面向不均衡数据的多分类集成算法
2022-01-25崔鑫,徐华,朱亮
崔 鑫,徐 华,朱 亮
江南大学 人工智能与计算机学院,江苏 无锡 214122
在机器学习中最为普遍的问题是分类问题。传统分类算法都是建立在数据类别分布均衡的基础上,然而在实际问题中并不能保证数据类别分布平衡,例如异常检测、故障诊断、医学数据分析等。不均衡分类问题可以分为绝对不均衡和相对不均衡。绝对不均衡指的是数据中某一类样本数量非常少比如只有10到20个,甚至不足10个,此类样本数量过少并不足够用于分类器的训练。相对不均衡指的是虽然少数类的数量很大比如1 000或者更多,但是多数类和少数类样本数比例却大于1或者更大,传统分类算法在处理此类数据会偏向多数类而忽略更具有分类价值的少数类。由于上述不均衡数据的特点,传统分类算法用以解决不均衡数据分类的问题往往并不能获得让人满意的效果。因此学术界有必要针对不均衡数据的特点寻找更加有针对性的算法。
面向不均衡数据分类的研究[1-2]是近年来机器学习、数据挖掘等领域的热点之一,针对不均衡数据的算法主要可以分为数据层面和算法层面。数据层面算法即对原数据进行重采样以平衡数据分布,重采样包括过采样和欠采样。最简单的欠采样方法是随机欠采样(random under-sampling,RUS),使用随机算法去除部分多数类样本以平衡数据分布,由于其实现简单且性能良好,该算法常被用作比较算法。但是由于采用随机算法,随机欠采样的性能不稳定且易丢失数据分布信息。2016年,Ha等人提出了基于遗传算法的欠采样GAUS(genetic algorithm based under-sampling)[3],通过最小化损失以选择最优的多数类子集,与RUS相比采样更加合理且性能更稳定,但是具有更高的时间复杂度。2017年,Rayhan等人提出了基于聚类的欠采样方法[4],将聚类和随机算法相结合降低了采样的盲目性。
少数类样本合成过采样技术[5](synthetic minority oversampling technique,SMOTE)是目前最流行的过采样算法之一,该算法在少数类与其最近邻间线性插值引入新样本。虽然SMOTE算法一定程度上缓解了过采样算法会引起过拟合的问题,但是却存在使用噪声样本合成新样本以及模糊类间边界的问题。针对SMOTE算法的不足,许多研究人员提出了SMOTE的改进算法[6-7],例如He等人提出基于SMOTE的自适应合成采样[8](adaptive synthetic sampling,ADASYN),该算法与SMOTE相比实现了对少数类样本的区别对待,对难以区分的少数类合成更多的样本,而易于区分的样本则合成较少的样本。2018年,赵清华等人抛弃了将正类样本点分组的思想提出了最远点少数类样本合成过采样技术[9](max distance SMOTE,MDSMOTE),在少数类质心和距离质心点最远距离的样本点间合成新样本。易未等人于2018年提出了改进的SMOTE算法improvedSMOTE[10],该算法增大了合成样本的分布范围,缓解了过拟合的问题。
算法层面包括代价敏感[11]、特征选择[12]和集成学习方法[13]。在不均衡分类问题中少数类具有更高的分类价值,代价敏感学习通过给予错分的少数类样本更高的错分代价,改善分类器对少数类的分类效果。如果数据集中样本分布不均衡,特征的分布也可能会不均衡,因此选用易于区分的特征可以提高分类性能。集成学习即组合多个基分类器得到一个强分类器,由于其独立性,集成学习常与抽样方法、特征选择方法相结合,例如Guo等人于2016年提出的集成学习方法[14](BPSOAdaboost-KNN),该算法将特征选择方法与Adaboost相结合,以及Liu等人提出的基于遗传欠采样和基于多目标蚁群优化的特征选择[15](genetic under-sampling and multiobjectie ant colony optimization based feature selection,GU-MOACOFS),该算法更是同时使用了欠抽样、特征选择和集成方法。
集成算法所得的多个基分类器中,有些分类器精度较差,有些分类器分类结果相似,即不具备多样性,这些分类器不会提高集成分类的性能。因此,有研究人员将多样性度量用于选择性集成,试图通过提高分类器的多样性从而提高集成分类的性能。虽然多样性对集成算法的性能有重大的影响,但是目前学术界未能明确多样性与集成算法性能间的关系。所以将多样性度量显式地应用在集成算法中会存在一定的争议。然而,除了显式的使用多样性度量,通过增加数据集的多样性来提高基分类器的多样性也是一种行之有效方法。因此,本文提出了一种基于采样和特征选择的不均衡数据集成分类算法(imbalanced data ensemble classification algorithm based on sampling and feature selection,IDESF)。IDESF算法采用有放回采样+SMOTE的两阶段采样方法,不仅可以平衡数据分布,而且可以通过增加数据集的差异性来隐式提高基分类器的多样性。为了降低过采样引入噪声样本的风险,IDESF引入了数据清洗操作。此外,IDESF算法引入了基于SPSO的特征选择算法,试图降低算法的复杂度。最后,通过多个对比实验验证了IDESF算法的有效性。
1 IDESF算法
1.1 两阶段采样
集成算法如果集成多个完全一致的分类器,那么对最终的分类效果没有任何帮助。基分类器间存在适当的多样性,那么如果某个样本被一个或者多个基分类器所错误分类,但是通过某种规则组合基分类器的分类结果却仍然可能获得正确的结果。此外,Kuncheva等人的研究[16]也同样表明设计多样化分类器的总体动机是正确的。因此,为了提高集成算法的分类性能,研究人员会采用一定的策略来保证基分类器间的多样性。研究人员试图对多样性进行显式度量,并在多样性度量的指导下进行选择性集成。但是多样性与集成系统精度的关系不明确,显式地度量分类器间的多样性并用来构建集成系统仍存在争议。然而像Bagging这样隐式地产生分类器间多样性的集成算法是十分具有价值的研究方向。对原数据集按照某种策略进行多次采样可以获得不同的数据集,分别在不同数据集上训练得到的分类器必然相互之间存在一定的差异,所以采样策略可以保证基分类器间的差异性。常用的算法例如SMOTEBoost、Bagging都是单阶段采样,单阶段采样使用同一策略获得了多个数据集,虽然可以保证数据集间存在一定的差异性,但是难以保证训练所得的分类器之间仍存在足够的差异性。为了进一步提高数据集间的差异性,从而提高基分类器的多样性,提出了有放回采样+SMOTE两阶段采样策略。
如图1所示,图(a)为原始数据集,(b)为有放回采样处理后的数据集,(c)为在(b)的基础上进行SMOTE过采样后的数据集,圆形为多数类,星型为少数类。假设原数据集中样本数量为n,x为原数据集中的一个样本,在此基础上进行有放回采样。以样本x为例,极端情况下样本x可能被采样n次也可能并未被采样,所以(b)中与x相同的样本数量在0到n之间。由此可知,(b)中的数据样本皆为原数据集中采样所得,并未对样本本身进行处理,保存了原数据集中样本信息。因此,图(a)和图(b)中数据的分布趋势较为一致。此外,图(a)和图(b)在数据密集程度上呈现了一定的差异,这是由于有放回采样导致数据集中部分样本被采样多次,而部分样本未采样。有放回采样是对原数据集进行随机采样,所得多个数据集的样本总数虽然相等但是某个样本的数量却存在差异,因此保证了数据集间的差异性。SMOTE过采样算法用少数类与其近邻的少数类合成新样本,因此参与合成的样本的合理性将直接影响新样本的合理性。有放回采样并未改变样本本身的信息,并且观察图1可知图(b)中的数据分布与原数据集图(a)中数据分布保持一致,因此在有放回采样所得的数据集上使用SMOTE算法可以保证参与合成的样本的合理性。同时,图(a)与图(c)数据分布趋势一致也表明SMOTE引入新样本的合理性。SMOTE过采样不仅可以获得分布均衡且合理的数据集,在有放回采样所得的多个数据集上分别进行SMOTE过采样,可以进一步扩大数据集间的差异。有放回采样所得的数据集间的差异体现于某一样本的数量,假设有放回采样得到两个数据集A和B,原数据集中某个样本x在数据集A中存在,在数据集B不存在。如果在数据集A和B中分别进行SMOTE过采样,数据集A通过样本x合成所得的新样本必然与数据集B中所得的新样本存在一定的区别。所以,在有放回采样的基础上进行SMOTE过采样会导致合成不同的新样本,数据集间的差异进一步扩大。综上所述,两阶段采样可以保证所得数据集的合理性,同时也可以保证数据集间的差异性。差异化的数据集上更易获得多样化的基分类器。因此,两阶段采样通过增大数据集间的差异,从而提高了基分类器的多样性。

图1 采样情况Fig.1 Sample situation
1.2 IDESF算法
IDESF算法框架如图2所示,首先使用有放回采样获得多个训练子集,每个数据子集的样本数量均与原数据集的样本数量保持一致,子集的个数作为超参数进行调优。然后在训练子集上依次使用SMOTE算法、数据清洗以及特征选择方法,在每个训练子集上获得一个分类器,最后使用加法法则获得最终分类结果。下文将介绍算法相结合的具体过程,各个模块以及模块间的联系。
如图2所示,首先对原数据集进行n次有放回的采样获得n个数据子集,此阶段获得数据子集的特点:(1)改变了某一个样本的数量,所以子集间存在一定的差异。(2)并未改变某一个样本自身的内容,所以又保存了原数据的信息。由于上述特点,在此阶段数据子集上进行SMOTE过采样可以保证获得的子集不会偏离原数据分布,又可以进一步扩大数据子集间的差异。少数类样本数量过少是不均衡分类中最为突出的问题:(1)分类器在训练过程中会追求正确率的最大化,少数类数量过少会导致分类偏向多数类,可能会将部分少数类当作噪声数据。如果少数类有多个子集且分布稀疏,则更易被当作噪声数据。(2)少数类数量少,则原数据集中所包含的分类信息自然就较少,信息的欠缺可能会导致分类器对训练集和测试集中的少数类样本都难以保证可靠的分类效果。SMOTE合成少数类的过采样技术,在少数类样本与其近邻的少数类样本间随机线性插值引入新样本,增加少数类样本数量获得均衡的数据集。SMOTE算法引入的新样本与原数据集中的样本存在一定差异,所以可以丰富少数类的分布,降低了过拟合的风险。有放回采样+SMOTE的两阶段采样方法可以获得分布均衡的数据集,同时在1.1节中也表明了其可以保证数据集的差异性和合理性,所以IDESF算法可以在不同的数据集上训练得到多样化的分类器。本文实验部分选用的数据集为多类别数据集,假设数据集中样本数量最多的类为y,y类的样本数量为N,IDESF算法在每个数据子集上分别使用SMOTE算法将所有类的样本数量扩充到N,得到各个类别分布均衡的数据子集。

图2 IDESF算法框架Fig.2 IDESF algorithm framework
由于实际情况的复杂性,在数据的获取和记录过程中难免发生错误而引入噪声样本。此外,目前所提出的过采样算法虽已获得较好的分类性能,但是都存在一定的局限性,例如有放回采样可能多次采样噪声样本,增加所得数据子集中噪声样本数量;SMOTE算法可能使用噪声样本参与合成新样本,难以保证所得新样本的合理性。考虑到采样策略的局限性以及原数据集中存在的噪声样本,过采样算法难以保证引入的新样本都符合原数据分布,所以两阶段采样后的数据集中必然含有一定数量的噪声样本。分布于边界的噪声样本可能会模糊类间边界,降低数据的可分性。噪声样本数量过多甚至会改变数据集原有的数据分布,导致分类器对测试数据出现大量的错误分类。噪声样本的存在严重损害了分类性能,所以保证新样本的合理性是十分必要的。为了提高采样算法所引入新样本的合理性,提高各类之间的可分性,IDESF算法在两阶段采样后使用了数据清洗操作。IDESF算法所采用的数据清洗操作是去除数据中互为最近异类的样本对,多类别数据集需对每对类组合进行清洗操作。例如对a类和b类进行数据清洗,样本点xi属于a类,以欧氏距离为评价标准,分别计算每个b类样本与样本点xi的欧氏距离,若b类样本xj与xi之间的距离最小,则xj为xi最近邻的b类样本。然后分别计算每个a类样本与样本xj间的欧氏距离,若xi为xj最近邻的a类样本,则xi与xj构成了互为最近异类的样本对,去除样本对xi和xj。分别对每个a类样本按照上述规则进行清洗,则完成了a和b类组合的数据清洗操作。
数据集中特征可以分为:相关特征,对分类问题有帮助,可以提高分类性能;无关特征,对分类器的训练没有帮助,不能提高分类性能;冗余特征,不能为分类器的训练带来新的信息,或者该特征的信息可以由其他的特征推断出。冗余特征和无关特征的存在会增加算法的时间复杂度,同时也会耗费过多的内存空间。特征选择算法可以去除冗余特征和无关特征,从而降低时间复杂度和空间消耗,并且提高分类效果。IDESF算法采用基于简化粒子群算法(simple particle swarm optimization,SPSO)的特征选择算法。SPSO基于群体随机搜索机制,利用群体中个体间信息交互与合作实现寻优。在迭代过程中每个粒子不断更新位置信息,最终得到满足终止条件的最优解。特征选择可以看作0-1组合优化问题,解为一个由0和1组成的向量为1表示第i个粒子在t次迭代的第d维特征被选中,为0则未选中。借鉴于文献[17],通过设定阈值δ将粒子的位置信息转换为解向量,如公式(1)所示:

SPSO算法使用粒子的位置、个体极值以及种群极值获得下次迭代粒子的位置。表示第i个粒子在t次迭代的第d维分量,w为惯性因子,c1和c2是学习因子,r1和r2是服从U(0,1)的随机数,pgd表示种群极值的第d维分量,pid表示第i个粒子个体极值的第d维分量,进化公式如公式(2)所示:

IDESF采用的特征选择算法——SPSO算法:
输入:训练集(xi,yi),i=1,2,…,N,种群大小M,最大迭代次数T,阈值δ。
输出:特征子集。
(1)初始化种群,随机生成M个粒子,粒子的每维分量都是服从U(0,1)的随机数。
(2)将每个粒子的位置信息根据公式(1)转化为特征向量,根据特征向量从原训练集中选取各自的训练子集,在训练子集上可得一个分类器H,根据分类器H所预测的结果可得一组ROC曲线下的面积(area under the curve,AUC),然后根据公式(4)得到AUCarea[18]并将其作为适应度,用粒子的位置信息初始化对应粒子的个体极值pi,最高适应度对应的位置信息作为种群极值pg。
(3)判断是否达到停止条件(最大迭代次数T或者最大适应度),如果达到停止条件则转步骤(5),否则转到步骤(4)。
(4)使用公式(2)更新所有粒子的位置,计算其适应度值,如果出现更优的pi和pg,则更新其值,然后转到步骤(3)。
(5)将pg转换为特征向量并输出,算法结束。
在数据子集上根据其各自的特征子集训练得到一组基分类器,最后采用加法法则组合基分类器得到最终的强分类器。加法法则即对每个类求得n个基分类器的分类概率和,预测结果即为分类概率和中最大的类别。设n为基分类器的个数,m为类别的个数,类标签为{C1,C2,…,Cm},Pij为第i个基分类器将预测样本预测为Cj类的概率,RCj为Cj类上n个基分类器的概率之和,pre为最终的预测结果,则pre=arg max{RC1,。
1.3 算法复杂度分析
定义n为数据集中样本数量,m为数据集类别数量,k为基分类器的数量。有放回采样的时间复杂度为O(n),有放回采样后样本数量仍为n。在此基础上进行SMOTE过采样,假设采样的倍率为t,则时间复杂度为O(n(n+t))。由于t一般远小于n,所以SMOTE的时间复杂度可以简化为O(n2)。数据清洗操作的时间复杂度为。假设迭代次数为t,粒子数为p,以决策树为分类器为例,基于SPSO算法的特征选择算法的时间复杂度为O(tp(n+m2))=O(n)。综上,IDESF算法的时间复杂度为O(k(n+n2+n2+n)),即O(n2)。IDESF算法的空间复杂度取决于有放回采样中所存储的多个数据集。因此,IDESF算法的空间复杂度为O(n)。
2 实验
2.1 数据集和评价指标
实验所选用的数据集均来自于KEEL(http://www.keel.es/datasets.php),源于不同的实际应用领域。数据集的详细信息见表1,其中IR表示多数类与少数类的数目之比。
不均衡分类实验中常用的度量指标是AUC,越大的AUC代表分类的效果越好。AUC可以定量比较不同分类器的性能,但是AUC是针对于二分类问题所设计的,而对于多分类问题AUC不能直接使用需对其进行扩展,常用的两种扩展方法:(1)一对一方法;(2)一对多方法。假设数据类标签集合Y={y1,y2,…,ym},第一种方法,计算每对类组合(yi,yj)(i≠j)的AUC。第二种方法,为每个类yi∈Y创建一个二分类问题,其中属于yi类样本为正类,其他样本为负类,然后为每个二分类问题计算AUC。以上两种方法都可以得到一组AUC值,取其平均值avgAUC作为多分类问题的评价指标。
两种扩展方法都易于理解和计算,但是平均值avgAUC并不能反映极端情况,例如一组AUC值中一个值较差只有0.5,其他的AUC值较高0.9以上,而avgAUC可能反映分类效果良好。这种情况在不均衡分类中更加有可能出现,从而错误判断少数类的分类效果。此外对于不同分类器,可能每个AUC值都不同,但是avgAUC却相等,此时就无法判断哪种分类器更优。
为此,Hassan等人提出了基于一对一的新的评价指标AUCarea,将一组AUC值在极坐标上表示,将极坐标上所覆盖的面积作为评价指标AUCarea,面积越大越好。假设数据类标签集合Y={y1,y2,…,ym},计算每对类组合(yi,yj)(i≠j)的AUC,可得一组AUC值{r1,r2,…,rq},q=C2m。坐标图的角度设置为2π,图中每个等角线代表一个AUC,所以图中有q个等角线。等角线的长度代表AUC的值,所以其长度最大为1。此外,{r1,r2,…,rq}在图中的表示需按照:r2为r1的近邻,r3为r2的近邻,…,rq为r1的近邻。连接近邻点所形成的图形面积即评价指标AUCarea。如图3所示,是一个三分类的AUCarea极坐标图示,虚线围成的三角形面积就是AUCarea。AUCarea的计算公式如公式(3)所示:
当所有AUC值为1时,可得AUCarea的最大值AUCarea_max=(q/2)sin(2π/q),为了AUCarea在[0,1]范围内取值对其进行归一化操作,如公式(4)所示:
为了书写方便,公式(4)所得的值仍记为AUCarea。与avgAUC相比,AUCarea除了可视化之外,AUCarea对于单个差的AUC更加敏感。假设ri变为ri-l,avgAUC和AUCarea的变化分别为:。因为单个AUC值都是大于等于0.5,所以如果某个AUC值下降,则AUCarea降低的幅度会更大。在不均衡分类问题中,少数类与其他类的AUC可能会较低,所以AUCarea更加适用于不均衡分类问题。
2.2 分类器类别及数量对分类性能的影响
为了研究分类器类别对分类性能的影响,实验固定基分类器个数为10,在决策树(decision tree,DT)、最近邻(k-nearest neighbor,KNN)以及逻辑回归(logistic regression,LR)三个不同的分类器中进行实验。实验结果如图4所示,不同分类器的分类效果各有不同。在balance数据集上,LR优势十分明显可以比DT和KNN分别高出0.087 6、0.098 4,且在dermatology和wine数据集上同样取得了较高的分类性能。但是在contraceptive和hayes-roth数据集上LR分类效果很差,特别在hayes-roth数据集上所得AUC比DT和KNN低了0.4左右。分类器DT和KNN在五个数据集上的分类效果相近,但是DT在contraceptive、dermatology、hayes-roth和wine数据集上均取得了最高的AUC。从五个数据集上的均值来看,DT、KNN和LR所得平均AUCarea分别为0.899 3、0.891 7、0.814 8,DT仍然取得了最高值。综上所述,下文的实验均采用DT作为基分类器。
为了研究分类器数量对分类性能的影响,实验设置决策树为基分类器,并设置分类器的数量为5、10、15、20、25、30。IDESF算法不同分类器数量的分类性能以及均值如图5所示。在dermatology数据集,基分类器数量达到10之后分类性能便趋于稳定。wine数据集上分类性能并未随着基分类器个数变化而产生波动,而是一直保持着最高的分类性能。balance数据集在基分类器数量为5和30时分类性能较低,而基分类器数量在10~25时分类性能较高且在小范围内波动。在contraceptive数据集上,分类性能随着基分类器数量的增加而增加,在基分类器数量达到20时性能趋于稳定。hayes-roth数据集,基分类器数量在5~20时分类性能保持上升且波动,在数量为20时性能达到峰值,之后随着基分类器数量增加,性能有所下降。基分类器数量为20和25时整体的分类性能均较高且相近,但基分类器数量为25仅在contraceptive数据集取得了最高的AUCarea,而基分类器数量为20在balance、dermatology、hayes-roth、wine以及均值取得了最高的AUCarea。综上所述,考虑到算法的分类性能和复杂度,下文实验将基分类器数量设置为20。

图5 基分类器数量对分类性能的影响Fig.5 Influence of base classifier number on classification performance
2.3 阈值对分类性能的影响
IDESF的特征选择算法通过设定阈值将粒子的位置信息转换为解向量,所以阈值设定必然会影响特征选取,进一步影响算法的分类性能。为了研究其对分类性能的影响,本文选择-0.2、-0.1、0、0.1、0.2、0.3、0.4、0.5、0.6、0.7、0.8、0.9这12个数值作为阈值,对比研究不同阈值下算法的性能。IDESF算法不同阈值的分类性能以及均值如图6所示。在balance数据集上阈值为0时AUCarea达到最大值,而阈值为其他值时AUCarea差别较小,性能曲线较为平滑。在contraceptive数据集上,在-0.2~0.1之间性能曲线略有上升,在0.1之后性能曲线剧烈波动,而在0.7之后性能曲线又急剧下降。dermatology数据集上,在-0.2~0.2和0.4~0.6区间内曲线较为平稳,而在0.3和0.8处曲线出现了凹点。hayes-roth数据集上,性能曲线在-0.2~0间小幅度上升,在0之后曲线波动且呈下降趋势。wine数据集上,性能曲线十分平稳且保持着最高的AUCarea。阈值为0时,在balance、dermatology、hayes-roth以及wine数据集上均获得了最高的AUCarea。此外,平均值曲线在阈值为0时取得了峰值,阈值为0与其他值相比优势较为明显。基于上述实验结果,下文实验中阈值选择为0。
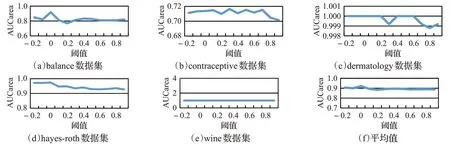
图6 阈值对分类性能的影响Fig.6 Influence of thresholds on classification perform
2.4 IDESF算法性能研究
为了进一步研究IDESF算法的有效性,将IDESF算法与BPSO-Adaboost-KNN[14]、基于聚类欠采样的集成不均衡数据分类算法[19](imbalanced data ensemble classification based on cluster-based under-sampling algorithm,ECUA)、文献[20]所提出的两种算法与bagging结合(分别简记为Centers和Centers_NN)以及有效不平衡分类的代价敏感决策树集成算法[21](cost-sensitive decision tree ensembles for effective Imbalanced classification,CS-MCS)进行对比。基于上文实验,IDESF选择DT作为基分类器,基分类器数量设置为20,阈值设置为0。SPSO算法的参数设置:种群粒子数为50,最大迭代次数为40,学习因子c1=c2=2,惯性因子w=0.8。采用AUCarea和另外一个广泛使用的不平衡分类评价指标GM(G-Mean)对算法进行评价,实验结果列于表2、3。
在表2中可以看出在所有数据集以及平均值上,IDESF与对比算法相比均获得了更高AUCarea。其中在balance数据集上IDESF的优势最为明显,与对比算法相比平均可以高出0.176。在contraceptive和hayes-roth数据集上,IDESF依然优势明显。contraceptive数据集上,IDESF比对比算法平均高出0.163。在hayes-roth数据集上,IDESF比对比算法平均高出0.097。dermatology和wine数据集上,六个算法均取得了较高的AUCarea。IDESF在dermatology数据集上AUCarea达到了1,Centers、Centers_NN、CS-MCS和IDESF在wine数据集上AUCarea达到了1,表明这些算法在对应的数据集中完全正确分类所有的测试数据,达到了最好的效果。从均值来看IDESF依然优势明显,IDESF比BPSO-Adaboost-KNN、ECUA、Centers、Centers_NN和CS-MCS分别高出了0.112、0.117、0.06、0.063、0.143。同时根据表3可知,IDESF同样在GM指标上获得了较好的结果,在contraceptive、dermatology和wine数据集上排在第一位,在hayes-roth数据集上排在第二位。从均值来看,IDESF比BPSOAdaboost-KNN、ECUA、Centers、Centers_NN和CS-MCS分别高出了0.016、0.116、0.056、0.033、0.024。

表2 六种算法的AUCarea值对比Table 2 AUCarea value comparison of six algorithms

表3 六种算法的GM值对比Table 3 Comparison of GM values of six algorithms
综上所述,通过一系列实验可知IDESF算法在评价指标AUCarea和GM上均获得较为可靠的性能,表明针对不均衡数据分类问题提出的IDESF算法是有效的。
3 结束语
针对不均衡分类问题,本文提出了一种集成分类算法IDESF,该算法融合了有放回采样+SMOTE的两阶段采样、去除互为最近异类样本对的数据清洗操作以及基于SPSO的特征选择方法。放回采样+SMOTE的两阶段采样通过增加数据集间的差异性,达到隐式提高分类器间多样性的目的。此外,放回采样+SMOTE的两阶段采样可以平衡数据分布,避免分类器倾向于多数类。数据清洗方法去除过采样引入的噪声样本,提高数据的可分性。特征选择可以去除冗余特征和无关特征,降低算法复杂度并提高分类性能。多个对比实验表明,IDESF算法与对比算法相比具有更好的分类效果,可以有效解决数据集中样本分布不均衡的问题。IDESF算法效率较低,所以下一步将试图在不降低性能的前提下提高其分类效率。
