融合BERT和自编码网络的短文本聚类研究
2022-01-25朱良奇黄季涛马莉媛史志才
朱良奇,黄 勃,黄季涛,马莉媛,史志才,2
1.上海工程技术大学 电子电气工程学院,上海 201620
2.上海信息安全综合管理技术重点实验室,上海 200240
随着互联网和移动终端的快速发展,网络深入人心,越来越多的人在线上完成交易,如网络购物、在线观影以及外卖等,所以产生了大量的行为数据,比如,购物评价、外卖评价以及影评等等,且以短文本居多。通过挖掘这些文本数据中潜在的信息,有助于企业发现新的商机,对于政府可以及时发现舆情事件并做出正确疏导有重要意义。其次,网络的发展,导致数据爆炸式增长,每天充斥着各种各样的新闻报道,对于准确地将各种新闻进行分类展示,便于人们快速获取热点信息。正是上述的问题以及需求,对大量的短文本数据做出快速、准确的聚类迫在眉睫。
短文本相比于长文本包含的字符数更少,文本描述更加随意,各个实体间的关系会更加模糊,完整的语义信息更加难以准确提取。传统的空间向量模型基于词出现的频率等方法进行文本向量化[1],应用于短文本的表示,容易出现高维稀疏,造成语义鸿沟,对于下游的文本聚类或者分类等任务会直接导致准确率下降。并且传统的聚类方法将特征表示和聚类分为两个步骤分别处理,这样容易造成聚类模型和特征不匹配,以上的两个原因导致最终聚类效果不尽人意。
针对以上短文本聚类过程出现的向量表征和模型匹配问题,本文提出一种BERT-AK模型,具体如下:
(1)首先利用预训练模型BERT(bidirectional encoder representations from transformers)[2]的多头注意力机制和动态词向量等特性获取具体语境的短文本向量表示,实现从数据空间到特征空间转换。
(2)构建一个降维自编码网络AutoEncoder,利用自监督学习方法,训练一个特征提取器Encoder,把输入的768维的高维向量进一步转换为低维稠密向量,用于下游聚类任务。
(3)联合训练聚类网络。利用Maaten和Hinton[3]提出的学生分布Q拟合文献[4]提出的样本点的辅助目标分布P,最后以这两个分布的KL散度为损失函数,迭代联合训练编码器Encoder和聚类模型K-Means。
1 相关工作
有学者利用词袋模型BoW(bag of words)和词频-逆文档频率TF-IDF(term frequency-inverse document frequency)[1]对短文本进行向量化表示,由于短文本本身字符数少的特性,导致利用上述的方法得到的文本向量高维且稀疏,利用这些文本向量进行相似度计算的时候,往往不能准确地反映样本间真正的距离[5],会产生较大的误差。Hu等[6]和Banerjee等[7]提出通过利用维基百科的相应数据扩充短文本数据,弥补短文本信息不足问题,增强短文本的表达能力。同样利用引入外部知识,增强文本表达的还有Hotho等[8]和Wei等[9]提出利用本体方法论来扩充短文本的信息表示,提高短文本的表示能力,以及Kozlowski等[10]和Zheng等[11]分别提出利用语料的主题和语义信息对短文本信息增强,但是这些方法都需要很强的自然语言处理相关知识储备,不同的数据源,需要不同的外部知识,不具一般性,导致成本过高。
近年,随着深度学习的快速发展,词嵌入方法[12],对于解决文本表示有很大的提升,通过在大量的语料中利用无监督的方法训练词之间的语义关系,得到的词向量更加稠密,更能表示该词的语义信息。本质上也是利用外部知识增强当前的文本表示方法,但是更具一般性和高效性。文献[4]提出深度嵌入聚类方法,利用神经网络学习文本的特征表示和聚类目标,该方法实现了从数据空间到低维特征空间的映射,然后迭代优化聚类目标。词向量是文本表示的基础,传统的词向量化的方式有词袋模型BoW以及静态词向量模型Word2Vec[13]等,由于前两种词表征方式都是从词频角度出发对词进行向量化,对于词汇相对少的短文本,得到的词向量是高维稀疏的,而且难以捕捉词之间的语义和语法联系,不利于下游任务的使用。而Word2Vec虽然是在大规模语料上训练得到的词向量,但是由于模型结构的原因,得到的是静态的词向量,对于包含多义词的文本向量表征不准确。BERT[2]预训练模型,该模型在亿级别规模的语料上无监督训练,并且利用掩码方式,同时利用上下文信息提取语义关系,实现根据环境动态提取词向量,和获取词之间的潜在语义关系,模型表现出很强的鲁棒性,在很多自然语言处理任务中取得了最好的结果[14-16]。本文提出采用BERT初始化文本向量表示,并在下游聚类任务中设计自编码网络进一步降维和抽取稠密特征,最后将编码器和聚类算法联合微调模型,以提高准确度。
2 方法
2.1 BERT预训练模型
BERT预训练模型是谷歌2018年提出的大型多任务语言模型[2],模型的结构如图1所示。为了同时捕获词和句子两个目标的特征信息表示,提出了MLM(masked language model)和NSP(next sentence prediction)任务,其中,MLM通过将输入句子中15%的词采用以下三种策略掩盖,具体的,该词有10%的可能被替换为随机词,80%的可能被MASK字符串替换和10%的可能被保留的方式来实现掩码效果,以提高模型的预测能力。NSP任务是因为在一些问答任务上需要两个句子的关系,所以BERT模型通过训练下一个句子预测任务,提高模型对于连续句子识别能力,提升在问答和推理等任务上的性能。
输入包括三部分,如图1所示,分别为词条的词嵌入(token embedding)、片段嵌入(segment embedding)和位置编码嵌入(position embedding)。其中词条的嵌入包括每个词的向量嵌入和不在词表中的词的字符嵌入,片段嵌入是为了当输入为两个句子时,用于后期训练该模型的NSP任务。位置编码嵌入是由于BERT利用Self-Attention机制,实现了输入句子中词之间相对距离都是1,解决了文本长距离依赖问题,但是丢失了原本的语序信息,对每个词加入位置信息作为位置编码,给模型提供词之间的相对位置,提高了文本表征中信息的完整性。
如图1所示,BERT的核心模块便是Transformer块,通过堆叠12个或24个该模块,形成深度神经网络提取文本之间的语义信息。Transformer[17]是2017年谷歌提出的一种新的语言模型,通过引入自注意力机制Self-Attention解决了传统自然语言处理问题的长程依赖问题,并且为了提高模型对于不同位置的识别能力,计算公式如式(1)所示:

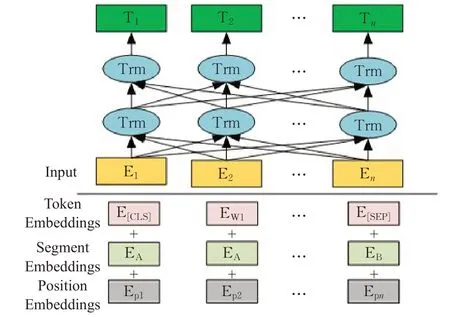
图1 BERT结构图Fig.1 BERT infrastructure diagram
其中,Q∈Rn×dk是查询向量,可表示为Q=[q1,q2,…,qn],T,K∈Rm×dk和V∈Rm×dv分别表示为K=[k1,k2,…,kn]T和V=[v1,v2,…,vn]T。Attention将一个n×dk的序列编码为一个n×dv的序列,为了防止计算过程中内积很大时梯度小的问题,加入dk作为调节因子。
为了进一步提高模型对于不同特征的关注,从而引入多头注意力机制,使模型可以专注于不同特征,不同注意力头head按照公式(2)进行拼接。相比于其他的语言模型,BERT通过引入大量的外部知识信息和从输入的上下文同时提取词的表示信息,最后获得词更加完整的表征信息。

其中,headi的计算公式如式(3)所示,对每个headi拼接得到最终的多头注意力输出,作为文本向量的表征,然后输入到前馈网络进行下一步的计算。
2.2 自编码网络AutoEncoder
神经网络的初始化对于模型结果至关重要,因此本文利用自编码网络实现对于特征提取器的参数初始化操作。自编码网络分为两部分,由编码器(Encoder)和解码器(Decoder)组成,并且两个网络呈对称结构。编码器和解码器通常都是三层神经网络,由输入层、隐藏层和输出层组成,如图2所示。其中,编码器的输出是解码器的输入,编码器和解码器的输出可以分别表示为公式(4)和(5)所示,自编码网络通过编码器提取高维特征并降维处理输出文本特征Zi,解码器通过对称的网络结构,对编码器的输入X进行重构,得到X′,目的是利用神经网络拟合一个恒等函数,提高编码器的特征提取能力。其中重构过程采用均方误差作为损失函数,为了防止模型过拟合,本文采用L2范数进行正则化,提高模型在测试集的表现。计算公式如式(6)所示。

图2 自编码网络Fig.2 Self coding network

其中,We和Wh是权重矩阵,be和bh是偏置向量,f1和f2是映射函数。
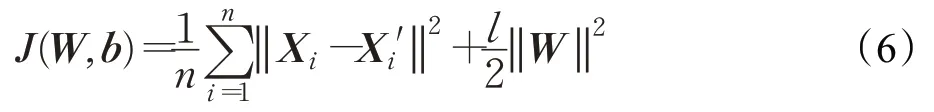
其中,λ为惩罚因子,控制模型的复杂度。n为批量样本个数,Xi为输入向量,Xi′为解码器的拟合分布。W为模型的参数。
2.3 模型搭建
利用自编码网络初始化特征提取器Encoder,相比于随机初始化,对于下游任务表现出更好的结果。本文所提出的BERT_AE_K-Means模型如图3,利用上述训练好的编码器Encoder对文本数据表示Embedding进一步做特征降维处理,然后通过将该部分和聚类网络Kmeans相结合,根据聚类结果反向调整网络参数。该过程可以抽象为以下过程。

图3 BERT-AK模型框架结构图Fig.3 Frame structure of BERT-AK model
(1)初始化K-Means聚类算法的簇心uj。由于基于划分的K-Means聚类算法对于初始簇心的选取十分敏感,因此本文在不同的簇心下,利用K-Means进行100次实验预估,计算划分误差最小的簇心作为初始的聚类簇心,然后计算每个样本点i属于簇j的概率qij,计算公式如式(7),得到样本点的概率分布Q。

其中,zi表示样本点的特征向量,uj表示簇心向量,v是t分布的自由度,本文为取值为1。
(2)本文中的自监督学习的目标分布采用Xie等[4]所提出的辅助目标分布P,该分布相对于步骤(1)得到的样本点的软分布Q,P更近似于原数据分布[4],所以作为自训练阶段的辅助目标具有合理性。辅助目标分布的计算公式如式(8)所示:

其中,qij表示样本i属于簇心j的估计概率。
(3)联合训练编码器Encoder和聚类网络K-Means。由于需要度量两个分布Q和P之间的差异,本文采用KL散度(KL-divergence)作为损失函数训练模型,计算公式如式(9)所示:

其中,P是估计分布,Q是辅助目标分布,pij是样本属于簇心j的近似概率,qij是样本i属于簇心j的估计概率值。
3 实验结果及分析
3.1 实验数据和步骤
本文在4个短文本数据集上进行实验:(1)Search-Snippets,该数据集来自谷歌搜索引擎,一共有12 295个短文本,包含8个不同类别[18]。(2)StackOverflow,该数据集是一些问答案例的标题数据,发布于Kaggle平台,一共有16 407个短文本,分别来自20个不同类别[19]。(3)BioMedical,该数据集发布于BioASQ官方网站,来自生物医学相关领域,一共包含20个类别和19 448个样本[20]。(4)Tweet,该数据集由2 472个短文本组成,包含89个类别[20]。关于数据集的详细信息如表1所示,其中N表示每个数据集包含的类别个数,T表示每个数据集包含的文本数量,L表示每一个数据集的样本平均长度。
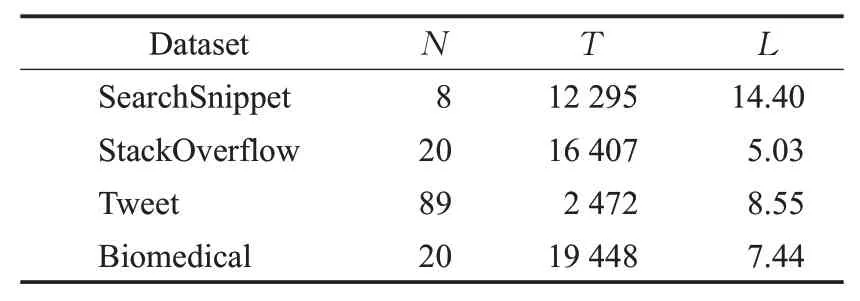
表1 短文本数据集Table 1 Short text dataset
本文实验中,利用BERT预训练模型获取词的上下文动态词向量表征,将模型[CLS]标签输出的768维向量作为短文本的向量表示,该标签是BERT模型输出的用于文本分类的包含全局信息的文本表示。由于当前得到的文本向量表示维度高,直接利用聚类算法聚类,不但准确率低,而且会导致模型的时间复杂度过高,因此本文提出利用AutoEncoder模型对上述的文本向量做特征提取和降维,自编码网络的内部分为Encoder和Decoder部分,Encoder模块包含输入层,隐藏层和输出层,神经元个数分别是768、1 000和128,特别的,编码器的输出作为解码器的输入,Decoder模块同样包含三层网络,神经元的个数分别是128、1 000和768,实现对输入数据的向量表征V进行重构。训练过程中,设置批处理大小为64,学习率为0.001,优化算法为随机梯度下降算法(stochastic gradient descent,SGD)。经过30次迭代优化,得到特征提取器Encoder,然后利用该编码器对输入的文本向量V进行降维和特征提取,然后输入到聚类网络,利用聚类结果反向优化编码器和聚类模型的参数,进行联合训练优化。该阶段模型的损失函数设置为KL散度,通过不断优化模型输出的样本估计分布Q和辅助目标分布P之间的距离,提高编码器对于当前数据的特征提取能力和聚类的准确度。
3.2 对比实验和评价指标
3.2.1 对比实验
本文一共设置了6组对比实验,分别在四个短文本数据集上进行实验,对比模型详细介绍如下:
前两组对比模型是基线模型,分别利用TF-IDF和Word2Vec获取词向量,然后基于词向量对文本进行特征表示,然后直接利用K-Means聚类算法进行聚类。
STC2[19]是一种基于词嵌入和卷积神经网络的短文本聚类算法,在聚类的过程中利用卷积神经网络学习文本表示。
GSDPMM[20]是一种用于短文本聚类的基于狄利克雷过程的多项式混合模型,该模型不需要提前指定簇的个数,由于模型的设计原因,通常趋向于产生更多的簇。
SIF-Auto[21]是一种利用SIF词向量表示方法进行文本表示,然后利用自编码网络进行特征提取,最后进行聚类的算法。
BERT_K-Means和BERT_AE_K-Means两个模型是本文提出的文本表示方法,均采用预训练模型BERT提取文本的语义表示,第一个模型相比第二个没有经过自编码网络进行特征提取和降维,用来验证提取到的高阶特征对下游文本聚类的重要性。
3.2.2 评价指标
本文在四个数据集上进行了多次实验,选用聚类准确率(accuracy,ACC)和标准互信息(normalized mutual information,NMI)作为模型评价指标。聚类准确率ACC的计算公式如下:

其中,N是样本个数,Ci是模型对样本点xi分配到的簇标,yi是样本点xi的真实标签,map(Ci)用于将模型得到的簇标映射为与yi相同的形式。δ(x,y)是判别函数,定义如式(11)所示,用于判断聚类得到的类别和真实标签是否相同。

标准互信息NMI计算公式如下:

其中,H(·)为信息熵,H(C),H(D)用于将互信息值归一化到[0,1]范围内。I(C,D)定义为C和D之间的互信息值,计算公式如式(13)所示:
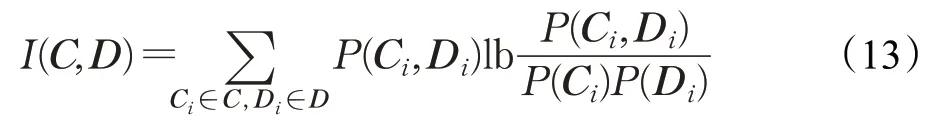
当聚类模型把数据C和D完美划分为两部分的时候,标准互信息值取到最大值为1。
3.3 实验结果分析
本文为了实验结果的可靠性,每个模型的结果都是取10次实验的平均值作为模型最终的结果,同时,在相同的数据集上做了6组对比实验,实验的结果分别如表2和表3所示。通过K-Means、Word2Vec_K-Means和BERT_K-Means三个实验,验证文本的不同向量表示对于文本聚类的重要性,从表2中可以看到3个实验中BERT_K-Means效果最好,相比于Word2Vec_KMeans模型在SearchSnippet数据集上准确率提高了24个百分点,而Word2Vec_K-Means模型相比于K-Means也提高了20个百分点,从实验结果可以看到,在短文本上,直接利用基于词频的文本表示效果最差,利用大量语料进行预训练可以有效地提高文本表示的能力,从而提高下游的文本聚类的效果。
实验GSDPMM和STC2以及SIF-Auto是近年提出的在这4个数据集上取得不错结果的方法,本文将其作为部分对比实验,验证本文提出的特征提取和聚类方法的有效性,从表2和表3中可以看到GSDPMM在Tweet数据集上均表现出了最好的结果,因为Tweet数据集包含89个类别,相比其他数据集样本数多出4倍,而GSDPMM模型趋向于产生更多的簇,因此在该数据上取得了最好的结果,其中ACC和NMI值均比本文提出的模型高不到1个百分点。本文提出的方法在其他3个数据集上均取得了最好的结果,其中ACC在StackOver-Flow数据集上比最好的对比模型SIF-Auto的结果提升3个百分点,NMI值在BioMedical数据集上相比对比模型SIF_Auto提升2.8个百分点。

表2 模型在数据集上的准确率对比Table 2 Accuracy comparison of models on datasets %
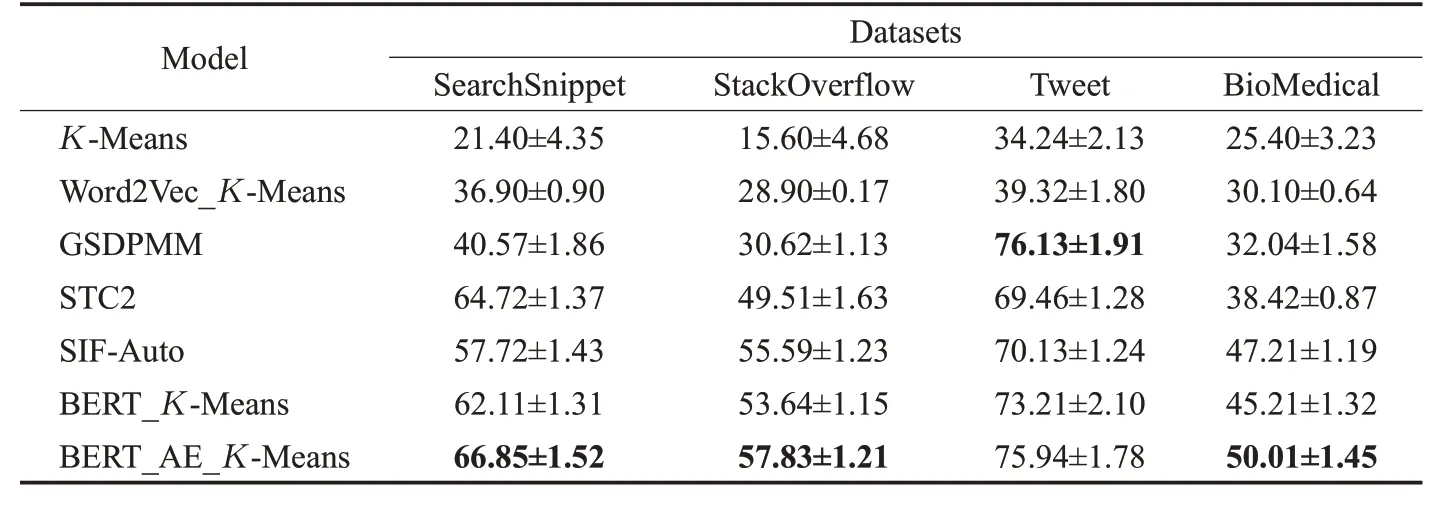
表3 模型在数据集上的标准互信息对比Table 3 Standard mutual information comparison of models on datasets %
最后两组实验BERT_K-Means和BERT_AE_KMeans进行对比验证本文提出的自编码网络对于文本特征提取和降维的有效性,通过该模块进行特征提取和降维之后,文本的表示向量更适合下游的应用。从表2和表3均可以看到,聚类准确率在各个数据集上均有提升,并且在除了Tweet数据集外,其他3个数据集上取得了对比实验中最好的效果,其中NMI值在StackOverflow数据集上比BERT_K-Means提升超过4个百分点,ACC提升6个百分点。说明了本文提出的对文本表示进行特征提取和降维方法可以有效地提高文本表示能力,从而提高了聚类算法的性能。
上述实验验证了本文所提出的文本表示和高阶特征提取方法对于提高聚类准确度方面的有效性,同时为了验证模型的计算效率,本文选取近年提出的对比实验STC2、SIF_Auto与本文所 提出的BERT_K-Means和BERT_AE_K-Means模型在四个数据集各一万条样本上进行运行时间测试,对比结果如图4所示。

图4 各个模型运行时间Fig.4 Running time of each model
从图4中可以看到,本文所提出的BERT_AE_KMeans模型在四个数据集上的运行时间均低于BERT_K-Means,略高于STC2和SIF_Auto两个对比实验,这是由于BERT预训练模型输出的是768维的高维特征向量,需要更多的计算时间,而相比BERT_K-Means,本文通过AutoEncoder模块提取高阶特征后,不但减少了计算量,而且聚类模型更容易收敛,所以运行时间低于BERT_K-Means模型。因此可以看出本文所提出的模型在提高聚类准确度的同时,时间复杂度并没有大幅提高。
为了更加直观地看到聚类结果的变化,本文在SearchSnippet数据集上将对比实验下的聚类结果进行降维处理,利用python的Sklearn库中的集成模型t-SNE将样本数据特征降维到2维空间,可视化如图5所示,可以直观地看到基于词频统计的TF-IDF模型所得到的聚类效果最糟糕,没有有效地将各个类别的数据划分开,这是因为对于短文本数据集,样本数据所包含的词汇数量少,能够体现文本意思的核心词汇不足,通过词频统计的文本向量化表征方法导致核心语义词汇并不能体现出高的权重,因此这种基于统计的文本表示方式所得到的聚类效果不好。STC2模型利用卷积网络提取文本信息的特征,相比于图5(b),聚类算法直接作用于数据空间,前者提取特征之后得到的聚类效果更加明显,各个簇的边界曲线更加清楚。图5(d)采用SIF进行文本表示之后利用自编码网络提取文本的高阶特征表示,有效地提高了聚类的效果。图5(e)是本文采用预训练模型BERT进行文本表示之后,直接利用K-Means进行聚类,和图5(b)相对比,可以明显看出预训练模型BERT利用上下文环境信息动态获取文本表示比利用Word2Vec得到的文本表示更有利于下游的聚类,各个簇的边界更加清晰。图5(f)是本文提出的模型BERT_AE_K-Means聚类得到的结果,通过和图5(e)相比,进一步验证本文提出采用自编码网络对于BERT得到的文本向量提取高阶特征之后,可以再次提升聚类模型的有效性,在SearchSnippet数据集上表现出最好的聚类效果,得到的簇的边界更加清晰。

图5 在SearchSnippets数据集上聚类结果的对比图Fig.5 Comparison of clustering results on SearchSnippets dataset
通过以上实验可以发现文本聚类任务中,对于文本的向量化表征十分重要,本文相比于传统的基于词频统计的向量表征方法和基于Word2Vec的静态词向量方法,充分利用大型预训练模型BERT提取词之间高维空间的语义和语法等信息,对于下游的文本聚类任务效果的提升尤为重要,以及配合本文提出的特征抽取、降维和聚类微调方法,在文本聚类任务上准确度有了较大的提升。本文将聚类准确率和标准互信息值在各个模型的纵向对比结果可视化如图6和图7所示,从图中可以直观地发现,本文所提出模型获得更高的准确率。

图6 模型的聚类准确率纵向对比图Fig.6 Accuracy comparison chart of model on dataset
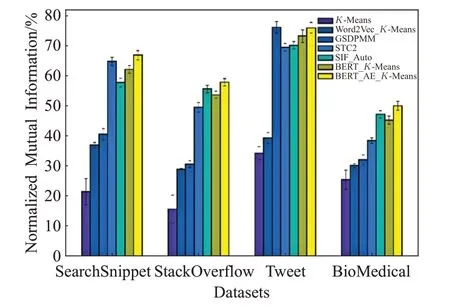
图7 模型的聚类标准互信息纵向对比图Fig.7 Standard mutual information comparison chart of model on dataset
4 结论
本文提出了一种组合模型用来解决短文本聚类问题,通过利用预训练模型BERT初始化文本向量表征,将文本数据空间转换到特征空间,提取词之间的高维语义关系,然后将得到的文本特征向量输入到自编码网络训练特征映射编码器,通过自编码网络的自监督学习完成编码器Encoder的训练,最后将编码器和聚类模型相结合。利用聚类网络K-Means计算每个样本点的估计概率分布Q和辅助目标分布P,利用KL散度作为损失函数联合训练编码器Encoder和聚类模型。本文的模型在4个公开的数据集上,聚类准确率ACC和标准互信息NMI基本都高于对比实验结果,在数据集SearchSnippet上,通过t-SNE方法对文本数据进行特征降维到2维空间,进行可视化,可以看到本文提出的模型的聚类效果更好,类之间的分割更加明确,本文的研究和提出的模型具有一定的意义。
