复杂抽样条件下应用不同方法估计EQ-5D量表的代答效应*
2022-01-19单得志张海悦张玉海谭志军
单得志 杨 柳 梁 英 张海悦 张玉海 尚 磊△ 谭志军△
【提 要】 目的 比较复杂抽样条件下不同倾向评分匹配法的EQ-5D代答效应估计效果。方法 基于2013年度陕西省卫生健康服务调查中EQ-5D量表的测量数据,构建单因素、多因素、复杂抽样分析及不同PSM法,对EQ-5D量表的5个维度、VAS及EQ-5D得分的代答效应进行估计,比较代答者相对于自答者在EQ-5D维度报告健康问题的优势比及VAS和EQ-5D得分的差异。结果 代答人群和自答人群在人口学特征、健康行为等方面存在较大差异。六种方法估计的维度代答效应(OR值)分别为:MO(1.470、1.611、1.732、1.573、1.606、1.533),SC(2.174、2.253、2.490、2.266、2.245、2.171),UA(1.819、1.916、2.050、1.864、1.897、1.777),PD(0.898、1.162、1.178、1.177、1.189、1.093),AS(1.135、1.379、1.377、1.480、1.468、1.372),EQ-5D VAS(0.666、-1.524、-1.298、-1.509、-1.550、-1.326),EQ-5D得分(-0.014、-0.023、-0.016、-0.023、-0.023、-0.017)。结论 代答者有将被代答者健康问题严重化的倾向。大样本调查中,只要混杂因素能够均衡,PS估计阶段是否考虑抽样权重不影响效应估计结果,但效应估计阶段需要考虑抽样权重。复杂抽样多因素分析需要考虑群效应,否则将低估抽样误差。
传统的倾向评分(propensity score,PS)法假设数据来源于完全随机样本[1]。复杂抽样调查(complex survey,CS)通常采用分层、整群、不等概率和多阶段等相结合的抽样设计方法,为PS法在复杂抽样调查数据中的应用带来了诸多挑战[2-3]。文献回顾显示,CS-PS法研究主要关注抽样权重和群效应两个因素的影响,即PS估计和效应估计两个阶段是否需要考虑和如何考虑权重以及群效应[4]。目前的研究并未在这两个问题上形成一致结论。前期,我们基于陕西省国家卫生服务调查数据,采用多因素回归和传统的倾向评分匹配法,发现代答(proxy response)会显著影响EQ-5D量表的报告结果[5-7]。由于陕西省国家卫生服务调查采用了复杂抽样设计,前期结果需要通过CS-PSM法进一步验证。为此,本文构建了3种倾向评分法分析策略和3种传统分析策略,通过比较不同倾向评分法和不同传统分析法的结果,为倾向评分法在复杂抽样调查数据中的应用提供参考。
材料与方法
1.数据来源
数据来源于2013年陕西省国家卫生服务调查(National Health Service Survey,NHSS),该调查采用分层、多阶段、整群、不等概率抽样方法,共抽取了32个样本县区、160个乡镇/街道、320个村/居委会、20702户,共57532名调查对象。经过缺失数据、不合格数据整理剔除12196名参与者后,本研究纳入45336例调查对象进行分析。
2.EQ-5D量表及转换
EQ-5D量表的内容见表1。为了便于分析,将EQ-5D量表中的各维度三水平结果转换为两水平结果。EQ-5D得分采用日本标准权重计算[8]。

表1 EQ-5D量表内容及重分类
3.混杂因素
调查表中包含13个混杂因素:是否为户主、年龄、性别、婚姻状况、文化程度、就业情况、吸烟情况、喝酒情况、体育锻炼情况、是否患慢性病、前两周患病情况、住院情况等。
4.统计分析方法
(1)抽样权重计算方法
观察个体的抽样概率π的倒数应该为该个体的抽样权重w,即w=1/π。陕西省第五次国家卫生服务调查个体的基础抽样权重可用公式计算:
wbase=w县区×w乡镇/街道|县区×w村/居委会|乡镇/街道×w户|村/居委会
上式中,w县区为县区的抽样权重,w乡镇/街道|县区为样本县区中乡镇/街道的权重,w村/居委会|乡镇/街道为样本乡镇/街道中村/居委会的抽样权重,w户|村/居委会为样本村/居委会中户的抽样权重[9]。
(2)分析方法
方法1:单因素回归分析法(SL法),以是否代答为自变量,以EQ-5D量表中的每个维度或EQ-5D VAS和EQ-5D Score为应变量,构建单因素效应分析模型。
方法2:多因素回归分析法(ML法),以EQ-5D量表中的每个维度或EQ-5D VAS和EQ-5D Score为应变量,以是否代答为自变量,是否为户主、年龄、性别、婚姻状况、文化程度、就业情况、吸烟情况、喝酒情况、体育锻炼情况、是否患慢性病、前两周患病情况、住院情况等13个混杂因素为协变量,构建logistic回归模型和一般线性模型。
方法3:复杂抽样多因素回归分析法(CS法),回归模型模型中的应变量、自变量和协变量与方法2相同,用SAS软件中的Surveylogistic过程和Surveyreg过程构建模型,模型中考虑抽样权重和群效应。
方法4、5、6为倾向评分匹配方法。方法4(PSM法)为传统倾向评分匹配法,PS计算采用多因素logistic回归模型,效应估计采用单因素logistic回归模型和一般线性模型。方法5(CS-PSM1法)的PS计算采用抽样权重加权的多因素logistic回归模型,效应估计方法与方法4相同。方法6(CS-PSM2)的PS计算采用抽样权重加权的多因素logistic回归模型,效应估计采用抽样权重加权的单因素logistic回归模型和线性回归模型。以上三种方法均采用应用最广泛的最邻近匹配法,综合考虑两组和样本量和匹配效率选择1∶2进行匹配,卡钳范围设置为0.2。
上述效应分析的模型中,均以代答标识变量为自变量且以“自答”为参照水平,logistic模型的OR值大于1、一般线性模型或回归模型的系数估计值小于0,表示代答会降低EQ-5D的报告结果,反之表示代答会提高EQ-5D的报告结果。
(3)均衡性评价方法
由于研究样本为大型观察性研究样本,运用标准化差异(standardized mean difference,SMD)比较倾向评分匹配前和两种倾向评分匹配后协变量在处理因素中的均衡性,按照文献标准,以SMD=0.1为界限,当SMD<0.1时,表明协变量在处理变量中均衡,否则表明不均衡[10]。
运用SAS 9.4 m5统计分析软件进行统计分析,并运用此软件执行Psmatch、logistic回归、Surveylogistic回归和Surveyreg回归等过程。
结 果
1.代答与自答人群特征
代答与自答人群的特征见表2。与自答人群相比,代答人群中的非户主、年轻、未婚、在校学生、较高文化程度的人群占比较高。此外,代答人群的健康行为明显比自答人群要好,表现为吸烟、饮酒的比例更低,而体育锻炼频率更高。同时,代答人群在健康状况方面表现较好,患慢性病、前两周患病和住院比例相对较低。

表2 自答和代答人群特征[n(%)]
2.自答与代答人群EQ-5D自报健康情况比较
在EQ-5D量表的五个维度中,代答人群在MO、SC、UA、AS等四个维度自报有健康问题的占比高于自答人群,EQ-5D VAS维度自报健康评分较高;而在PD维度中自报有疼痛的相对占比较低,EQ-5D Score得分也略低。
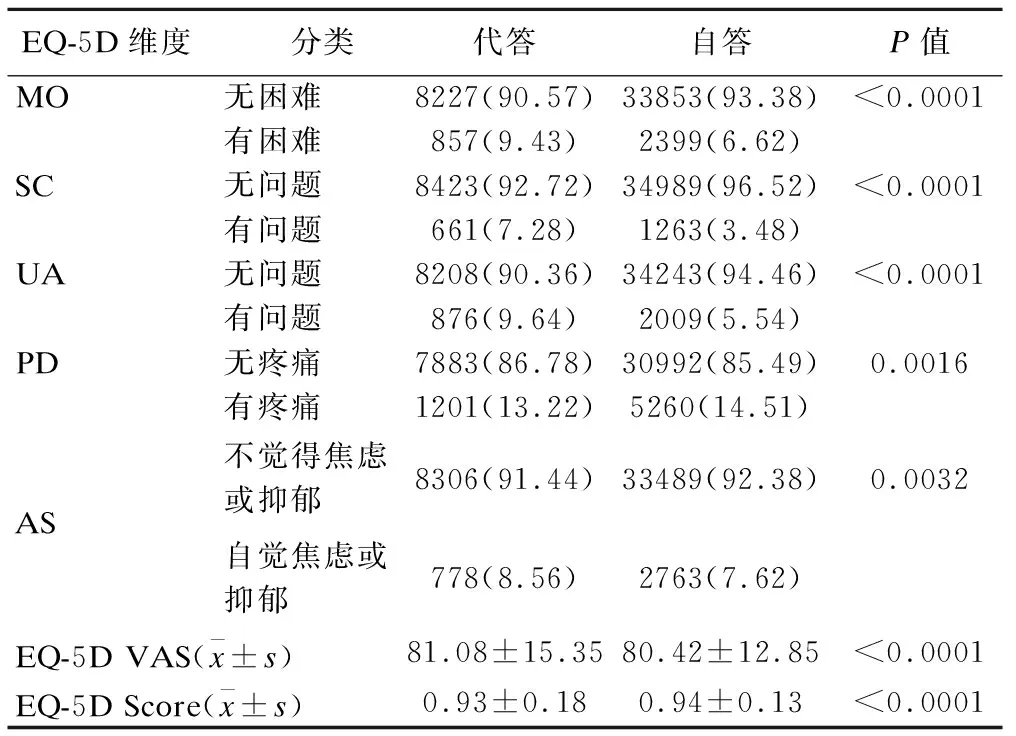
表3 EQ-5D自报指标在自答和代答人群中分布情况比较[n(%)]
3.两种倾向评分匹配的组间均衡性评价结果
表4显示,倾向评分匹配前,在是否为户主、婚姻情况中已婚、年龄中45岁~64岁阶段、就业情况中在校学生等方面SMD>0.1,表明在以上方面代答组与自答组不均衡,经过倾向评分匹配后,仅有婚姻状况中已婚情况的尚未得到均衡。在倾向评分过程中考虑抽样权重后,同样仅有婚姻状况中已婚情况尚未得到均衡。同时,在SMD>0.05的协变量中,经过倾向评分匹配后,均SMD<0.05。

表4 倾向评分匹配前、倾向评分匹配后、加权倾向评分匹配后均衡性比较
4.代答效应估计结果
图1和图2分别为6种方法得到的EQ-5D维度和评分的代答效应估计结果。单因素效应分析结果显示,EQ-5D各维度及评分的代答效应的方向并不一致。其他五种方法效应估计结果可以看出,代答效应分析结果在分类的五个维度中OR值均大于1,在EQ-5D VAS和EQ-5D SCORE中方向一致,点估计结果相似,但在可信区间范围中,CS方法的范围明显比其他方法更宽。而PSM法分析结果和CS-PSM1分析结果基本一致。
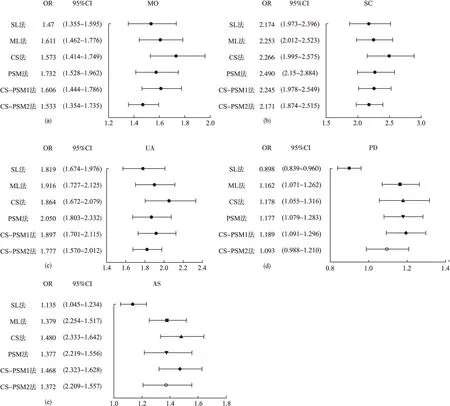
图1 EQ-5D五个分类维度OR值估计结果

图2 VAS、EQ-5D Score维度回归系数估计结果
讨 论
本研究结果显示,多因素方法和倾向评分匹配法较好地校正了混杂因素,同时考虑了复杂抽样特征,获得了较为准确的代答效应估计结果,发现代答者有将被代答者健康问题严重化的倾向。
1.不同倾向评分匹配方法的均衡性比较
不同的倾向评分匹配方法均能较好地均衡混杂因素。匹配前有4个协变量的SMD>0.1,6个协变量SMD在0.05~0.1之间,匹配后,4个SMD>0.1的协变量均衡了3个,剩余1个也接近0.1,而6个SMD>0.05的协变量SMD也降到0.05以下,其他混杂因素的SMD均有不同程度的下降。通过比较PSM和CS-PSM1匹配后各协变量的SMD,发现在倾向评分匹配过程中,是否考虑抽样权对均衡性的影响并不大。这与Lenis等研究者的研究结论一致[11]。
2.不同效应估计方法的代答效应比较
(1)单因素方法的代答效应估计不够准确。EQ-5D 的五个维度估计结果显示,PD与MO、SC、UA、AS的代答效应方向相反,VAS与EQ-5D得分的代答效应方向相反。这种内部的不一致性,反映出单因素方法未校正混杂因素、未考虑复杂抽样特征,估计结果存在较大偏倚,说明复杂抽样调查数据分析中,一方面需要校正较多的混杂因素,另一方面需要考虑复杂抽样特征,否则分析结果出现偏差的几率将会上升。
(2)倾向评分估计阶段是否纳入抽样权重,对效应估计结果的影响不大,但效应估计阶段不纳入抽样权重可能会导致很大的效应估计偏差[11]。PSM、CS-PSM1两种效应分析结果显示,两种效应分析法的代答效应点估计和回归系数并无太大差别,而CS-PSM1、CS-PSM2两种效应分析结果显示,两种效应的点估计和回归系数有差别,表明混杂因素的均衡并不意味着权重的均衡,权重纳入效应估计模型后提升了代答效应的估计精度。
(3)群效应影响效应估计的置信区间。CS法考虑了抽样权重和群效应,其效应估计值的95%置信区间明显要比其他方法宽,提示如采用复杂抽样多因素分析方法,应该考虑群效应,否则将低估模型参数的变异程度。本研究的匹配方法允许跨群匹配,匹配后群聚集的特征将会被打破,因此效应估计阶段无需考虑群效应。采用群内匹配的方法,并在效应估计阶段考虑群效应是否会增大模型参数的变异度,还有待进一步研究。
3.代答效应偏倚的意义及应对措施建议
国家卫生服务调查(NHSS)的代答率约为20%,如不考虑代答效应,分析结果可能存在较大的偏倚。对于如何控制代答效应产生偏倚,有以下两点建议:(1)严格代答机制的触发条件。在调查期间,如果受调查人员不满足代答条件,可以运用电子版调查表、调查app等手段完成调查任务。(2)统计分析方法控制偏倚。将是否代答作为混杂因素纳入分析模型,从而做到控制偏倚的效果[12]。
