基于集成学习方法的CLDAS土壤湿度降尺度研究
2022-01-20韩慧敏沈润平黄安奇狄文丽
韩慧敏 沈润平 黄安奇 狄文丽
0 引言
土壤水分参与地-气水分和能量交换,从而对作物生长、流域水文过程和气候变化产生重要影响[1-3],准确获取土壤湿度时空变化分布信息具有重要意义.近年来,多套基于陆面模式发展起来的土壤湿度陆面同化系统,包括全球陆面数据同化系统(GLDAS,0.25°×0.25°)[4]、北美陆面数据同化系统(NLDAS,0.125°×0.125°)[5]和中国气象局(CMA)陆面数据同化系统(CLDAS,0.062 5°×0.062 5°)[6].土壤湿度产品已被广泛用于陆面分析和气象业务,但是空间分辨率较低,极大地限制了其进一步应用,特别是在需要更高空间分辨率的精确农业管理和干旱监测领域.
为获得更高空间分辨率数据,许多学者对土壤湿度的降尺度方法开展了研究,目前主要有基于卫星遥感数据融合的方法、基于地理信息数据的方法以及基于模型的方法[7].基于卫星遥感数据融合的方法主要使用遥感数据,而不依赖站点资料,适用于区域大尺度的土壤湿度降尺度研究,但受卫星观测时间限制和云层覆盖的影响[8-9].基于地理信息数据的方法主要是利用地形、土壤质地和植被覆盖等参数,建立地理信息与土壤湿度之间的关系,获得高分辨率土壤湿度,但需要大量的实地数据来构建地统计或分形插值模型,从而限制了在较大尺度区域内的应用[10].基于模型的降尺度方法主要包括数理统计模型(如基于地统计学、多重分形或小波)和陆面模型,该类方法应用时需考虑模型关系的时空普适性,以及大量站点数据的输入[11].随着计算机性能的提高和人工智能技术的发展,机器学习方法被引入土壤湿度降尺度研究中,它能在缺乏连续数据的情况下,建立土壤湿度与陆表参数之间的关系,且具有较强的非线性问题学习能力和整合多源数据的灵活性,成为提高土壤湿度空间分辨率的有效技术.但单一机器学习方法易表现出对非线性及表征空间大的数据性能的不足,且易产生过拟合[12],难以全面考虑土壤湿度变化特征,导致估算精度不高、模型鲁棒性低等问题.而集成学习方法能结合多种学习器的优势,具有更高的模型准确性、鲁棒性和整体归纳能力,目前在土壤湿度降尺度研究中还鲜有应用.
CLDAS是国家气象信息中心研发的中国气象局陆面数据同化系统(CMA Land Data Assimilation System,CLDAS),其土壤湿度产品是利用我国多种资料融合和同化获得的大气强迫数据,驱动多种陆面模式模拟得到[13].该产品时空连续、不受天气影响,在中国区域的表现优于国际同类产品[14],目前空间分辨率只有6 km.为此,本文利用梯度提升机、深度前馈神经网络、随机森林以及Stacking集成学习方法,以华北地区为例,开展了对CLDAS土壤湿度产品进行降尺度研究,将其空间分辨率降尺度至1 km,以获得高时空分辨率连续的土壤湿度估算.
1 研究区域与数据
1.1 研究区概况
研究区位于我国华北地区,空间范围为110°21′~122°43′E,31°23′~41°36′N,包括北京、天津、河北、河南和山东5个省(市),占地约54万km2,是我国最主要的粮食产区,耕地面积大(面积占比71%)(图1),历史上多次遭受重大干旱,土壤湿度能够直接表征地表水分状态,是关键地表参数.
1.2 研究数据
1.2.1 CLDAS土壤湿度数据
中国气象局陆面数据同化系统(CLDAS-V2.0)土壤湿度资料是基于数据融合和同化技术,利用气温、气压、湿度、风速、降水辐射数据和初始场信息,驱动CLM和Noah-MP陆面模式集合模拟而获得[15].CLDAS-V2.0土壤湿度数据垂直分为5层,分别为0~5、0~10、10~40、40~100、100~200 cm,单位为m3/m3,产品覆盖东亚区域(60°~160°E,0°~65°N),空间分辨率为0.062 5°,时间分辨率为逐小时.将每24 h的土壤湿度值求平均,获得逐日土壤湿度,研究利用2019年4月1日至2019年10月31日0~10 cm土层土壤湿度数据(中国气象数据服务中心:http:∥data.cma.cn)开展研究.
1.2.2 遥感数据
采用Terra与Aqua卫星的MODIS数据(来源于美国国家航空航天局(http:∥ladsweb.modaps.eosdis.nasa.gov))获得的高分辨率陆面地表参量.时间范围为2019年4—10月.
1)地表温度数据:来自MODIS的MOD11A1和MYD11A1 V6产品,空间分辨率为1 km,时间分辨率为1 d.该数据采用广义分裂窗算法反演得到,同时它能够有效地消除大气的影响[16].为保持土壤湿度数据与地表温度数据的时间一致性,从数据集中提取白天地表温度数据和夜晚地表温度数据,经过投影、系数转换,并对同日次的白天和夜晚地表温度数据进行平均合成,得到逐日平均地表温度数据.
2)地表反照率数据:来自MODIS BRDF/ALBEDO系列MCD43A3产品,空间分辨率为500 m,时间分辨率为1 d,该数据是经过双向反射函数(BRDF)模型计算修正的反照率产品[17].本数据集包括7个窄波段和3个宽波段的黑空和白空反照率.白空反照率是漫射-半球反照率,反映了阴天条件下的地表反射状况;黑空反照率能够较为准确地反映正午时刻地球表面对太阳直射光线的反射情况[18].由于白空反照率和黑空反照率的平均值差异较小,且高度相关,实际地表反照率可选择白空、黑空反照率的平均值计算获得[19].
3)地表反射率数据:来自MODIS的MOD09A1和MYD09A1产品,空间分辨率为500 m,时间分辨率为8 d,共包含7个波段,其对应的波长范围如表1所示.该数据是低观测角度条件下,受云、云阴影及气溶胶等影响最小的8 d日数据合成产品[20].归一化差异水体指数(NDWI)计算公式[21]如下:
(1)
其中,ρ(858 nm)和ρ(1 240 nm)分别对应反射率数据的2、5波段.
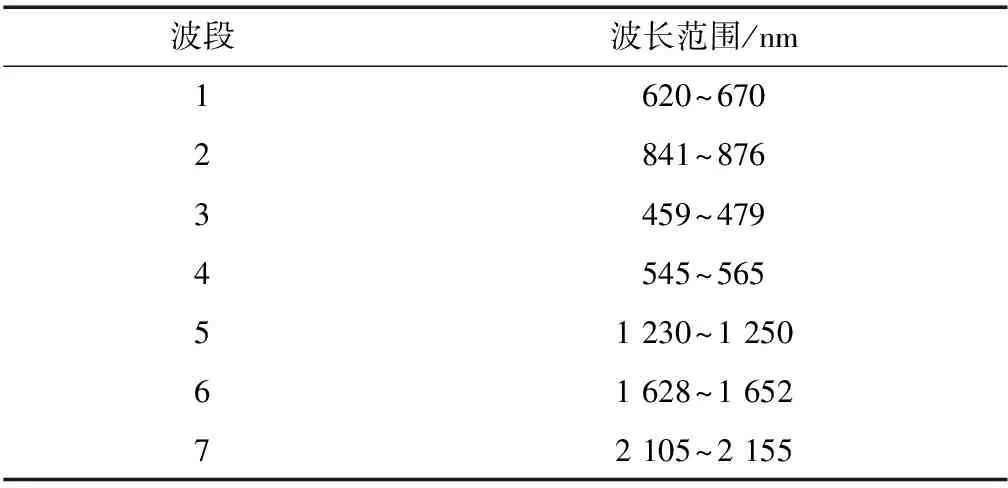
表1 反射率数据的波长范围
1.2.3 土壤质地数据
土壤质地数据来源于中国科学院资源环境科学数据中心(http:∥www.resdc.cn),投影为Albers正轴等面积双标准纬线圆锥投影,空间分辨率为1 km.该数据是根据1∶100万土壤类型图和第二次土壤普查获取到的土壤剖面数据编辑制作而成的,依据砂粒、粉粒、黏粒含量进行土壤质地划分,将数据分为Sand(砂土)、Silt(粉砂土)与Clay(黏土)3大类,每一类数据均通过百分比来反映不同质地颗粒的含量.
1.2.4 地形数据
数字高程模型(Digital Elevation Model,DEM)数据选用SRTM DEM数据,来源于中国科学院资源环境科学数据中心(http:∥www.resdc.cn).该数据是基于雷达测图技术通过美国“奋进”号航天飞机获得的,涵盖了60°N~56°S间陆地地表80%面积范围,经NASA喷气推进实验室处理完成[22].研究采用的数据是基于版本4.1的DEM数据,经重采样生成1 km全国数据.
将以上遥感数据、土壤质地数据以及地形数据投影统一转换至经纬度投影,利用华北地区行政边界裁剪等预处理,经双线性插值方法,对数据重采样,分别生成分辨率6 km和1 km的两种数据,6 km数据和CLDAS 6 km土壤湿度数据相匹配,用来训练降尺度模型,1 km数据作为降尺度模型输入数据,用于估算高分辨土壤湿度.
1.2.5 站点观测数据
站点数据来源于国家气象信息中心资料服务室的2019年逐小时观测资料[23].该站点土壤湿度观测在垂直方向上分为8层:0~10 cm、10~20 cm、20~30 cm、30~40 cm、40~50 cm、50~60 cm、60~80 cm、80~100 cm.利用频域反射技术(Frequency Domain Reflectometry,FDR)来测定土壤体积含水量[24].研究参考韩帅[25]提出的方法对土壤湿度观测数据进行质量控制,得到有效站点223个,采用随机方法,抽出185个作为训练站点数据用于建模,38个站点数据用于验证(图1).
2 研究方法
2.1 降尺度因子的选择
华北地区的土壤湿度在时间尺度上具有明显的季节性,受到夏季风的影响,夏季土壤湿度高,冬季土壤湿度低.在地域上中部区域地势较平坦,土地利用类型以农业用地为主,土壤湿度高;北部与西南部地形复杂,土地利用类型以草地和灌木丛为主,涵养水源的作用较差,土壤湿度低;南部和沿海地区粉砂粒和黏粒含量高、砂粒含量低,土壤湿度高.总体上除降水外,本地区土壤湿度变化受到温度、地形、植被、土壤等因素的共同影响[26-27].地表温度为监测和降尺度土壤湿度中最重要的变量,土壤表层温度发生变化,其内在因素是土壤热惯量,且随着土壤湿度的增大,土壤热惯量增大,因此,地表温度与土壤湿度有密切的相关性[28].高程和坡度是影响土壤湿度空间分布的关键因素[26],华北地区高程为-23~2 539 m,高程变化大,坡度为0°~22°,其中,94%的区域坡度为0°~5°,坡度变化小,所以引入高程作为降尺度因子之一.在可见光和近红外区域,土壤湿度与植被光谱响应之间存在显著关系,研究表明,短波红外区域对土壤湿度的监测效果更好[29-31].同时,短波红外波段是植物叶片吸收水分的区域,植被反射率与叶片含水量呈负相关[32].因此,选择基于短波红外波段的归一化差异水体指数,作为降尺度因子之一.土壤异质性通过土壤质地的变化,包括土壤颗粒和孔隙分布的变化,影响土壤湿度的分布.此外,地表反照率受到土壤颜色的影响,从而影响植被稀疏土壤的蒸发效率,进而影响土壤湿度[33].因此,参照前人研究[34-38],选用更高分辨率地表温度、高程、归一化差异水体指数、土壤质地和地表反照率等对土壤水分较为敏感的因子指标,作为降尺度因子来开展研究.
2.2 梯度提升机(GBM)
梯度提升机(Gradient Boosting Machine,GBM)是一种可以解决分类、回归和重要性排序问题的机器学习模型,是Boosting算法的典型代表.它遵循了集成学习的一种思想,即分多个阶段迭代训练一系列可叠加的基学习器模型,在迭代的推进过程中不断进行优化和提升,使每一次新的迭代都是为了减少上一次迭代的残差,使模型沿着残差减少最快的方向进行,由此产生一系列弱分类器,每个弱分类器都是一棵二叉树,最终将这些弱分类器组合形成能使损失函数达到极小的模型[39].GBM对异常值和不平衡数据具有鲁棒性,确保了高效的性能.其算法过程[40]如下:
1)输入训练集数据T={(x1,y1),(x2,y2),…,(xn,yn)},损失函数L(y,f(x)).
2)初始化模型f0(x)=arg min∑L(yk,c),c为常量,是用来估计损失函数最小化的常数值.
3)迭代n=1,2,…,N(N为样本数),k=1,2,3,…,K(K为基学习器的个数),计算rkn:
(2)
式中,rkn为损失函数负梯度在当前模型的值,若损失函数已达到最小值,则进行步骤5),否则进行下一步.
4)对rkn建立基学习器模型Tk(x),对梯度提升进行更新:
fm(x)=fm-1(x)+Tk(x).
(3)
5)得到强学习器:
(4)
梯度提升机方法基于陆地表面变量和土壤湿度之间的统计关系,降尺度过程主要涉及两个阶段:
1)训练.基于CLDAS土壤湿度数据,与土壤湿度数据空间分辨率保持一致的陆表变量数据和站点数据建立梯度提升机回归模型.
2)预测.将高分辨率陆表变量数据输入第1阶段建立的回归模型,以生成高分辨率土壤湿度数据(图2).

图2 梯度提升机土壤湿度降尺度结构示意Fig.2 Downscaling of soil moisture based on gradient boosting machine
2.3 深度前馈神经网络(DFNN)
本研究采用深度前馈神经网络(Deep Feedforward Neural Network,DFNN)作为深度学习算法.在回归任务中,该模型可以从大量变量中提取高级特征,以实现较高的预测精度[41].每一层的神经元可以接收前一层神经元的信号,并产生信号输出到下一层.第0层叫做输入层,最后一层叫做输出层,其他中间层叫做隐藏层(图3).这种网络模型在各层之间具有全连接的神经元结构,其中隐藏层根据模型的复杂程度可以设计成任意数量的多层,各层之间的连接表示特征的权重,其中信息没有反馈的从左向右传输.连接输入和输出的每层神经元结构具有以下映射关系[42]:
y=f(x,θ),
(5)
其中x和y分别代表输入和输出,θ表示已知输入和期望输出值之间映射的最优参数解.为了避免深层网络反向传播可能带来的梯度消失和梯度爆炸的问题,各层的激活函数采用ReLU函数.输出层概率分布计算采用softmax函数.假设输入样本表示为:X=(X1,X2,X3,X4,X5),两个隐藏层h1,h2的维度分别为H1,H2,则两个隐藏层的输出分别如式(6)、式(7)所示,输出层的输出如式(8)所示.W1,W2,W3为各连接层的连接权重矩阵,b1,b2,b3为各层偏移量.模型训练优化的参数集合为θ={W1,W2,W3,b1,b2,b3}.
yh1=ReLU(W1X+b1),
(6)
yh2=ReLU(W2yh1+b2),
(7)
y=softmax(W3yh2+b3).
(8)
模型训练及预测过程如下:
1)变量因子标准化及输入.本研究使用标准差标准化方法,如式(9)所示,将处理好的标准化6 km空间分辨率自变量与因变量因子输入DFNN模型.
2)模型调参.需要通过调整模型参数以达到最好的训练效果,主要参数包括隐藏层层数L、隐藏层每层神经元数量N和训练迭代次数epochs.
3)土壤湿度预测.得到最优训练模型后,将1 km空间分辨率的自变量因子输入训练好的模型,得到1 km空间分辨率预测土壤湿度(图3).
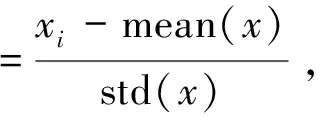
(9)
式中,xi为一列自变量中的第i个值,mean(x)和std(x)分别是x所在列自变量的均值和标准差.
2.4 随机森林(RF)
随机森林是Bagging算法的典型代表,作为一种增强型决策树模型,可用于分类、回归等任务[43].此外,模型对异常值不敏感,在样本和变量的随机化训练阶段表现出良好的性能.与其他机器学习方法相比,随机森林模型被广泛应用于微波土壤湿度产品降尺度[44].随机森林模型的主要思想是基于回归树建立输入变量与输出土壤湿度之间的非线性函数[45]:
SSMO=fRF(C)+ε,
(10)
C=(LST,Albedo,DEM,soiltexture,NDWI,CLDAS-SSM),
(11)
其中:SSMO表示训练阶段的实测土壤湿度值;C为输入向量,表示输入变量,包括地表温度(LST)、地表反照率(Albedo)、高程(DEM)、土壤质地(soil texture)、归一化差异水体指数(NDWI)和CLDAS土壤湿度(CLDAS-SSM);fRF是一个非线性函数,在输入变量和输出SSMO之间建立关系.
在本研究的回归任务中,首先在训练期间内建立若干棵决策树,每棵决策树由bootstrap样本建立,其中训练输入数据约占总样本的2/3,其余(1/3)的样本用于验证每棵树.为了进一步提高随机森林模型的泛化能力,通过对许多独立回归树的结果求算术平均来生成最终模型预测值,模型最终结果表示为
(12)
式中,p(SSMO|C)为最终预测结果,m是回归树的数量,Pi(SSMO|C)表示第i棵树的预测结果.
2.5 Stacking集成学习方法
集成学习的优势在于将多个基学习器的结果进行优化组合输出,以获得比任意基学习器更好的结果[46].集成学习主要包括并行化集成的Bagging、序列化集成的Boosting以及堆叠式集成的Stacking等.以Bagging和Boosting为代表的集成方法可以对训练效果差的样本赋以较高的权重进行二次学习,提高组合预测的泛化能力.然而该类方法只能集成同类决策树模型,难以融合其他模型的优势特性,不同算法间数据观测的差异性难以体现[47].Stacking是一种分层模型集成框架(图4),首先调用不同类型的学习器对数据集进行训练学习,将各学习器得到的训练结果组成一个新的训练样例,作为元学习器的输入,最终第2层模型中元学习器综合多个基学习器的输出特征,作出最后的决策[48].因此,Stacking增加了模型的准确性、鲁棒性和整体归纳能力.
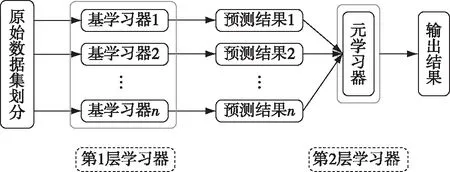
图4 Stacking集成学习结构示意Fig.4 Structure of Stacking ensemble learning
广义线性模型(Generalized Linear Models,GLM) 作为一般线性模型的扩展,基本思想是通过概率分布函数模拟非线性过程,它具有清晰的变量权重结构,能够模拟非线性的响应关系,模型不会出现明显的过拟合,对每个基学习器的效应产生清晰的认识[49].GLM模型主要通过连接函数,建立响应变量的数学期望值,及其与代表线性组合的预测变量间的关系.一个广义线性模型包括随机成分、系统成分和连接函数三部分:
(13)
ni=β0+β1xi1+β2xi2+…+βpxip,
(14)
E(Yi)=μi=g-1(ni).
(15)
随机成分即因变量的概率分布,其中a(φi),b(θi),c(yi,φi)为已知的函数;系统成分即自变量的线性组合.连接函数建立了随机成分与系统成分之间的特定关系.
本文基于Stacking集成学习的土壤湿度降尺度模型框架(图5),算法步骤如下:
1)输入原始数据集T,即包括CLDAS土壤湿度数据、与土壤湿度数据空间分辨率保持一致的陆表变量数据和站点数据,并按照3∶1的比例随机划分训练集T1和测试集T2,T=T1∪T2,T1∩T2=∅.
2)学习并生成新的数据集.第1层包含3种基学习器:梯度提升机、深度前馈神经网络和随机森林,采用K折交叉验证来训练第1层模型,3种模型扩展之后生成第2层训练集T′1.在基学习器模型进行K折交叉验证过程中,对测试集K次计算结果求平均,3种模型扩展后生成第2层测试集T′2.T′1和T′2构成新的数据集T′.
3)将得到的T′1用于训练第2层元学习器广义线性模型,并用T′2验证模型性能.训练得到最终土壤湿度降尺度模型.
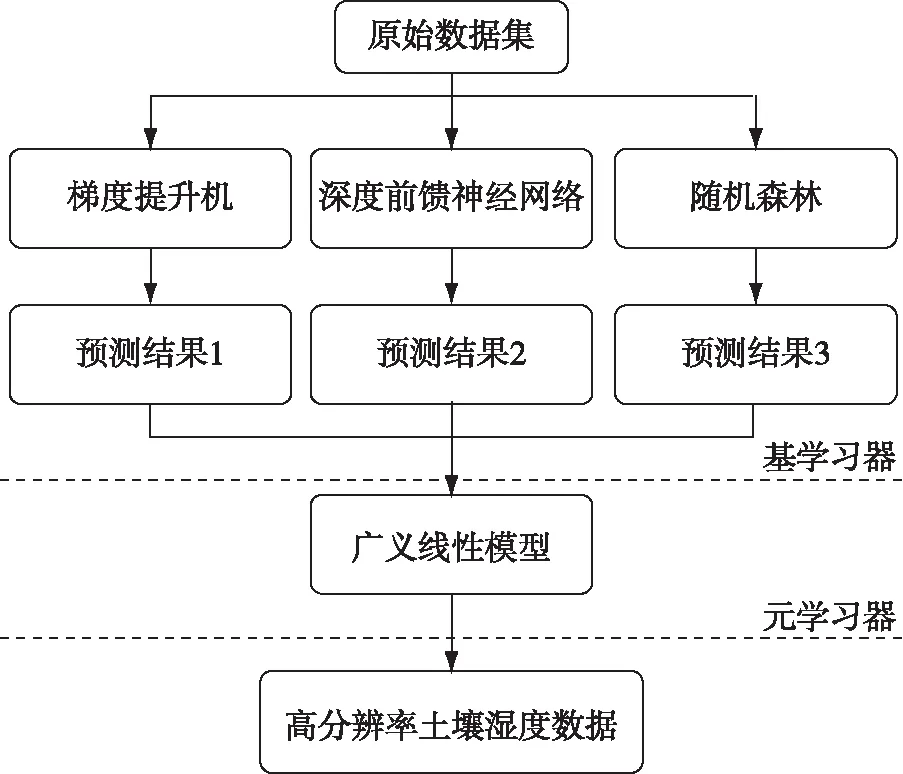
图5 Stacking集成学习方法土壤湿度降尺度结构示意Fig.5 Downscaling of soil moisture based on Stacking ensemble learning
2.6 评价指标
本研究采用相关系数(R)、偏差(Bias,其量值记为B)和均方根误差(RMSE)3个指标定量地分析原始CLDAS土壤湿度和降尺度土壤湿度,计算公式[50]如下:
(16)
(17)
(18)

精度评估过程中,采用双线性内插法,将CLDAS土壤湿度和不同方法降尺度结果内插到站点,然后与站点观测数据进行分析,计算相关系数、均方根误差和偏差.
采用决定系数(R2)和均方根误差(RMSE)对深度学习模型预测结果进行精度判定.均方根误差如式(18)所示,决定系数计算公式[51]如下:
(19)
3 结果与分析
3.1 深度前馈神经网络参数调优
研究使用决定系数R2和均方根误差RMSE来表征深度前馈神经网络的拟合效果.通过调整隐藏层层数L、神经元数量N和迭代次数epochs,得到模型训练集和测试集的决定系数R2和均方根误差RMSE.当模型包含过多参数时,为了避免模型结果过拟合,提高模型的泛化能力,有必要同时考虑训练集和测试集具有最高的决定系数和最低的均方根误差.结果表明(表2),固定神经元数量N=400,逐渐增加隐藏层层数L或迭代次数epochs时,总体上,训练集和测试集的决定系数逐渐增大,均方根误差逐渐降低.当隐藏层层数L=5,迭代次数epochs=600时,训练集和测试集的决定系数分别为0.936和0.830,均方根误差分别为0.018和0.030 1 m3/m3,此时再逐渐增加隐藏层层数L或迭代次数epochs,训练集和测试集的决定系数逐渐降低,均方根误差逐渐增大.因此,在本研究中最终选择以下数值作为模型的初始输入参数:隐藏层层数L=5,神经元数量N=400,迭代次数epochs=600.
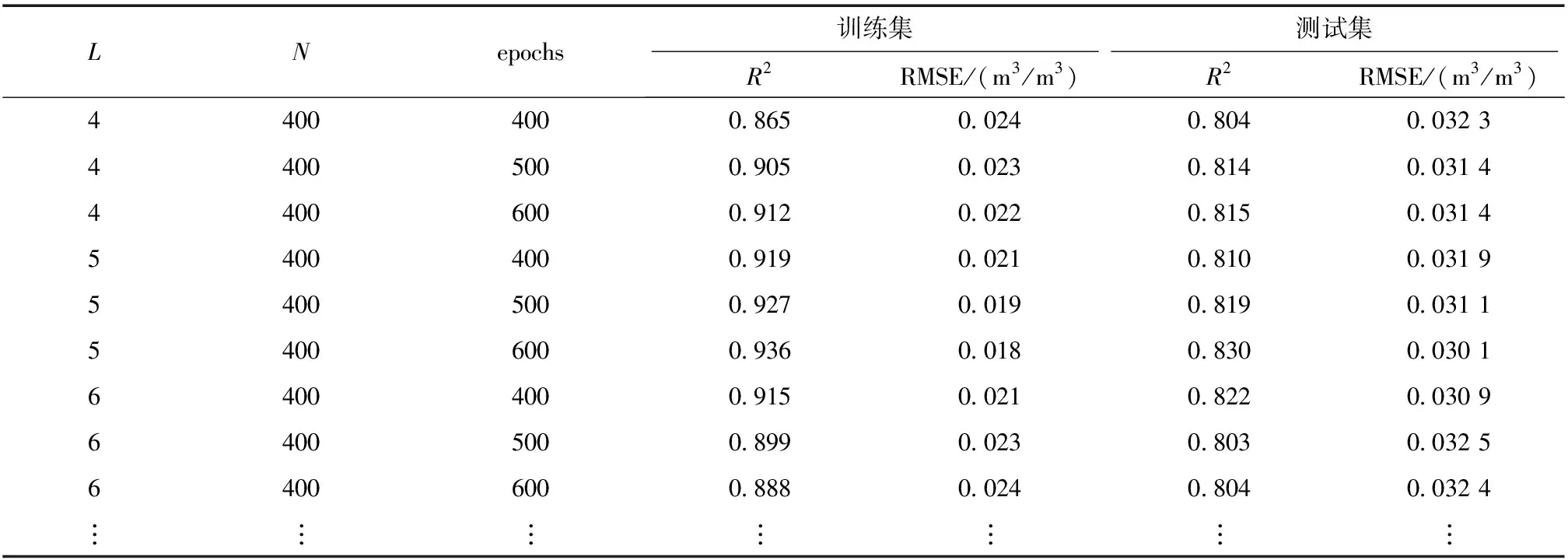
表2 模型参数调整结果
3.2 不同方法降尺度结果空间分布
为了比较不同方法降尺度效果,研究比较了梯度提升机(GBM)、深度前馈神经网络(DFNN)、随机森林(RF)和Stacking集成学习等4种方法,因土壤温度小于0 ℃时,观测仪器异常导致缺少可靠的观测数据,研究仅分析2019年4—10月的CLDAS土壤湿度产品降尺度效果.从降尺度结果和原土壤湿度日均值分布(图6)可以看出,总体上,华北地区的南部和沿海区域土壤湿度较高,中部和北部土壤湿度较低,平均土壤湿度均达到0.2 m3/m3以上,降尺度前后产品均较好地反映出此变化规律.但降尺度前土壤湿度日均值的平均值为0.226 m3/m3,降尺度后土壤湿度有所降低,日均值的平均值分别为:GBM(0.208 m3/m3)>DFNN (0.207 m3/m3)>RF(0.207 m3/m3)>Stacking (0.206 m3/m3).特别是华北地区的南部和沿海区域降尺度后降低明显,降尺度前土壤湿度日均值大于0.25 m3/m3,降尺度后介于0.2~0.3 m3/m3之间,并且降尺度后土壤湿度的空间分布细节更加丰富,这与降尺度过程中融合了对土壤湿度影响较大的高分辨率地表温度、地表反照率、地形等地表变量数据有关.
3.3 不同方法降尺度效果精度分析
利用站点观测数据逐日土壤湿度评估表明(图7和图8):不同降尺度方法预测的降尺度结果与站点观测土壤湿度之间存在显著的相关性,相关系数介于0.699 6~0.756 8,高于原土壤湿度的相关系数0.651 1;降尺度后均方根误差介于0.050 5~0.055 3 m3/m3之间,低于原土壤湿度均方根误差0.062 3 m3/m3;降尺度后偏差介于-0.008 1~-0.005 2 m3/m3之间,比原土壤湿度偏差0.023 9 m3/m3更接近于0,说明降尺度后土壤湿度精度得到提高,相比于原土壤湿度,降尺度结果更接近于实测值.
对比4种不同的降尺度方法结果的相关系数表明(图8),Stacking集成学习土壤湿度和RF土壤湿度相关系数较高,分别为0.756 8和0.740 2,其次为DFNN和GBM土壤湿度,分别为0.7155和0.699 6,且Stacking集成学习土壤湿度和RF土壤湿度均方根误差较低,分别为0.050 5 m3/m3和0.050 9 m3/m3,其次为GBM土壤湿度和DFNN土壤湿度,分别为0.055 3 m3/m3和0.055 4 m3/m3.4种不同降尺度方法结果偏差均在0以下,存在一定程度上的低估,但绝对偏差小于CLDAS产品,一定程度上改善了其高估现象,以Stacking集成学习方法低估程度最小,土壤湿度绝对偏差为0.005 2 m3/m3.因此,相对来说,Stacking集成学习方法优于其他3种方法,其相关系数最高,均方根误差和偏差相对较小,这与Stacking集成学习方法能够更好地挖掘出输入变量和土壤湿度的相关性,提升模型拟合效果有关.
3.4 不同方法降尺度结果时间序列及误差分析
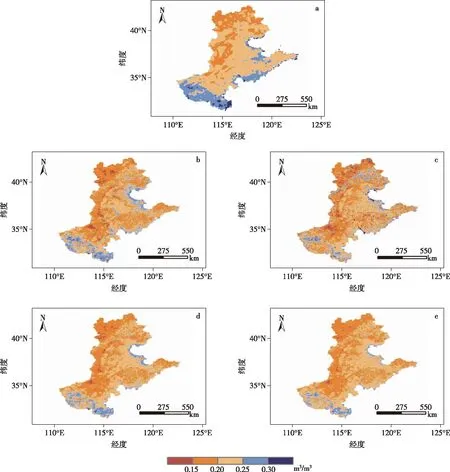
图6 不同方法结果土壤湿度日均值空间分布 a.CLDAS;b.GBM;c.DFNN;d.RF;e.Stacking集成学习Fig.6 Spatial distribution of original and downscaled daily average soil moisture a.CLDAS;b.GBM;c.DFNN;d.RF;e.Stacking ensemble learning
从不同方法降尺度结果0~10 cm土层土壤湿度时间序列来看(图9),4种降尺度方法的降尺度结果和原土壤湿度的变化趋势与观测值总体上相似,均能反映出土壤湿度随时间变化的规律,但大多数日次原土壤湿度存在高估现象,在整个时间段内,比观测值高0.013 7 m3/m3.4种降尺度结果则存在一定程度上的低估,尤其在91~98、180~190、200~210和240~270日次,但整体上降尺度结果和观测值的曲线更为接近.按其与观测值偏离程度大小依次为:GBM>DFNN>RF>Stacking集成学习方法,其中,Stacking集成学习土壤湿度比观测值低大约0.005 2 m3/m3,整体上,Stacking集成学习降尺度土壤湿度与观测值曲线趋势变化更相吻合,更接近站点观测数据.
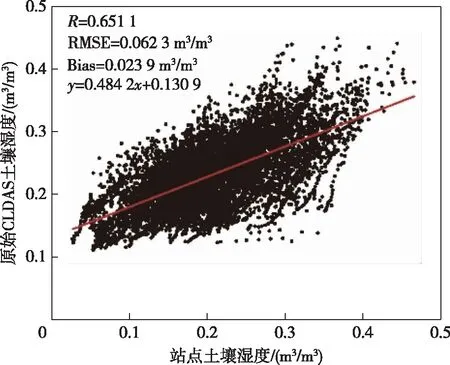
图7 CLDAS逐日土壤湿度精度站点评估散点图Fig.7 Scatter plot of CLDAS daily soil moisture and observations
从土壤湿度与观测值的相关系数和误差分析(图10)来看,与原土壤湿度相比,4种降尺度方法降尺度结果相关系数均有所提升,其中,Stacking集成学习土壤湿度相关系数提高较大,平均提高0.13,其次为RF土壤湿度,平均提高0.12.与原土壤湿度相比,4种不同降尺度方法降尺度结果的均方根误差均有明显的降低,其中,Stacking集成学习土壤湿度和RF土壤湿度比原土壤湿度的均方根误差,分别平均降低了0.012 1和0.011 7 m3/m3,更接近于观测值.4种方法降尺度结果的偏差绝大多数日次在0以下,即降尺度结果存在一定程度的低估现像.原土壤湿度偏差均值为0.023 9 m3/m3、GBM为-0.008 1 m3/m3、DFNN为-0.005 8 m3/m3、RF为-0.005 6 m3/m3、Stacking集成学习方法为-0.005 2 m3/m3,4种降尺度结果均改善了原土壤湿度的高估问题,其中,以Stacking集成学习方法最优.
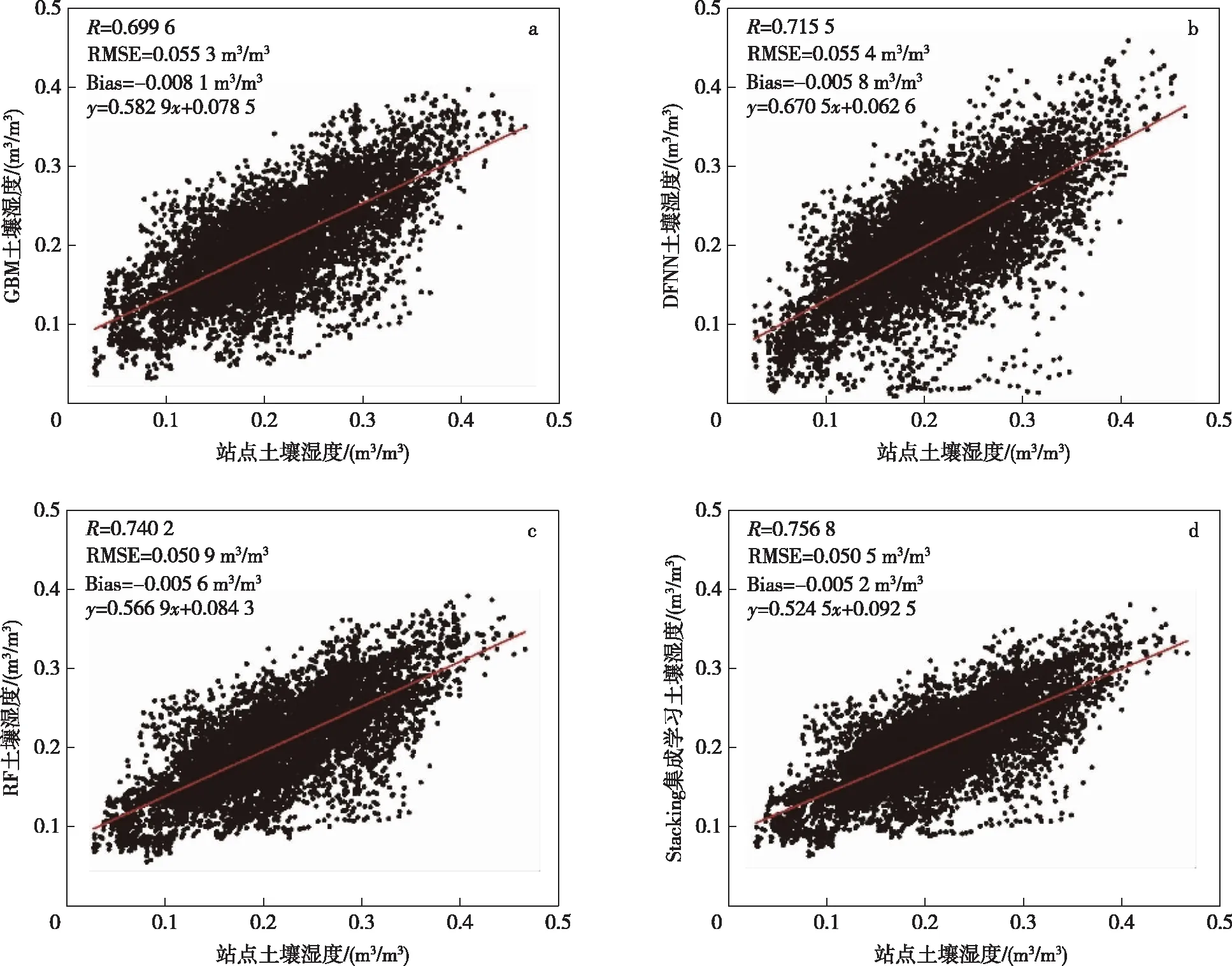
图8 不同方法降尺度结果站点精度评估散点图 a.GBM;b.DFNN;c.RF;d.Stacking集成学习Fig.8 Scatter plots of downscaled soil moistures and observations a.GBM;b.DFNN;c.RF;d.Stacking ensemble learning

图9 不同方法降尺度结果0~10 cm土层土壤湿度时间序列Fig.9 Time series of 0-10 cm soil moisture downscaled by different methods

图10 不同方法降尺度日均土壤湿度与观测值的相关系数与误差Fig.10 Correlation coefficients (up),RMSEs (middle),and biases (down) of downscaled daily average soil moistures compared with observations
表3为4种不同降尺度方法的降尺度结果与观测值在月尺度上的相关系数和误差.4种方法降尺度结果与观测值的相关系数达到0.45以上,其中,4月、6月、7月和8月相关系数较大,均达到0.7以上,9月较小,介于0.5~0.6之间,这可能与夏季降水频繁,土壤水分具有较强的空间异质性,增加了土壤湿度估算的不确定性有关.整体来看,平均相关系数均大于0.65,其中,Stacking集成学习方法最高.除9月外,4种方法降尺度结果与观测值在月尺度上的绝对偏差均小于0.01 m3/m3,其中,4月绝对偏差最小.在整个时间段内,除RF土壤湿度在4月偏差为正值,其余各月偏差均为负值,各月土壤湿度估算值均低于观测值.绝对偏差均值大小依次为:GBM>DFNN>RF>Stacking集成学习.4种方法降尺度结果与观测值在月尺度上的均方根误差介于0.043~0.067 m3/m3之间,其中,9月均方根误差较大,各方法降尺度结果的均方根误差均大于0.059 m3/m3,4月均方根误差较小,各方法降尺度结果的均方根误差介于0.043~0.050 m3/m3之间,以Stacking集成学习方法最小.因此,Stacking集成学习方法在月尺度上优于其他方法.
4 结论与讨论
研究以华北地区为例,以地表温度、地表反照率、土壤质地、高程、归一化差异水体指数以及站点数据作为建模数据,基于3种单一模型(梯度提升机、深度前馈神经网络和随机森林)以及多模型Stacking集成学习的方法,开展了中国气象局陆面数据同化系统(CLDAS-V2.0) 0~10 cm土层土壤湿度数据降尺度研究,使其空间分辨率从6 km降尺度至1 km,并以站点观测数据对降尺度结果进行精度分析,得到以下结论:

表3 不同方法降尺度月均土壤湿度与观测值的相关系数与误差
1)4种不同降尺度方法的降尺度结果和原土壤湿度在华北地区的空间分布具有相似规律,南部和沿海区域土壤湿度较高,中部和北部土壤湿度较低,平均土壤湿度均达到0.2 m3/m3以上.降尺度后土壤湿度日均值有所降低,特别是在华北地区的南部和沿海区域.
2)4种不同降尺度方法均有效提高了CLDAS土壤湿度产品的空间分辨率和精度,4种方法绝对偏差均小于CLDAS产品,一定程度上改善了高估现象.原土壤湿度与站点观测数据的相关系数、均方根误差和偏差分别为0.651 1、0.062 3 m3/m3和0.023 9 m3/m3,降尺度土壤湿度的精度高低依次是Stacking集成学习方法、随机森林、深度前馈神经网络、梯度提升机.Stacking集成学习降尺度方法估算精度最高,相关系数、均方根误差和偏差分别为0.756 8、0.050 5 m3/m3和-0.005 2 m3/m3,梯度提升机估算效果较差,相关系数、均方根误差和偏差分别为0.699 6、0.055 3 m3/m3和-0.008 1 m3/m3.
3)原土壤湿度和4种不同降尺度方法的降尺度结果均能较好地体现土壤湿度的日变化特征,但大多数日次原土壤湿度存在高估现象,4种降尺度结果存在一定程度上的低估.整体上,降尺度结果和观测值的曲线更为接近,其中,Stacking集成学习方法最优,与原土壤湿度相比,相关系数平均提高0.13,均方根误差平均降低0.012 1 m3/m3,偏差均值为-0.005 2 m3/m3.月尺度结果中,4种不同降尺度方法的降尺度结果在9月相关系数均较小,均方根误差和偏差较大,整体来看,与其他3种方法相比,Stacking集成学习土壤湿度在月尺度上相关系数较大,均方根误差和偏差较低,估算的土壤湿度精度较高.
本文利用梯度提升机、深度前馈神经网络、随机森林和Stacking集成学习方法,对CLDAS 0~10 cm土层土壤湿度产品开展了降尺度研究,使其空间分辨率从6 km降尺度至1 km,且精度有所提高.但本研究选取的土壤湿度数据时间范围为2019年4—10月,即春夏秋三季,未考虑冬季降尺度模型的土壤湿度估算表现,主要是因为当前土壤湿度测量仪器在土壤含有冰水混合物时,测量结果存在误差与不确定性,冬季的降尺度结果有待进一步研究.另外,与土壤湿度相关的降尺度因子数据的质量对建模效果有较大影响,高质量的数据会提高降尺度结果的精度.
