基于突发词对主题模型改进算法的微博热点话题发现研究*
2022-01-28向卓元张芙玮
向卓元 吴 玉 陈 浩 张芙玮
(中南财经政法大学信息与安全工程学院 武汉 430073)
0 引 言
随着移动互联网的快速发展,微博、贴吧等社交媒体得以蓬勃发展,用户生成的社交媒体信息量呈现爆炸式的增长,同时互联网将产生海量的短文本信息。新浪微博是国内大型网络媒体之一,人们可以不受时间、空间限制,实现实时分享与传播互动。当某一个话题爆发时,微博对事件能够做出快速的反应,用户可以通过PC端、移动端等方式获取有关话题信息,或者参与信息交互(转发、评论、点赞等操作),在短时间内形成舆论焦点,从而使该话题形成一个热点话题。因此,微博具有短文本性、实时性和交互性的特点。如何从海量的短文本数据中高效、准确地挖掘热点话题是目前舆情分析中的一个研究热点问题。
1 相关工作概述
梳理已有文献可以发现传统主题模型[1-3]是为挖掘长文本主题设计的,当应用这些模型来处理短文本时,会面临数据稀疏、语义信息匮乏、向量维度高等问题,从而无法从短文本中有效的挖掘文本主题信息,失去了在长文本话题发现中所发挥的优势。
近些年来,为了解决短文本的数据稀疏问题,部分学者通过语料数据文档的词对共现信息来学习主题。Yan等人在2013年提出词对主题模型(Biterm Topic Model,BTM)[4],通过构建词对解决短文本的稀疏性问题,实验表明该模型挖掘的话题质量不受文本长度的限制,在短文本上同样取得较好的效果;但BTM模型挖掘的主题可能属于普通话题,也可能属于热点话题,因此无法直接用于热点话题发现。王亚民等[5]利用BTM模型进行微博舆情热点发现,与改进TF-IDF算法进行特征提取及相似性度量,解决了传统短文本主题模型的高维度和稀疏性问题。李卫疆等[6]结合BTM话题模型和K-means聚类算法来检测微博话题,缓解了短文本数据稀疏的问题。这些主题模型及其改进方法虽然能解决短文本的稀疏问题,但是无法直接用于发现热点话题,需要一些启发式后处理等工作。Hoffman等[7]提出了在线主题模型(Online for Latent Dirichlet Allocation,OnlineLDA),但仍然存在需要手工标注话题数目等后处理问题。M.Gerlach等[8]提出的hSBM模型通过调整具有非参数先验的随机块模型(SBM),获得了一个更通用的主题建模框架,它能够自动检测主题的数量,并对单词和文档进行分层聚类。分析表明,在统计模型选择方面,SBM方法比LDA方法能得到更好的主题模型。
为了解决BTM模型无法直接应用于短文本热点话题发现的问题,Yan等[9]在2015年提出了突发词对主题模型(Bursty Biterm Topic Model,BBTM),将词对突发概率作为模型的先验知识,可直接用于突发话题的发现。黄畅[10]改进BBTM模型,提出热点话题发现方法(Hot topic-Hot Biterm Topic Model,H-HBTM),用传播值来量化词对热值突发概率,设计了一种自适应学习话题数目的方法。林特[11]改进BBTM模型量化词对突发概率方法,提出了一种结合基于自动状态机的枚举突发词对和正态分布的方法来量化突发词对。
为了考虑词语间的语义信息,沈兰奔等[12]结合注意力机制和BiLSTM用于检测中文事件。Yuan等[13]在2016年提出的词共现网络模型(WNTM)将文档中的词共现信息构建成词网络,提高了数据空间的语义密度。彭敏等[14]提出了一个基于双向LSTM语义强化的概率主题模型,强化语义特征之间的关系。和志强等[15]提出了基于双向LSTM的短文本分类算法,该算法能够有效解决短文本分类过程中语义缺乏的问题。
也有学者致力于将人工神经网络结合主题模型来研究短文本主题挖掘。Li等[16]提出了一种基于反馈递归神经网络的主题模型,将LSTM与主题模型结合,提升了模型挖掘文档集合主题的效率。石磊等[17]利用RNN来学习词之间的关系作为先验知识加入到稀疏主题模型,结合主题模型发现社交网络突发话题。张翠等[18]将CNN和BiLSTM获取的特征进行融合,能充分理解上下文信息,有效提取文本特征信息。Chitkara等[19]提出了一种具有自我注意力的层次模型,将深度学习技术应用于话题发现。
由上述内容可知,主流主题模型存在未进行特征选择、没有考虑词语之间语义信息、未削弱高频中性词对主题的影响、需要人工指定话题数目等问题,针对这些问题设计一种基于密度的BiLSTM-HBBTM的最优话题数目选择方法,提出基于双向长短期记忆网络的热点突发词对主题模型(BiLSTM based on topic-hot Bursty Biterm Topic Model,BiLSTM-HBBTM)。
2 基本概念
2.1微博传播值微博传播值的计算如公式(1)所示。传播值越大,则该微博越有可能是热点微博。
spreadd=γ·max{ln(repd),0}+χ·
max{ln(comd),0}+μ·max{ln(attd),0}
(1)
其中,spreadd表示微博文档d的传播值,repd、comd、attd分别表示微博文档d被转发数、被评论数、被点赞数。γ、χ、μ分别表示微博文本被转发、评论和点赞对微博传播值的影响权重。当spreadd=0时,将该微博标记为噪声微博并将其删除。
2.2词项H指数受到Hirsch[20]提出的H指数的启发,本文提出词项H指数,将每篇微博文档被转发数作为该篇文档每个词语的被浏览次数。词项H指数的定义如下:假设有N条微博中包含词项wi,并且有H条微博的被转发频次大于或等于H次,那么该H值就是词项的H指数,用来确定该词项对微博语料库的重要性。
2.3词对先验知识为了解决BBTM模型没有考虑词语之间关系的问题,本文在BBTM模型的基础上融入了词对之间的关系作为共现词对分布的先验知识来强化词对主题的相关性。
基于BiLSTM的先验知识框架如图1所示。首先,BiLSTM-HBBTM使用词嵌入算法表示文本向量,引入BiLSTM来学习词之间的关系。其次,为了过滤高频中性词对于主题质量的影响,BiLSTM-HBBTM将改进词语的逆文档频率(IDF)作为先验知识的一部分。将BiLSTM的输出信息和IDF结果的加权值作为模型的先验知识。
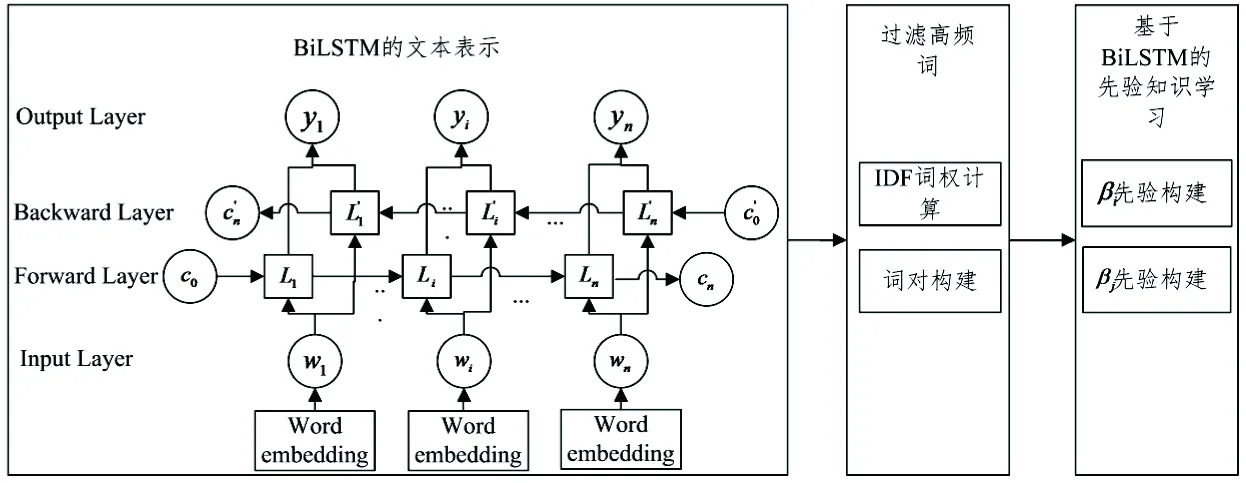
图1基于BiLSTM的先验知识框架

根据Yan等[9]对BBTM模型的分析,在时间片t上词对b的突发概率估计方法如式(2)所示。
(2)
2.5词对热值突发概率词对热值突发概率γb,t可以表示为词对b在t时刻的热度值φb,t相对于历史平均热度值φb,h的增长率,φb,t和φb,h的计算如式(3)和(4)所示。
(3)
(4)
词对热值突发概率γb,t如式(5)所示:
(5)
其中,δ用于过滤低频词对,s表示相关时隙大小,Mt表示t时隙内的微博数目,spreadi,b指词对b所在微博i的传播值。
3 BiLSTM-HBBTM算法设计
3.1算法步骤BiLSTM-HBBTM算法步骤如图2所示,以下各节对主要部分进行详细阐述。
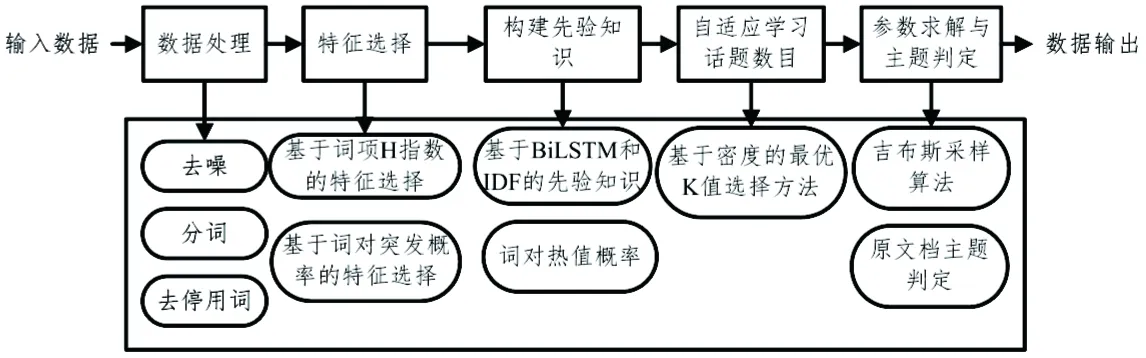
图2 BiLSTM-HBBTM算法流程图
3.2特征选择微博中的词可以分为热点词和非热点词。热点词是指与热点话题相关的词, 在文本中出现的次数具有短期突增的特点,利用词项H指数和词的突发特性选择微博特征, 选择词项H指数在前80%的词以及突发概率大于阈值ω的词作为微博的特征词。这样筛选出来的词能够更利于热点话题的发现,为后面建模减少了维度,降低了数据稀疏性和计算效率。特征选择算法如算法1所示。
算法1 特征选择算法
输入:数据处理后的文本集text,词突发概率阈值ω,相关时间片段s
输出:文本特征集text_features
1.sorted(repw,reverse=True) /按每个词的被浏览数降序排序/
2. calculateHw/计算词w的H指数/
3. sorted(Hw,reverse=True)
4. ifHw排序在前80%
5. 将词w加入text_h
6. forwi,wjin text_h
7.b=(wi,wj) /获取词对/
12.将词对b加入text_features
13. end for
3.3词对热值概率化BBTM模型中的词对突发概率只考虑了词出现的频次,但是与热点话题相关的微博不只是表现为相关的微博数量变多,还表现为微博的评论数、转发数和点赞数增多。热点词是热门微博文本的组成部分,同时具有突发性和传播性。因此,将词对热值突发概率代替词对突发概率作为BBTM模型的先验概率。词对热值概率化算法如算法2所示。
算法2 词对热值概率化算法
输入:文本特征集text_features,相关时间片段s
输出:(b,γb,t)
1.b=(wi,wj) /读取词对/
2.calculateφb,hby formula (5)
3.calculateφb,tby formula (6)
4.calculateγb,tby formula (7)
3.4自适应学习话题数目按照主题相似度最小时话题质量最佳的原则,在平均主题相似度最小时确定自适应学习主题数K。根据文献[21]中的基于密度的自适应学习话题数目的选择方法,本文采用词嵌入Word2Vec算法的方式来表示话题向量。由于向量维度太高会淡化词之间的关系,维度太低又不能将词区分,因此将话题向量的维度设置在300维。改进的确定话题数目方法称为基于密度的BiLSTM-HBBTM最优话题数目K值确定方法。BiLSTM-HBBTM算法中的词嵌入模型使用基于负方向采样的Skip-gram词向量来训练模型微博文本向量。基于密度的BiLSTM-HBBTM最优K值选择方法的基本过程如算法3所示。
算法3 基于密度的BiLSTM-HBBTM最优K值选择算法
输入:(b,γb,t,maxKit)
输出:K
1.随机初始化话题数目K,K∈(20,100)。set flag=-1,simHis=1,topic=K,simBest=1。
2.while话题数目K不再改变时 or 达到最大迭代次数
3. CalculateSimavgby formula (12) and(13)
4. ifSimavg>simHisthen
5.flag=-flag
6. else
7.flag=flag
8. ifsimBest>Simavgthen
9.simBest=Simavg,simHis=Simavg,topic= K
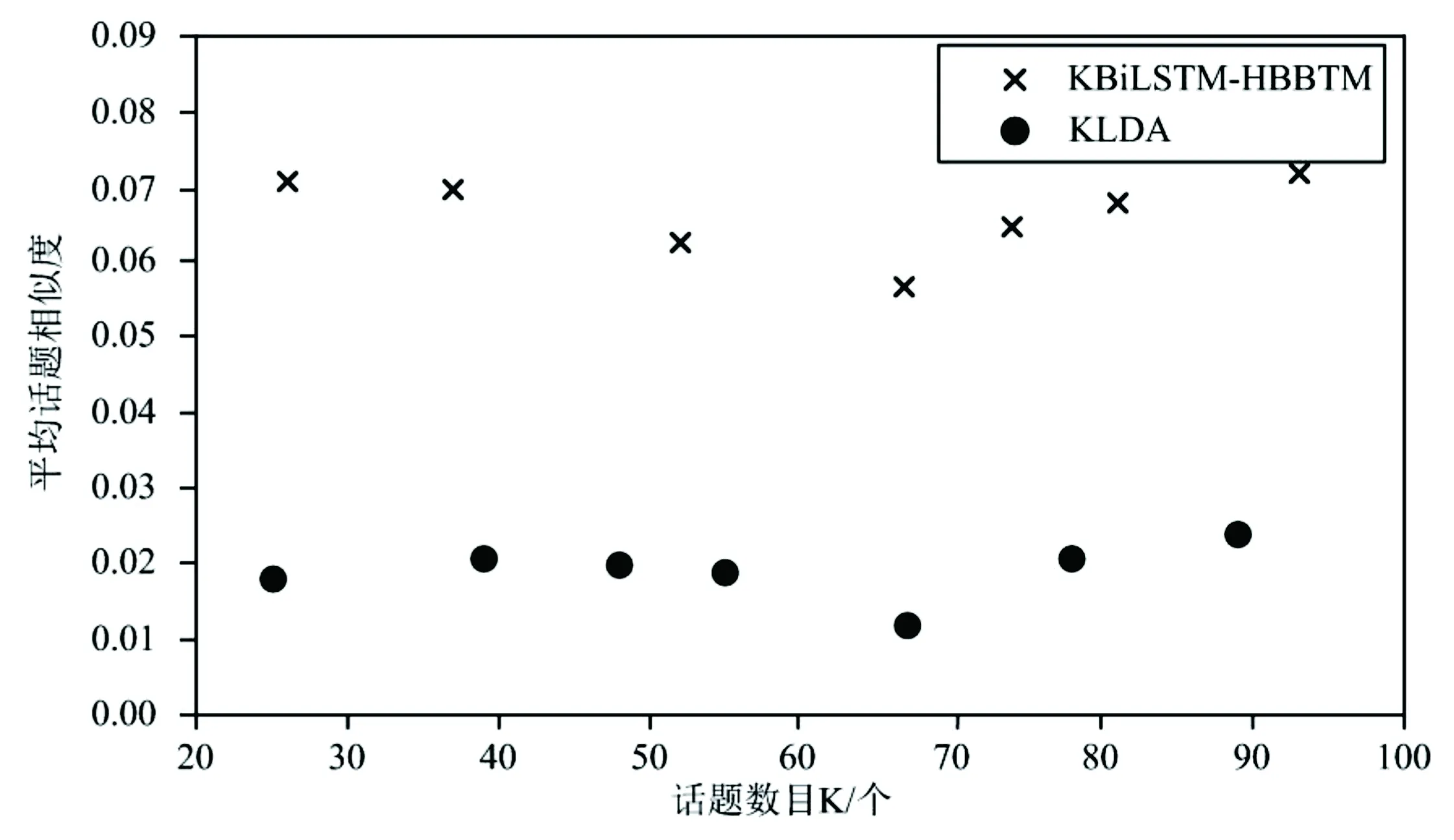
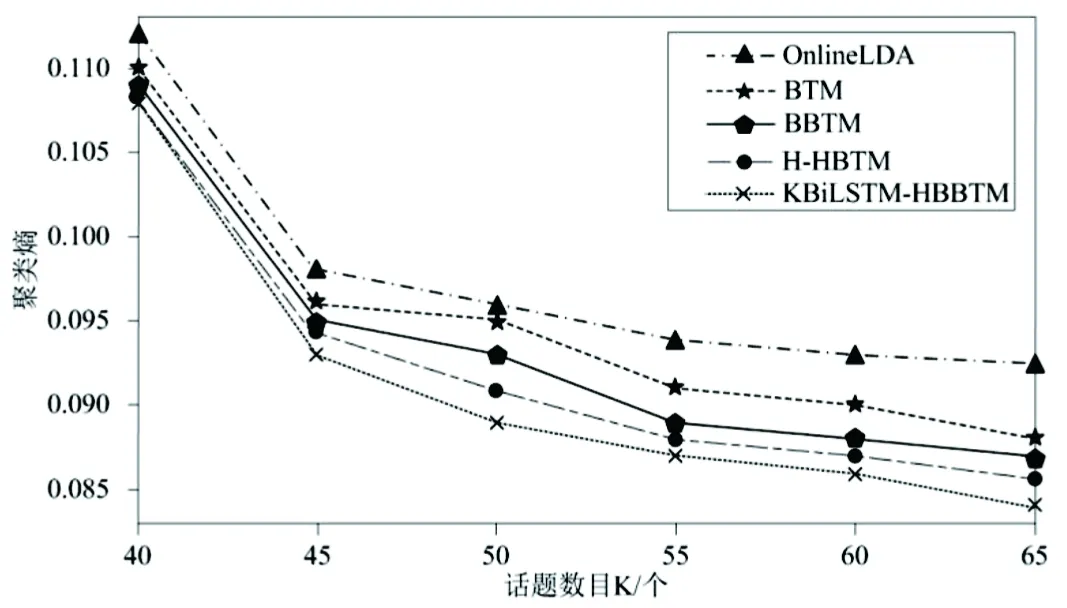
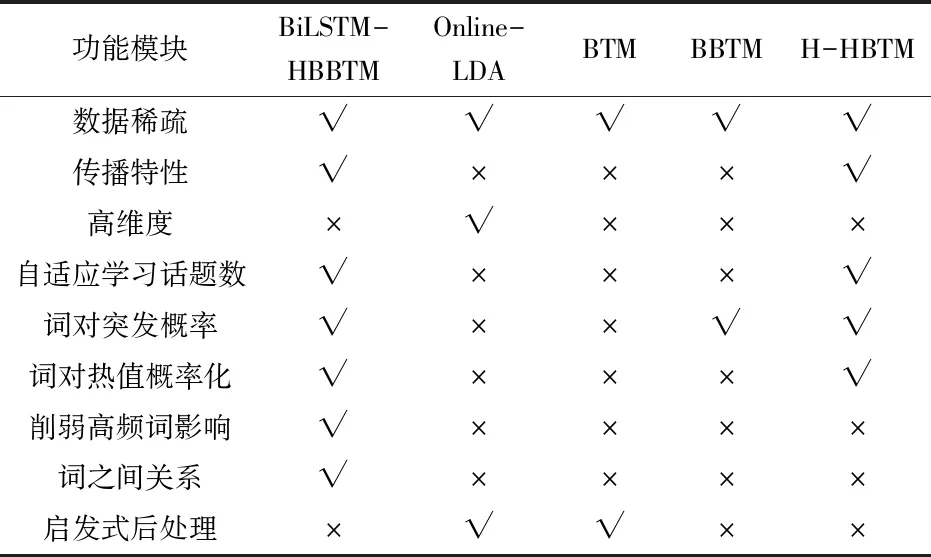
10. ifsimkd 11.统计每个话题的话题密度 12.计算噪声话题数C,即话题密度小于K/3的话题数。 13. update K,K=K+flag×C 14.return K 3.5模型参数求解BiLSTM-HBBTM用Gibbs采样方法对参数进行求解,需要采样的参数变量有z,θ和φ。词对的条件概率分布分别如式(6)和(7)所示。 (6) (7) 经过足够次数的迭代后,收集统计信息并逐一更新每个单词对的主题类型表示变量和主题分配。这些统计信息可用于估计各种参数。在达到最大迭代次数之后,将学习到的参数的平均值用作参数估计值。最后,推导出微博热点话题分布和单词分布参数结果,如公式(8)和(9)所示。 (8) (9) BiLSTM-HBBTM的吉布斯采样算法具体描述如算法4所示。 算法4 BiLSTM-HBBTM吉布斯采样算法 输入:(K,α,β,B) 输出:(θ,φ) 1.随机初始化e,z 2.foriter=1 toNiterdo 3. for eachbi=(wi,1,wi,2)∈Bdo 4.从式(8)和(9)抽取ei,k 5. ifei=0 then 6. updaten0,wi,1,n0,wi,2 7. else 8. updatenk,n0,wi,1,n0,wi,2 9. end for 10.end for 11.returnθandφ 4.1实验环境本章实验均是在 Intel(R)Core(TM),i5-8250U CPU,1.60GHz的主频, 8GHe内存,Windows 10操作系统上进行的。应用软件采用3.7版本的Python程序结合2019.3.1版本的JetBrains Pycharm进行实证分析。 4.2数据集本文选取对热点事件传播影响力较大的官方微博,通过Python爬虫抓取从2020年1月1日至2020年3月31日的微博,共计151 240条构成本实验原始数据集,用于发现疫情期间的微博热点话题。其中,每条微博数据包括发布时间、微博正文、点赞数、评论数以及转发数。 4.3参数设置 4.3.1 词对突发概率阈值 BiLSTM-HBBTM在特征选择中的词对突发率阈值ω的取值大小会影响到最后话题的质量。ω的取值范围为(0,1),如果取值太小不能有效的过滤非突发词,取值过大则容易丢失部分突发词,因此进行了阈值ω变化对话题质量影响的实验。实验结果如图3所示。实验结果纯度(Purity)指标的值越大表示话题质量越好,从图中可知,参数ω取0.4时纯度最高,说明此时生成的话题质量最好,因此实验中参数ω的取值为0.4。 图3 参数ω的实验结果 4.3.2 其他参数 根据参考文献[7],OnlineLDA的参数α,β分别为0.05,0.01;BTM、BBTM、BiLSTM-HBBTM中的参数根据文献[4]和[8]的思想,设置为α=50/K和β=0.01,热点主题的数量从20个到100个不等。Gibbs采样过程的迭代次数都设置为1000次。根据文献[10],H-HBTM,BiLSTM-HBBTM的其余参数取值为:s=4,δ=1,γ=0.7,χ=0.2,μ=0.1。 4.4评价指标 4.4.1 主题相关性评估 a.平均话题相似度。根据文献[21]的思想,主题间平均话题相似度最小时模型发现的各个话题相关程度最低,表明此时模型达到最优。两个文本向量k和d的相似度Simk,d用余弦距离与IDF结合计算,能够削弱高频中性词对主题的影响,文本的相似性计算方法如公式(10)。 Simk,d= (10) 式中,ki表示k向量对应i维上的值;di表示d向量对应i维上的值。 用两两话题向量间相似度的平均值来表示平均话题相似度,其计算公式如式(11)。 (11) 式中,Simi,j是第i个话题与第j个话题之间的相似度,n表示为话题向量维度。 b.点互信息。受到信息论中互信息的启发,本文主题一致性评估采用点互信息(Pointwise Mutual Information,PMI)指标,点互信息的值越高,说明词语的相关性越大,越能解释同一个主题。本文PMI计算公式如式(12)所示。 (12) 其中,w1,w2,…,wN为主题z前N个可能的词,p(wi,wj)是词对 4.4.2 话题质量评估 a.平均准确度。将在不同热点话题数目K下的平均准确度(P@K)作为发现热点话题准确度的评价指标。将算法生成的话题随机混合在一起,邀请7个志愿者根据给出的话题信息对生成的热点话题进行人工标注。一个话题被认定是热点话题的标准是:当有超过50%志愿者都将该话题标注为热点话题,则该话题被认定是一个热点话题。平均准确度计算如式(13)。 (13) 其中,K为算法生成热点话题数目,Kv为人工标注的热点话题数目。 b.熵值和纯度。话题质量评估采用熵值(entropy)[22]和纯度(purity)[23]来度量。整个聚类划分的熵值和纯度的计算如式(14)和(15)。 (14) (15) 式中,mi表示为在聚类i中所有成员的个数,mij表示为聚类i中的成员属于类j的个数,m是整个聚类划分所涉及到的成员个数,K是聚类的数目,L是类的个数。 4.5实验过程和结果分析为了证明算法的有效性,选取了当前三个业界主流模型OnlineLDA、BTM和BBTM以及BBTM模型的改进算法H-HBTM作为基准模型,以平均话题相似度、平均准确度熵值、纯度、点互信息作为指标,在自适应学习话题数目、发现准确度、发现质量和主题一致性这四个角度上,对改进的模型与基准模型进行比较。 4.5.1 自适应学习话题数目实验 针对传统主题模型存在需要人工确定话题数目的问题,BiLSTM-HBBTM算法中采用了基于密度的BiLSTM-HBBTM最优K值选择方法(KBiLSTM-HBBTM),用于确定话题数目K。当主题之间平均余弦距离最小时,话题质量最佳,模型最优。为了证明该方法能够自适应学习话题数目,将其与原方法KLDA进行比较,并在运行时间角度同时与hSBM[8]比较。 在不同话题数目下,KBiLSTM-HBBTM与KLDA方法平均话题相似度的变化情况如图2所示。当话题数目K=67时,两种方法的平均话题相似度都最低。由于基于密度的最优K值选择方法是根据LDA的模型结构提出,将最优K值选择与模型参数估计统一在一个框架里,因而基于密度的最优K值选择方法会更适合LDA模型,KLDA的平均话题相似度也低于KBiLSTM-HBBTM。从图4的实验结果可知,基于密度的BiLSTM-HBBTM的自适应学习话题数目的方法,能够较好地确定最优话题数目K。 图4 KBiLSTM-HBBTM和KLDA选择K的性能表现 为了证明BiLSTM-HBBTM模型使用的词嵌入算法能够改善LDA模型的高维度问题,提高运算效率,与KLDA、hSBM分别在10组不同话题数目下比较完整运行一次算法所用的时间,实验结果如图5所示。 从图5可看出,KBiLSTM-HBBTM、KLDA与hSBM三种方法的运行时间,都随着话题数目的增加而增长。 图5 不同话题数目K下的运行时间 在相同数量的话题数目下,KBiLSTM-HBBTM的运行时间都少于KLDA和hSBM模型的运行时间,主要原因是KLDA使用向量空间表示话题分布,向量的维数与微博文本中特征词的数量相同,会出现高维度的问题。hSBM算法构造无向图,数据量越大,运行时间呈几何增长,因此当数据集很大时,所耗费的时间会非常久,运算效率低。而在KBiLSTM-HBBTM方法中,采用Word2Vec词嵌入的方式来表示话题向量,将话题向量维数设置在300,极大地降低了话题向量维度,缩短了在不同话题数目下每轮迭代过程中计算话题相似度所消耗的时间。由此可知,与KLDA、hSBM方法相比,KBiLSTM-HBBTM方法能够改善维度过高的问题,缩短计算时间。 4.5.2 特征选择结合BBTM与BBTM、H-HBTM发现热点话题对比 本文引入了基于传播值和词项H指数的特征选择方法,从文档层面和词语层面进行特征选择。为了验证本文提出的特征选择方法的有效性,对比传播值与词项H指数结合BBTM建模(HBBTM)与H-HBTM模型、BBTM模型,分别得出每类热点主题下的词分布以及词语之间的PMI。提取“各地医生驰援湖北”“火神山医院施工现场”两个话题中出现概率最大前5个词,实验结果如表1所示。 表1 模型改进前后挖掘主题比较 由表1可以看出,通过BBTM模型得出的关键词从语义上来看有些和主题无关,例如“危重症”和“观看”;通过H-HBTM算法提取的话题词能较好地描述主题,但也存在少量干扰词。前两种方法计算出的PMI均比HBBTM低,说明BBTM和H-HBTM模型发现的热点话题中词语之间的相关性比HBBTM低,HBBTM能够更好地发现热点话题。实验结果表明,通过微博传播值和词项热度结合BBTM建模,每个话题得出的词语与主题高度相关,能与主题相吻合,实验结果优于BBTM和H-HBTM方法。这是因为传播值综合考虑了微博的被转发数、点赞数、评论数对微博文本的影响;而词项H指数考虑了词项的热度。因此,使用结合传播值和词项H指数的特征选择法建模得出的词语能够覆盖整个话题的表述。 4.5.3 BiLSTM-HBBTM与BBTM、H-HBTM发现热点话题对比 针对传统主题模型存在忽略词之间关系的问题,本文引入了BiLSTM来双向学习词语之间的关系。为了验证BiLSTM学习的词之间的关系对挖掘热点话题的的有效性,将BiLSTM-HBBTM建模与H-HBTM模型、BBTM模型对比,得出每类热点主题下的词分布以及词之间的PMI。对比两个话题中出现概率最大的前5个词,实验结果如表2所示。 表2 模型改进前后所得的话题词及PMI 由表2可以看出,BiLSTM-HBBTM模型得出的每个话题的词语与热点主题语义相近,而通过H-HBTM和BBTM建模得出的每个主题的词语中,有一部分词语与主题语义无关或者语义相差较远。从PMI得分也能看出BiLSTM-HBBTM输出的词语之间关联程度更高,能够更好地描述主题。这是因为BBTM是以概率的方法来计算词的突发概率,并将其作为模型的先验知识,只从统计的角度考虑词语的热度;而BiLSTM考虑了词语之间的语义关系,并且利用逆文档频率削弱了高频中性词的影响,因此,引入BiLSTM能够更加准确地提取各个热点话题下的关键词,更有利于热点话题的发现。 4.5.4 BiLSTM-HBBTM与对比算法在话题发现准确度上的比较与分析 为了评估本文方法与基准模型发现热点话题的准确性,计算在不同的热点话题数目K下对应的平均准确度(P@K),作为各方法发现热点话题准确度的评价指标。实验结果如表3所示。 表3 不同话题数目下的准确度 由表3可知:BiLSTM-HBBTM方法的平均准确度都是大于0.8,明显优于其他方法。这说明BiLSTM-HBBTM结合传播值和词项H指数进行特征选择,利用BiLSTM学习词之间的关系,并且将词对热值突发概率代替词对突发概率作为BBTM模型的先验概率,过滤掉一些非热点词,提高了热点话题发现的准确度。 4.5.5 BiLSTM-HBBTM与对比算法在话题发现质量上的比较与分析 为了评价热点话题发现的质量,选择纯度和熵作为评价指标,纯度越大、熵值越小表示性能越好。话题数目设置为K∈[40,65]。各个方法在不同话题数目下的热点话题聚类结果如图6和图7所示。 图6 不同话题数目下的聚类纯度 图7 不同话题数目下的聚类熵 由图6和图7的实验结果可以看出,相比其他对比算法,本文提出的BiLSTM-HBBTM方法在纯度和熵指标的实验结果更好。BBTM、H-HBTM的实验效果较好,但稍微差于本文所提方法,这是因为BiLSTM-HBBTM利用微博传播值和词项H指数选择微博文本和特征词,并且将词对热值突发概率作为模型的先验概率,更好地表征词对热度;考虑了词语关系,过滤掉高频中性词,能够更准确地发现热点问题。 4.5.6 BiLSTM-HBBTM与对比算法在主题一致性上的比较与分析 本文选用点互信息(PMI)指标来度量BiLSTM-HBBTM方法的主题一致性,当PMI越高时,表明该主题的主题一致性更强。BiLSTM-HBBTM与对比算法在不同热点话题数量下的热点话题的主题一致性结果如图8所示。 图8 不同话题数目下的主题一致性 由图8可知,相比于其他对比方法,BiLSTM-HBBTM方法的主题一致性实验效果更优,说明BiLSTM-HBBTM方法发现的热点话题里,各个词语之间的一致性更高。 为了定性分析主题一致性,此次实验随机挑选了一个出现频次较高且是热点话题的话题标签。抽取话题“双黄连可抑制新型冠状病毒”的实验结果,分别列出概率最高的前10个词语,如表4所示。 表4 话题“双黄连可抑制新型冠状病毒”发现概率 由表4的实验结果可知,BiLSTM-HBBTM中词语之间的PMI最大,说明各个词语间语义相关性最强,与话题的一致性也更强。BBTM、H-HBTM发现的话题关键词的相关性也较大,但也存在与话题不相关或相差较远的词语。OnlineLDA中的PMI最低,词以日常通用词语为主,与话题相关的词语比较少,因此,在所有对比方法中,OnlineLDA得出的结果与主题相关性最低。BTM的实验结果虽然略优于OnlineLDA方法,但也包含了较多的日常通用词,比如说“生产”和“早期”,表明BTM模型挖掘的主题有可能是普通话题,不是热点话题。 4.5.7 总结 从前文的分析可以得到以下各个模型功能模块的对比结果,详见表5。 表5 模型功能模块对比 从表5可以看出,传统主题模型仍然存在一定的缺陷。本文提出的基于双向长短期记忆网络的热点突发词对主题模型(BiLSTM-HBBTM)在话题发现准确度、话题质量、话题一致性方面都取得了较好的实验效果。这是因为BiLSTM-HBBTM结合微博的传播性与词项热度进行了文档和词项的特征选择,将词之间的关系和词对热值概率作为词对的先验知识,同时削弱高频中性词对话题的影响,采用基于密度的自适应学习话题数目方法,能够从嘈杂的微博文本中挖掘出高质量的热点话题。 本文提出了一种基于基于突发词对主题模型改进的微博热点话题发现方法(BiLSTM-HBBTM),用来发现微博中的热点话题。BiLSTM-HBBTM先引入微博传播值、词项H指数和词对突发概率,从文档和词语两个层面进行特征选择,再通过BiLSTM训练词语之间的关系,计算词对热值突发概率,为BBTM模型提供了更加准确的先验知识,最后使用基于密度的方法自适应选择话题数目,解决了传统的主题模型需要人工指定话题数目的问题。然而,本文数据集只选取微博的文本进行建模,但微博数据中还包含有图片、视频、音频、表情包等相关能反映话题的信息,未来或许可以考虑结合多方面的数据信息建模来更精确的挖掘热点话题。
4 实验分析








5 结 语
