基于最小机器数的柔性作业车间调度研究
2022-01-25李中胜杨玉中
李中胜,杨玉中
河南理工大学 能源科学与工程学院,河南 焦作 454003
柔性作业车间调度问题(flexible job-shop scheduling problem,FJSP)是对传统作业车间调度的扩展,FJSP的柔性表现在加工某道工序的机器有多种选择,而且机器性能的不同可能导致工序的加工时间存在差异[1]。在对FJSP模型研究的过程中,往往需要对机器故障[2-5]、准备时间[6]、最大延迟[7]、缓冲区间[8]、工件移动[9]等这些问题进行约束,以贴合实际生产。在对机器故障的研究上,朱传军等人[10]在研究含有机器故障的FJSP模型中,为保证调度的稳定性和鲁棒性,对故障机器上的未加工工件进行重调度,以减少故障对优化指标的影响,而Iwona等人[5]对机器故障问题提出一种先验规则、优先级规则的预测调度方法,并允许人员计划性、预防性的维护,这种方法降低了由机器故障引起意外中断的频率。在对机器准备时间和延迟时间的研究上,李明等人[6]采用新型帝国竞争算法对关键目标的最大完工时间和总延迟时间进行持续优化,同时兼顾非关键目标的总耗能,以此来改善作业车间调度的结果。在对缓冲区间设置的研究上,曾程宽等人[8]在缓冲区间有限的条件下,提出以最小化最大完工时间为目标的非线性混合整数规划模型,来分析缓冲区间的大小对车间调度产生的影响。在对夹具资源有限和工件移动的研究上,吴秀丽等人[11]针对夹具资源有限的情况,提出一种考虑装卸的FJSP双资源调度模型来解决此问题。以上文献,为贴合实际生产,考虑了FJSP的众多因素,但都是在指定机器数量的基础上进行生产调度优化,并未在生产调度之前测算调度的最小、最优机器数,也没有在最小机器数的条件下研究机器利用率等其他指标的变化趋势,导致其在优化提升方面具有一定的限制性和盲目性,需要相关研究来补充此内容。因此提出一种在满足最小化最大完工时间和交货期的条件下,求解最小机器数(minimum number of machines,MNM)的双层优化模型。模型的外层目标为最小机器数,主要作用是提供机器数量不同的机器组合,然后以内层目标、交货期等约束来选择符合条件的机器组合,并在此基础上,对比机器组合中的机器数,最后求得众多机器组合中最小的机器数。模型的内层目标为最小化最大完工时间,用于求解在某一机器组合下的最小化最大完工时间,供外层目标使用。通过实例验证分析,该模型可行、有效,能够在实际应用中减少机器数,缩减加工成本和人力,节约能耗。
在研究FJSP问题中,很多学者提出或引入多种智能算法,来优化生产调度。常用的算法有粒子群算法[12-14]、蚁群算法[15-16]、免疫算法[17-18]、遗传算法[7,19-24]和其他融合算法[18,21-22]。因遗传算法具有良好的鲁棒性和可扩展性[1],所以在FJSP中应用较多。如李尚函等人[20]用一种超启发式遗传算法求解模糊柔性作业车间调度。石小秋等人[21]提出一种自适应变级遗传杂草融合算法来求解FJSP。在众多相应的研究文献中,遗传算法表现出“早熟”的缺点[1,7,20],容易陷入局部最优,无法取得全局最优解。理论上,遗传算法中的变异操作能够防止算法“早熟”,但是为了保证算法的稳定性,变异率通常设定很小,导致其无法突破“早熟”。因此采用大变异遗传算法(great mutation genetic algorithm,GMGA)来减少陷入局部最优解的可能,GMGA在迭代过程中[23],当所有的个体集中在一起时,进行一次远大于设定变异率的变异操作,使其产生更多的新个体,“打散”收敛,从而使整个种群脱离“早熟”。GMGA既保证了遗传算法的稳定性,又大大提高了其突破“早熟”的能力。通过对最小机器数优化模型的实例验证分析,证明了算法的有效性。
1 最小机器数优化模型
1.1 问题描述
求解最小机器数时,首先要对数据中指定的机器数(工序所利用到的全部机器)进行调度,初始化参数,然后对加工时间矩阵,采用遍历法的方式,减少机器序列,如调度共有5个机器,首先减少一个机器数,然后分别遍历删除第一个机器、第二个机器、……、第五个机器,并删除对应机器的加工时间序列,其次记录产生的五种机器组合和组合对应的加工时间矩阵,如果减少一个机器数的调度,仍然满足约束,再次减少一个机器数,即减少2个机器数,按照上述方法再次遍历删除机器,直至调度不满足约束,即求得最小机器数。其具体约束如下:
(1)所有的机器在t=0时刻都是可以使用的;
(2)每一个工件都可以在t=0时刻开始加工;
(3)在相同的时刻,每台机器只能加工一道工序;
(4)在相同的时刻,每个工件只能在一台机器上加工;
(5)工件加工顺序不能更改,即待加工工件,只能在紧前工序加工完成后,才能进行下一道工序;
(6)机器在加工工件时不能中断;
(7)每道工序在可选择机器上的加工时间是确定的;
(8)总工件完工时间小于交货期;
(9)在机器数相同、最小化最大完工时间相同的情况下,保留机器总负载较小的机器组合。
1.2 符号定义
MNM优化模型所涉及到的符号及定义如表1所示。
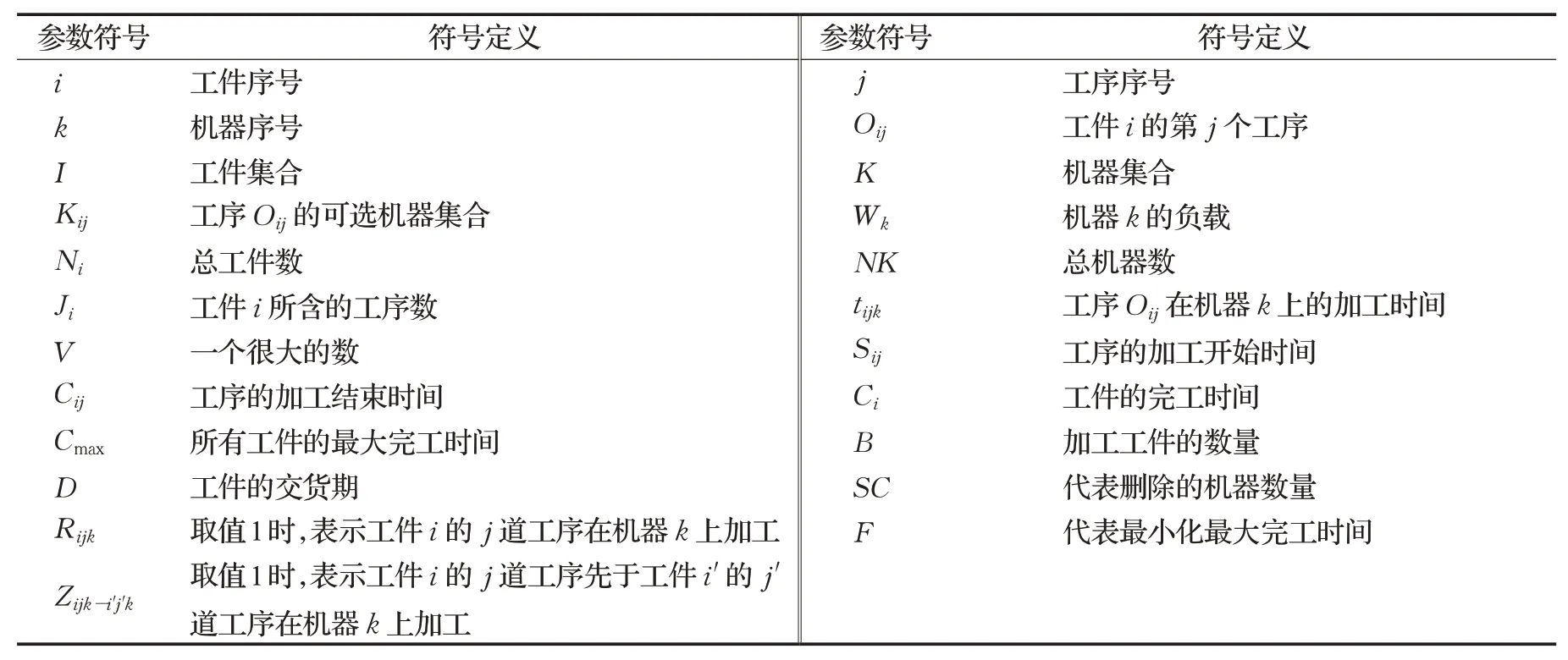
表1 符号及其定义Table 1 Symbols and their definitions
1.3 模型构建
通过机器总数减去删除的机器数获得最小机器数,即优化模型目标。目标函数表达式,见式(1):
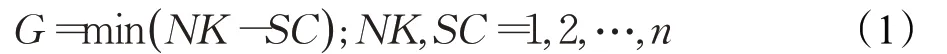
约束条件的具体表达式为:
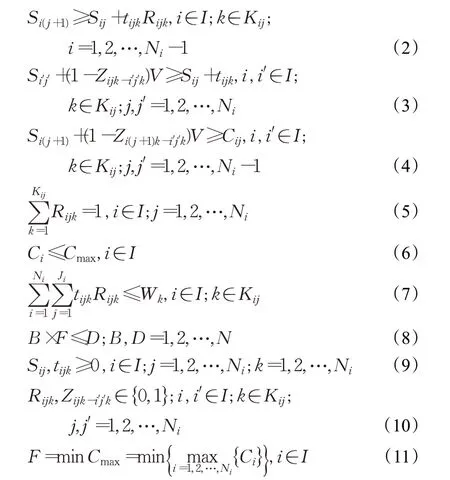
式(2)表示每个工件的工序,必须按照工艺顺序进行加工;式(3)和式(4)表示一个工序只能在所选机器空闲且前道工序加工完成后才能加工;式(5)表示每个工序只能从候选机器集合中选择一台机器;式(6)表示最大完工时间;式(7)表示机器k的上加工工序总时间小于等于机器负载;式(8)表示在最小机器数的情况下,总工件的加工时间小于等于交货期内的有效时间;式(9)表示工序的开始时间和加工时间;式(10)表示决策变量的取值范围;式(11)为最小化最大完工时间。
1.4 模型求解步骤
PC代表某一种机器组合的最小化最大完工时间F;FG代表在G机器数量下,所有机器组合中最小的F,G为常数;MC为常数,用于记录在减少同样数量机器的情况下,每次删除的机器序号;储备集用于储存每次调度的FG和其对应删除的机器序号、机器数量SC。图1为求解步骤图,模型的具体步骤如下:
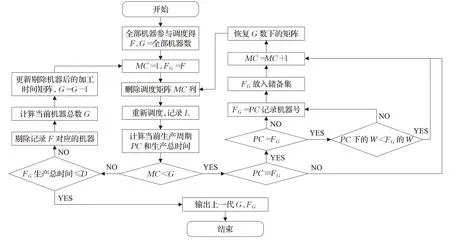
图1 求解模型步骤图Fig.1 Solving model steps diagram
(1)在不删减机器的情况下,对机器运用GMGA进行求解F,并把机器总数赋予G。
(2)初始化参数MC=0,G,FG=F。
(3)首先删除G数量下第一个机器(MC=1)和其对应的加工时间序列,生成新的加工时间矩阵。
(4)导入新的加工时间矩阵,用GMGA进行求解,并记录当前机器组合下的最小化最大完工时间,即PC,同时记录删除的机器数量SC。
(5)判断k是否小于G,如果MC
(6)比较当前机器组合下的PC与减少同样机器数量下的FG的大小,如果PC≤FG,进行(7)操作。如果PC>FG,直接转(9)操作。
(7)判断PC是否等于FG,如果相等,比较FG和PC对应调度方案下的机器负载,PC负载小转(8),PC负载大转(9)。如果PC≠FG,转(8)。
(8)把PC得到的最小化最大完工时间F赋值给FG,始终保证FG为同样机器数量下最小的F,记录PC对应的机器号,并放在同样机器数量下的储备集中。
(9)重新恢复G数量下的加工时间矩阵,进行MC=MC+1操作,删除下一个机器号和其对应的加工时间序列,生成新的加工时间矩阵,转(4)。
(10)判断在此机器数下的生产总时间是否大于交货期,如果大于交货期,输出上一代的G、FG、SC,结束求解,如果小于交货期,转(11)。注:假设减少一个机器数时,发现其不符合交货期,则输出上代未减少机器数时的G、FG、SC,参数储存在储备集中。
(11)剔除在G数量下,与FG对应的机器号,删除机器号对应的加工时间序列,并赋值G=G-1,生成新的加工时间矩阵,覆盖上一代G数量下的加工时间矩阵,转(3)。
2 基于MNM优化模型的大变异遗传算法
2.1 编码方案
编码就是把解的参数形式与基因串的表达形式对应起来。针对FJSP问题,通常采用基于工序编码和基于机器编码相结合的二维染色体编码方式,即双层实值编码。高变异率下实值编码优于二进制编码,实值编码可以提高搜索能力,且不会损害收敛特征[25]。其运用两个L维的数据串,来描述每道工序在选定机器上的加工顺序,L代表总工序数,见式(12):

OS(operation sequencing)数据串用来确定工序Oij的加工位置,MA(machine assignment)数据串用来确定每道工序Oij的加工机器Mk。如表2,OS行中2工件的第一次出现,表示2工件的第一道工序,2工件的第二次出现,表示2工件的第二道工序,由此对应的MA位置,代表工序在此机器上加工。如表2中工序的加工顺 序是(O21→O41→O31→O11→O42→O22→O32→O12→O23→O43→O33→O13→O14→O24→O44→O34),OS工序对应的MA加工机器为(M1,M3,M6,M3,M7,M4,M2,M4,M5,M2,M6,M7,M5,M8,M2,M3),数据引用文献[26]。

表2 编码表达式实例Table 2 Examples of coding expressions
2.2 解码方案
对FJSP的染色体进行解码,就是确定加工工序在对应加工机器上的起止时间。本文采用半主动调度的解码方式[27-28]:在满足工序约束的情况下,从左至右遍历OS、MA,即依次根据工序染色体OS上的加工顺序,染色体MA上对应的机器顺序,并对照各工序的加工时间,累计计算到最后一道工序的结束时间,即得到完工时间。对表2数据进行解码,其结果见图2车间调度甘特图。

图2 机器分配甘特图Fig.2 Gantt chart of machine allocation
2.3 选择操作
选择操作的作用就是优胜劣汰,在父代种群中选出优良个体,给予优良个体更大的生存概率,实现复制、交叉重组等操作。选择操作采用顺序选择策略[28-29]来设置固定化的概率,具体的操作步骤为:根据个体适应度值的大小进行排序,其次为最优的个体设定选择概率q,则排序后的第n个个体的选择概率见公式(13),其优点是能最大限制地保留最优个体。NP表示种群总数,选择概率为0.9,个体适应度值为最小化最大完工时间。

2.4 交叉操作
交叉操作采用Shi在1997年提出的优先操作交叉算子(priority operation crossover,POX),基于双层编码的POX具体操作过程为[28]:首先将工件集I随机分为2个互补子集I1和I2,I1、I2非空,在属于I1的父代P1中选择出集合I1里面的工件,复制到子代offspring中,同时在属于I2的父代P2中选择出集合I2里面的工件,复制到子代offspring中,复制过程中集合I1、I2的工序顺序,依照其在父代P1、P2的位置顺序进行排列组合,同时复制工件对应的机器号,POX交叉过程中保留了父代部分工件的位置,而且子代保留了父代在每台机器上加工工序的顺序,具有很好的保优作用。POX交叉的具体过程见图3,图3应产生两个子代,但由于图线交叉,不易理解,所以另一个子代并未在图中显示。
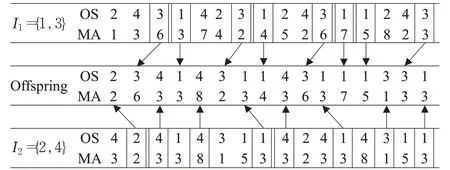
图3 POX交叉过程Fig.3 POX crossover process
2.5 变异操作
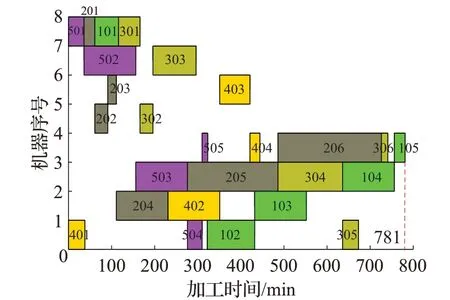
基于遗传算法“早熟”的特点,采用大变异策略来弥补这种缺陷。GMGA中大变异的操作步骤为[23-24]:首先设置合适的变异率进行搜索,同时记录迭代过程中的最大适应度值,一旦迭代的过程中,出现种群个体比较集中的现象,即平均适应度值满足δ×Fmax 在大变异策略下的变异操作,采用互换变异的方式,具体步骤为[1,25]:首先按照事先设置的变异概率,判断个体是否进行变异,然后对确定变异的个体,随机选择两个变异位置,并交换这两个变异位置上的OS、MA基因,见图4。 图4 互换变异操作Fig.4 Swap mutation operation 大变异遗传算法整体流程图见图5。 图5 算法流程图Fig.5 Algorithm flowchart 在进行实例分析时,首先要对GMGA的参数进行设置。经过大量算例验证[20-21,26,30-32],GMGA在交叉率0.8、变异率0.08效果最优。对变异率进行敏感性分析,采用文献[26]的数据做验证说明。图6表示在变异率为0.1、0.08、0.03的情况下,种群均值和迭代速度的变化趋势。从图6中可以看到在变异率为0.08时,收敛速度下降最快,种群均值最小,并能得到最优解。在变异率0.1和0.03情况下,其最优解、收敛速度、适应度平均值(即图6中种群均值的变化)稍逊于变异率为0.08情况下的运算结果,所以在求解模型时采用0.08的变异率。 图6 不同变异率下的仿真效果Fig.6 Simulation effect under different mutation rates 测试环境是在Window10操作系统、处理器Intel®CoreTMi5-4200M CPU@2.50 GHz、运行内存8 GB的个人PC电脑上进行测试。运用GMGA对文献[30]、[31]、[32]中的三组实例数据进行求解验证、对比分析。其求解思路是在最小化最大完工时间的基础上考虑最小机器数,依据最小化最大完工时间与交货期的比较结果,来判定是否进一步减少机器数或终止运算。 图7采用文献[30]的数据(10工件、8机器、35工序),其主要运用改进型的蝙蝠算法(bat algorithm,BA)和非支配排序遗传算法(non-dominated sorting genetic algorithm II,NSGA-II)进行对比分析。由于文献未给交货期,所以采用文献中的最优解作为交货期,以下两组数据的处理也采用此方法。独立运行20次,其结果见表3。GMGA达到最优解的概率为0.45,NSGA-II达到最优解的概率为0.15,说明GMGA具有较强的稳定性。其次机器数减少1台,最优解从85、79提升到76,机器利用率分别提升了22.39%、12.76%。从以上四个方面来看,GMGA在机器数、最优解、机器利用率、算法稳定性上均优于其他两种算法(下文表中“—”表示文献未给出相关数据或者此项无数据)。 图7 基于GMGA的调度结果(采用文献[30]的数据)Fig.7 Scheduling results based on GMGA(using Ref.[30]data) 表3 算法对比结果(采用文献[30]的数据)Table 3 Algorithm comparison results(using Ref.[30]data) 图8采用文献[31]的数据(5工件、11机器、26工序),其主要运用基于直觉模糊集相似度值的遗传算法(genetic algorithm based on intuitionistic fuzzy set similarity,IFS_GA)和NSGA-II进行对比分析。独立运行20次,其结果如表4。GMGA达到最优解的概率为0.8,说明GMGA具有很强的寻优能力和稳定性。其次机器数减少3台,最优解从913、793提升到781,机器利用率分别提升了12.09%、6.56%。从以上三个方面来看,GMGA在机器数、最优解、机器利用率上均优于其他两种算法。 图8 基于GMGA的调度结果(采用文献[31]的数据)Fig.8 Scheduling results based on GMGA(using Ref.[31]data) 表4 算法对比结果(采用文献[31]的数据)Table 4 Algorithm comparison results(using Ref.[31]data) 图9采用文献[32]的数据(6工件、10机器、36工序),其主要运用基本遗传算法和多种群遗传算法进行对比分析。独立运行20次,结果如表5。GMGA达到最优解的概率为0.45,说明GMGA具有较强的稳定性。其次机器数减少3台,最优解从55、50提升到49,机器利用率分别提升了20.3%、16.1%。从以上三个方面来看,GMGA在机器数、最优解、机器利用率上均优于其他两种算法。 表5 算法对比结果(采用文献[32]的数据)Table 5 Algorithm comparison results(using Ref.[32]data) 图9 基于GMGA的调度结果(采用文献[32]的数据)Fig.9 Scheduling results based on GMGA(using Ref.[32]data) 综上所述,模型在减少机器的情况下,还能满足交货期等其他约束,说明模型假设成立,有效且可行。从最优解和稳定性两方面来看,算法有效、可行。结合文献[30-32]可以看出,在最小机器数的模型中,机器柔性越大,机器利用率就越高。在柔性较大的情况下,机器数比工件数越大,其减少机器数的可能性就越大,减少的机器数也就越多。 通过对MNM优化模型和GMGA的研究,并结合实例验证分析,结果表明在可接受的交货期内,所构建的MNM优化模型有效,可使车间调度性能明显提升,能为企业生产管理提供相应的指导,是一种实现高效率、低成本的有效调度方法,进一步丰富了车间调度的研究内容。本文提出的问题,在资源限制上仅研究了机器数量和加工时间,为了进一步贴合实际生产,应系统全面考虑机器效能、机器耗能、机器固定成本等因素,进行全资源优化,以此来完善模型,这也是下一步研究的方向。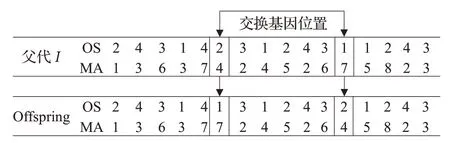

3 实例分析与结果
3.1 变异率敏感性分析

3.2 模型、算法对比分析





4 结语
