短文本聚类方法研究综述
2022-01-24和志强王梦雪
和志强,王梦雪,马 宁,陈 萌
(河北经贸大学 信息技术学院,河北 石家庄 050061)
0 引言
随着信息传播速度的提高与网络空间的不断扩大,互联网信息量呈指数级快速增长,非结构化文本数据量不断增大[1]。为有效利用文本数据中所蕴含的有价值信息,通过聚类算法依据文本数据间的共性特征构建文本聚簇来完成后续的信息处理与分析,是有价值信息提取的重要一环。短文本数据主要分为社交媒体类、新闻类、观点评论类、问答类、摘要类等,通常应用于事件检测[2-3]、信息检索[4]、信息推荐[5]等方面。短文本数据呈现语义稀疏、表意歧义和噪声较多的特点[6]。因此对低词汇量的短文本提取其有效特征进行低维稠密向量化表示,是影响聚类结果好坏的关键步骤。此外在不同应用场景下,应根据数据特点来计算文本间相似度,以达到聚簇内部相似性高与簇间相似性低的聚类要求。
本文从短文本向量化表示方法和聚类评价两方面对短文本聚类研究进行综述,在不同类别的聚类算法的基础上,对基于文本离散化表示与分布式表示的聚类方法的优化、改进与应用进行研究,并对聚类效果的常用评价方法进行总结。
1 短文本聚类方法研究概述
短文本聚类算法是一种无监督分析算法,能够定量化描述数据中的集聚现象,挖掘非结构化短文本数据中隐含的重要信息。文本聚类方法主要分为基于划分的聚类算法、基于层次的聚类算法、基于密度的聚类算法、基于网格的聚类算法、基于模型的聚类算法和基于模糊的聚类算法[7],其主要思想、典型算法与特点如表1所示。文本的向量化表示是短文本间相似度计算与聚类分析的基础,文本向量化是将文本表示成为计算机可识别与计算的结构化实数向量。文本表示方法依据其粒度大小分为基于字、基于词、基于句子和基于篇章四种层次,方法包括文本数据的离散化表示与分布式表示。

表1 文本聚类算法类别
1.1 基于文本离散化表示的聚类方法
文本的离散化表示以字、词汇之间相互独立为基础,构成不考虑关联性的独立词典,通过词频统计的方式对文本进行表示,常用离散化文本表示方法及其特点如表2所示。One-Hot Representation作为最简单的词向量化表示方法,目前主要应用于其他语言模型中文本的输入编码。在此基础上的词袋模型是基于句子与篇章级的文本编码模型,其根据一段文本中包含词的出现次数来对文本进行编码。N-gram算法常应用于相似度计算与歧义切分。王贤明[8]等提出了一种基于随机N-gram的长文本相似度计算方法,充分利用粗粒度与细粒度的上下文特征对文本进行编码表示。凤丽洲[9]等利用N-gram能获取双向局部特征的特性,来实现最优分词序列的选择,有效解决长词歧义切分问题。
Salton G[10]等提出的TF-IDF算法常作为基础表示向量的特征权重计算方法与其他特征属性提取算法相结合使用。黄承慧[11]等在使用TF-IDF提取重要词项的基础上,借助外部词典扩充语义信息来计算文本间相似度。王少鹏[12]等把LDA主题模型与TF-IDF结合,依据主题与特征权重两方面来计算相似度,利用K-means进行聚类实现舆情分析。陈朔鹰[13]等在TF-IDF的基础上利用词语的时间属性来计算增长速度,将词语的动态属性融入编码特征中,利用CURE来进行聚类实现话题检测。叶雪梅[14]等使用NLPIR PARSE中文分词工具对文档新词的TF-IDF权重进行优化,在保证提取文本中有效特征的同时,降低其特征向量维度。张蕾[15]等将已有学科分类信息加入至TF-IDF特征权重的计算中,来解决一词多义的编码问题,并通过K-mean++依据论文关键词进行学科聚类。

表2 离散化文本表示方法
1.2 基于文本分布式表示的聚类方法
针对文本的离散化表示中存在的维度灾难、向量稀疏、不能捕捉长距离信息、不能表示文本潜在的语法与语义信息的问题,产生了将高维向量映射为更加低维、稠密的连续向量的分布式表示方法[16],该方法利用语言模型依据上下文信息来对词汇进行表示,充分考虑词之间的联系。常用分布式文本表示方法及特点如表3所示。其中NNML[17]和Word2Vec[18]属于静态词向量表示,Word2Vec因为其训练的高效性与表示的低维性常作为原始特征向量,来进行后续特征提取与融合运算。孙昭颖[19]等针对短文本特征稀疏的特点,在Word2Vec的基础上利用卷积神经网络进行特征提取形成稠密向量,再通过K-means进行分析验证其有效性。蔡庆平[20]等同样将Word2Vec与卷积神经网络联合使用,对产品评论进行缩短分割,依据提取的特征词实现产品与评论的聚类。颜端武[21]等利用LDA主题模型提取的浅层特征与加权Word2Vec提取的语义特征融合构建文本表示向量,再使用K-means实现微博的主题聚类。
属于动态词向量的表示方法ELMo[22]、GPT[23]和BERT[24]是在基础语言模型训练得到词向量的基础上,再在实际应用场景中对其进行动态调整,解决了静态词向量表示中的一词多义问题[25]。2018年由Google发布的基于双向Transformer的BERT模型在各项NLP任务中表现出惊人成绩,BERT模型利用大规模无标注语料进行训练,来获取包含丰富语义信息的表示特征。程思伟[26]等利用BERT的预训练词向量和图卷积神经网络来强化特征表示。朱良奇[27]等在BERT预训练的文本表示基础上利用自编码器与K-means联合训练,优化特征提取与聚类模块,实现短文本聚类。唐晓波[28]等在LDA主题聚类的基础上,通过Sentence-BERT 预训练模型编码问题的语义表示,实现辅助问答系统。

表3 分布式文本表示方法
2 聚类结果的无监督评价方法
对无标签数据的聚类结果进行评价,是引导聚类算法优化与改进的重要依据,采用人工评价方法存在低效、高主观性与高成本的问题,无监督聚类评价指标的构建在一定程度上解决了这些问题。聚类结果的无监督评价是基于聚类自身进行评估,即保证聚类的结果是类间相似性低,类内相似性高。常用指标及其计算方法如下。
2.1 误差平方和(SSE)
通过计算拟合数据与原始数据对应点的误差平方和来判断聚类效果,其在K-means中应用的计算公式如式(1)。其中p代表预测值,m代表原始样本点,SSE值越接近于0,则说明模型与数据拟合度越好。
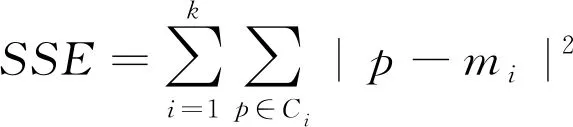
(1)
2.2 轮廓系数(SC)
轮廓系数由评价簇内样本点差异的聚合度和评价簇间差异的分离度两部分组成,聚合度由样本点到其他样本点的平均距离,聚合度a(k)计算如式(2),簇内样本点的紧密程度由所有样本点聚合度的均值表示。
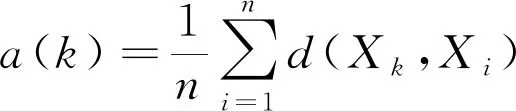
(2)
分离度由簇内样本点到其他簇外样本点的最小平均距离,分离度b(k)计算如式(3),簇间样本点的紧密程度由同簇内所有样本点分离度的均值表示。
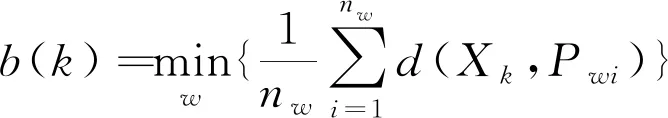
(3)
簇内样本点Xk的轮廓系数计算如式(4),聚类的轮廓系数由簇内所有样本点的轮廓系数的均值表示,当轮廓系数趋近于1时表示聚类效果越好。轮廓系数适用于类别未知的情况,不适用于不同聚类算法之间的比较。

(4)
2.3 Calinski-Harabasz(CH)指数
CH指数通过最小化簇内数据协方差,最大化类别之间协方差来评价聚类效果,其计算如式(5),其中m为训练样本数,k为聚簇数,Bk为簇间协方差矩阵,Wk为簇内协方差矩阵,CH指数越大表示聚类效果越好。CH指数不适用于基于密度的聚类算法评价。

(5)
2.4 Davies-Bouldin(DB)指数
DB指数通过计算任意两聚簇的簇内所有点到中心的平均距离和,除以两聚簇中心距离,求最大值,计算如式(6)。其中n为聚簇数,ci表示第i个聚簇的中心,σi表示簇内样本点到聚簇中心的平均距离,DB指数越小代表聚类效果越好。DB指数不适用于环状分布聚类评价。

(6)
3 总结与展望
本文根据短文本数据特点解释了文本的向量化表示与特征提取对其聚类分析与处理的关键性,并分别阐述了基于文本离散化表示与基于文本分布式表示的短文本聚类方法及其优化、改进与应用。介绍了常用聚类评价算法原理及其应用特点。经过对现有算法与研究的总结与分析,得出在短文本聚类分析过程中,首先应该对文本进行基础词向量编码,再对其特征向量进行赋权调整,融合深层语义与文本结构信息,使其映射至低维稠密向量,最后根据聚类评价指标来训练优化聚类模型。
短文本数据爆炸式增长的态势下,提取其中有效信息仍然是研究的重点。针对短文本稀疏性特点,识别短文本中关键信息与关键信息的强化,对后续的聚类聚类分析实现与聚类效果的提高具有极高的促进作用,因此后续工作应围绕其进行研究与开发。
