基于改进YOLOV3算法的斜拉桥拉索表面缺陷检测方法*
2022-01-17李运堂谢梦鸣王鹏峰李孝禄
李运堂谢梦鸣王鹏峰李孝禄
(1.中国计量大学机电工程学院,浙江 杭州 310018;2.中国计量大学现代科技学院,浙江 杭州 310017)
近年来,大跨度桥梁在国家和地区经济发展中的作用越来越重要。斜拉桥作为现代大跨度桥梁的重要结构形式,因优越的跨越能力在跨河、跨海大桥中得到广泛应用[1-3]。斜拉桥主要由索塔、拉索和梁三部分构成。其中,拉索为主要受力部件,由外部保护套和内部钢丝束组成[4]。由于拉索长期暴露于外部环境,日晒雨淋等环境因素容易引起保护套破损,外部腐蚀性物质由破损处侵入拉索内部,极易导致钢丝束锈蚀甚至断裂,严重威胁桥梁安全[5-7]。因此,拉索表面缺陷检测极为重要[8]。
常见的拉索表面缺陷检测方法有三种:一是目测,检测人员手持望远镜观察拉索表面是否存在缺陷,效率低、准确性差;二是采用拉索检测车[9],检测人员乘坐吊篮升至高空检查拉索,危险性高、检测结果主观性强;三是视频检测,机器人搭载摄像头沿拉索爬升,拍摄和存储拉索表面视频数据,设备返回后,检测人员通过观看视频检查索体,实时性差、人工判断费时费力。因此,拉索表面缺陷检测的自动化水平亟待提高。
韩国世宗大学Ho等[10]提出拉索表面缺陷位置检测算法,通过滤波降噪和图像增强去除图片中无关干扰并将结果投射到PCA空间完成缺陷识别和分类。李新科等[11]设计了拉索表面缺陷分布式视觉检测系统,采用中值滤波降噪,通过改进Sobel算子提取边缘特征,利用形态学中的开操作对缺陷区域进行分割处理,并对处理后的区域进行像素点统计,根据像素点聚合数目完成决策判别,算法简单、执行效率高,但形态学算子需手动调整。Hou等[12]采用Cascade Mask RCNN算法进行缺陷分割提取,针对拉索表面缺陷数据集稀少问题,利用迁移学习的思想,将混凝土缝隙数据集训练模型权重参数迁移至拉索表面缺陷数据集训练,虽然模型分割效果较好,但是Cascade Mask RCNN为二阶段算法,模型分割效率低。李鑫[13]选用PVC管材模拟桥梁拉索并将缺陷分为片状缺陷和条状缺陷,针对条状缺陷误检率较高的问题,引入PCA算法配合图像旋转进行二次判定,提高了准确率,但效率偏低,关键变量需手动赋值。可见,传统图像处理技术拉索表面缺陷检测的自动化程度不高。
目标检测为深度学习应用领域之一,相对于传统图像处理技术,物体识别更精确,效率更高。Ren[14]等提出的Faster R-CNN为最具代表性的二阶段目标检测算法,识别效果好,但算法处理速度较慢。Redmon等[15]针对此问题提出快速物体识别算法:You Only Look Once,简称YOLO。YOLO属于端对端模型,以整幅图片输入,采用回归机制,直接输出预测框以及框内目标种类。在YOLO基础上,2018年升级的YOLOV3引入残差结构加深主干特征提取网络,并利用多尺度预测增强中小目标检测能力。相对于Faster R-CNN,YOLOV3速度更快。
1 拉索表面缺陷特征分析
根据拉索保护套破损程度,可将表面缺陷分为穿透性缺陷和损伤性缺陷。穿透性缺陷属于严重缺陷,根据形状可细分为孔洞和缝隙。损伤性缺陷危害程度相对较低,外部腐蚀性物质无法直接作用于内部钢丝束,但如果不及时检测并维护,在外部环境催化下,损伤性缺陷可能转变为穿透性缺陷。
不同拉索表面缺陷特征各异。孔洞缺陷尺度不一,较小的孔洞甚至难以肉眼识别,检测难度大;缝隙缺陷与损伤缺陷中的条状损伤外观非常相似,极易混淆,但前者属于穿透性缺陷,危害大,后者属于损伤性缺陷,危害较小。传统图像处理技术侧重于特征提取,适用于背景简单和实时性要求不高的场合。拉索表面缺陷检测实时性和检测精度要求较高,并且缺陷类别分辨困难,传统图像处理方法无法满足要求。YOLOV3算法作为优秀的一阶段目标检测模型,融入了多尺度特征融合结构,兼顾了检测精度和速度,适合拉索表面缺陷自动化检测。
2 YOLOV3算法原理
2.1 网络结构
YOLOV3网络结构包括主干特征提取网络DarkNet53和多尺度融合特征金字塔结构,如图1所示。

图1 YOLOV3网络结构
其中,虚线框部分为DarkNet53主干特征提取网络,Y1、Y2、Y3为不同尺寸特征图,DBL由相应的卷积层(Conv)、批量归一化层(BN)和Leaky ReLu激活函数组成。
DarkNet53为卷积层和5个残差模块串联构成的残差网络,每个残差模块中堆叠不同数量的残差元,残差元由快捷链路和两个DBL模块构成[16]。可通过增加网络深度提高特征学习率,内部残差元的快捷链路缓解了过度增加网络深度导致的梯度消失问题。特征金字塔结构对DarkNet53第五个残差块输出结果进行五次卷积运算,卷积结果一部分输出大尺寸目标预测结果,另一部分通过卷积和上采样与DarkNet53第四个残差模块的输出进行通道上堆叠,堆叠后的输出再进行五次卷积处理,处理结果一部分输出中等尺寸目标预测结果,另一部分与DarkNet53第三个残差模块输出再进行通道上堆叠,最后将堆叠后的特征图进行五次卷积输出小尺寸目标预测结果。YOLOV3网络通过多尺度特征融合,可同时学习浅层与深层特征层语义信息,提高网络模型细粒度,泛化目标检测能力。
2.2 网络预测
YOLOV3算法将输入图片划分为不同尺度网格,实现大、中、小三种尺度目标预测。以输入416×416图片为例,经过DarkNet53和特征金字塔结构后,输出13×13、26×26、52×52三种特征图,相当于将输入图片分别划分为169、676和2704个网格,每个网格负责对应像素区域的预测结果,每种尺度网格均含有大、中、小三种尺寸的先验框。常规YOLOV3算法先验框尺寸如表1所示。

表1 常规YOLOV3算法先验框尺寸
YOLOV3预测为先验框调整过程,每个先验框有5+c个参数,分别为:中心坐标(t x,t y),尺寸系数t w、t h,置信度分数P以及分类总数c。图2(a)为预测框调整示意图。(c x,c y,c w,c h)为最终得到的预测框参数值,采用式(1)计算。σ(t x)、σ(t y)为Sigmoid函数归一化坐标偏移量,(b x,b y)为每个划分的1×1网格左上角坐标,p w、p h分别为先验框的宽和高在当前特征图的映射。

置信度分数P由预测框是否包含目标物体、物体属于某类的概率以及预测框和真实框的交并比(IOU)决定,采用式(2)计算。P r(c)表示目标框是否包含目标物体,包含置1,不包含置0。P r(obj)为目标属于某类的概率。
IOU示意图如图2(b)所示,采用式(3)计算。其中,S A∩B表示真实框A与预测框B交集的面积,S A∪B表示真实框A与预测框B并集的面积。IOU越大表明网络预测效果越好,最大值为1。

图2 预测框调整和IOU示意图
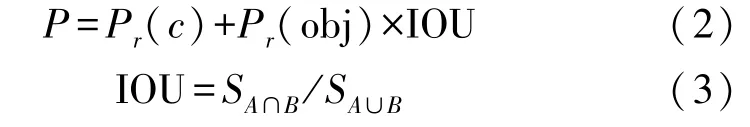
特征层中一个目标区域可生成多个预测框,需采用非极大值抑制进行筛选,筛选方式如式(4),具体步骤为:将预测框按属于某类的置信度得分排序;选择排序靠前的框作为目标预测框;设定概率阈值T;去除与目标预测框重叠较多的预测框。

式中:I为真正预测框,IOU(G,E i)为目标预测框G和其余框E i的交并比,T c为概率阈值。
2.3 常规YOLOV3算法的不足
常规YOLOV3先验框尺寸针对COCO数据集,不符合拉索表面缺陷特征;拉索表面缺陷尺度多变、类别较少,且与颜色无关,常规YOLOV3的DarkNet53网络层数冗余较大,特征金字塔结构多尺度信息学习能力不足;缝隙缺陷与损伤缺陷中的条状损伤类似,缺陷尺度多变,预测框回归位置不精确,常规YOLOV3分辨效果不好。
因此,需对常规YOLOV3先验框选取,网络框架结构以及损失函数进行改进,从而满足拉索表面缺陷检测要求。
3 YOLOV3算法改进
3.1 先验框选取
先验框尺寸影响模型训练的预测效率和准确率。YOLOV3引入了Faster R-CNN的先验框机制,但常规YOLOV3算法先验框尺寸针对COCO数据集,见表1,不符合拉索表面缺陷特征。通过分析数据集图像中各缺陷尺寸特点,以平均交并比(Avg_IOU)作为评价标准,从数据集中随机抽取数据样本,采用K-Means[17]聚类算法对样本数据进行聚类分析,获得更符合缺陷特征的先验框。Avg_IOU计算式为

式中:T为样本中标注的真实框,I e为聚类框,k为设置的聚类框数目,N为样本数据中真实框数目,N k为第k个聚类框对应的样本数量,fIOU为计算聚类框和真实框交并比的函数。
k取值1~10,对数据样本进行先验框聚类试验,结果如图3所示。

图3 聚类试验结果
由图3中可以看出,当k较小时,Avg_IOU随k增大逐渐增大,但增长速度逐渐减小,当k≥9时,Avg_IOU增长速度趋近于0,Avg_IOU趋于最大值。由于k大于9影响算法收敛速度[18],取k=9,即通过聚类分析得到9种先验框尺寸,如表2所示。

表2 改进YOLOV3先验框尺寸
3.2 网络结构改进
常规YOLOV3网络针对COCO数据集中复杂的种类特征,采用较多的网络层数完成语义信息学习。考虑到拉索表面缺陷种类较少、缺陷识别与颜色无关、检测实时性要求高等因素,削减DarkNet53网络层数,将主干网络中融合的残差块数量减少至15,能够在不影响缺陷识别精度的同时,大幅度提高识别效率。在特征金字塔结构中,虽然常规YOLOV3网络采用类似FPN的上采样加融合方法,提高了中、小尺度物体预测能力,但拉索表面缺陷尺度信息非常丰富,常规YOLOV3依然存在漏检和错检。针对此问题,引入SPP-Net[19]中SPP(Spatial Pyramid Pooling)结构,如图4所示。

图4 SPP结构示意图
SPP结构分为两部分,一部分通过5×5、9×9、13×13尺寸的最大池化层,另一部分通过快捷链路与池化后的结果进行通道堆叠。通过多重感受野特征融合,能够聚合不同区域中最显著的上下文信息,使网络有效学习多尺度拉索表面缺陷特征。Dark-Net53中的第五个残差块后接SPP结构,通过五次卷积调整通道数并进一步提取特征,卷积后的结果一部分用于Y1特征图预测,一部分通过卷积和上采样应用至后续预测;Y2和Y3特征图前设置SPP结构用于提升中、小尺寸目标预测精度。改进后的网络结构如图5所示。

图5 改进的YOLOV3网络结构
3.3 损失函数设计
常规YOLOV3损失函数由预测框回归损失、置信度分数损失和分类损失三部分组成,预测框回归损失直接使用IOU作为损失函数,虽然可提高预测框回归质量,具有尺度不变性,但存在以下问题:
①预测框和真实框如果无交集,二者无论距离多远,IOU均为0,模型无法优化无重叠预测框和真实框。
②收敛慢,回归不准确。
③无法完整体现YOLO算法预测框特点,优秀的预测框回归损失应该包含三个要素:交集区域面积、中心点间距和宽高比[20],IOU回归损失只考虑了交集区域面积。
针对上述问题,引入CIOU作为预测框回归损失,CIOU包含回归损失的三要素,预测框回归更精确,由于规定了与真实框的最小标准化距离,加快了函数收敛速度。图6为CIOU计算示意图,采用式(6)计算。

式中:d2(b gt,b)为真实框中心点和预测框中心点的欧氏距离,即图6中的D;c为同时包围预测框和真实框的最小包围框的对角线距离,即图6中的C。α为正值权衡参数,见式(7)。q用于衡量宽高比一致性,采用式(8)计算,w gt和h gt分别表示真实框的宽和高,w和h分别表示预测框的宽和高。

图6 CIOU计算示意图

采用式(9)计算预测框回归损失,CIOU越大,回归损失越小,预测框越准确。预测框回归损失Coordloss、置信度损失Confloss和原分类损失Classloss分别采用式(9)、式(10)和式(11)计算。

式中:表示第i个网格中的第j个预测框是否包含物体,包含物体fobji j置1,否则置0。s表示图像划分的网格数,B表示单个网格包含的预测框数,C为缺陷种类数,p为属于某一类的概率,c为缺陷种类编号,λnoobj为惩罚系数。
由于拉索表面缺陷中条状损伤和缝隙较为相似,常规YOLOV3分类效果不好,需增大分类损失在损失函数中的权重系数λclass,提升分类精度,修改后的分类损失函数为

经试验可知,λclass=1.5时,分类效果较好。综合式(9)、式(10)和式(12)得到网络总损失函数。

4 缺陷检测实验
4.1 实验样机和数据集
由于拉索表面缺陷没有公开的数据集,并且实地采集困难,采用与拉索表面外观相近的PVC管材模拟拉索保护套常见的三种缺陷,孔洞、缝隙、损伤。
如图7所示,四个摄像头均匀设置在爬升机构上,无线信号接收机接收发射机传回的图像数据,画面分割器将四路视频信号转换成单路视频信号,通过图像采集卡输入计算机。

图7 图像检测系统
图8为图像检测系统各个模块。图8(a)为图像采集模块,包含CCD和镜头,CCD采用顺华利电子有限公司的SHL-019,500万像素,最大分辨率1920*1080;镜头选用定焦5 mm,C接口参数为2/3的工业镜头,镜头中心与拉索表面距离约110 mm。四个图像采集模块互成90°设置,采集拉索周向表面图像。
图8(b)为无线图传模块,包括四个发射机Ⅰ和一个接收机Ⅱ,每个发射机与对应的图像采集模块连接,外置电池供电。接收机接收四路发射机信号后输出四路HDMI信号。发射机和接收机之间有效传输距离为500 m,视频画面清晰度1080p,传输时间小于150 ms,满足实时性要求。
图8(c)为图像后处理模块,Ⅰ为MT-VIKI画面分割器,将接收的四路信号转换成单路信号,在单个屏幕上同时显示拉索表面周向图像。Ⅱ为图像采集卡,将画面分割器输出的HDMI信号转换成USB信号输入计算机。

图8 图像检测系统各模块
计算机硬件环境:CPU为Intel i5 8th;显卡为NVIDIA GEFORCE GTX 1050Ti,显存4G;内存16G。算法开发基于Windows10系统,采用VSCODE开发环境,Python3.6开发语言,Pytorch1.2深度学习框架和开源算法库OpenCV4.1。
为了提高模型训练结果的鲁棒性,通过更换PVC管、改变拍摄角度和摄像头相对位置获取更多的图像数据,得到3 000张随机包含孔洞、缝隙、损伤三种缺陷图像,并按5∶1随机划分为训练集和测试集。采用LabelImg对图像中包含的缺陷进行标注,标注界面如图9所示,输出包含缺陷位置、种类等信息的xml文件。

图9 LabelImg标注界面
4.2 评价指标
为了检验改进YOLOV3缺陷识别效果,选取目标检测领域中主流检测指标对模型进行性能评估。假设T C为属于当前类别并被正确划分为该类别的缺陷数量;F C为属于其他类别但是被错误划分到当前类别的缺陷数量;F N为属于当前类别但被错误划分到其他类别的缺陷数量。定义如下指标:
①精确率P e

②召回率R

③F1分数

④P-R曲线的面积,AP

⑤均精度值,mAP

为了综合考虑精确率和召回率,引入AP值概念,其量化方式为P-R曲线所包围的面积,AP值越高,分类性能越好。对于多分类场合,采用mAP对分类性能进行评价。
4.3 网络训练
对改进后YOLOV3算法使用GPU进行训练,采用Adam优化器,Batch_size设置为4,初始学习率设置为0.001,学习率衰减系数设置为0.000 5。网络模型共迭代400次,迭代训练的损失值变化如图10所示。可以看出,前50次迭代中,损失曲线下降速度非常快,继续训练至100个世代后,损失值变化趋于稳定,最终收敛于0.4左右。

图10 损失值-迭代次数曲线
4.4 检测实验
将训练好的模型在测试集上测试,通过增加图像中缺陷数量,对比改进YOLOV3算法与常规YOLOV3算法的识别效果。检测结果如图11所示。图11(Ⅰ):改进YOLOV3预测框定位较常规YOLOV3更准确,表明将IOU进化成CIOU作为预测框回归损失提高了缺陷定位准确性。图11(Ⅱ):由于靠下的缝隙缺陷和长条状损伤缺陷相似度较高,常规YOLOV3出现误判,改进YOLOV3由于增大了分类损失权重,可以准确判别。图11(Ⅲ):常规YOLOV3将两处损伤缺陷识别成四个,缺陷定位不准确,部分预测框没有完全包围缺陷轮廓,改进YOLOV3定位精确,无错检和漏检。图11(Ⅳ):常规YOLOV3出现漏检,并且将单个缝隙缺陷错分成两个,改进YOLOV3由于增加了SPP结构,增强了多尺度特征学习能力,没有出现错检和漏检。由此可见,算法改进有效可行,改进后的YOLOV3比常规YOLOV3更准确。

图11 模型效果对比图
检测实验定性表明了改进YOLOV3识别效果优于常规YOLOV3,现定量分析常规YOLOV3和三种改进方法的测试结果。采用划分好的测试集进行测试,测试集随机包含Ⅰ类缺陷(孔洞)、Ⅱ类缺陷(缝隙)以及Ⅲ类缺陷(损伤)。三种改进方法分别为:改进先验框(方法1);改进先验框尺寸和调整损失函数(方法2);修改网络结构并改进先验框尺寸、调整损失函数(方法3)。精度指标采用单分类精度AP、多分类精度mAP和算法优劣评价指标F1分数,速度指标采用视频帧率FPS进行评估,测试结果如表3所示。

表3 分类精度和速度表
可以看出,相对于常规YOLOV3,方法2各类缺陷的AP值、mAP指数和F1分数均有所提升,表明调整后先验框尺寸更符合拉索表面数据集的图像特征。方法2相对于方法1和常规YOLOV3,各项指标均有所提高,表明采用CIOU作为预测框回归损失,增大分类损失在总损失中的权重有助于提高分类精度。方法3在改进损失函数和调整先验框的同时,精简主干特征提取网络提高了检测效率,并通过在特征金字塔中添加SPP结构,融合了不同感受野的显著特征,提升了网络检测精度,相对于方法2、方法1以及常规YOLOV3,方法3检测精度和速度均有一定程度提高,可够满足拉索缺陷检测精度和实时性需求。
4.5 不同算法检测结果对比
选用目标检测领域中主流的检测算法:Faster R-CNN、常规YOLOV3和改进YOLOV3在测试集中进行试验对比,精度指标选用mAP,速度指标采用视频帧率FPS,试验对比结果如表4所示。可以看出,两阶段检测的Faster R-CNN结构复杂、耗时较长、不能满足拉索检测实时性需求,改进YOLOV3相对于常规YOLOV3、Faster R-CNN精度和速度均更优。

表4 不同模型测试性能对比
5 结论
提出了基于改进YOLOV3的拉索表面缺陷检测方法。利用K-Means聚类算法对数据集进行聚类分析,得到合适的先验框尺寸和数量;通过精简主干特征提取网络的残差块数量提高检测效率,在Dark-Net53结构第五个残差块的输出以及Y2和Y3特征图前分别设置SPP结构,融合不同感受野的特征信息提升网络整体预测精度;引入CIOU作为预测框回归损失,提升预测框定位精度,针对实际分类效果较差问题,增大了分类损失权重,提高分类精度。经过一系列迭代训练,在测试集中与常规YOLOV3和Faster R-CNN进行性能对比。试验结果表明,改进YOLOV3检测效率和精度均优于前两者,mAP和FPS指数分别达到了93.7%和17,满足拉索缺陷检测精度和实时性需求。改进YOLOV3可以为拉索运行状态评估提供参考,同时可用于型材划痕检测、高空管道检测以及地下管线检测等领域。
