基于YOLOv5网络的气田无人值守场站多路入侵目标检测
2022-01-18左应祥倪建辉杨圆鉴韩光谱
左应祥 倪建辉 杨圆鉴 韩光谱 彭 聪
(1. 中国石油西南油气田分公司 重庆气矿, 重庆 400021; 2. 重庆科技学院 安全工程学院(应急管理学院), 重庆 401331)
0 前 言
当前,人工监控预警模式效率低下、实时性较差的问题日渐突出,智能化监控模式成为新的应用研究方向。采用智能化监控模式,可以实时检测并识别入侵目标,提取其外观特征,跟踪其运动轨迹,并及时预警。入侵目标检测是智能化监控的核心技术,经过多年发展其算法也在不断成熟,传统的算法有光流法、粒子滤波和均值漂移等。Lucas 等人对光流法进行了改进[1],通过对比相邻帧的特征点得到运动目标的光流矢量,进而获取该目标在当前帧下的位置坐标。粒子滤波算法是通过粒子集来表示概率,Andrew等人将该算法应用于目标跟踪领域[2-3]。他们提取了目标特征,根据高斯分布规律进行粒子采样,将采集到的样本与提取到的目标特征进行匹配,从中选取相似度最高者作为预测结果。均值漂移法最早由Fukunaga 等人应用于 Hosterler数据分类上[4],之后在目标跟踪领域也有所表现[5]。该算法是以概率分布理论为基础,利用颜色直方图进行识别,经过多次迭代后获得目标位置的概率分布,目标位置的概率最大。
随着入侵目标检测应用的普及,传统算法的不足逐渐显现出来。其中,光流法的计算耗时较长,无法满足运动目标检测中的实时性需求[6]。粒子滤波算法仅利用颜色直方图进行图像识别,当图像背景与检测目标本身颜色相似时,则极有可能跟踪失败[7]。均值漂移法虽具有识别速度快、鲁棒性好等优点,但其空间信息描述不足,同样会面临目标与背景颜色相似等问题,存在一定的局限性[8]。
当前常用的一种入侵检测思路是,通过卷积神经网络实现入侵目标的外观特征提取[9],基于滤波算法实现入侵目标的运动特征提取[10]。基于相关滤波算法提取运动特征,提取效果和鲁棒性较出色,但无法描述入侵目标的外观特征,因此需要配合卷积神经网络进行外观特征提取[11]。而在多种卷积神经网络中,YOLO网络因其较高的精度和较快的检测速度而得以广泛应用[12]。
本次研究将针对当前气田无人值守场站的监控问题,讨论基于YOLOv5网络的入侵目标检测方法[13],采用Deep SORT算法对检测到的入侵目标进行跟踪[14]。为解决卷积神经网络对于显存资源消耗较大而无法满足多路摄像头同时检测的问题,在此采用拼接画面的方式进行检测,使用单一摄像头资源进行多路摄像头并行检测。
1 多目标入侵检测方法
1.1 入侵检测流程
入侵检测的基本流程包括:采用拼接画面的方式实现多个摄像头同时检测;通过YOLOv5网络实现人体检测;应用Deep SORT算法对检测到的人体进行跟踪,判断目标是否进入危险区域。入侵检测整体设计流程如图1所示。
1.2 YOLOv5模型
进行入侵检测,首先需要实现对入侵目标的识别。在此,采用卷积神经网络中的YOLOv5模型。经过多次版本迭代,该模型比一些经典的神经网络模型(如AlexNet、SSD等)在精度上有了巨大提升;而且,可同时对多个区域进行检测,相比其他采用滑动检测框的单一检测方法其检测速度也更具优势。
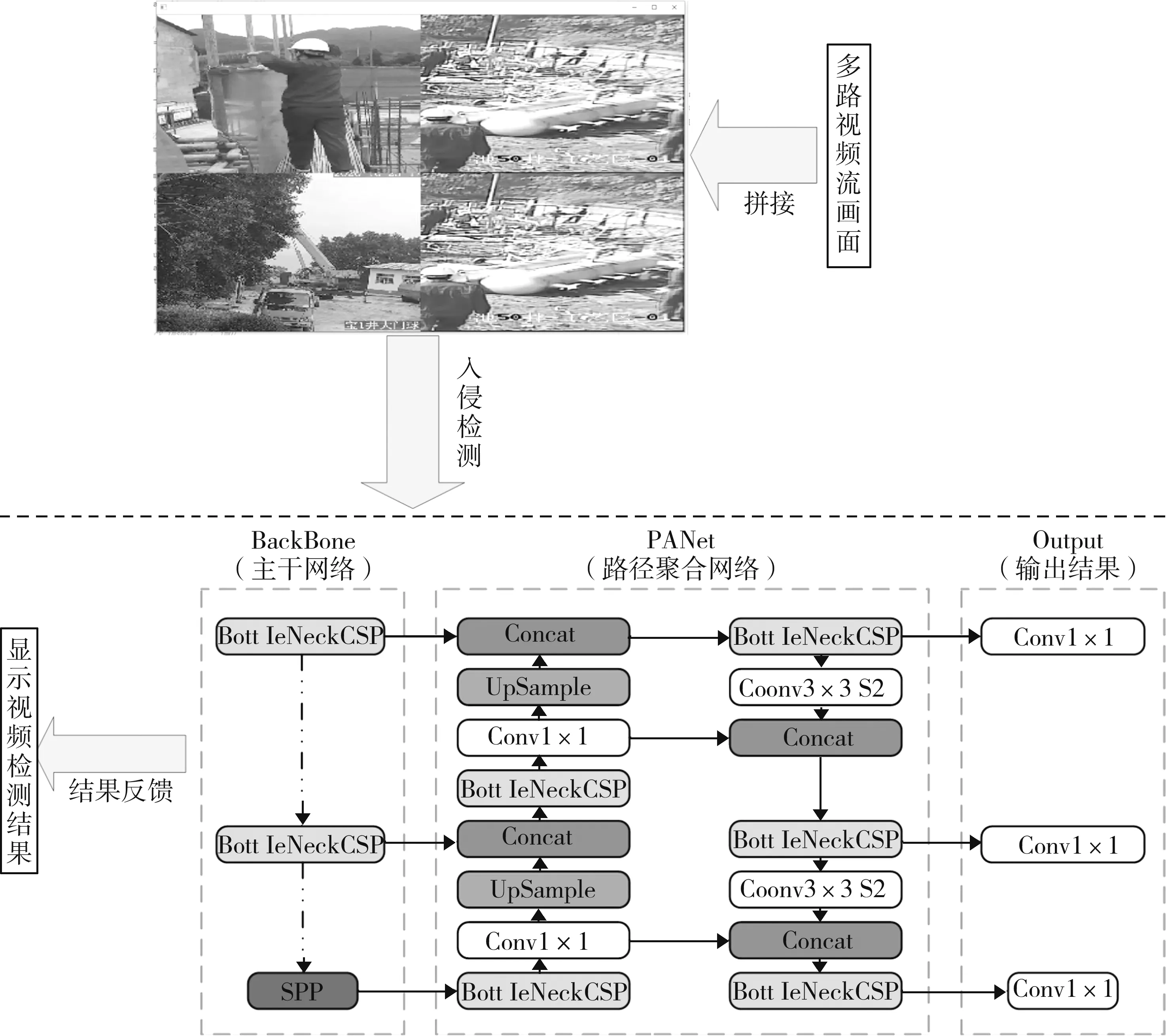
图1 入侵检测整体设计流程
YOLOv5网络架构如图2所示[15]。其中,在图像特征提取部分,边缘提取方法及纹理、颜色等潜层特征与其他网络相类似,因此这一部分借鉴了VGG网络、深度残差网络等模型。在特征增强部分,参考了FPN、PANet等模型。在检测头部分,通过反卷积层对其进行反卷积操作从而得到检测框,实现结果输出。
1.3 多目标跟踪算法
在入侵检测中,既要实现对入侵目标的识别,也要实现对检测目标的实时跟踪。采用传统算法,跟踪效果易受光线强弱、背景颜色变化等因素的影响,效果不佳。在此采取滤波与深度学习相结合的方法,用Deep SORT算法实现多目标跟踪。在当前帧检测到目标时,随即在下一帧根据当前目标所在位置对其进行预测,并按照合适的匹配策略对预测框的归属进行分配,从而实现目标跟踪。
对于通过卡尔曼滤波得到的预测状态与当前检测到的状态评价匹配问题,引入马氏距离进行评价[9]:
(1)
式中:d(1)(i,j) —— 第j个检测框和第i个轨迹间的匹配度;
Si—— 由卡尔曼滤波预测得到的空间协方差矩阵;
yi—— 当前预测状态;
dj—— 第j个检测框的状态。
马氏距离应用于简单场景的检测效果较好。但现实场景中目标运动的不确定性较高,因此又引入最小余弦距离进行评价[9]:
(2)
式中:rj、rk—— 表面特征描述量;
Ri—— 第i个轨迹中特征描述的集合。
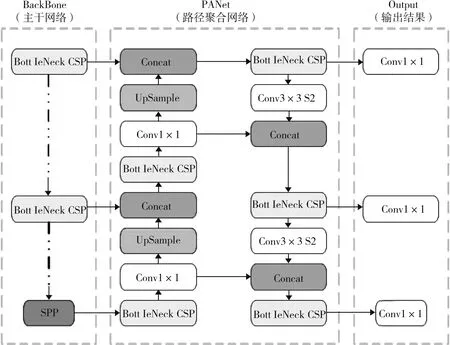
图2 YOLOv5网络架构
1.4 危险区域及多路摄像头实时监控
在实际生产当中,某些特定区域具有一定的危险性,严格禁止无关人员进入。如在实地考察中发现,重庆气矿张家站某些区域硫化物含量极高,禁止非工作人员进入。经沟通后,最终由气矿安全部门通过监控画面标定危险区域。当目标进入上述危险区域时,监控系统随即发出警报。
深度学习的优势在于能够获得极高的精度。但在一般情况下,准确有效的特征提取结果才能保证获取高精度的图像。本次研究中所用的摄像头为萤石云C6,显卡为nVidia公司的RTX 3070,单个摄像头会占用1.5~2 GiB的显存。该显卡的显存容量为8 GiB,即使采用多线程并行检测的方式实现多路摄像头监控,最多也只能满足4个摄像头的实时运行需求,这与硬件投入的成本不相匹配。因此,需要寻求一种新的方法,在节约显存资源的情况下采用多个摄像头实现实时入侵检测。
我们采用图像拼接的方式,仅利用单一摄像头的显存资源实现多个摄像头实时检测,在YOLOv5网络中检测模型会自动将图像调整为适合检测的尺寸。因此,通过OpenCV技术获取每一个摄像头当前时刻下的画面时,可以将所有图像调整尺寸后以矩阵相加的形式拼接成一张图像,然后送入模型中完成检测,以节约显存资源。
2 模型训练
2.1 数据集制作
采用OTB100及气矿监控视频集成的自建数据集,样本数共计500个,详情见表1。图3所示为自建数据集部分图像。
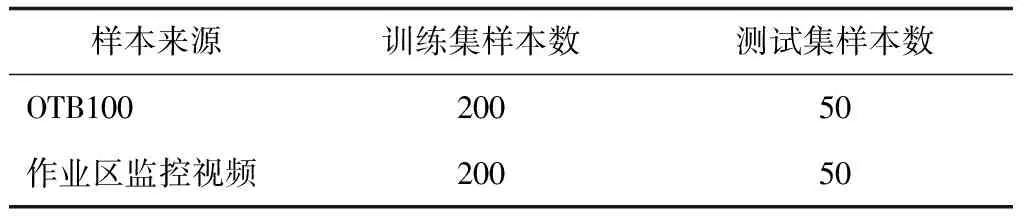
表1 数据集样本来源及数量
2.2 训练过程
从自建数据中选取75%组成训练集,将剩余的25%组成测试集,在训练过程中应用自适应学习率进行训练。YOLOv5网络本身的预训练权重用于人体检测效果较好,因此选择在预训练权重的基础上进行迁移学习,使用此次构建的数据集对网络进行训练。其间,共进行300轮次训练,达到了较为出色的训练效果。图4所示为训练效果曲线。

图3 自建数据集部分图像
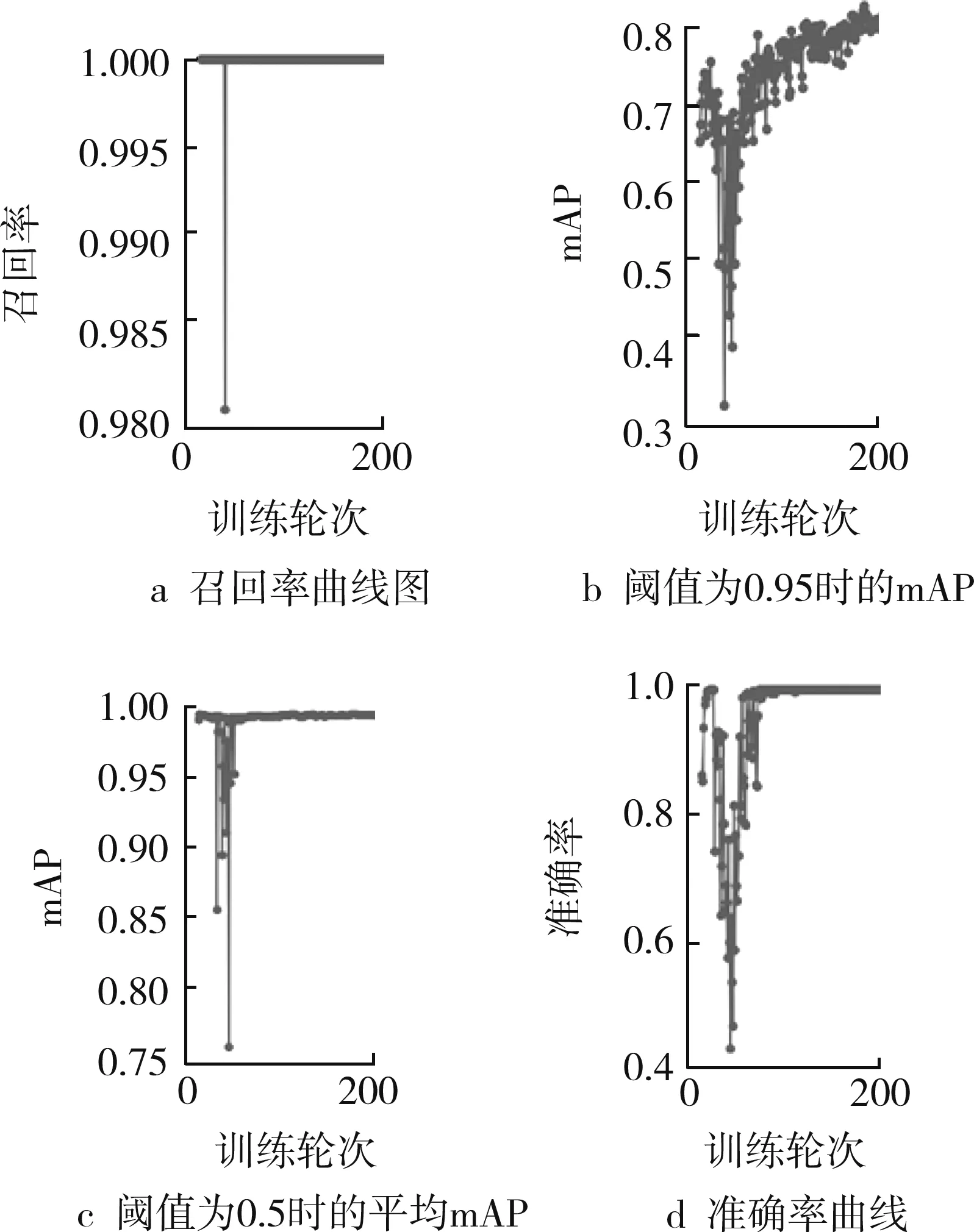
图4 训练效果曲线
从训练效果图可以看出,在第50轮次左右精度开始上升,在200轮次精度趋于稳定,最终精度达到95%。
3 实际训练效果分析
应用本次研究的入侵目标检测方法,以重庆气矿大竹采输气作业区实际监控为例进行了测试。图5所示为部分测试图像的效果。
可以看出,入侵目标识别的实际训练效果达到了预期要求。在针对人体的目标识别结果中,没有出现误报、漏报的情况,达到mAP值95%的训练要求。同时,在识别光线明暗层次变化比较明显的场景时,也具有极强的鲁棒性,能够满足实际需求。
4 结 语
本次研究基于YOLOv5网络构建模型,预训练权重,增添自建数据集,并从该数据集中提取数据用作迁移学习的训练样本。应用此模型在气田作业区场景下进行样本训练,获取了良好的训练效果。通过多个摄像头获取图像,经拼接后对其进行检测,并对网络模型进行资源分配;最后,仅利用单一摄像头的显存资源,实现多路摄像头入侵检测。训练结果表明,该模型在气田作业区的误报率和漏报率均符合使用标准,且在复杂环境下具有良好的鲁棒性。
