高职学生就业因素分析与就业预测模型构建
2022-01-21熊露露王方士
熊露露,王方士
(1.新疆铁道职业技术学院,乌鲁木齐 830011;2.浩蓝环保股份有限公司,广州 200010)
0 引言
2019年国务院印发的《国家职业教育改革实施方案》中指出要把职业教育摆在教育改革创新和经济社会发展中更加突出的位置。据中国青年报统计,2020年高职毕业生已达到385万人,毕业生人数的快速增加,使高职毕业生就业形势严峻,越来越多的高职毕业生面临着一毕业就失业的危机,这与国家大力发展职业教育的初衷并不相符。如何提高高职学生的就业率是十分迫切和重要的工作,通过挖掘影响高职学生就业的因素,学校可以据此优化就业指导方案,修订人才培养方案;学生可以利用就业预测模型,对能否顺利就业进行预测,针对就业的需要进行积极的准备,从而提高高职院校学生的就业率。本研究以异构数据源为研究对象,利用决策树算法,不但可以建立切实可行的高职学生就业状况预测模型,还能够分析得到影响高职学校毕业生就业的关键因素。
1 相关研究
近年来,国外内有很多学者对影响学生就业因素和就业预测模型进行了研究。程昌品等人[1]采用信息增益比的决策树算法对毕业生就业进行了预测,唐燕等人[2]利用C4.5决策树算法和随机森林算法对医药院校毕业生建立了就业预测模型,李琦[3]运用基于HMIGW和XGBoost的毕业生就业预测算法,为毕业生的就业预测提供了很大的帮助。对高校利用数据挖掘进行就业指导分析发现:数据挖掘技术在高校就业工作的指导作用已经引起了越来越多的关注,然而大多数已有研究存在数据样本量较低、样本分布不均衡、对高职毕业生就业预测研究较少等问题。因此本研究采用决策树算法建立高职毕业生就业预测模型,以期为高职院校的招生、学生培养和毕业生就业提供决策依据,提高高职学生就业率。
基于数据挖掘算法的异构数据源知识发现遵循科学领域逻辑框架内的知识发现研究[4],在知识处理流程中关注数据规范,其中机器学习等方法是实现高效领域知识发现的一条必经之路。
2 数据预处理
2.1 数据来源
本研究以某高职院校的毕业生就业数据和成绩数据为研究对象。从学校招生就业系统中提取2016—2020年毕业生就业数据4078条记录,从教务管理系统中提取相应毕业生3年6学期成绩数据24468条记录。毕业生就业数据包含姓名、身份证号、学号、性别、民族、民族代码、专业代码、政治面貌、院系、班级、所属校区、专业、就业情况、毕业时间等26个属性列,每个毕业生每学期成绩数据包含学号、姓名、科目等10个属性列。
2.2 数据清洗
2.2.1 就业数据
本研究选择了就业数据中对预测模型影响较大的学生就业的属性信息,故用人工抽取的方式保留了主要属性列,去除不必要属性列,经过提取最终保留7列属性。
2.2.2 成绩数据
每个毕业生包括了6学期的成绩,将每个学生的所有成绩计算了平均值,这样成绩数据从原来的24468条减少到了4078条。最终成绩数据包含学号,平均成绩两列属性。
2.2.3 数据集成
将经过处理后的就业数据和成绩数据,通过“学号”进行关联合并,合并后的数据集作为样本数据,以学号作为关键字段,每个样本数据包含8个属性列(性别、民族、政治面貌、专业、所属校区、毕业时间、平均成绩、就业情况)。
2.2.4 文本数据数值化
为了便于数据挖掘模型的建立,本研究将定性数据均改为数值型数据[5],例如,性别属性列中,设“男”为2,“女”为1;就业情况属性列中,设“能就业”为1,“不能就业”为-1等。
2.2.5 数据归一化
运用最大-最小规范化,使属性列的数据取值范围为[0,1]。
经过上述步骤,数据呈现可处理状态,最终得到4078条数据。如表1所示。
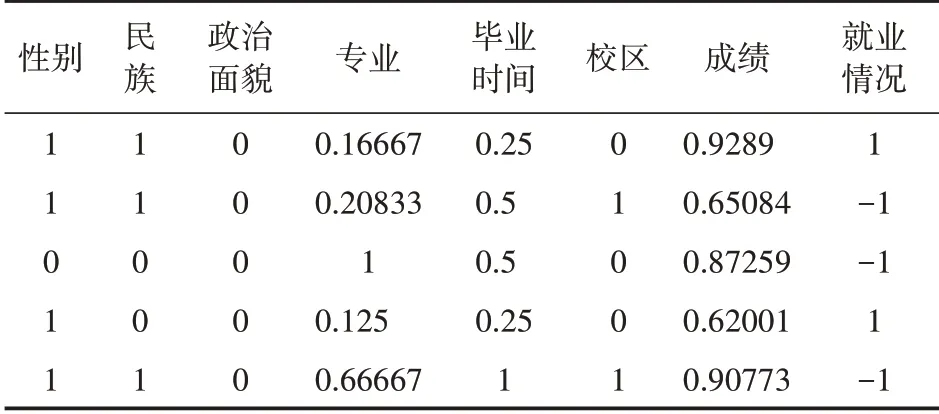
表1 处理后的研究数据(部分)
3 高职学生就业预测模型构建
经过数据预处理后,为了降低预测模型的泛化误差,先将数据样本按照7∶3的比例分为训练集数据和测试集数据,训练集数据2852条,测试集数据1226条;再对训练集数据采用10折交叉验证的方法来训练模型,具体操作是将训练集数据等分为10个互斥子集,每次选择其中的9∕10作为训练集,剩下的1∕10作为验证集,此操作重复10次,将10次测试结果的均值作为模型的预测结果。将“性别”、“民族”、“政治面貌”、“专业”、“所属校区”、“毕业时间”、“平均成绩”7列属性作为输入值,将训练集中“就业情况”作为最终的分类结果(分类结果为“就业”和“未就业”两种情况)。
决策树是应用统计、机器学习和数据挖掘领域的监督学习算法[6]。主要用于分类和预测模型,不仅可以获得准确的分类结果,而且可以根据其树状结构解释内部数据分类过程[7]。一般一个决策树包含一个根结点、若干个内部结点和若干个叶结点;叶结点对应于决策结果,其他每个结点对应于一个属性测试,根结点包含样本全集,从根结点到每个叶结点的路径对应了一个判定测试序列。常用的决策树算法有ID3,C4.5,CART算法,其中C4.5算法有两个明显的优势,一是能够更有效的处理连续属性,二是可以解决ID3算法出现的过拟合问题。本研究采用C4.5算法构建决策树模型,利用信息“增益率”来选择最优划分属性。C4.5算法的计算过程如下。
3.1 计算样本集的初始信息熵
“信息熵”是度量样本集合纯度最常用的指标。
假设D为样本集合,D中第k类样本所占的比例为Pk(k=1,2,…|γ|),则D的信息熵如公式(1)所示。
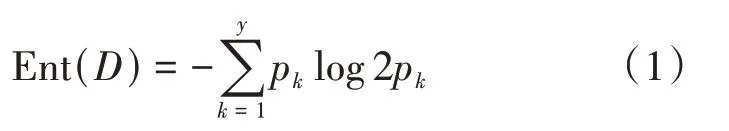
3.2 计算样本数据集的分裂熵
假定属性a有V个可能的取值{a1,a2,…av},若使用a来对样本集D进行划分,会产生V个分支结点,其中第v个分支结点包含了D中所有在属性a上取值av的样本,记为Dv。考虑到不同的分支结点所包含的样本数不同,给分支结点赋予权重,结合公式(1),样本数据集的分类熵计算方法如公式(2)所示:

3.3 计算属性a的信息增益
为了确定属性a能否有效降低整体“信息熵”,a属性的信息增益可定义为:

3.4 计算属性a的信息增益率
为了解决信息增益可能造成的过度拟合问题,C4.5算法采用信息增益比来选择最优划分属性。属性a的固有值定义为:

属性a的信息增益率定义为:

C4.5算法选择Gain_ratio(D,a)最大的属性a*作为根结点,对a*的不同取值对应的D的V个子集递归调用上述过程生成a*的子节点,从而生成一棵树。
使用Python软件,利用sklearn模块中的DecisionTreeClassifier进行数据挖掘。为避免决策树分支过多而出现过拟合,利用5折交叉验证法验证当决策树的最大深度max_depth设置为5,min_samples_split为10时,能够较好地拟合训练集数据,且能较好地预测测试集数据。利用sklearn.feature_selection中的SelectKBest特征选择函数,得到属性列的重要程度如图1所示。

图1 影响高职学生就业因素得分柱形图
横坐标表示实际训练数据的属性列名称,纵坐标表示属性的得分值,分值越高,属性越重要。从图中可知,特征得分大小排序结果为:毕业时间2020>民族>性别>成绩>专业>所属校区>政治面貌,这与决策树算法得出的结论一致。由此可知,影响高职毕业生就业的最重要因素是毕业时间2020年,2020年作为划分数据的根结点,与该年的疫情影响有一定关系;其次,民族属性很重要,原因是从2017年开始,该高职学校的毕业生少数民族与汉族的比例从50%开始逐年增加;性别属性也较为重要,这与用人单位对于理工院校的用人需求以男生为主有关。
利用决策树挖掘的规则为:毕业时间在2017—2019年的学生除了少数所在系部为铁路工程的女生外基本都能成功就业;2016年成绩低于75.82分的女生均不能就业,成绩高于75.82分且所在系部为运营管理的女生均能就业;2020年,少数民族学生成绩低于73.37分的学生均不能就业,成绩高于77.7分的少数民族男生均能就业,成绩高于77.37分所在系部为机车车辆的女生均能就业,2020年,汉族男生所在系部为机车车辆且成绩高于70.78分均能就业,非机车车辆的汉族男生均能就业。
4 模型评价
为了确定利用决策树算法建立的高职学生就业预测模型的实用性,以四格表为数据基础,运用查准率(precision)、召回率(recall)、正确率和F值[8]和精确度5个评价指标对决策树算法的性能进行评价,其中精确度借鉴F值的调和平均值计算方法,定义为正确率和F值的调和平均值[9]。
本研究中TP(true positive)为真正例,即实际结果为“就业”,数据挖掘结果也为“就业”的样本数;TN(true negative)为真负例,即实际结果为“未就业”,数据挖掘结果也为“未就业”的样本数;FP(false positive)为假正例,即实际结果为“未就业”,数据挖掘结果为“就业”的样本数;FN(false negative)为假负例,即实际结果为“就业”,数据挖掘结果为“未就业”的样本数。
查准率越高,算法的敏感性越好;召回率越高,算法的灵敏度越好,正确率越高,说明算法准确度越高;精确度越高,说明算法的精确度越好;F值越大,说明算法的整体性能越好[10]。
根据决策树算法建模,采用样本总体的30%作为测试集进行测试,分别计算相应的评价指标,计算结果如表2所示。

表2 决策树算法性能指标
从表2可知,决策树算法建立的高职学生就业预测模型的F值为0.9026,精确度为0.8702,说明该算法较好地实现了数据挖掘和分类预测。
5 结语
大数据时代,数据是宝贵的资源,如何运用数据挖掘算法对其进行有效的挖掘和分析从而指导我们的工作至关重要。本研究运用决策树算法挖掘了影响学生就业的关键因素,从实验结果发现影响高职学生就业的主要因素为毕业时间,其次是民族、性别、成绩和专业;其中毕业时间、性别、民族这些关键因素属于客观因素,学生不能改变,但是学习成绩是可以通过努力提高的。学生要顺利就业的成绩要求为:女生成绩高于75.82分,少数民族男生成绩高于77.37分,汉族男生的成绩要高于70.78分;相对于汉族学生,用人单位对少数民族学生的学习能力要求更高,所以少数民族学生想要顺利就业除了学习好国家通用语言文字以外,要努力提高自己的学习能力。因此学校在制定人才培养方案时,需要提高对少数民族学生学习能力的要求;相对于男生而言,就业单位选择女生时不仅仅有学习成绩还有专业的要求,学校在考虑招收女生时应该适当的对女生就业率高的专业扩大招生。通过对高校数据挖掘发现学校与企业签订订单协议这种方式能够保证高的就业率,因此学校今后可以考虑增加订单培养的规模。
利用决策树建立的学生就业预测模型,对未毕业学生就业情况进行预测,可以使学校有针对性的调整招生、就业指导方案,帮助学生端正就业观念,学生可以根据预测结果及时调整自己的学习状态,制定合理的职业生涯规划,最终提高高职毕业生的就业率。
