基于条件变分自编码器的井下配电室巡检行为检测
2022-01-19党伟超史云龙白尚旺高改梅刘春霞
党伟超, 史云龙, 白尚旺, 高改梅, 刘春霞
(太原科技大学 计算机科学与技术学院, 山西 太原 030024)
0 引言
目前,采煤机械化程度越来越高,为了保障井下生产工作的正常运转和用电安全,煤矿通常都会制定井下配电室巡检制度。一般情况下,巡检制度要求巡检人员检查各仪表和信号装置是否指示正常;检查导线、设备开关、接触器和接线端有无过热及打火现象;检查设备的工作噪声有无明显变化,并对配电装置、仪表表面和室内环境进行清扫。由此可见,一套完整的巡检行为通常包含多个具体的巡检动作,这些具体巡检动作可分为站立检测、下蹲检测、来回走动、站立记录和坐下记录5类。但是,在实际巡检过程中,有时巡检人员并未按规定要求完成必要的巡检动作,这种行为会导致事故发生的概率大大增加[1]。当前大部分煤矿企业主要通过检查纸质记录及人工查看监控视频方式来监督巡检人员的工作,这类做法成本高、效率低。为此,有学者提出利用深度学习技术对井下配电室巡检行为进行识别。杨清翔等[2]采用区域建议网络生成井下行人候选区域,采用动态自适应池化方法对不同特点的池化域进行自适应池化操作,提高了网络训练和检测的速度。莫宏伟等[3]将OHEM(Online Hard Example Mining)算法和批量规范化算法与Faster R-CNN算法进行改进结合,可以有效识别出静态图像中存在的小样本特征。王琳等[4]结合PSPnet(金字塔场景解析网络)中的金字塔池化单元,引入充分的上下文信息,提出了井下行人检测网络YOLOv2_PPM,提升了井下行人检测的准确率。李伟山等[5]对RPN(区域候选网络)结构进行了改进,提出了一种“金字塔RPN”结构,并利用特征融合技术将底层特征和高层语义特征进行融合来共同实现目标的分类。李现国等[6]基于DenseNet网络和ResNet网络改进SSD(Single Shot MultiBox Detector)网络的基础网络和辅助网络,提出了一种井下视频行人检测方法。王勇[7]通过研究背景差分法原理,分析了基于混合高斯建模的背景构造原理,在诸多不确定性因素下,实现了序列视频的自适应背景构建。
综上可知,现有研究方法的重点在于视频动作的分类,并取得了较好效果。但在实际应用中,对于端到端的视频检测任务,不仅需要识别巡检动作的类别,还需要预测巡检动作发生的开始时间和结束时间。并且这类研究以监督学习的方式训练网络,监督学习需要标注视频的每一帧,存在数据集制作繁琐、训练时间较长等问题。因此,基于弱监督学习的动作定位问题也逐渐引起关注。目前,弱监督动作定位方法有2类:第1类是自上向下的方法,这类方法首先学习一个视频级别的分类器,然后通过检查产生的时间类激活映射(Temporal Class Activation Map,TCAM)[8]来获得特征帧的注意力。TCAM被用来生成自上而下的、类感知的注意力映射。Wang Limin等[9]使用注意力权重对动作进行定位,同时提出了弱监督行为识别和时序行为检测任务。K.K. Singh等[10]提出了一种在训练过程中随机隐藏部分帧的模型,该模型能够在剩余帧中学习区分度较低的动作特征。第2类是自下向上的方法,这类方法从原始数据中直接预测时间注意力,在视频分类任务中优化注意力,将注意力值高的部分视为动作部分,其他视为背景部分。Zhong Jiaxing等[11]提出了一种擦除模型,擦除部分视频片段后,可以更好地学习剩余视频中的特征。但上述方法均非常依赖视频分类模型,导致了在没有视频帧级别标注的条件下很难区分动作帧和背景帧。
在井下配电室场景中,监控视频视为由动作帧和背景帧组成。其中,动作帧为存在巡检动作的视频帧,背景帧为无人在配电室中巡检的视频帧。为了降低数据集的制作成本并准确地区分配电室监控视频中的动作帧和背景帧,本文提出了一种基于条件变分自编码器的巡检行为检测模型。该模型主要由判别注意力模型和生成注意力模型组成,利用判别注意力模型完成巡检行为的分类任务,对分类结果进行后处理,完成巡检行为的定位任务。为了提高定位任务的精度,加入基于条件变分自编码器的生成注意力模型,利用条件变分自编码器与解码器的生成对抗对视频的潜在特征进行学习。在公共数据集和自制的井下配电室数据集上进行测试,均取得了较为理想的结果。
1 巡检行为检测模型总体框架
由于不需视频帧级别的标签,弱监督学习方法通常是通过聚合所有相关视频帧的特征进行分类。视频中的背景帧和动作帧通常混杂在一起,背景帧很容易被识别为动作帧而影响检测精度。为了区分背景帧和动作帧,巡检行为检测模型需要捕获它们之间的潜在差异。因此,增加生成注意力模型来模拟基于注意力的视频特征,通过优化生成注意力模型来学习注意力。巡检行为检测模型总体框架如图1所示。
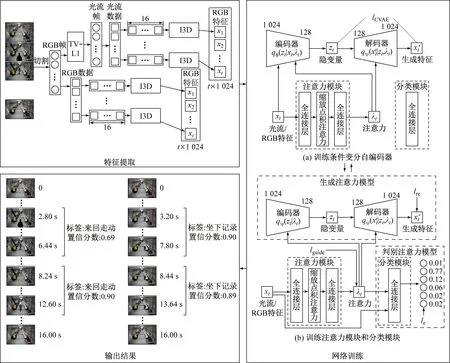
图1 巡检行为检测模型总体框架Fig.1 Overall framework of inspection behavior detection model
首先利用特征提取模型分别提取出井下配电室监控视频的RGB特征与光流特征。然后将获取到的RGB特征与光流特征输入注意力模块中进行训练,其中,RGB特征与光流特征分开训练。网络训练过程分为2个阶段交替进行:第1个阶段冻结注意力模块和分类模块,训练条件变分自编码器;第2个阶段冻结条件变分自编码器,训练注意力模块和分类模块。最后对判别注意力模型的输出进行后处理,最终输出视频中包含巡检动作的时间区间、动作标签及置信度,即完成了巡检动作的分类及定位。
2 巡检行为检测实现
2.1 特征提取
在完整的巡检监控视频中采样T帧视频为1个片段,将这个片段切割为RGB帧,并使用TV-L1算法将RGB帧转换为光流帧,再将光流帧转换为矩阵数据;将RGB和光流数据切分成若干不重叠的片段,每个片段为16帧。将这些片段输入经过Kinetics数据集预训练的I3D[12]网络进行特征提取,以获得每个片段的1 024维特征(图1)。在巡检行为检测模型训练过程中,RGB和光流特征将分开进行训练。
2.2 注意力模块
注意力模块用于提取特征帧的注意力,动作帧会得到更高的注意力得分,相反,背景帧的注意力得分较低。特征xt(xt为第t(t=1,2,…,T)帧的特征,且xt∈Rd,R为实数集,d为特征维度)输入注意力模块后,得到注意力λt(λt为第t帧的注意力)。注意力Attention的表达式为
(1)
式中:Q为查询值;K为键值;V为输出值;softmax为逻辑回归模型;dK为键值的维度。
巡检行为检测模型在注意力模块中引入了多头注意力机制[13]。多头注意力机制可以描述为将Q、K和V分别用不同的、经过训练的线性投影对dQ、dK和dV维进行线性投影h次,然后将它们拼接起来并再次投影,得到最后的结果。dQ为查询值的维度,dV为输出值的维度。多头注意力的表达式为
MultiHead(Q,K,V)=Concat(head1,
head2,…,headh)WO
(2)
(3)
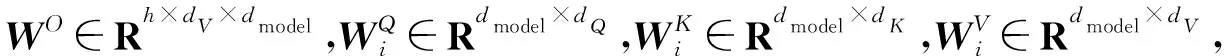
在特征提取过程中,特征xt作为注意力模块的输入,dQ、dK、dV与xt的维度相同,输出为特征的对应权重。通过式(1)—式(3)可计算得到特征对应的注意力。
2.3 判别注意力模型
判别注意力模型主要完成巡检动作分类任务。分类模块是判别注意力模型的主要组成部分。判别注意力模型将注意力λt作为权重,连同视频特征xt一起输入分类模块,产生视频的前景特征xfg∈Rd:
(4)
使用1-λt作为权重来计算视频的背景特征xbg∈Rd:
(5)
分类模块利用前景和背景特征训练网络,输出为该特征对应每一分类的分数,即为特征的软分类。在训练判别注意力模型期间,同时优化注意力模块和分类模块。
2.4 生成注意力模型
(6)
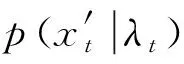

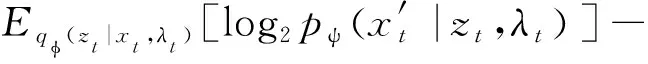
KL(qφ(zt|xt,λt)‖pψ(zt|λt))
(7)

2.5 损失函数及优化
巡检行为检测模型包含条件变分自编码器、分类模块、解码器、注意力4个模块,为了使各个模块在训练中优化网络参数,从而提升巡检行为检测的准确率,下面分别定义各自的损失函数。
定义条件变分自编码器损失函数lCVAE为

KL(qφ(zt|xt,λt)‖pψ(zt|λt))≈
KL(qφ(zt|xt,λt)‖pψ(zt|λt))
(8)
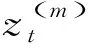
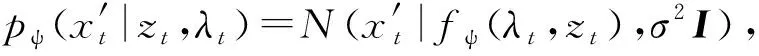

(log2Σφ)(m)-1]
(9)

定义分类模块损失函数le为
(10)
式中:lfg为前景损失函数;α为平衡前景损失值和背景损失值的超参数;lbg为背景损失函数;pθ为分类网络,该网络由一个全连接层和softmax层构成;y为标签。
定义解码器损失函数lre为
(11)
TCAM是某时间步上特定类的激活映射,可以为特征帧标记指定动作的注意力,确保输出的时间区间与目标动作相对应。给定一个带有标签y的视频,TCAM可表示为
(12)
(13)

(14)
在模型每一轮迭代训练中,先最小化lCVAE,然后最小化损失函数l:
l=le+γ1lre+γ2lguide
(15)
式中γ1和γ2分别为平衡解码器损失值和注意力模块损失值的超参数。
2.6 输出结果
对分类模块输出的软分类值进行后处理,完成定位任务。将分类分数高于阈值的分类均视为该部分可能的动作类别,并为每一个动作类别生成对应的时间区间([time_start,time_end])和动作分类置信度(confidence)。其中,[time_start,time_end]为动作发生的开始时间和结束时间,单位为s;confidence为动作分类置信度。输出结果如图1所示。
在后处理过程中,为了更精准地完成动作定位任务,使用注意力区分背景帧和动作帧,使用TCAM区分出包含特定动作类别的帧,两者相乘得到加权TCAM。过滤掉加权TCAM低于阈值的部分,将剩下部分在整段特征中的位置索引用于动作定位。池化检测出的每一个时间区间的加权TCAM,以得到置信度。
3 实验分析
3.1 巡检行为数据集
实验中所使用的数据集全部取自于井下配电室监控视频,并剪裁出其中包含清晰巡检动作的片段共174个,这些片段涵盖了站立检测、下蹲检测、来回走动、站立记录和坐下记录5种动作类别,如图2所示。



(e) 坐下记录图2 巡检动作分类Fig.2 Inspection action classification
在这些动作片段中,挑出76个动作片段作为训练集,另外的98个动作片段作为测试集,其中每一个动作片段时长大约为8 s,并且只包含一个动作类别。
3.2 评价指标
实验遵循THUMOS14数据集[15]给出的标准评估方案,记录了在不同的交并比(IoU)阈值下的平均精度均值(mAP)。其中,当IoU为0.5时得到的mAP最具代表性,记为mAP@0.5。同时为了分析分类性能,记录了检测出正确动作类别的数量占对应动作真值数量的百分比。最终结果为5次以上运行结果的平均值。
3.3 实验环境与参数设置
巡检行为检测模型是在PyTorch环境、单个NVIDIA GeForce GTX 1060 GPU上进行样本训练,使用Adam优化器,学习率为0.001,每批数据量大小为32,每10次迭代测试一次。实验中,设置α为0.03,β为0.1,γ1在RGB流中设置为0.5,在光流中设置为0.3,γ2设置为0.1,隐变量z的维度为128,r设置为1,σ设置为1。后处理中,RGB阈值设置为0.03,光流阈值设置为0.08。
在注意力模块中,头的数量h为4,丢弃率dropout为0.1,输入为1 024维的特征,输出为特征对应的注意力。注意力模块包括缩放点积注意力层和1个全连接层。在分类模块中,输入为1 024维的带权特征,输出为该特征对应的6个分类的得分。分类模块由1个全连接层构成。编码器输入为1 024维的特征和其对应的注意力,输出为128维的隐变量z。编码器模块包括3个全连接层,各层节点数依次为128、128和256。解码器输入为128维的隐变量z和特征的注意力,输出为1 024维的重构特征。解码器模块包括3个全连接层,各层节点数依次为128、128和1 024。
3.4 THUMOS14数据集上的实验
为了更好地评估巡检行为检测模型性能,在THUMOS14数据集和自制的巡检行为数据集上进行了实验。在训练期间,训练集只提供每个视频的分类标签。
在THUMOS14数据集中,视频被分为20类动作。按照惯例,选取200个视频作为训练集,212个视频作为测试集。每一个视频平均包含15.5个动作片段,每个动作实例为几秒到几分钟不等的片段。
在THUMOS14数据集上进行了实验,不同弱监督动作定位模型在THUMOS14数据集上的检测结果对比见表1。

表1 不同模型在THUMOS14数据集上的检测结果Table 1 Detection results of different models on the THUMOS14 dataset %
从表1可看出,Hide-and-Seek模型[10]的mAP@0.5为6.8%,这是由于在训练过程中隐藏了区分度较高的帧,导致检测效果不佳;UntrimmedNet模型[9]的mAP@0.5为13.7%,这是由于在检测时动作边界的动作帧与背景帧存在混淆,导致定位效果不佳;SEOC模型[11]的mAP@0.5为15.9%,这是由于对包含多个不同动作的视频分类不准确,导致检测效果不佳;本文模型的mAP@0.5达到17.0%,优于其他几种模型,这表明本文模型相比其他几种模型可做出更准确的预测。
3.5 巡检行为数据集上的实验
由于可获得的配电室监控视频有限,导致自制的巡检行为数据集的数据量较小。所以,采用迁移学习的方法,将经过THUMOS14数据集训练后的模型参数迁移到自制的巡检行为数据集上继续训练。在巡检行为数据集上的动作检测率见表2,由表2可看出,下蹲检测动作的分类准确率并不高,这是由于下蹲检测动作与坐下记录动作极为相似,部分下蹲检测动作被识别为坐下记录动作,从而导致了这2个动作的混淆。

表2 本文模型在巡检行为数据集上的动作检测率Table 2 The action detection rate of this model on the inspection behavior dataset
本文模型在巡检行为数据集上的结果见表3, 对比表3和表1可看出,在自制的巡检行为数据集上的预测结果比在THUMOS14数据集上更加准确。这是由于在井下配电室监控视频中,场景较为固定,巡检动作分类较少,使得模型检测结果更佳。这也同时说明了本文模型更适用于井下配电室巡检行为检测场景。

表3 本文模型在巡检行为数据集上的检测结果Table 3 Detection results of this model on the inspection behavior dataset
3.6 模型在井下配电室场景中的应用
将训练完成的参数输入到巡检行为检测模型,对井下配电室监控视频进行动作分类及定位。输入一段井下配电室监控视频,模型将对这段监控视频进行动作分类与定位,同时生成动作检测文件,其中包含动作发生的时间区间、类别及置信度。依据动作检测文件将视频进度(time)、当前动作类别(label)和置信度(score)标记在监控视频左上方作为最终检测结果输出,如图3所示,视频总长度为130 s,当前视频播放进度为14.88 s,巡检人员正在执行下蹲检测,置信度为0.88,表示模型认为在当前视频帧中最可能存在下蹲检测动作,且存在的概率为88%,证明了巡检行为检测模型在实际场景中的有效性。

图3 检测结果Fig.3 Detection results
4 结论
(1) 基于条件变分自编码器的巡检行为检测模型由判别注意力模型和生成注意力模型组成,利用判别注意力模型完成巡检行为的分类任务,对分类结果进行后处理,完成巡检行为的定位任务。利用加入基于条件变分自编码器的生成注意力模型对视频的潜在特征进行学习,以提高定位任务的精度。该模型提高了巡检工作效率,降低了训练成本。
(2) 为了尽可能地捕捉视频特征间的微小差异,利用条件变分自编码器来构造基于不同注意力时不同特征的分布,解决了弱监督动作定位中动作帧和背景帧易混淆的问题,具有较高的检测精度,在THUMOS14数据集上,mAP@0.5达到了17.0%,并将模型参数迁移到自制的巡检行为数据集上继续训练,在自制的巡检行为数据集上mAP@0.5达到了24.0%,满足了井下配电室巡检行为检测精度要求。
(3) 实验结果表明,检测精度还存在很大的提升空间,在接下来的工作中,可通过扩充行为检测数据集的样本数量和类型,以得到更高的检测精度,或通过优化网络结构提高模型的泛化能力。
