基于YOLOv5的毫米波图像目标检测方法研究
2022-01-18张格菲李春宇刘金坤屈音璇
张格菲 李春宇 刘金坤 屈音璇
(中国人民公安大学侦查学院,北京 100038)
1 引 言
近年来,随着暴力恐怖事件的增多,安全问题越来越引起人们的关注。爆炸案是最严重的暴力犯罪,社会危害大,关注度高。爆炸带给人们的不仅仅是经济损失、生命威胁,同时也危及到国家和社会的稳定性[2]。为防范恐怖爆炸犯罪,需要对机场、港口、海关、车站等重点场所进行全天候安全检查和监控,严防爆炸物、易燃物品带入车辆或混入重点场所。传统上,违禁物品主要包括枪支、金属刀具和爆炸物。但是,随着科学技术的发展,陶瓷刀具、塑料炸药、化学制剂等新型违禁物品不断涌现,给违禁物品的检测带来新挑战。
检测待测目标的传统方法[3-7]是采用特征分类器来完成图像中的目标检测。但是,这种传统的物品检测方式存在一定的缺陷,即泛化能力较差。目标检测算法的性能往往受图像背景的复杂程度影响。图像背景越简单,目标检测的效率也就越高,检测性能越好。相反,一旦图像背景变得复杂,目标检测的效率以及性能都会随之下降。为了解决上述缺陷,有学者在深度学习技术的基础上研发出了卷积神经网络CNN(Convolutional Neural Network)[8]。卷积神经网络不但能够完成特征提取,并且具有较好的鲁棒性以及较强的表达特征性能,不管是简单环境还是复杂环境,都能精准定位到检测目标。随着检测技术的不断发展[9],R-CNN(Region-CNN)算法成功将深度学习应用到目标检测领域中,并带动了卷积神经网络的发展[10],卷积神经网络通过不断的深化和研发,相继发展出Fast R-CNN[11]技术,以及其优化算法Faster R-CNN[12]技术。Faster R-CNN设计出RPN(Region Proposal Networks)区域生成网络,替代了R-CNN中的选择性搜索方法用于实现端到端的模型训练。借鉴Faster R-CNN的技术思想,进一步推导出YOLO(You Only Look Once)[13]、SSD(Single Shot MultiBox Detector)[14]、R-FCN(Region-based Fully Convolutional Networks)[15]等一系列目标检测方法[16]。YOLO创造性的提出了one-stage,也就是将物体分类和物体定位在一个步骤中完成,完全能够满足实时性要求。SSD提取不同尺度的特征图来做检测,采用不同尺度和长宽比的先验框,在准确度和速度上都有极大的的提升。相比传统金属安检门,毫米波人体安检系统在使用中不会对人体造成伤害,且毫米波成像不受衣物影响,能够获取人体形状特征以及藏匿于服饰下的危险物品,因而毫米波人体安检系统逐渐得到广泛运用。有鉴于此,基于深度学习和YOLO系列的研究成果,本文要解决的关键问题是如何保证携带不同刀具的毫米波图像能够正确识别和检测,降低复杂环境下的误检和漏检率,提高检测和识别的准确性。本文采用YOLOv5目标检测算法对可携带刀具的毫米波图像进行检测,并改进了YOLOv5算法,以提高YOLOv5的检测精度。
2 毫米波成像与算法简介
2.1 毫米波成像原理
毫米波收发机在扫描平面上上下扫描,扫描的频率范围从28GHz到33GHz,覆盖介于两者之间的64个频率点。将收发器在某一时刻的位置记录为(a,b,Z),此时的频率为ω,光速常数为c,波数为k=ω/c,目标物体在位置(x,y,Z)处的反射系数记为f(x,y,Z),通过将整个目标视场的像素点积分,获得电磁场数据为
(1)
推导反射系数f(x,y,Z),以重建物体的图像
(2)
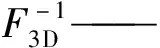
传统的目标检测算法主要是针对光学图像数据库,应用基于图像特征的图像分割方法,这种方法误检率高,易受到人体姿态的干扰。而毫米波成像技术在新兴的安检应用中,虽然在标准数据库的建立与目标检测算法的应用尚处在起步阶段,但在安全性、隐蔽性和实时性等方面表现突出,尤其在人体安全检查领域有着良好的应用前景。因此研究符合此应用场景的目标检测算法并提升相应的检测速度与检测准确率具有重要的应用意义和很高的应用价值。
2.2 YOLOv5网络模型
YOLOv5网络模型具有深度、宽度两个结构参数,参数值不同构造出不同的网络结构。YOLOv5包括四种不同的网络结构:YOLOv5s,YOLOv5m,YOLOv5l,YOLOv5x。这四种网络结构的深度参数值、宽度参数值,见表1。
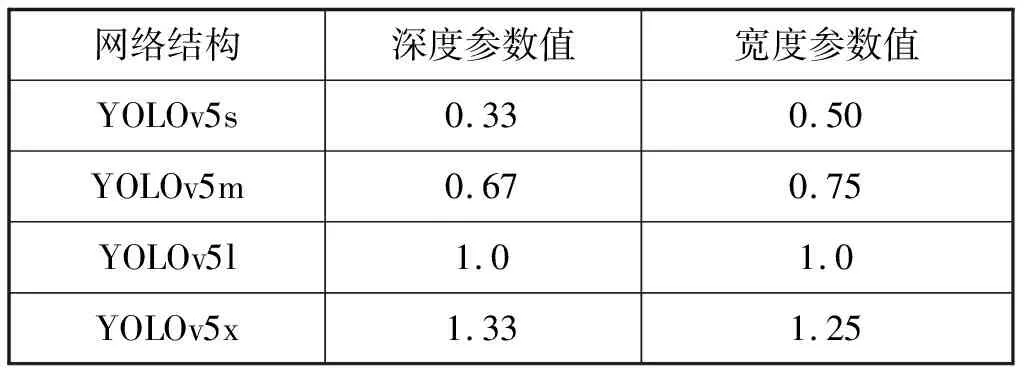
表1 YOLOv5深度和宽度参数对比
与深度最浅的YOLOv5s结构相比,YOLOv5x结构的Neck数量最多,是YOLOv5s结构的4倍。YOLOv5s结构的宽度最窄,YOLOv5x结构的卷积核数量最多,通道层数是YOLOv5s结构的2.5倍。在相同数据集的情况下,YOLOv5s结构的训练和推理性能最好,体积最小,而YOLOv5x结构的平均准确率最好[18]。
YOLO主要网络结构性能对比见表2。本文使用的YOLOv5x网络结构模型如图1所示。
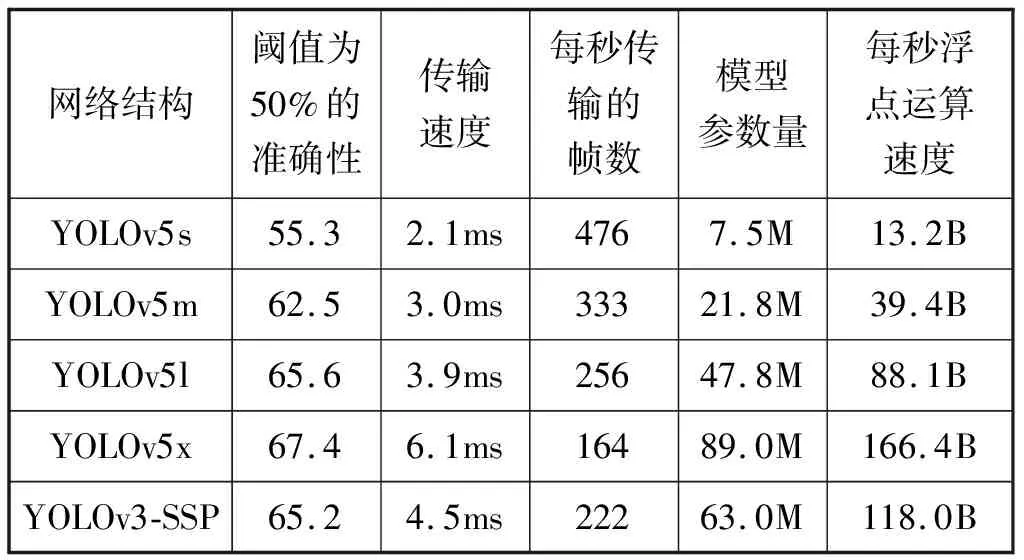
表2 YOLO主要网络结构对比
图1 YOLOv5x网络结构模型框图
BackBone结构是YOLOv5技术的网络核心,其目的是在图像输入的过程中提取信息以进行利用和处理。在网络结构模型当中,梯度信息往往存在许多重复性的问题,可以结合CSPNet技术来解决,使得梯度变化和特征图融入在一起,将模型的参数量和模型FLOPS值都控制在较低的范围之内,从而提高推理的精确度和效率,也可以达到缩小模型体积的目的。
PANet是在Mask R-CNN网络框架和FPN网络框架基础上发展而来的,对信息的传播功能进行了优化和改善。该网络在提取特征的过程中增强了自底向上的路径,提高了底层特征的传播。对于第三个网络路径,上一个网络阶段的数据信息特征映射就是这一个阶段的输入端,按照3×3卷积的方式来操作,每一个阶段输出的特征映射值会直接和同一个阶段的路径信息进行连接,有效增强了高层与低层信息的联合利用。区域和特征之间那些受到损伤的信息路径,在自适应特征池的作用下,也能够得到迅速的恢复[19],并在各特征层对各候选区域进行聚合,避免随机分配。
在深度学习网络中有一个非常重要的环节就是选择正确的激活函数。在YOLOv5中,中间/隐藏层使用Leaky ReLU[20]激活函数,最后一个检测层使用sigmoid型激活函数。本文使用GIOU_Loss损失函数进行bounding box结构的损失计算,表达式为
(3)
GIOU_Loss损失函数与IOU一样,具有非负性、尺度不变性等特性,相比IOU_Loss,GIOU_Loss在任意情况下都可以进行训练。GIOU_Loss损失函数有效的处理了IOU_Loss中bounding box不重叠情况,具有更快的收敛速度,稳定性更强,极大地提升了衡量尺度相交的能力,并利用基于二叉交叉熵和logits函数的损失函数计算目标分数的类概率和损失[21]。
3 实验数据集的准备
由于刀具具有易获取、便携性等特点,是危害人员密集场所安全的主要因素,本实验以可携带刀具作为检测对象,采用航天科工集团203所研制的毫米波人体三维图像集作为实验数据集,包含1081幅携带陶瓷刀和金属刀的人体毫米波图像,目标种类和位置信息都属于数据集中的标注信息。为了确保训练数据和测试集尽可能多的通用性,按照1∶10的比例划分了测试集和训练集。
3.1 数据预处理
对于收集得到的图像数据,采用数据增强的方法来保证不同图像可以被充分训练。本研究主要使用Mosaic数据增强、自适应锚定帧计算、自适应图像缩放等方法。
Mosaic数据增强的实现思路是:一次读取4张图片,对4张图片进行翻转、色域变换以及缩放等操作,并依次摆放在左上、左下、右上、右下4个方向,然后按照4个方向的位置拼接在一起,且图片中保留标注框,至此完成图片和标注框架的组合。Mosaic数据增强丰富了检测数据集,增强了算法的鲁棒性,提高了检测小目标的能力[18]。
在YOLO算法中,为不同数据集设置初始长度和锚宽复选框。在网络训练中,网络基于初始锚定帧输出预测帧后与实际帧的groundtruth进行比较,在计算两者之间的差距后对网络参数进行反向更新迭代。在常见的目标检测算法中,不同图片具有不同的长度和宽度。因此,常见的方法是将原始图像统一缩放到标准大小,并将其发送到检测网络,即自适应图像缩放法。
本研究通过减小图像两端的黑色边缘高度优化原始图像处理方法,减少了推理中的计算量,提高了目标检测的速度。通过这个简单的改进,推理速度提高了37%,效果非常显著。
3.2 数据的标注
在标记数据时,使用labelimg工具进行选择框并标记,分为陶瓷刀和金属刀两种工具,标注的示例如图2所示。
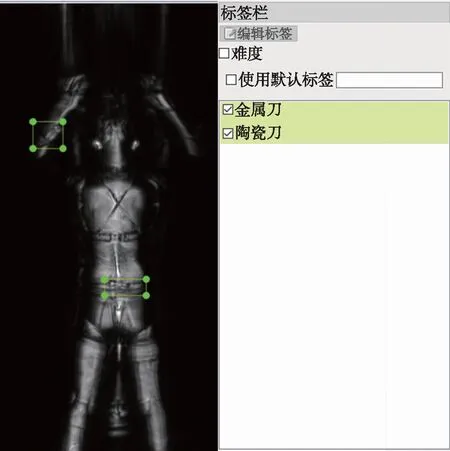
图2 可携带刀具标注图
4 实验与结果分析
4.1 实验设定
毫米波图像目标识别任务模型训练的实验环境为:RTX4000显卡,CUDA10.1 GPU驱动,Pytorch深度学习框架。训练时设置参数:轮数(batch-size)16,初始学习率0.01,动量0.937,训练总迭代次数500次。
4.2 改进方向分析
为了让数据集中包垂直方向的目标数据,Mosaic数据增强部分增加了垂直旋转90°的增强。该增强效果明显,可以有效丰富训练数据的分布,使拟合更加科学合理,同时优化了检测模型的泛化功能。另外,通过适当添加图像数据噪声,使模型的鲁棒性和整体性能更优。
4.3 实验结果分析
从实验结果可以看出,采用YOLOv5算法模型进行训练,训练效果较好,如图3所示。YOLOv5在目标检测上的准确率较高,可以准确地检测和识别相关刀具,但仍需进一步训练以提高准确率。
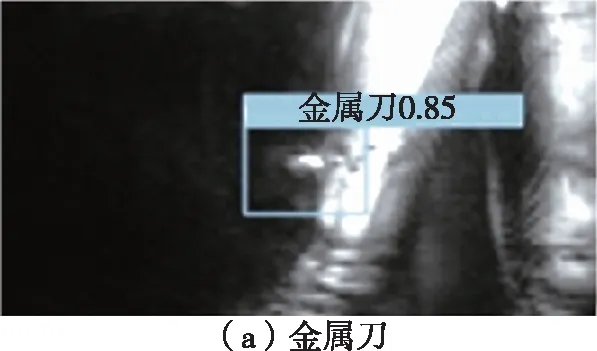
图3 金属刀和陶瓷刀检测结果图
5 结束语
本文重点介绍如何使用YOLOv5网络模型实现不同刀具的毫米波图像检测,介绍YOLOv5算法、数据集处理和网络参数优化,并提出了相应的分析改进思路。通过实验结果证明,YOLOv5能够保证对相应目标的检测,检测速度较快,检测准确率较高。结果表明,该模型的检测精度很高,但仍有一些不完善之处。在训练过程中,要注意迭代次数,否则结果会过拟合,图片无法正常识别。后续将进一步优化补充毫米波图像集,增加环境与检测物品的多样性,并研究提升检测性能的策略。
