基于深度学习网络的星表非结构化岩石目标辨识方法研究
2022-01-21毛晓艳谢心如胡海东
黄 璐,毛晓艳,杜 航,谢心如,胡海东
北京控制工程研究所,北京 100094
0 引 言
作为计算机视觉领域的重要研究方向,目标检测技术广泛应用于视频监控、虚拟现实、人机交互、行星探测和行为理解等领域[1].然而,在实际应用场景中,目标检测与跟踪系统面对的情况往往复杂多变,如背景复杂、目标遮挡及目标尺度和外观变化等,上述情况直接或间接影响目标检测的精度和鲁棒性.
地外行星表面环境复杂未知,具有形貌原始自然、纹理相似度高、巡视搜索跟踪区域广等特点,属于典型的复杂场景;同时,地外星表包括凸起石块、岩石等对象,探测任务需要获取星表的地形信息.地外星表的安全高效通行、目标探测等任务,需要探测器具备对未知目标的快速精准识别的能力.
因此针对地外环境中面临的行星地表地形目标尺度多等瓶颈问题,研究地外复杂非结构化岩石目标的快速精准检测与识别方法,实现地外行星表面复杂场景下小对象快速精准的检测识别.目前,人工智能在地外星表上的探测应用在我国尚缺乏相关研究,因此有必要开展行星表面目标辨识方法研究,结合人工智能领域的研究成果,研究行星表面石块目标识别方法.
针对地外天体复杂场景下形状多样等特点,面向岩石等典型地表目标,构建标注目标区域与属性的检测与识别样本集,分析非结构化石块目标对象,设计面向目标分类方法,提出多尺度目标的快速精确检测识别方法,突破目标自主检测与识别等技术,实现多尺度多目标的快速检测与精准识别.
目前的目标识别算法一般分为传统目标识别算法和深度学习目标识别算法.传统目标识别算法一般由预处理、特征提取和分类识别[2]3个步骤组成.图像的特征提取一般从颜色、梯度和纹理等计算.目前模式识别上最常用且有效的特征有:Haar特征[3]、SIFT特征、LBP特征和HOG特征[4]等.
深度学习目标识别算法在计算机视觉中常用的分类器主要有罗杰斯特回归(logistic regression)、Softmax分类器、朴素贝叶斯分类器(naive bayes)、决策树(decision trees)、KNN分类器(k-nearest neighbor)和支持向量机(SVM)[5]等.深度学习的2个方向包括以RCNN[6]为代表的基于区域生成的深度学习目标检测算法(RCNN、SPP-NET、fast-RCNN[7]和faster-RCNN[8]等),需要先使用CNN网络产生区域生成,然后再在区域上做分类与回归.还有以YOLO为代表的基于回归方法的深度学习目标检测算法(SSD[9]和YOLO[10]等),其仅用一个CNN网络就可以直接预测目标的位置和类别.深度学习的目标检测算法如SSD、RCNN等网络复杂度很高,速度慢,而YOLO系列方法在满足实时性要求的同时,解决了网络复杂度高的问题.
基于上述分析,本文主要面向复杂条件下的目标检测,提出了一种新的地外环境下非结构化目标智能辨识方法,通过优化深度学习的YOLO方法,采用正负样本标注训练,改进神经网络模型结构,采用马赛克数据增强和非极大值抑制参数调节的方式,实现对地外非结构化地形中的小目标的智能化识别与检测,进一步增强了小目标特征提取和快速识别能力,将其应用于地外天体地形的小目标识别检测问题.
1 YOLOv5神经网络模型
YOLO目标检测算法是Redmon等[10]在2016年提出的一种新的端到端的目标检测算法.与Fast R-CNN、Faster R-CNN等使用区域网络预测目标可能位置的算法不同,YOLO直接通过一次回归得到所有的目标可能位置.算法的时间效率大大提高,获得了一种实时性较好的目标检测方法.经过近几年的创新与发展进步,REDMON等[11-12]在YOLO的基础上又提出了YOLO9000、YOLOv3和YOLOv4等目标检测算法,在保持高精度的同时,速度也比其他算法高出好几倍.YOLOv5能实现快速检测,其中YOLOv5s网络是YOLOv5系列中深度最小,特征图的宽度最小的网络.后面的3种YOLOv5模型m、l、x都是在此基础上不断加深加宽,AP精度也不断提升,但速度的消耗也不断增加.
Yolov5的网络结构如图1所示,分为输入端、Backbone、Neck和Head 4个部分[12].其中Backbone为在不同图像细粒度上聚合并形成图像特征的卷积神经网络;Neck为一系列混合和组合图像特征的网络层,并将图像特征传递到预测层;Head为对图像特征进行预测,生成边界框和并预测类别.
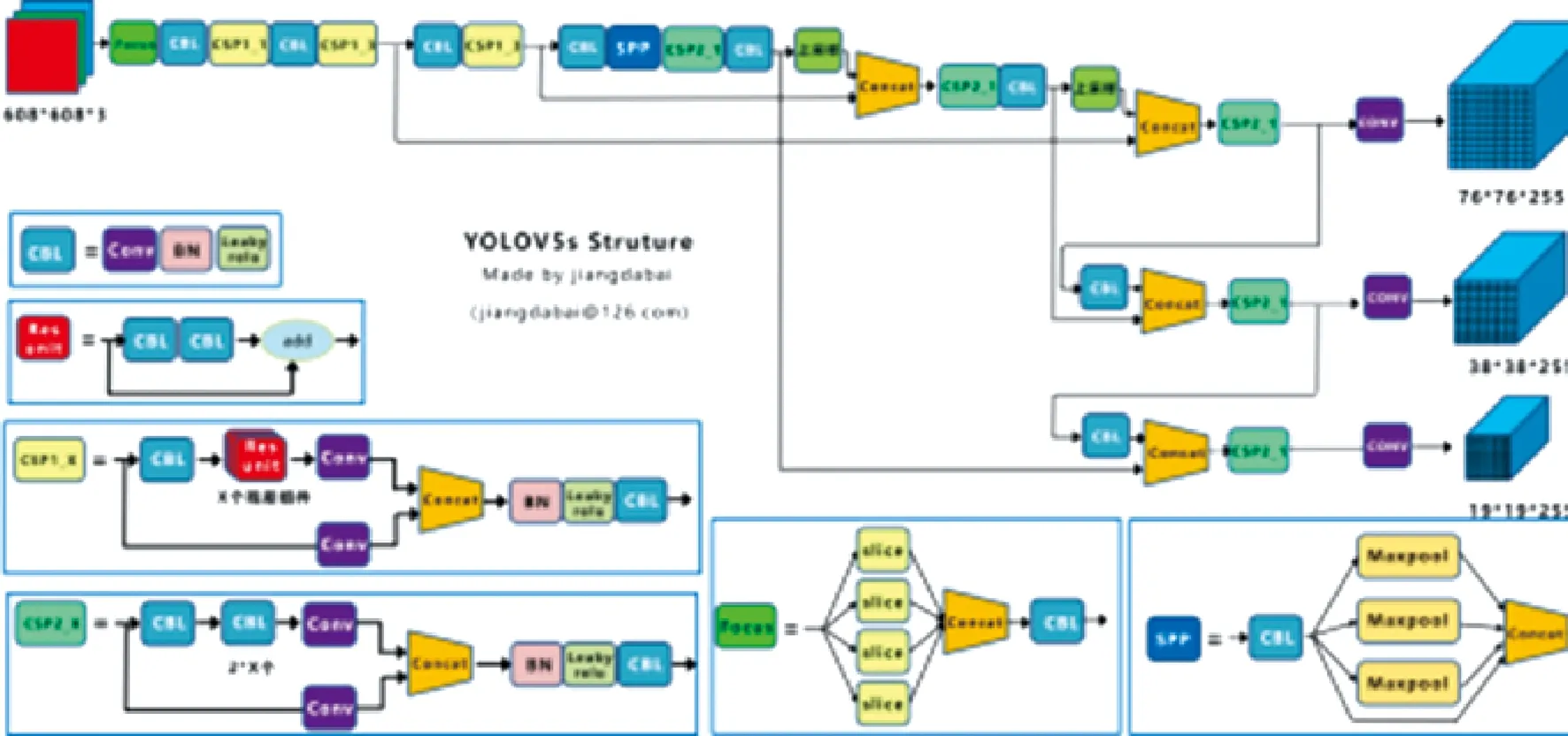
图1 YOLOv5网络结构Fig.1 Yolov5 network structure
输入端包括马赛克数据增强、自适应锚框计算和自适应图片缩放.马赛克数据增强的作用是丰富数据集,基本原理是对图片进行随机缩放,再随机分布进行拼接,大大丰富了检测数据集,特别是随机缩放增加了许多小目标,加强了对小目标的提取能力,让网络的鲁棒性更好.同时可以减少资源占用,一个GPU可以同时计算4张图片.在自适应锚框计算中,YOLO算法会针对输入的数据集类型选择不同的锚框,基于锚框输出预测框.而YOLOv5每次训练时自适应的计算不同训练集中的最佳锚框值,自动匹配最佳锚框.在自适应图片缩放中,进行自适应缩放填充,提升了推理速度.
Backbone的作用是进行特征提取,整体结构包括Focus、CSP结构和SPP结构.其中,Focus结构的作用是减少计算量、加快速度.该模块在图片进入backbone前对图片进行切片操作,在一张图片中每隔一个像素取一个值,最终获得4张图片互补,这样就将宽度和高度的信息集中到通道空间,即拼接起来的图片相对于原先的RGB 3通道扩充为12个通道,进行有效特征融合,最后将新生成的图片经过卷积操作,得到没有信息丢失的2倍下采样特征图,结构如图2所示,其中CBL结构由卷积层、归一化和激活函数组成.SPP结构主要进行了空间金字塔池化,把输入的特征地图划分为多个尺度,对每个小拼图进行最大池化,生成数字,把所有数字拼接起来成为一维向量,输入SPP层获取分类.

图2 Focus结构图Fig.2 Focus structure diagram
Neck结构如图3所示,其作用是一系列混合和组合图像特征的网络层,并将图像特征传递到预测层[13].FPN网络解决目标检测中的多尺度问题,通过不同层的连接实现,不增加原有模型计算量,大幅提升小物体检测的性能,通过高层特征进行上采样和底层特征进行自顶向下的连接.自底向上的PAN网络用来融合多级特征,作用目的和FPN网络类似.

图3 Neck结构框架图Fig.3 Frame diagram of Neck structure
Head作用是对最终输入特征进行预测输出,进行IOU和非极大值抑制NMS,输出包围框.调整非最大值抑制阈值参数对比性能,选择最优阈值,优化检测效果.
(1)
每次优化更新时对每个样本进行梯度更新,对于很大的数据集来说,可能会有相似的样本,在计算梯度时会出现冗余[14],而SGD每次只进行一次更新,没有冗余且速度比较快,并且可以新增样本.Adam(adaptive moment estimation是一种自适应学习率的方法,利用梯度的一阶矩估计和二阶矩估计动态调整每个参数的学习率)集成了SGD的一阶动量和RMSProp的二阶动量.但是Adam可能不收敛和错过全局最优解.YOLOv5默认优化函数Adam,Adam的学习率通常比SGD低.但是对于小样本、小目标检测的数据集,考虑使用SGD优化,提高算法效果.因此根据数据集比较选择SGD优化模型.
2 基于改进YOLOv5的星表非结构化岩石目标辨识方法
在当前各类目标检测任务中YOLOv5已取得了非常优越的效果,但算法仍需改进,特别是在样本准备、识别精度和处理速度方面.在实际的星表非结构化地形小目标数据中,使用YOLOv5直接训练数据,最终得到的模型有很好的召回率,但准确率不高,存在误检测和检测框重复的问题.为了获得目标的实时检测精度和虚警率都比较好的算法模型,以YOLOv5s为基础网络模型,结合背景添加空标签作为负样本、改进网络优化方式和非极大抑制参数调节来提升深度网络的准确率和速度.
1)由于有效图像数量较少,对Yolov5进行在线数据增强,也就是对每个Epoch中的数据,都经过数据增强后提高泛化能力.通过数据加载器传递每一批训练数据,并同时增强训练数据.数据加载器进行3种数据增强:缩放、色彩空间调整和马赛克增强.马赛克数据增强确实能有效解决模型训练中的“小对象问题”,即小对象不如大对象那样准确地被检测到.
由于训练过程中发现有误检测现象出现,通常是背景环境较暗,被误检测为石块.分析原因可能是YOLO只有正样本进行标注训练,网络没有充分学习哪些是非石块目标,因此考虑增加负样本,把容易被误检测的背景在标注时作为空标签,将正样本和负样本同时作为数据集进行网络模型训练.使用空标签会带来一些泛化,那么可以使用大量的实际场景背景做空标签,使用空标签训练作为小样本数据增强.增强后数据规模扩充了1.5倍,主要增加了负样本和更有效的正样本数量进行神经网络的训练.
2)最终模型的性能与模型优化算法的选择有关.有时效果不好可能是优化算法的问题.YOLOv5默认优化函数Adam,并预设了与之匹配的训练超参数.Adam的学习率通常比SGD低.但是对于小样本、小目标检测的数据集,可能对于YOLOv5网络模型来说SGD效果比Adam好.因此考虑使用SGD优化,提高算法效果.
3)在实验验证阶段发现,有检测框重复检测的现象存在,因此分析认为非极大值抑制模块效果不好,考虑调整参数对比性能,选择最优阈值,优化检测效果.
3 实验仿真结果及分析
3.1 数据收集与处理
实验使用kinectv2相机在1 m左右的高度拍摄了17 597张地外试验场的模拟火星地形图像,包括6 745张RGB图像,大小为1 920×1 080的PNG图片,具体拍摄了有岩石和石块的地形场景.与原来的Kinect类似,该传感器能够以高速率(30帧/s)获取准确的深度图像.与Kinect采用结构化光技术相比,Kinect v2基于飞行时间测量原理,因此也可以在室外阳光下使用(效果受限).
数据集中的场景包含为岩石、沙丘和沙地,背景环境较为复杂,如图4所示.数据集图像中目标有大有小,形态各异,使用LabelImg进行图像目标的标注,设定类别为石块,标签标为stone,存为txt和xml文件.

图4 采集的部分地形图像Fig.4 Collected partial terrain images
对石块进行标注来制作数据集,为提升目标检测泛化性,对受遮挡的石块目标也进行标注,希望最终模型能识别遮挡目标.
由于背景环境较暗,容易被误检测为石块.YOLO网络只有正样本进行标注训练,网络没有充分学习哪些是非石块目标,因此考虑增加负样本,把容易被误检测的背景在标注时作为空标签,将正样本和负样本同时作为数据集进行网络模型训练.使用空标签会带来一些泛化,那么可以使用大量的实际场景背景做空标签,使用空标签训练作为小样本数据增强.使用LabelImg将背景(颜色较暗,与石块颜色纹理较相似)标注为空标签类txt文件,作为负样本;石块为正样本,stone类别.
3.2 模型训练
实验平台使用ubuntu 18.04系统,CPU i7,GPU为GeForce GTX TITAN X,16G内存,python3.8和pytorch 1.7.1环境.训练模型使用已在大数据集训练好的预训练模型权重文件,在自制数据集上继续训练模型.以YOLO原作者在COCO上训练好的YOLOv5s模型为基础模型,对地外试验场采集的6 745张图像进行预处理之后选取自采集的数据集中的RGB图像进行训练和测试.在测试过程中,初始NMS阈值为0.6.对YOLOv5的原始网络和改进后的网络进行了训练和测试.
3.3 实验结果分析
以召回率(recall)和准确率(precision)作为模型的评价标准.准确率是真实目标占网络预测目标总数的比例,表示该网络的分类准确率.召回率是网络成功预测的真目标数与实际真目标数的比值.目标的交集/并集比IOU(intersection over union,如式(1)所示)大于0.5作为真目标,IOU为预测目标包围框和真值矩形重叠区域面积占二者并集面积的比值.
(2)

(3)

(4)
式(2)~(4)中,tp(true positives)为网络预测真目标数,fn(false negatives)为未能成功预测真目标数,n为预测总数.用测试集验证训练好的模型,分析准确率、召回率和mAP等曲线.YOLOv5原网络和改进网络的P-R曲线对比如图5所示,准确率提高至81.84%,召回率提高至79.04%.

图5 原网络和改进网络准确率和召回率曲线对比Fig.5 Comparison of accuracy and recall curves between original network and improved network
目标检测中衡量识别精度的指标是mAP.多个类别物体检测中,每一个类别都可以根据R和P绘制一条曲线,AP是计算某一类P-R曲线下的面积,mAP则是计算所有类别P-R曲线下面积的平均值(由于本实验只检测一类目标,因此mAP与AP相等).YOLOv5原网络和改进网络的mAP曲线对比如图6所示,发现mAP值有明显提升,达到了86.17%.FPS是指画面每秒传输帧数,即1 s能进行检测的图片数量.FPS也是测量用于保存、显示动态视频的信息数量.通过在检测一定数量的测试图之前和之后使用计时函数time(),计算得到时间差Δt,再与这之间进行识别测试的图片数量相除,即得到FPS(帧/s).在运行Tesla P100的YOLOv5 Colab笔记本中,每个图像的推理时间快至0.007 s,意味着也达到了140 FPS.

图6 原网络和改进网络mAP曲线对比Fig.6 Comparison of mAP curves between original network and improved network
与其他方法对比,由表1可知,基于改进YOLOv5的星表非结构化岩石目标辨识方法在提高了AP精度的基础上,还达到了140FPS,快速又准确地识别出了目标石块.

表1 算法性能对比Tab.1 Algorithm performance comparison
测试图像中网络模型的检测效果如图7所示.可以看出,在地形图像中可以检测到岩石和石头目标,部分遮挡的目标也能识别出来.最明显的效果是去除了重复检测框,漏识别的石块也在改进的网络中识别了出来,同时检测框的锚点也更加准确.由图5可知改进网络在两项主要指标上都比原网络更好,由于引入了易误识别的背景负样本,增强了优化部分对分类结果的影响,抑制了置信度低的检测框,增强网络的识别能力,提升了网络的召回率和准确率.

图7 原网络和改进网络识别检测效果对比Fig.7 Comparison of identification and detection effects between original network and improved network
使用该改进网络模型对NASA毅力号火星车采集的火星地表图像进行训练和测试后,目标石块检测效果如图8所示。

图8 对毅力号采集的火星图像进行目标检测的效果Fig.8 Effect of target detection using Mars images collected by perseverance
在该运行环境下,70 轮迭代后的 YOLOv5网络计算耗时0.051 h,改进后的YOLOv5网络计算耗时0.057 h,SGD模型优化的额外计算时间比较少,优化效果较明显.
4 结 论
本文利用当前研究热点的深度学习目标探测算法,以YOLOv5网络为基础,学习了传统机器学习训练分类器的思路,将容易被误识别的背景部分作为负样本进行标注引入到了YOLOv5的网络中,能够有效改进小样本识别检测的问题,得到保持了实时性,而且更高召回率和精度的优化网络[15].对实际采集的复杂行星地表非结构化岩石目标图像进行试验,实验结果表明,该网络能够有效地检测复杂行星地形下的小目标.在自制数据集上证实了该方法的准确性和有效性,为未来深空探测任务中探测车识别地表目标障碍物奠定人工智能方法基础.
