结合网络表示学习和文本卷积网络的类案发现
2022-01-25梁鸿翔张步烨李炜卓程茜雅
梁鸿翔,张步烨,李炜卓,程茜雅
1.中国航天科工集团第二研究院,北京 100854
2.东南大学 网络空间安全学院,南京 211189
3.东南大学 计算机科学与工程学院,南京 211189
在智能革命时代背景下,“智慧法院”的建设正如火如荼地进行,并已取得阶段性实效。与此同时,如何对法院系统中丰富的案例进行语义检索并有效地利用已经成为了智慧司法研究的共识[1]。“同案不同判”一直是影响司法公信力的重要原因之一,也是司法体制改革与检察改革所关注的重要问题[2]。作为智慧法院的核心应用之一,相似裁判文书的发现(简称类案发现)有助于解决司法过程中的裁判尺度不统一、类案不同、量刑不规范等问题。
然而,衡量裁判文书之间的相似性是一项重大挑战,主要表现在以下两个方面[2]:一方面,裁判文书通常正文篇幅较长且结构复杂,往往难以提取裁判文书中的核心要素;另一方面,单个裁判文书可能牵涉到不同的法律问题。例如,对于网络虚拟财产盗窃案件的定性,不同法院持有不同观点。一部分法院认为网络虚拟财产不属于现实财产,不符合盗窃罪的构成要件,故不构成盗窃罪,应以非法获取计算机信息系统数据罪定罪处罚。也有其他法院认为网络虚拟财产也凝结了他人无差别的人类劳动,属于财产,应以盗窃罪定罪处罚。上述问题均给衡量文书之间的相似性带来了巨大挑战。
近些年来,国内外学者尝试从不同的角度设计模型来克服上述挑战。例如,王君泽等人[3]尝试将裁判文书对篇章结构和语言表述方面的特征进行建模利用,并设计相应的案情相似度模型来发现裁判文书的相似性。王禄生[4]通过构建法律图谱,并利用图谱的结构化信息来提升相似裁判文书的发现效果。相对的,印度学者[5-6]尝试用引文网络来对裁判文书进行建模,并取得了一定的效果。除此之外,一些学者尝试将类案发现转化为分类任务[7],利用监督学习模型来进行建模,从而根据预测的分类结果进行相似案件的发现[8-10]。
然而,将上述方法运用在真实的类案发现场景却存在两点局限性。首先,真实的裁判文书的罪名种类较多且判决的粗细粒度不同,仅利用裁判文书在篇章结构和语言表述来提取的特征无法保证其对多类罪名的泛化能力。另一方面,真实场景中的裁判文书数量十分巨大,基于网络关联的方法虽然可以构建关于裁判文书的语义网络,但仍然无法胜任大规模的网络计算,且无法有效地将法律的先验知识与标签信息进行融合。相对而言,基于监督学习的分类模型虽然可以在整体上保证类案发现的精度,但判断的罪名一旦存在偏差,输出的结果则会给法律工作人员带来较差的体验。
为此,本文提出了一种基于网络表示学习和文本卷积网络的类案发现方法。方法分别从无监督与有监督的视角来编码裁判文书中的信息,并在原有模型的基础上利用法律知识体系进行了改进。最终,方法采用设计的投票机制将两类模型的输出结果进行融合。实验表明,本文提出的方法较已有方法能在类案发现任务中取得更好的效果。
1 研究现状
对于相似裁判文书发现任务,可以将其视为相似文本发现的一类特殊情况[11]。目前的文本相似度计算方法主要包括基于统计的方法和基于语义嵌入的方法两大类。
基于统计的方法主要是统计文本中各词项的出现频度,以词频信息为基础来计算文本之间的相似度,其代表为词频-逆文档频率(term frequency-inverse document frequency,TF-IDF)[12]。方法首先将已有裁判文书中的词进行收集。然后,针对每一个文档,将其拆解成多个词,并利用词频与逆文档频率公式得到每个词的TF-IDF值。最终,集合中的每一个文档可以由所有词所组成的向量进行表示,其中每一维的取值为词所相应的TF-IDF值。如果该词未在裁判文书中出现,对应的维度取值为0。相对的,概率潜在语义分析(probabilistic latent semantic analysis,PLSA)[13]和潜在狄利克雷分布(latent dirichlet allocation,LDA)[14]的提出不仅提高了向量空间模型的计算效率,同时也降低了多义性和同义词的影响。
随着词嵌入技术的兴起,越来越多基于语言模型的无监督嵌入模型被研发出来,并逐步运用到相似文本的计算中来。Par2Vec[15]模型作为Word2Vec[16]的拓展,它对文本中包含的每一个单词进行逐一预测,但并不会考虑单词的顺序或是更加复杂的信息。这种方法证实了通过训练一个文档向量去衡量两个文档的相似性是可行的。BERT(bidirectional encoder representations from transformers)[17]是继Word2Vec之后,谷歌提出的一种大规模预训练方法。BERT使用Transformer[18]作为框架,能够更好地捕获语句的前向后向关系,Transformer中的Self-Attention改善了长距离文本的表示效果。此外,BERT利用训练语句中被遮盖的词和预测文档中的下一句话进行训练,从而加强了预训练的效果。
近些年来,国内外学者尝试将文本相似度的技术引入到相似裁判文书发现的任务中来。王君泽等人[3]依据裁判文书的书写规范,设计了案件事实部分的抽取策略;同时,他们依据词性的不同对裁判文书中的词项进行分类,并根据不同类词性的重要程度来设计了一个案情相似的计算模型。王禄生[4]则提出了利用法律图谱的思路来描述案件画像,这不仅可以解决类案发现识别准确率低的问题,同时也有助于法官来梳理案件的情节。相对的,印度学者Minocha等人[5]发现了国外裁判文书引用网络的特殊性。由于基于案件文本特征的相似度计算策略往往不如引用网络的相似度计算策略,因此,他们尝试利用引文网络来对裁判文书进行建模。Kumar等人[6]则进一步利用“段落衔接”的方法来改善引文网络在相似裁判文书发现上的效果。除此之外,也有部分学者尝试将类案发现转化为多分类任务[7],利用有监督学习模型根据裁判文书中的罪名标签进行建模。在预测的过程中,再根据预测罪名的概率分布来进行相似案件的推送[8-10]。
可以发现,目前关于相似裁判文书发现的各类研究工作仍存在不足。王君泽等人[3]与王禄生[4]的工作虽然考虑了法律先验知识的重要性,但对于标注提出了很高的要求,人工参与的代价巨大。因此,面对罪名种类多样的裁判文书,该类方法的泛化能力十分受限。相对的,Minocha等人[5]与Kumar等人[6]提出的引文网络则属于无监督学习模型的。面对上百万份的法律文书,方法虽然可以构建关于裁判文书的语义网络,但仍然无法胜任大规模网络计算且无法有效地将法律的先验知识与标签信息进行融合。相对而言,基于监督学习的分类模型[8-10]虽然能够在整体上保证类案发现任务的准确率,但罪名判断一旦出现错误,全部错误的文书推送则会给法律工作者人员带来较差的体验。
本文提出的方法则是将无监督学习模型与有监督的模型的优势进行结合,并在原有模型的基础上利用法律知识体系对其负采样策略进行了改进。最终,方法基于提出的投票机制将两类模型的输出结果进行融合,从而得到更好的类案发现结果。
2 研究方法
2.1 方法技术路线
在介绍本文提出的方法之前,首先给出相似裁判文书的建模描述。
相似裁判文书建模.给定裁判文书的集合D,相似裁判文书的建模在于学习到一个目标函数f:D×D→R+,使得f(di,dj)能够度量任何两个裁判文书di,dj∈D的语义相似度。
图1为文中相似裁判文书发现的具体处理流程。对于获取到的裁判文书,方法首先采用文本嵌入学习模型对裁判文书以及相应的法律实体进行预训练,得到它们的初始向量表示。随后,方法将裁判文书与法律实体的向量表示分别输入到法律网络模块与罪名预测模块中,并利用网络表示学习模型与文本卷积网络模型进行相应的模型训练。最后,方法根据设计的投票机制将两类模型的输出结果进行有效融合,并将前k条相似的裁判文书进行推送。
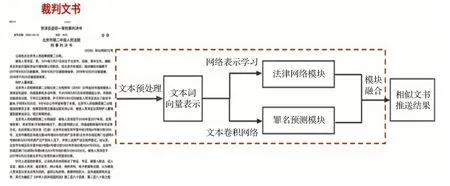
图1 技术路线概览Fig.1 Overview of technique route
2.2 文本预处理
对于获取到的裁判文书,方法首先对裁判文书进行中文分词。考虑到中文描述上的差异性,方法对不同俗称的法律实体名称按法律术语进行归一化处理(如:案由与起诉罪名)。同时,对一些复杂的法律实体描述字段进行简化(如:盗窃的赃物、犯案时间),以此来缓解模型训练时词条的长尾现象。
本文利用文本嵌入学习模型对裁判文书以及分词得到的实体进行预训练,得到裁判文书与法律实体预训练后的初始向量表示。具体地说,方法利用BERT[17]来捕获词在语句中的前向后向关系。相比于早期的Word2Vec[16]、Par2Vec[15],BERT使用Transformer[18]作为框架,其中的Self-Attention可以提高长距离文本的表示效果。除此之外,BERT利用训练语句中被遮盖的词和预测文档中的下一句话进行训练,从而加强了预训练的效果。
通过文本预训练的方式能够在一定程度上保留法律实体(词项)在裁判文书中的语义信息,而生成的文本词向量能够使得法律网络模块与罪名预测模块获得更好的输出结果。
2.3 法律网络模块
网络表示是衔接网络原始数据和网络应用任务的桥梁,记作G=(V,E),其中V是节点集合,E是边的集合,边e=(vi,vj)∈E表示了节点vi到vj的一条边[19]。网络的邻接矩阵定义为A∈R|V|×|V|,其中如果(vi,vj)∈E则Aij=1,否则Aij=0。邻接矩阵是信息网络中的一种简单直接的关联表达形式。邻接矩阵A的每一行描述了一个节点和所有其他节点的链接关系,可以看作是对应节点的一种表示。
尽管邻接矩阵表示直接,但这样的网络表示受到计算效率问题的影响。可以发现,邻接矩阵A需要占用|V|×|V|的存储空间。这在|V|增长到百万级时,计算的代价通常是不可接受的。另一方面,邻接矩阵中绝大部分的数值为0,这种数据的稀疏性使得统计学习方法快速有效的应用变得十分困难。为此,研究者们提出了网络表示学习的思路[19],他们尝试将网络中的节点编码为低维稠密的实值向量v∈Rd,其中d≪|V|,在模型编码的过程中,通过拟定的目标函数将网络的结构信息与实体之间的语义关联进行有效的保留。
受到该类网络表示学习的启发,本文首先利用裁判文书以及相应它们关联的法律实体(词项)来构建成法律网络,通过网络表示学习模型来学习它们的语义向量表示,继而计算裁判文书之间的语义相似度。本文使用网络表示学习模型为LINE[20]。为了更好地区分LINE模型中的一阶邻接关系与二阶邻接关系,将构建的法律网络的节点分为上下两层,上层的节点用裁判文书的ID来表示其唯一性,下层的节点为所有的法律实体,当法律实体在相应的裁判文书出现时,则在两个节点之间添加一条边,构建的法律网络样式如图2所示。

图2 基于LINE的法律网络建模Fig.2 Legal network modeling based on LINE
由于在类案发现业务中裁判文书之间的邻接关系未知,因此在法律网络模块中直接采用了LINE的二阶邻接关系来进行建模。在二阶邻接关系中,LINE模型假设两个节点(裁判文书)共享连接的其他节点越多,那么这两个节点彼此越相似。这些共享的节点(法律实体)被视为特定的“上下文”,并且假设在“上下文”上具有相似分布的节点是相似的。为了维持二阶邻接关系,LINE模型要求每一个低维表示节点所指定的上下文的条件分布接近经验分布。相应的目标函数定义如下:

其中,O2表示LINE二阶邻接关系的损失函数,vi表示标号为i的节点,V表示节点上下文节点的集合(这里指的是两跳以内的节点)。为前节点的声誉值,其中wik为每个节点出度的权重,p2(⋅|vi)表示节点的条件分布,表示节点的经验分布,d(⋅,⋅)表示两个分布的距离。LINE通过最大化这个概率来更新节点的向量表示。模型对序列中的每个节点计算它的条件概率,即该节点出现的情况下序列中其他节点出现的概率的log值。
由于整体优化公式(1)代价太高,为此方法采用了文献[16]的负采样策略,根据每条边(ui,uj)∈E的噪声分布进行负采样。具体的目标函数如公式(2)所示:

其中,σ=1/(1+exp(-x))为sigmoid函数,ui、uj表示网络中的节点的向量表示,为文献[16]定义的负采样分布。简单来说,对于每条边(ui,uj)∈E,在节点集合V中按负采样分布寻找其他的节点进行替换生成一个负例(ui,uj′)或者(ui′,uj)。
由于法律的专有名词之间可能存在一定的逻辑关联,因此本文尝试利用法律知识体系的弱层次关系对负采样所替换的实体进行约束。具体来说,当节点ui或者uj为知识体系中的专有名词(如著作权),那么该专有名词的上位概念(如知识产权)与下位概念(如软件开发权)均不能作为替换节点ui′或者uj′。除此之外,当两个实体在裁判文书中的点互信息(pointwise mutual information)大于一定阈值时,负采样过程应将该类配对的情况予以排除。
2.4 罪名预测模块
模块采用的罪名预测模型为文本卷机网络模型TextCNN[21],它是将卷积神经网络CNN应用到文本分类任务,利用多个不同大小的核函数来提取句子中的关键信息(类似于多窗口大小的n-gram),从而能够更好地捕捉局部相关性。
基于TextCNN的罪名预测模块如图3所示。首先,根据BERT预训练好的词向量矩阵输入到文本中得到每个词语的向量表示。然后,将词向量序列依次送入由卷积层、激活层和池化层构成的特征抽取器,提取文本的语义特征。最后,将特征向量送入由两层全连接层和一层激活层组成的分类器,进行分类预测,输出每项罪名的分类概率。

图3 文本卷积网络的整体框图Fig.3 Whole diagram of TextCNN
考虑裁判文书的内容较长,但段落之间的关系和逻辑性较为紧密,因此用TextCNN来进行建模较为合理。此外,TextRNN[22]与FastText[23]同样可以用于罪名的分类判断,但从裁判文书罪名分类的实际应用效果上来看,TextCNN较两者更加合适。
2.5 模块融合
基于LINE的网络表示模型应用在类案发现中分为线下与线上两个部分:(1)当裁判文书已经存在于构建的法律网络中(线下),则直接利用裁判文书之间的向量表示来计算它们之间的相似度。(2)对于新的裁判文书(线上),由于未出现在法律网络中,因此需要根据裁判文书所关联的实体来获得它们之间的相似度。通用的做法是利用关联实体向量的算术平均来表示该裁判文书的语义向量[24],相关的公式定义如下:

其中,n为裁判文书所关联的法律实体个数,ei为基于网络表示学习模型训练后的法律实体向量表示。类似的,已存在网络中的裁判文书也需要通过它们关联的法律实体向量来表示其语义向量,以此来统一相似裁判文书的计算。
相对的,基于TextCNN的罪名预测模块,可以直接根据新输入的罪名得到相应罪名的分类概率。本文将概率最大的罪名作为分类的结果。
考虑LINE与TextCNN分别采用无监督学习与有监督学习的策略。因此,在相似文书发现时,本文采用投票的机制进一步对两类模型结果进行融合。具体的融合策略如算法1所示。在得到LINE模型推送的前1 000条相似度裁判文书以及TextCNN模型判断的罪名类别CType后,首先统计前1 000条裁判文书中的罪名类型与数量。当CType属于排名前3种罪名类别时,根据具体的排名以及相应罪名的数量进行相似文书的推送。步骤3、4返回的是保留罪名类型为CType的前k条相似文书,步骤5、6返回的是保留罪名类型为Type1的前k条相似文书。当CType不属于排名前3种罪名类型时,直接返回原LINE模型推送的前k条相似文书。
算法1基于LINE与TextCNN的投票策略
输入:基于LINE模型获得的前1 000条推送裁判文书集合D,基于TextCNN获取的罪名分类CType
输出:前k条相似的文书
1.[Typei,Numi]←降序统计集合D的罪名类型与数量
2.If CType∈{Type1,Type2,Type3}
3.If CType=={Type1}or(Num1≤500)
4.return LINE的推送结果中罪名类型为CType的前k条相似文书
5.else if(Num1>500)
6.return LINE的推送结果中罪名类型为Type1的前k条相似文书
7.else
8.return LINE推送结果的前k条相似文书
3 结果与讨论
3.1 数据来源
实验的数据来自于国双提供的裁判文书,将其细分为小规模数据集(记作Legal-Small)与全数据集(记作Whole-Small),具体统计如表1所示。
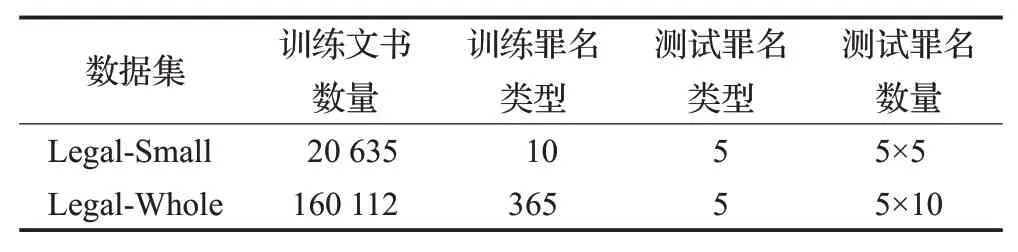
表1 裁判文书数据集统计Table 1 Statistics of data sets of judgment documents
小规模数据集总计20 635份。一共包含诈骗罪,盗窃罪,毒品走私罪,寻衅滋事罪,危险驾驶罪,抢劫罪,拐卖妇女儿童罪,生产、销售假药罪,非法持有、私藏枪支弹药罪,开设赌场罪10种类常见的罪名类型。对于评估样本,本文从法信网(http://www.faxin.cn/)上基于诈骗罪,盗窃罪,走私、贩卖、运输、制造毒品罪,寻衅滋事罪,危险驾驶罪随机各自选取了5份案例进行评估测试。
全数据集总计160 112份。一共涉及法律案由中涉及一级到三级共365类常见的罪名类型。对于评估样本,本文从法信网上基于诈骗罪、交通肇事罪、盗窃罪、制造毒品罪、走私毒品罪、非法吸收公众存款罪随机各自选取了10份案例进行评估测试。
3.2 对比方法与评估方式
为了验证本文提出方法在相似裁判文书发现中的有效性。实验分别选取TF-IDF[12]、LDA[14]、Par2Vec[15]、BERT[17]、TextCNN[21]、DeepWalk[25]、LINE[20]来 进 行 对比。其中TF-IDF、LDA为相似文本任务中统计方法的代表,本文通过词项的统计数值来组成向量,以此来获得裁判文书的向量表示。Par2Vec、BERT为文本嵌入学习方法的代表,本文利用其端到端的思想直接训练得到裁判文书的向量表示。TextCNN为罪名文本分类模型。预测时,模型根据的罪名输出类别进行过滤推送。DeepWalk、LINE为网络表示学习模型的代表(GraRep[26]与Node2Vec[27]等模型由于实验室工作站硬件条件不足,无法在该数据集上进行训练),建模的方式与本文中的法律网络模块一致(见2.3节)。本文的方法则是基于改进后的LINE与TextCNN模型,结合设计的投票机制提出的联合方法,记为Legal-E。其中文本预处理选用BERT作为预选训练模型来获得裁判文书与法律实体的初始向量表示。上述方法均在PyTorch(https://pytorch.org/)与OpenNE(https://github.com/thunlp/OpenNE)平台的帮助下以Python语言进行实现,实验训练与测试均采用个人工作站进行完成,其中CPU为安擎E5-2620V4*2,内存为128 GB。针对中文描述的裁判文书,方法选用结巴中文分词工具(https://github.com/fxsjy/jieba)来对其描述内容进行中文分词处理。
实验共邀请3位人民检察院的法律专家对类案发现的结果进行评估,重点从罪名和犯罪情节两方面来进行度量。简单来说,如果推送裁判文书与测试文书中的罪名和犯罪情节都一致,记1.0分。如果罪名不对,记0分。如果罪名相符但情节偏差较大,则记0.5分。具体评估公式如下:

其中,scoreij表示第j位专家对推送的第i篇裁判文书进行打分,k为方法推送的裁判文书数量,在实验评估中k=10。
3.3 实验结果与原因分析
小规模数据集的类案发现实验结果如表2所示。整体来说,TF-IDF与LDA在P@10的指标上均好于文本嵌入学习模型Par2Vec与BERT,可以发现词频相对于文档上下文在类案发现任务中发挥了更大的作用。相对的,BERT对文本序列的正向与反向词之间的依存关系均进行了建模,因此效果较Par2Vec更好。而单独的TextCNN则因为单个案例的罪名预测出现了部分误判,导致整体的类案发现效果不佳。基于网络表示学习的DeepWalk与LINE整体要好于上述模型,表明了该类模型构建的网络可以更好地建模裁判文书与实体之间的语义关联。

表2 类案发现在Legal-Small数据集中P@10的实验结果Table 2 Experimental results of similar case discover on Legal-Small in terms of P@10
本文提出的方法Legal-E则有效地结合了有监督学习模型与无监督学习模型的优势,并采用设计的投票机制的将结果进行融合,因此,它能在单个案例与整体类案发现任务中同时取得最佳的效果。
表3列出了上述方法在整体数据集上的实验结果。由于LINE模型在法律整体数据集构建的网络上无法训练,因此,在Legal-E的法律网络模块中,方法采用DeepWalk模型进行替代。可以发现,由于罪名种类和文书数量的增多,原有对比模型的P@10数值均出现了不同程度的下降。然而,当它们融入罪名判断模块与投票机制之后,推送的效果均有明显的提升。Legal-E依然在大部分任务上取得了最佳的效果。值得注意的是,当基准方法TF-IDF与LDA加入罪名判断模块后,均可以达到与Legal-E相当的结果。但就推送时间而言,受益于网络表示学习中裁判文书与法律实体的低维向量表示,平均推送时间均在0.1 s内完成。

表3 类案发现在Legal-Whole数据集中P@10的实验结果Table 3 Experimental results of similar case discover on Legal-Whole in terms of P@10
实验进一步对小规模训练数据进行了等比例划分,来分析裁判文书数量对模型的推送精度的影响。关于盗窃罪的类案发现结果如表4所示。整体而言,当裁判文书数量越大时,上述模型的P@10均有所提升,类案发现效果会变好。然而,Par2Vec与BERT的变化趋势并不稳定。分析认为,主要是该类方法侧重建模文档的上下文,而忽略了词频在推送任务中的效果。

表4 不同比例训练样本在盗窃罪上的类案发现结果Table 4 Results of similar case discover on larceny with different proportions of training samples
就时间开销而言,TF-IDF能在100 s内完成Legal-Small数据集的训练。其他模型均需要30 min以上才能完成。这里较为耗时的模型主要为BERT与LINE模型。前者需要考虑文本前后之间的依存关系,后者的时间复杂度与网络边的数量是多项式相关的,因此需要耗费更多的时间。
4 结束语
本文提出了一种基于网络表示学习与文本卷积网络的联合方法用于类案发现的研究。方法通过设计较为合理的投票机制将无监督学习模型与有监督的模型的优势进行结合,并进一步利用法律知识体系中的弱层次关系对网络表示学习进行负采样改进。实验结果表明,本文提出的联合方法在P@10指标上优于对比模型,有效地提升了推送准确率。本文下一步的工作将从多重罪名与少样本罪名方向进行类案发现的探索研究。
