基于多通信半径和麻雀搜索的节点定位算法*
2022-01-17铎杨雅文高玉蔚王婵飞
彭 铎杨雅文高玉蔚王婵飞
(兰州理工大学计算机与通信学院,甘肃 兰州 730050)
无线传感器网络(Wireless Sensor Network,WSN)是由低成本、低功耗、可自重构的传感器节点组成。并且无线传感器网络在军事、环境监测、工农业生产、医疗健康、建筑物监测、空间探测等领域有着广阔的应用前景和巨大的应用价值[1-2]。能够准确得知无线传感器网络的节点位置是将无线传感器网络技术应用于实际的前提,因此,如何提高无线传感器网络的定位精度是近年来的热点研究领域之一。现有的无线传感器网络定位算法主要分为距离相关算法和距离无关算法[3]。常见的距离相关算法有到达时间算法(ToA)、到达角度(AoA)、接收信号强度(RSS)等[4-5]。但由于距离相关算法需要额外的硬件支持,因此距离无关算法应用更为广泛。
1 概述
DV-hop算法作为距离无关算法,具有易实现,成本低,不需要额外硬件设备等优点被广泛应用。近年来许多学者将与自然相关的进化算法应用于提高DV-hop算法定位精度中,如粒子群算法(PSO),鲸鱼优化算法(WOA),萤火虫算法(FA)等。以下文献采用了智能优化算法的思想:文献[6]提出了基于改进的布谷鸟算法,采用Levy飞行策略和柯西分布对布谷鸟算法进行改进,增强其寻优性能并应用于DV-hop算法中有效地提高了定位精度。文献[7]对跳距进行了修正,并且采用新型智能优化算法runner-root算法优化传统DV-hop算法,得到更加精确的未知节点坐标。文献[8]将定位问题抽象为函数寻优问题,采用并行鲸鱼优化算法提升了原算法定位精度。本文所采用的麻雀搜索算法(SSA)是新型智能优化算法,相比于其他优化算法有更强的寻优性以及收敛更快的优点;使用多种通信半径细化节点跳数以降低平均跳距误差的思想也被广泛应用。文献[9]采用双通信半径进行广播,使节点间的跳数不再为整数,使计算出的平均跳距更加精确,达到提高定位精度的目的。文献[10]利用多级通信半径修正锚节点到信邻节点的跳数信息。再根据信标节点与未知节点的距离,对平均跳距加权处理,并将每个加权后的平均跳距参与未知节点平均跳距的计算,使未知节点的平均跳距更符合实际网络情况。以上改进针对传统算法中使用平均跳距误差较大的问题对跳距进行了修正,或使用智能优化算法改善采用最小二乘法估计坐标存在的对初值敏感的问题。但以上改进仅单一的考虑了DV-hop算法在传播阶段或在坐标估计阶段产生误差的原因,因此本文提出了一种基于多通信半径和麻雀搜索算法的WSN定位方法,对算法在估计平均跳距阶段因为网络拓扑分布不均,节点间跳距误差较大的问题采用了多通信半径进行修正;以及对计算节点坐标阶段,使用最小二乘法对初值敏感、受测量误差较大的问题采用了LSSA智能优化算法进行修正,以此达到提高算法定位精度的目的。
1.1 DV-hop算法
DV-hop算法主要分为3个步骤[11]:
①计算最小跳数
各锚节点向整个网络广播发送包含其位置坐标的信息,节点间跳数初始化为0,接收到信息的节点将跳数记为1跳,并将其转发。每转发一次跳数值加1,每个节点记录其接收到的最小跳数值。对于接收到跳数较高的锚节点信息记为无用信息并忽略。
②估计到各锚节点的平均跳距
每个锚节点根据上一步中记录的与其他锚节点的位置信息和相距跳数,利用式(1)估算平均每跳的距离:
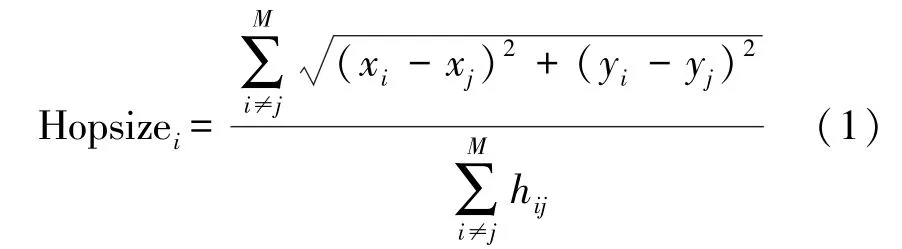
式中:(x i,y i)和(x j,y j)是锚节点i和j的坐标,h i j是锚节点i与j(i≠j)之间的跳数。获得各锚节点平均跳数Hopsizei后,各锚节点向整个网络广播其平均跳距。未知节点保留接收到的第一个跳距信息并转发给邻居节点。
③未知节点位置估计
未知节点通过②获得到每个锚节点的信息,通过平均跳数和跳距计算到每个锚节点间的距离。再采用三边测量法或最大似然估计法计算其自身位置坐标。
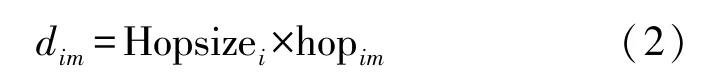
式中:d im和hopi m为锚节点i和未知节点m之间的距离和最小跳数。
2 基于动态自适应Levy步长的麻雀搜索算法(LSSA)
2.1 麻雀搜索算法[12]
SSA是一种受麻雀觅食行为和反捕食行为启发而提出的一种新型群体智能优化算法,SSA算法相比于已有优化算法如:灰狼优化算法、粒子群优化算法、引力算法等,对单峰值函数、多峰值函数以及固定维度函数都有更好的寻优效果,即寻优精度更高,在同等迭代次数下能更快的收敛到最优解;SSA算法相对于其他算法而言具有更好的鲁棒性和收敛速度,可以作为解决优化问题的有效工具。
SSA算法将整个过程抽象为发现者和加入者模型,并且加入了侦查预警机制。在整个群体中,发现者搜索范围更广拥有较强的全局搜索能力,加入者为了获得更好的适应度向发现者靠近。当整个种群意识到危险时将会进行反捕食行为。
发现者数量为20%,在迭代过程中发现者的位置更新定义为:
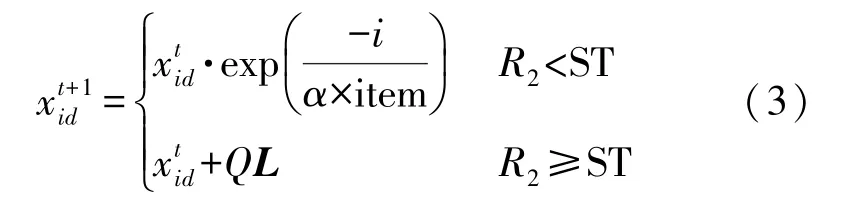
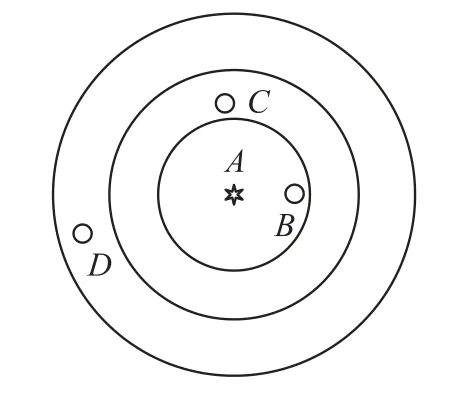
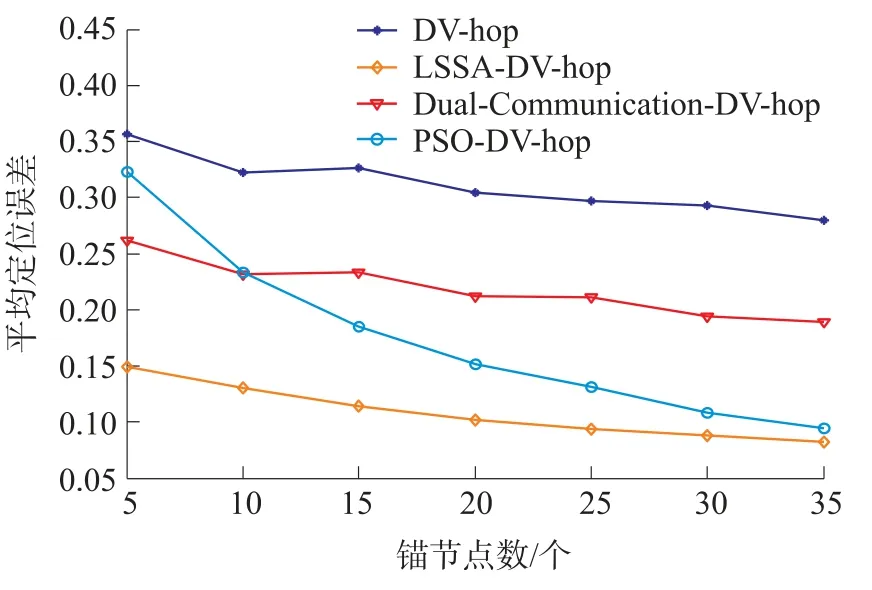
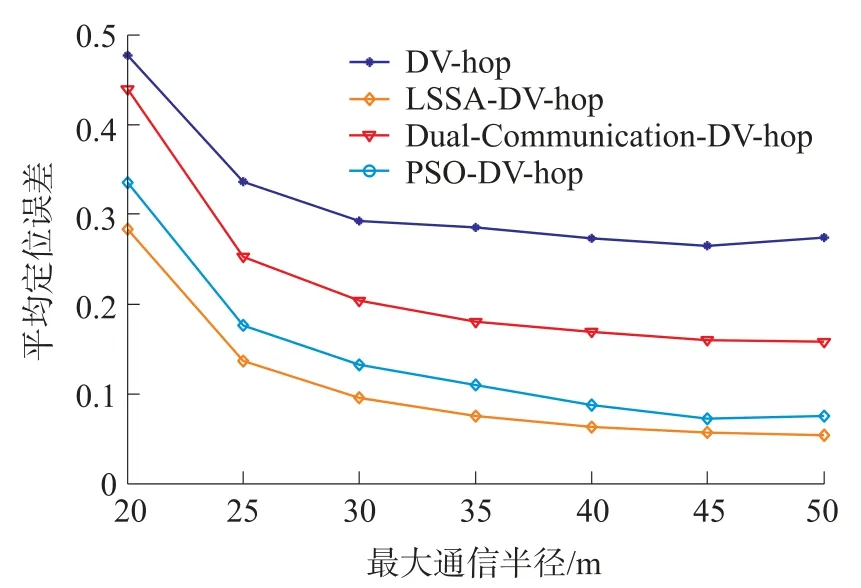
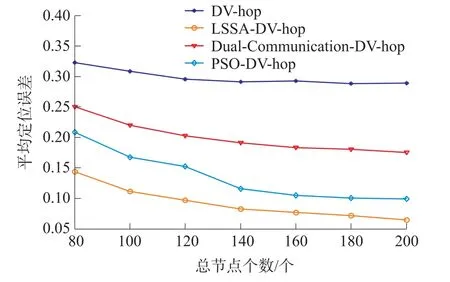
式中:t为当前迭代次数;item为最大迭代次数;α∈(0,1]为随机数;R2∈[0,1],ST∈[0.5,1]分别表示安全值和预警值,Q为服从正态分布的随机数,L表示1×d的元素全为1的矩阵。当R2 除发现者外其余麻雀为加入者,根据下式进行位置更新: 种群中负责侦查预警的麻雀占种群总数的10%~20%,其位置按照下式进行更新: 式中:β表示步长控制参数,且β~N(0,1)为一随机数;K为[-1,1]之间的一个随机数,控制麻雀的移动方向及步长;ε为一最小常数;f i表示第i只麻雀的适应度值;f g和f w分别为当前最优适应度和最差适应度值。 SSA算法在搜索最优解时依然存在容易陷入局部最优解以及过早收敛的问题,因此提出采用动态自适应Levy步长改进SSA算法。 Levy分布是由是由法国数学家莱维(Levy)提出的一种概率分布,Levy飞行服从Levy分布,Levy飞行可以扩大搜索空间,因此把Levy飞行引入智能优化算法中更容易使算法避免过早收敛。Levy飞行位置更新式为 式中:为第t代的位置;⊕为点对点乘法;Levy(λ) 为随机搜索路径,并且满足:Levy~u=t-λ,1<λ≤3,在实验中由于Levy分布较难实现,所以Levy分布通常由Mantegna算法来实现。其中的α为一固定常数,因此在搜索过程中可能存在搜寻能力较差以及精度不够高的问题,因此引入自适应动态步长α1来代替α。寻优初期粒子位置更新变化较大,需要较大步长,使粒子个体能快速寻找到最优解,寻优后期,需要较小步长来提高最优解的精度,因此需使步长的变化呈递减趋势,即α1值越大则搜索步长较大,使算法更趋向于全局搜索;α1值越小则步长越小,使算法更趋向于局部寻优。步长改进如下式[13]: 则改进后的自适应Levy步长为 式中:t为当前迭代数;tmax为最大迭代次数,exp为动态递减因子,即随迭代次数t的增加而减小,在寻优过程中α值较大或较小会导致整体步长增大或减小,此时添加动态因子的作用相应削弱,当α取值足够大或足够小时动态因子的作用则可以忽略不计,则使得在整个寻优过程中无法准确实现算法前期增大步长加强全局搜索能力,而在算法后期减小步长增强局部寻优的目的,因此本文取α=1,对动态因子影响最小,使成为控制步长的决定参数; 定义权重因子f: SSA算法较其他算法本身具有更好的寻优能力,因此在采用Levy飞行策略改进SSA算法时对种群中的部分个体进行扰动。对变异麻雀个体的选择,采用轮盘选择的思想,产生[0,1]之间的一个随机数rand,定义惯性权重递减因子f如式(9),若rand>f则对当前最优解进行动态自适应Levy飞行变异。随迭代次数t的增加f逐渐减小,则产生随机[0,1]之间的数rand大于f的可能性就越小,即上述规则可使寻优前期对麻雀个体变异可能较大,更加有效的搜索到可能存在最优解的区域;算法后期对个体位置变异可能较小,主要在最优解可能存在的区域内进行局部搜索最优解,最大迭代次数过小可能导致算法寻优效果变差,过大会导致算法整体运行时间变长,因此本文设置最大迭代次数tmax为50。 算法流程为: Step 1 初始化,种群规模为N,发现者个数为p,侦查预警麻雀数为s,目标函数维度D,以及迭代次数。 Step 2 计算每只麻雀的适应度值f i,并对f i进行排序,选出当前最优适应度f g和其对应位置xb,以及最差适应度值f w和其对应位置xw。 Step 3 选取适应度优的前p个作为发现者,根据式(3)更新其位置。 Step 4 除发现者以外其余麻雀作为加入者,根据式(4)更新其位置。 Step 5 在种群中随机选取s只麻雀作为警戒者,并根据式(5)更新其位置。 Step 6 一次迭代完成后重新计算每只麻雀的适应度值f i。 Step 7 根据判断是否rand>f成立,选择采用式(8)进行Levy飞行变异,产生新解。 Step 8 是否满足停止条件,满足则退出,输出结果,否则,重复执行Step 2~7; 在DV-hop算法中,只要在锚节点广播半径范围内的节点跳数均记为一跳。如图1所示,图中锚节点A与未知节点B、C、D间跳数均记为一跳,但AB、AC、AD的距离相差较大,采用原传播方式记录跳数存在较大误差,因此引入多通信半径进行传播。 图1 最大通信半径内节点通信图 在算法的第一阶段,锚节点传播半径为: 式中:R为最大通信半径,r为广播半径。 多跳传播时,已划分的单跳会影响多跳的值,减少多跳的误差,但是多跳的跳数值与实际的最优跳数依旧存在较大偏差。单一的锚节点估算出的平均跳距不能完全代表整个网络的跳距情况,并且多跳情况下,未知节点与锚节点的估算距离并不是按照直线计算,节点密度低的区域节点的折线率增大,距离误差将进一步累积,对定位效果产生影响[14]。 因此引入跳数修正因子[14],将锚节点i,j之间的距离定义为d i j,节点i,j之间的真实距离与最大传播半径R的比值定义为相对最佳跳数H ij: 比较估算出的跳数h ij和相对最佳跳数H ij的差值,定义偏差系数σij: σi j能够体现互相通信的锚节点间估算跳数h i j与相对最佳跳数Hi j存在的差异情况。σi j越大,标志着二者之间存在更大的偏差。在通信半径不变的情况下,估算跳数将大于或等于相对最佳跳数,利用式(13)定义差值修正系数ωi j,以优化跳数信息减少误差的累积。 将ωij应用于全网跳数估计: 式中:h xj为未知节点x到锚节点j的估计跳数,h′xj为修正后的跳数,且修正后跳数更接近于相对最佳跳数,跳数值误差将会更小。 无线传感器网络的定位问题可以抽象为求解函数最优值问题,确定适应度函数为: 式中:(x p,y p)为已知锚节点p的坐标,d pu为未知节点u与锚节点p之间的距离。使用本文提出的LSSA算法寻求适应度函数最小值,得到的函数最小值坐标点即为优化后的未知节点坐标。 为验证本文算法有效性,采用MATLAB2014a进行仿真实验。并将本文提出算法与传统DV-hop算法、PSO-DV-hop算法以及文献[9]提出的双通信半径算法进行比较。设定仿真范围为100 m×100 m正方形区域,并在试验区域内随机生成100个节点,具体试验参数如表1所示。 表1 网络环境及参数配置 本实验通过改变锚节点数量、节点通信半径以及节点总数进行实验,验证本文提出算法性能,并使用所有节点的归一化平均定位误差作为衡量定位效果的标准,计算公式如下: 式中:(x,y)为所求得未知节点坐标,(x i,y i)为未知节点实际坐标。R为通信半径,N为未知节点个数。 设置节点总数为100,锚节点数量为25,节点通信半径为30 m。本文提出算法与传统DV-hop算法定位效果如图2所示,可以看出本文提出算法估计节点位置相对传统算法更加精确,本文算法估计的部分节点位置与实际节点位置重合,个别节点仍存在误差,但整体定位误差较小。 图2 LSSA-DV-hop定位效果 4.2.1 定位误差分析 在100m×100m的检测区域内随机分布100个节点,设置锚节点数为20个,通信半径为30 m,四种算法误差如图3所示。 图3 各未知节点定位误差 可以看出各节点定位误差相比于经典DV-hop算法、双通信半径算大以及PSO-DV-hop算法均为最低。DV-hop算法定位误差平均值为9.417 8 m,双通信半径算法定位误差平均值为6.736 1 m,POSDV-hop算法定位误差平均为5.189 4 m,本文算法LSSA-DV-hop定位误差平均值为3.462 1 m。与其他三种算法相比,LSSA-DV-hop算法定位误差分别降低了63.23%、48.60%和12.92%。本文所提出算法的定位精度有了明显提高。 4.2.2 锚节点数对平均定位误差影响 在检测区域随机分布100个传感器节点,通信半径为30 m,锚节点数从5到35时,对比四种算法的定位精度,如图4所示。 图4 锚节点数对定位性能影响 随着锚节点数量的增加四种算法的定位误差整体呈下降趋势,这是由于随锚节点数量增加,各节点的平均跳距误差减小,未知节点和锚节点间的距离估计更加准确。相比于其余三种算法,在同等条件LSSA-DV-hop算法误差始终最小,并且PSO-DV-hop算法在锚节点数为5时误差为0.322 9误差较大。在锚节点数量为15以上时,误差率在8%~12%之间,当锚节点个数为35时误差最小为8.22%,此时DV-hop算法误差、双通信半径算法及PSO-DV-hop算法误差分别为27.98%、18.90%和9.42%,本文算法平均定位误差分别降低了70.62%、56.50%和12.74%。在锚节点个数为5个~35个时算法的定位精度均有了明显提高。 4.2.3 通信半径对平均定位误差影响 在检测区域随机分布100个传感器节点,锚节点数量设置为30个。改变节点通信半径由20 m到50 m,结果如图5所示。 图5 通信半径对定位性能影响 随通信半径增加定位误差总体呈下降趋势,这是因为通信半径较小时未知节点可通信区域存在锚节点数量较少,未知节点无法准确获得自身位置。在同等条件下可以看出LSSA-DV-hop算法定位误差始终低于其余三种算法。平均误差在5%~29%之间,在通信半径为50m时,平均误差最小为5.38%,此时DV-hop算法误差、双通信半径算法和POS-DV-hop算法误差分别为27.43%、15.77%和7.52%,LSSA-DV-hop算法平均定位误差分别降低了80.39%、65.88%和28.46%,定位误差有了明显的下降。 4.2.4 节点总数对平均定位误差影响 设置通信半径为30 m,锚节点数量为总节点数的20%,节点总数为80到160时比较三种算法定位误差,如图6所示。 图6 节点总数对定位性能影响 可以看出四种算法随节点总数增加定位误差呈下降趋势,这是因为随节点总数增加网络连通度提高,未知节点可以获取更多辅助定位的信息。相同条件下本文算法误差始终最低。LSSA-DV-hop算法定位误差在6%~14%,在节点总数为200时,平均误差最小为6.51%,此时DV-hop算法误差、双通信半径算法和POS-DV-hop算法误差分别为28.87%、17.56%和9.89%,本文算法平均定位误差分别降低了77.45%、62.92%和34.18%。说明本文所提算法在各情况下定位误差明显小于DV-hop算法、双通信半径算法以及PSO-DV-hop算法。 4.2.4 算法复杂度分析 由于无线传感器网络通常资源有限的因此在设计定位算法时不能只考虑提升算法定位精度的问题,算法的复杂度也是重要因素之一。设节点总数为n,锚节点数为m,则DV-hop算法中计算节点间最小跳数的复杂度为o(n3),计算平均跳距的复杂度为o(n),计算锚节点与未知节点间距离的复杂度为o(m×n)。[15]文献[9]中,在原始DV-hop算法上增加复杂度o(m×n);PSO-DV-hop算法相较于DVhop算法复杂度增加o(n2)。本文所提算法在多通信半径阶段复杂度为o(m×n),麻雀搜索算法阶段复杂度为o(n2)。因此本文所提算法复杂度相较于DV-hop算法复杂度增加了o(n2)+o(m×n);相较于文献[9]算法复杂度增加了o(n2);相较于PSO-DVhop算法复杂度增加o(m×n),但本文所算法定位误差降低明显,在各情况下定位性能稳定,明显优于DV-hop算法、文献[9]所提出算法的双通信半径算法以及PSO-DV-hop算法。 本文通过分析现有定位算法定位精度低的原因,对产生误差的定位步骤进行优化,提出了基于多通信半径和麻雀搜索的节点定位算法。首先,在广播阶段采用多通信半径的形式细化节点间跳数,并对多跳情况产生的偏差使用跳数修正因子进行修正,使平均跳距更加精确。然后,引入了寻优能力更强的LSSA优化算法对未知节点定位过程进行改进,使定位算法计算出的未知节点坐标更精确,仿真结果表明本文提出的LSSA-DV-hop算法定位精度明显提高,具有良好的定位性能。

2.2 基于动态自适应levy步长的麻雀搜索算法
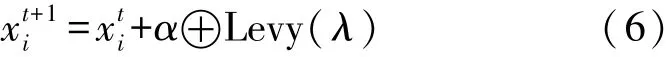
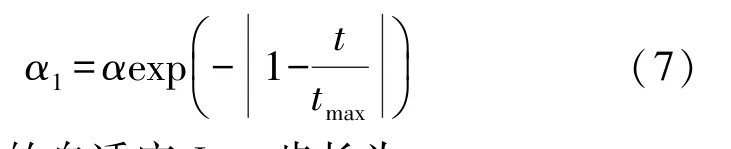
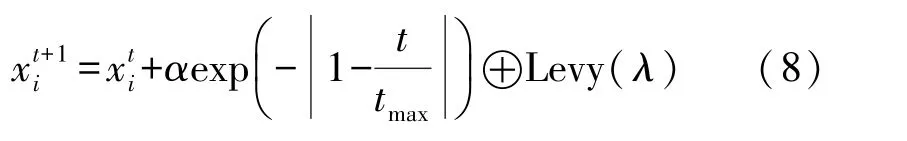

3 基于多通信半径和LSSA的节点定位算法
3.1 多通信半径
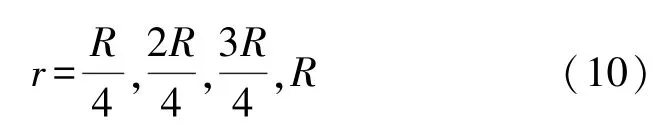
3.2 多跳跳数修正




3.3 坐标优化
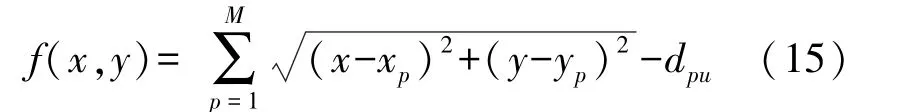
4 仿真结果分析
4.1 实验参数设置

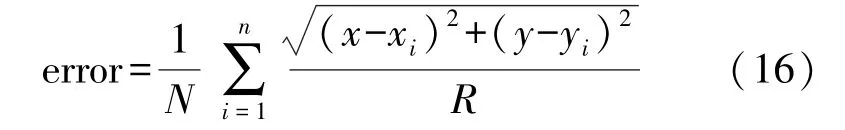
4.2 实验分析


5 总结
