一种基于产品方面的神经网络推荐模型
2022-01-23王素格刘宇飞符玉杰郑建兴
王素格, 刘宇飞, 李 旸, 符玉杰, 郑建兴
(1.山西大学 计算机与信息技术学院 山西 太原 030006;2.山西大学 计算智能与中文信息处理教育部重点实验室 山西 太原 030006;3.山西财经大学 金融学院 山西 太原 030006)
0 引言
推荐系统是电子商务和服务型移动终端应用发展的必然产物,给人们的生活提供了便利。目前,在许多电子商务网站或论坛中存在着大量的用户评论,这些评论可以作为推荐系统中重要的信息补充。用户在文本评论中经常针对产品的某些方面发表自己的使用感受,例如,在汽车领域有外观、动力、操控、舒适性等方面。用户评论在一定程度上蕴含着用户的个人偏好以及用户对项目性能的体验,可以作为用户对项目某些方面进行评分的依据。
近年来,在推荐系统领域涌现出利用深度学习处理文本信息的一些方法,主要有卷积神经网络[1-2]、循环神经网络[3]以及去噪自动编码器[4]。现有的方法只简单地为每一个用户和项目计算一个低维的向量,并进行最后的评分预测,这样的做法忽略了用户和项目之间的细粒度交互过程[5]。在用户/项目方面级别细粒度交互的ANR方法[6]中,仅仅将方面作为一个随机初始化的矩阵,使得方面表示的准确性无法得到保证。以往推荐系统的研究大都关注于如何提高推荐的准确性,较少考虑与用户的交互。若推荐系统给出适当的例子与用户交互,不仅能够提升系统的透明度,还可以提高用户选择推荐产品的概率以及用户的满意度。文献[7]使用情感词库提取用户/项目评论集中的显式特征,从而给出特征级别的解释。文献[8]针对序列推荐任务,利用注意力机制获得目标用户的历史交互项目的重要性,从而给出项目级别的解释。文献[9]通过使用知识图谱中用户与项目之间的连接路径学习组合关系表示,并通过具体路径给出推荐解释。本文改进了ANR模型的方面表示,提出一个基于产品方面的神经网络推荐(product aspect-based neural network recommendation,PANNR)模型。该模型将用户/项目评论中的具体方面融入模型的输入,并使用注意力机制突出评论中重要的部分,得到用户和项目的方面级别的表示。在此基础上,通过注意力机制建模用户和项目间的细粒度交互过程,以提高推荐结果的可解释性。此外,在中文汽车领域数据集和英文Yelp公开数据集上与NARRE[2]和ANR[6]方法进行了对比实验,验证了所提方法的有效性。
1 PANNR模型框架

图1 结合产品方面的推荐模型框架
PANNR模型框架中一些模块的具体性能如下。
1) 嵌入层。用户评论集Tu中包含了与用户u有交互历史的若干项目的评论,同样地,项目评论集Ti中包含了与项目i有交互历史的若干用户的评论。对Tu和Ti采用两种词嵌入方式:一是采用word2vec或Glove[10]词向量,获得PANNR+W推荐模型;二是采用BERT[11]的变体模型BERT-wwm产生预训练向量,获得PANNR+B推荐模型。在PANNR+W模型中,使用word2vec或Glove预训练词向量,将用户评论集Tu转化为词向量矩阵Mu∈Rn×d,其中n是用户评论集Tu中的词数,d是每个词向量的维度。在PANNR+B模型中,使用哈工大讯飞联合实验室发布的基于全词覆盖的中文BERT预训练模型BERT-wwm,将其应用到用户/项目评论集和用户/项目方面集的表示中。在利用BERT海量语料基础上,通过自监督学习方法为每个字学习一个特征表示,再根据推荐任务通过BERT进行微调,获取与用户/项目整体评分预测任务相关的特征,从而将用户评论集Tu转化为字向量矩阵Mu∈Rn×d,其中n是用户评论集Tu中的字数,d是每个字向量的维度。最终得到方面级别的用户表示Pu={pu,a|a∈Au},Au为用户方面集且|Au|=K。
2) 全连接层。该层使用参数矩阵Wk∈Rd×h1,其中k∈{0, …,K}。将用户评论集初始化表示Mu∈Rn×d进一步重新表示为Mu,k∈Rn×h1。为得到多方面的用户表示pu,a,在全连接层使用K个不同的映射矩阵Wk对用户评论集进行重新表示,每一个映射矩阵Wk在全连接层的用户评论集表示为
Mu,k=MuWk。
(1)
zu,k[j]=(Mu,k[j-(c-1)/2]:…:
Mu,k[j]:…:Mu,k[j+(c-1)/2]),
(2)
其中:“:”是拼接操作,将窗口内的字表示进行拼接;Mu,k[j]为用户u的评论集的第j个字表示;c为窗口大小,它由词向量的维度d和h1得出,即
c=d/h1。
(3)
利用(2)式的zu,k[j]与用户方面a的表示vu,a,通过内积计算第j个字对方面a的注意力得分。将用户评论集中所有字的注意力得分进行Softmax归一化,得到注意力权重向量,可以表示为
attnu,a[j]=Softmax(vu,a(zu,k[j])T),
(4)
(5)
其中:attnu,a[j]为用户评论集第j个字相对于用户方面a的注意力权重向量。第j个字的重要性取决于第j个字和其周围窗口大小c之内的字。利用注意力权重向量attnu,a与用户u的评论集表示Mu,k,通过加权和得到特定方面a的用户表示pu,a,即
(6)
同理,通过上述过程可以得到项目i特定方面a的表示qi,a。在用户和项目之间共享每一个映射矩阵Wk,而用户方面集Au是从用户评论集提取而来,因此每个用户的方面集各不相同。同样地,项目方面集Ai是从项目评论集提取而来,因此每个项目的方面集也各不相同。
4) 方面重要性学习层。不同用户对项目的某些方面有着各自不同的偏好,例如,用户A可能喜欢某款车的外观,而用户B可能喜欢同款车的大空间和舒适性。另外,在用户进行总体满意度的评分时,各个方面往往并不相互独立。因此,本文动态估计每个用户/项目对的用户方面重要性和项目方面重要性,使用一个动态估计方面重要性学习模块,在方面级别上建模用户和项目之间的细粒度交互过程,其目的是得到用户方面重要性权重向量βu∈RK和项目方面重要性权重向量βi∈RK。
为了在计算用户方面重要性时融入方面级别项目表示,以及在计算项目方面重要性时融入方面级别用户表示,假设方面级用户表示和项目表示分别为Pu∈RK×h1和Qi∈RK×h1,构建方面级交互矩阵S,可以表示为
AURK属于丝氨酸-苏氨酸激酶,在调控细胞周期方面起重要作用[34]。本实验结果表明,Danu是通过抑制AURK和p53-p21信号轴来影响HepG2细胞周期分布的。AURK活性受到抑制后,中心体成熟受限,纺锤体非正确组装并延迟分裂退出,最终导致HepG2细胞阻滞于G2/M期。此外,胞质分裂被阻止,导致异倍体的出现。Danu上调了p53和p21的表达,进而抑制Cyclin B1-CDC2复合体的活性,最终导致HepG2细胞阻滞于G2/M期。
(7)
其中:Ws∈Rh1×h1是一个可学习的参数矩阵;ReLU(x)=max(0,x)为激活函数。利用方面级交互矩阵S,并参考文献[12]将其作为特征,可以得到在特定用户/项目对场景下的用户潜在表示Hu和用户u的方面重要性权重向量βu,分别表示为
Hu=ReLU(PuWx+ST(QiWy)),
(8)
βu=Softmax(Huvx),
(9)
其中:Wx∈Rh1×h2、Wy∈Rh1×h2和vx∈Rh2是可学习的参数矩阵。同理,可得项目潜在表示Hi,
Hi=ReLU(QiWy+S(PuWx))。
(10)
通过项目潜在表示Hi可得项目i的方面重要性权重向量βi,
βi=Softmax(Hivy),
(11)
其中:vy∈Rh2是可学习的参数矩阵。在式(8)和式(10)分别计算Hu和Hi时,均利用了方面级用户表示Pu和方面级项目表示Qi。这样,可以利用方面重要性学习层获得用户方面重要性权重向量βu和项目方面重要性权重向量βi,且它们均与具体用户和具体项目相关。
5)预测层。结合方面级用户表示Pu、方面级项目表示Qi、用户方面重要性权重向量βu和项目方面重要性权重向量βi,建立预测用户u对项目i的总体评分模型,可以表示为
(12)
其中:bu、bi、bo分别为用户偏置、项目偏置和全局偏置。
2 实验
在中文汽车领域数据集以及英文Yelp公开数据集上进行实验,用于评估本文模型PANNR+W和PANNR+B的性能。
2.1 实验数据
中文汽车领域数据集来自第七届中文倾向性分析评测(COAE2015)的细粒度标注数据,与标准推荐数据集的不同之处在于该数据集是带有方面标签的交互数据。采用8∶1∶1的比例将数据集划分为训练集、验证集和测试集,并保证验证集和测试集中交互数据对应的用户和项目都包含在训练集中。
英文Yelp公开数据集是从Yelp餐厅领域数据集中筛选出交互数量大于10的用户和项目,并且在每条交互数据的基础上,使用外部模型BERT-E2E-ABSA[13]提取文本评论中的方面信息作为方面标签。同样地,去除验证集和测试集中未在训练集中出现过的用户和项目,使用8∶1∶1的比例将数据集划分为训练集、验证集和测试集。两种数据集的统计情况如表1所示。

表1 两种数据集的统计情况
2.2 模型参数设置
使用均方误差(MSE)作为模型的损失函数,并利用反向传播学习模型获得各个层的参数。为了评价参数h2对模型性能的影响,通过调整参数的范围,将参数h2在区间[50, 220]做步长为10的增长,在Yelp公开数据集上进行实验,h2对模型性能的影响如图2所示。可以看出,模型的性能在整体上会随着参数h2的增长而产生波动,当h2设置为60时,模型达到最佳性能。

图2 h2对模型性能的影响
经过调整超参数,对中文汽车领域数据集与Yelp公开数据集采取了不同的实验设置。对于中文汽车领域数据集,在数据预处理中使用jieba对用户评论集和项目评论集的文本评论进行分词,将输入的用户评论集Tu和项目评论集Ti的长度设置为500,输入的用户方面集Au和项目方面集Ai的大小设置为5;模型中局部注意力窗口大小设置为3,h1设置为100,h2设置为50,学习率设置为0.002。对于Yelp公开数据集,将Au和Ai的大小设置为10;模型中局部注意力窗口大小设置为1,h1设置为300,h2设置为60,学习率设置为0.000 6。两种数据集均使用Adam算法进行优化,所有的实验采用五次不同的随机初始化,将得到的MSE值取平均数,作为性能的评估标准。
2.3 对比实验结果及分析
为了验证PANNR+W方法的有效性,选取NARRE和ANR两种方法在相同预训练情况下进行模型性能比较。在中文汽车领域数据集上使用word2vec预训练词向量,在Yelp数据集上使用Glove预训练词向量,不同方法在两种数据集上的MSE结果如表2所示。可以看出,PANNR+W模型在中文汽车领域数据集和Yelp公开数据集上的MSE均优于NARRE和ANR模型。另外,中文汽车领域数据集的MSE显著低于Yelp公开数据集,这是由于在中文汽车领域数据集中用户/项目交互的整体评分标签为“1”“2”“3”,而非Yelp公开数据集的“1”“2”“3”“4”“5”。
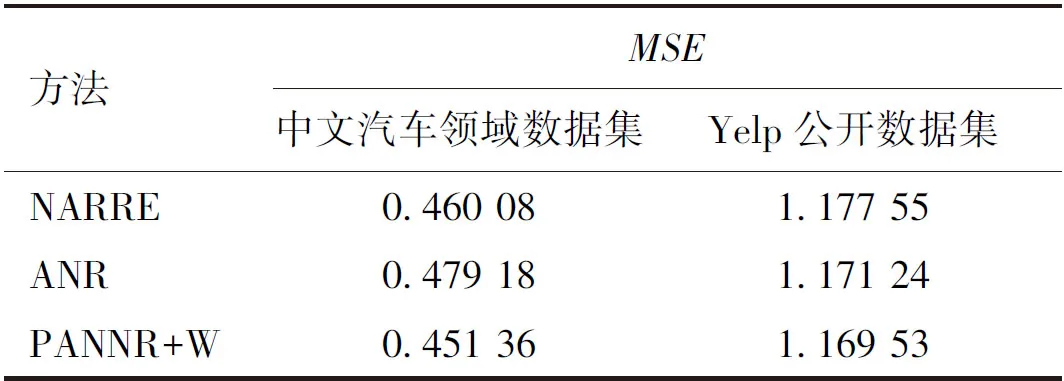
表2 不同方法在两种数据集上的MSE结果
此外,为了获得更加全面的对比,将PANNR和ANR均采用BERT-wwm预训练模型,即为PANNR+B和ANR+B模型,这两种模型在中文汽车领域数据集的MSE结果分别为0.427 65 和0.438 17,表明无论采用哪一种预训练,本文方法都是比较好的。
2.4 消融实验
为了分析模型中各个部分对预测结果的有效性,使用四种简化模型与PANNR+B模型进行比较实验,模型超参数设置与2.2节一致,四种简化模型如下。
1) PANNR+B-全连接模型。利用式(1)将用户评论集、项目评论集的表示输入全连接层得到新表示时,使用一个整体共享的参数矩阵W,而不是K个参数矩阵Wk。
2) PANNR+B-方面重要性学习模型。直接使用方面级用户表示和方面级项目表示作为预测层的输入,计算K个方面上的算术平均,省略方面重要性学习层中建模用户和项目的细粒度交互过程得到的方面重要性。
3) PANNR+B-显式方面模型。该模型等同于ANR+B模型,使用随机初始化的向量来代替显式的方面信息,而不使用用户方面集和项目方面集。
4) PANNR+W模型。在进行模型输入时,选用word2vec直接获得用户评论集、项目评论集、用户方面集以及项目方面集的词表示,而不使用BERT-wwm。
在中文汽车领域数据集上,不同模型消融实验的MSE结果如表3所示。可以看出,① 在全连接层使用单个共享参数矩阵的变体模型PANNR+B-全连接,其性能大幅下降,因此在全连接层使用K个参数矩阵是有必要的。② PANNR+B-方面重要性学习模型在计算评分时,由于忽略了方面重要性权重向量而使模型的推荐效果不佳,因此使用方面重要性学习层动态捕捉用户偏好和项目特性,对模型性能的提升是不可或缺的。③ 在基于产品方面的注意力层中未使用方面标签信息的变体模型PANNR+B-显式方面,系统的推荐性能明显下降,说明方面标签信息对于建模用户偏好和项目特性起到了至关重要的作用。④ 使用word2vec进行词表示的模型PANNR+W,其性能劣于PANNR+B,说明使用BERT获得模型输入的表示对模型性能有提升作用。

表3 消融实验的MSE结果
2.5 基于方面信息的推荐解释
在中文汽车领域数据集中随机地选取一条用户评论数据作为示例,以展示基于方面的注意力层的计算结果。用户评论注意力热度图如图3所示,注意力分数越高的词汇对应的色块颜色越深。

图3 用户评论注意力热度图
在图3中,w1, w2,…, w14分别为[‘速腾’, ‘不错’, ‘,’, ‘但’, ‘不’, ‘便宜’,‘;’, ‘甲壳虫’,‘拉风’,‘,’,‘太’,‘不’, ‘实用’,‘;’],是由文本评论使用jieba分词得到的。方面1,方面2,…,方面5分别为[‘性价比’, ‘外观’, ‘实用性’, ‘〈pad〉’, ‘〈pad〉’],是本条评论的方面标签。在方面个数设为5时,为了使方面个数保持一致,第4个标签和第5个标签的表示向量采用随机初始化的形式赋值。可以看出,注意力层对于与显式方面标签相关的词汇及其评价词分配了较高的注意力权重。因此,利用显式方面标签,可以将推荐结果形成模板的推荐解释。例如,在选购商品时,可能关注此款商品在性价比、外观、实用性等方面的表现,若它在这些方面有比较好的表现,便可以推荐此款商品。同样地,对于得到较低预测评分的用户/项目对,可以通过类似的解释来说明此款商品不适合特定用户的原因。
3 小结
本文提出一个基于产品方面的神经网络推荐(PANNR)模型,由于PANNR模型包含基于产品方面的注意力模块和方面重要性学习模块,使模型利用显式方面标签作为重要的输入信息与文本评论组成了模型的输入部分,得到用户和项目的方面级别的表示,通过方面重要性学习模块建模特定用户/项目对的细粒度交互过程,使用户评论信息得到更有效的利用。通过一系列的实验验证了推荐模型的有效性,而且通过可视化展示说明了模型具有可解释性。在以后的工作中,将进一步挖掘用户对项目具体方面的情感信息,以提高模型预测评分的性能,并进一步利用注意力机制得出更具可解释性的推荐结果。
