基于改进YOLOv2的动车组裙板螺栓检测
2022-01-22刘伟铭邹星宇
刘伟铭,邹星宇
(华南理工大学土木与交通学院,广州 510640)
引言
自2007年国内第一列动车组投入运营,铁路事业蓬勃发展,截至2020年7月底,全国铁路营运总里程达14.14万km,高铁线路占3.6万km,国内已建成世界最大的高铁网[1]。动车组高速运行过程中,任何细微的故障都有可能造成很大的安全隐患,虽然国内极少出现动车组运营过程中的重大安全事故,但因故障导致的列车紧急停车与晚点却时有发生[2]。随着动车组每日发行量的增加,以智能化与信息化为主导的高速铁路安全防护技术成为动车组安全运行的重要保障[3]。动车组运行故障检测系统(Trouble of moving EMU Detection System,TEDS)是一套对动车组运行状态图像进行实时监控的联网监控系统,减少了传统人工列检的压力,充分提高了列检效率。该系统利用高速线阵相机采集运行中的动车组车身、底板图像,通过网络传输至数据分析中心,供室内分析员分析列车关键部位的状况[4]。图1为动车组运行故障动态图像检测系统概览。

图1 动车组运行故障检测系统概览
动车组结构复杂,零部件多,其中螺栓起着固定车身以及零部件的作用,高速运行的动车组难免出现因振动等原因导致的螺栓丢失情况。图2为系统传回的一张裙板扫描图像,其中,绿框标注的为螺栓区域,图像中多个螺栓均为尺寸近似的小目标。TEDS系统中4枚线阵相机负责扫描动车组车身,动车组经过时,以8编组动车组为例,每一枚相机可以捕获200多张扫描图像,TEDS分析员需在15 min完成动车组扫描图像的分析,包括判别800多张裙板图像中螺栓正常或丢失的状态。

图2 裙板扫描图像示例
短时间内依靠人工识别大量的图像,不仅费时费力,还难以保证准确率,因此,亟需一套智能的目标检测算法提升TEDS系统图像处理能力,保障动车组运行安全。
目标检测主要分为基于手工特征和卷积神经网络的方法,随着深度学习的不断发展,基于卷积神经网络(Convolutional Neural Network,CNN)的目标检测算法逐渐发展为TWO-STAGE和ONE-STAGE方法[5]。TWO-STAGE方法先提取图片中目标的候选区域,再利用卷积神经网络进行检测,该方法检测精度高,抗干扰能力强,但速度较慢,主要有Fast R-CNN[6]、Faster R-CNN[7]等算法。ONE-STAGE方法对整张图像进行卷积,直接预测出图像中的位置与分类信息,该方法结构简单,检测速度快,但精度与鲁棒性较差,主要有YOLO系列[8-11],SSD[12]等算法。
目前,已有学者将卷积神经网络用于铁路图像的处理[13-15],运行列车关键部位的检测[16-21]。由于运行动车组裙板螺栓丢失样本过少,对TEDS系统采集的裙板螺栓丢失图像进行平移,旋转以及缩放操作,扩充成裙板螺栓缺陷数据集。为保证实时的检测效果,选取ONE-STAGE算法中具有代表性的YOLOv2、YOLOv3、YOLOV4进行实验。
1 YOLO系列算法
1.1 YOLOv2
YOLOv2在YOLO的基础上提高了定位的准确度与召回率,同时对检测速度进行了提升。YOLOv2采用Darknet-19作为骨干网络,图3为Darknet-19的网络结构。
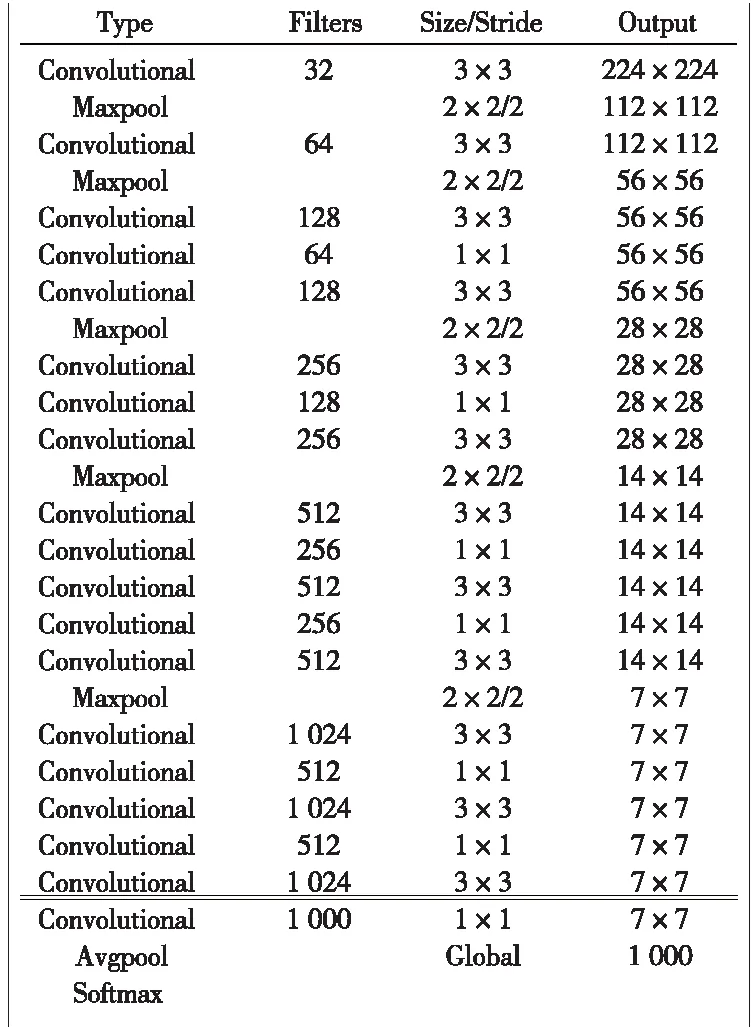
图3 Darknet-19网络结构
该网络去除了全连接层,使用全局平均池化的方法得到固定长度的特征向量,从而可以输入高分辨率的图像进行训练和检测。为获得更丰富的特征信息,YOLOv2输入尺寸为416×416,经过5次降采样后,得到13×13的特征图,通过分类器进行目标检测与分类。算法处理过程中,首先将图片划分成13×13的网格,当目标的中心落在单元格的中心时,由该单元格预测目标的边界框与种类。每个单元格预测的位置信息为(tx,ty,tw,th),但与YOLO不同,输出的位置信息是相对该单元格坐标(cx,cy),宽高(pw,ph)的偏移量,因此,目标边界框可表示为
(1)
另外,与YOLO中手工选取待检测目标先验框不同,YOLOv2使用K-Means对训练数据集的目标边界框进行聚类,使训练过程中预设的先验框与真实的目标边界框能有更高的交并比(IOU),从而提高训练速度,提升模型稳定性及检测精度。IOU计算公式如式(2)所示,当IOU=1时,表示先验框与目标边界框重合。
(2)
式中,btrue为真实的标注框;bpred为算法初始的候选框。先验框与目标边界框的距离函数定义为
d(box,centroid)=1-IOU(box,centroid)
(3)
相比较传统的欧式距离,这种表示方法使得误差与边界框的绝对大小无关。box与centroid分别表示训练数据集标注的边框与聚类算法计算得出的边框。
1.2 YOLOv3
YOLOv3采用Darknet-53作为骨干网络,利用残差网络(Residual Network,ResNet)[22],解决了随网络深度增加产生的模型退化问题,有效避免训练过程中梯度消失和梯度爆炸的情况,提高了模型的特征学习能力。但更深层的网络结构相应增加了计算量,相对YOLOv2,YOLOv3检测速度有明显的下降。图4为YOLOv3网络结构示意。
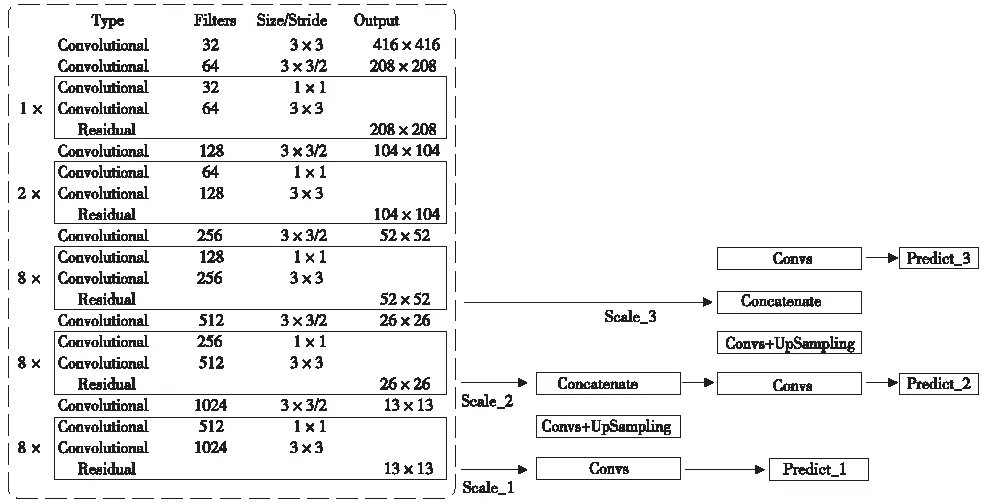
图4 YOLOv3网络结构示意
图4中左侧虚线框为Darknet-53网络,输入图像为416×416分辨率时,经过8倍,16倍以及32倍下采样,输出13×13,26×26,52×52的特征图。同时,YOLOv3借鉴了特征金字塔网络(Feature pyramid networks,FPN)[23],融合多尺度特征进行目标检测,通过卷积与上采样将不同尺度的特征图融合,得到13×13,26×26,52×52的特征输出,将输出特征图上分别做独立检测,提升小目标的检测能力。
1.3 YOLOv4
YOLOv4采用CSPDarknet53作为骨干网络,使用CSP(Cross Stage Partial)结构可在保持准确率的同时,轻量化卷积神经网络,减少内存使用,降低计算瓶颈。随后通过空间金字塔池化(Spatial Pyramid Pooling,SPP)[24]扩大网络感受野,使用路径聚合网络(Path Aggregation Network,PANet)[25]进行特征融合,最后使用与YOLOv3相同的分类回归层,同样在3个不同尺度的特征图进行分类检测。
2 YOLOv2-SPP
文中待检测的目标为动车组裙板螺栓以及螺栓丢失区域,此类目标在整张裙板扫描图像中所占比重较小,需着重考虑算法小目标检测的性能。在TEDS系统中,由于线阵相机相对动车组运动方向垂直固定安装,各个相机拍摄的裙板螺栓图像均可近似视为从螺栓正上方拍摄。从提高感受野,改善小目标的角度出发,对YOLOv2进行改进,提出了适应小目标检测的YOLOv2-SPP。
YOLOv2-SPP在YOLOv2第17层卷积层后引入SPP模块,融合多重感受野,提高小目标的检测能力,图5展示了SPP模块结构示意。
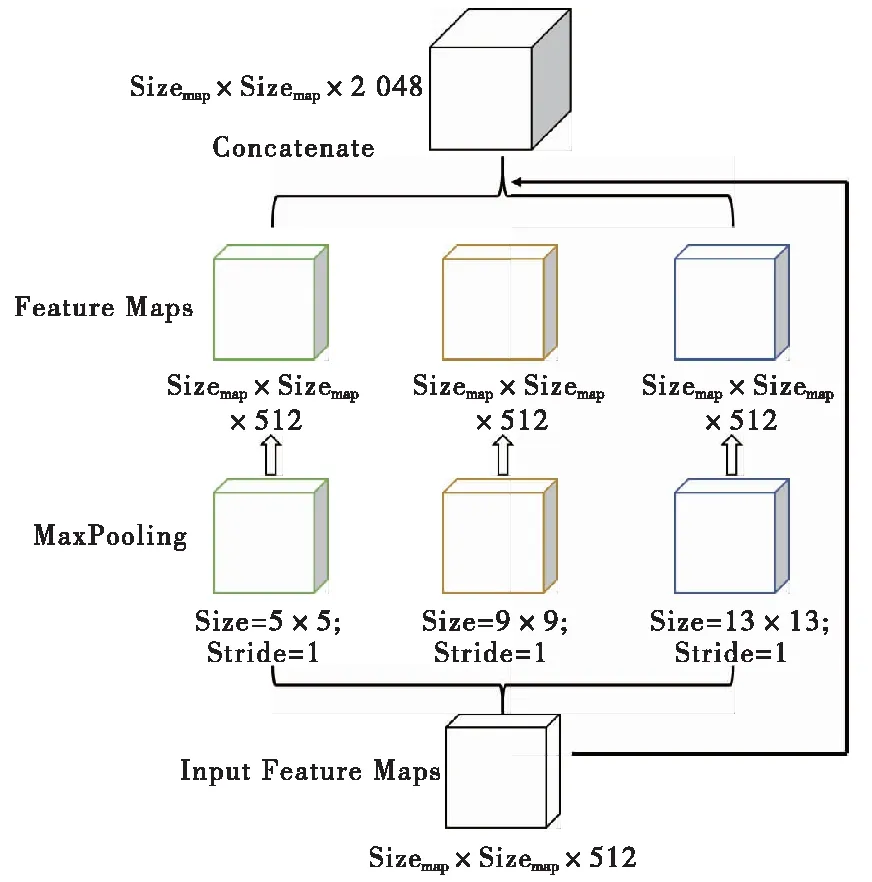
图5 SPP结构示意
YOLOv2第17层卷积层的输出特征图尺寸为13×13×512,引入的SPP模块分别对其进行步长为1,采样核为5×5,9×9以及13×13的最大池化(MaxPooling),将得到的3个池化特征图依次与原输入的特征图进行叠加融合,得到13×13×2048的特征图,最后通过1×1卷积层降维至13×13×512的特征图。图6展示了加入SPP模块的YOLOv2-SPP结构示意。加入SPP模块的YOLOv2-SPP最终输出的检测结果向量为K×(5+C),其中,K为设置的预选框个数;C为待分类的检测目标种类。
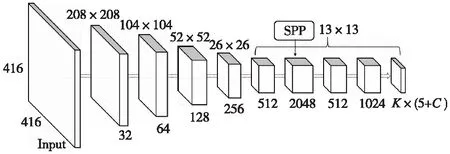
图6 YOLOv2-SPP结构示意
3 实验与分析
3.1 实验条件
表1列出了实验的硬件配置,对应的运行环境为Ubuntu 18.04,CUDA10.2,深度学习框架采用Darknet。

表1 实验硬件配置
3.2 实验数据
实验数据源自TEDS系统捕获的裙板扫描图像,原始图像分辨率为2048×1400,单个待检测的螺栓区域所占像素约为125×125。污渍,磨损,反光,拍摄过程中运动变形及复杂光照环境的影响下,待检测的样本之间存在明显的差异。图7展示了部分待检测螺栓区域样本,图(a)~图(c)为正常状态的螺栓,图(d)~图(f)为螺栓脱落的区域。因此,算法应当具有强大的小目标特征提取能力和抗干扰能力。由于螺栓丢失的缺陷样本相对稀缺,对螺栓丢失图片中的螺栓丢失区域即缺陷样本采取平移、旋转、镜像等数据增强的方法进行扩充,得到正常状态螺栓的训练样本850个,螺栓丢失状态即缺陷样本850个的训练数据集。测试数据集与训练数据集相互独立,采用相同的数据增强方法得到2种样本分别220个的测试集。

图7 待检测螺栓区域样本
3.3 实验与分析
首先,通过K-Means对训练数据集中标注的目标边界框进行聚类,图8展示了3个聚类中心时,训练样本标注框尺寸的归类情况,候选框大小设置为[133,109],[82,72]和[115,84]。

图8 目标框尺寸K-Means聚类分布
本文任务为检测并标识动车组裙板正常螺栓及螺栓丢失区域,即2种检测分类对象。完成候选框设定后,应用YOLOv2、YOLOv2-SPP分别对训练集训练6 000次,批大小设置为64,衰减系数为0.000 5,初始学习率为0.001,随机梯度下降动量为0.9,置信度阈值选取为0.25,表2、表3分别展示了算法改进前后的检测指标。

表2 YOLOv2检测结果

表3 YOLOv2-SPP检测结果
表2、表3中,TP为算法正确识别的正样本数;NP为误识别为正样本的负样本数;FN为误识别为负样本的正样本数。所得精确率P(Precision)和召回率R(Recall)计算公式如下
(4)
(5)
对于待检测的正常螺栓与螺栓丢失区域,改进后的YOLOv2-SPP相比YOLOv2在精确率与查全率均有提升。增加的SPP模块扩大了网络的感受野,提高了小目标的检测能力。为更好地描述多标签图像分类算法的目标检测性能,使用平均精度均值(mean Average Precision,mAP)作为性能指标,每秒处理的图片帧数(Frame Per Second,FPS)作为速度指标。表4对比了YOLOv2、YOLOv2-SPP、YOLOv3、YOLOv4的性能。

表4 算法检测性能对比
改进后的YOLOv2-SPP速度略有下降,但算法平均精度均值相对YOLOv2提升了1.71%,达到95.83%,与YOLOv3,YOLOv4的检测准确度基本一致。得益于更轻量的网络结构,YOLOv2-SPP每秒检测图片的帧数达到了73.6FPS,是YOLOv3的2.3倍,YOLOv4的3倍,更适用于TEDS系统中动车组实时图像检测的任务。
4 结语
针对人工识别动车组关键部位图像效率低下的问题,提出了小目标检测性能更强的改进YOLOv2算法,并将其应用于动车组裙板螺栓检测。在YOLOv2模型中增加SPP模块,扩大了模型网络感受野,提高了小目标检测的准确率。实验结果表明,改进的YOLOv2-SPP算法平均精度均值由94.12%提升至95.83%,相同实验环境下检测速度达到YOLOv3的2.5倍,YOLOv4的3.3倍。提出的YOLOv2-SPP算法满足高准确率,快速检测的要求,更适用于TEDS系统实时检测运行动车组裙板螺栓状态的任务。然而,由于裙板螺栓丢失的缺陷数据集稀缺,该算法投入实际运用之前仍需经过更多真实缺陷数据样本的考验,如何进一步改进算法,提高真实场景下动车组裙板螺栓状态检测的准确率将成为未来研究的方向。
