基于GBDT 的船舶油耗预测模型设计
2022-01-25陈陆,吴桦
陈 陆,吴 桦
(武汉邮电科学研究院,湖北 武汉 430074)
数据研究表明,国际对外贸易货物运输量的90%由水路运输完成[1]。相对其他运输方式,水路运输单位耗能小、运输量大、运输距离远、运输成本低。因而随着全球经济的快速发展,海上运输业发展迅速。
2020 年8 月4 日,国际海事组织(IMO)第四次温室气体研究(GHG4)报告已提交IMO 第75 届海上环境保护委员会,正式向全球发布。研究显示,2012~2018 年间,国际海运碳强度降低了约11%,但温室气体年排放量从9.77 亿吨增加到10.76 亿吨。预计到2050 年,随着海运需求的不断增长,二氧化碳排放量将比2018 年增长约50%,比2008 年增长约90%~130%。随着全球经济的发展,航运业也必将日益繁荣,随之而来的环境污染问题也会日益加剧。另一方面,随着对自然资源的逐渐开发利用,船舶所需的燃油价格呈现波动增长的趋势,而船舶运营过程中,其燃料成本占据整个运营成本的50%~60%。可以看出,国际航运业面临着巨大的节能减排的压力。
为实现船舶节能减排的目的,需要充分理解船舶油耗的各种有效影响因子,并在综合考虑这些因子的基础上搭建合理的船舶油耗预测模型。该文基于上述理论将梯度提升决策树(Gradient Boosting Decision Tree,GBDT)应用到船舶油耗预测建模中。以某一远洋船舶的实船监测数据为基础,分析影响船舶油耗的因素,应用GBDT 算法结合训练数据建立船舶油耗预测模型,并通过测试数据对油耗预测模型的可靠性进行验证。该油耗预测模型的建立能为航行优化提供决策基础,对实现船舶节能减排具有重要意义。
1 GBDT算法
GBDT 是Friedman 于2001年提出的,一种广泛用于分类、回归和推荐系统中排序任务的机器学习算法[2]。GBDT 算法本质上是大量简单模型的联合,其核心在于,从第二棵决策树开始,每棵决策树的输入为其之前所有决策树的输出总和,基于这种提升思想,多个决策树的结论累加获得最终的输出。
1.1 CART回归树
在GBDT 中采用的决策树是CART 回归树。由于CART 回归树既可以处理梯度值又可以处理连续值,所以不管是GBDT 回归问题还是GBDT 分类问题所采用的决策树都是CART 回归树。
在回归树算法中,最重要的步骤是找出最优的划分点,而数据中所有特征的所有可能的取值都可以作为回归树的划分点。在分类树中是基于熵或基尼系数来选取划分点,而在回归树中,样本标签是连续的,无法使用熵等指标作为划分点选取的依据,因此将平方误差作为选取依据,平方误差能够对拟合程度进行很好的评价。
CART 回归树构建过程:
1)输入训练数据集D,终止条件;
2)选取最佳切分变量j和切分点s,即选择使式(1)最小的j和s的组合;
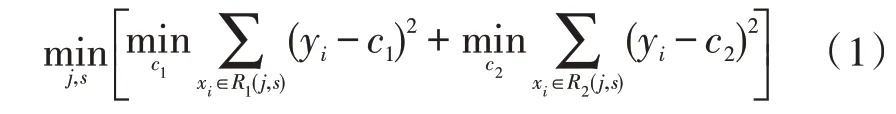
3)将选定的j和s用于区域划分,并确定输出值:
4)对划分后的两个子区域调用2)、3),直到满足终止条件;
5)将输入的训练数据集划分为M个区域,生成CART 回归树:
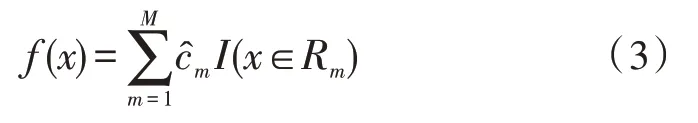
6)输出CART 回归树f(x)。
1.2 拟合负梯度
在GBDT 的迭代过程中,假设第t-1 次迭代获得的强学习器为ft-1(x),则损失函数为L(y,ft-1(x)),那么第t次迭代的目的是寻找一弱学习器ht(x),使第t次迭代的损失最小,即本轮迭代需要找到一个决策树,使样本的损失尽量变得更小。但是损失的拟合不好度量,损失函数的种类也较多,GBDT 选取了容易优化的平方损失作为损失函数。GBDT 中采用损失函数的负梯度来拟合当前迭代损失的近似值,从而拟合一个决策树。
第t轮迭代中第i个样本的损失函数的负梯度为:
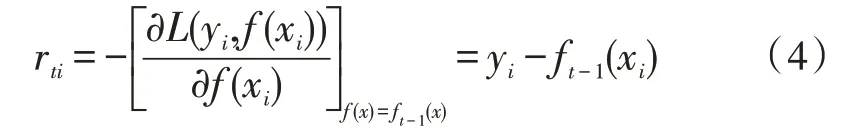
GBDT 伪代码:

2 油耗预测模型建立
2.1 油耗预测模型
现今的船舶油耗预测模型的建立方式主要有两种:建立在已知物理关系基础上和建立在数据统计分析基础上。前者需要完整的船舶设计参数,例如船体线型图、主机型号及参数、螺旋桨设计参数等[3];此外还需要大量实船实验数据,例如静水船模实验、螺旋桨淌水实验、实船航行数据等,分析过程复杂,模型建立难度较大,实用性差。后者只需要对影响船舶油耗的相关因素进行分析,以船舶运营过程的实测数据为基础,结合数学模型得出合适的模型参数从而建立油耗预测模型[4]。通过这种方式建立的油耗预测模型不需经历复杂的分析过程,模型建立难度较小,实用性好,能更加全面地考虑对船舶油耗产生影响的因素,且采用实测数据建立模型,所得模型的准确率较高[5-6]。因此该文基于实测数据结合GBDT 模型建立船舶油耗预测模型,模型框架如图1 所示。
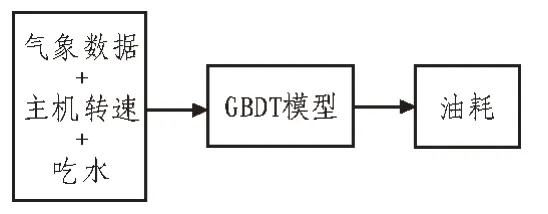
图1 油耗预测模型框架
2.2 模型数据说明及处理
文中选取的研究对象为运营于中国大连港至巴西航线的一艘40 万吨货运远洋船,其航线示意图如图2 所示,对象船单次航程所需时间为45~50 天。
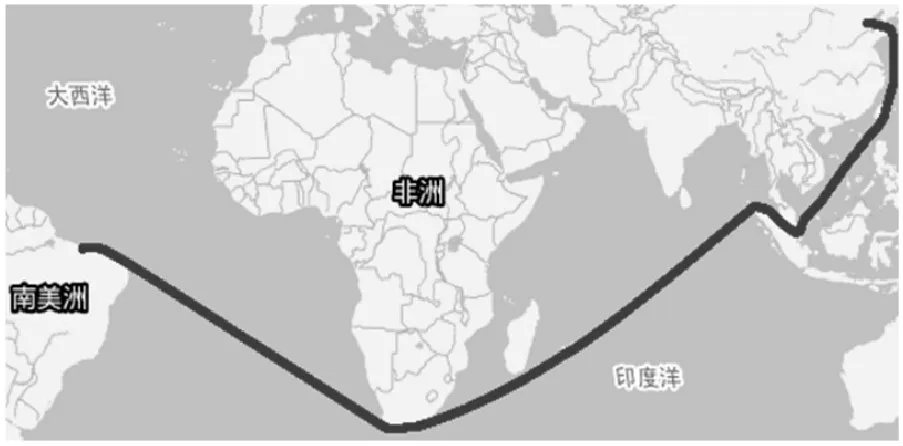
图2 船舶航线示意图
油耗预测模型的基本框架如图1 所示,模型的期望输出为油耗,表1 所列为模型的各输入特征,其中8 个特征为气象数据,4 个特征为航向与气象数据的组合特征,剩余2 个特征为可调节的主机转速和与载货量相关的船舶吃水[7-12]。
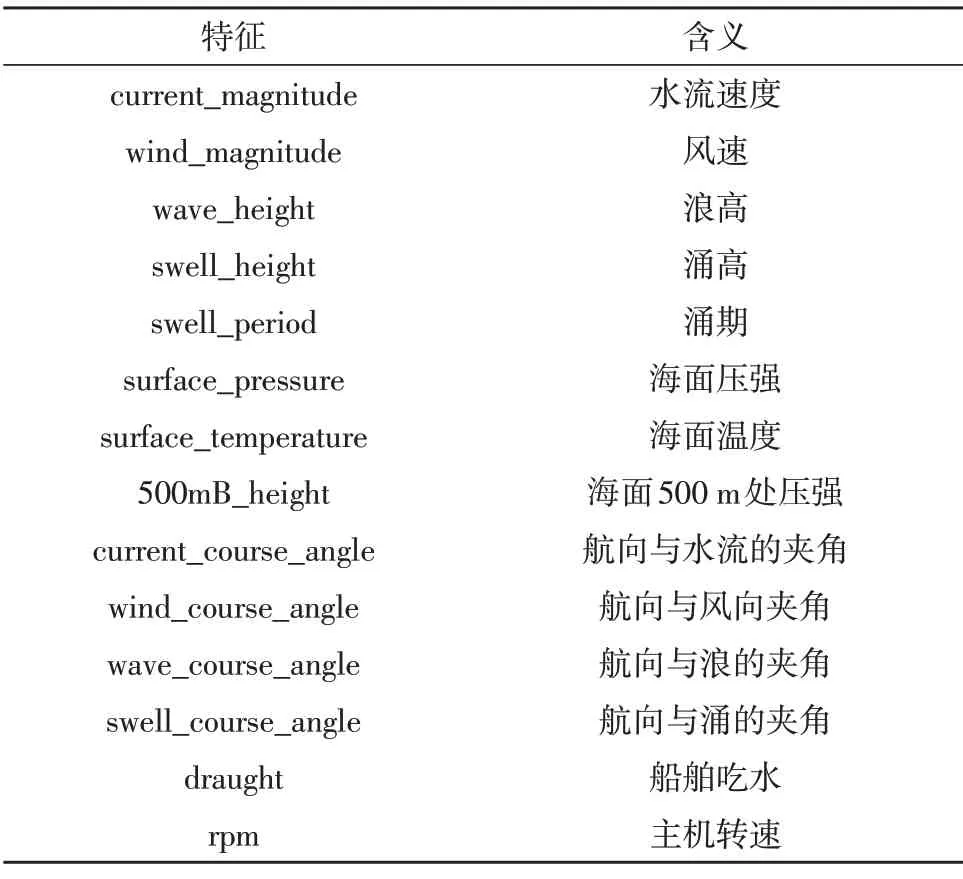
表1 油耗预测模型输入特征
模型建立所用的数据为目标船安装在船体各处的各类传感器所返回实测数据,由于传感器的类别不同,所返回数据的时间间隔也不同,出于模型建立的需要,将实测数据处理为时间间隔都为600 s 的数据,特征处理公式如下:

模型中所用到的气象数据由气象局所提供,数据格式为时间间隔为3 h,区域大小为间隔一经度间隔一纬度的分区域数据。因而在气象数据的处理上需要进行时间和区间上的插值,气象特征处理公式如下:
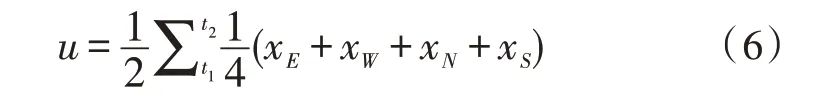
式(6)中,t1、t2分别为所提供气象数据的时刻,即两者之差为3 h,包含所需时间戳;xE、xW、xS、xN分别为包含目标位置点矩形区域的4 个顶点处的气象值。
目标船所能用于进行模型训练验证的历史航行数据有25 538 条,其中包含3 个完整的航次数据和5个短的航段数据,需要将数据划分成3 个数据集:训练数据集、验证数据集、测试数据集,且测试集需为一条完整的航次数据,所以取一个完整的历史航次数据作为测试数据集,该历史航次数据集中包含数据5 433 条,剩余的20 105 条历史航行数据按照4∶1的比例分别划分为训练数据集和验证数据集。
3 目标船的油耗预测结果
3.1 油耗模型预测结果分析
上述模型训练结果的精度衡量标准为模型输出结果与实测数据的总计油耗绝对误差百分比ω和总计油耗误差百分比ε,计算公式如下:
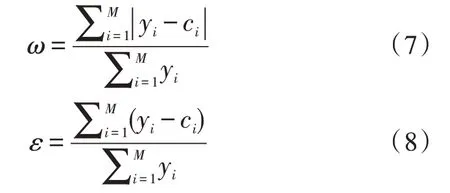
式(7)、(8)中,yi为模型输出油耗期望值,ci为模型输出油耗实际值,M为样本总个数。
在训练数据集上,模型输出数据与实测数据的对比如图3 所示。从图中可以看出,模型在训练完成后,训练样本的油耗输出数据与实测数据基本重合。这表明经过训练后的模型能够基本精确地表达输入特征与输出目标值之间的关系。图4 是模型在测试数据集上的预测效果对比。从图中可以看出,预测结果与实测数据的变化趋势一致,说明所训练出来的模型在测试数据集上表现效果良好。
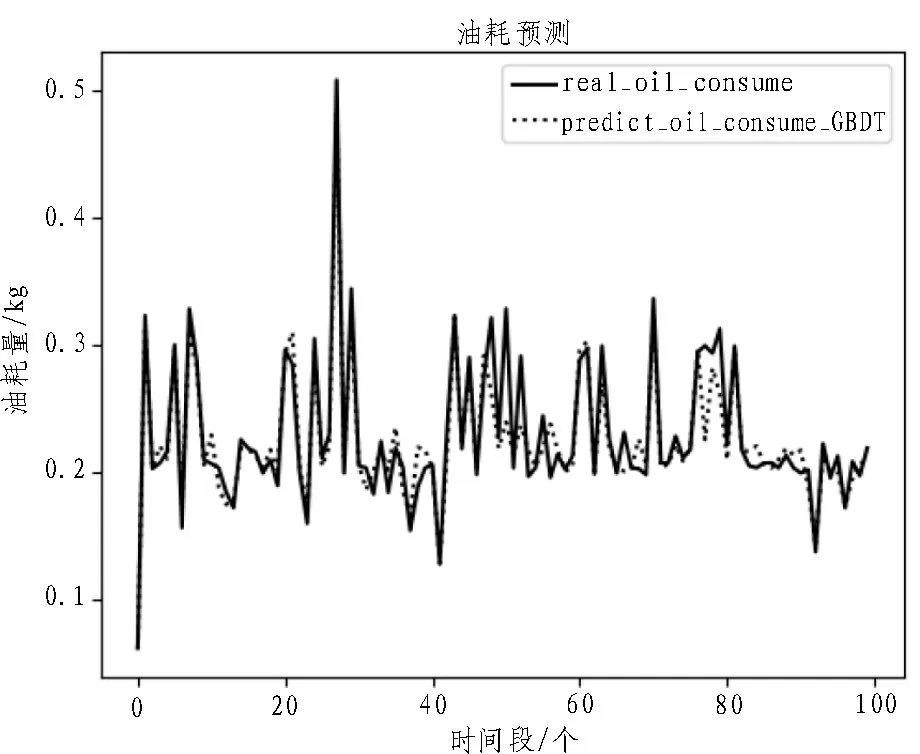
图3 训练结果对比
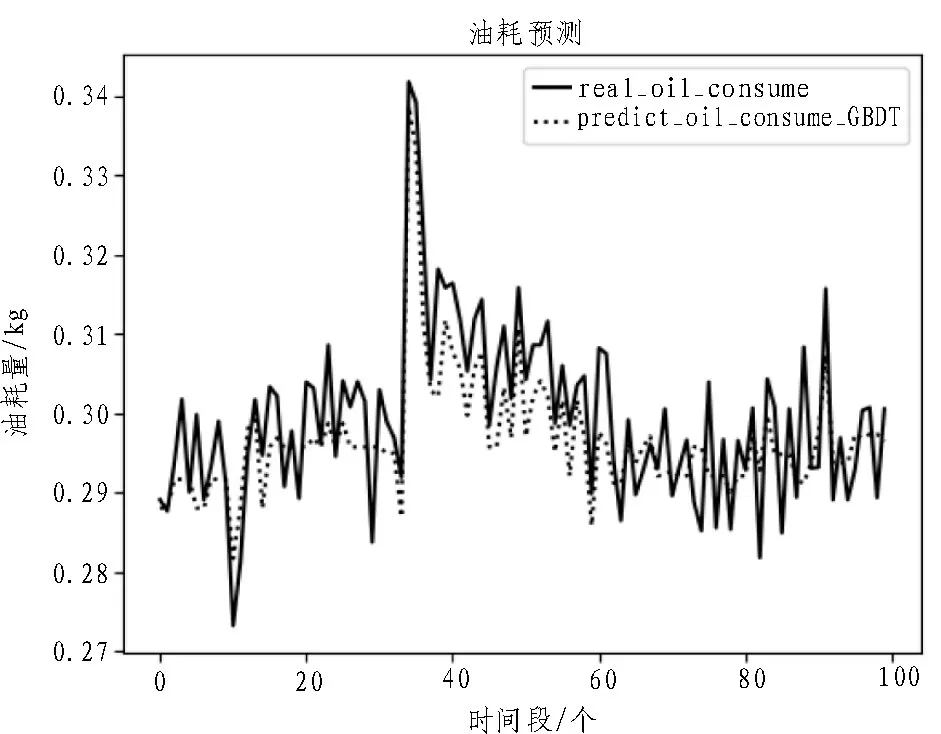
图4 测试结果对比
表2 中列出了模型在训练数据、验证数据和测试数据上的预测误差。从表中数据可以看出,模型的总计油耗绝对误差百分比均低于8.5%,满足后续工程需要,且模型在训练数据、验证数据和测试数据上的误差差距不大,表明模型不存在过拟合现象,模型泛化能力强。

表2 GBDT模型预测误差
3.2 GBDT模型与决策树、随机森林模型的比较
为体现GBDT 模型的优越性,分别基于决策树模型和随机森林模型建立油耗预测模型,对比基于3 种不同模型建立的油耗预测模型的预测效果。
依据图1 中的油耗预测模型框架分别构建基于决策树模型和随机森林模型的油耗预测模型,保持模型建立过程的一致性。同时,使用相同的交叉验证数据分组,避免训练数据集、验证数据集、测试数据集不同所带来的差异,保证对比结果的可信度[13-16]。
图5 为基于GBDT、RF、DT 所建立油耗预测模型的模型预测值与真实观测值之间的对比,可以看出基于GBDT 建立的油耗预测模型的预测效果最佳,预测值的趋势与真实值趋势一致。
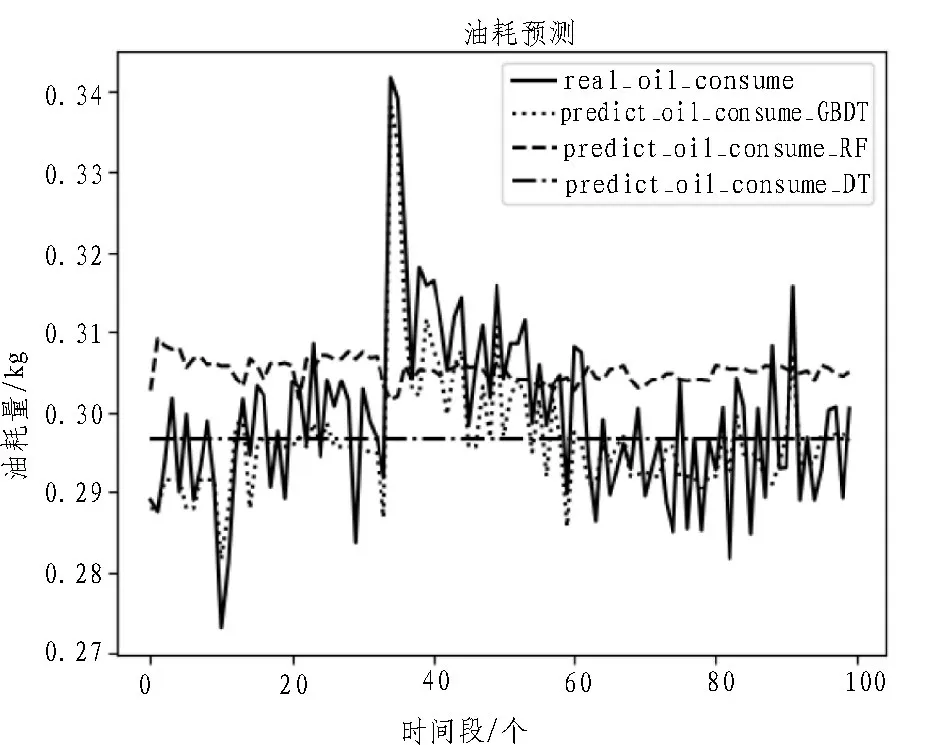
图5 GBDT模型与决策树、随机森林模型预测效果对比
表3 为各模型预测性能指标的汇总。从表中可以看出,在测试数据集上GBDT 模型的表现效果最好,其次为随机森林模型,且GBDT 在训练数据集、验证数据集、测试数据集上的预测误差相差不大,变化幅度在正常范围内说明GBDT 模型的泛化能力强于其他两个模型。
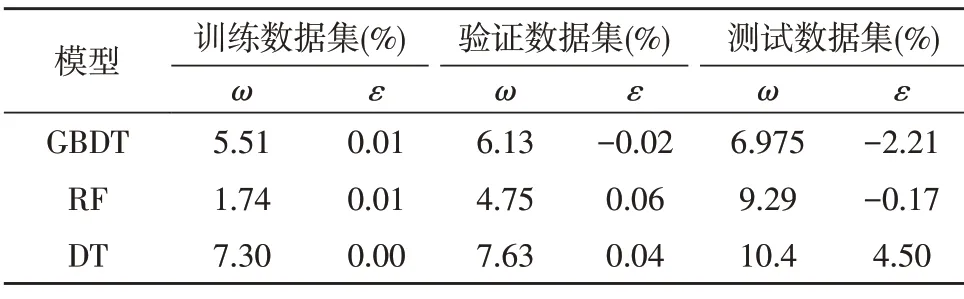
表3 不同模型在油耗预测上的效果汇总
4 结论
文中以某一远洋船的实际运营数据作为基础,结合GBDT 算法构建了单位时间内船舶油耗预测模型,依据实验结果可得如下结论:
1)GBDT 算法能够以实船监测数据为基础构建单位时间内船舶油耗预测模型,由实验结果得到,GBDT 模型可以比较精确地预测船舶油耗,且将误差控制在6.98%以内,预测效果优于基于相同样本建立的随机森林模型和决策树模型,可考虑作为进行后续船舶运行优化的基础;
2)基于GBDT 建立的油耗预测模型在训练数据集、验证数据集、测试数据集上的表现效果差别不大,模型泛化能力良好;
3)文中模型的输入变量大部分为气象数据,后续需要对影响船舶油耗的因素作进一步分析,以期在合理的精度范围内以最少的输入变量数目构建船舶油耗预测模型。
