科学实践的建议补充版》,规定了对科研数据的具体要求[6]。2014年,德国信息基础设施委员会成立,根据德国联邦教育和研究部制定的原则,其任务是“负责为进一步发展、扩大教育和科学数字基础设施提供跨学科和跨机构的建议”。规定明确了教育和科学数字基础设施是诸如图书馆、档案馆和科研数据收集单位,其任务为系统的参与收集和共享数据及信息。同年德国高校校长联席会议指出,高校必须制定与自身相应的科研数据指导方针[7]。在此背景下,2015年,DFG再次发布“Eine Ausschreibung im Rahmen des LIS Förderprogramms ‘Informationsinfrastrukturen für Forschungsdaten’”(文献保障和信息系统资助项目‘科研数据信息基础设施’框架下的招标公示)[8],明确了数据知识库为主的资助建设目标。德国第二个科研数据项目波峰到来。2018年以来,科研数据相关政策大量增加(见图2),主要是由于目前科研数据管理越发规范,针对其他科研项目的科研数据规定变多,但也可以预见未来德国科研数据类项目也会有较大的增幅。
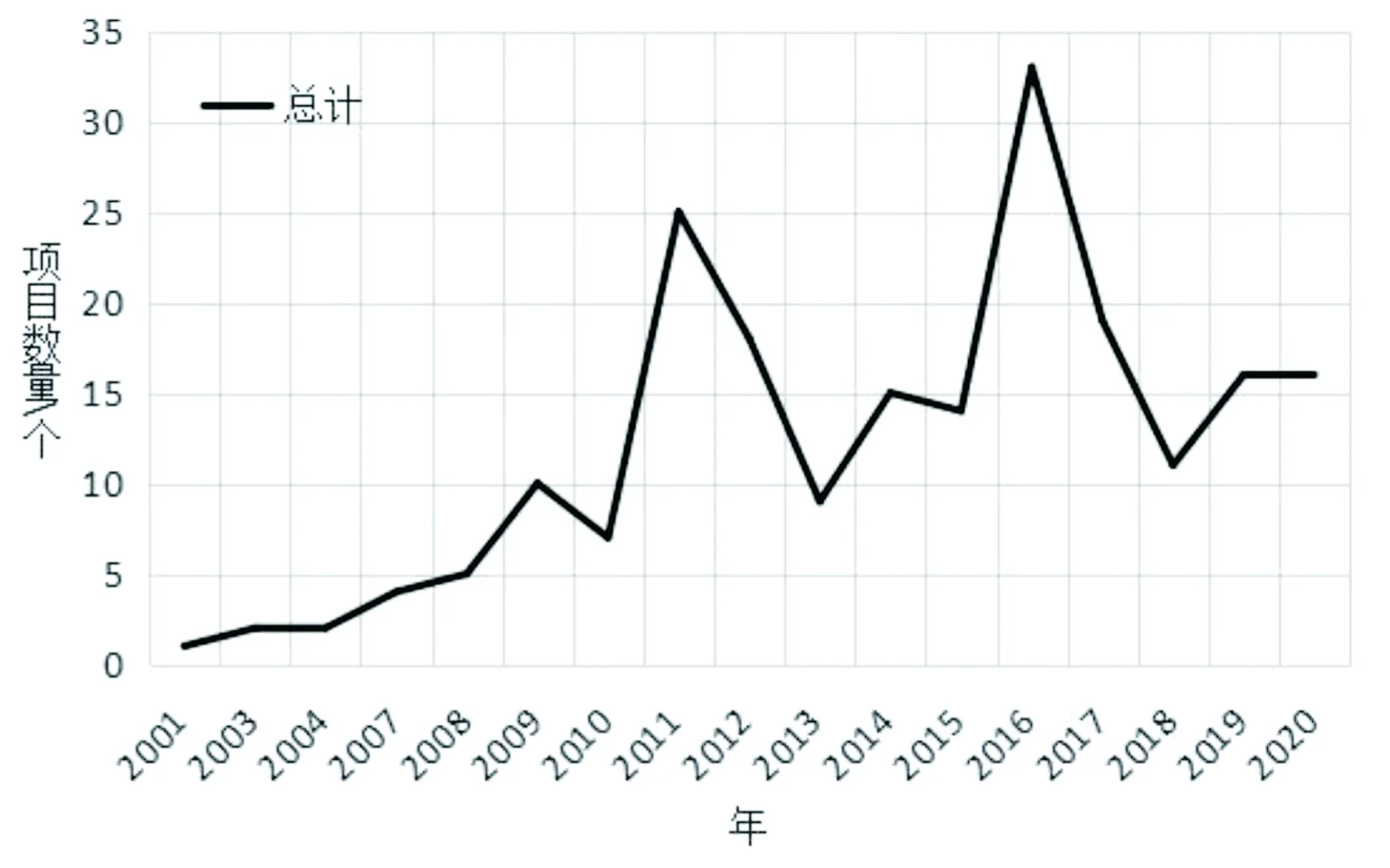
图1 德国科研数据研究项目逐年变化趋势
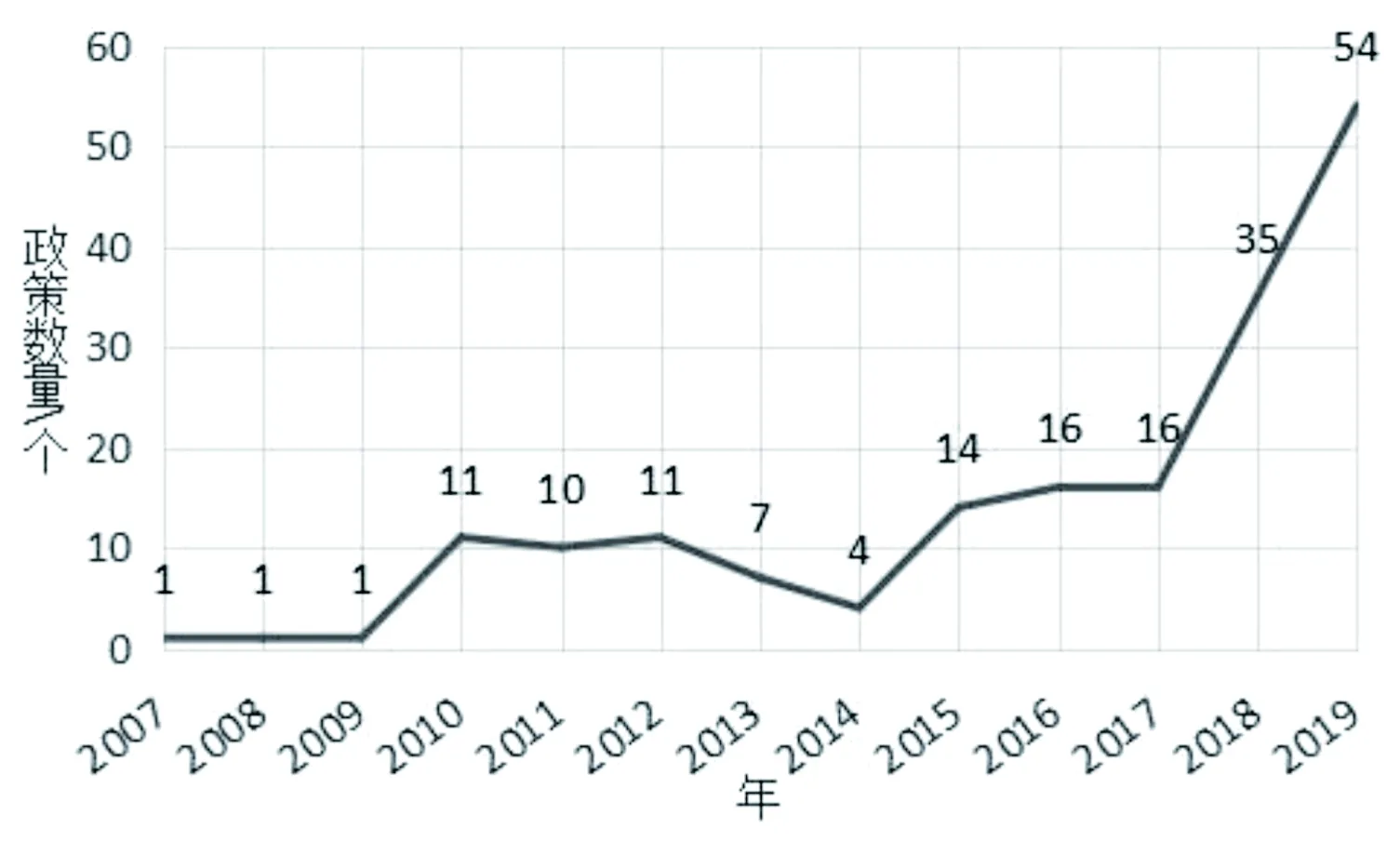
图2 包含科研数据内容的DFG政策数量逐年变化趋势
2.2学科变化特点讨论科研数据发展的特点,首要关注的问题就是学科变化,原因主要是:(1)科学数据顾名思义其核心是数据,而不同学科数据的属性不同,不同学科数据受到的技术发展水平影响的程度不一;(2)从治理角度上看,科学数据管理政策也多从专业进行划分,因而从学科讨论数据发展特点还有实际管理意义。德国科研数据类项目的学科变化如图3所示,其中数字代表的意义为:0-通用类项目、1-人文社科类项目、2-生命科学类项目、3-自然科学类项目、4-工程技术类项目。

图3 德国科研数据项目分学科变化趋势
2.2.1 第一阶段——文博类学科项目为主 在开始阶段(2009年之前),德国科研数据项目主要是人文社科类项目,而又以文博数据为主。其主要原因是文博类数据不同于其他学科,有大量存在博物馆、档案馆的资料可以进行数字化建设,而形成用于科研的基础学术数据,这些数据又具有公益性和便捷的可获取性,往往也不存在太多权益和共享机制问题,具有代表性项目包括Informationsnetz zur umfassenden Bereitstellung von digitalen Forschungsdaten archäologischer Feldprojekte (Ausgrabungen, Feldsurveys)(全面提供考古现场项目(挖掘、实地调查)科研数据的信息网络建设)、Bibliotheken und Archive im Verbund mit der Forschung: Digitales Ortsnamenbuch Online(图书馆和档案馆研究结合:数字地名簿在线建设)等。
2.2.2 第二阶段——数据密集型学科项目增多 在这一阶段,除了因为2010年DFG开展第一轮科研数据项目申请,原先人文社科类项目继续大幅增长外,生命科学类项目和自然科学类项目开始显著增多。这些领域也都具有数据密集和尺度规模较大的特点,因此在科研数据有一定基础之后,相关数据建设工作也便于开展。另外一个重要的原因可能在于,生命科学和自然科学数据相对规整,在研究方法、观测手段和仪器类别上也较为统一。据德国同期研究项目调查,有4/5的人文社科类和自然科学类研究项目都有机构标准或自有的元数据方案,这个比例在生命科学中为3/4,而在工程类项目中只有2/3。在具体学科领域中,生命科学中主要以生物多样性研究和传染病学为主,自然科学类项目主要以地理、地质学为主,如Kompetenzzentrum für Forschungsdaten aus Erde und Umwelt(地球与环境科研数据能力中心建设)、Entwicklung von Workflowkomponenten für die Langzeitarchivierung von Forschungsdaten im Bereich Erd- und Umweltwissenschaften(地球环境科学科研数据长期归档工作流程组成开发项目)等。
2.2.3 第三阶段——数据类型多样的工程技术项目涌现 自2015年开始,工程技术类项目开始明显增加。工程类科研数据由于涉及面更加广泛,数据类型、来源各式各样,因此在科研数据研究项目里出现最晚,往往需要在技术积累到一定程度之后才能有效开展。如2016年开始的EngMeta工程元数据项目开发的元数据方案组成元素就主要由现有方案,如DataCite、ExptML、PROV/ProvOne、CodeMeta、PREMIS等组成,单独构建的元数据元素很少。从学科特点来看,材料领域是工程技术开展科研数据研究的重要学科。主要原因在于,基础材料数据具有物性变量较为统一,数据较为规范的特点,其复用无需与论文挂钩,往往在研究中起到基础手册的作用,如Partikelmigration in zementbasierten Materialien bei hohen Scherraten(高剪切速率下水泥基材料中的颗粒迁移的科研数据)等。
2.2.4 现阶段——国家科研数据学科体系逐步确立 目前,以国家科研数据基础设施(NFDI)项目为标志,德国国家科研数据学科体系已经逐步确立。2018年8月,德国科学组织联盟发布了《关于制定联邦-州建立国家研究数据基础设施协议的讨论文件》,明确了德国将从国家层面开始进行科研数据基础设施建设。2019年第一批NFDI项目开始申请,包括化学国家科研数据基础设施项目(NFDIChemie)、国家工程科研数据基础设施(NFDI4ING)、文化遗产国家科研数据基础设施(NFDI4Culture)、文本语料资源科研数据基础设施(Text+)等22个项目,之后在2020年又有如人工智能和数据科学(NFDI4DataScience)、数学(MaRDI)等学科的国家科研数据基础设施建设开始建设[9]。
2.3开发重点变化科研数据管理按照数据生命周期包括数据的收集、处理、数据的分析、数据的长期存储、数据的复用等,而在每个环节中又涵盖不同的技术开发和应用邻域。而同时,项目的开展一般还会与技术发展程度相关,在不同时期往往项目特征不同。因此,本节将主要立足数据生命周期,讨论周期内不同时间段内的主要开发项目和重点,同时依照项目实施年代先后进行排序,以期发现不同工作的客观发展规律和未来整体趋势。
2.3.1 数据的收集阶段——侧重不同学科的数字化建设 这一阶段主要是在2013年之前,而且对于不同学科专业数据数字化建设的方式又有所不同。
a.文博数据的收集加工。正如上文所述,博物馆、档案馆和以地理为代表的基础学科拥有大量实物,所以,对这些实物进行获取/创建元数据、数字化/转录/转化是这一阶段文博数据收集的首要工作内容。从而使得文献处理方式、数据格式、元数据等一些基本技术和储备成为这一阶段的重点开发内容。具有代表性的有德国文本档案项目(Das Deutsche Textarchiv,以下简称DTA)。DTA的目标是汇编从17世纪初至19世纪末的德语文本,首先对于不同文本采用了人工和OCR相配合的数据采集方式保证了高精确度,之后,文献利用计算机辅助加工,使用自动标记化、词形化和POS标记方法,并利用DDC进行索引,便于查询。2011年德国社科类科研数据项目CLARIN-D也建议将DTA流程和格式作为“最佳实践”。同期如萨克森-安哈尔特州历史数据中心项目(Historische Datenzentrum Sachsen-Anhalt)、科隆数字档案项目(Das digitale Historische Archiv Köln)也都在加工处理历史资源数据上积累了开发管理办法。特别是萨克森-安哈尔特州历史数据中心项目利用注释和标识工具及各种数据信息的融合建立了该州重要历史人物传记的结构化信息,为之后的大范围应用进行了技术储备和示范。
b.其他学科注重虚拟研究环境的搭建。与文博数据不同,其他学科的数据往往产生于研究过程中,因此如何介入数据产生过程是数据收集的重要问题。搭建虚拟研究环境是这一阶段工作的主要内容。而且提供自动的数据收集工具可以减少耗费时间,提高科研数据共享意愿[10]。2009年,Beweissicheres elektronisches Laborbuch (实验室电子笔记本)项目开发了实验室记录工具BeLab,实现了实验室数据记录、保存和认证过程的自动化。同年Studiolo communis(为艺术和建筑史研究扩展建立一个互动工作环境)项目开始。其研发原型是文艺复兴时期艺术家创作环境。项目的核心是基于多媒体数据库(图像数据库、文献数据库、雕塑数据库、音乐数据库等)建立一个艺术家工作环境,科研人员可以在这个虚拟的工作室内进行各种如创建、编辑和构造媒体对象等工作,过程数据都可以方便保存。
相对而言社科领域和特定研究主题研究所需要的专特工具较少或较为单一,现代科学研究还需要现代化的协作平台和软件工具。具有代表性的包括:VFU soeb 3(用于社会经济报告的虚拟研究环境)是在社科经济领域支持不同空间分布的科研机构联合协作进行研究的虚拟平台。具体包括数据的交互和软件的使用(如SPSS、Stata、R语言)、实时的浏览和处理等。基尔科研数据基础设施(Kieler Datenmanagement Infrastruktur)项目由德国基尔大学和位于基尔的德国亥姆霍次海洋研究所联合搭建。基尔作为最重要港口城市是德国海洋研究的重要基地。大学成立数据管理团队,搭建海洋和地球科学的虚拟研究环境,并提供模块化组件,用于数据输入、文档、发布和协作。
大量研究虚拟环境的搭建是否取得成功?DFG在2013年开展DFG-VRE(DFG-虚拟环境建设与可持续发展的成功标准)项目,研究如何才能成功建设虚拟研究环境。报告从用户、运营者、资助方三个角度给出了虚拟环境搭建有效性的测量标准,分别认为学科研究特点、接受程度和工作/知识流动便易、可互操作性、模块化以及加速结果产出、平台的再利用程度是成功的关键[11],避免了一拥而上导致的资源浪费。
2.3.2 数据处理阶段——数据的深加工及关联集成 数据密集型科研方式的基础就是如何快速有效地对科研数据进行关联和分析,以加速知识的发现[12]。科研数据的机器可读性成为必需,从而帮助和增强人类处理与集成科研数据的能力。而同时,许多机构(例如档案馆、博物馆)管理自己的数据库,但是由于使用的数据模型不同,格式和基础结构使在标准数据的基础上进行合作开发变得更加困难。所以,2011年开始德国科研数据项目深层次加工的主要问题就是语义加工和数据关联,这也成为之后FAIR原则的核心问题之一。由于早期的科研数据主要集中在GLAM数据和地理信息数据,因此作为数据关联重要基础的规范文件就成为开发的必要条件。这一时期主要项目包括:IN2N(Institutionenübergreifende Integration von Normdaten规范数据的跨机构整合)项目的目的就是促进跨机构开发和维护规范数据文件,打破重用和维护规范数据领域一直存在的技术和组织障碍。LAUDATIO(Long-term Access and Usage of Deeply Annotated Information,长期访问和深度注释信息使用项目)项目建设了历史语料库,可使用搜索和可视化工具ANNIS在语料库中进行搜索和注解,并支持在知识共享许可下开放访问、搜索和下载,一方面知识得到充分溢出加速了使用,另一方面也保证了知识更新的可持续性。而LIFE(Linked Data for eScience Services,e科学服务下的关联数据项目)则更近一步,执行方明斯特大学(ULB)地理信息学院语义互操作性实验室(MUSIL)和大学图书馆利用语义组织,将文献数据中的时空数据进行关联,便于科研人员进行时空检索。
2.3.3 数据的保存阶段——充分利用公共科研数据基础设施 在一些数据密集型学科、领域具备数据和相应技术之后,一方面数据的统一发现亟待增强,另一方面一些数据产生相对较为分散、规模相对较小的学科也需要相关科研数据管理服务。在此背景下,从2013年开始,一些公共的科研数据基础设施项目开始实施。其中较为典型的项目包括re3data.org(Registry of Research Data Repositories,科研数据存储库注册)和RADAR(Research Data Repositorium,科研数据知识库)项目。其中,re3data.org为已建成的数据知识库建立名录,方便科研人员查找数据专业或通用保存设施[13]。而RADAR项目则是要建立一个通用数据存储库,直接服务于仍然缺少科研数据管理服务的细分学科专业(“小科学”)。RADAR项目针对的是科研人员个体(例如在项目中)和机构(例如图书馆),提供两种服务:只有简单元数据和与格式无关的数据归档的跨学科入门级产品;提供包括数据发布、DOI分配、集成归档和数据检索并通过国家和国际专业门户网站提供下载的扩展级产品。因此,RADAR不仅为缺失科研数据基础设施的细分学科领域提供基础服务,避免了与特定主题的数据知识库互相竞争,而且也为扩展国内和国际信息创建了一个基础构建块,利用该基础设施服务可以通过接口集成到其他第三方服务(例如外部数据中心、专业协会和出版商)中。
2.3.4 数据利用阶段——加深FAIR原则 随着2016年正式发布FAIR原则,可发现、可访问、可互操作、可重用成为提高科研数据开放性、透明性和可重用性的准则[14]。FAIR原则的首要问题是可发现,而可发现最重要的是有清晰的标识符。国际通行的数据标识符主要为数字对象唯一标识符(DOI),但对于直接产生数据的科学软件却还没有相应标识。而科学进步越来越取决于软件的使用和开发。但由于版本不同或者其他软硬件的配置不同,可能会导致明显不同的结果。在此背景下,Sciforge(Publikation und Zitierbarkeit wissenschaftlicher Software mit persistenten Identifikatoren,具有永久标识符的科学软件的发行和引用项目)开始实施。与数据出版物相似,科学软件的发布和引用应符合科学标准,并使用持久标识符(DOI)进行。为此,Sciforge项目搭建了一个由科研人员、项目、机构/领域、出版社和DOI系统组成的平台,组织上,DOI组织通过代理为出版社、机构/学科社区提供标示符,技术上以分布式版本服务器(DVCS)为核心关联DOI系统和软件的发布,并集合软件开发和评价所需要的如API、知识库、授权认证、计量指标等其他功能。
当然只有标示符还远远不够,不完整的文档、质量不明确的文件也使得数据在结果、理解、重用和可重复性变得更加困难。而同时机器可读的、自动的检查、检测元数据文件、有效的说明文档是在科学产出密集情况下,实施FAIR原则的重要保障。因此,德国也从机构源头开展一些列科研项目,着力从科研人员和机器辅助两个层面建立数值质量保障体系。比勒菲尔德大学图书馆2016年开始实施Conquaire(Continuous quality control for research data to ensure reproducibility,确保可重复性的持续对科研数据进行质量控制)项目,通过持续集成的手段(Continuous Integration,以下简称CI)实现科研数据可再现性的质量控制。持续集成是基于互联网敏捷开发过程,通过日常编译和自动化测试来及时发现提交代码问题的重要方法。在CONQUAIRE项目中,按照此原理对科研数据进行连续监控,科研人员可以在研究早期将其数据和脚本提交到分布式版本控制系统(DVCS)中,建立相关检验测试程序,实现再现性。在研究中,过程数据也需通过之前设定的测试,实现在CI中发现错误,保障最终科研数据的可再现性。而对于一些小型科研机构或者传统学科领域,则主要通过在采集、分析和保存的良好实践保障科研数据负责质量原则。如德国柏林水技术中心有限公司承担的小型科研机构科研数据管理项目FAKIN[15],按照数据的全生命周期,从文件命名、说明文件、元数据、源代码等方面制定规则,从而可以有效避免科研数据中发生无意义信息、错误描述、歧义性描述、版本混乱、元数据不规范的常见错误。同时该方案具有较强的可操作特性和规范性,易于对数据进行溯源,也具备较强的机器可读性,便于数据复用。
3 德国科研数据项目建设特点
3.1 GLAM一体化发展,构建数据基础设施科研数据管理的基础是数据资源。博物馆、档案馆存有大量数据,这部分数据在共享上又不存在着较为复杂的利益关系。同时这些数据既是人文学科研究领域必不可少的基础数据,又在技术-人文交叉越来越多的背景下对科学技术创新又有辅助作用。因此,德国在发展科研数据管理中,将美术馆、图书馆、档案馆和博物馆(GLAM)的数据都纳入科研数据管理的范畴,推动了这些机构的数据进行组织和再利用。而从整个科学体系来说,学科交叉越来越大,人文与科学技术的关联越来越紧,因此,集成文博数据是构成整个数据基础设施的重要关键步骤。
3.2德国科研数据学科体系强调前沿科学德国国家科研数据的学科体系不仅包括化学、工程、地质、地理信息、植被等传统支撑性科研数据基础设施,还包括如文本语料资源、人工智能、数据科学、数学等当前科技应用前沿。目前,数据要素已经成为经济社会发展的新动力。而这些学科科研数据的经济价值、社会效益更高,数据的生产要素特性更强。而且在这些领域,国际上知名的科研数据中心也较少,因此,从这个层面上看,德国举全国之力建设这些学科的科研数据基础设施,未来更有可能变成领域内国际数据枢纽,数据的汇集力会更强,数据加速创新效果更好。
3.3国家级项目为科研数据管理发展提供了良好示范作用在科研数据发展过程中,德国通过DFG和各个部委,设立专项科研数据类国家级项目,为科研数据管理发展提供了良好示范作用,并体现在以下三个方面:一是在学科上,德国国家级项目包括社会学科、自然科学、工程技术、文化遗产,具备专业学科的普遍性;二是在技术上,涵盖科研数据管理和服务全生命周期过程中的核心技术,包括数据管理计划、数据的转化/转录、数据的加工和关联、发现系统设计、数据元数据方案的制定、数据的长期存储、数据的FAIR原则、数据的核验等,这些都是服务于数据最终再利用的核心技术,因而具有良好的知识溢出效果;三是在时间上,具有一定承接关系。比如在文本数字化过程中,首先立足于扫描过程的标准化,在此基础上,才进行数据关联发现原型的开发,进而逐步扩大规范文件建设,将数据关联做大做深。
3.4以数据密集型学科和领域为引导,注重发展规律和技术储备一是数据密集型学科和领域除了上文所述的文博数据,还包括如地理信息、地质学等自然科学、传染病、生物多样性等生物医学和社会学、经济学等社哲科学等,这些领域数据积累已经较为成熟,研究范式也较为统一,引导示范作用明显。二是科学的进步需要遵循科学发展规律,所以,科研数据实施能否取得成功也要注重自身的发展规律。德国在科研数据建设中在数据收集之后,首先开始以数据加工、语言组织的数据关联工作为主;其次,以科研人员为中心,开展虚拟平台的建设,从外部环境上为科研数据的共享提供便利;再次,在积累了足够经验之后,建设不同公共、通用科研数据基础服务设施,推广科研数据管理,同时对于数据质量的提升,着力发展FAIR原则;最后在微观上的科研素养、科研数据管理服务较为成熟后,开始按照生态理念打造全科学体系的数据基础设施建设。三是科研数据管理在文本处理、图像处理、音视频数据处理、数据的关联、规范文件的制定以及数据质量、FAIR原则检测等领域有较为通用的技术,因此有效的技术储备可以有效节约科研数据管理服务开发的资源投入。德国在项目执行过程中,进行了如文献数据加工流程、语义组织关联、虚拟环境搭建评判准则等一系列工作,其具有极强的通用性,对技术进行了有效积累,使未来的工作有了参考依据。
4 借鉴和启示
目前,从政策层面看,我国已形成由以政府、行业机构和领域数据中心为主体的数据政策体系;从共享实践层面看,既包括政府、科研机构,也囊括企业社会力量。但正是由于这种相伴而生的共享实践,导致我国科研数据基础设施整体规划有所不足,大部分科学数据依然保存在项目组或个人手中。同时,机构开展科研数据管理服务又存在着较大差距,只有少量机构建有较为完整的数据知识库,大部分机构的数据管理服务处于起步阶段或还为空白。所以,探索德国科研数据项目建设历程发现其运行规律,对我国相关建设具有较强的借鉴意义。
4.1融合文博数据,减少内部条块分割虽然2018年颁布的《科学数据管理办法》对于科研数据有明确定义,2020年公布的《科学技术研究档案管理规定》对研究档案也进行了充分的定义。但在科学研究、工程技术中需要的数据需求范围往往很大,超出了科研数据定义的范畴。因此,在数据的使用、流动过程中,可能存在着范畴界定不对等的情况,导致在使用过程中可能存在上游数据不全,从而无法真正利用数据资源加速科学研究的进程。所以,我国在进行科学数据建设时,可以在操作层面融合其他领域的数据。具体来看,国外GLAM机构呈现出鲜明的一体化趋势,而国内主要涵盖的还是研究机构或高校图书馆,尚未涉及档案馆、博物馆等文博机构,数据行政性条块分割较为明显,但数据体系区分又有所不清。其实在一些科学研究中,文博数据必不可少,特别是在人文社科研究、建筑、规划等区域研究中,这类数据作用明显。因此,整合包括GLAM等所有机构的数据,形成数据基础设施,并按照应用场景进行联合建设是实现数据密集加速科研产出成效的必由之路。同时充分利用这些现成的数据也是进行必要先行技术开发的有效手段。
4.2健全我国科研数据学科体系,抢占前沿尖端学科数据优势我国科学数据中心在学科上主要以基础学科为主,数据类型也侧重于空间、地理、植被等支撑性数据,前沿科学数据较少。而目前德国规划的科学数据基础设施建设涵盖工程、经济、教育等各类学科。特别是在人工智能、神经科学、数据科学、文本语料等尖端、前沿科学领域,都规划建立相关科学数据基础设施,这些数据的科研价值、经济价值更高。所以,我国首先应该健全我国科研数据学科体系。其次,发挥在战略性新兴技术上的优势,以“十四五”规划和2035年远景目标规划中重点建设的前沿性科学和引领性技术为主,抢先布局科学数据建设体系。特别是一些以建设国际科技创新中心的城市目前都在积极建设新兴研发机构,建议现阶段参考新型研发机构的体系布局,以量子、脑科学、人工智能、区块链、纳米能源、应用数学、干细胞与再生医学等学科领域为主,率先重点建设一批科学数据基础设施。同时,注重典型示范引领,逐步扩大我国科学数据建设体系。
4.3启动国家科研数据科研项目建设目前,在我国充分发挥集中力量办大事的组织优势,依托中科院系统、部分专业院所和北京大学、清华大学等部分高校,初步建成了如国家基础学科公共科学数据中心等科学数据平台,在地方层面,广东、陕西等建有省级科学数据平台,对科技创新起到了重要支撑作用。但由于财政支持的阶段性较强,数据的技术、标准往往还不成熟、不完善,即便存在一些技术研究成果也往往集中在项目组、成员单位范围内,一方面无法实现技术方案共享,财政经费利用效度不高,另一方面,也造成了各个平台技术标准不一,对于未来的互联互通方面带来障碍。而德国在科研数据发展过程中,始终通过设立国家级科研项目,解决技术中的难点,发挥知识溢出、示范效果。因此,参考德国模式,我国也应该尽快设立国家级科研数据类科研项目,组织上,设立科研数据项目专项资金,解决领域内重点技术问题,同时在自然科学基金和社会科学基金中都要固定一定比例持续支持相关领域前沿研究;内容上,项目支持领域应覆盖数据的全生命周期,既要涵盖主要阶段内的重点技术,如采集标准、元数据规则、数据关联等,也要重点解决当前领域内全球热点问题,如科研数据实施FAIR原则等系列技术。
4.4尊重科研数据发展的客观规律我国科研数据服务研究主要包括两个阶段,初期主要集中在科研数据服务的内涵、国际现状等解决“是什么”的问题;目前则重要集中于服务实践,主要解决“怎么办”的问题,包括数据政策、管理实践、平台建设、制约和刺激因素、馆员能力、数据标准和规范等方向。在机构执行层面,除了中科院系统、部分专业院所依托自身数据云和/或国家科技基础条件平台外,大部分高校、科研机构的科研数据建设还较少。而且即便是建成了一些平台,也存在诸如重复建设、数据量有限、重建轻用等问题。研究层成功向执行层转化的还比较少。大部分学者认为图书馆应从技术支撑、科研数据组织、科研数据服务、用户信息素养教育等方面进行科研数据管理服务,并从整体服务内容或是某项单独服务能力两方面进行了大量研究。但其本质是围绕科研数据生命周期同时进行工作,但大多没有考虑科研数据发展的客观进程和规律。纵观德国科研数据发展的历史,始终遵循数据先行、技术储备、项目示范和全面开展等领域发展规律,比如没有过分强调数据共享等结果,而采取了首先搭建虚拟研究平台、开展公共通用基础设施建设来增强科研人员的共享意愿,也并没有过多研究政策设计、激励刺激因素等。因此,针对我国现实情况,各研究机构应首先判断自身在科研数据发展的阶段,从客观规律出发着力加强自身建设,进行技术储备。而对于部分已经具备较强硬件条件的单位,也需要在综合研判学科发展的基础上,补充可能缺乏的一些软件设施。
