基于流程控制的汉语篇章结构语料协同标注系统*
2022-01-15徐宸涵顾宇浩张志昊褚晓敏
徐宸涵 顾宇浩 张志昊 褚晓敏 蒋 峰
(苏州大学计算机科学与技术学院 苏州 215006)
1 引言
篇章分析是自然语言处理领域的一个重要研究方向。篇章分析的主要任务是对自然语言文本的内在结构和文本单元间的逻辑语义关联进行研究,从而挖掘出文本的结构化和语义信息[1],为自然语言处理的应用(如自动文摘[2~4]、机器翻译[5~7]、信息抽取[8~9]、问答系统等[10])提供帮助。构建一定规模的篇章结构分析语料资源库是进行科学有效的篇章结构分析的基础。现有的篇章语料资源中,英文的主要包括宾州篇章树库(PDTB)[11]、修辞结构理论篇章树库(RST-DT)等[12],中文的主要包括基于连接依存树的汉语篇章树库(CDTB)[13]和借鉴RST标注的汉语篇章语料库(CJPL)[14]等。就中文语料来说,主要存在两个问题。第一,绝对数量不足,相比英文语料的PDTB标注的2304篇文章,CDTB由500个文档组成,标注了7310个关系,而CJPL仅完成了97篇篇章结构标注。第二,缺少篇章宏观结构语料,无论是哪一个中文语料库都没有篇章宏观结构语料资源。
宏观篇章结构标注任务的起点为扁平的文章段落(图1中P1~P6叶子);需要标注的内容为段落之间的关系(图1中内点)和主次(图1中的箭头指向主要单元);标注任务的终点为只有一个根的篇章结构树。此外在标注过程中,同时需要产出每个段落的主题句、全文主题等辅助数据。
标注任务要求标注者对篇章的主旨和内容有全面的理解。具体而言,标注者需要首先自顶向下通读文章,把握文章的整体结构,然后依据段落之间的相关性自底向上逐层组合,并判断关系和主次,构建上层结点,并最终完成一棵完整的篇章结构树。
根据上述分析,开展汉语篇章宏观结构语料标注(以下简称“语料标注”)是必要且紧迫的。然而,现有的语料批量标注流程模式主要有两种,即纯手工标注[15]和单机辅助标注[16]。在纯手工标注流程中,标注主体为各标注小组,标注工具为传统的纸笔,管理方式为人工控制。标注小组各成员首先分别对一份篇章结构生语料进行独立标注,接着通过组内讨论的形式对有疑问的部分进行意见统一,并将一轮标注工作计算的一致率和讨论成果交由标注小组负责人进行抽样交叉检查,对存有疑问的篇章还要进行组间讨论。在单机辅助标注流程中,标注主体仍然为各标注小组,标注工具升级为单机辅助标注程序。使用该程序,通过对篇章结构生语料进行导入、预处理、标注、导出的标准流程操作,基本将手工独立标注的部分转移至计算机。剩余标注流程与纯手工标注基本一致。
结合以上两种标注模式可以发现,篇章语料的篇幅长度、结构复杂性、语义模糊性决定了语料标注并不是单纯的个人行为,而是综合了个人行为、集体行为,并且严格遵循一套既定流程的、具有主观性和特殊性的活动。开展这样的活动仅依靠人力进行流程控制有很大概率会在流程交接环节损失不小的效率,产生不可避免的主观误差,从而得到并不准确的标注成果评估。例如,小组进行组内、组间讨论实际操作起来协作效率很差;对一轮标注工作手工计算一致率时可能导致运算失误;将单机辅助标注成果导入、导出计算机的过程同样增加时间成本等。
针对以上问题,本文提出并实现了一种基于流程控制的汉语篇章宏观结构语料协同标注系统(以下简称系统),它综合了标注流程控制、用户管理、语料库管理三大模块,对篇章语料标注流程的各个部分进行了针对性的设计和系统性的优化。部分系统效果图见图2~图3。
基于本文设计的流程控制机制,该系统具有以下三种优势:第一,语料集中管理:将生语料以任务的形式进行管理标注入库,并为每一任务状态维护一个标志以实现进展跟踪和自动控制。第二,系统权限分明:系统设立标注员、审核员、管理员三角色,分权限分工协作,契合任务流程。第三,标注过程易于控制:根据任务状态准确分配语料到各个角色,收集标注成果数据及标注流程中产生的行为数据优化控制过程。基于上述设计,系统简化了语料在各个环节的交接过程,极大增强了协作性,提高了标注效率,减轻了工作负担。
2 基于流程控制的汉语篇章宏观结构语料协同标注系统
相比于微观结构标注(如句法结构等),宏观篇章结构标注由于其需要阅读的内容多、结构界限较为模糊等固有特点,导致标注者的标注结果带有更多的主观成分,不易取得完全相同的看法。为了消除主观性对标注结果质量的影响,需要在标注流程上采取协同的方式,从多个标注者的主观结果中寻找共性和客观性。另外,为了解决在标注实践中出现的语料版本混乱、结果无法溯源、进度难以监控等问题,减少不必要的麻烦,提高标注效率,亟需一个中心化的标注系统协调所有语料标注参与者的合作。

图4系统结构与功能
图4 为本文设计的标注系统的总体结构与提供的功能。该系统以标注流程控制为核心,结合用户管理和标注后的语料成品库子系统,提供进度监控、协同标注、版本控制等多种服务,提高工作效率,以期加速语料库的建设。严格遵循一套完整的标注流程规范是该系统解决传统标注问题的基本思想。对使用传统手工标注的小组工作时间进行统计,独立标注效率约为6.9篇/时,小组讨论效率约7.7篇/时[1],并且未包括数据统计、数据整合等中间步骤耗时。使用该系统进行标注,独立标注效率约为8.0篇/时,中间步骤耗时几乎可以忽略,效率有了一个显著的提升。
3 标注流程控制
纯手工标注和单机辅助标注要面临的最大问题就是标注流程复杂,包括人员的分配、标注内容的提交与审核、绩效评定等,而将这些流程规范化、系统化是本系统的首要任务。
标注流程控制设计是系统设计的核心,对生语料从上传到标注完成入库进行全面控制管理。流程分为生语料创建(包括生语料入批、人员分配)、标注员标注、一致性检查及审核员审核、成果入库几个部分。
图5为标注流程示例,图中包含了3位标注员,实际标注人数可以视情况调整标注环节的人员数量。对单个生语料直接进行管理过于精细,管理操作琐碎,通常,生语料以批的形式进行标注入库,可按批次分配标注员、审核员。由于标注任务繁重,实际标注过程采用分组的形式进行工作,为了避免小组之间产生风格差异,还需要进行经常性的组员轮换。

图5 标注流程的数据流转
标注进度的监控将由生语料和生语料批次(即任务)状态来描述。具体来说,在标注开始时,一份新的生语料由管理员添加到一个任务,并分配相应的标注员和审核员,此时这些生语料和任务都应处于待标注状态。当且仅当一份生语料被分配到的所有标注员都完成标注,但未通过一致性检查时,该份生语料改变为待审核状态;当且仅当任务所属的所有生语料没有处于待标注状态时,任务改变为待审核状态。标注完成的生语料通过了一致性检查或审核员完成审核后,改变为已完成状态;当且仅当任务所属的所有生语料都处于已完成状态,任务改变为已完成状态。进度监控是实时的,对任务所属生语料的增删、标注人员的增删应同步改变状态。
标注任务创建到完成的过程类似工厂的流水线,以确保数据的规范和可控。当生语料进入标注流程控制,无论是标注员还是审核员,在提交了成果后都不能再修改,保证语料库中所有的语料都有溯源记录,同时也实现了最低程度的版本控制。
根据上面的论述,设计的数据库结构如图6所示,图中省略了实体的标识符主键属性。中间结果表的主键为人员标识符、任务批次、生语料标识符,其中人员标识符和任务批次是标注分配表的复合外键,人员标识符和生语料标识符是语料分配表的复合外键,除此之外,还需通过存储过程来保持中间结果为标注分配和语料分配的笛卡尔积。状态标志用于跟踪任务进展和结果保护(例如当入库之后历史记录就不再允许改动),在存储过程中自动维护、更新。
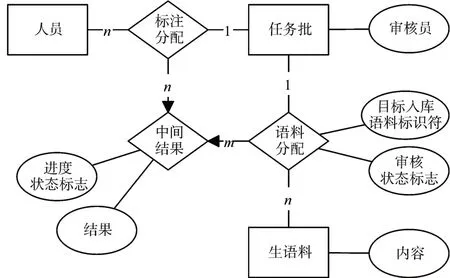
图6 数据库ER图
通过这种设计,可以实现对标注各个环节的关键数据留档备份,和对任务进度的实时监控。
如果需要在下一批次的任务中轮换小组成员,只需在新建的任务批次记录中设置不同的人员即可,所以,小组人员组成的概念实际上被任务批次的人员分配取代,并且容易实现对不同的任务批次分配不同数量的标注人员的需求。
对于多个标注者标注的不同结果,为发挥计算机的优势,在将不同标注结果提交审核员之前,系统计算这些成果的一致性,来侧面衡量标注结果的客观性,验证标注质量。一致率不足的需要提交审核员审核。一致率的计算公式如式(1)所示,式中A、B分别代表两名标注者。

为了避免偶然的标注一致对指标计算的干扰,还需使用式(2)进行Kappa值的计算,式中P(A)表示标注一致的比例,P(E)表示偶然一致的比例。
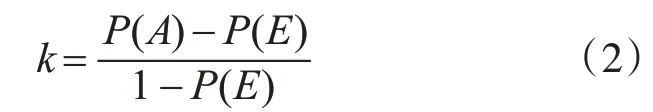
系统还实现了把已标注的生语料退回流程重标的需求,为此,一个关键的设计是将生语料与熟语料统一到兼容的格式定义中。篇章结构的构建是自底向上进行的,在标注过程中,生语料从多根的树林转变到单根的篇章结构树,因而根据此点设计出兼容生语料与熟语料的文件格式。
一个完整的标注系统同时需要提供标注、审核等工具,通过工具可以方便收集人员标注过程的各种副产物数据,如标注时长等,可用于对标注人员建立用户画像,这是手工管理不可能实现的。最后,系统还需要丰富的格式化转换器以与其它系统一同工作。
4 用户管理
用户管理系统的设计充分考虑到了完整的标注流程所涉及到的角色与权限,目标是清晰区分标注活动的参与者,便于标注活动的管理,提高标注效率。围绕标注流程控制设计,在实现基础的用户创建、注销等功能之上,系统为防止越级修改增设了权限控制功能,为对标注活动进行更好的检测增设了绩效评定服务。
权限控制分为动态权限控制和静态权限控制两方面。动态权限控制在标注流程控制中已经提到,即在存储数据时使用人员标识符作为中间结果的主键。静态权限分成语料库权限、用户管理权限、使用格式化器的权限、生语料管理权限、任务管理权限五种共27个具体的权限。不同的角色拥有的权限大小有区别。一般地,标注员和审核员禁止被赋予任务管理权限,管理员拥有大部分权限。
绩效评定针对标注员,依赖于标注成果的统计和行为分析数据的收集。标注成果统计较为直接,通过该标注员已标注的生语料数、通过一致性检查概率等数值体现。由于本系统基于的流程控制的特性,部分从标注行为中收集的数据也将影响绩效评定,故将统计量罗列在此。对单个标注员标注单份生语料的流程,系统主要关注标注总时间、正操作次数、反操作次数及最大间隔时间这四个数据量。
4.1 标注总时间
标注总时间统计标注员从进入该份生语料的标注页面,到提交标注成果离开之间的时间差。消除噪音数据后,一份生语料的标注总时间明显地与它的复杂程度呈正相关。标注总时间将被计算入标注员绩效。
4.2 正操作次数
标注员标注一份生语料操作的次数与语料的复杂程度呈不严格的正相关。定义正操作次数为对建立一棵篇章结构树有促进作用的操作,则正操作次数最后将得到粗略的对生语料的标注起到促进作用的操作次数,或用于对一份生语料的篇幅长度和复杂程度进行评估,得到相应的反馈呈现给审核员。
标注一份生语料主要包括了以下操作:选择关系类型,选择关联子节点个数,选择中心数,创建新的关系,删除关系,修改边的权重和回退操作。由于创建新的关系的前提是正确配置关系,因此正操作次数为避免重复,仅将创建关系节点的操作以及修改任意边的权重的操作计算在内。删除已创建节点和回退操作不计入正操作,也不扣除正操作次数。
4.3 负操作次数
与正操作数不同,负操作次数统计了标注员在进行篇章标注时对解构一棵篇章结构树有促进作用的操作,包括已有关系节点的移除和回退操作。负操作次数直观地给出了在一篇语料标注的过程中标注员认为自己标注错误的次数,对评估该份生语料和负责此次标注任务的标注员的绩效都能形成参考。
4.4 最大间隔时间
一份语料的标注重心或难点能够通过标注的间隔时间有所体现,因为通常来说人思考得越久,就表明越不能很有把握得对此处如何标注下结论。
间隔时间用来描述标注员在篇章标注过程中两次操作的间隔。系统统计标注员标注一份生语料所进行的所有操作中,间隔时间最长的若干操作,并对应到这些操作所关联的节点。另外,设置间隔时间阈值,对小于阈值的间隔时间的操作忽略,判定为正常标注。考虑到人的思考习惯和标注习惯不同,有些标注员的标注习惯是仔细考虑之后再操作,并不会出现太多增删的二次操作,使用最大间隔时间能够在一定程度上弥补正负操作次数的局限性。
随着一份生语料任务被多个标注员标注,系统中行为数据会不断丰富,在提交审核员审核时,系统将对不同标注员的上述数据量进行均值计算,最终向审核员提交该份语料的整体难度、标注重点段落的提示,以帮助审核员快速定位审核重点,提高审核效率。
5 语料库管理
语料库管理系统最主要的功能是接收通过合法流程标注完成的语料,并对其进行管理。语料库管理的方式如上文所述,以批的形式标注入库,同时保存带有状态标记的中间结果。
为了协助标注人员更好地进行标注,语料库管理系统提供部分辅助统计组件,即篇章语料统计功能。
褚晓敏等提出[1],通过每个类别的篇章关系的数量以及主次关系,可以推断某一类文章常用的篇章关系,以及常用写作架构。因此,系统参考建立了基本篇章语料统计功能,并实验性地进行了一部分统计,获得了部分数据,而篇章语料统计分析数据对真实世界的反馈还有待进一步研究。
篇章语料统计主要分为两个部分:生语料数据库和熟语料统计分析。其中,生语料数据库主要为生语料标注流程控制提供基本数据,包括生语料索引表、任务分配表、审核表等。熟语料统计分析主要分析已通过审核员审核并入库的已标注语料,具体熟语料统计项见表1。

表1 熟语料统计条目
系统数据库采用实时更新策略,当标注流程的终端审核员通过审核时,已标注语料文件将被收录至后端熟语料数据库中,数据库会根据熟语料统计项,对新入库熟语料进行统计分析,并将结果更新。
熟语料数据库中已有1200篇已标注语料,其中共有6763个段落,最长段落为34段,最短段落为两段,平均篇章段落数为5.64,篇章段落分布见图7。
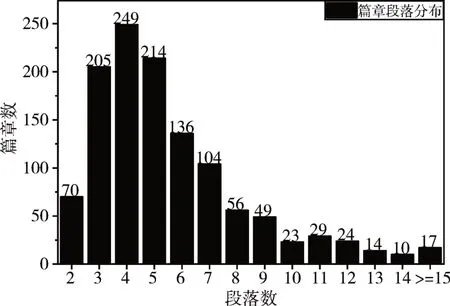
图7 篇章段落分布
在篇章关系方面,并列类关系数量为2150个,占比44.12%;因果类关系数量为621个,占比12.74%;解说类关系数量为2102个,占比43.14%。具体关系及数量见表2。并列类关系和解说类关系数量相似,但因果类关系数量却少许多,数据集存在不平衡。

表2 熟语料统计条目
在主次关系方面,主-次关系(PS)数量为3536个,占比72.56%;次-主关系(SP)数量为156个,占比3.20%;同等重要(EI)关系数量为1181,占比24.24%。具体关系类主次分布见表3。显然数据集中存在不平衡。

表3 篇章关系中主次分布
同时统计了篇章以及段落功能语用,统计结果见表4。从数据来看,篇章语用以新闻报道和故事为主,段落语用以情景、补充和总述-导语为主,与已标注语料中大部分为新闻报道语料的特征相符合。
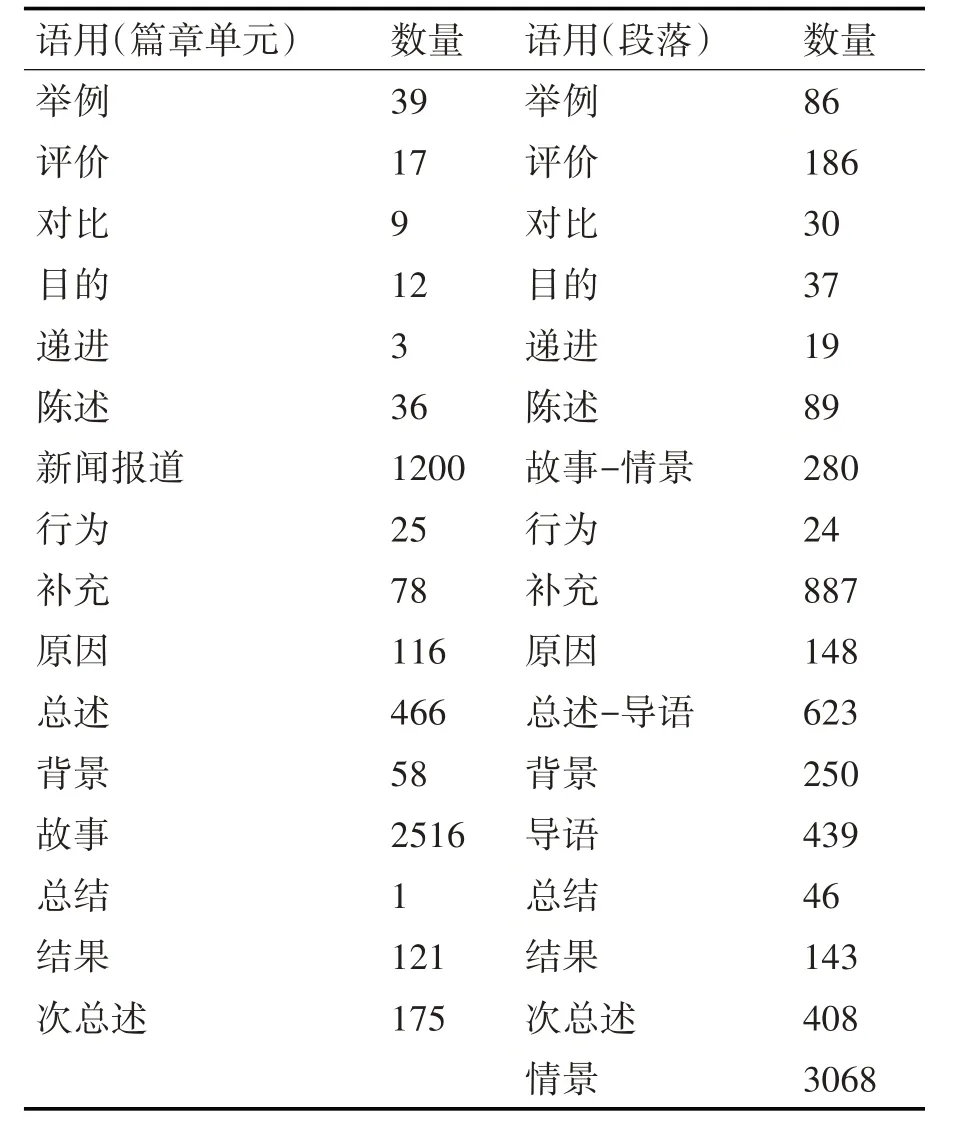
表4 语用分布
6 结语
本文针对手工标注和单机辅助标注汉语篇章宏观结构流程复杂、效率不高、标注质量欠缺的问题,提出一种基于流程控制的汉语篇章宏观结构语料协同标注系统。它能够通过本文设计的流程控制机制,消除了多余的可能产生误差的中间环节,提升了语料标注质量,减少了退回重标的次数,推动了宏观篇章语料库的建设。在接下来的工作中,本文将充分利用系统内收集的标注行为数据,开发智能流程控制系统,进一步优化语料标注流程,提高标注效率和准确度,最终实现一个智能化流程控制的汉语篇章宏观结构语料协同标注系统。
