基于深度学习的行为识别算法综述
2022-01-20胡凯郑翡卢飞宇黄昱锟
胡凯 郑翡 卢飞宇 黄昱锟
0 引言
随着虚拟现实技术[1]、人机交互技术[2]等在现实生活中的广泛应用,针对行为识别的研究日渐发展,在计算机视觉中占据着举足轻重的地位.行为识别研究的目的是在视频或图像序列中得到正在进行的行为动作,判断其行为类别.
目前,行为识别的研究方法分为两类:一类是基于手动提取特征的方法[3-7],另一类是基于深度网络学习特征的方法.
基于手动提取特征的方法是采取传统机器学习方法对视频提取特征,然后对特征进行编码,对编码向量进行规范化,并训练模型,最后进行预测分类.其优点在于能够根据需要提取特征,针对性强、实现简单,但由于行为识别存在光照、动作相似(慢跑和跑步)、动态背景等噪声[8],手动提取的特征不能很好地满足之后的分类任务,因此基于手动提取特征的方法对行为识别的研究取得的效果不是很显著.其中可靠性最高的是iDT(improved Dense Trajectories),但该算法计算速度很慢,无法满足实时性要求.
近年来,深度学习得到深入发展,在很多领域得到了应用.因为深度学习的原理是用大量神经元来模拟人类视听、思考等活动,与行为识别具有相同的机制[9],因此科研人员也尝试使用深度学习来解决行为识别问题,并取得了一系列较好的成果.总体而言,基于深度学习的行为识别方法的优点是能够自动学习特征,实现端对端的学习过程,学习到的特征较为全面,性能较好,缺点是需要大量的数据来训练.
现有的基于深度学习的行为识别算法的网络框架大多由卷积神经网络发展而来.由于行为识别的对象为视频序列,与单张图像相比,增加了时间序列的信息,因此基于深度学习的行为识别算法更多的是用来学习时间序列上的特征.
较为经典的网络有Simonyan等[10]于2014年提出的双流卷积网络,它将空间流和时间流特征分开学习,最后将两者融合,该方法解决了传统方法中时间流特征缺失的问题.针对双流卷积网络中丢失了动作的时间关联信息的问题,Wang等[11]提出了三流卷积网络,在双流网络的基础上将时间流进一步细分为局部时间流和全局时间流.Feichtenhofer等[12]针对双流卷积网络融合方式不佳,导致网络性能不佳的问题,改进了双流网络融合的方式和位置.针对双流卷积网络无法对长时间序列建模的问题,Wang等[13]提出将双流卷积网络结合均匀稀疏采样方法,来对整段视频序列进行建模.在Wang等[13]的基础上,Lan等[14]对融合部分的片段加入了权重,而Zhou等[15]则提出通过对不同长度视频帧的时序进行推理然后融合得到结果的想法.
在双流卷积网络提出之后,Tran等[16]受到时间流特征的启发,提出了3D卷积网路(C3D),在2D卷积的基础上增加了时间维度来学习时间流特征.由于双流卷积网络和3D卷积的出色表现,Carreira等[17]提出了I3D网络,采用双流卷积网络和3D卷积相结合的网络结构,基于inception-V1模型将2D卷积扩展到3D卷积.Diba等[18]提出了T3D网络,采用3D卷积运用到DenseNet模型中,并引入TTL层(Temporal Transition Layer),使用不同尺度的卷积来捕捉信息.Qiu等[19]提出了P3D网络,该网络改进了ResNet网络内部的卷积形式并加深了网络.Ng等[20]将经典的处理时间序列网络——LSTM网络和双流卷积网络的结构相结合来学习时间特征.2019年,Li等[21]提出的时空特征协同学习网络设计了联合时空特征学习操作(CoST),采用2D卷积联合学习时空特征,在不降低准确率的前提下加快了计算速度.上述方法在行为识别研究中普遍取得了较高的准确率.本文按照网络的框架结构分类在第三章进行了具体介绍.
本文首先介绍了行为识别的背景;接着介绍了本领域研究人员常用的数据库;然后介绍了行为识别的传统方法中效果最好的iDT算法及其前身DT算法,以及其采样特征和编码的方式;再按照发展历程,从最早2014年提出的双流卷积网络到2019年提出的时空特征协同学习网络,重点介绍了几个基于深度学习的具有影响力的行为识别算法,具体包括它们的基本框架和流程,比较了各个算法性能,提供了它们的资源,并对网络结构进行了分类;最后是总结,以及对未来行为识别的研究方向的展望.
1 数据库
国内外研究团队在算法训练中通常采用人体动作数据库来检测算法的精确性和鲁棒性.数据库至少有如下两个重要作用:
1)使研究人员无需关心采集与预处理的过程;
2)能够检测和比较不同算法在同一标准下的不同性能.
常用数据库简介如表1所示.
KTH数据库[22]于2004年发布,包括25个人在4个不同场景下的6种动作(包括慢走、慢跑、跑、拳击、挥手、拍手),共有2 391个视频样本,包含了尺度变换、衣着变换、光照变换,但拍摄相机固定,背景较单一.
Weizmann数据库[23]于2005年发布,包括9个人分别完成的10个动作(弯腰、拉伸、跳高、跳跃、跑步、站立、蹦跳、慢走、挥手1、挥手2),数据库中除了类别标记外还有前景人的剪影和方便背景提取的背景序列,但该数据库视角固定、背景简单.
上述两个数据库发布时间较早,在传统方法的行为识别中引用率很高,大大促进了之后行为识别的发展,但因其背景简单、视角固定,每段视频只有一个人做动作的不足日渐显现,已经不能满足人们对现实行为识别的要求,所以现已经很少使用.
UCF-101数据库[24]是美国中佛罗里达大学于2012年发布的,数据集中的样本包括来自电视台收集的各种运动样本、从视频网站YouTube上下载保存的视频样本,共有5类大动作(人物交互、人人交互、肢体运动、身体运动、乐器弹奏),101类具体小动作,共13 320段视频.该数据库样本数量大、动作类别丰富,能够较好地训练算法,因此应用较多.
HMDB-51数据库[24]是布朗大学于2011年发布的,视频样本来自电影和视频网站YouTube中的视频片段,共有51类样本动作,共6 849段视频,每类样本动作至少含有101段视频.
上述两个数据集样本较多、背景繁杂,不仅能够检验算法结果的精确性,而且能够检测算法的鲁棒性.目前,UCF-101和HMDB-51数据集在基于深度学习的行为识别中应用较多.
除了上述应用较为广泛的数据库外,还有例如Sub-DBMS、PennAction、SBU、NTU等应用较少的数据库,在此简单介绍.
Sub-DBMS数据库包含316个视频,12种动作类别(例如抓取、行走、打高尔夫、投掷橄榄球等),数据库容量较小.
PennAction数据库由宾夕法尼亚大学收集发布,其中包含15个不同动作的2 326个视频序列,并且包含每个视频序列的人体关节注释.
SBU数据库全称SBU Kinect互动数据库,相较于Kinectics数据库,该数据库多了人类肢体的动作,更强调人体肢干,用以识别人的肢体动作.

表1 常用数据库简介
NTU数据库由56 880个动作样本组成,其中包含每个样本的RGB视频、深度图序列、3D骨架数据和红外视频,更加注重人体骨骼在动作运动中的位置变化,因此更适合于最近兴起的基于骨架检测的行为识别算法.
2 传统方法的行为识别算法
行为识别主要分成基于手工提取特征和基于深度学习两种方式.
虽然基于深度学习的行为识别算法效果均已经超过了DT/iDT算法,但是DT/iDT算法对本领域发展产生了重大影响,后续许多取得良好性能的新方法都是采用了将深度学习和iDT算法相结合的思路,因此DT/iDT算法是在行为识别领域中不可或缺的.iDT算法是密集轨迹算法(Dense Trajectories,DT)的改进,因此先介绍DT算法.
2.1 DT算法
DT算法的基本框架[25]如图1所示,具体流程为:
步骤1.将视频每一帧图片划分为多个尺度,通过网格划分的方式对每个尺度的图片进行密集采样特征点,并去除一些无法跟踪的特征点.
步骤2.跟踪特征点来获得视频序列中的轨迹,某个特征点在连续的L帧图像上的位置构成了一段轨迹,特征点的跟踪在每个尺度上独立进行.为避免漂移现象,每L帧就要重新采集特征并重新跟踪.
步骤3.沿着某个特征点长度为L的轨迹,在每帧图像上去特征点周围N×N的区域构成时间-空间体,将该时间-空间体分出nσ×nσ×nτ块区域用来特征提取,采用HOG特征来计算灰度图像梯度直方图,采用HOF特征来计算光流信息(方向和幅度信息)直方图,采用MBH特征来计算光流图像梯度直方图,采用L2范数对HOG、HOF、MBH特征归一化.
步骤4.一段视频中存在大量轨迹,每段轨迹对应一组特征,对每个特征组采用Bag of Features进行特征的编码,得到一定长度的特征编码来进行视频分类.
步骤5.采用RBF-x2核和一对多策略训练的SVM对视频进行分类.

图1 DT算法的基本框架[25]Fig.1 Basic framework of DT algorithm[25]
2.2 iDT算法
iDT算法是DT算法的改进版,大致过程和框架和DT算法类似,在一些特征处理和噪声处理上进行了改进以提升算法性能.
改进1[26].通过估计相机运动来消除背景上的光流和轨迹.由于相邻两帧图像之间变化较小,可以假设后一帧图像由前一帧图像通过投影变换得到,因此估计相机运动问题可以近似为利用前后帧图像计算投影变换矩阵.在两帧图像之间采用SURF特征和光流特征进行特征点匹配,然后利用随机抽样一致算法(RANdom SAmple Consensus,RANSAC)估计投影变换矩阵.
改进2.在图像中人的动作较为显著,人身上的匹配点对使得投影矩阵的估计不准确.因此iDT算法中使用人体探测器检测人的位置框,并去除该框中的匹配点对,使得人的运动不影响投影矩阵的估计.
上述两个改进对iDT算法性能的提升有很大帮助.除此之外,iDT算法采用L2范数进行特征归一化,使用Fisher Vector[27]进行特征编码,以此来提升算法的准确率和速度.
iDT算法对于DT算法主要改进在于对光流图像的优化、特征正则化方式和特征编码方式,这些改进使得算法的效果有了明显的提升,在HMDB-51数据集上的准确率从46.6%提高到57.2%.
iDT算法在提取特征方面具有针对性,相比深度学习,iDT算法能够较为精确地提取出与行为相关的特征,因此其稳定性较高,与第三章的深度学习算法结合能够提高深度学习算法的性能.
3 基于深度学习的行为识别算法
深度学习中用于行为识别的网络主要是卷积神经网络(CNN)和循环神经网络(RNN).CNN通常由卷积层、池化层和全连接层组成.经典的CNN,如AlexNet、VGG16等,通过对卷积层、池化层和全连接层的不同排列组合,达到不同的提取特征的效果.RNN是以一段序列数据为输入,在序列的变化方向进行递归,并且循环单元按照链式连接的递归神经网络[28].CNN在网络的层与层之间建立了权值连接,而RNN在层之间的神经元之间也建立了权值连接,其输出不仅与一个序列的当前输入数据有关,还与之前的输出有关.
现有的基于深度学习的行为识别算法大多在双流网络、3D卷积网络和RNN(尤其LSTM)的基础上发展而来.近两年基于人体骨架、多视角等其他深度学习算法逐渐发展,因此本文按照网络的结构发展将行为识别的深度学习算法分为四大类:基于双流网络、基于3D卷积网络、基于LSTM网络、其他算法,并在此分类基础上,对基于深度学习的行为识别算法进行介绍.
3.1 基于双流网络的行为识别深度学习算法

图2 双流卷积网络工作流程[10]Fig.2 Workflow of two-stream convolutional networks[10]
Simonyan等[10]提出了基础的双流网络结构.如图2所示,该网络设计了空间流和时间流两个并行的网络[29],使用两个独立的CNN网络来分开处理视频中空间和时间信息,空间流网络的输入为视频中采样的单帧图像,时间流网络的输入是光流信息,然后将两个网络识别的结果进行融合,最终得到识别的结果.该网络最终在UCF-101数据库、HMDB-51数据库上分别达到了88%、59.4%的准确率.由于它具有非常好的结构,并具有很好的拓展性,所以引起了科研人员的关注.围绕双流网络准确率和鲁棒性,后续涌现了许多改进的算法.
针对双流卷积网络通过直接平均或支持向量机融合了空间流和时间流的识别结果,不能很好地融合时间和空间信息的问题,Feichtenhofer等[12]改进了双流网络融合的方式和位置,如图3所示,提前采用双线性融合的方式融合了空间流和时间流的信息.实验结果表明在最后一层卷积层融合的效果最好,和采用相同模型的原始双流卷积网络相比,不仅减少了网络参数,而且准确率提高了4个百分点.

图3 双流网络融合方式[12]Fig.3 Two-stream convolutional network fusion[12]
Wang等[13]结合均匀稀疏采样方法抓捕到了时间范围较长的信息以处理长时间的视频.该网络将视频分为K段,将每段视频都输入到双流网络得到分类结果,采用加权平均的方式将所有结果融合得到最终结果,克服了经典的双流网络只能处理短时视频的问题.而Diba等[30]采用另一种融合方式,提出了一个时序线性编码层(Temporal Linear Encoding,TLE),以此来对视频分段后提出的特征进行融合编码,捕捉所有空间位置上特征之间的相互作用,以实现捕捉长时间的动态过程,并且能够在有限的样本下学习卷积神经网络模型.
虽然双流网络解决了视频动作识别上关于时间序列的部分问题,但还是丢失了动作在时间序列上的关联性.为了弥补双流网络在时间序列上信息的缺失,Wang等[11]提出了三流网络,在双流网络的基础上,将时间流进一步细分为局部时间流和全局时间流.空间流网络的输入为视频中采样的单帧图像,局部时间流网络的输入是光流信息,全局时间流网络的输入是运动堆叠差异图像(Motion Stacked Difference Images,MSDI),采用PCA-Whitening操作对三个流(空间流、局部时间流、全局时间流)上学习的特征进行预处理,然后进一步由soft-VLAD(局部聚合描述符的矢量)[31]编码并使用SVM分类.三流网络相比双流网络在UCF-101和HMDB-51数据库上的准确率都有显著提升.除此之外,其他研究者受到Wang等[11]的启发,开始了多流网络对动作识别的研究[32-33],提高了时空信息的鲁棒性和识别结果的准确性.
双流网络除了在准确率方面有提升的空间,在计算量方面也存在计算速度慢的缺点,其中计算光流信息浪费了大量计算资源,而Zhao等[34]提出了一种无需依赖光流信息的特征学习模型,能够直接从原始视频中提取出运动的动态信息,省去了计算光流信息的过程,节约了计算资源,提升了速度.其中动态信息包括静态特征、动态特征和特征变化三个部分,它们共享低级特征,通过3D池化得到静态特征,采用Cost volume得到动态特征,采用Warped differences得到特征变化,最后将三个特征取平均融合在一起得到最终预测结果,其模型大致类似于三流网络.该网络在仅使用RGB图像帧的条件下和当前技术[13,16-17,19]相比取得了很好的结果,在UCF-101数据集上达到了91.8%的准确率,并且效率也高.分离动态信息网络模型[34]如图4所示.基于双流网络的行为识别深度学习算法对比如表2所示.
双流网络作为基于深度学习的行为识别算法中最早出现的网络,其将视频序列分为时间和空间两种特征的思想为研究者们提供了丰富的思路.若不考虑网络预训练等训练技巧,双流网络针对视频序列的特征处理的贡献是C3D和LSTM网络不可比拟的[16].
3.2 基于3D卷积的行为识别深度学习算法
卷积神经网络一般采用2D卷积,在多帧图像上2D卷积的结果是一张特征图,只包含高和宽,而3D卷积的结果是立体的,除了高和宽之外还含有时间维度,因此3D卷积更适合用来处理视频序列的信息.如图5展示了2D卷积和3D卷积的区别[16].
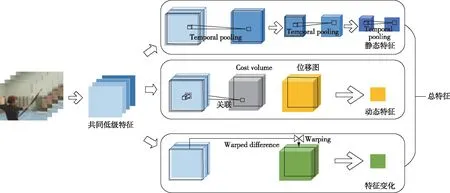
图4 分离动态信息网络模型示意[34]Fig.4 Schematic diagram of disentangling components network model[34]
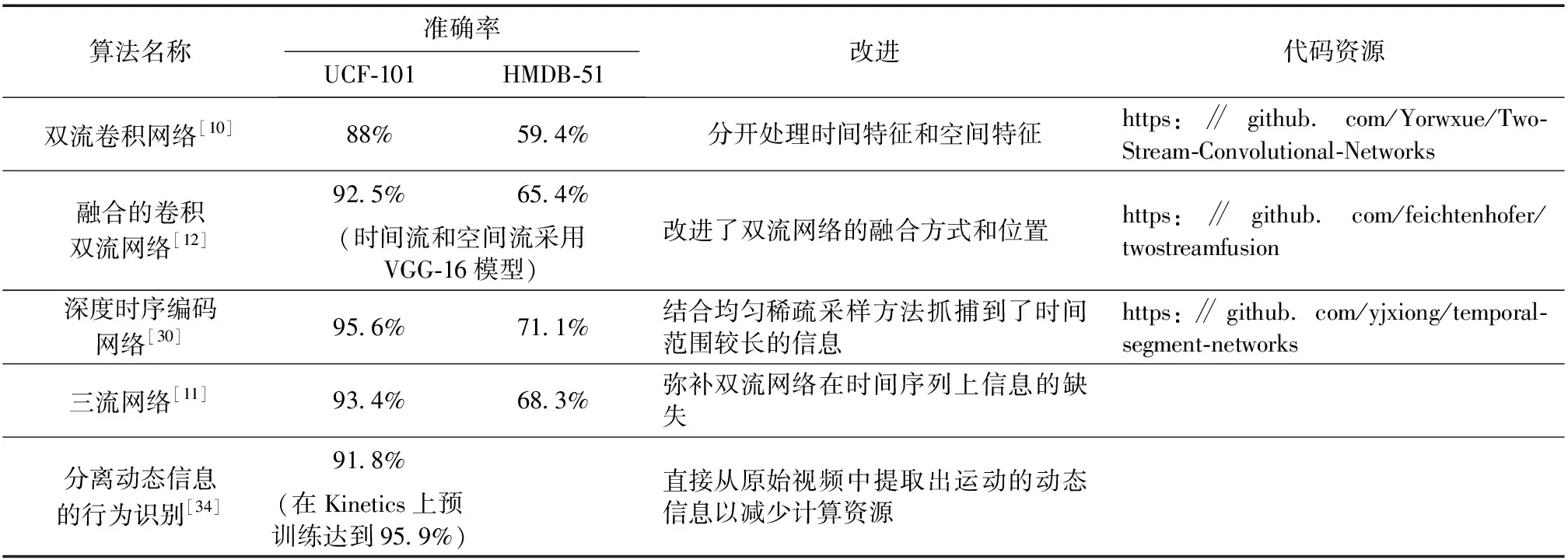
表2 基于双流网络的行为识别深度学习算法总结
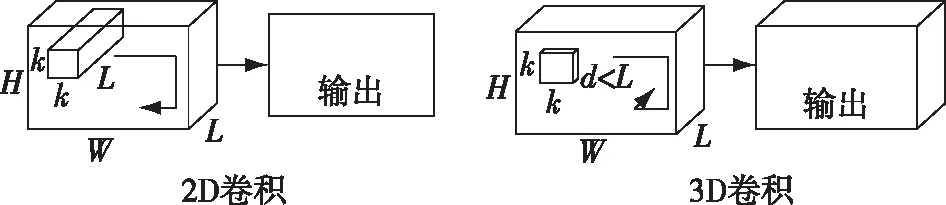
图5 2D卷积和3D卷积的区别[16]Fig.5 Difference between 2D convolution and 3D convolution[16]
最开始,Tran等[16]提出了一种名为C3D(Convolutional 3D)的3D卷积神经网络,在该网络中首次出现了3D卷积,并将其应用在了行为识别中.通过对比实验,确定了3×3×3为最优3D卷积核尺寸.如图6所示,该网络设计了:8个卷积层,所有的3D卷积核尺寸为3×3×3,步长为1×1×1;5个池化层,第一层池化层尺寸为1×2×2,步长为1×2×2,其余池化层尺寸为2×2×2,步长为2×2×2,以保留更多的时间信息;2个全连接层,尺寸为4 096;1个softmax输出层.
该网络在UCF-101数据库达到的最好准确率为85.2%,和iDT结合达到90.4%的准确率,在相同条件下与双流网络相比,准确率提升了1.6个百分点.该网络具有良好的泛化性能,能够灵活地和其他网络相结合,并且其计算效率高,没有过多的计算公式,易于训练和使用.
由于C3D无法利用在ImageNet上预训练过的2D网络,导致参数过多增加了计算量,并且当时缺乏足够大的视频数据集来训练网络.为了改进上述缺点,Carreira等[17]提出了I3D网络(Two-Stream Inflated 3D ConvNet)和Kinetics数据库.I3D将3D卷积网络和双流网络相结合,卷积网络应用了Inception-V1模型[17],将原网络中的卷积核扩展为3D卷积核,因此I3D可以直接使用已经在ImageNet上预训练的2D卷积核参数来初始化参数,改进了C3D参数多的问题,提高了网络的训练效率,并在Kinetics数据库上进行预训练,以提升网络的性能.
在对比实验中,该网络在UCF-101数据库、HMDB-51数据库上分别达到了93.4%、66.4%的准确率,若采用Kinetics数据库进行预训练,能在UCF-101数据库、HMDB-51数据库上分别达到98%、80.7%的准确率,达到了很好的效果,也验证了采用足够大的数据库进行预训练能够提升网络性能.
另一种将参数从预先训练的2D卷积网络转移到随机初始化的3D网络中,以实现稳定的权重初始化的方法是Diba等[18]提出的T3D(Temporal 3D ConvNet),该网络采用了DenseNet[35],将DenseNet中的卷积核换为3D卷积核,并提出了TTL层(Temporal Transition Layer),能够使用不同尺度的卷积来捕捉不同时序信息,将TTL层嵌入到DenseNet中,既能减少参数,又能提高准确率.TTL层的结构如图7所示.

图6 3D卷积网络的结构图[16]Fig.6 Structure of 3D convolutional network[16]
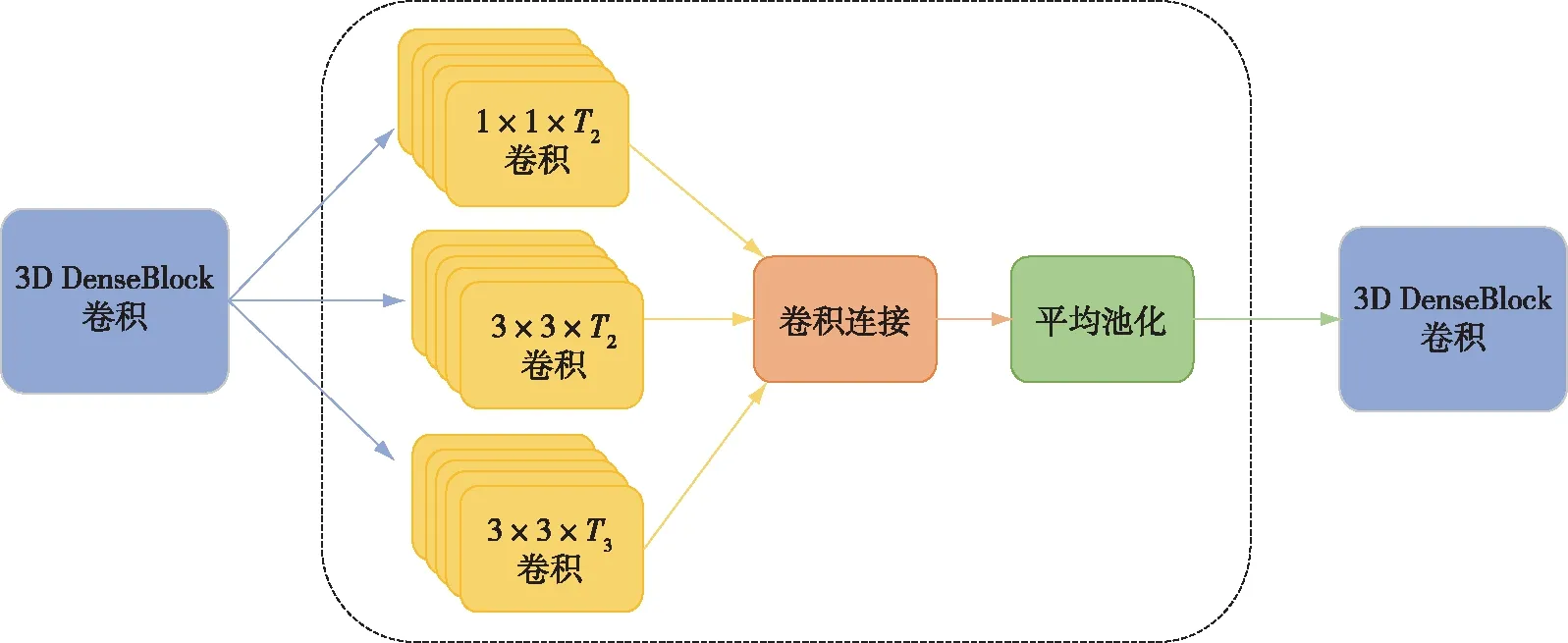
图7 TTL层的结构[18]Fig.7 Structure of TTL[18]
3D卷积包含时间维度,能够很好地适用于处理视频数据,但参数设置过于复杂,因此Qiu等[19]提出了另一种减少网络参数的模型——P3D残差网络(Pseudo-3D ResNet),采用ResNet的网络框架,使用1×3×3卷积(用来获取空间维特征)和3×1×1卷积(用来获取时间维特征)级联或并联的方式来代替3×3×3的原始3D卷积,并且设计了较深的网络将如图8所示的三种P3D结构都应用了进去.

图8 三种P3D结构[19]Fig.8 Three structures of P3D[19]
3D卷积的大量参数增加了3D卷积神经网络的优化难度、内存使用和计算成本,导致训练3D神经网络十分困难.鉴于2D卷积在二维图像处理中的优良表现,Zhou等[36]提出一个3D/2D混合卷积模块(MiCT)来处理视频数据.MiCT模块(图9)结合了3D/2D串联混合模块和3D/2D跨域残差并联模块,既增加了3D卷积神经网络的深度,能够生成更高级的3D特征,也降低了学习3D特征和时空特征融合的复杂性.MiCT使3D卷积神经网络以更少的3D时空融合、更小的模型、更快的速度来提取到更深的时空特征.
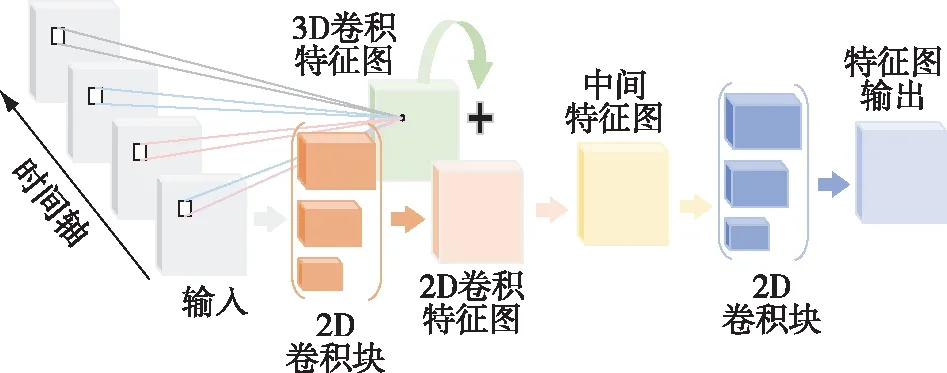
图9 MiCT模块图[36]Fig.9 MiCT model[36]
C3D网络的提出将研究者们的思路从二维卷积中解放出来,3D卷积泛化性能好,能和许多网络结合应用,并且提高了原有网络的性能.C3D和双流网络、LSTM网络的最大不同之处在于C3D减少了网络参数,加快了网络的训练速度.
基于3D卷积的算法对比如表3所示.
3.3 基于LSTM网络的行为识别深度学习算法
循环神经网络在神经网络的输入层、隐藏层和输出层之间的神经元中建立了权值连接,网络模块的隐藏层每个时刻的输出都来自之前时刻的信息[37].RNN的循环网络模块不仅能够学习当前时刻的信息,也会保存之前的时间序列信息,但对于时间序列较长的信息,RNN容易出现梯度消失的问题,因此提出了LSTM网络来解决这个问题.

表3 基于3D卷积的行为识别深度学习算法总结
LSTM网络用一个记忆单元替换原来RNN模型中的隐藏层节点[38],其关键在于存在细胞状态来存储历史信息,设计了三个门结构通过Sigmoid函数和逐点乘积操作来更新或删除细胞状态里的信息.如图10所示为LSTM网络一个单元的内部结构[39],从左到右分别为遗忘门、输入门和输出门.LSTM网络通过累加的线性形式处理序列信息来避免梯度消失的问题[40],也能学习到长周期的信息,因此能够用来学习长时间序列的信息.

图10 LSTM网络单元的内部结构[39]Fig.10 Internal structure of LSTM network unit[39]
遗忘门的状态方程为
ft=σ(wf*[ht-1,xt]+bf).
(1)
输入门的状态方程为
ft=σ(wi*[ht-1,xt]+bi),
(2)
kt=tanh(wk*[ht-1,xt]+bk).
(2)
更新之后的细胞状态为
Ct=ft⊗Ct-1+it⨁kt.
(4)
输出门的状态方程为
Ot=σ(wO*[ht-1,xt]+bO),
(5)
ht=Ot*tanh(Ct).
(6)
由于LSTM能够处理时间序列信息,因此LSTM网络也常被应用于行为识别领域.而为了能够降低计算量同时学习到视频的全局特征,Ng等[20]提出了结合LSTM的双流网络模型(图11),使用了在ImageNet上预训练的CNN网络(AlexNet或GoogLeNet)来提取视频帧的图像特征和光流特征,然后将提取到的图像特征和光流特征输入给LSTM网络来处理,得到最终结果.虽然该网络达到的效果一般,但给行为识别领域的研究提供了新思路:即使光流图像存在许多噪声,与LSTM结合之后,也对分类有一定帮助.

图11 卷积网络连接LSTM部分的框架[20]Fig.11 Frame of convolutional network connecting LSTM part[20]

图12 RPAN网络结构[41]Fig.12 Structure of RPAN network[41]
由于之前的卷积神经网络和LSTM结合的方法不能表示精细动作,其他的注意力机制和LSTM结合的方法不能很好地训练LSTM网络,Du等[41]提出了一种端到端的循环姿态注意网络(RPAN),如图12所示的网络结构:该网络在第t帧采用双流网络中的网络生成特征图,姿态注意机制和前一帧LSTM隐藏模块共同从第t帧的特征图中学习与人体部位相关的特征,经过池化生成一个高分辨的姿态特征输入给LSTM.最终该网络在Sub-JHMDB、PennAction数据库上分别达到了78.6%、97.4%的准确率.LSTM和注意力机制结合在行为识别方面能取得很好的效果,但网络结构较为复杂.
研究者们注意到视频分类本质上是多模态的,图像、运动以及声音都可能作为视频中行为识别的判断依据,然而之前的行为识别网络都没有注意到声音特征,因此Long等[42]提出了一种融合多模态的RNN框架,他们将视觉特征(包含RGB图像特征和光流特征)和声学特征分割为等长的片段输入到LSTM,减少了计算量,提升了速度,将LSTM网络应用到了提取不同的特征中.多模态LSTM网络框架如图13所示.
由于RGB信息存在许多噪声,Song等[43]提出用不同的特征信息来取代RGB信息,而骨架信息具有特征明确简单、不易受外界因素影响的优点,因此采用骨架信息来训练LSTM网络.他们提出的网络中有两个LSTM子网络:一个为时域注意力子网络,学习一个时域注意力模型来给不同帧分配对应的重要性,并以此对不同帧信息进行融合;另一个为空域注意力子网络,依据序列的内容自动选择每个帧中的主导关节.
最开始将LSTM网络和双流网络结合起来的LSTM的双流网络模型在UCF-101的数据库上准确率相较于双流网络并没有显著提高(表4),但其减少了网络的计算量,并且在之后的发展中可以看出:效果较好的LSTM扩展网络所应用的数据库大多为融入人体肢体动作的数据库.LSTM网络相较于双流网络和C3D,其对于细长的肢体动作信息更为灵敏,但归根结底,基于深度学习的行为识别算法的发展,离不开双流网络、C3D网络、LSTM网络的贡献.
3.4 其他行为识别深度学习算法
除了双流网络、3D卷积网络和LSTM网络在行为识别领域上的广泛应用,还有许多其他算法也在行为识别领域中有出色的表现,这些算法不仅有较高的准确率,在速度和鲁棒性方面也有一定提升.
大尺寸的视频和时序信息的冗余导致深度的视频学习任务比图像的难度大很多,Wu等[44]提出直接在压缩视频上训练深度网络来滤除噪声使视频的训练更加容易,主要做法是将视频分为I-frames(原始图像)和P-frames(运动信息)两个部分学习特征,最后将结果相加融合.
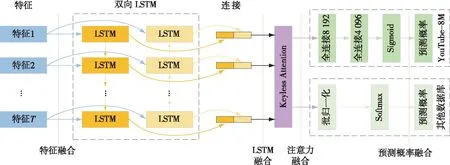
图13 多模态LSTM网络框架[42]Fig.13 Framework of multimodal LSTM network[42]

表4 基于LSTM网络的行为识别深度学习算法总结
Li等[21]于2019年设计了联合时空特征学习操作(CoST),克服了3D卷积网络的大量参数和计算量限制其实时性、有效性和2D卷积无法学习时间特征的缺点,CoST能够在权重共享的情况下用2D卷积联合学习时空特征.该网络以ResNet为骨干框架视频序列进行处理,如图14所示.具体操作为:将视频序列的3D向量从不同视角分解为3个2D图像,用3个相同的2D卷积核对三个视角的图像进行卷积,然后通过加权求和将三个特征图进行融合,如图15所示.该网络提出从多个视角联合学习时空特征,直接用2D卷积代替3D卷积,在保持准确率的前提下减少了计算量,并且网络结构较为清晰.

图14 进行CoST操作的ResNet框架[21]Fig.14 The ResNet framework for CoST operation[21]
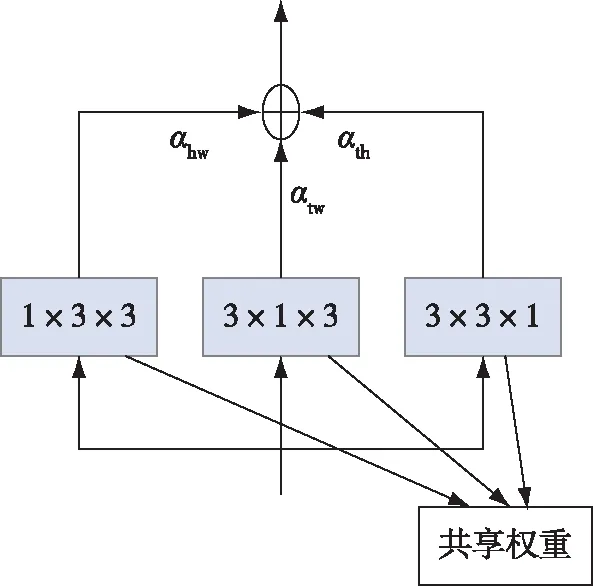
图15 时空操作联合学习[21]Fig.15 Joint learning of time and space operation[21]
Choutas等[45]认为单独处理图像和运动特征的双流结构不能够为动作识别提供足够丰富的信息,从而提出了一种新颖的方法:将人体关节作为关键点,对其运动变化进行编码,得到的特征称为PoTion,将该特征图输入到卷积神经网络中进行行为识别.实验结果表明,PoTion和其他网络结合能够提升原网络的性能.
而Cho等[46]提出了一种新的时空融合网络——STFN,它整合了整个视频的图像和运动信息的时间序列,然后聚合捕获的时间序列信息以获得更好的视频特征并通过端到端训练学习.该网络能够获取互补数据的局部和全局信息,并适用于任何视频分类网络.
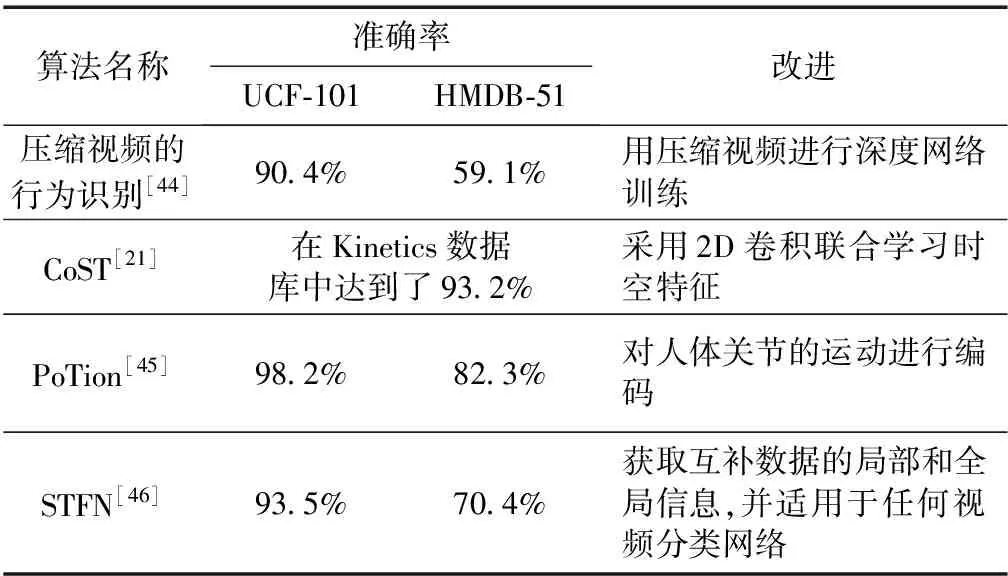
表5 其他网络的行为识别深度学习算法总结
4 总结和展望
人体行为识别在当今社会中有着越来越多的应用需求,受到了相关领域研究者们的极大关注[29].本文对近几年流行的基于深度学习的行为识别方法进行了整合分析.iDT算法是采用深度学习进行行为识别研究之前效果最好、稳定性最好、可靠性最高的方法,但其计算速度较慢,现有的深度学习方法可以很好地改进这一缺点,同时iDT算法中的思路值得借鉴,和深度学习的方法结合后在行为识别领域中取得了很好的效果.基于深度学习的行为识别方法不需要人工过多参与,直接在视频数据集上进行训练学习[47],虽然需要大量的数据来支撑,但能得到较为全面的特征,相较于传统的行为识别方法,泛化性能更好,结果也更精确,尤其在数据简单的情况下取得的效果更好.对于视频序列,深度学习能更好地处理时间序列的信息,因此深度学习比传统提取特征的方法更适用于行为识别领域.
现有的行为识别方法大多从双流卷积网络和3D卷积网络中受到启发并进行衍生.不同的组合能碰撞出新的火花,相同的网络和其他网络模型组合(如融合的卷积双流网络和iDT结合、双流3D卷积网络采用Inception-V1模型等)或采用数据库预训练(如双流3D卷积网络、CoST采用Kinetics数据库进行预训练等)都能取得比原单一网络更好的效果.LSTM网络既能处理视频的时间信息,又能解决梯度消亡的问题,因此也常常应用在行为识别网络中.虽然LSTM网络和双流网络结合的效果并不是特别好,但之后的研究者们从此受到启发,将LSTM网络和人体骨架检测结合起来进行行为识别,如Zhang等[48]提出了视图自适应递归神经网络,利用两个LSTM网络回归人体骨架的空间旋转参数和平移参数,将骨架旋转到一个合适的角度输入给LSTM网络进行行为类别的预测.
随着计算机视觉技术的发展,2018年至今出现了许多脱离双流网络和3D卷积网络的行为识别算法:基于骨架检测的行为识别算法、基于3D骨架检测的行为识别算法、基于注意力机制的行为识别算法、移动设备上的实时性强的行为识别算法.
近几年,研究者们在骨架检测上也取得了不错的成果,并且骨架信息相较于未处理过的肢体信息更加稳定,不受背景干扰,因此基于骨架检测的行为识别也随之发展,成为计算机视觉中一个重要的领域[49].骨架检测的行为识别对于幅度较大的动作能够取得较高的识别准确率[50-52],尤其是基于3D骨架的行为识别算法[52-54]实现了3D行为识别,但是各种行为识别算法对于微小的细节动作识别效果还不是很好,仍是个具有挑战性的问题.除网络架构之外,还有将注意力机制[41,55]引入行为识别中,发现深度学习无法选择重点关注的内容,如何降低算法的复杂性需要进一步研究.行为识别算法除了准确率的要求还有快速性的要求,Zhang等[56]首次提出在移动设备上部署当前深度学习动作识别模型,在不降低精确度的情况下,比其他模型的识别速度提升了6倍.基于深度学习的行为识别方法在最近出现了许多新方法、新模型,行为识别结果也朝着准确率高、实时性高的方向稳步发展,但目前仍存在所需样本数量庞大、网络模型复杂等问题,需要在以后的发展中进一步完善.
