基于在线评论情感分析和模糊认知图的产品差异性研究
2022-01-22段恒鑫叶晓庆
段恒鑫, 刘 盾,2, 叶晓庆
(1.西南交通大学 经济管理学院 成都 610031; 2.重庆邮电大学 计算智能重庆市重点实验室 重庆 400065)
0 引言
随着互联网技术的飞速发展、在线支付的普及以及物流配送效率的提升,在线购物成为主流趋势,电子商务成交量逐年增加[1]。然而,在电子商务飞速发展的同时,品牌之间的竞争也日益严重,品牌想要冲出重围,需要形成自身特色,并以此来提高品牌的竞争力。为此,大多企业一般采取产品差异化战略,通过突出品牌优势来吸引用户,提高产品竞争力。
产品差异性是用户接受商家品牌与其他竞争者之间的差异程度[2]。以化妆品品牌为例,企业针对不同目标用户,将旗下品牌按照“高端”、“轻奢”、“平价”进行市场细分。例如,世界著名化妆品巨头欧莱雅集团旗下一线品牌有赫莲娜;二线品牌有兰蔻和碧欧泉;三线品牌有巴黎欧莱雅、科颜氏等。从企业角度,分析产品差异性可以帮助企业有效获取用户需求,精准定位目标用户,核定市场细分,为生产安排提供反馈;从用户角度,分析产品差异性可以给用户更多的关于产品横向对比信息,辅助购买决策[3]。
在线评论是获取商品评价的重要渠道,对企业和用户来说都有重要意义。借助互联网平台交互性、个性化、便捷性等特点,越来越多的用户愿意在网络社区或电子商务网站上浏览和发布信息,以达到产品信息交流和购物体验分享的目的。对于用户而言,在线评论反映了产品的真实信息,可以帮助用户进行购买决策;对于企业而言,在线评论中蕴藏着有关产品、服务质量和用户情感态度等丰富的信息,是企业获取用户需求的重要来源。因此,近年来,在线评论逐渐成为商家和电子商务平台关注的焦点[4]。一方面,在线评论直接反映了用户对产品的满意度;另一方面,在线评论间接地反映了用户的主要需求,是实现品牌差异性分析的有效信息。
然而,如果要实现精准的品牌差异性分析,我们不但需要挖掘用户主要关注属性,还要获取用户对不同属性的情感倾向以及属性间的关系。基于此,本文提出了基于在线评论情感分析和模糊认知图的产品差异化分析模型。该模型首先通过机器学习算法与深度学习技术从在线评论中挖掘用户关注的属性,进行情感判断,再通过模糊认知图(fuzzy cognitive map, FCM)获取用户对产品不同属性的情感倾向,以此获得产品差异性分析的综合评价。
1 相关理论
1.1 LDA主题模型
LDA是由Blei等[5]提出的文本主题提取模型,用于直接提取文本中具有语义解释性的主题特征。在LDA中存在一个假设,即用户在编辑评论文本时,在他的意识中会存在一些主题元素,而这些主题中会存在不同的词或句,通过主题-词选择来构成用户产生的在线评论,LDA具体模型如图1所示。其中:k表示提取主题的数;N表示在线评论包含的词数量;wm,n表示第m篇文档的第n个词;tm,n表示第m篇文档第n个主题;φk表示各主题下对应的词概率分布;θm表示各文档下对应的主题分布。假设整体在线评论存在V个非重复词汇,根据上述模型,可计算相应的联合概率分布为

图1 LDA模型
当超参数α、β给定时,可通过吉布斯采样对LDA中参数θm和φk进行估计求解:
通过对参数θm和φk进行求解,可获得各在线评论文本的主题分布和各主题下的词分布,由此来实现基于LDA的在线评论主题提取。
1.2 长短期记忆网络(LSTM)
LSTM是Hochreiter等[6]提出的一种特殊的循环神经网络,主要为了解决长序列训练过程中的梯度消失和梯度爆炸的问题。LSTM通过一个记忆单元与三个门(遗忘门、更新门、输出门)结构来实现对每个单元状态的控制[7],其结构如图2所示。与循环神经网络相比,长短期记忆LSTM有2个传输状态:c1(cell state),h1(hidden state)。循环神经网络中的h1就是LSTM中的c1,这也是LSTM的关键。LSTM利用门的结构来精确控制加入或移除信息到记忆状态。

图2 LSTM结构图
1.3 模糊认知图(FCM)
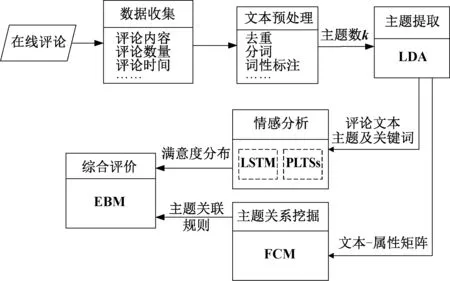
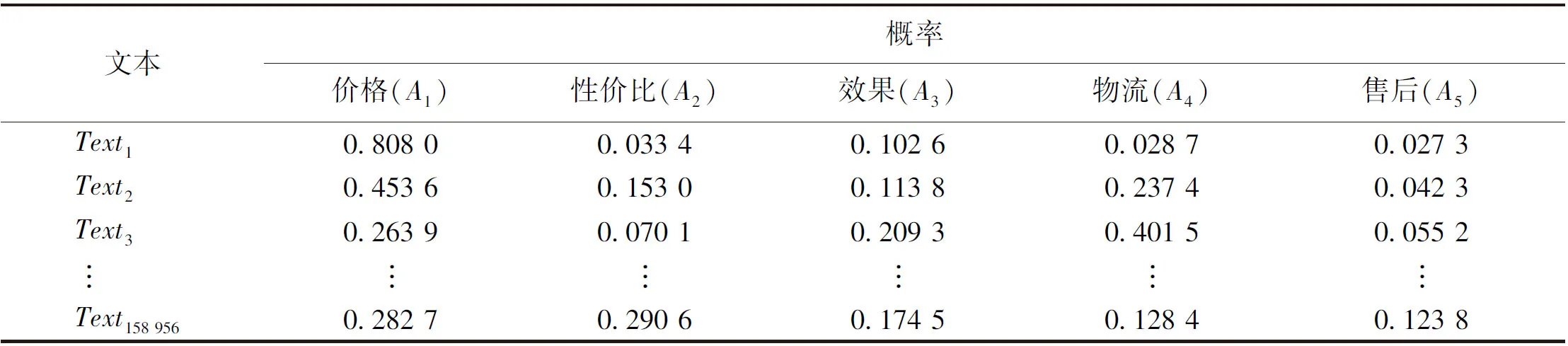
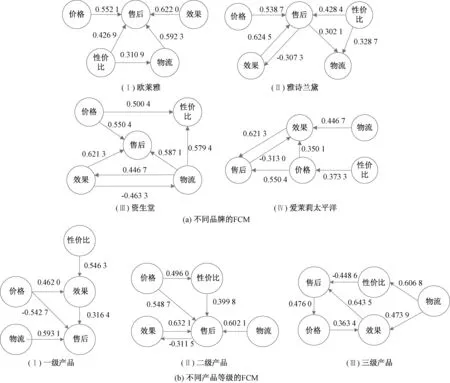
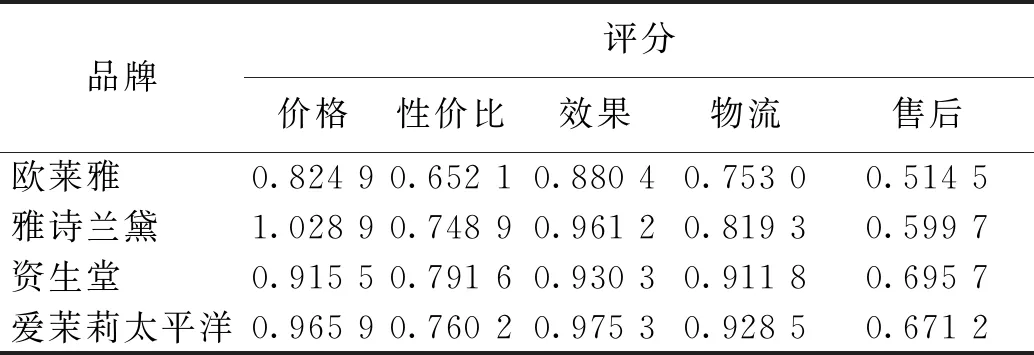
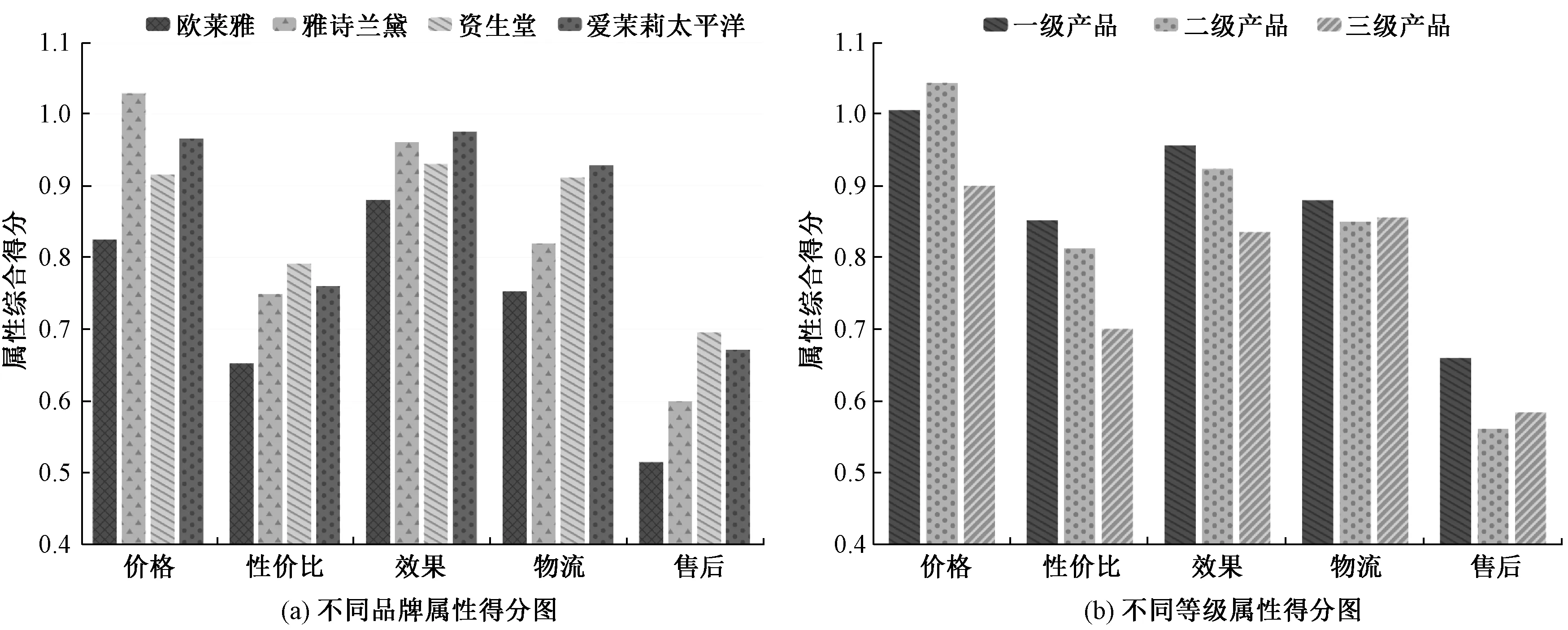
模糊认知图(fuzzy cognitive map, FCM) 是一种利用现有知识和专家经验来模拟复杂系统的方法[8]。模糊认知图利用接近于人类认知的方式描述一个系统,通过强调因果连接和图的结构来表示知识,同时利用规则的形式将专家知识和从数据中获得的有用知识合并在一起[9]。在网络管理[10]、故障分析[11]、专家决策[12]等领域有广泛应用。在模糊认知图中,用有向弧表示概念节点之间的关系,从原因指向结果[13],其主要结构如图3所示。在模糊认知图中,集合Ci(i=1,2,…,n)代表一组有语义的概念节点,其中n代表节点个数。节点间的有向弧表示两者间的因果关系,权重Wij(-1≤Wij≤1)的大小表示原因节点对结果结点的影响程度[14]。当0 图3 FCM结构图 在本小节中,为了挖掘用户对品牌特定属性的情感倾向,探索品牌差异性,我们构建了一种基于情感分析和模糊认知图的在线评论分析模型。该分析模型主要有四个步骤:第一,利用LDA提取用户关注属性;第二,通过LSTM与概念语言术语集挖掘用户对不同属性的情感倾向;第三,构造FCM挖掘属性之间的关系;第四,基于EBM获取综合评价。为了更清楚地描述上述流程,图4给出该模型的基本模型框架图。 图4 基本模型框架图 本文利用LDA模型对评论文本进行主题提取,并根据LDA获取的文本主题分布来确定用户关注属性。首先,将处理后的评论文本输入LDA模型,为每个主题词分配一个属性;其次,遍历所有主题词,根据Gibbs抽样公式对每个单词的属性分布进行重采样和更新,直到结果收敛;最后,合并类似主题并给出相应属性命名,并据此构造每条评论文本在不同属性下的文本-属性矩阵。 为了挖掘用户对品牌特定属性的情感倾向,本文采用LSTM对每个评论文本的情感进行分析,并对文本信息进行量化。通过情感分析,每个评论文本都有一个介于0到1之间的情感得分,1表示最积极的情感,0表示最消极的情感。因此,每一个分数代表了评论文本的情感程度,可利用情感得分评估用户对不同品牌的满意度。为了更清晰地衡量用户的情感态度,本文利用PLTSs来评估用户对不同属性的情感。在PLTSs的框架下,可以将满意度分为5个等级:(1, 0.8);(0.8, 0.6);(0.6, 0.4);(0.4, 0.2);(0.2, 0)[16],它们分别对应了“非常满意”、“满意”、“一般”、“不满意”、“非常不满意”5种语言术语集。据此,本文将情感得分按照5个等级进行划分,相应的情感分析过程可分为以下4个步骤。 步骤1 对每条评论文本进行预处理,并得到属性及主题词; 步骤2 用训练集数据训练LSTM模型,并利用训练好的模型计算每条评论的得分; 步骤3 利用PLTSs将情感得分划分到5个等级中; 步骤4 将5个情感水平百分比标准化为满意度。 为了进一步挖掘属性之间的关系,我们进一步通过模糊关联规则进行属性关系挖掘,建立描述属性相互关系的FCM模型。其中,用Aj→Al表示属性Aj和Al(j≠l)之间的模糊关联规则,M为评论数量,vij和vil分别表示文本Texti(i=1,2,…,M)对属性Aj和Al的影响,其值分别等于文本Texti属于Aj、Al的概率。根据文献[17],可以计算Aj→Al的支持度、置信度和提升度分别为 (1) (2) lift(Aj→Al)=conf(Aj→Al)/supp(Al), (3) 其中:supp(Aj→Al)为支持度,用于描述属性Aj和Al同时出现的可能性;conf(Aj→Al)为置信度,它刻画了Aj对Al的影响;lift(Aj→Al)为支持度,它可以衡量模糊关联规则的极性。 在构建基于关联规则的FCM模型时,需要设立一个最小支持度与最小置信度,用于删除支持度小于最小支持度、置信度小于最小置信度的关联规则。在其余的关联规则中,选择置信度作为关联规则的绝对权重,用提升度确定权重的极性。对于每个关联规则Aj→Al,如果lift(Aj→Al)=1,则Aj与Al相互独立;如果lift(Aj→Al)>1,则Aj与Al正相关;如果lift(Aj→Al)<1,则Aj与Al负相关;在本文中,最小置信度设为0.25,最小支持度为0.30。基于上述分析,可以构造相应的模糊认知图,具体分为3个步骤。 步骤1 根据公式(1)~(3),计算supp(Aj→Al)、conf(Aj→Al)与lift(Aj→Al); 步骤2 删除支持度小于最小支持度的规则,删除置信度小于最小置信度的规则; 步骤3 根据lift(Aj→Al)计算出该关联规则的权重。 Itj=B·Ptj. (4) 在FCM中,中心度被用来描述确定属性重要性的度量,它可以利用属性的索引值Indegree(Aj)和出度值Outdegree(Aj)计算权重信息。这里,属性的度中心性定义为 Degreecentrality(Aj)=Outdegree(Aj)+Indegree(Aj), (5) 其中:索引值等于指向该属性的所有关联规则的权重之和;出度值等于从该属性中指出的所有关联规则的权重之和。如果一个属性具有更高的度中心性,那么它在FCM图中应该扮演更重要的角色。据此,我们可以进一步规范化属性Aj的度中心性,并计算中心度的权重为 (6) 作为聚合算子的典型代表之一,BM算子(bonferroni mean operator)不仅可以计算每种属性的重要性,而且能够有效地捕获属性间的内在联系,因而常常被应用到多属性群决策问题中。然而,虽然BM算子考虑了属性之间的相互作用,但这种交互是非定向的。对于FCM而言,每个关联规则表示属性之间的因果关系。基于上述分析,对于一个特定的品牌,我们使用了改进的EBM算子来测量满意度得分。 对于第t个品牌,基于EBM的计算结果,分别使用乘法属性计算每个属性Aj的满意度得分, (7) (8) 为了验证所提出方法的有效性,选取京东商城化妆品真实数据进行验证,爬取了2016年6月至2020年6月京东商城中欧莱雅、雅诗兰黛、资生堂和爱茉莉太平洋4个化妆品品牌的在线评论数据。经过数据清洗后有效评论为156 956条,其中包含111 365条正向评论和47 591条负向评论。平均每条评论长度为154字,经过Jieba分词后平均分词数为54个。文本情感极性标签分别用1和0表示,1代表正向评论,0代表负向评论。所有有效评论数据集包含4个大品牌,每个大品牌下均有一级、二级、三级产品。如雅诗兰黛旗下一级产品有海蓝之谜;二级产品有雅诗兰黛、悦木之源;三级产品有朗仕等,其数据分布如表1所示。 表1 4个品牌评论数据分布表 3.2.1属性挖掘 根据图4的提出的框架模型,利用LDA对在线评论进行主题提取,可以得到价格(A1)、性价比(A2)、效果(A3)、物流(A4)、售后(A5)5个属性,每一个属性及其对应的主要关键词如表2所示。如在“价格”主题下,有“划算”、“便宜”、“优惠”等关键词;售后主题下则有“客户”、“保障”、“服务态度”等关键词。 表2 评论主题与核心关键词表 根据表2提取的5个主题,分别计算每条在线评论对5个属性的概率分布,得到的文本-属性概率矩阵结果如表3所示。以Text2为例,它对A1、A4的概率值分别为0.453 6、0.237 4,这说明第2条在线评论对应“性价比”概率为0.453 6,对应“物流”关键词的概率为0.237 4。 根据表3,可以分别计算文本-属性概率矩阵中每一行的最大值,其代表该文本的主属性,如:Text1的主属性为“价格”;Text2的主属性为“价格”;Text3的主属性为“物流”等。此外,可以据此简单统计各属性下评论的主属性分布情况,其中涉及价格属性33 129条、性价比属性55 513条、效果属性8 598条、物流属性7 965条、售后属性53 751条。显而易见地,在所有评论中,“性价比”和“售后”两条主属性的评论数量均超过5万条,这说明所有评论对“性价比”和“售后”两个属性最为关注。然后,根据LSTM计算每条文本的情感分布,也可以计算每一条文本的情感得分情况,如:Text1的情感得分为0.808 0;Text2的主属性情感得分为0.033 4;Text3的情感得分为0.102 6等。可以看到,每一条文本的输出概率在0和1之间,其数字大小含义为:如果该条评论得分越高,就越接近正向评论;得分越低,则越接近负向评论。进一步地,通过LDA和LSTM计算的结果并结合 PLTSs,可以计算各个属性的总体满意度比例,如表4所示。 表3 文本-属性概率矩阵 表4 属性的总体满意度比例表 3.2.2属性关系分析 根据表3和公式(1)~(3),可计算相应的置信度和提升度矩阵,计算结果如表5和表6所示。根据表5~6可以绘制总体FCM。在图5中,箭头代表两属性的关联。在总体模糊认知图中,其他几个属性均与属性“售后”有关联,由此可见,该属性在分析在线评论中具有很重要的意义。根据公式(4)~(7),可以分别计算不同品牌和不同产品等级的属性综合评分,如表7所示。 表5 总体置信度矩阵 表6 总体提升度矩阵 图5 总体FCM 最后,根据品牌和产品等级数据,通过公式(1)~(3)分别构建相应的FCM,结果如图6所示。一方面,通过图6(a)可以发现,不同品牌间属性关系存在差异。如品牌“欧莱雅”的“价格”、“性价比”和“物流”属性对“售后”属性有正向关系;品牌“雅诗兰黛”的“价格”、“性价比”、“效果”属性对“售后”属性有正向关系,“售后”对“物流”有正向关系,“售后”对“效果”有负向关系;另一方面,由图6(b)可以得到,不同产品等级间属性关系差异较大,一级产品的属性“物流”、“效果”与“售后”存在正向关系,而“价格”与“售后”存在负向关系,一级产品价格较高,用户在购买时更看重产品质量与效果。 图6 不同品牌和不同产品等级FCM 3.2.3综合评价 根据表7~8和公式(8),可以得到不同品牌和不同产品等级的最终加权满意度得分,其品牌得分排序情况:欧莱雅(0.903 1)<雅诗兰黛(0.919 5)<资生堂(0.952 6)<爱茉莉太平洋(1.021 8);从等级角度,则有一级产品(1.010 7)>二级产品(0.952 1)>三级产品(0.852 1)。为了更加方便地对其进行比较,我们将不同品牌属性和不同产品等级得分进行汇总,结果如图7所示。 表7 不同品牌的属性评分表 由图7(a),从品牌角度,在综合满意度最高的爱茉莉太平洋中,“性价比”、“售后”是其应该关注的属性。根据其模糊认知图,可以发现,“效果”、“价格”与“售后”呈明显正相关,品牌方应多关注这两个属性;在资生堂中,“效果”、“价格”则需要引起高度关注;在雅诗兰黛中,“价格”是其主要优势,需要在“物流”、“售后”方面投入更多精力;在欧莱雅中,各项属性均落后于其他三个品牌。由图7(b)从用户角度,三个产品的等级呈现出了明显的大小关系。一级产品在除“价格”以外的几个属性上均优于其他两种产品;二级产品则在“售后”属性上落后于三级产品。 表8 不同产品等级的属性评分表 图7 不同品牌和不同等级属性得分图 基于上述分析,从品牌等级角度来看,一级产品的各项指标远远高于二级和三级产品,验证了“差异化”营销的有效性。同时,在所有属性中,“售后”属性表现最差,这说明所有品牌都需要对这一指标采取措施用以提升顾客满意度。 为了进一步验证本文所用LSTM算法的有效性,我们选取情感分析常用的支持向量机(SVM),朴素贝叶斯(Naive Bayesian)、卷积神经网(CNN)、极限梯度提升算法(XGBoost)作为基准算法。这里,我们采用精度(Precision)、召回率(Recall)和F1值三个指标作为评价标准来衡量不同算法在情感分析过程中的表现情况,算法所用公式为 Precision=TP/(TP+FP); (9) Recall=TP/(TP+FN); (10) F1=2precision·recall/(precision+recall)。 (11) 结果汇总如表9所示。无论是在Precision、Recall还是F1值的表现上,LSTM相较其他算法都取得了较好的预测效果,这也间接说明本文利用LSTM进行情感分析是合理和有效的。 表9 算法结果汇总表 为了帮助企业发现市场的差异化需求,对某产品或服务进行有效创新和改进,本研究以化妆品市场为例,针对差异性产品,分别从品牌和用户两个维度,挖掘产品差异化特征,分析用户满意度,对差异化产品的竞争性进行探讨,并提出相应的改进建议。首先,利用LDA挖掘用户所关心的产品特征;其次,利用长短期记忆和概率语言术语集更准确地测度了用户对不同产品特征的情感;然后,利用模糊认知图和关联规则进一步研究了各产品特征之间的相互关系,构建了特征之间的关系图;最后,通过EBM算子对决策信息进行聚合,得到最终综合评价。总而言之,本文所提出的模型和方法能够将在线评论的非结构化数据转化为定量信息,获得产品特征的满意度评价,并在主题提取、情感分析、以及综合评价方面取得了一定的效果。在未来研究中,一方面可以将数据的时序性引入到研究中,根据时间动态变化来探索动态的用户满意度变化,并分析产品差异性变化趋势;另一方面,考虑到模糊认知图只是衡量属性关系的一种形式,后续还可以探讨其他模型来实现相关任务。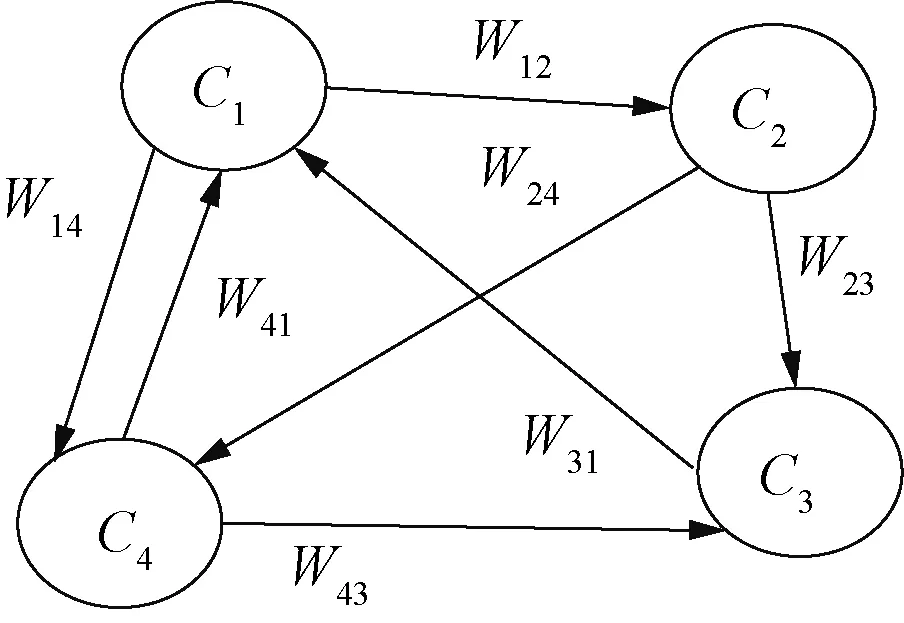
2 基于在线评论情感分析和模糊认知图的分析模型
2.1 挖掘用户关注属性
2.2 属性情感分析
2.3 属性关系挖掘
2.4 总体评价
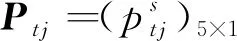

3 实验结果与分析
3.1 实验数据

3.2 实验结果分析






3.3 情感分析结果对比

4 结论与展望
